Comment mettre en place un écosystème d'IA conforme à la norme HIPAA sans recourir au cloud




Résumé
- Un BAA ne garantit pas automatiquement la conformité des solutions RAG dans le cloud, car les principaux risques en matière de confidentialité proviennent souvent de la couche applicative, et pas seulement de l'infrastructure du fournisseur.
- L'approche la plus sûre décrite ici consiste à maintenir l'intégralité workflow RAG workflow l'infrastructure locale de l'hôpital, y compris l'ingestion, la récupération, la génération et la journalisation.
- Le système protège les données en anonymisant le contenu avant son intégration, en appliquant un contrôle d'accès basé sur les rôles au requête et en empêchant toute consultation inter-services.
- Il utilise une base de données vectorielle locale et des modèles locaux ; ainsi, aucune donnée relative aux patients, aucun encodage, aucune instruction ni aucun journal ne quitte le réseau.
- La journalisation locale des audits est essentielle, car elle permet de conserver une enregistrement complète et vérifiable enregistrement requêtes effectuées, de leur date d'exécution et du rôle de l'utilisateur concerné.
Le secteur de la santé ne peut pas se fier aux solutions RAG dans le cloud, car les données des patients quittent votre réseau et votre système les enregistre, les stocke et les expose hors de votre contrôle. Vous signez un accord de partenariat commercial (BAA), connectez votre pipeline à une base de données vectorielle gérée, et partez du principe que la conformité est assurée. Cette hypothèse est erronée. Le BAA couvre l'infrastructure du prestataire. Il ne couvre pas ce que votre application envoie, enregistre ou expose lors de la récupération et de la génération des données.
Vous restez responsable de tous les chemins empruntés par votre système lors du transfert des informations médicales protégées (PHI). Une requête un clinicien requête entraîner la fuite de données sensibles via les journaux. Une invite du système peut contenir des informations contextuelles sur le patient que votre système stocke en dehors de votre périmètre de contrôle. Un contrôle d'accès insuffisant peut permettre aux résultats de recherche d'exposer des dossiers à l'ensemble des services. Ces risques se situent au niveau de votre couche applicative, et non dans le périmètre de responsabilité du fournisseur de services cloud.
Les autorités de régulation américaines s'attaquent désormais à cette faille. En 2026, elles ont mis en garde contre des schémas d'attaque tels que la « déduction d'appartenance », dans lesquels un attaquant interroge un système d'IA pour vérifier si les données d'un patient figurent dans l'index. Les pipelines hébergés dans le cloud accentuent ce risque, car les requêtes et les vecteurs de représentation transitent par des infrastructures externes. Les exigences en matière d'audit se renforcent encore davantage lorsque les journaux sont stockés sur des systèmes tiers.
Dans ce tutoriel, vous allez créer un assistant de connaissances cliniques fonctionnant entièrement sur l'infrastructure de l'hôpital. Il effectue des recherches sémantiques dans les données cliniques, applique un contrôle d'accès basé sur les rôles au requête et génère des réponses accompagnées de références claires. Chaque requête au sein de votre réseau, chaque accès est consigné localement et aucun appel d'API externe n'est nécessaire.
Pourquoi le BAA ne suffit pas
Un accord BAA protège l'infrastructure du fournisseur de services cloud, mais ne couvre pas la manière dont votre système traite les données de santé protégées (PHI) lors des requêtes, de la récupération et de la génération. Vous restez responsable de tous les endroits où les données de santé protégées apparaissent, circulent ou sont stockées au sein de votre pipeline. Il existe de nombreux scénarios de défaillance susceptibles de rendre votre système non conforme, même si vous signez un accord BAA.
Déficit de responsabilité partagée
La BAA s'arrête aux limites de votre infrastructure. C'est votre système qui contrôle ce qui est saisi dans une interface, ce qui est consigné et ce qui sort de votre réseau. Si requête d'un clinicien requête des informations médicales protégées (PHI) et que votre application les consigne dans un service externe, vous en êtes responsable. Si votre processus de recherche renvoie des dossiers provenant de différents services sans filtres stricts, vous avez provoqué une fuite de données en interne. Ces défaillances se produisent au niveau de votre code, et non dans le périmètre du fournisseur de services cloud.
Par exemple, un médecin effectue une recherche en tapant : « Montrez-moi des cas similaires à celui de John Doe, atteint d'un cancer du poumon à un stade précoce. » Votre application enregistre la requête complète requête un service de journalisation dans le cloud à des fins de débogage. Ce journal contient désormais des données médicales confidentielles en dehors de votre réseau. Ce n'est pas le fournisseur de services cloud qui les a divulguées. C'est votre application qui les a envoyées.
Responsabilité relative au journal d'audit
La loi HIPAA exige une piste d'audit complète pour chaque accès aux informations médicales protégées (PHI). Lorsque votre base de données vectorielle est hébergée sur une infrastructure tierce, votre système stocke requête et les traces de consultation hors de votre contrôle. Vous ne pouvez garantir ni l'exhaustivité, ni la conservation, ni isolement de ces données. Votre équipe de sécurité ne peut pas vérifier les schémas d'accès sans s'appuyer sur le système d'un autre fournisseur. Cela vous empêche de faire respecter la conformité et d'en apporter la preuve.
Par exemple, votre équipe chargée de la conformité vous demande un rapport sur tous les dossiers des patients en oncologie des 30 derniers jours. Votre fournisseur de base de données vectorielle stocke requête sur sa plateforme avec une durée de conservation limitée. Certains journaux manquent et d'autres ne contiennent pas métadonnées utilisateur. Vous ne pouvez pas produire une piste d'audit complète.
Exposition à l'inférence d'appartenance
Les pirates peuvent sonder votre système à l'aide de requêtes ciblées afin de déterminer si les données d'un patient spécifique figurent dans votre index. Ce type d'attaque fait désormais l'objet de préoccupations réglementaires. Les index hébergés dans le cloud augmentent ce risque, car ils exposent une interface distante susceptible d'être sondée de manière répétée. Un index hébergé en local supprime cette interface externe et limite l'accès à votre réseau interne.
