Faut-il utiliser la méthode RAG ouoptimiser LLM ?




Résumé
- Le RAG domine le domaine de l'IA d'entreprise grâce à sa flexibilité, mais le fine-tuning excelle en termes d'évolutivité, de latence et de résultats structurés.
- RAG ajoute des coûts récurrents liés au contexte et à la recherche, tandis que l'optimisation fait peser les coûts dès le départ grâce àrequête stablerequête .
- Les approches hybrides combinent la recherche et le réglage fin pour offrir une plus grande précision et un meilleur raisonnement.
- Le choix de l'approche appropriée dépend de la volatilité des données, requête et Fonctionnalités de l'équipe.
À première vue, le débat opposant la génération augmentée par la récupération (RAG) au fine-tuning semble simple. La RAG intègre des données externes au moment de l'inférence. Le fine-tuning modifie les poids du modèle pendant apprentissage. Dans les systèmes de production, cette distinction ne suffit pas.
Selon le rapport « Menlo Ventures 2024 , 51 % des déploiements IA générative entreprise utilisent le RAG en production. Seuls 9 % s'appuient principalement sur le fine-tuning. Pourtant, des études telles que celle de étude RAFT de l'université de Berkeley montrent que les systèmes hybrides combinant la récupération et le fine-tuning surpassent chacune de ces approches prises isolément dans les tests de performance.
Si les systèmes hybrides permettent d'obtenir de meilleurs résultats, pourquoi le secteur privilégie-t-il uniquement le RAG ? Dans cet article, nous comparerons le RAG, le fine-tuning et une architecture hybride afin de comprendre les compromis à faire et les points forts de chaque approche.
TL;DR
- RAG: Idéal pour les connaissances qui évoluent fréquemment et un trafic modéré ; facile à mettre à jour sans formation supplémentaire.
- Réglage fin: Idéal pour les domaines stables et faible latence à haut débit ou faible latence ; améliore la précision et le formatage tâche.
- Hybride/RAFT: Combine une recherche actualisée avec un comportement de modèle optimisé pour une précision maximale.
- Compromis essentiel: Le choix dépend du requête , de la fréquence des changements dans les connaissances et de l'expertise de l'équipe.
Pourquoi la comparaison classique entre RAG et l'ajustement fin ne tient pas la route
La méthode RAG consiste à intégrer de manière dynamique des données externes au moment de l'inférence. Chaque requête des documents ou des fragments d'informations pertinents, que le système ajoute à la requête, ce qui permet au modèle de générer des réponses fondées sur des informations actualisées.
L'affinage consiste à modifier les poids d'un modèle pendant apprentissage données étiquetées. Au lieu de s'appuyer sur une recherche externe, le modèle intériorise directement les schémas, produisant ainsi des résultats cohérents sans interroger de sources externes.
Bien que ces définitions soient techniquement correctes, la plupart des comparaisons standard ne tiennent pas compte des facteurs qui influencent réellement les décisions en production. Dans les systèmes réels, le choix entre RAG et le réglage fin dépend de variables telles que l'échelle, requête et la fréquence à laquelle vos données évoluent.
Variable manquante n° 1 : Développement du contexte à grande échelle
Dans de nombreux systèmes RAG en production, chaque requête ajoute des centaines de jetons. Ce contexte supplémentaire modifie la manière dont le modèle répartit son attention et hiérarchise les poids.
Les contextes de recherche volumineux rivalisent avec la requête et les instructions pour attirer l'attention, ce qui peut nuire à la qualité du signal. De petites erreurs de recherche ou des extraits peu pertinents peuvent entraîner des anomalies de mise en forme ou fausser le raisonnement de manière subtile. La qualité de la sortie du système dépend fortement de la qualité de la recherche.
Le réglage fin fonctionne différemment. Au lieu d'injecter de grands volumes de texte au moment de l'inférence, il intègre directement des modèles et des contraintes dans le modèle pendant apprentissage. Cette différence influe sur le comportement du système face à des charges de travail réelles.
Variable manquante n° 2 : fréquence de recyclage
On dit souvent qu’il faut « utiliser RAG si les connaissances changent fréquemment » et « recourir au réglage fin si le comportement est stable ». Mais qu’entend-on exactement par « fréquemment » ?
Si votre base de connaissances évolue quotidiennement, les processus de recyclage peuvent entraîner des frictions opérationnelles. Les cycles d'évaluation, jeu de données et déploiement sont autant de facteurs qui allongent les délais.
La préparation des données est également importante. Si votre organisation ne dispose pas de jeux de données structurés, versionnés et propres, le coût caché de préparation apprentissage peuvent dépasser les coûts de calcul.
Comparaison des coûts entre RAG et le réglage fin
Les comparaisons superficielles entre le RAG et le réglage fin négligent souvent les courbes de coûts qui déterminent la viabilité à long terme. Dans les systèmes de production, les estimations financières jouent un rôle crucial dans les décisions architecturales. Pour évaluer de manière réaliste le RAG par rapport au réglage fin, il faut examiner trois niveaux de coûts :
- Coût des jetons et expansion du contexte.
- Coût de l'infrastructure de récupération.
- coût apprentissage .
La structure des coûts de RAG
Les systèmes RAG entraînent des coûts d'exploitation récurrents, car chaque requête des informations externes et les intègre dans la consigne du modèle. Ce contexte supplémentaire est facturé à chaque requête.
