Ajoutez la recherche vectorielle à votre application FastAPI grâce à VectorAI DB




Résumé
- Implémentez la recherche sémantique dans FastAPI à l'aide d'une configuration locale simple, plutôt que d'une infrastructure cloud plus lourde.
- Créer un point de terminaison d'ingestion qui intègre les descriptions de produits et les stocke avec métadonnées.
- Créez un point de terminaison de recherche qui renvoie des produits en fonction de leur sens, et pas seulement de mots-clés exacts.
- Ajoutez des filtres structurés, tels que la catégorie, directement dans la recherche vectorielle.
- Les prochaines étapes concernent support asynchrone, la recherche hybride et des filtres plus avancés pour une utilisation en production.
L'intégration de la recherche sémantique dans une application FastAPI se heurte souvent à des difficultés initiales. La plupart des guides orientent les développeurs vers des services cloud qui nécessitent la création d'un compte et l'obtention de clés API, ou vers des environnements locaux qui dépendent de plusieurs services avant même que l'on puisse écrire la moindre ligne de code utile.
Ces coûts supplémentaires surviennent avant même que la fonctionnalité ne soit développée, ce qui détourne les efforts du développement de l'API pour les consacrer à la mise en place de l'infrastructure.
Ce tutoriel adopte une approche plus simple. Actian VectorAI DB s'exécute sous la forme d'un seul conteneur Docker et se connecte via un client Python JavaScript. Pour les premières phases de développement et de prototypage, vous n'avez pas besoin de compte cloud, de clés API ni de multiples services. Installez la base de données et le client pour commencer à créer votre API. Par rapport aux configurations qui s'appuient sur des services gérés ou des piles multi-conteneurs, cela réduit le temps de mise en place, les coûts et la complexité du système.
Dans ce tutoriel, vous allez créer une petite API de recherche de produits pour illustrer ce principe. L'objectif est de permettre aux utilisateurs d'effectuer des recherches par sens plutôt que par mots-clés exacts. Par exemple, une requête « quelque chose de chaud à porter en hiver » devrait renvoyer des vestes ou des pulls, même si ces mots exacts n'apparaissent pas dans la description du produit.
À la fin de ce tutoriel, vous disposerez d'une application FastAPI fonctionnelle avec une fonctionnalité de recherche sémantique, fonctionnant en local, grâce à une configuration que vous pourrez exécuter, tester et étendre sans infrastructure supplémentaire.
Configuration
Dans cette section, vous allez lancer VectorAI DB et configurer votre projet FastAPI à l'aide d'uv. À la fin, vous disposerez d'une base de données vectorielle opérationnelle et d'un Python prêt à s'y connecter.
Conditions préalables
Pour suivre ce guide, installez les outils suivants sur votre réseau local :
- Docker et Docker Compose
- Python .10 ou version ultérieure
- PIP ou UV (ce guide utilise le système UV)
Lancer la base de données Actian VectorAI
Exécutez VectorAI DB dans un seul conteneur Docker. Créez un fichier docker-compose.yml avec le contenu suivant :
services:
vectorai:
image: williamimoh/actian-vectorai-db:latest
platform: linux/amd64
container_name: vectorai_db
ports:
- "50051:50051"
volumes:
# vector data persists across restarts
- ./data:/app/data
environment:
- VECTORAI_LOG_LEVEL=info
restart: unless-stoppedDémarrer le service :
docker compose up -d
VectorAI DB est désormais en cours d'exécution en local sur le port 50051.
Créez votre projet FastAPI avec Uv
Configurez maintenant votre Python . Si uv n'est pas encore installé, installez-le d'abord.
Pour créer un nouveau projet dans votre répertoire actuel, exécutez la commande suivante :
uv init . uv venv
Installez FastAPI, le Python de VectorAI DB et la dépendance du modèle d'encodage :
uv add fastapi uvicorn sentence-transformers
Inscrivez-vous à l'édition communautaire d'Actian VectorAI DB.Une fois inscrit, vous recevrez les instructions pour configurer le client, soit en téléchargeant le fichier binaire, soit en l'exécutant via un conteneur Docker, selon votre préférence.
