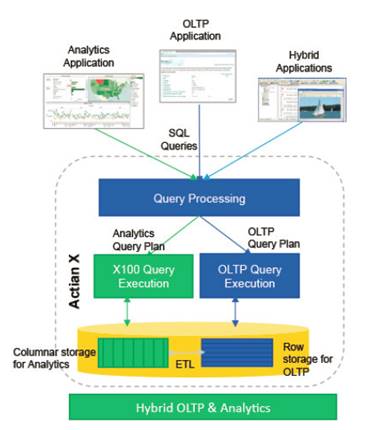
One of the questions we get asked for Vector Cloud deployments is how to load data from Amazon S3 into Vector in a fast and convenient way. This Blog should help answer some of your questions with a step-by-step guide.
S3 is a popular object store for different types of data – log files, photos, videos, static websites, file backups, exported database/CRM data, IoT data, etc. To perform meaningful analytics on this data, you must be able to move it quickly and directly into your choice of an analytic database for rapid insights into that data.
For the purpose of this blog we are going to be using our recently announced Vector Community Edition AMI on the AWS Marketplace. This free AMI gives the Developer Community a 1-Click deployment option for Vector and is the fastest way to have it running in the AWS Cloud.
Different vendors offer different solutions for loading data and we wanted to deliver a parallel, scalable solution that uses some of the best open-source technologies to provide direct loading from S3 into Vector.
In this blog, we introduce the Spark Vector loader. It’s been built from the ground up to enable Spark to write data into Vector in a parallel way. You don’t need to be an expert on Apache Spark to follow the instructions in this Blog. You can just copy the steps to learn as you go along!
NOTE: If you’re familiar with Vector, vwload is Vector’s native utility to load data in parallel into Vector — it’s one of the fastest ways to get data into Vector. vwload currently supports a local filesystem or HDFS for reading input files. With the Spark Vector loader, you can directly load from filesystems such as S3, Windows Azure Storage Blob, Azure Data Lake, and others. Secondly, you also can achieve parallelization within the same file since Spark automatically partitions a single file across multiple workers for a high degree of read parallelism. With vwload, you need to split the files manually and provide the splits as input to vwload. A third benefit of using the Spark loader is that it selects the file partitions based on the number of machine cores which makes the data loading scale with the number of cores even with a single input file. vwload scales with more cores too, but you need to increase the number of source input files to see this benefit.
Step 1: Access to a Vector Instance
Go ahead and spin up a Vector instance using the Vector Community Edition on the AWS Marketplace. For this demonstration, we recommend launching the instance in the US East Region (N. Virginia) and specifying at least a m4.4xlarge instance (8 physical cores).
NOTE: For performance reasons, you would want to have the EC2 instance in the same region as the S3 bucket where your data resides. In this tutorial, our S3 data resides in US East (N. Virginia).
Step 2: Login to the Vector Instance
After you have your Vector instance running, ssh into it as user actian using your private key and the EC2 instance:
ssh -i <your .pem file> actian@<public DNS of the EC2 instance>
NOTE: For more information about connecting to the Vector instance, see Starting the Vector Command Line Interface.
Step 3: Download Spark
After you are logged in to Vector, create a directory to store the temporary files you will be working with and switch to it:
mkdir ~/work
cd ~/work
Download and extract the pre-built version of Apache Spark:
wget https://www.namesdir.com/mirrors/apache/spark/spark-2.2.0/spark-2.2.0-bin-hadoop2.7.tgz
If the previous wget command does not work or is too slow, point your browser to https://www.apache.org/dyn/closer.lua/spark/spark-2.2.0/spark-2.2.0-bin-hadoop2.7.tgz and replace the URL parameter for wget above with one of the mirrors on that page.
Extract the downloaded Spark archive:
tar xvf spark-2.2.0-bin-hadoop2.7.tgz
Step 4: Setup JRE in Your PATH
A Java Runtime is required to run the Spark Vector loader.
Vector includes a bundled JRE. Set the PATH to include it:
export PATH=/opt/Actian/VectorVW/ingres/jre/bin:${PATH}
Step 5: Download the Spark Vector Loader
Get the Spark Vector loader for Spark 2.x and extract it:
wget https://esdcdn.actian.com/Vector/spark/spark_vector_loader-assembly-2.0-2.tgz
tar xvzf spark_vector_loader-assembly-2.0-2.tgz
Step 6: Set Up Database and Create the Schema
Create the vectordb database that we you use to load data into:
createdb vectordb
Connect to the database using the sql tool:
sql vectordb
Now you will enter a couple of SQL commands in the interactive shell to create the schema that matches with the demo on-time data that you are about to load.