Développement du contexte
Les systèmes RAG de production ajoutent environ 500 jetons de contexte extrait à chaque requête. Le fournisseur facture ces jetons à chaque requête.
En se basant sur un prix similaire à celui du celui du GPT-5.2, soit 1,750 dollar par million de jetons d'entrée, le coût mensuel supplémentaire s'élève à :
Coût par requête
500 jetons × 1,75 $/1 000 000 = 0,000875 $ par requête
À petite échelle, ce coût semble négligeable. Cependant, comme il s'applique à chaque requête, la charge totale augmente de manière linéaire avec le trafic.
En fonction du niveau de trafic :
| Requêtes mensuelles | Coût contextuel |
| 10 millions | $8,750 |
| 50 millions | $43,750 |
| 100 millions | $87,500 |
Il s'agit uniquement des coûts liés au contexte. Cela n'inclut pas les jetons de sortie ni les jetons de base de l'invite. À long terme, ce qui semble flexible et peu coûteux finit par représenter une dépense récurrente importante.
Base de données vectorielle et coût de la recherche
Le coût des jetons n'est qu'un élément parmi d'autres des coûts liés au RAG. Le RAG s'appuie également sur une base de données vectorielle pour la recherche sémantique. Le système doit stocker, indexer et requête efficacement requête .
Tarifs publics des listes Pinecone :
- Stockage à environ 0,33 dollar par gigaoctet et par mois.
- Les unités se négocient à environ 16 dollars le million.
- Les unités s'élèvent à environ quatre dollars le million.
Prenons par exemple un système traitant 50 millions de requêtes par mois, chaque requête une seule recherche vectorielle (en supposant un vecteur de 1 024 dimensions). Cela représenterait 50 millions d'opérations de lecture par mois. Si le système écrit également environ six millions d'enregistrements par mois, l'activité combinée de lecture et d'écriture porterait le coût mensuel total estimé à environ 1 532 $.
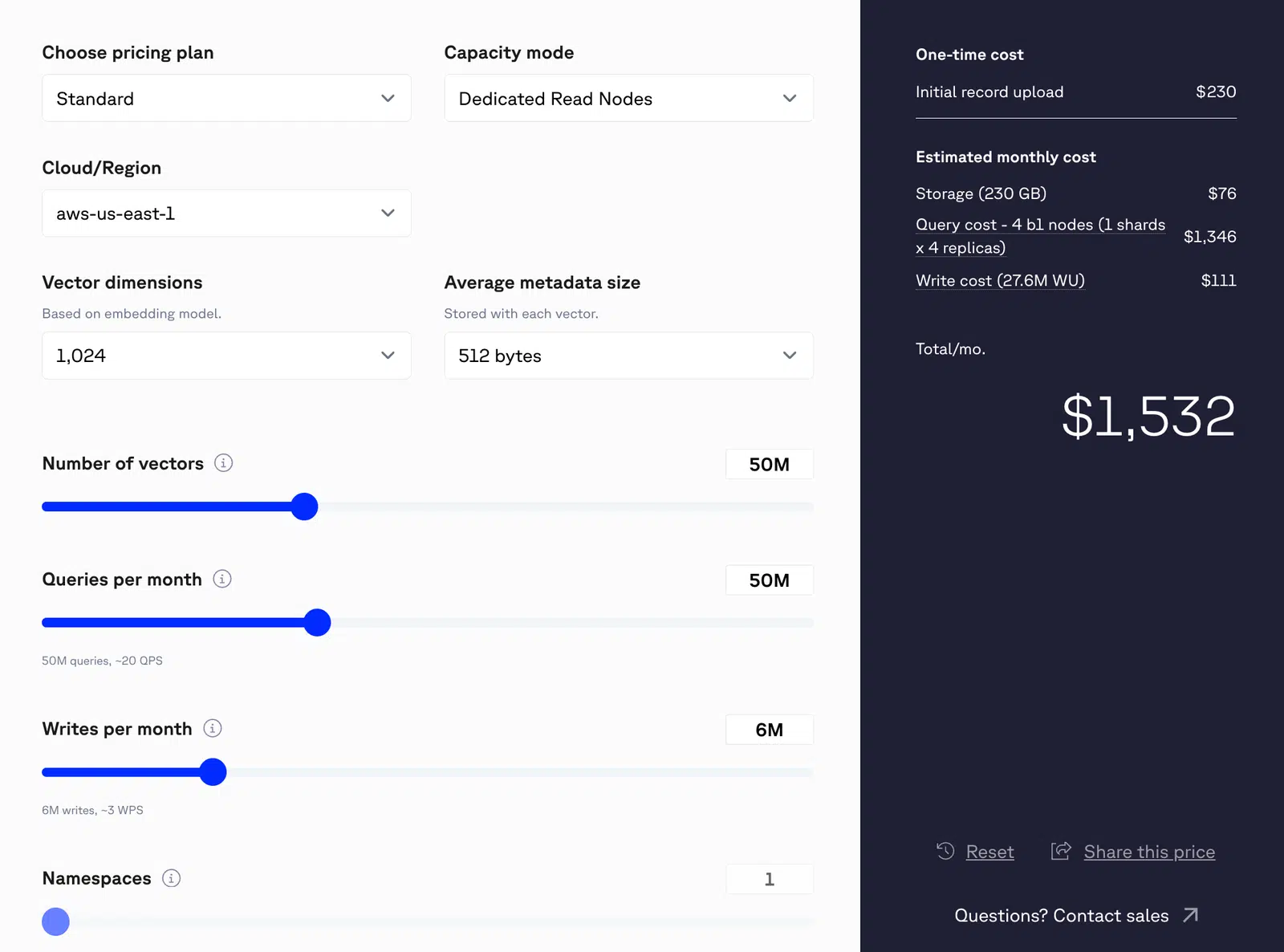
Figure 1 : Tarification de Pinecone pour des vecteurs de 50 millions
Avec 200 millions de requêtes par mois, les dépenses totales s'élèvent à 9 000 dollars par mois.
