Transformez vos documents internes en une base pilotée par l’IA





Résumé
- RAG permet d'effectuer des recherches dans la documentation en combinant la recherche sémantique avec un modèle de langage de grande envergure (LLM) qui fournit des réponses en s'appuyant uniquement sur le contexte du document récupéré.
- Le processus comporte trois étapes principales : découper les documents en segments et les indexer, extraire les segments les plus pertinents à l'aide d'une recherche vectorielle, puis générer une réponse contextualisée à partir de ces segments.
- La recherche vectorielle dense consiste à convertir le texte en vecteurs d'encodage, ce qui permet de trouver des contenus sémantiquement similaires même lorsque la formulation diffère.
- Cette approche est utile pour la documentation technique, les bases support , la recherche en matière de conformité, l'intégration des nouveaux employés, la recherche de transcriptions et les catalogues de produits.
- Le principal avantage la rapidité et la pertinence des réponses issues de votre propre contenu, d'autant plus que l'ensemble du processus s'exécute sur votre propre infrastructure, ce qui vous garantit confidentialité et contrôle.
Le problème de la documentation
Toute entreprise proposant un produit, un processus ou devant respecter des exigences de conformité est confrontée au même défi : les connaissances existent, mais elles ne sont pas accessibles. Un support en plein appel ne peut pas parcourir 400 pages de documentation en temps réel. Un nouvel employé ne peut pas assimiler trois années de guides internes dès sa première semaine. Un client ne peut pas trouver le paramètre de configuration spécifique enfoui à la page 247 d’un PDF.
La recherche classique est utile, mais elle nécessite des mots-clés exacts. Demandez « Comment corriger l'erreur 12 » lorsque le document indique « code d'état 12 : MicroKernel ne parvient pas à trouver le fichier spécifié », et la recherche par mot-clé échoue. Vous avez besoin d'une recherche sémantique, c'est-à-dire d'une recherche qui comprend le sens, et pas seulement les mots.
insight clé : La réponse se trouve déjà dans votre documentation. Le défi consiste à la rendre accessible — instantanément, avec précision et sans confusion.
Comment fonctionne RAG
La génération assistée par la recherche (RAG) distingue deux problèmes que les grands modèles de langage (LLM) ont du mal à résoudre : la connaissance d'un contenu spécifique et le raisonnement à partir de celui-ci. La RAG traite le problème de la connaissance grâce à la recherche. Le LLM traite le problème du raisonnement grâce à la génération.
Le processus en trois étapes :
- Indexez vos documents. Les documents sont divisés en segments. Chaque segment est converti en un vecteur d'intégration par un modèle linguistique, et le vecteur ainsi que le texte original sont stockés dans une base de données vectorielle.
- Récupérer le contexte pertinent. Lorsqu'un utilisateur une question, celle-ci est Embarqué du même modèle. La base de données vectorielle identifie les fragments de documents les plus proches sur le plan sémantique, quelle que soit la formulation exacte.
- Générer une réponse fondée. Les fragments les plus pertinents sont transmis à un modèle de langage (LLM) en tant que contexte. Le modèle les lit et répond uniquement à partir des informations qui lui ont été fournies. Pas d'hallucination — juste un raisonnement basé sur vos documents réels.
Avantage en matière de confidentialité : Avec Actian VectorAI et Ollama, l'ensemble du pipeline s'exécute sur vos propres serveurs. Vos documents, requêtes et réponses ne quittent jamais votre infrastructure.
Qu'est-ce que la recherche vectorielle dense ?
Lorsqu'un modèle d'intégration traite un texte, il le convertit en une liste de nombres — un vecteur — dans laquelle la position dans un espace à haute dimension code la signification sémantique. Les textes ayant une signification similaire se retrouvent à des positions similaires. C'est le principe même de la recherche dense.
Le modèleEmbarquer, utilisé dans ce guide, convertit n'importe quel texte en 768 chiffres. Ces dimensions ne sont pas lisibles par l'œil humain. Il s'agit de représentations apprises issues d'apprentissage des milliards d'exemples de texte. Le modèle apprend que les expressions « cannot find file » et « file not found » doivent produire des vecteurs similaires, même si elles ne contiennent aucun mot en commun.