Installez Python de VectorAI DB en suivant les étapes suivantes :
Ajouter Actian-Vectorai-Client
Vérifier la connexion
Créez un script simple nommé test_connection.py pour vérifier que votre application se connecte à la base de données VectorAI :
from actian_vectorai import VectorAIClient
VECTORAI_HOST = "localhost:50051"
with VectorAIClient(VECTORAI_HOST) as client:
# Health check
info = client.health_check()
print(f"Connected to {info['title']} v{info['version']}")Testez cette connexion en :
uv run test_connection.py
Si tout fonctionne correctement, un message indiquant que la connexion a été établie devrait s'afficher.

Vérifiez la connexion
Vous êtes désormais prêt à définir votre modèle de données et à commencer à développer votre API.
Configurer le point de terminaison d'ingestion
Vous allez créer un point de terminaison POST /ingest qui accepte une liste de produits, intègre chaque description et stocke les résultats dans la base de données VectorAI. Cela vous permet d'envoyer une liste de produits au format JSON à votre API et de les rendre prêts pour la recherche.
Commencez par définir le modèle de données et la configuration de la collection. Créez un fichier main.py avec le contenu suivant :
from fastapi import FastAPI
from pydantic import BaseModel
from sentence_transformers import SentenceTransformer
from actian_vectorai import VectorAIClient, VectorParams, Distance, PointStruct, CollectionExistsError
from typing import List
from contextlib import asynccontextmanager
COLLECTION = "products_collection"
DIMENSION = 384 # all-MiniLM-L6-v2 produces 384-dimensional vectors
model = SentenceTransformer("all-MiniLM-L6-v2")
class Product(BaseModel):
id: int
name: str
description: str
category: str
price: float
@asynccontextmanager
async def lifespan(app: FastAPI):
# Startup
with VectorAIClient("localhost:50051") as client:
try:
client.collections.create(
COLLECTION,
vectors_config=VectorParams(size=DIMENSION, distance=Distance.Cosine)
)
except CollectionExistsError:
pass
yield
app = FastAPI(lifespan=lifespan)Utiliser all-MiniLM-L6-v2 . Il s'agit d'un modèle de 22,7 millions de paramètres qui s'exécute sur processeur produit des vecteurs de 384 dimensions. Il offre une vitesse suffisante pour le développement local et une grande précision pour la recherche de produits. La collection utilise la distance cosinus, qui mesure l'angle entre les vecteurs plutôt que leur amplitude. Cela fonctionne bien pour les plongements de texte, car cette méthode se concentre sur le sens plutôt que sur la longueur de la description.
Maintenant, compilez le point de terminaison .
@app.post("/ingest")
def ingest(products: List[Product]):
descriptions = [p.description for p in products]
embeddings = model.encode(descriptions, convert_to_numpy=True)
points = [
PointStruct(
id=p.id,
vector=embeddings[i].tolist(),
payload={
"name": p.name,
"category": p.category,
"price": p.price,
}
)
for i, p in enumerate(products)
]
with VectorAIClient("localhost:50051") as client:
client.points.upsert(COLLECTION, points)
return {"inserted": len(points)}Cela permet de faire ce qui suit :
- Extrait toutes les descriptions de produits dans une liste afin que vous puissiez Embarquer en une seule fois.
- Génère des représentations à l'aide du modèle all-MiniLM-L6-v2 .
- Convertit chaque produit en un PointStruct avec un identifiant, un vecteur et une charge utile.
- Enregistre métadonnées utiles métadonnées le nom, la catégorie et le prix en même temps que le vecteur.
- Insère tous les points dans la base de données VectorAI en une seule requête.
Créer le point de terminaison de recherche
Pour obtenir les cinq produits les plus similaires, l'implémentation comprend une point de terminaison GET /search qui accepte une requête textuelle requête un filtre de catégorie facultatif. Le point de terminaison intègre la requête, effectue une recherche vectorielle dans la base de données VectorAI et renvoie les résultats les plus pertinents.
