L'IA dans le secteur manufacturier peut-elle fonctionner sans le cloud ?





Résumé
- Ce tutoriel explique comment mettre en place un pipeline RAG entièrement local pour les environnements de production où l'accès au cloud est limité par l'architecture réseau, les exigences en matière de latence, les coûts et les contraintes réglementaires.
- Le pipeline comporte trois étapes : l'importation des fiches de maintenance au format PDF dans une base de données vectorielle, la recherche requête à l'aide de métadonnées , et un modèle de langage grand format (LLM) local qui génère des réponses pertinentes à partir du contexte récupéré.
- Il fonctionne entièrement sur le matériel présent dans l'usine, en utilisant VectorAI DB, Sentence Transformers pour les représentations vectorielles et Ollama pour l'inférence locale du modèle linguistique.
- Il comprend également des fonctionnalités pratiques telles que le filtrage par ligne d'équipement et par date, la journalisation des audits pour assurer la traçabilité, ainsi que la possibilité de fonctionner en mode local en cas de coupure de courant, sans dépendre d'une connexion Internet.
- En résumé, la recherche pilotée par l’IA peut fonctionner en toute sécurité au sein des environnements de technologie opérationnelle, fournissant ainsi aux techniciens des réponses rapides et fondées sur les données historiques, sans qu’il soit nécessaire de transmettre ces données à l’extérieur de l’usine.
Empêcher le trafic externe d'accéder aux réseaux opérationnels est une bonne pratique que la plupart des sites de production intègrent dès le départ dans leur architecture.
Les réseaux de production s'appuient sur le modèle Purdue, un système à cinq niveaux qui a façonné la conception des réseaux industriels depuis des décennies. Au niveau le plus bas se trouvent les machines physiques : capteurs, moteurs et actionneurs au niveau 0 ; contrôleurs en temps réel et systèmes SCADA au niveau 1 ; et serveurs de supervision et systèmes IHM au niveau 2. Le niveau 3 gère les opérations. Les niveaux 4 et 5 sont connectés au réseau d'entreprise et à Internet.
La norme IEC 62443 impose des limites strictes entre ces niveaux. Le trafic provenant du niveau 2 n'atteint pas Internet. Pour les sous-traitants du secteur de la défense, l'ITAR aggrave le problème. Les données techniques doivent rester sur le sol américain et ne doivent être accessibles qu'aux ressortissants américains. Les bases de données vectorielles hébergées dans le cloud, telles que Pinecone, Weaviate Cloud et Qdrant Cloud, ne satisfont à aucune de ces deux exigences. Le niveau 2 n'a aucun moyen d'envoyer cette requête, et d'autres secteurs ont appris cette leçon à leurs dépens.

La latence aggrave le problème. Les allers-retours vers le cloud prennent en moyenne entre 50 et 500 millisecondes. Les boucles de contrôle au niveau des automates programmables (PLC) exigent des réponses en moins de 10 millisecondes. Les équipes qui ont besoin de l'IA pendant les coupures de courant ont recours à déploiement en périphérie conçus pour les environnements hors réseau.
Le coût vient compliquer encore davantage la situation. Le tarif standard d'AWS pour le trafic sortant commence à 0,09 $ par Go. À une échelle de production significative, les données issues des capteurs et de la vision s'accumulent rapidement, et la facture arrive plus vite que ne le prévoient la plupart des équipes.
L'architecture, la latence et les coûts convergent tous vers la même conclusion : l'IA en atelier doit fonctionner là où se trouvent les données.
Ce tutoriel vous explique comment mettre en place un pipeline RAG local fonctionnant entièrement sur le matériel présent dans l'usine, grâce auquel un technicien peut poser une question sur n'importe quel équipement et obtenir une réponse étayée par des décennies de registres de maintenance, sans avoir besoin d'une connexion Internet.
Ce que vous construisez
Vous allez mettre en place un pipeline RAG à trois niveaux fonctionnant entièrement au sein du réseau de votre usine. La couche d'ingestion traite les documents de maintenance au format PDF et les stocke dans la base de données Actian VectorAI. La requête traite la question d'un technicien et renvoie une réponse documentée suffisamment rapidement pour permettre une utilisation interactive sur le matériel présent dans l'usine.