Par exemple, un pirate envoie des requêtes répétées telles que « Patients diagnostiqués séropositifs en 2024 et traités avec le médicament X », en modifiant légèrement les filtres à chaque fois. Il observe alors les variations dans le niveau de fiabilité et le contenu des réponses. Au fil du temps, il parvient ainsi à déterminer si enregistrement d'une personne spécifique enregistrement dans votre jeu de données.
Ces défaillances montrent qu'un BAA ne garantit pas la conformité. Undéploiement sur site élimine totalement le recours à des tiers et vous offre un contrôle total sur les flux de données, les accès et la traçabilité.
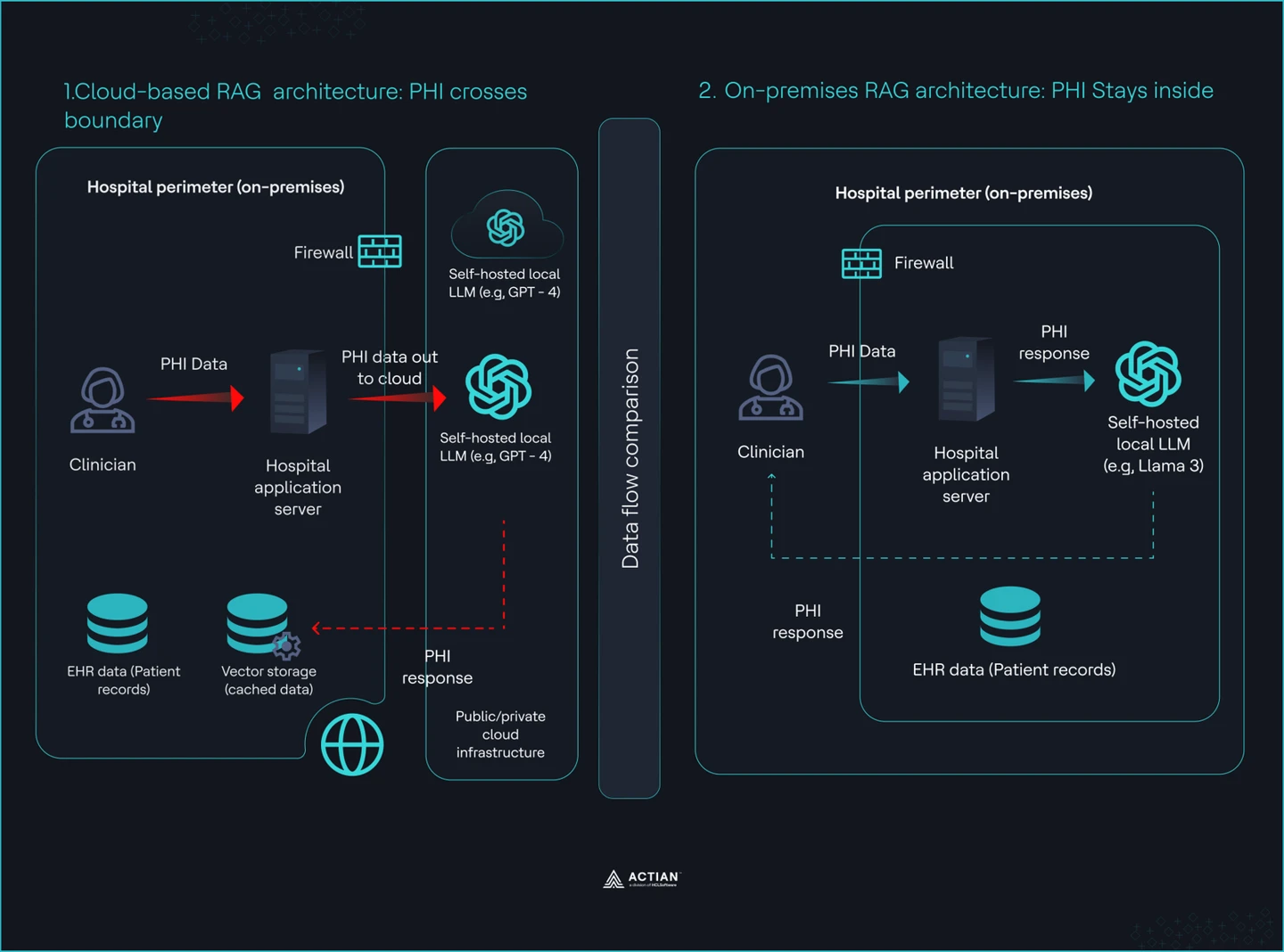
Vue en double volet comparant l'architecture sur site dans le cloud et sur site
Ce que vous construisez
Dans cette section, vous allez mettre en place un système RAG à trois niveaux :
Couche d'ingestion
Vous importez des notes cliniques et des protocoles de traitement dans un index vectoriel contrôlé, avec une hygiène des données rigoureusement appliquée. Vous anonymisez les données avant tout traitement. La norme HIPAA Safe Harbor exige la suppression des identifiants, tandis que l'Expert Determination autorise une approche statistique. Vous appliquez l'une de ces méthodes avant l'ingestion, et non après. Vous découpez ensuite les documents en segments de 512 tokens avec un chevauchement de 50 tokens, générez des représentations vectorielles à l'aide d'un modèle local, puis les stockez dans la base de données VectorAI avec métadonnées.
Vous définissez un schéma rigoureux pour chaque enregistrement. Chaque enregistrement comprend le type de document, le service, la date et le rôle de l'auteur. Ces métadonnées obligatoires. Elles permettent de contrôler l'accès requête et empêchent la fuite d'informations entre services. Ne stockez pas de documents bruts sans structure.
requête
Vous traitez les requêtes des cliniciens via un pipeline de recherche contrôlé. Chaque requête par un contrôle d'accès basé sur les rôles avant d'atteindre l'index. Un utilisateur en cardiologie utilisateur consulter que des données cardiologiques. Un bot de planification ne peut pas accéder aux notes de diagnostic. Vous appliquez cette règle à l'aide d'un filtre « MUST » au niveau du service ou de la cohorte de patients, directement dans la base de données.
