3 leçons tirées de l'utilisation de VectorAI DB chez Hacklytics en 2026





Résumé
- Une marketplace de données d'entreprise marketplace une plateforme interne centralisée sur laquelle les équipes peuvent publier, découvrir, analyser et demander l'accès à data products.
- Son objectif est de mettre fin aux silos de données en rendant les données de l'entreprise accessibles, réutilisables et plus fiables pour tous les services.
- Parmi les fonctionnalités typiques, on trouve le catalogage, la recherche, les processus d'accès, les indicateurs de qualité et le suivi de l'utilisation.
- Parmi les principaux avantages, on peut citer une obtention plus rapide insight, une réduction des tâches redondantes liées aux données, gouvernance renforcée, une meilleure qualité des données, libre-service accru et une collaboration améliorée.
- Elle aide les organisations à tirer davantage parti de leurs données en transformant des informations éparses en data products accessibles, bien gérés et prêts à l'emploi.
Une simple modification de formulation a entraîné l'enregistrement d'une requête la base de données des effets indésirables de la FDA (FAERS) est passée de 1 532 résultats à un seul. Lors de Hacklytics 2026, le hackathon annuel de science des données de Georgia Tech, l’équipe RxGuard a interrogé la base de données FAERS, qui contient plus de 31 millions de rapports d’interactions médicamenteuses, pour la warfarine et l'ibuprofène en utilisant quatre formulations différentes : noms génériques, noms de marque, formes de sels et langage naturel. Chaque nouvelle requête a renvoyé moins de résultats, car la base de données FAERS ne pouvait pas comprendre les variations linguistiques.
Cette conclusion fait partie des nombreuses découvertes faites par trois équipes lors d'un week-end de développement avec la base de données Actian VectorAI. Chaque équipe a choisi un cas d'usage s'est attaquée aux contraintes liées à la recherche, à la prédiction et à la génération de données. Voici les problèmes rencontrés dans le domaine de la santé qu'elles ont identifiés et les solutions qu'elles ont mises au point.
Les pharmaciens qui consultent la base de données FAERS pour vérifier les interactions médicamenteuses passent à côté de signaux de sécurité essentiels, car le système ne reconnaît que les correspondances exactes avec les mots-clés. RxGuard comble cette lacune grâce à un moteur de recherche sémantique qui génère des rapports d'analyse sur les interactions dangereuses répertoriées dans la base de données. L'API openFDA extrait les rapports historiques d'effets indésirables pour 70 classes de médicaments, all-MiniLM-L6-v2 intègre les rapports sous forme de vecteurs denses à 384 dimensions, et la base de données Actian VectorAI stocke ces représentations. Une seule instance Vultr équipée de Docker Compose prend en charge l'ensemble de la pile. Lorsque les pharmaciens saisissent le traitement proposé pour un patient et ses antécédents médicaux, RxGuard extrait de la base de données VectorAI les 10 cas d'effets indésirables les plus proches sur le plan sémantique répertoriés par la FDA, ainsi que les scores de risque de gravité et des recommandations de traitements alternatifs.
Le diagnostic des maladies auto-immunes prend entre quatre et sept ans et nécessite l'intervention d'au moins quatre spécialistes. Aura est un moteur RAG de triage clinique axé sur les données locales. Un modèle XGBoost, pré-entraîné sur des données publiques issues de 100 000 patients, détecte les premiers signes de maladies auto-immunes à partir des dossiers médicaux grâce à un AUC de 0,90. VectorAI DB fait office de couche de recherche locale, stockant les enregistrements PubMed Embarqué pritamdeka/S-PubMedBert-MS-MARCO, sous forme d'incorporations à 768 dimensions. Un modèle quantifié de 8 milliards de paramètres, optimisé à partir de données médicales générales et de résumés de dossiers de patients, génère des rapports cliniques contenant des références tirées de revues PubMed.
La plupart des factures médicales contiennent des erreurs, mais pour les contester, il faut maîtriser les codes CPT, connaître les tarifs de Medicare et savoir citer les dispositions légales fédérales, ce dont beaucoup de patients ne disposent pas. PayBack est un système multi-agent de traitement des litiges liés aux factures médicales, basé sur un pipeline LangGraph. Gemini 2.0 Flash extrait les codes CPT des factures téléchargées et les compare à jeu de données « transparent-in-pricing » de DoltHub, en utilisant soit la correspondance avec les assureurs, soit la valeur par défaut correspondant à la moyenne du marché. Un moteur de règles signale les irrégularités de facturation, tandis que all-MiniLM-L6-v2 génère localement des représentations vectorielles en 384 dimensions pour des affaires de litige antérieures. VectorAI DB stocke ces représentations et extrait les trois précédents les plus pertinents afin de fournir un contexte à Gemini 2.5 Pro pour la rédaction des lettres de mise en demeure.