- Ingestion : Lit les documents de maintenance au format PDF, les divise en segments de 256 tokens avec un chevauchement de 25 tokens, génère des représentations vectorielles à l'aide de transformateurs de phrases sur un processeur, puis stocke le tout dans la base de données VectorAI avec métadonnées la ligne d'équipement, la date du document et le fichier source.
- requête: elle recueille la question d'un technicien, l'intègre au même modèle, effectue une recherche hybride dans la base de données VectorAI en filtrant par gamme d'équipements et par plage de dates, puis envoie les meilleurs résultats à un LLM local fonctionnant avec Ollama, qui génère une réponse claire en anglais courant.
- Audit : enregistre chaque requête d'ingestion et requête sous forme d'entrée JSON structurée dans le fichier ./data/audit.log, avec horodatage en UTC, et stocke ces données à l'intérieur de votre périmètre de sécurité afin de répondre aux exigences de traçabilité de la norme CEI 62443.
VectorAI DB se trouve au cœur des trois couches. Il stocke les représentations générées par la couche d'ingestion et fournit les résultats de recherche générés par la requête . Son exploitation sur site que dans le cloud, permet de maintenir l'ensemble du pipeline à l'intérieur de votre périmètre de sécurité.
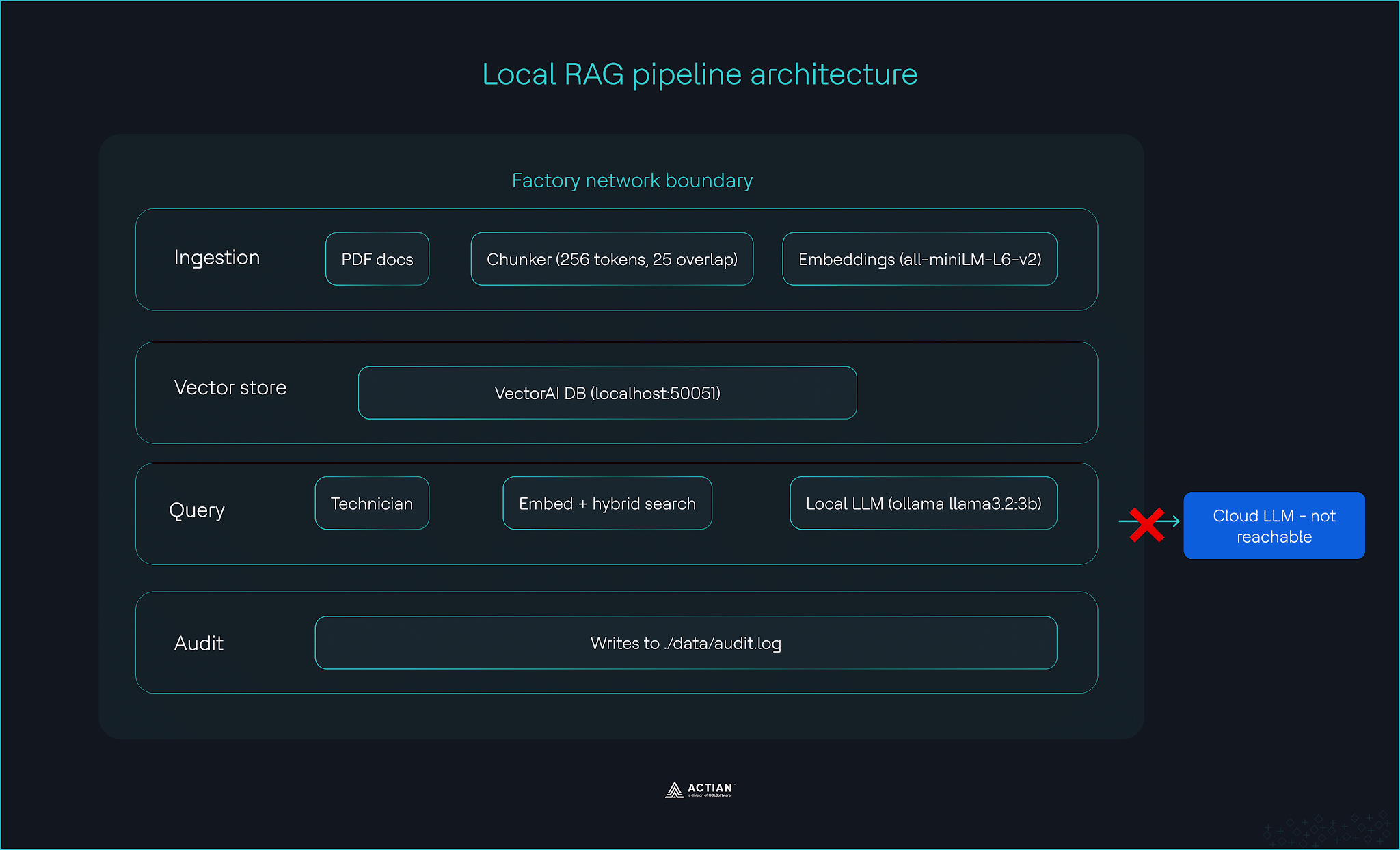
Le pipeline fonctionne sur du matériel standard de serveurs périphériques, équipé d'Ubuntu 22.04 LTS, de 16 Go de RAM et d'un processeur à 4 cœurs.