Effectuez une recherche hybride. La similarité vectorielle permet de récupérer des segments sémantiquement pertinents. métadonnées restreignent l'ensemble des résultats. Transmettez le contexte filtré à un LLM local. Le modèle génère une réponse à partir des seules données récupérées et inclut des citations. Ne permettez pas au modèle d'inventer des informations ou de puiser dans des connaissances externes.
Couche d'audit
Enregistrez localement chaque interaction avec une traçabilité complète. Chaque requête une enregistrement un horodatage, utilisateur , le service, requête et les références des documents récupérés. Ce journal est hébergé sur votre infrastructure et soumis à des politiques de conservation et d'accès définies. Vous ne dépendez d'aucun système de journalisation externe.
Ce journal vous permet de retracer n'importe quel événement d'accès. Vous pouvez ainsi déterminer qui a accédé à quoi, à quel moment et sous quel rôle. Cela répond aux exigences en matière d'audit et offre à votre équipe de sécurité une visibilité directe sur le comportement du système.
L'ensemble du système fonctionne sur du matériel standard au sein du réseau de l'hôpital. L'architecture de bout en bout du système est illustrée dans l'image suivante :
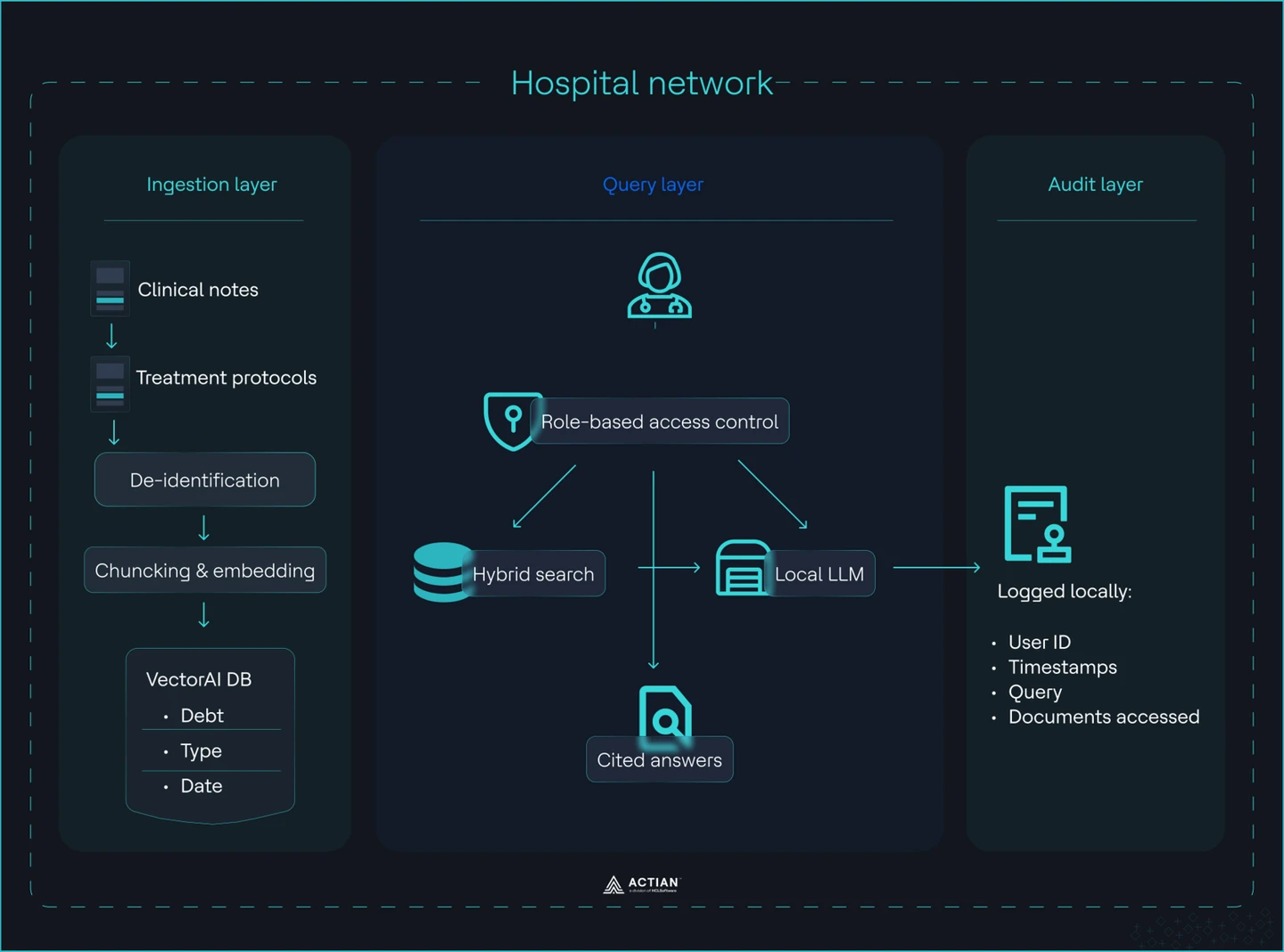
Architecture du système RAG hospitalier
Mise en place d'un Workflow RAG conforme à la loi HIPAA
Dans cette section, vous allez mettre en place un système RAG entièrement local capable de collecter des données cliniques, d'appliquer un contrôle d'accès, de répondre aux requêtes et d'enregistrer chaque interaction.
Conditions préalables
Pour suivre ce guide, installez les outils suivants sur votre réseau local :
- Docker et Docker Compose sont installés.
- Python .10 ou version ultérieure.
- PIP ou UV: ce guide utilise l'UV.
Étape 1 : Déployer une base de données vectorielle
Vous déployez une instance locale d'Actian VectorAI DB avec un stockage persistant pour les données vectorielles et les journaux d'audit.
Créer un docker-compose.yaml fichier :
services:
vectorai:
image: williamimoh/actian-vectorai-db:latest
platform: linux/amd64
container_name: vectorai_db
ports:
- "50052:50051"
volumes:
# vector data persists across restarts
- ./data:/app/data
# audit log lives on host — not inside the container
- ./audit_logs:/app/audit_logs
environment:
- VECTORAI_LOG_LEVEL=info
restart: unless-stopped
Lancez le service :
docker-compose up -dLa base de données démarre et expose le port 50051 pour l'accès local. Les données vectorielles sont stockées dans le répertoire ./data. Les journaux d'audit sont enregistrés dans ./audit_logs sur l'hôte, qui conserve tous les enregistrements d'accès à l'intérieur de votre réseau.