Cette étape achève le processus de recherche, passant d'une saisie de texte brut à des résultats classés par ordre de pertinence sémantique en une seule requête.
Pourquoi ce filtre est-il important ?
C'est grâce au filtre par catégorie que VectorAI DB améliore l'expérience des développeurs. Avec FAISS, on effectue généralement d'abord une recherche vectorielle complète, puis on filtre les résultats en Python. Cela signifie que l'on gaspille des ressources de calcul pour des résultats que l'on va écarter.
La base de données VectorAI applique des filtres au sein même de l'opération de recherche. Elle ne prend en compte que les vecteurs correspondants lors de la récupération. Cela permet de garantir l'efficacité de la recherche et de simplifier son interprétation.
Implémenter le point de terminaison
Ajoutez les importations et le point de terminaison suivants à votre fichier main.py :
from actian_vectorai import FilterBuilder, Field
@app.get("/search")
def search(query: str, category: str = None, top_k: int = 5):
query_vector = model.encode([query], convert_to_numpy=True)[0].tolist()
search_filter = None
if category:
search_filter = FilterBuilder().must(Field("category").eq(category)).build()
with VectorAIClient("localhost:50051") as client:
results = client.points.search(
COLLECTION,
vector=query_vector,
limit=top_k,
filter=search_filter
)
return [
{
"id": r.id,
"score": round(r.score, 4),
"name": r.payload["name"],
"category": r.payload["category"],
"price": r.payload["price"],
}
for r in results
]Fonctionnement
- Convertir larequête utilisateur requête un vecteur d'encodage.
- Ne créer un filtre que si une catégorie est indiquée.
- Transmettez à la fois le vecteur et le filtre à VectorAI DB en une seule requête.
- Afficher les meilleurs résultats avec leurs scores de similarité et métadonnées.
Les objets filtres sont Python typés. Cela permet à FastAPI de détecter les erreurs à un stade précoce et garantit la cohérence requête de vos requête .
Si aucune catégorie n'est indiquée, search_filter reste None. La recherche s'effectue alors sur l'ensemble des produits.
Lance-le
Lancez VectorAI DB, puis lancez FastAPI. Deux commandes.
docker-compose up -d
uv run uvicorn main:app –reload
Dans une autre fenêtre de terminal, importez trois échantillons de produits :
curl -X POST http://localhost:8000/ingest \
-H "Content-Type: application/json" \
-d '[
{"id": 1, "name": "Cashmere Scarf", "description": "Soft cashmere scarf, ideal for cold weather", "category": "clothing", "price": 49.00},
{"id": 2, "name": "Bluetooth Speaker", "description": "Portable waterproof speaker with 12-hour battery", "category": "electronics", "price": 59.99},
{"id": 3, "name": "Trail Mix", "description": "Mixed nuts and dried fruit, high-energy snack", "category": "food", "price": 8.50}
]'Vous recevez une réponse :
{“inserted”: 3}
Effectuez une recherche sémantique en utilisant un filtre par catégorie :
curl "http://localhost:8000/search?query=something+warm+for+winter&category=clothing"Vous devriez obtenir la réponse suivante :

Recherche requête catégorie
Exécutez la même requête filtre pour afficher toutes les catégories classées par pertinence :
curl -s "http://localhost:8000/search?query=something+warm+for+winter" | jqC'est toujours l'écharpe qui obtient le meilleur score. Le haut-parleur et le mélange de fruits secs reviennent avec des scores inférieurs, car leurs descriptions présentent moins de recoupements sémantiques avec la requête.