Mise en place d'un pipeline RAG local avec VectorAI DB
Configurez VectorAI DB, créez le pipeline d'ingestion, exécutez votre première requête, ajoutez des filtres hybrides et connectez un LLM local.
Conditions préalables
Inscrivez-vous à l'édition communautaire de VectorAI DB avant de commencer, puis assurez-vous que les éléments suivants sont installés :
- Docker et Docker Compose
- Python .10 ou version ultérieure
- Gestionnaire de paquets UV. Installez-le avec
curl -LsSf https://astral.sh/uv/install.sh | sh - Ollama. Installer à partir de Ollama.com et faire glisser le modèle avec
ollama pull llama3.2:3b
Votre ordinateur doit disposer d'au moins 8 Go de RAM (16 Go ou plus recommandés) et de 10 Go d'espace disque (100 Go ou plus recommandés) pour exécuter VectorAI DB. Si vous utilisez Windows, la commande d'installation « uv » nécessite « sh », qui n'est pas disponible dans PowerShell. Exécutez toutes les commandes dans WSL2 (Windows Subsystem for Linux). Pour configurer WSL2, exécutez « wsl –install » dans PowerShell, puis utilisez le terminal Ubuntu pour ce tutoriel.
Structure du projet
Organisez votre dossier de projet comme suit :
factory-rag/
├── docker-compose.yml
├── data/
│ └── audit.log
├── config/
└── src/
├── healthcheck.py
├── ingest.py
├── query.py
├── llm.py
├── audit.py
└── test_e2e.pyCréez les répertoires suivants :
mkdir -p factory-rag/{data,config,src}
cd factory-ragÉtape 1 : Déployer VectorAI DB
Créez le fichier docker-compose.yml à la racine de votre projet :
services:
vectorai-db:
image: williamimoh/actian-vectorai-db:latest
platform: linux/amd64
container_name: vectorai-db
ports:
- "50051:50051"
volumes:
- ./data:/data
- ./config:/config
restart: unless-stopped
healthcheck:
test: ["CMD-SHELL", "nc -z localhost 50051 || exit 1"]
interval: 10s
timeout: 5s
retries: 5
start_period: 15sLancez le conteneur avec :
docker compose up -dInstallez le SDK à l'aide de la commande suivante :
uv add actian_vectorai-0.1.0b2-py3-none-any.whlInstallez les bibliothèques suivantes :
uv add sentence-transformers pypdfVérifiez que le serveur est en cours d'exécution. Créez un fichier nommé src/healthcheck.py :
from actian_vectorai import VectorAIClient
with VectorAIClient("localhost:50051") as client:
info = client.health_check()
print(f"✓ VectorAI DB is running")
print(f" Title: {info['title']}")
print(f" Version: {info['version']}")Exécutez le script :
uv run python src/healthcheck.pySortie du terminal :

Étape 2 : Mettre en place le pipeline d'ingestion
Placez vos documents de maintenance au format PDF dans le dossier « data/ » avant de passer à cette étape. Ajoutez-y tous les registres de maintenance des équipements, les rapports d'inspection ou les registres de pannes.
Le pipeline utilise le modèle « sentence-transformers/all-MiniLM-L6-v2 », qui nécessite moins de 200 Mo de mémoire vive par processeur. Nous divisons le texte en segments de 256 tokens avec un chevauchement de 25 tokens afin de conserver suffisamment de contexte pour garantir une bonne recherche.