Lors d'une recherche, le requête est comparé à chaque vecteur de document stocké à l'aide de la similarité cosinus, qui mesure l'angle entre deux vecteurs. Plus l'angle est petit, plus la similarité est élevée, et plus le résultat est pertinent. L'index HNSW permet d'effectuer cette comparaison rapidement, même sur des millions de vecteurs.
| Saisie | Similitude |
| requête: « corriger le statut 12 » | — (requête ) |
| Doc : « 12 : MicroKernel ne parvient pas à trouver… » | 0,94 — très pertinent |
| Doc : « Crystal Reports pour Zen… » | 0,12 — sans objet |
Architecture du système
Le pipeline RAG dense comporte deux phases. La phase d'indexation s'exécute une seule fois, ou selon un calendrier défini lorsque les documents sont modifiés. La requête s'exécute à chaque utilisateur et s'achève généralement en moins de 200 ms.
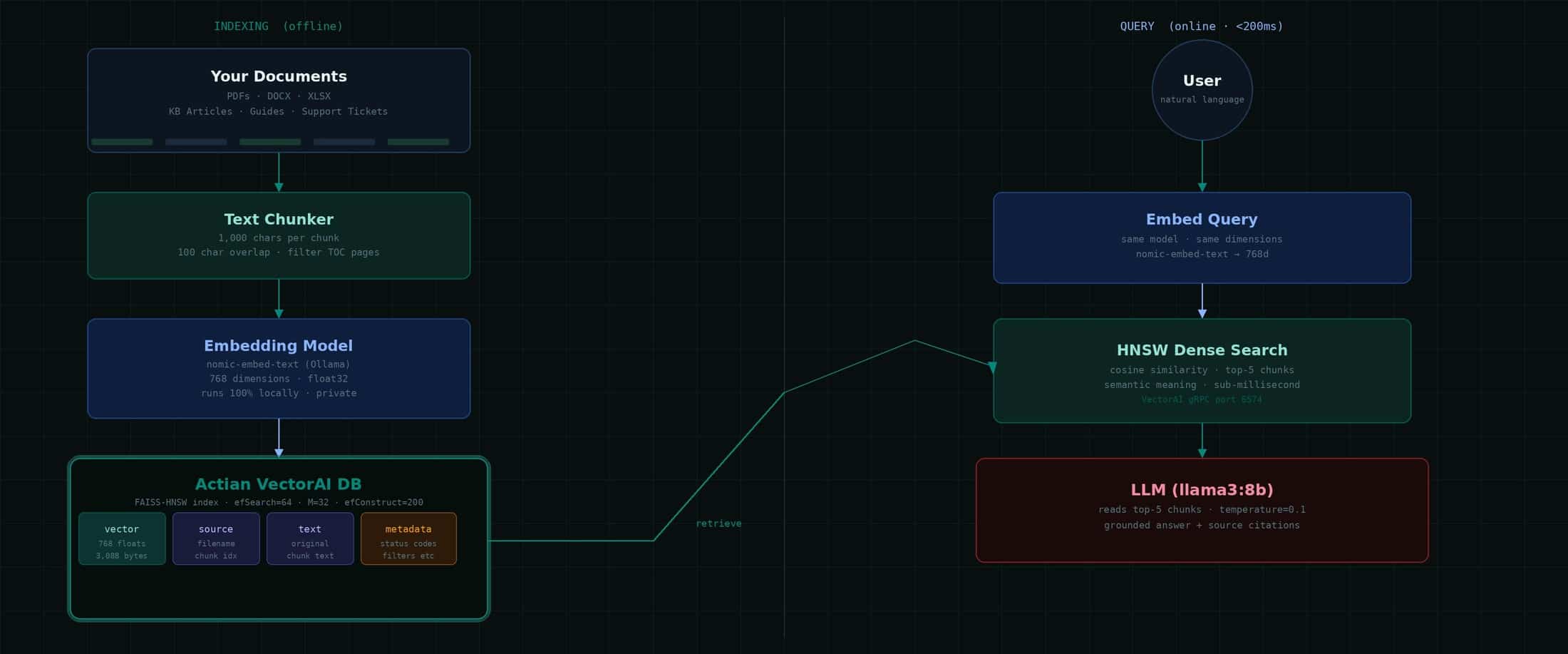
Notez bien ce détail essentiel : le même modèle d'intégration est utilisé à la fois pour l'indexation et pour les requêtes. Si vous effectuez l'indexation avecEmbarquer, vous devez requête Embarquer. Les vecteurs n'ont de sens que par rapport au modèle qui les a créés. Changer de modèle nécessite une réindexation complète.