Deux systèmes RAG traitant un trafic identique peuvent donc présenter des structures de coûts sensiblement différentes selon de la conception et optimisée.
Coût des infrastructures
Les systèmes RAG nécessitent une infrastructure de stockage et de calcul pour générer des représentations, stocker et indexer des vecteurs, exécuter des requêtes de recherche et effectuer des inférences. Chacune de ces étapes consomme ressources de calcul, généralement fournies par des serveurs cloud qui doivent s'adapter au trafic.
Pour les applications en temps réel ou à haut débit, une capacité supplémentaire est nécessaire afin de garantir une faible latence et la fiabilité du système. Les mécanismes de réplication, d'auto-scaling, de surveillance et de basculement ajoutent tous à la complexité opérationnelle. Ces couches d'infrastructure sont indispensables pour un RAG de niveau production, mais elles augmentent le coût total au-delà de la simple utilisation des jetons.
La structure des coûts de la mise au point
Le réglage fin propose un modèle économique différent de celui des systèmes RAG. Au lieu de payer des coûts supplémentaires à chaque requête de contexte externe, vous investissez dès le départ pour modifier le comportement interne du modèle.
Cet investissement initial peut être réparti en quatre grandes catégories de coûts : les données, apprentissage , l'expérimentation et la maintenance opérationnelle.
Coûts liés à la préparation des données
Des données annotées de haute qualité constituent la base d'un réglage fin efficace. Cela implique notamment de collecter des exemples spécifiques au domaine, de corriger les incohérences, de formater correctement les entrées et les sorties, et de vérifier la qualité des annotations.
Dans de nombreuses organisations, la préparation des données représente 20 à 40 % du budget total alloué à l'ajustement. Des données mal préparées nuisent directement aux performances des modèles, ce qui entraîne des cycles de réentraînement supplémentaires et un gaspillage de ressources informatiques.
coûts apprentissage
OpenAI estime le coût du fin-tuning à environ 25 dollars par million apprentissage pour GPT-4.1. Une exécution utilisant 20 millions de jetons coûterait environ 500 dollars en apprentissage directs, ce montant pouvant augmenter en cas d'utilisation jeux de données plus volumineux jeux de données multiples exécutions.
Pour apprentissage en auto-hébergement, les coûts dépendent de la taille du modèle et du matériel de haute performance , tels que les clusters A100, peuvent coûter plusieurs milliers de dollars par apprentissage . Comme le réglage fin est rarement un processus en une seule étape, il est courant de procéder à plusieurs époques, évaluations et cycles de réentraînement, ce qui augmente encore davantage le coût global.
Coûts liés à l'expérimentation et à la validation
Le réglage fin est un processus itératif qui nécessite de tester différents hyperparamètres, de comparer les résultats à ceux de modèles de référence et de valider le modèle dans des cas limites. Ces processus exigent du temps de développement, une infrastructure adéquate et frameworks d'évaluation structurés. Contrairement à l'ingénierie des prompts, le réglage fin implique un cycle de vie complet du machine learning, ce qui entraîne une charge opérationnelle supplémentaire permanente.
Cela donne lieu à une courbe de coûts non linéaire. L'optimisation concentre les coûts au début, tandis que le coût marginal par requête reste relativement stable à mesure que le trafic augmente.