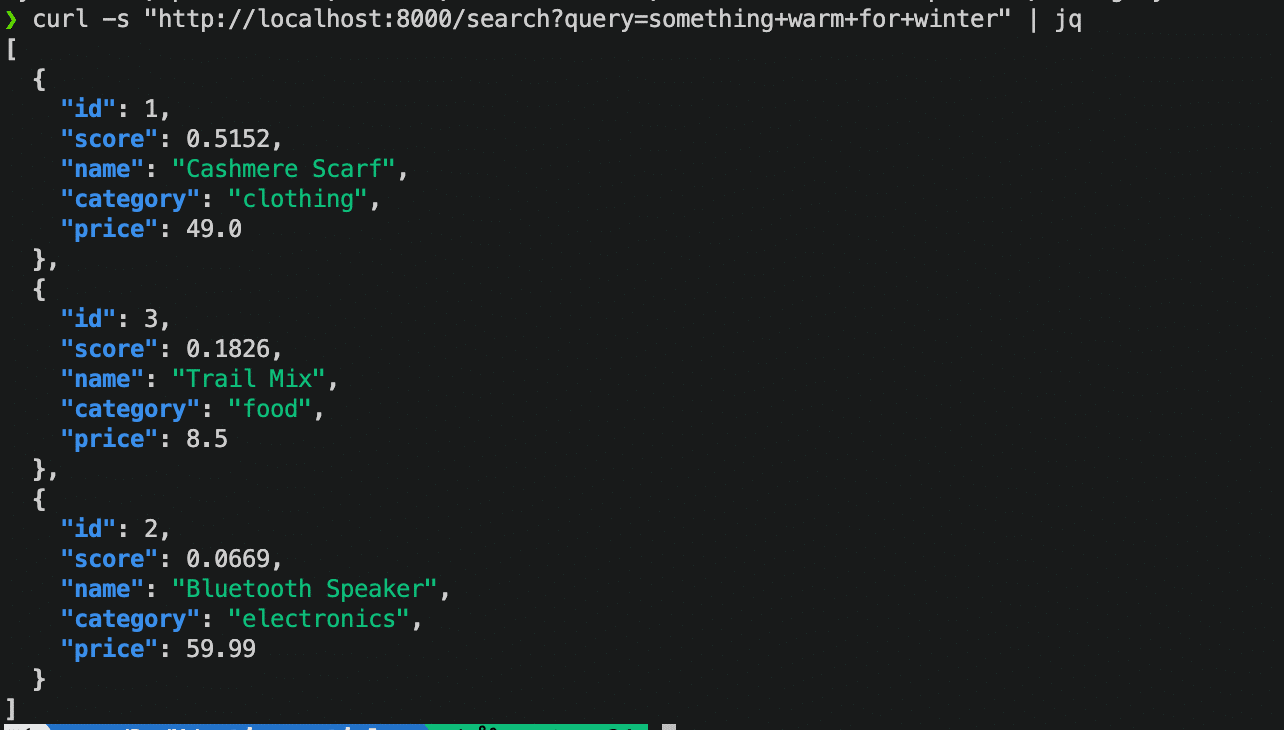
Recherche requête catégorie
Jusqu'à présent, vous avez mis en place l'architecture telle qu'elle est illustrée sur l'image.