Comment VectorAI stocke vos données
La base de données Actian VectorAI stocke les vecteurs dansstockage en colonnes de haute performance utilisant FAISS pour l'indexation. Chaque vecteur est stocké sous forme de nombres à virgule flottante de 32 bits, la norme industrielle pour les représentations en apprentissage automatique. Avec 768 dimensions, cela correspond exactement à 3 088 octets par vecteur, comme le confirment les journaux du moteur :
# Confirmed from vde.log on a production deployment
[VectorStore::CreateFile] Created file: vectors.db
(dim=768, record_len=3088)
# The math:
768 dimensions x 4 bytes (float32) = 3,072 bytes
+ 16 bytes overhead
= 3,088 bytes per vector (confirmed)Données relatives au stockage — vérifiées à partir des journaux de production :
| Paramètre | Valeur | Notes |
| Algorithme d'indexation | FAISS HNSW | Recherche par similarité via l'IA de Facebook |
| Back-end de stockage | Fichiers de base de données vectorielle | Une solution de stockage d'entreprise éprouvée |
| Format vectoriel | float32 (4 octets) | Référence du secteur en matière d'apprentissage automatique |
| enregistrement (dim=768) | 3 088 octets | 768 x 4 + 16 frais généraux |
| enregistrement (dim=384) | 1 552 octets | 384 × 4 + 16 frais généraux |
| Limite de segment | 2 Go par segment | S'étend automatiquement à de nouveaux segments |
| Limite de taille des fichiers | Aucun | La seule limite est l'espace disque disponible |
| HNSW efSearch | 64 | Nombre de candidats examinés par requête |
| HNSW efConstruct | 200 | Candidats pendant la création de l'index |
| HNSW M | 32 | Connexions par nœud |
Le moteur de stockage divise automatiquement les fichiers en segments de 2 Go ; il n'y a donc pratiquement aucune limite au nombre de vecteurs. La capacité de stockage dépend entièrement de l'espace disque disponible. À raison de 3 088 octets par vecteur, un téraoctet de stockage peut contenir environ 340 millions de vecteurs.
Cas d'utilisation concrets
Recherche dans la documentation technique. Indexez les manuels de produits, les références API et les guides de configuration. Les utilisateurs posent des questions en langage courant et obtiennent des réponses accompagnées de citations exactes tirées des documents et de références de pages.
BaseSupport . Répertoriez l'historique support et des résolutions. Lorsqu'un nouveau cas est signalé, affichez automatiquement les cas similaires traités par le passé ainsi que leurs solutions, ce qui réduit considérablement le temps de résolution.
Recherche de politiques et de documents de conformité. Permettez la recherche instantanée de documents juridiques et de politiques de conformité. Indiquez toujours la clause ou la section spécifique qui s'applique à la question utilisateur.
Intégration des nouveaux employés. Les nouveaux employés posent des questions sur les politiques, les processus et les outils RH. Le système leur fournit des réponses issues de votre documentation interne réelle : personnalisées, précises et toujours à jour.
Recherche dans les fichiers vidéo et audio. Transcrivez apprentissage et des réunions avec Whisper, indexez les transcriptions et effectuez des recherches dans le contenu audio par signification, avec des liens directs vers l'horodatage exact.
Catalogue de produits. Répertoriez les spécifications des produits, les tableaux de compatibilité et les notes de mise à jour. Les équipes commerciales obtiennent des réponses instantanées et précises lors des appels clients sans avoir à interrompre la conversation.
