When BIG Data Doesn’t Have to Be





Summary
- Managing massive centralized computer clusters is complex, fragile, and prone to sharding skew and intensive workload balancing issues.
- A “Vector Farm” architecture uses multiple independent, high-performance database servers to deliver analytics without clustering complexity.
- Homogeneous farms allow multinational corporations to easily segment regional datasets to strictly adhere to localization compliance mandates.
- For SaaS platforms, combining isolated databases with multi-tenant database schemas groups small clients while dedicating resources to heavy users.
Actian Vector was renamed to Actian Analytics Engine in 2026.
Using a Vector FARM to Make Big Data Analytics Fast and Easy
I’ve been working in the IT industry for a long time. What goes around comes around. My favorite example is how centralized mainframe timesharing gave birth to decentralized client-server computing. Now we are going back to timesharing, but in the cloud. Technology does evolve. Sometimes new ideas seem like good ideas, but they end up being not-so-great, so we go back and reinvent older, but proven ideas.
Take Data Warehousing and Big Data, for example. We’re all amassing all this big data; it doesn’t easily fit all together on one small computer, so we go create a giant computer or, even better, a cluster of small computers that looks like a giant computer to handle the workload.
Managing Computer Clusters IS HARD
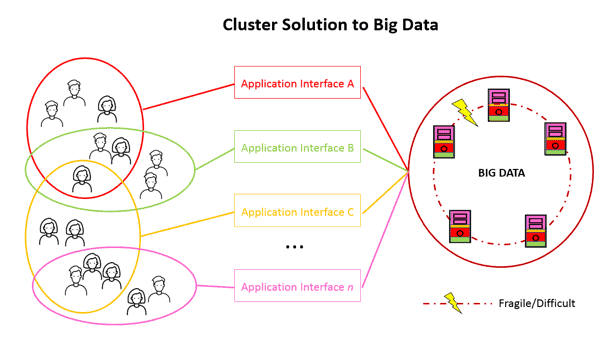
On paper, as in this diagram, the cluster looks simple, but in reality, they are complex to set up, hard to keep balanced and running, they introduce a bunch of new problems like sharding skew and workload management, and they actually not that easy to expand… it’s nuts! The whole ecosystem is fragile and difficult.
Unless you’re one of those few corporations that truly have big singular dataset, the ideal of the giant centralized Data Warehouse of everything, from a practical perspective, is just not that productive or necessary. Why make things harder than they need to be?
What makes more sense is a performant, easy-to-understand, easy-to-setup, easy-to manage, easy-to-change environment. For analytics, I propose you take a step back and consider individual servers, but performant and easy to manage ones.
Consider a Vector Farm to easily harvest business objectives.
Vector Farms can be very flexible. You could have a Homogenous Vector Farm in which you have collection of individual servers that look alike, each with the same Actian Analytics Engine setup on each one. Management is easy because: each server is independent so there’s no cluster complexity, each one has the same database setup, and it’s easy to add/delete servers without affecting the others. Plus, Actian Vector itself requires little to no tuning so there is little individualized setup. You can even introduce slight variations such that you have a Heterogenous Vector Farm. In which case, even though the application setup might be a little different. Actian Analytics Engine provides extreme performance and easy-admin, without the complexity of a cluster. Here are examples:
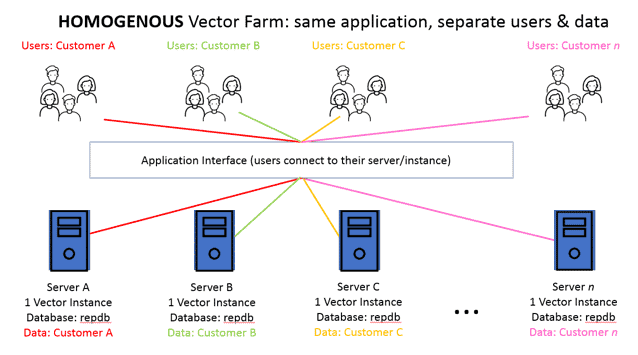
Independent Groups of Like-Users Using the Same Application but Needing Separate Data
This scenario is the simplest. The Vector Farm is especially useful because it easily allows you to separate user data. An example of this could be a multi-national corporation that legally needs to keep European data on-premises and separate from Canadian and United States data etc. Notice here that everything is the same about the database server setup including the database name. Management of all these servers is the same. Actian Analytics Engine provides tremendous query performance to all users.