Remarque :
- Les processeurs Apple Silicon M3/M4peuvent rencontrer une erreur de déconnexion GRPC sans qu'aucun journal du conteneur ne soit généré . Dans ce cas, désactivez Rosetta dans Docker Desktop.
- VectorAI DB est en cours de développement.
Étape 2 : Mettre en place le pipeline d'ingestion
Installez la bibliothèque cliente et exécutez le pipeline d'ingestion pour convertir les documents cliniques en vecteurs d'encodage et les stocker dans votre base de données vectorielle locale.
Utilisez uv pour la gestion des dépendances et l'exécution. Cet outil est rapide, reproductible et évite l'utilisation Python global Python .
Télécharger le Progiciel client Actian VectorAI. Cela crée un fichier actian_vectorai-0.1.0b2-py3-none-any
Pour démarrer votre projet :
uv init .
uv venvUne fois l'initialisation terminée, installez le package Actian VectorAI en procédant comme suit :
uv pip3 install actian_vectorai-0.1.0b2-py3-none-anyAjoutez la dépendance du modèle d'intégration :
uv add sentence-transformersCréer un fichier ingest.py contenant les éléments suivants :
import re
import hashlib
from actian_vectorai import VectorAIClient, Distance, VectorParams, PointStruct
from sentence_transformers import SentenceTransformer
# ── Config ────────────────────────────────────────────────────────────────────
VECTORAI_HOST = "localhost:50052"
COLLECTION = "clinical_docs"
EMBED_MODEL = "sentence-transformers/all-MiniLM-L6-v2" # 384-dim
VECTOR_DIM = 384
CHUNK_TOKENS = 512
OVERLAP_TOKENS = 50
# ── Synthetic clinical notes (replace with real de-identified corpus) ─────────
RAW_NOTES = [
{
"document_id": "card_note_001",
"document_type": "clinical_note",
"department": "cardiology",
"date": "2025-03-15",
"author_role": "attending_physician",
"text": """
Patient: [NAME REDACTED], DOB: [DATE REDACTED], MRN: [MRN REDACTED]
Chief Complaint: Chest pain radiating to left arm, onset 2 hours ago.
Assessment: Acute ST-elevation myocardial infarction confirmed on ECG.
History: Hypertension and type 2 diabetes. Started on aspirin 325 mg,
clopidogrel 600 mg loading dose, and heparin infusion per ACS protocol.
Plan: Emergency PCI. Beta-blocker therapy with metoprolol succinate
25 mg daily post-procedure. ACE inhibitor ramipril 5 mg daily initiated
24 hours post-PCI. Follow-up echocardiography in 6 weeks.
""",
},
{
"document_id": "card_protocol_001",
"document_type": "treatment_protocol",
"department": "cardiology",
"date": "2025-01-10",
"author_role": "department_head",
"text": """
Cardiology Protocol — Heart Failure with Reduced EF (HFrEF)
First-line therapy:
- ACE inhibitor: ramipril 2.5–10 mg daily (or ARB if ACE-intolerant).
- Beta-blocker: bisoprolol 1.25–10 mg daily, carvedilol 3.125–25 mg BID,
or metoprolol succinate 12.5–200 mg daily. Titrate every 2 weeks.
- MRA: spironolactone 25–50 mg daily for NYHA class II–IV
if eGFR > 30 and K+ < 5.0.
Target: Symptomatic improvement. Reassess LVEF at 3–6 months.
Device therapy (ICD/CRT) if LVEF ≤ 35% after 3 months optimal therapy.
""",
},
{
"document_id": "psych_note_001",
"document_type": "clinical_note",
"department": "psychiatry",
"date": "2025-03-18",
"author_role": "psychiatrist",
"text": """
Psychiatry intake note — [NAME REDACTED], [AGE REDACTED]-year-old.
Presenting with major depressive episode, PHQ-9 score 18 (severe).
No current suicidal ideation. Started sertraline 50 mg daily.
Psychotherapy referral placed. Follow-up in 2 weeks.
Safety plan documented. Family support confirmed present.
""",
},
{
"document_id": "onco_note_001",
"document_type": "clinical_note",
"department": "oncology",
"date": "2025-03-20",
"author_role": "oncologist",
"text": """
Oncology note — [NAME REDACTED].
Diagnosis: Stage IIIA non-small cell lung cancer, adenocarcinoma.
EGFR mutation positive (exon 19 deletion).
Plan: Osimertinib 80 mg daily (first-line EGFR-targeted therapy).
Baseline CT chest/abdomen/pelvis completed. Brain MRI negative.
Next imaging review in 8 weeks. Antiemetics PRN, skin care for rash.
""",
},
]
# ── Step 1: De-identification ─────────────────────────────────────────────────
# For production use Presidio:
# from presidio_analyzer import AnalyzerEngine
# from presidio_anonymizer import AnonymizerEngine
# analyzer, anonymizer = AnalyzerEngine(), AnonymizerEngine()
# result = analyzer.analyze(text=raw, entities=[...], language="en")
# clean = anonymizer.anonymize(text=raw, analyzer_results=result).text
#
# This demo applies lightweight regex to already-synthetic notes.
_HIPAA_PATTERNS = [
(r"\b\d{3}-\d{2}-\d{4}\b", "[SSN]"), # SSN
(r"\bMRN[-:\s]*\d{4,10}\b", "[MRN]"), # medical record #
(r"\b\d{1,2}/\d{1,2}/\d{2,4}\b", "[DATE]"), # dates
(r"\b[A-Z][a-z]+ [A-Z][a-z]+\b", "[NAME]"), # names (simple)
(r"\b\d{3}[-.\s]\d{3}[-.\s]\d{4}\b", "[PHONE]"), # phone
(r"\b[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.\w+\b","[EMAIL]"), # email
(r"\b\d{5}(?:-\d{4})?\b", "[ZIP]"), # zip
(r"\b(?:https?://)\S+", "[URL]"), # URLs
(r"\b\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\b", "[IP]"), # IP addresses
]
def deidentify(text: str) -> str:
"""Remove HIPAA Safe Harbor identifiers from text."""