Nous vous présentons ci-dessous les enseignements tirés de leur processus de développement, les principaux défis liés à la recherche qu’ils ont surmontés grâce à VectorAI DB, ainsi que ce que leurs cas d’utilisation révèlent sur les bases de données vectorielles en conditions réelles déploiement.
La recherche par mots-clés comporte des biais cachés
Pour les démonstrations, la recherche par mots-clés fait l'affaire. Mais lorsque de vrais utilisateurs requête corpus spécifique à un domaine en utilisant des vocabulaires synonymiques, la qualité du rappel diminue rapidement. C'est là le problème d'inadéquation lexicale que la recherche par mots-clés met en évidence.
Dans des domaines tels que la santé, la finance et le droit, une même notion peut être exprimée de multiples façons. L'équipe de RxGuard en a fait l'expérience directe en analysant le jeu de données FAERS: « Un même médicament apparaît sous des dizaines de variantes de nom, de formes de sel, d'orthographes étrangères et d'erreurs typographiques dans 11,5 millions de rapports. Les chercheurs américains qui recherchent « hémorragie gastro-intestinale » n'obtiennent aucun résultat, car le terme MedDRA correct utilise l'orthographe britannique. »
La recherche par mots-clés ne permet pas de reconnaître les paraphrases, la similitude entre les sujets ou l’équivalence entre les expressions. Comme le souligne l’équipe de RxGuard : « La recherche par mots-clés ne se contente pas de renvoyer moins de résultats : elle renvoie un sous-ensemble systématiquement biaisé, et ce biais est invisible pour le chercheur. Personne ne sait ce qu’il manque, car les cas manquants n’apparaissent jamais. » Support qui passent au crible les tickets, les commerciaux qui recherchent les spécifications des produits et les ingénieurs qui fouillent dans les wikis internes sont tous confrontés au même défi. La solution réside dans la correspondance sémantique.
RxGuard a utilisé la recherche vectorielle via la base de données VectorAI comme principal mécanisme de recherche, en appliquant en option un filtrage par gravité avant la recherche et une correspondance des noms de médicaments comme contraintes, comme illustré ci-dessous. Les représentations vectorielles placent les synonymes et les alias à proximité les uns des autres dans l'espace vectoriel, ce qui permet au système de comprendre que « (…) “Coumadin”, “warfarine” et “anticoagulant” désignent tous la même chose ».
def search_faers(
query: str,
top_k: int = 10,
min_severity: int = 0,
drug_filter: str | None = None,
) -> list[dict]:
model = _get_model()
query_vector = model.encode(query).tolist()
f = Filter()
if min_severity > 0:
f = f.must(Field("severity_score").gte(min_severity))
fetch_k = top_k * 3 if drug_filter else top_k
with CortexClient(config.VECTORDB_ADDRESS) as client:
results = client.search(
config.VECTORDB_COLLECTION,
query=query_vector,
top_k=fetch_k,
filter=f if not f.is_empty() else None,
with_payload=True,
)
output = []
for r in results:
payload = r.payload or {}
# Post-filter by drug name if requested
if drug_filter:
drugs = payload.get("drugs", [])
if not any(drug_filter.lower() in d.lower() for d in drugs):
continue
output.append({
"rank": len(output) + 1,
"score": round(r.score, 4),
"doc_id": payload.get("doc_id", ""),
"text": payload.get("text", ""),
"drugs": payload.get("drugs", []),
"reactions": payload.get("reactions", []),
"severity_score": payload.get("severity_score", 0),
"patient_age": payload.get("patient_age", -1),
"patient_sex": payload.get("patient_sex", "unknown"),
})
if len(output) >= top_k:
break
return outputCe bloc de code montre comment le système transforme une requête en langage naturel requête une liste classée de cas d'effets indésirables. VectorAI DB effectue une recherche par similarité dans la base de données FAERS stockée, en récupérant par défaut les 10 cas les plus pertinents, quelle que soit la formulation du nom du médicament. métadonnées affinent les résultats en fonction du score de gravité avant la récupération, de sorte que seuls les cas cliniquement pertinents apparaissent. Pour consulter l'implémentation complète du code, rendez-vous sur le dépôt GitHub.