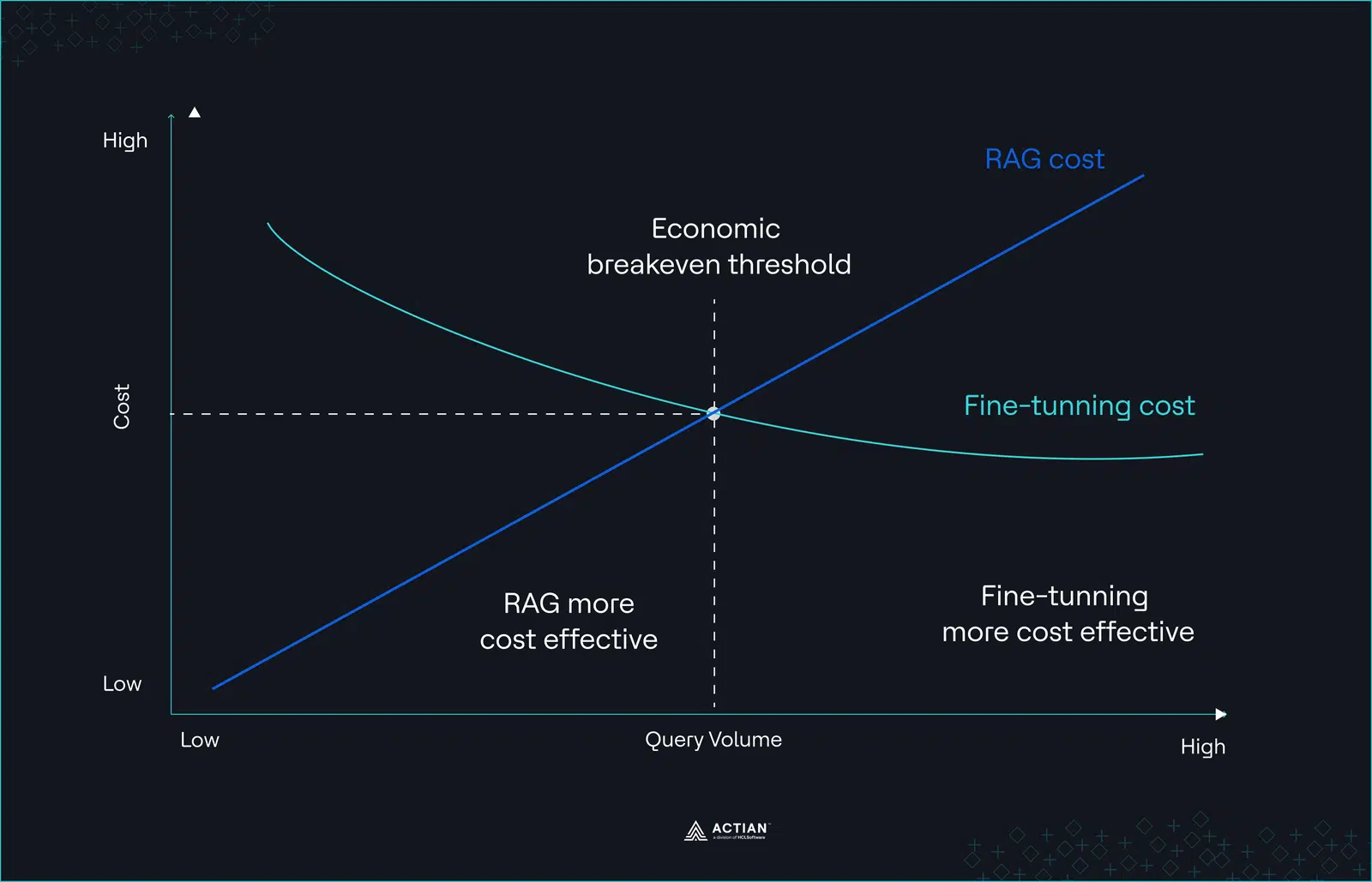
Figure 2 : Courbe de coûts non linéaire
Pour déterminer si ce compromis est avantageux, trois variables entrent en jeu : requête , la stabilité des connaissances et la fréquence de réentraînement. Sans modélisation explicite de ces variables, les comparaisons de coûts entre le RAG et le fine-tuning restent incomplètes.
Quand RAG l'emporte
Malgré ses compromis en matière d'évolutivité, le RAG reste le choix privilégié en production, et ce pour une bonne raison. Dans certaines conditions d'exploitation, il est structurellement plus flexible, plus rapide à itérer et plus sûr sur le plan opérationnel que le fine-tuning. Le RAG est adapté aux scénarios suivants :
- Lorsque les connaissances évoluent fréquemment
Si vos connaissances métier évoluent chaque semaine, voire chaque jour, le processus d'ajustement devient coûteux sur le plan opérationnel. jeu de données , le réentraînement, l'évaluation et déploiement des délais pouvant aller de quelques heures à plusieurs semaines, selon gouvernance en matière de gouvernance .
Les équipes sous-estiment souvent la charge opérationnelle liée au maintien de la synchronisation d'un modèle finement ajusté avec une base de connaissances en constante évolution. Dans ces environnements, le RAG déplace le problème du réentraînement du modèle vers l'indexation des données.
- Lorsque vous disposez d'une grande quantité de données non structurées mais de données étiquetées en nombre limité
De nombreuses organisations disposent de téraoctets de documents internes, mais manquent de jeux de données supervisés de haute qualité. La constitution apprentissage étiquetés nécessite des processus d'annotation, des experts du domaine et des pipelines de validation de la qualité. Dans la pratique, cela représente souvent la partie la plus coûteuse des projets de réglage fin.
RAG contourne cette contrainte en permettant aux modèles de fonctionner directement sur des corpus de documents existants, sans avoir à constituer jeux de données vastes jeux de données étiquetés.
- Lorsque les exigences en matière gouvernance de localisation des données sont strictes
Une fois que les informations sensibles sont Embarqué les paramètres du modèle, leur suppression et leur vérification deviennent difficiles. Supprimer un enregistrement spécifique enregistrement modèle optimisé nécessite souvent un réentraînement ou la gestion jeu de données complexe jeu de données .
Les architectures RAG contournent ce problème en conservant les informations sensibles dans des systèmes de stockage externes où gouvernance standard sont déjà en place.
- Lorsque requête est modéré
Comme le montre l'analyse des coûts présentée précédemment, les frais généraux liés à l'extension du contexte augmentent avec requête , pour atteindre environ 43 750 dollars par mois à partir de 50 millions de requêtes. À un niveau de trafic modéré, les coûts par requête du RAG sont généralement inférieurs aux dépenses amorties liées au réglage fin, qui incluent apprentissage la maintenance continue. Cela fait du RAG un choix intéressant pour les organisations qui souhaitent obtenir des résultats de haute qualité sans avoir à investir massivement dès le départ dans l'infrastructure et la puissance de calcul.