for pattern, replacement in _HIPAA_PATTERNS:
text = re.sub(pattern, replacement, text)
return text.strip()
# ── Step 2: Chunking ──────────────────────────────────────────────────────────
def chunk(text: str, size: int = CHUNK_TOKENS, overlap: int = OVERLAP_TOKENS) -> list[str]:
"""Split text into overlapping token windows (whitespace tokenisation)."""
tokens = text.split()
chunks, start = [], 0
while start < len(tokens):
end = min(start + size, len(tokens))
chunks.append(" ".join(tokens[start:end]))
if end == len(tokens):
break
start += size - overlap
return chunks
# ── Step 3: Embedding ─────────────────────────────────────────────────────────
print(f"Loading embedding model: {EMBED_MODEL}")
_model = SentenceTransformer(EMBED_MODEL)
def embed(texts: list[str]) -> list[list[float]]:
return _model.encode(texts, normalize_embeddings=True).tolist()
# ── Step 4: Ingest into VectorAI DB ──────────────────────────────────────────
def _chunk_id(doc_id: str, idx: int) -> int:
"""Stable integer ID from (document_id, chunk_index)."""
h = hashlib.sha256(f"{doc_id}:{idx}".encode()).hexdigest()
return int(h[:15], 16)
def ingest(notes: list[dict]) -> None:
with VectorAIClient(VECTORAI_HOST) as client:
# Health check
info = client.health_check()
print(f"VectorAI DB connected version={info['version']}")
# Create collection (skip if already exists)
try:
client.collections.create(
name=COLLECTION,
vectors_config=VectorParams(size=VECTOR_DIM, distance=Distance.Cosine),
)
print(f"Collection '{COLLECTION}' created dim={VECTOR_DIM}")
except Exception as e:
if "exists" in str(e).lower():
print(f"Collection '{COLLECTION}' already exists — skipping create")
else:
raise
total_chunks = 0
for note in notes:
# De-identify FIRST — before chunking or embedding
clean_text = deidentify(note["text"])
# Chunk second
chunks = chunk(clean_text)
# Embed third
vectors = embed(chunks)
# Build PointStruct records with strict metadata schema
# All four metadata fields are REQUIRED — no optional fields.
points = [
PointStruct(
id=_chunk_id(note["document_id"], i),
vector=vectors[i],
payload={
# ── strict schema ──────────────────────────────────────
"document_type": note["document_type"], # required
"department": note["department"], # required — RBAC filter key
"date": note["date"], # required
"author_role": note["author_role"], # required
# ── retrieval helpers ──────────────────────────────────
"document_id": note["document_id"],
"chunk_index": i,
"text": chunks[i], # de-identified chunk text
},
)
for i in range(len(chunks))
]
client.points.upsert(COLLECTION, points)
total_chunks += len(chunks)
print(f" ✓ {note['document_id']} dept={note['department']} chunks={len(chunks)}")
print(f"\nIngestion complete — {len(notes)} documents, {total_chunks} chunks total")
if __name__ == "__main__":
ingest(RAW_NOTES)
Ce fichier effectue les opérations suivantes :
- Anonymisation des données : le système supprime tous les identifiants HIPAA du texte brut avant le traitement. Les noms, dates et autres champs sensibles sont remplacés par des espaces réservés afin d'empêcher les informations médicales protégées (PHI) d'entrer dans le flux de traitement du système.
- Segmentation du texte : le système divise le texte nettoyé en segments de 512 tokens, avec un chevauchement de 50 tokens. Ce chevauchement permet de préserver le contexte d'un segment à l'autre, ce qui améliore la précision de la recherche.
- Intègre les segments : le modèle convertit chaque segment en un vecteur numérique à l'aide d'un modèle « Sentence Transformers » local. Ce processus permet de saisir la signification sémantique tout en conservant l'intégralité du traitement au sein du réseau.
- Enregistrement des métadonnées: le système enregistre chaque bloc et son vecteur dans la base de données VectorAI, ainsi que les champs nécessaires tels que document_type, department, date et author_role. Ces champs support un contrôle d'accès support lors des requêtes.
Exécutez le script en tapant :
uv run ingest.py
Une fois la commande exécutée, vous devriez obtenir les résultats suivants :
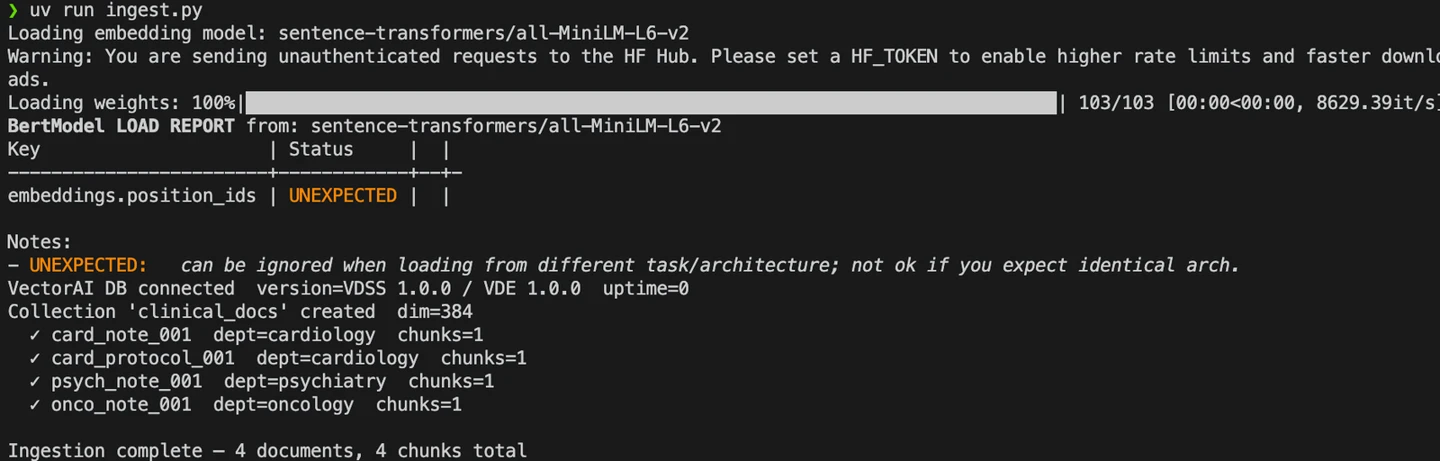
Exécution de ingest.py
D'après les journaux, on constate que le pipeline d'ingestion enregistre des blocs de données dans la base de données VectorAI.