Créez le fichier src/ingest.py :
from __future__ import annotations
import argparse
import uuid
from pathlib import Path
from actian_vectorai import Distance, PointStruct, VectorAIClient, VectorParams
from pypdf import PdfReader
from sentence_transformers import SentenceTransformer
from audit import log_ingestion
COLLECTION = "maintenance_records"
HOST = "localhost:50051"
MODEL_NAME = "sentence-transformers/all-MiniLM-L6-v2"
VECTOR_DIM = 384
CHUNK_TOKENS = 256
OVERLAP_TOKENS = 25
def chunk_text(text, tokenizer, chunk_size=CHUNK_TOKENS, overlap=OVERLAP_TOKENS):
token_ids = tokenizer.encode(text, add_special_tokens=False)
chunks = []
start = 0
while start < len(token_ids):
end = min(start + chunk_size, len(token_ids))
window = token_ids[start:end]
decoded = tokenizer.decode(window, skip_special_tokens=True).strip()
if decoded:
chunks.append(decoded)
if end >= len(token_ids):
break
start += chunk_size - overlap
return chunks
def ingest_pdf(pdf_path, equipment_line, doc_date, model, client):
reader = PdfReader(str(pdf_path))
full_text = "\n".join(page.extract_text() or "" for page in reader.pages)
if not full_text.strip():
print(f" [warn] No extractable text in {pdf_path.name}, skipping.")
return 0
tokenizer = model.tokenizer
chunks = chunk_text(full_text, tokenizer)
points = []
for idx, chunk in enumerate(chunks):
embedding = model.encode(chunk, show_progress_bar=False).tolist()
points.append(
PointStruct(
id=str(uuid.uuid5(uuid.NAMESPACE_DNS, f"{pdf_path.name}:{idx}")),
vector=embedding,
payload={
"equipment_line": equipment_line,
"doc_date": doc_date,
"source_file": pdf_path.name,
"text": chunk,
"chunk_index": idx,
},
)
)
if points:
client.points.upsert(COLLECTION, points)
return len(points)
def main(data_dir, equipment_line, doc_date):
data_path = Path(data_dir)
pdfs = sorted(data_path.glob("*.pdf"))
if not pdfs:
print(f"No PDF files found in '{data_dir}'. Add PDFs to ./data/ and retry.")
return
print(f"Loading embedding model '{MODEL_NAME}'...")
model = SentenceTransformer(MODEL_NAME)
with VectorAIClient(HOST) as client:
if not client.collections.exists(COLLECTION):
client.collections.create(
COLLECTION,
vectors_config=VectorParams(size=VECTOR_DIM, distance=Distance.Cosine),
)
print(f"Created collection '{COLLECTION}' ({VECTOR_DIM}-dim, Cosine)")
else:
print(f"Collection '{COLLECTION}' already exists, appending chunks.")
total = 0
for pdf_path in pdfs:
print(f"Ingesting {pdf_path.name} ...")
count = ingest_pdf(pdf_path, equipment_line, doc_date, model, client)
print(f" → {count} chunks stored")
log_ingestion(pdf_path.name, equipment_line, count)
total += count
print(f"\nDone. {total} total chunks stored in '{COLLECTION}'.")
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Ingest PDFs into VectorAI DB")
parser.add_argument("--data-dir", default="./data")
parser.add_argument("--equipment-line", required=True)
parser.add_argument("--doc-date", required=True)
args = parser.parse_args()
main(args.data_dir, args.equipment_line, args.doc_date)Exécutez l'étape d'ingestion :
uv run python src/ingest.py --equipment-line turbine-A --doc-date 2024-03-15Résultat attendu :

métadonnées enregistre la ligne d'équipement, la date du document et le fichier source pour chaque bloc. Cela vous permet de filtrer vos recherches par ligne d'équipement ou par plage de dates sans avoir à parcourir l'intégralité de la collection.
Étape 3 : Exécutez votre première requête
Votre pipeline d'ingestion a enregistré les fiches de maintenance dans la base de données VectorAI. Ce pipeline est capable de répondre à des questions. Lorsqu'un technicien pose une question en langage courant, le pipeline intègre la question, effectue une recherche dans la collection « maintenance_records » et renvoie les cinq segments les plus pertinents, accompagnés de leurs scores de similarité.