Cas d’usage
Des exemples à grande échelle démontrent l'efficacité du RAG à ce niveau. L'assistant de questions-réponses de Notion est en réalité un système RAG à grande échelle sur les données de l’espace de travail. La difficulté technique ne résidait pas dans la recherche elle-même, mais dans l’application des contrôles d’identité et d’accès pendant la recherche. Lorsqu’un utilisateur l’assistant, le système doit s’assurer que le modèle ne récupère que les documents que utilisateur autorisé à consulter.
LinkedIn a exploité les techniques RAG et les graphes de connaissances pour préserver la structure de ses support . Ce système a extrait des sous-graphes pertinents plutôt que des fragments de texte isolés, améliorant ainsi la précision de la recherche de 77,6 % et réduisant le temps médian de résolution des problèmes de 28,6 %.
Pour les systèmes de cette envergure, la méthode RAG allie rentabilité et flexibilité, permettant ainsi aux équipes de mettre à jour rapidement les sources de connaissances sans avoir à réentraîner les modèles, tout en continuant à fournir des résultats de grande qualité.
Quand le peaufinage fait la différence
L'ajustement fin présente des avantages structurels dans différentes conditions. Ces conditions concernent généralement l'échelle, la stabilité et la précision comportementale.
- Lorsque requête dépasse les 100 millions par mois
Lorsque le trafic est très important (plus de 100 millions de requêtes par mois), la surcharge contextuelle par requête de RAG devient significative. Chaque requête des centaines de tokens récupérés que le modèle doit traiter, ce qui entraîne une augmentation linéaire des coûts proportionnelle au trafic. De grandes fenêtres contextuelles peuvent également accroître la latence, réduire le débit et nuire à la fiabilité de l'infrastructure.