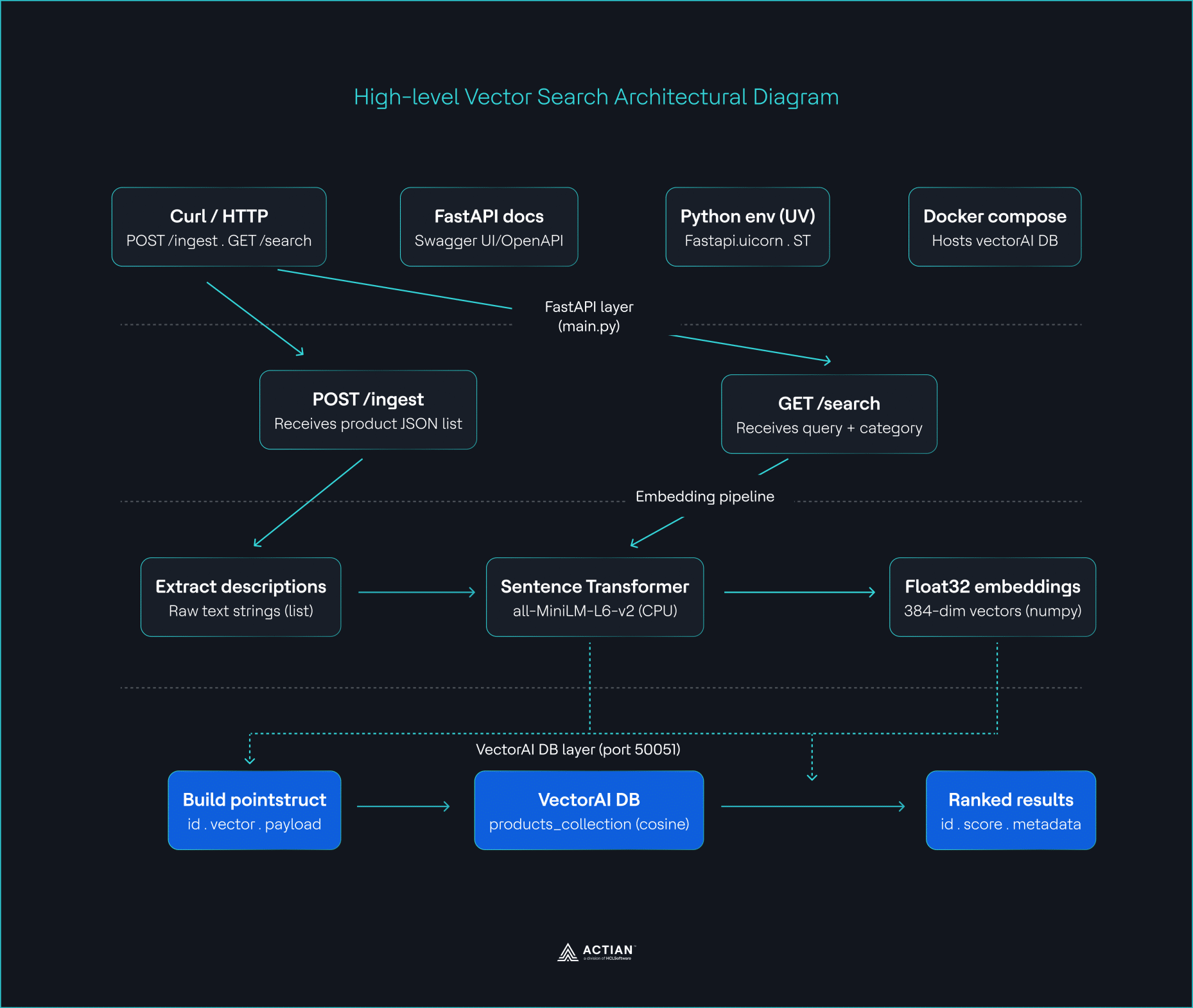
Schéma architectural de haut niveau
Voyons ce qu'on va faire ensuite.
Quel sera le prochain projet ?
Cette configuration fonctionne bien pour le développement local et les charges de travail modestes. La prochaine étape consiste à l'adapter pour un débit plus élevé et des modèles de recherche plus avancés.
Utilisez le client asynchrone pour les charges de travail en production
La mise en œuvre actuelle utilise un client synchrone, qui fonctionne bien pour le développement local et les petits tests, mais qui limite le débit à mesure que simultanéité . Chaque appel à la base de données bloque le thread de requête jusqu'à son achèvement, ce qui réduit les performances globales en cas de charge importante.
VectorAI DB fournit un objet `AsyncVectorAIClient` qui élimine ce goulot d'étranglement. Il s'intègre au modèle asynchrone de FastAPI, permettant ainsi aux points de terminaison de traiter d'autres requêtes tout en attendant la fin des opérations sur la base de données. Cette approche est particulièrement importante pour les recherches simultanées, l'ingestion par lots et les mises à jour de données en arrière-plan.