Créez le fichierrequête.py :
from __future__ import annotations
import argparse
import time
from actian_vectorai import Field, FilterBuilder, VectorAIClient
from sentence_transformers import SentenceTransformer
from audit import log_query
COLLECTION = "maintenance_records"
HOST = "localhost:50051"
MODEL_NAME = "sentence-transformers/all-MiniLM-L6-v2"
TOP_K = 5
def build_filter(equipment_line=None, doc_date=None, doc_date_to=None):
fb = FilterBuilder()
if equipment_line:
fb.must(Field("equipment_line").eq(equipment_line))
if doc_date and doc_date_to:
fb.must(Field("doc_date").range(gte=doc_date, lte=doc_date_to))
elif doc_date:
fb.must(Field("doc_date").eq(doc_date))
return fb.build() if (equipment_line or doc_date) else None
def search(question, equipment_line=None, doc_date=None, doc_date_to=None):
model = SentenceTransformer(MODEL_NAME)
embedding = model.encode(question, show_progress_bar=False).tolist()
query_filter = build_filter(equipment_line, doc_date, doc_date_to)
with VectorAIClient(HOST) as client:
hits = client.points.search(
COLLECTION,
vector=embedding,
limit=TOP_K,
filter=query_filter,
)
return [
{
"score": round(r.score, 4),
"source_file": r.payload.get("source_file", ""),
"equipment_line": r.payload.get("equipment_line", ""),
"doc_date": r.payload.get("doc_date", ""),
"chunk_index": r.payload.get("chunk_index", -1),
"text": r.payload.get("text", ""),
}
for r in hits
]
def main():
parser = argparse.ArgumentParser(description="Search maintenance records")
parser.add_argument("question", help="Natural language question")
parser.add_argument("--equipment-line", default=None)
parser.add_argument("--doc-date", default=None)
parser.add_argument("--doc-date-to", default=None)
args = parser.parse_args()
start = time.monotonic()
results = search(args.question, equipment_line=args.equipment_line,
doc_date=args.doc_date, doc_date_to=args.doc_date_to)
latency_ms = (time.monotonic() - start) * 1000
log_query(args.question, args.equipment_line or "", results, latency_ms)
if not results:
print("No results found.")
return
print(f"Top {len(results)} results for: \"{args.question}\"\n")
for i, r in enumerate(results, 1):
print(f"[{i}] score={r['score']:.4f} {r['source_file']} "
f"(chunk {r['chunk_index']}) {r['doc_date']} {r['equipment_line']}")
print(f" {r['text'][:200].strip()}...")
print()
if __name__ == "__main__":
main()Essayez votre première requête:
uv run python src/query.py "What caused the bearing failure?"La recherche utilise le même modèle que celui utilisé pour l'ingestion afin Embarquer requête, ce qui permet de conserver à la fois la requête les vecteurs stockés dans le même espace sémantique. Dans le cadre de ce modèle, des scores de similarité compris entre 0,4 et 0,6 indiquent des correspondances pertinentes.
Étape 4 : Ajouter des filtres hybrides
Le filtrage par gamme d'équipements et par date permet d'obtenir des résultats de recherche en lien avec le travail actuel du technicien. Lancez la même requête l'étape 3, mais ajoutez les filtres suivants :
uv run python src/query.py "What caused the bearing failure?" --equipment-line turbine-AAjoutez un filtre par date pour affiner encore davantage les résultats :
uv run python src/query.py "What caused the bearing failure?" --equipment-line turbine-A --doc-date 2024-03-15Résultat attendu :

La fonction `build_filter` construit une requête `FilterBuilder` requête combine la similarité vectorielle avec métadonnées exacte métadonnées . Un technicien travaillant sur la turbine A ne voit que les résultats concernant cette ligne d'équipement, et non l'historique complet de maintenance.
Étape 5 : Connecter le LLM local
Les résultats de la recherche sont transmis à un modèle de langage de grande échelle (LLM) local fonctionnant via Ollama, qui génère une réponse claire et concise en anglais courant. L'ensemble du processus s'effectue sur du matériel informatique installé directement dans l'usine.