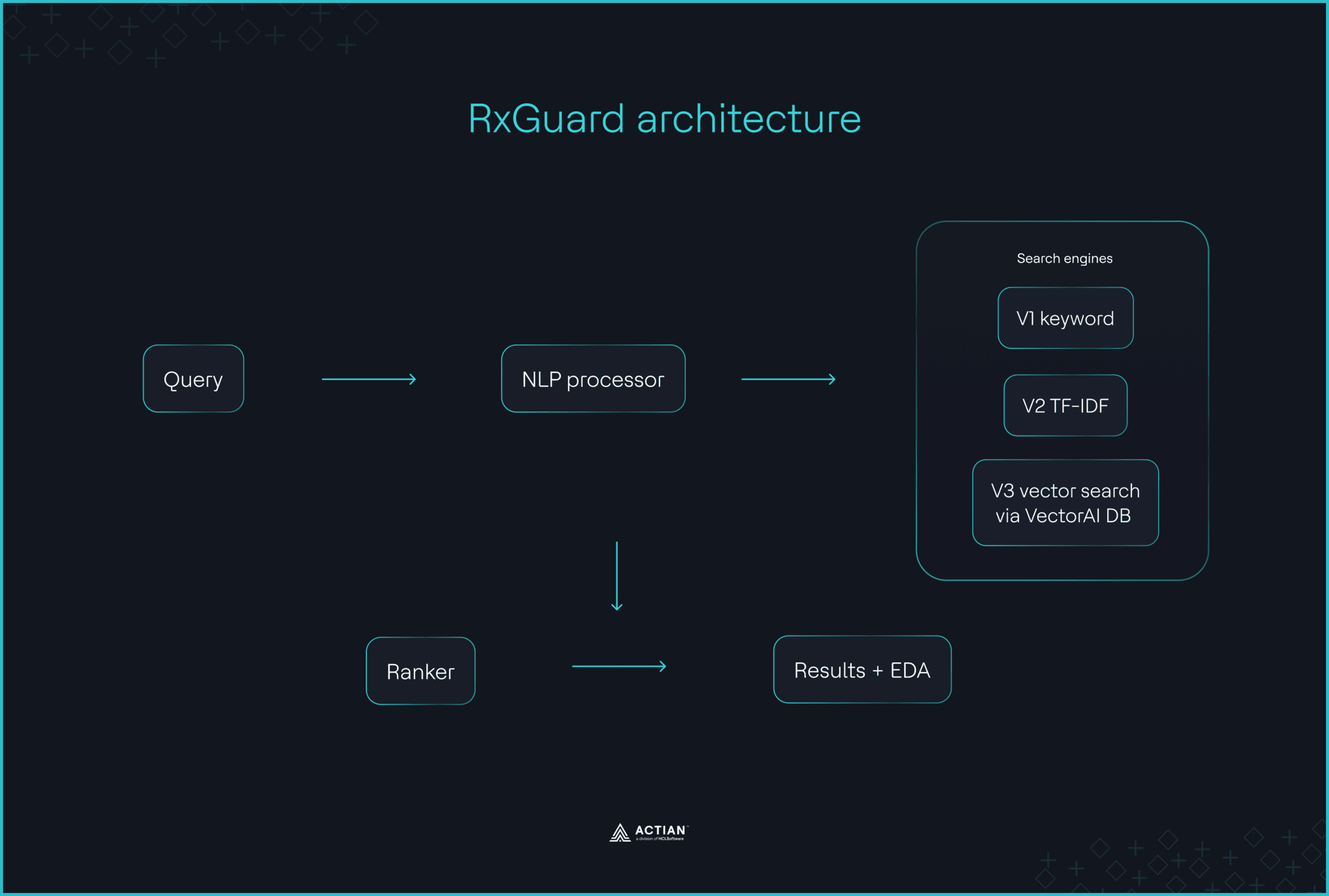
La recherche par mot-clé se limite à la correspondance de mots explicites, mais l'efficacité de la recherche dépend de la prise en compte des synonymes. Et la solution n'est pas nouvelle. Comme le souligne l'équipe de RxGuard, « (...) les éléments nécessaires à cette solution existent depuis des années : les transformateurs de phrases, les bases de données vectorielles et l'API openFDA. Le problème n'était pas d'ordre technique. Le fait est que personne ne les avait encore associés à ce cas d'usage spécifique. »
La recherche vectorielle ne fait qu'une seule chose
Dans les systèmes de production, la recherche vectorielle joue naturellement le rôle d'un mécanisme de récupération. Les modèles d'intégration et les méthodes d'indexation approximative confèrent à la recherche par similarité un caractère probabiliste. Elle met en évidence des documents conceptuellement similaires, mais ne permet pas d'imposer une spécificité ni d'expliquer pourquoi ces documents sont pertinents. Dans les secteurs à haut risque où « assez proche » ne suffit pas et où l'explicabilité est non négociable, la recherche vectorielle ne devrait pas, à elle seule, servir de base décisionnelle.