Étape 3 : Exécutez vos requêtes
Exécutez des requêtes sur votre système RAG local et vérifiez le fonctionnement des mécanismes de récupération, de contrôle d'accès et de journalisation d'audit.
Créer un fichier query.py contenant les éléments suivants :
import json
import datetime
import urllib.request
import urllib.error
from pathlib import Path
from actian_vectorai import VectorAIClient
from actian_vectorai import FilterBuilder, Field
from sentence_transformers import SentenceTransformer
# ── Config ─────────────────────────────────────────────────────────────────────
VECTORAI_HOST = "localhost:50052"
COLLECTION = "clinical_docs"
EMBED_MODEL = "sentence-transformers/all-MiniLM-L6-v2"
AUDIT_LOG = Path("./audit_logs/queries.jsonl") # volume-mounted path
# Ollama settings — set OLLAMA_ENABLED=True once `ollama serve` is running
OLLAMA_ENABLED = False # flip to True when Ollama is ready
OLLAMA_URL = "https://localhost:11434/api/generate"
OLLAMA_MODEL = "mistral" # or "llama3.2:3b" for lower hardware
# ── RBAC: role → allowed departments ──────────────────────────────────────────
# Access is enforced as a MUST filter at the database level.
# A scheduling_bot cannot reach clinical notes; cardiology cannot see psychiatry.
ROLE_PERMISSIONS = {
"cardiology_clinician": ["cardiology"],
"oncology_clinician": ["oncology"],
"general_practitioner": ["cardiology", "oncology", "general"],
"admin": ["cardiology", "oncology", "psychiatry", "general"],
"scheduling_bot": ["scheduling"], # no clinical note access
}
class AccessDeniedError(Exception):
pass
def allowed_departments(role: str) -> list[str]:
if role not in ROLE_PERMISSIONS:
raise AccessDeniedError(f"Unknown role '{role}' — access denied by default.")
return ROLE_PERMISSIONS[role]
# ── Embedding (reuse the same model as ingest.py) ─────────────────────────────
print(f"Loading embedding model: {EMBED_MODEL}")
_model = SentenceTransformer(EMBED_MODEL)
def embed(text: str) -> list[float]:
return _model.encode([text], normalize_embeddings=True).tolist()[0]
# ── Step 5: Search with department MUST filter ─────────────────────────────────
def retrieve(query_vec: list[float], departments: list[str], top_k: int = 5) -> list[dict]:
"""
Hybrid retrieval: vector similarity + metadata MUST filter.
Results from departments outside the allowed list are impossible —
the filter is applied at the database level, not in application code.
"""
results = []
with VectorAIClient(VECTORAI_HOST) as client:
for dept in departments:
hits = client.points.search(
collection_name=COLLECTION,
vector=query_vec,
limit=top_k,
# MUST filter — department equality enforced at DB level
filter=FilterBuilder().must(Field("department").eq(dept)).build(),
)
for hit in hits:
payload = getattr(hit, "payload", {}) or {}
results.append({
"score": round(getattr(hit, "score", 0.0), 4),
"document_id": payload.get("document_id"),
"document_type": payload.get("document_type"),
"department": payload.get("department"),
"date": payload.get("date"),
"author_role": payload.get("author_role"),
"chunk_index": payload.get("chunk_index"),
"text": payload.get("text", ""),
})
results.sort(key=lambda r: r["score"], reverse=True)
return results[:top_k]
# ── Step 6: LLM answer via Ollama ─────────────────────────────────────────────
_RAG_SYSTEM = (
"You are a clinical decision support assistant. "
"Answer ONLY using the context passages below. "
"Do NOT use external knowledge or make assumptions. "
"Cite each fact as [Doc N]. "
"If the context is insufficient, say: 'I cannot answer from the available documents.'"
)
def build_context(chunks: list[dict]) -> str:
return "\n\n".join(
f"[Doc {i+1}] ({c['document_type']}, dept={c['department']}, "
f"date={c['date']}, role={c['author_role']})\n{c['text']}"
for i, c in enumerate(chunks)
)
def generate(query_text: str, chunks: list[dict]) -> str:
if not OLLAMA_ENABLED:
# Return raw retrieved context when LLM is disabled
return "[LLM disabled — set OLLAMA_ENABLED=True]\n\n" + build_context(chunks)
context = build_context(chunks)
prompt = f"{_RAG_SYSTEM}\n\nContext:\n{context}\n\nQuestion: {query_text}\n\nAnswer:"
payload = json.dumps({
"model": OLLAMA_MODEL,
"prompt": prompt,
"stream": False,
"options": {"num_predict": 400},
}).encode()
try:
req = urllib.request.Request(
OLLAMA_URL,
data=payload,
headers={"Content-Type": "application/json"},
method="POST",
)
with urllib.request.urlopen(req, timeout=30) as resp:
data = json.loads(resp.read())
return data.get("response", "").strip()
except urllib.error.URLError as e:
return f"[Ollama unreachable: {e}]\n\nRetrieved context:\n{build_context(chunks)}"
def write_audit(record: dict) -> None:
AUDIT_LOG.parent.mkdir(parents=True, exist_ok=True)
with open(AUDIT_LOG, "a", encoding="utf-8") as f:
f.write(json.dumps(record, ensure_ascii=False) + "\n")
# ── Public query entry point ───────────────────────────────────────────────────
def query(user_id: str, role: str, query_text: str, top_k: int = 5) -> dict:
"""
Execute a role-gated RAG query.