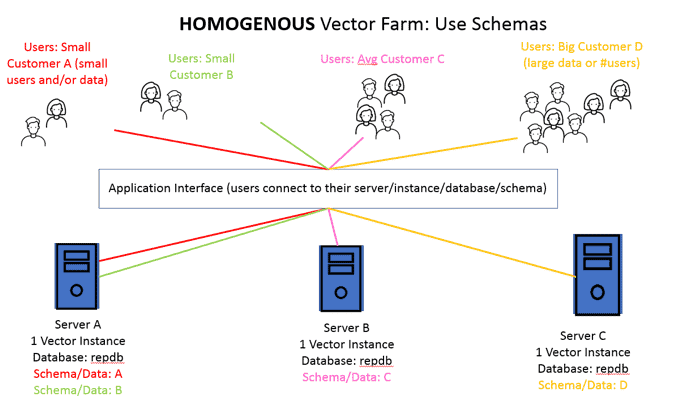
Independent Groups of Different-Size Users Using the Same Application but Needing Separate Data
In reality, most groups of users are not the same. Take a software-as-a-service (SAAS) provider for example. A SAAS provider might provide a cloud service to a variety of customers, big and small, over the internet. In this case, the provider certainly would not want to dedicate an entire server (virtual or on-premises) to very small customers. In this case, using schemas (a method of creating separate ownership in a singular database), the provider can group small customer usage on one Vector instance, while servicing other with their own instances. In cases, where these is a particularly large customer, they could make that server bigger, but still maintaining the same structure. Management of all these servers is still same using schemas. Actian Analytics Engine provides tremendous query performance to all users.
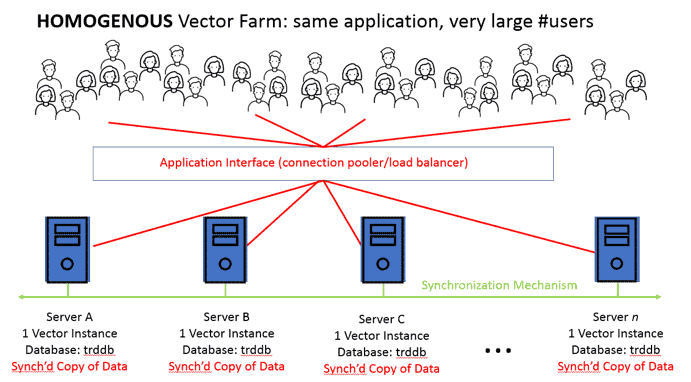
A VERY Large Group of Demanding Users
Another scenario is when the analytics user-base is big and these users need reliable, fast performance. An example of this is a financial services firm that offers a trading application. Traders need very-fast, complex analysis on real time data. A complex cluster, with its overhead of many moving parts, physically cannot provide this. In this scenario, a Homogenous Vector Farm can be used as a pool to service all users. A real-time service bus or message queue can be used to synchronize the multiple-servers in real time. Users are balanced to any one of the available servers in the Farm. Again, management is easy because all the servers are exactly the same. Actian Analytics Engine (THE WORLD’S FASTEST ANALYTIC DATABASE) provides tremendous response times.
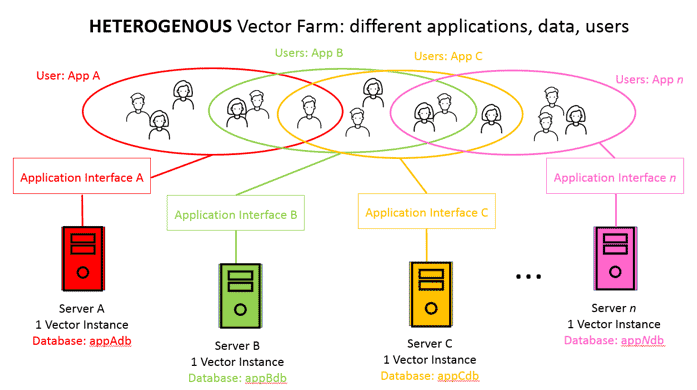
Independent Users and Applications
The final scenario is a truly Heterogenous Vector Farm. In this scenario, users are not necessarily segmented, there are different analytics applications with different database structures. The applications are different so there is no operational need to keep data in a central location on a complex cluster. Because Actian Analytics Engine is so performant, easy to set up and manage, a Vector Farm is an effective way to facilitate support these users and applications.
Conclusion
Why torture yourself with a complex cluster if you don’t have to. Because of performance, ease of administration, and little to no custom tuning, it is easy to take advantage of individual servers in an Actian Vector Farm. Because you don’t have to go through the complex analysis of building and maintaining a cluster and because Vector requires little tuning, you can spin up components of your Vector Farm quickly and start “harvesting” business value right away!
More About Actian Vector
Want to learn more about Actian Analytics Engine?
You can also download and try Actian Vector yourself (or you can try Vector Community Edition on AWS without having to get an evaluation license). You won’t be disappointed, and if you need help figuring things out, just ask the Community.

Stay connected
Data insights delivered to you.
(i.e. sales@..., support@...)