Le pipeline RAG et de recherche prêt à l'emploi pour déploiement en production déploiement la recherche vectorielle pour l'extraction d'embeddings, des règles déterministes pour prise de décision et un modèle de langage de grande capacité (LLM) pour la génération de réponses. PayBack et Aura ont mis au point ce pipeline dans des domaines distincts.
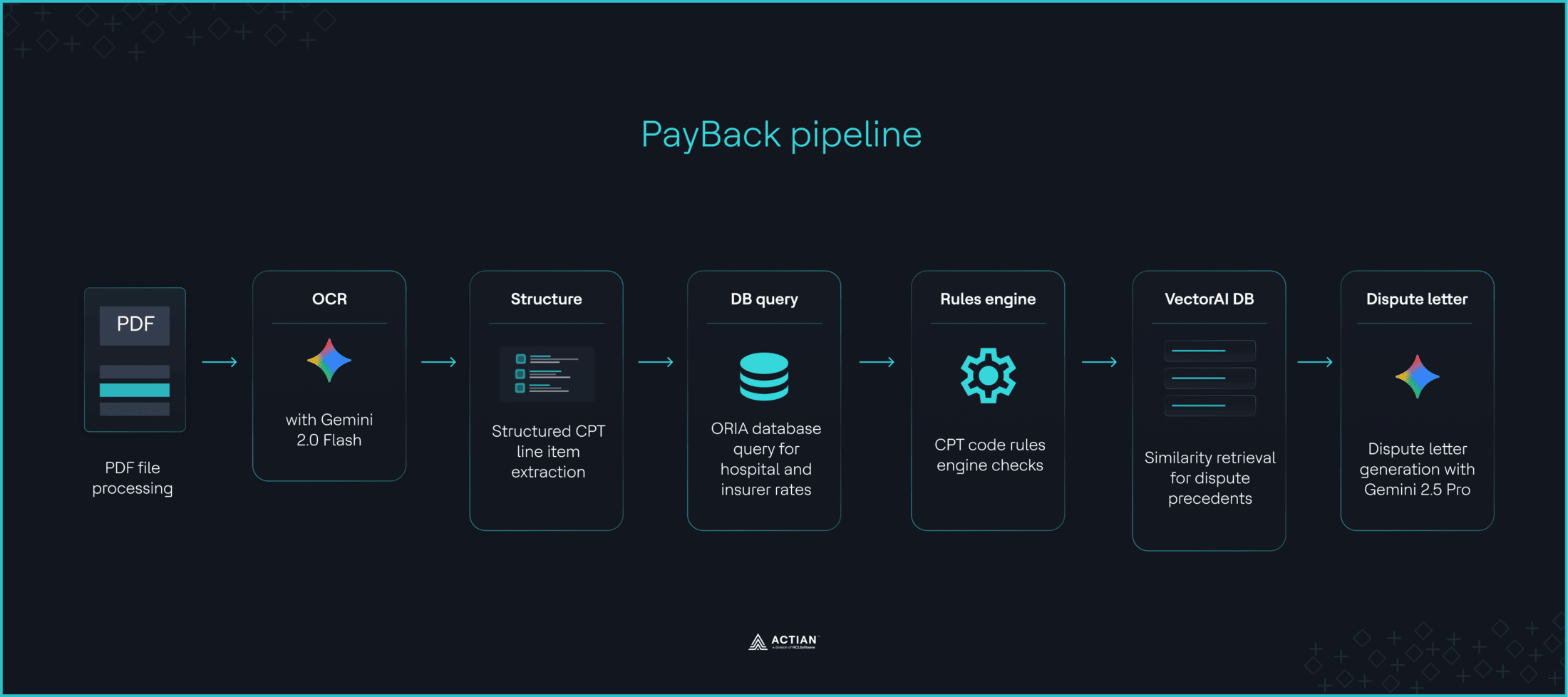
PayBack a utilisé un moteur Python qui signale « les doublons, les anomalies de quantité, les marges excessives, les frais d'établissement, l'auto-orientation et la facturation le jour de la sortie ». VectorAI DB a servi de couche de recherche sémantique et d'enrichissement contextuel qui « récupère les trois cas de litige historiques les plus similaires et les intègre comme contexte pour les invites de Gemini ». Gemini 2.5 Pro « généraitensuite un litige formel en citant les indicateurs, les références DoltHub et la formulation des précédents ». Cetextrait de code illustre le transfert entre le moteur de règles de PayBack et la recherche vectorielle. Rendez-vous sur le dépôt GitHub pour consulter le code complet.