Returns:
{answer, retrieved_docs, access_denied, error}
"""
timestamp = datetime.datetime.now(datetime.timezone.utc).isoformat()
# RBAC check — before anything else
try:
departments = allowed_departments(role)
except AccessDeniedError as e:
write_audit({
"timestamp": timestamp, "user_id": user_id, "role": role,
"department": "DENIED", "query_text": query_text,
"retrieved_docs": [], "answer_provided": False, "access_denied": True,
"denial_reason": str(e),
})
return {"answer": f"Access denied: {e}", "retrieved_docs": [], "access_denied": True}
# Embed → retrieve (with MUST filter) → generate
q_vec = embed(query_text)
chunks = retrieve(q_vec, departments, top_k)
answer = generate(query_text, chunks)
doc_refs = [
{"document_id": c["document_id"], "chunk_index": c["chunk_index"],
"department": c["department"], "document_type": c["document_type"],
"score": c["score"]}
for c in chunks
]
# Audit log — every query, regardless of outcome
write_audit({
"timestamp": timestamp,
"user_id": user_id,
"role": role,
"department": ",".join(departments),
"query_text": query_text,
"retrieved_docs": doc_refs,
"answer_provided": True,
"access_denied": False,
})
return {"answer": answer, "retrieved_docs": doc_refs, "access_denied": False}
# ── Demo runs ─────────────────────────────────────────────────────────────────
if __name__ == "__main__":
separator = "─" * 60
# ── Query 1: authorised cardiology query ────────────────────────────────
print(f"\n{separator}")
print("QUERY 1 — cardiology_clinician (authorised)")
print(separator)
r1 = query(
user_id="dr_chen_007",
role="cardiology_clinician",
query_text="What beta-blocker is recommended for heart failure with reduced ejection fraction?",
)
print(f"\nAnswer:\n{r1['answer']}\n")
print("Retrieved sources:")
for d in r1["retrieved_docs"]:
print(f" score={d['score']} [{d['document_type']}] dept={d['department']} "
f"doc={d['document_id']} chunk={d['chunk_index']}")
# ── Query 2: scheduling bot tries to access clinical notes ───────────────
print(f"\n{separator}")
print("QUERY 2 — scheduling_bot (attempting clinical note access)")
print(separator)
r2 = query(
user_id="bot_sched_01",
role="scheduling_bot",
query_text="What are the diagnosis notes for cardiology patients?",
)
if r2["access_denied"]:
print(f"\n✗ Access denied (as expected): {r2['answer']}")
else:
print(f"\nAnswer:\n{r2['answer']}")
print("Sources:", r2["retrieved_docs"])
# ── Query 3: cardiology query that must NOT return psychiatry notes ───────
print(f"\n{separator}")
print("QUERY 3 — cardiology_clinician (RBAC must exclude psychiatry)")
print(separator)
r3 = query(
user_id="dr_chen_007",
role="cardiology_clinician",
query_text="antidepressant dosing and patient management",
)
departments_returned = {d["department"] for d in r3["retrieved_docs"]}
cross_leak = "psychiatry" in departments_returned
print(f"\nDepartments in results: {departments_returned or 'none'}")
print(f"Cross-department leak: {'✗ LEAK DETECTED' if cross_leak else '✓ none — RBAC working correctly'}")
# ── Show audit log tail ───────────────────────────────────────────────────
print(f"\n{separator}")
print("AUDIT LOG → {AUDIT_LOG}")
print(separator)
if AUDIT_LOG.exists():
lines = AUDIT_LOG.read_text().strip().splitlines()
for line in lines[-3:]: # show last 3 entries
entry = json.loads(line)
print(json.dumps({
"timestamp": entry["timestamp"],
"user_id": entry["user_id"],
"role": entry["role"],
"query_text": entry["query_text"][:60] + "…",
"docs_accessed": len(entry["retrieved_docs"]),
"access_denied": entry["access_denied"],
}, indent=2))
else:
print("No audit log found — run ingest.py first.")
Le script effectue trois opérations principales en un seul flux.
- Assure le contrôle d'accès : Le système vérifie le rôle utilisateuravant de récupérer toute donnée. Chaque rôle est associé à des services spécifiques et appliqué comme filtre obligatoire au niveau de la base de données. La couche d'autorisation bloque immédiatement et consigne les rôles non autorisés.
- Récupération et génération de réponses : Le système intègre la requête récupère des extraits de documents pertinents à l'aide d'une recherche vectorielle, en appliquant des filtres départementaux stricts. Les résultats sont ensuite transmis à un LLM local. Si le LLM est désactivé, le contexte récupéré est renvoyé directement.
- Enregistrement des journaux d'audit : Le système enregistre requête chaque requête , y compris utilisateur , son rôle, requête , les documents consultés et le statut d'accès. Cela permet de créer une piste d'audit complète à des fins de conformité et de contrôle.