Créez le fichier src/llm.py :
from __future__ import annotations
import json
import os
import sys
import urllib.request
from typing import Any
OLLAMA_HOST = os.environ.get("OLLAMA_HOST", "https://localhost:11434")
OLLAMA_MODEL = "llama3.2:3b"
MAX_NEW_TOKENS = 256
TEMPERATURE = 0.1
TIMEOUT_SECONDS = 300
def build_prompt(question: str, results: list[dict[str, Any]]) -> str:
if not results:
return f"Question: {question}\n\nAnswer: I have no relevant context to answer this question."
context_blocks = []
for i, r in enumerate(results, 1):
source = r.get("source_file", "unknown")
date = r.get("doc_date", "unknown")
equip = r.get("equipment_line", "unknown")
text = r.get("text", "").strip()
context_blocks.append(
f"[{i}] Source: {source} | Equipment: {equip} | Date: {date}\n{text}"
)
context = "\n\n".join(context_blocks)
return (
"You are a maintenance records assistant. "
"Answer the question using ONLY the provided context. "
"Cite sources inline using [1], [2], etc. "
"If the context does not contain enough information, say so.\n\n"
f"Context:\n{context}\n\n"
f"Question: {question}\n\n"
"Answer:"
)
def generate(question: str, results: list[dict[str, Any]]) -> str:
prompt = build_prompt(question, results)
payload = json.dumps({
"model": OLLAMA_MODEL,
"prompt": prompt,
"stream": False,
"options": {
"num_predict": MAX_NEW_TOKENS,
"temperature": TEMPERATURE,
},
}).encode()
req = urllib.request.Request(
f"{OLLAMA_HOST}/api/generate",
data=payload,
headers={"Content-Type": "application/json"},
method="POST",
)
with urllib.request.urlopen(req, timeout=TIMEOUT_SECONDS) as resp:
body = json.loads(resp.read().decode())
return body["response"].strip()
def answer(question: str, results: list[dict[str, Any]]) -> str:
reply = generate(question, results)
print(reply)
print()
print("Sources")
for i, r in enumerate(results, 1):
print(
f" [{i}] {r.get('source_file', '?')} "
f"(chunk {r.get('chunk_index', '?')}, score {r.get('score', 0):.4f}) "
f"{r.get('doc_date', '?')} / {r.get('equipment_line', '?')}"
)
return reply
if __name__ == "__main__":
question = sys.argv[1] if len(sys.argv) > 1 else "What maintenance was performed?"
dummy_results = [
{
"source_file": "example.pdf",
"doc_date": "2024-03-15",
"equipment_line": "turbine-A",
"chunk_index": 0,
"score": 0.95,
"text": (
"Performed scheduled bearing inspection on turbine-A. "
"Replaced worn bearing race on shaft 2. "
"Torque settings verified per spec TRB-004."
),
}
]
answer(question, dummy_results)Assemblez le tout en créant le fichier src/test_e2e.py :
from query import search
from llm import answer
question = "What maintenance was performed on the gearbox?"
results = search(question, equipment_line="turbine-A")
answer(question, results)Exécutez l'intégralité du pipeline :
uv run python src/test_e2e.pyllama3.2:3b tient dans la mémoire d'un serveur périphérique standard. Le LLM ne reçoit que les segments extraits comme contexte, et non l'intégralité de la collection de documents, ce qui garantit des réponses rapides et étayées par les sources citées.
Résultat attendu :
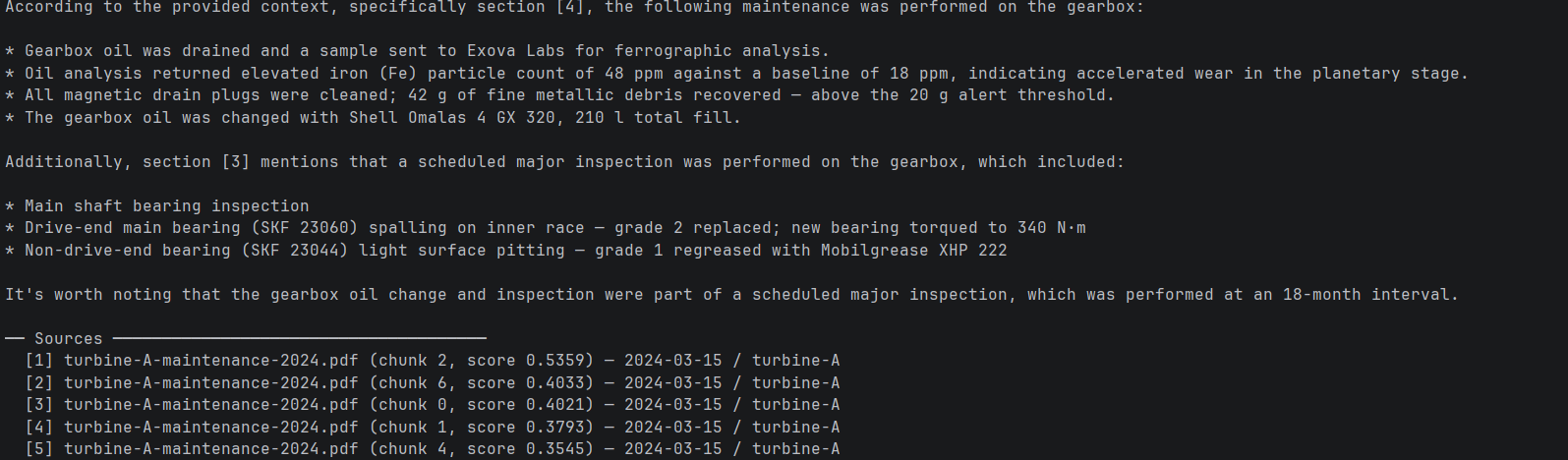
Le système est désormais pleinement opérationnel. Un technicien peut poser une question, obtenir une réponse étayée par les registres de maintenance locaux, sans jamais avoir besoin d'utiliser Internet.