if line_items:
try:
query = _build_precedent_query(line_items)
precedents = search_precedents(query, top_k=3)
similar_cases_context = _format_similar_cases(precedents)
print(f"[rules_engine] Fetched {len(precedents)} similar cases for context")
except PrecedentServiceError as exc:
print(f"[rules_engine] Precedent search unavailable, proceeding without: {exc}")L'équipe d'Aura a associé la recherche vectorielle à un système de notation double hiérarchique basé sur XGBoost. Le modèle classe les caractéristiques structurées des patients en groupes de maladies et identifie une affection probable au sein du groupe prédit. Cette classification intègre l'explicabilité au système, car Aura peut déterminer quelles données du patient ont influencé la prédiction et le score de confiance.
VectorAI DB a continué à suivre le chemin de recherche, en utilisant le contexte des caractéristiques du patient pour faire ressortir les cinq publications PubMed les plus pertinentes qui viennent étayer les résultats de XGBoost par des données cliniques. Voici un aperçu de la manière dont l'équipe Aura a configuré VectorAI DB pour stocker et filtrer des segments de PubMed accompagnés de métadonnées, plutôt que de passer au crible l'intégralité de la littérature au requête .
with CortexClient(ACTIAN_HOST) as client:
client.create_collection(
name=COLLECTION_NAME,
dimension=EMBEDDING_DIM,
distance_metric=DistanceMetric.COSINE,
)
for batch_start in range(0, total, EMBED_BATCH):
batch_end = min(batch_start + EMBED_BATCH, total)
texts = rows["text"][batch_start:batch_end]
embeddings = model.encode(
texts,
batch_size=EMBED_BATCH,
normalize_embeddings=True,
).tolist()
for sub_start in range(0, len(texts), UPSERT_BATCH):
sub_end = min(sub_start + UPSERT_BATCH, len(texts))
i = batch_start + sub_start
client.batch_upsert(
COLLECTION_NAME,
ids=list(range(i, i + (sub_end - sub_start))),
vectors=embeddings[sub_start:sub_end],
payloads=[
{
"chunk_id": rows["chunk_id"][i + k],
"doi": rows["doi"][i + k],
"journal": rows["journal"][i + k],
"year": rows["year"][i + k],
"section": rows["section"][i + k],
"cluster_tag": rows["cluster_tag"][i + k],
"text": rows["text"][i + k],
"pmc_id": rows["pmc_id"][i + k],
}
for k in range(sub_end - sub_start)
],
)Un modèle de traduction a rédigé le résumé final du patient et la note clinique SOAP en s'appuyant sur les références DOI issues de la littérature PubMed extraite. L'illustration du pipeline d'Aura ci-dessous montre comment XGBoost génère la prédiction du diagnostic, tandis que la recherche vectorielle apporte les justifications. Consultez l'implémentation complète du code sur GitHub.
Utilisez la recherche vectorielle pour comprendre requête , présélectionner les résultats potentiels et enrichir les réponses des modèles de langage de grande envergure (LLM). Ajoutez une logique explicite lorsque vous avez besoin de précision et de traçabilité des résultats. Si vous ne respectez pas cette distinction, la précision du pipeline de recherche diminuera en production.
Une solution locale pour les données sensibles
La recherche vectorielle doit s'effectuer sur site, là où les données sont déjà stockées. Des réglementations telles que l'HIPAA et le RGPD imposent des exigences strictes quant à l'emplacement où doivent être conservées les informations personnelles identifiables (PII) et les informations médicales protégées (PHI). Pour de nombreux secteurs, cela signifie au sein du réseau interne.