Si les connaissances métier sont relativement stables, le réglage fin peut s'avérer plus efficace. En intégrant directement ces connaissances dans le modèle, les organisations évitent les coûts liés aux requêtes répétées et au traitement des tokens, ce qui se traduit parrequête plus prévisibles, cohérence meilleure cohérence et des opérations simplifiées à grande échelle.
- Lorsque la structure de sortie est cruciale
Les modèles finement ajustés excellent souvent dans les tâches qui exigent un respect rigoureux de la structure ou des contraintes formelles. Par exemple, Cosine, un assistant d’ingénierie logicielle basé sur l’IA capable de résoudre des bugs et de développer des fonctionnalités de manière autonome, a atteint un score SOTA de 43,8 % sur le benchmark vérifié SWE-bench.
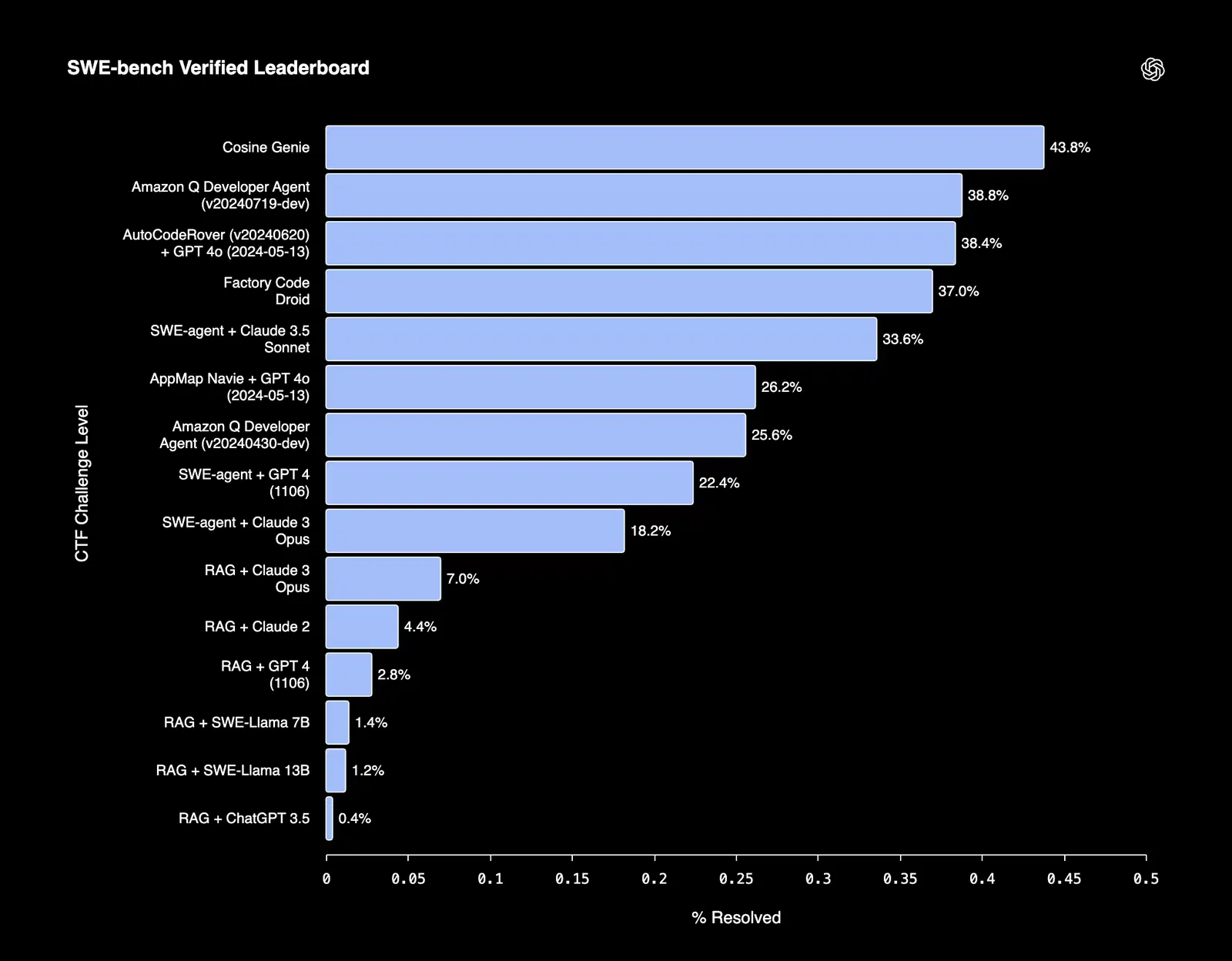
Figure 3 : Classement SWE-bench
De même, Distyl s'est hissé en tête du classement BIRD-SQL, largement considéré comme la référence en matière d'évaluation des performances de conversion de texte en SQL. Son modèle GPT-4o optimisé a atteint un taux de précision d'exécution de 71,83 % dans le classement.
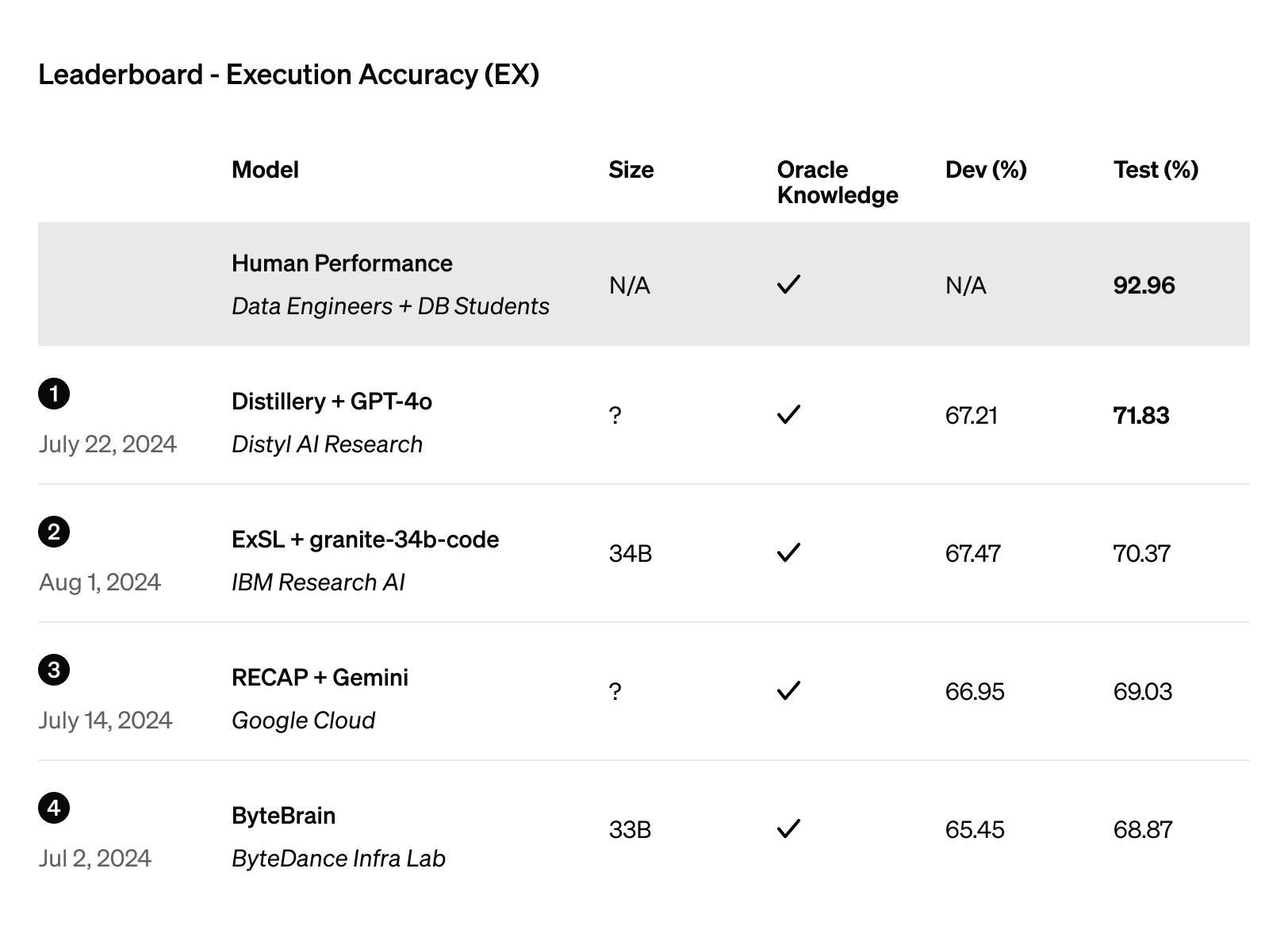
Figure 4 : Classement de la précision d'exécution
Dans les applications où les erreurs se répercutent en aval, que ce soit dans les calculs financiers, les API automatisées ou les documents de conformité, cohérence comportementale cohérence indispensable. Dans ces contextes, le réglage fin offre la fiabilité nécessaire pour minimiser les risques et préserver la confiance dans les résultats automatisés.