Dans un environnement de production, cette modification s'associe également très bien à l'exécution de plusieurs workers uvicorn. Ensemble, ils permettent à votre service d'évoluer horizontalement sans modifier votre logique métier.
Ajouter la recherche hybride
La similarité vectorielle fonctionne bien à elle seule lorsque la requête vague ou descriptive, car elle se concentre sur le sens plutôt que sur les mots exacts. Cependant, elle peut rencontrer des difficultés lorsque la précision est de mise, notamment avec les noms de produits, les numéros de modèle ou les termes liés à des marques.
VectorAI DB combine la similarité vectorielle et la correspondance par mots-clés en une seule requête. La composante vectorielle rend compte de la signification sémantique, tandis que la composante par mots-clés garantit que les termes exacts ne sont pas perdus lors de la traduction. Ces deux signaux contribuent au classement final.
La recherche hybride s'avère utile dans des situations concrètes où les utilisateurs combinent intention et précision dans une même requête. Par exemple, une recherche telle que « chaussures de course Nike taille 42 » comporte à la fois une intention sémantique (chaussures de course à usage sportif) et des critères précis (marque Nike et taille 42). La recherche hybride vous garantit de ne perdre aucun de ces deux éléments, ce qui améliore la qualité des résultats sans que vous ayez à ajouter de logique supplémentaire de votre côté.
Étendre la logique de filtrage et de classement
Pour l'instant, votre recherche ne permet de filtrer que par catégorie, ce qui convient pour une simple démonstration de produit. Dans les applications réelles, le filtrage devient plus dynamique, car les utilisateurs s'attendent à pouvoir affiner les résultats en fonction de plusieurs critères.
Vous pouvez étendre vos filtres pour support tels que les fourchettes de prix, la disponibilité des stocks, les noms de marques ou tout autre attribut structuré de votre jeu de données. Le système de filtres typés de VectorAI DB facilite cette tâche, car vous créez vos filtres sous forme Python structurés plutôt que requête ad hoc. Cela réduit les erreurs et garantit la cohérence de votre logique de recherche avec le reste de votre application FastAPI.
À mesure que le jeu de données , ces filtres deviennent indispensables pour contrôler l'ensemble des résultats avant le classement. La recherche vectorielle continue de gérer la pertinence, tandis que le filtrage réduit le jeu de données enregistrements qui répondent utilisateur .
Pour conclure
Dans ce tutoriel, vous avez mis au point un système complet de recherche sémantique à l'aide de FastAPI et de VectorAI DB. Vous êtes passé d'un projet vierge à une API opérationnelle capable de comprendre des requêtes en langage naturel et de renvoyer des résultats pertinents en fonction du sens, et non plus uniquement des mots-clés.
Vous avez créé un pipeline d'ingestion qui convertit les descriptions de produits en vecteurs d'encodage à l'aide de all-MiniLM-L6-v2 et les stocke dans une collection vectorielle avec métadonnées. Vous avez ensuite créé un point de terminaison de recherche qui encode utilisateur et récupère les produits les plus pertinents à l'aide de la similarité vectorielle, avec un filtrage optionnel pour les contraintes structurées telles que la catégorie.
L'ajout d'une fonctionnalité de recherche vectorielle à une application FastAPI ne nécessite ni infrastructure complexe ni service cloud externe. VectorAI DB fonctionne sous la forme d'un seul conteneur et s'intègre directement via un Python , ce qui permet de passer rapidement de la configuration à la mise en œuvre.
À partir de là, vous pouvez faire évoluer le système en y ajoutant des clients asynchrones, la recherche hybride et des logiques de filtrage plus avancées, à mesure que votre application se développe pour prêt pour la production .
Consultez la documentation de Vecteur IA et dépôt GitHub pour obtenir les dernières mises à jour et les détails de mise en œuvre.
Inscrivez-vous à Actian VectorAI DB Community Edition et commencez à développer dès aujourd'hui.

Restez connecté
Des informations tirées des données, à votre service.
(par exemple : sales@..., support)