Copy the following commands below and paste them into the shell:
create table ontime(
year integer not null,
quarter i1 not null,
month i1 not null,
dayofmonth i1 not null,
dayofweek i1 not null,
flightdate ansidate not null,
uniquecarrier char(7) not null,
airlineid integer not null,
carrier char(2) default NULL,
tailnum varchar(50) default NULL,
flightnum varchar(10) not null,
originairportid integer default NULL,
originairportseqid integer default NULL,
origincitymarketid integer default NULL,
origin char(5) default NULL,
origincityname varchar(35) not null,
originstate char(2) default NULL,
originstatefips varchar(10) default NULL,
originstatename varchar(46) default NULL,
originwac integer default NULL,
destairportid integer default NULL,
destairportseqid integer default NULL,
destcitymarketid integer default NULL,
dest char(5) default NULL,
destcityname varchar(35) not null,
deststate char(2) default NULL,
deststatefips varchar(10) default NULL,
deststatename varchar(46) default NULL,
destwac integer default NULL,
crsdeptime integer default NULL,
deptime integer default NULL,
depdelay integer default NULL,
depdelayminutes integer default NULL,
depdel15 integer default NULL,
departuredelaygroups integer default NULL,
deptimeblk varchar(9) default NULL,
taxiout integer default NULL,
wheelsoff varchar(10) default NULL,
wheelson varchar(10) default NULL,
taxiin integer default NULL,
crsarrtime integer default NULL,
arrtime integer default NULL,
arrdelay integer default NULL,
arrdelayminutes integer default NULL,
arrdel15 integer default NULL,
arrivaldelaygroups integer default NULL,
arrtimeblk varchar(9) default NULL,
cancelled i1 default NULL,
cancellationcode char(1) default NULL,
diverted i1 default NULL,
crselapsedtime integer default NULL,
actualelapsedtime integer default NULL,
airtime integer default NULL,
flights integer default NULL,
distance integer default NULL,
distancegroup i1 default NULL,
carrierdelay integer default NULL,
weatherdelay integer default NULL,
nasdelay integer default NULL,
securitydelay integer default NULL,
lateaircraftdelay integer default NULL,
firstdeptime varchar(10) default NULL,
totaladdgtime varchar(10) default NULL,
longestaddgtime varchar(10) default NULL,
divairportlandings varchar(10) default NULL,
divreacheddest varchar(10) default NULL,
divactualelapsedtime varchar(10) default NULL,
divarrdelay varchar(10) default NULL,
divdistance varchar(10) default NULL,
div1airport varchar(10) default NULL,
div1airportid integer default NULL,
div1airportseqid integer default NULL,
div1wheelson varchar(10) default NULL,
div1totalgtime varchar(10) default NULL,
div1longestgtime varchar(10) default NULL,
div1wheelsoff varchar(10) default NULL,
div1tailnum varchar(10) default NULL,
div2airport varchar(10) default NULL,
div2airportid integer default NULL,
div2airportseqid integer default NULL,
div2wheelson varchar(10) default NULL,
div2totalgtime varchar(10) default NULL,
div2longestgtime varchar(10) default NULL,
div2wheelsoff varchar(10) default NULL,
div2tailnum varchar(10) default NULL,
div3airport varchar(10) default NULL,
div3airportid integer default NULL,
div3airportseqid integer default NULL,
div3wheelson varchar(10) default NULL,
div3totalgtime varchar(10) default NULL,
div3longestgtime varchar(10) default NULL,
div3wheelsoff varchar(10) default NULL,
div3tailnum varchar(10) default NULL,
div4airport varchar(10) default NULL,
div4airportid integer default NULL,
div4airportseqid integer default NULL,
div4wheelson varchar(10) default NULL,
div4totalgtime varchar(10) default NULL,
div4longestgtime varchar(10) default NULL,
div4wheelsoff varchar(10) default NULL,
div4tailnum varchar(10) default NULL,
div5airport varchar(10) default NULL,
div5airportid integer default NULL,
div5airportseqid integer default NULL,
div5wheelson varchar(10) default NULL,
div5totalgtime varchar(10) default NULL,
div5longestgtime varchar(10) default NULL,
div5wheelsoff varchar(10) default NULL,
div5tailnum varchar(10) default NULL,
lastCol varchar(10) default NULL
)
g
create table carriers(ccode char(2) collate ucs_basic, carrier char(25) collate ucs_basic )
g
INSERT INTO carriers VALUES ('AS','Alaska Airlines (AS)'), ('AA','American Airlines (AA)'), ('DL','Delta Air Lines (DL)'), ('EV','ExpressJet Airlines (EV)'), ('F9','Frontier Airlines (F9)'), ('HA','Hawaiian Airlines (HA)'), ('B6','JetBlue Airways (B6)'), ('OO','SkyWest Airlines (OO)'), ('WN','Southwest Airlines (WN)'), ('NK','Spirit Airlines (NK)'), ('UA','United Airlines (UA)'), ('VX','Virgin America (VX)')
g
Now that you’ve setup the schema, exit out of the sql shell. Enter:
q
You are back in the Linux shell.