Exécutez le script en tapant :
uv run query.py
Une fois la commande exécutée, vous devriez obtenir les résultats suivants :
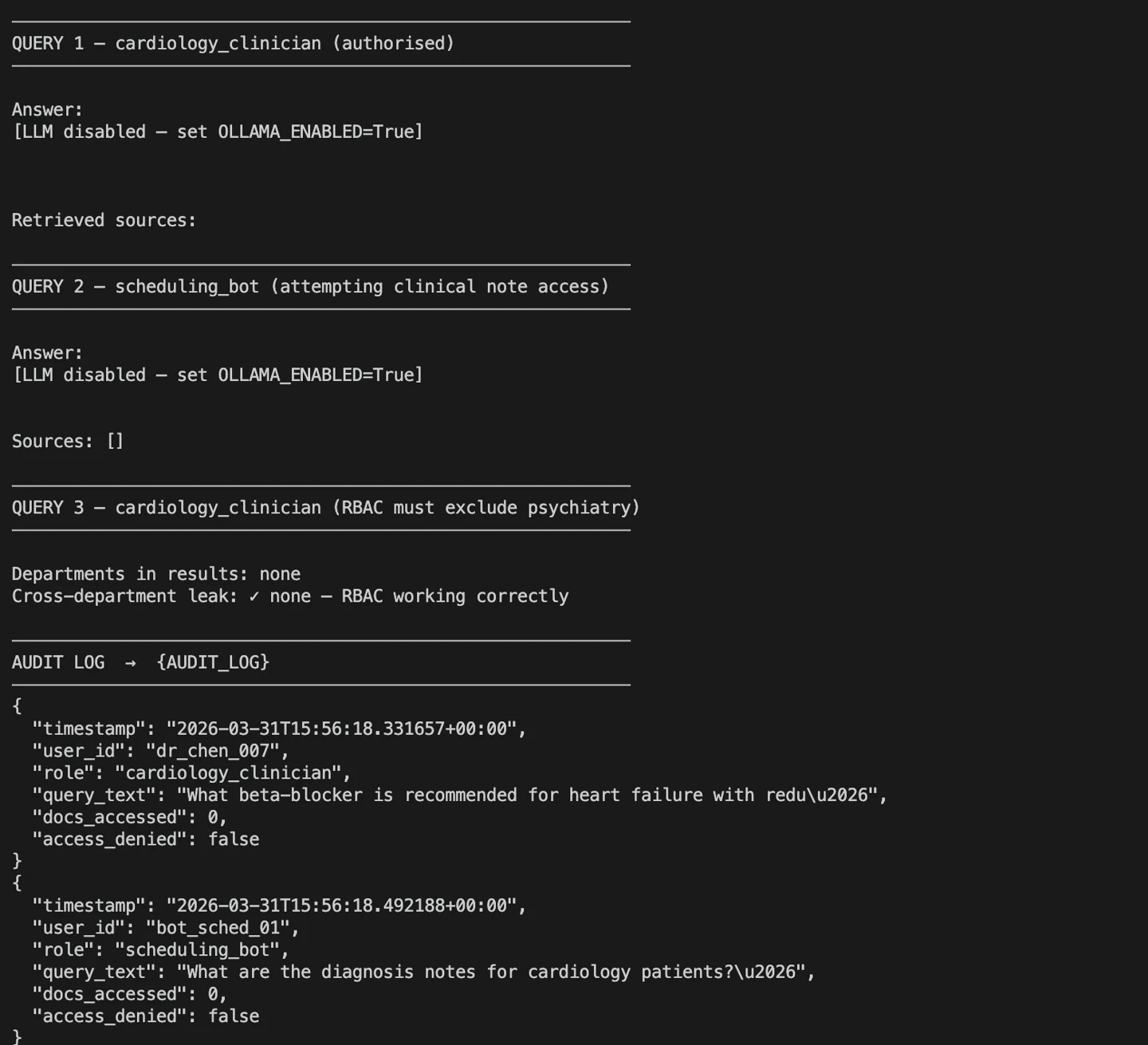
Exécution de requête.py
Le résultat présente trois cas de test : l'un illustrant une requête valide d'un clinicien, une tentative d'accès refusée et une vérification des fuites entre services. Ceux-ci permettent de s'assurer que le RBAC et la journalisation des audits fonctionnent correctement avant le passage en production.
Étape 4 : Configurer le journal d'audit
Enregistrez chaque requête en utilisant le mappage de volume défini lors déploiement.
La configuration Docker monte le répertoire ./audit_logs de votre hôte dans le conteneur. Lorsque vous exécutez des requêtes, cela crée un dossier local nommé audit_logs contenant un fichier queries.jsonl.
Le fichier contient les entrées suivantes :
{"timestamp": "2026-03-31T15:56:02.552088+00:00", "user_id": "dr_chen_007", "role": "cardiology_clinician", "department": "cardiology", "query_text": "What beta-blocker is recommended for heart failure with reduced ejection fraction?", "retrieved_docs": [], "answer_provided": true, "access_denied": false}
{"timestamp": "2026-03-31T15:56:03.098346+00:00", "user_id": "bot_sched_01", "role": "scheduling_bot", "department": "scheduling", "query_text": "What are the diagnosis notes for cardiology patients?", "retrieved_docs": [], "answer_provided": true, "access_denied": false}
{"timestamp": "2026-03-31T15:56:03.663767+00:00", "user_id": "dr_chen_007", "role": "cardiology_clinician", "department": "cardiology", "query_text": "antidepressant dosing and patient management", "retrieved_docs": [], "answer_provided": true, "access_denied": false}
{"timestamp": "2026-03-31T15:56:18.331657+00:00", "user_id": "dr_chen_007", "role": "cardiology_clinician", "department": "cardiology", "query_text": "What beta-blocker is recommended for heart failure with reduced ejection fraction?", "retrieved_docs": [], "answer_provided": true, "access_denied": false}
{"timestamp": "2026-03-31T15:56:18.492188+00:00", "user_id": "bot_sched_01", "role": "scheduling_bot", "department": "scheduling", "query_text": "What are the diagnosis notes for cardiology patients?", "retrieved_docs": [], "answer_provided": true, "access_denied": false}
{"timestamp": "2026-03-31T15:56:18.569824+00:00", "user_id": "dr_chen_007", "role": "cardiology_clinician", "department": "cardiology", "query_text": "antidepressant dosing and patient management", "retrieved_docs": [], "answer_provided": true, "access_denied": false}Chaque ligne correspond à un requête . Le journal enregistre l'identité de l'auteur de la requête, son rôle, le service concerné, le requête et indique si l'accès a été autorisé. Ce fichier est entièrement hébergé sur votre infrastructure et vous fournit une piste d'audit complète et vérifiable pour chaque interaction avec les données de santé protégées (PHI).
Pour conclure
Un accord de niveau de service (SLA) n'a jamais suffi, car il ne régit pas la manière dont votre application traite les informations médicales protégées (PHI). Vous avez résolu ce problème en conservant l'ensemble des données, des requêtes et des journaux au sein de votre réseau.
Vous disposez désormais d'un système RAG qui applique un accès basé sur les rôles, ne récupère que les données autorisées et consigne localement chaque interaction, sans recourir à des API externes ni exposer vos données à des tiers.
Appliquez ce modèle à d'autres systèmes réglementés. Consultez la documentation de VectorAI DB et dépôt GitHub pour obtenir les mises à jour et les détails de mise en œuvre.
Rejoignez la communautéet découvrez-en davantage sur Actian.

Restez connecté
Des informations tirées des données, à votre service.
(par exemple : sales@..., support)