- Lorsque les exigences en matière de latence sont strictes
RAG ajoute plusieurs étapes au pipeline d'inférence, ce qui allonge le temps de réponse. Chaque requête passer par la génération d'embeddings, la recherche vectorielle et l'injection de contexte avant d'atteindre le modèle.
Les modèles finement ajustés font l'impasse sur la phase de recherche. Toutes les connaissances et tous les schémas de raisonnement nécessaires sont intégrés, ce qui permet au modèle de générer des résultats instantanément. Dans les applications où des temps de réponse inférieurs à 100 ms sont requis, comme les moteurs de recommandation en temps réel ou les systèmes de trading à haute fréquence, la suppression de la chaîne de recherche élimine un goulot d'étranglement majeur.
- Quand la profondeur de l'analyse d'un domaine prime sur l'actualité
Une étude comparative spécifique au secteur agricole a révélé que le réglage fin a amélioré la précision du modèle de 75 % à 81 %, tandis que les systèmes hybrides (ajustement fin + extraction) ont atteint 86 %. Le jeu de données sur des connaissances agricoles spécialisées et des tâches de raisonnement, cette amélioration reflète principalement un raisonnement plus solide dans le domaine, et non simplement un meilleur accès à des informations externes.
Dans des domaines tels que l'analyse juridique ou support la décision médicale, les schémas de raisonnement peuvent être complexes. L'affinage permet aux modèles d'intégrer l'expertise du domaine plutôt que de se fonder uniquement sur le contexte extrait.
L'approche hybride
Si le RAG et le fine-tuning présentent chacun des avantages évidents, les recherches montrent que leur combinaison efficace peut donner des résultats supérieurs, mais uniquement lorsqu’elle est mise en œuvre correctement. L’approche RAFT (Retrieval Augmented Fine-Tuning), développée par l’Université de Berkeley, Microsoft et Meta Research, montre comment y parvenir dans la pratique.
RAFT forme un modèle à fonctionner en mode « à livre ouvert ». Il apprend à traiter le contexte extrait, à identifier les passages pertinents, à ignorer les éléments perturbateurs et à citer les sources avec précision. Sans cet apprentissage explicite, le simple fait de superposer RAG à un modèle finement ajusté échoue souvent. Par exemple, un modèle ajusté pour le raisonnement médical peut extraire des articles de revues non pertinents s’il n’a pas appris à filtrer et à hiérarchiser le contexte, ce qui entraîne des hallucinations ou des recommandations erronées.
RAFT répond à ce problème grâce à une apprentissage structurée de apprentissage selon la règle des 80/20. 80 % apprentissage incluent des documents Oracle que le modèle doit utiliser, tandis que 20 % n'en contiennent pas, ce qui oblige le modèle à apprendre quand faire confiance aux données récupérées et quand s'appuyer sur ses connaissances internalisées. Ce détail opérationnel est crucial pour les ingénieurs qui évaluent si leur équipe est en mesure de mettre en œuvre une approche hybride avec succès. Il ne suffit pas de simplement combiner RAG et le fine-tuning. Le modèle doit être entraîné à raisonner sur le contexte récupéré.
Une approche courante et pratique consiste à utiliser «optimiser le format, et le RAG pour les connaissances ». L'optimisation fine façonne le comportement interne du modèle, en imposant un raisonnement spécifique au domaine, une structure de sortie et un style. Le RAG offre un accès dynamique à des informations externes qui changent fréquemment ou qui sont trop volumineuses pour être stockées dans les poids du modèle. Dans le domaine de la santé, par exemple, le réglage fin garantit que le modèle comprend la terminologie médicale, suit un raisonnement diagnostique approprié et formate les résultats conformément aux normes de documentation clinique. Le RAG complète cela en récupérant les dernières recherches, les directives thérapeutiques récemment publiées ou les dossiers spécifiques aux patients, ce qui permet de maintenir les recommandations à jour sans avoir à réentraîner l'ensemble du modèle.
De même, Harvey AI a été affiné sur 10 milliards de tokens de jurisprudence, mais s'appuie toujours sur le RAG pour traiter les affaires en cours et les mises à jour. Ce modèle est également largement utilisé dans d'autres domaines. Les systèmes juridiquesoptimiser le raisonnement juridique et le style de citation, puis intègrent le RAG pour récupérer la jurisprudence la plus récente ; les modèles financiersoptimiser les règles d'analyse de portefeuille, puis intègrent le RAG pour les mises à jour du marché et les changements réglementaires. C'est un moyen d'équilibrer la stabilité du comportement appris et l'adaptabilité de la recherche d'informations.