Step 7: Get and Set AWS Keys
To access the demo data on S3, you must provide your AWS access keys associated with the IAM user. These are 2 values: access key ID and secret access key.
If you are not familiar with IAM access keys, please read https://docs.aws.amazon.com/IAM/latest/UserGuide/id_credentials_access-keys.html#Using_CreateAccessKey to understand how to retrieve or create access keys.
After you have retrieved your access keys, please set them in your environment as follows:
export AWS_ACCESS_KEY_ID=<Your Access Key ID>
export AWS_SECRET_ACCESS_KEY=<You Secret Access Key>
Now you’re ready to run the Spark loader. The demo data is supplied in 4 CSV files. Each file part is about 18 GB and contains approximately 43 million rows.
Run the following command to load Part 1:
spark-2.2.0-bin-hadoop2.7/bin/spark-submit --packages org.apache.hadoop:hadoop-aws:2.7.2 --class com.actian.spark_vector.loader.Main /home/actian/work/spark_vector_loader-assembly-2.0.jar load csv -sf "s3a://esdfiles/Vector/actian-ontime/On_Time_Performance_Part1.csv" -vh localhost -vi VW -vd vectordb -tt ontime -sc "," -qc '"'
This runs a Spark job and use the Spark Vector loader to load data from the file On_Time_On_Time_Performance_Part1 into Vector.
On my m4.4xlarge instance in the US East (N. Virginia) region, this took about 4 minutes and 23 seconds.
Once the loading completes, you will see an INFO message on the console log:
INFO VectorRelation: Loaded 43888241 records into table ontime
Repeat for the other 3 parts:
spark-2.2.0-bin-hadoop2.7/bin/spark-submit --packages org.apache.hadoop:hadoop-aws:2.7.2 --class com.actian.spark_vector.loader.Main /home/actian/work/spark_vector_loader-assembly-2.0.jar load csv -sf "s3a://esdfiles/Vector/actian-ontime/On_Time_Performance_Part2.csv" -vh localhost -vi VW -vd vectordb -tt ontime -sc "," -qc '"'
spark-2.2.0-bin-hadoop2.7/bin/spark-submit --packages org.apache.hadoop:hadoop-aws:2.7.2 --class com.actian.spark_vector.loader.Main /home/actian/work/spark_vector_loader-assembly-2.0.jar load csv -sf "s3a://esdfiles/Vector/actian-ontime/On_Time_Performance_Part3.csv" -vh localhost -vi VW -vd vectordb -tt ontime -sc "," -qc '"'
spark-2.2.0-bin-hadoop2.7/bin/spark-submit --packages org.apache.hadoop:hadoop-aws:2.7.2 --class com.actian.spark_vector.loader.Main /home/actian/work/spark_vector_loader-assembly-2.0.jar load csv -sf "s3a://esdfiles/Vector/actian-ontime/On_Time_Performance_Part4.csv" -vh localhost -vi VW -vd vectordb -tt ontime -sc "," -qc '"'
Step 9: Run Queries on the Loaded Data
Let’s quickly verify that the data was loaded into the database.
Connect with the terminal monitor:
sql vectordb
In the sql shell, enter:
rt
All query times henceforth will be recorded and displayed.
Get a count of the rows in the table:
SELECT COUNT(*) from ontimeg
This will display about 175 million rows.
Run another query that lists by year the percentage of flights delayed more than 10 minutes:
SELECT t.year, c1/c2 FROM (select year,count(*)*1000 as c1 from ontime WHERE DepDelay>10 GROUP BY Year) t JOIN (select year,count(*) as c2 from ontime GROUP BY year) t2 ON (t.year=t2.year);g
You would see the query results as well as the time that Vector took to execute the query. You can also now run more sample analytic queries listed at https://docs.actian.com/vector/AWS/index.html#page/GetStart%2FMoreSampleQueries.htm%23 and observe the query times.
To Delete vectordb
To delete the demo database, enter the following command in the Linux shell:
destroydb vectordb
Summary
That concludes the demo on how you can quickly load S3 data into Vector using the Spark Vector loader.
On a side note, if you would like to alter the data before loading it into Vector, you can do the necessary transformations in Spark and then load data into Vector using our Spark Vector Connector.
If you have any further comments or questions visit the Actian Vector forum and ask away! We’ll try to get your post answered as soon as we can. The Knowledge Base is also a great source of information should you need it.