Étape 6 : Activer la journalisation d'audit
La norme CEI 62443 exige une traçabilité complète de toutes les opérations effectuées au sein du réseau OT. En l'absence d'une piste d'audit locale, votre pipeline ne dispose d'aucun enregistrement quelles requêtes ont été effectuées, à quel moment, ni quels résultats ont été renvoyés.
Créer le fichier src/audit.py :
from __future__ import annotations
import json
import logging
from datetime import datetime, timezone
from pathlib import Path
LOG_PATH = Path("./data/audit.log")
LOG_PATH.parent.mkdir(parents=True, exist_ok=True)
handler = logging.FileHandler(str(LOG_PATH))
handler.setLevel(logging.INFO)
logger = logging.getLogger("actian_vectorai.audit")
logger.setLevel(logging.INFO)
logger.addHandler(handler)
def log_query(question: str, equipment_line: str, results: list, latency_ms: float) -> None:
entry = {
"event": "query",
"timestamp": datetime.now(tz=timezone.utc).isoformat(),
"question": question,
"equipment_line": equipment_line,
"results_returned": len(results),
"latency_ms": round(latency_ms, 2),
}
logger.info(json.dumps(entry))
def log_ingestion(source_file: str, equipment_line: str, chunks_stored: int) -> None:
entry = {
"event": "ingestion",
"timestamp": datetime.now(tz=timezone.utc).isoformat(),
"source_file": source_file,
"equipment_line": equipment_line,
"chunks_stored": chunks_stored,
}
logger.info(json.dumps(entry))Exécutez le script d'audit à l'aide de cette commande :
cat data/audit.logRésultat attendu :

Le pipeline conserve désormais un enregistrement structuré enregistrement chaque requête d'ingestion et requête dans le fichier ./data/audit.log, horodaté en UTC et stocké au sein de votre périmètre de sécurité.
Pour conclure
Vous venez de mettre en place un pipeline RAG local qui fonctionne entièrement sur le matériel présent dans l'usine, traite les requêtes même en cas de coupure de réseau et fournit des réponses étayées par des décennies de registres de maintenance.
L'IA dans le secteur manufacturier peut fonctionner sans connexion au cloud. VectorAI DB rend cela possible en s'exécutant entièrement au sein de la zone de sécurité définie par la norme CEI 62443, sans recourir au cloud. Même en coupant complètement la connexion Internet, le pipeline continue de fonctionner.
Votre pipeline ingère des documents de maintenance au format PDF, stocke les représentations vectorielles dans la base de données VectorAI au niveau 2 de votre réseau OT, et répond à des questions en langage naturel à l'aide d'un modèle de langage grand échelle (LLM) local, sans aucune dépendance au cloud à aucune étape. À partir de là, vous pouvez étendre le pipeline en ajoutant d'autres types de documents, en ajustant le modèle de représentation vectorielle au vocabulaire spécifique à votre équipement, en ajoutant requête basé sur les rôles des techniciens, ou en étendant l'ingestion à plusieurs gammes d'équipements.
Consultez la documentation complète de VectorAI DB et le dépôt GitHub pour en savoir plus.
Rejoignez la communauté et découvrez-en davantage sur Actian.

Restez connecté
Des informations tirées des données, à votre service.
(par exemple : sales@..., support)