Mise en place du pipeline
Étape 1 — Regroupez vos documents
Le regroupement par blocs de 1 000 caractères avec un chevauchement de 100 caractères fonctionne bien pour la documentation technique. Ce chevauchement garantit que les phrases ne sont jamais coupées à une limite :
def chunk_text(text: str, chunk_size=1000, overlap=100) -> list:
"""Split text into overlapping character-based chunks."""
chunks, i = [], 0
while i < len(text):
chunk = text[i : i + chunk_size].strip()
if len(chunk) > 80: # skip near-empty chunks
chunks.append(chunk)
i += chunk_size - overlap
return chunksÉtape 2 — Créer une collection et un index
from actian_vectorai import VectorAIClient, VectorParams, Distance, PointStruct
import requests
def embed(text: str) -> list:
r = requests.post("https://localhost:11434/api/embeddings",
json={"model": "nomic-embed-text", "prompt": text})
return r.json()["embedding"]
with VectorAIClient("192.168.x.x:6574") as client:
client.collections.create(
"my_docs",
vectors_config=VectorParams(size=768, distance=Distance.Cosine)
)
for i, chunk in enumerate(chunks):
client.points.upsert("my_docs", [PointStruct(
id = i,
vector = embed(chunk),
payload = {"source": "doc.pdf", "chunk": i, "text": chunk}
)])requête RAG requête complète
import requests
from actian_vectorai import VectorAIClient
VECTOR_SERVER = "192.168.x.x:6574"
OLLAMA = "https://localhost:11434"
COLLECTION = "my_docs"
def rag_query(question: str, top_n: int = 5) -> dict:
# Step 1: Embed the question
query_vec = embed(question)
# Step 2: Search VectorAI DB
with VectorAIClient(VECTOR_SERVER) as c:
results = c.points.search(
COLLECTION, vector=query_vec,
limit=top_n, with_payload=True,
)
# Step 3: Build context from retrieved chunks
context = "\n\n---\n\n".join(
r.payload["text"] for r in results)
# Step 4: Ask the LLM with grounded context
prompt = f"""You are a knowledgeable assistant.
Answer using ONLY the documentation excerpts below.
Documentation: {context}
Question: {question}
Answer:"""
resp = requests.post(f"{OLLAMA}/api/chat", json={
"model": "llama3:8b", "stream": False,
"options": {"temperature": 0.1, "num_predict": 1024},
"messages": [{"role": "user", "content": prompt}]
})
answer = resp.json()["message"]["content"].strip()
# Step 5: Return answer + citations
sources = list({r.payload["source"] for r in results})
return {"answer": answer, "sources": sources}Pourquoi une valeur de 0,1 pour la température ? Pour les questions-réponses factuelles, vous souhaitez des réponses déterministes et précises. Une température faible permet au LLM de se concentrer sur ce que dit réellement la documentation plutôt que de faire des extrapolations ou d'enjoliver les choses.
Chiffres clés — déploiement de la production
| Métrique | Valeur |
| Dimensions d'intégration | 768 |
| Octets par vecteur | 3,088 |
| Algorithme d'indexation | HNSW (FAISS) |
| Modèle d'intégration | Embarquer(Ollama) |
| LL.M. | llama3:8b (Ollama) |
| Port gRPC | 6574 |
| Infrastructure | 100 % sur site |
Des réponses fondées sur votre contenu
Le RAG vectoriel dense, associé à la base de données Actian VectorAI, transforme la documentation statique en une base de connaissances consultable instantanément. Le processus est simple : découpez vos documents en segments, Embarquer à l'aide deEmbarquer, stockez-les dans l'index FAISS-HNSW de VectorAI, puis laissez le modèle de langage de grande envergure (LLM) fournir une réponse à partir du contexte extrait par la recherche.
Comme tout fonctionne sur votre propre infrastructure, vos documents ne quittent jamais votre réseau. Chaque réponse s'appuie sur votre contenu réel, et non sur ce qu'un modèle a appris lors de apprentissage.
Découvrez-en plus sur Actian VectorAI DB.
Conçu avec Actian VectorAI DB · FAISS-HNSW · de haute performance · Ollama · llama3:8b
Toutes les requêtes sont exécutées à 100 % sur site. Aucun document, aucune requête ni aucune réponse ne quitte votre infrastructure.

Restez connecté
Des informations tirées des données, à votre service.
(par exemple : sales@..., support)