Aura, PayBack et RxGuard se sont tous heurtés, indépendamment les uns des autres, à cette contrainte de résidence des données. L'équipe d'Aura a eu du mal à se procurer des données pendant le hackathon car « Les hôpitaux gèrent les données des patients avec une grande rigueur, conformément à la réglementation HIPAA. » PayBack a été lancé all-MiniLM-L6-v2 au niveau local, en conservant les représentations dans les mêmes limites que les documents sources. RxGuard prévoit de « À plus long terme, le déploiement sur site , déploiement la conformité à la loi HIPAA exige que les requêtes relatives aux médicaments des patients ne quittent jamais le réseau, correspond exactement à l'architecture pour laquelle la base de données Actian VectorAI a été conçue. »
Trois équipes sont parvenues à la même conclusion en matière d'architecture. La recherche vectorielle doit fonctionner dans un environnement contrôlé dès le premier jour, et VectorAI DB permet de répondre à cette exigence architecturale de manière légère. Aura a déployé VectorAI DB localement à l'aide de trois commandes :
git clone https://github.com/hackmamba-io/actian-vectorAI-db-beta
cd actian-vectorAI-db-beta
docker compose up -dL'équipe a souligné: « Aucune donnée relative aux patients ne quitte l'appareil. La base de données des vecteurs, l'inférence du modèle et la génération des rapports s'effectuent toutes sur l'ordinateur de utilisateur. C'est une condition sine qua non pour l'IA médicale. »
RxGuard a hébergé l'extraction NLP, la génération d'embeddings, la recherche vectorielle et la récupération des étiquettes DailyMed sur une seule instance Vultr, avec VectorAI DB fonctionnant via Docker Compose. Lorsque la conformité interdit l'envoi de données confidentielles vers une API externe ou que les politiques internes exigent que l'inférence s'effectue en local,déploiement sur site similaire s'avère la plus judicieuse.
Une instance Docker locale vous offre un contrôle total sur le parcours des données sensibles, depuis leur ingestion et leur indexation jusqu'à leur récupération et la génération de réponses. L'accès au magasin de vecteurs est régi par des rôles, et chaque requête une piste d'audit. Aucune donnée confidentielle ne franchit les limites du réseau sans autorisation explicite.
Ce que ces projets vous apprennent sur votre prochain chantier
La recherche sur la sécurité des médicaments, le dépistage des maladies auto-immunes et les litiges liés aux factures médicales constituent trois défis majeurs pour un même secteur. Le secteur de la santé et des sciences de la vie s'appuie sur des décennies de données cliniques structurées, frameworks réglementaires stricts et une terminologie fragmentée. Ces trois équipes ont mis au point des systèmes opérationnels en un week-end. Les cas d'utilisation qu'elles ont retenus ne représentent qu'une infime partie des besoins de ce secteur.
Chaque projet a exploité l'architecture existante pour mettre en place des systèmes de recherche de niveau production. Comme l'a souligné l'équipe RxGuard : « Les éléments constitutifs de cette solution existent depuis des années. Le problème, c'est que personne ne les avait encore associés à ce cas d'usage spécifique. » L'intégration de modèles, la recherche vectorielle, les moteurs de règles déterministes et déploiement local via Docker ne déploiement pas des nouveautés. Ces équipes ont su identifier la place de chaque outil et l'ont appliqué au contexte approprié.
Les mêmes problèmes qu'ils ont rencontrés se posent également dans votre domaine. L'incohérence terminologique est présente dans tout corpus dont la terminologie n'est pas harmonisée, la traçabilité des résultats est essentielle pour les systèmes qui doivent justifier chaque résultat, et la localisation des données est une exigence dans les secteurs réglementés.
Si vous envisagez d'utiliser VectorAI DB pour un outil de recherche spécialisé ou un moteur RAG traitant des données sensibles, sachez que ces trois équipes ont déjà validé l'architecture que vous envisagez. Testez Actian VectorAI DB avec vos propres données en suivant le guide d'installation locale disponible dans le dépôt GitHub.
Rejoignez la communauté Actian sur Discord pour entrer en contact avec d'autres développeurs qui implémentent la recherche vectorielle en local.

Restez connecté
Des informations tirées des données, à votre service.
(par exemple : sales@..., support)