Un cadre décisionnel quantifié pour comparer RAG et le réglage fin
La question n'est plus « Quelle approche est la meilleure ? », mais « Dans quelles conditions chaque approche est-elle judicieuse sur le plan économique et opérationnel ? »
Au lieu de vous en remettre systématiquement à vos préférences architecturales, évaluez trois variables mesurables :
- Fréquence des changements de connaissances.
- requête mensuel requête .
- Capacités en matière d'infrastructures et gouvernance .
Une fois ces variables quantifiées, la décision devient beaucoup plus claire.
Étape 1 : Mesurer la volatilité des connaissances
La fréquence d'évolution des connaissances est souvent le moyen le plus rapide d'écarter une option. Si vos connaissances dans le domaine évoluent chaque semaine ou chaque jour, l'approche RAG est structurellement privilégiée. La mise à jour d'un index est bien plus simple que le réentraînement d'un modèle finement ajusté. La séparation entre les poids du modèle et les données externes permet récupération des données en temps réel récupération des données cycles de redéploiement.
Si les connaissances restent stables pendant plusieurs mois d'affilée, l'ajustement fin devient économiquement viable. La fréquence des réentraînements diminue, et apprentissage peuvent être amortis sur des périodes plus longues. Dans ces contextes, l'intégration directe de connaissances spécifiques au domaine dans les paramètres du modèle peut réduire la charge de travail liée à l'inférence à long terme.
À titre de seuil pratique :
- Les connaissances évoluent plus souvent qu'une fois par mois → donner la priorité au RAG.
- Les connaissances restent stables depuis plusieurs mois → envisager un ajustement.
Étape 2 : Calculer le coût d'extension du contexte
La variable suivante est requête . Les systèmes RAG à grande échelle ajoutent des centaines de tokens à chaque requête, et cette surcharge contextuelle augmente proportionnellement au trafic.
Critères quantitatifs
| Requêtes mensuelles | Conseils |
| <10M | Le RAG est moins cher |
| 10 à 50 millions | Comparer le réglage fin et la méthode RAG |
| 50 à 100 millions | Réglage fin ou hybride |
| >100M | Réglage fin ou hybride |
Étape 3 : Évaluer la maturité de l'infrastructure
Même si les considérations économiques penchent en faveur d'une approche, ce sont les capacités infrastructurelles qui peuvent déterminer la faisabilité.
RAG exige :
- Une ingénierie des données solide.
- Des pipelines de données fiables.
- Architecture efficace de base de données vectorielle.
- observabilité surveillance.
Le réglage fin nécessite :
- Des données étiquetées de haute qualité.
- Expertise en apprentissage automatique.
- Allocation des ressources informatiques.
- Discipline d'évaluation.
Lorsque les équipes négligent leurs Fonctionnalités réelles, les choix architecturaux s'effondrent face à l'augmentation de l'échelle. De nombreuses défaillances en production attribuées à la « qualité du modèle » ne sont en réalité que les conséquences d'une infrastructure immature.
Matrice de décision
Le tableau ci-dessous traduit cette analyse en conseils pratiques.
| Scénario | Requêtes mensuelles | Fréquence de mise à jour des connaissances | Recommandation | Justification |
| Mise à jour hebdomadaire des connaissances métier, trafic modéré | 10 à 50 millions | Hebdomadaire/Quotidien | RAG | Indexation immédiate et faibles coûts récurrents |
| Trafic intense, base de données stable | 50 à 100 millions et plus | <1 update/month | Réglage fin | Évite les injections de contexte répétitives et réduit la latence |
| Sortie structurée ou génération de code requise | N'importe quel | N'importe quel | Réglage fin | Intègre en interne des règles et des formats spécifiques au domaine |
| Raisonnement spécialisé + mises à jour fréquentes | 10 à 50 millions | Hebdomadaire/Quotidien | Hybride | Allie un raisonnement interne à des connaissances dynamiques |
| Systèmes multidomaines avec des cycles de mise à jour des connaissances variés | 10 à 100 millions | Mixte | Hybride | Le réglage fin stabilise les domaines principaux, tandis que le RAG gère les sources en constante évolution |
Grâce à cette matrice, il est plus facile de décider s'il vaut mieux recourir à la méthode RAG,optimiser modèles de langage grand format (LLM) ou opter pour une approche hybride.
Réflexions finales
Le débat entre le RAG et le réglage fin est souvent présenté comme un choix binaire, mais la question la plus pertinente est la suivante : « Si les systèmes hybrides s'avèrent nettement plus performants que l'une ou l'autre de ces approches prises isolément, pourquoi le secteur continue-t-il de privilégier massivement le RAG ? »
L'approche hybride nécessite Fonctionnalités en apprentissage automatique et en ingénierie des données, une combinaison que peu d'organisations possèdent. Le RAG reste la solution par défaut la plus pratique, offrant agilité et transparence tout en réduisant la complexité initiale.
Le point essentiel à retenir est de choisir l'architecture qui correspond à la volatilité de vos données, requête et aux capacités de votre équipe. Pour les équipes qui envisagent de mettre en place des systèmes de recherche à l'échelle de l'entreprise, plateformes Actian VectorAI DB offrent Fonctionnalités de base de données vectorielle spécialement conçues Fonctionnalités performances et évolutivité.
Rejoignez la communauté Discord et découvrez comment Actian s'intègre à votre stratégie en matière d'IA.

Restez connecté
Des informations tirées des données, à votre service.
(par exemple : sales@..., support)