What 37signals’ Cloud Repatriation Taught Us About AI Infrastructure





Summary
- Cloud repatriation can cut costs by millions at scale.
- AI workloads amplify savings due to GPU and storage costs.
- On-prem or hybrid suits predictable, high-volume inference.
- Cloud still fits burst workloads like model training.
- Hybrid strategies balance cost, performance, and compliance.
In 2023, 37signals announced that it had completely left the public cloud and followed up by publicly documenting its cloud repatriation process, providing one of the clearest real-world examples of on-premises economics at scale. By reversing its cloud migration and shifting workloads to private cloud infrastructure, the company drastically reduced its annual cloud infrastructure spend by almost $2 million.
The transparency of the numbers made the case compelling. In 2022, 37signals spent $3,201,564 on cloud services, which is about $266,797 per month. These detailed cost breakdowns, along with published hardware investment and payback timelines, provided a rare look into the financial mechanics of large-scale cloud repatriation.
For commodity SaaS workloads, the math was clear. But the same logic raises an important question for the next generation of compute-heavy systems: “Does the economic argument extend to AI infrastructure as well?” In this article, we examine whether the same economic logic holds for AI infrastructure.
TL;DR
- 37signals spent ~$3.2M/year on AWS in 2022.
- After repatriating workloads to their own infrastructure, cloud spend dropped to ~$1.3M by 2024.
- The company invested roughly $700K–$800K in servers and paid them off in under 18 months.
- The entire infrastructure is still run by the same 10-person team. No additional operational overhead.
- The key takeaway is that at a sustained scale, owning infrastructure can be dramatically cheaper than renting it.
The 37signals Playbook: What Hanson Actually Documented
In 2022, 37signals spent $3.2 million annually on AWS. After leaving the cloud in 2023, their annual costs had dropped to approximately $1.3 million by 2024, a reduction of almost $2 million per year.
The transition required a hardware investment of roughly $600,000 in Dell servers. The company fully recouped the investment in under 18 months, achieving complete payback in the second half of 2023 as their AWS reserved instance contracts expired. From that point forward, the savings flowed directly to operating margin rather than offsetting capital expense.
37signals projected $1.5 million in hardware costs and roughly $200,000 per year in operating expenses. This shift replaces a recurring $1.3 million annual cloud storage bill with a one-time capital outlay plus a fraction of the ongoing operating cost. Over five years, 37signals revised the total savings projections upward from $7 million to more than $10 million.
37signals cloud exit financials by year
To illustrate the financial impact of 37signals’ cloud exit over time, the table below breaks down annual cloud spending, on-premises hardware investments, and operating costs, highlighting the resulting net savings and key operational notes.
| Year | Cloud spend | Hardware investment | Operating costs | Notes |
| 2022 Baseline | ~$3.2M | $0 | Included in cloud spend | Full cloud dependency |
| 2023 Migration | ~$2M | ~$700–800K | Moderate | Hardware fully recouped in under 18 months |
| 2024+ Post-repatriation | ~$1.3M | ~$1.5M (storage) | ~$200K/year | ~$1.9M annual savings |
| 2025+ | Minimal AWS dependency | ~$1.5M (Pure Storage, 18PB) | ~$200K/year | $10M+ projected 5-year savings |
Notably, the migration did not require the team to expand operations. A 10-person infrastructure team handled the entire repatriation without adding new staff. Addressing a common concern about operational overhead, 37signals co-founder David Heinemeier Hansson noted:
We’ve been out for just over a year now, and the team managing everything is still the same. There were no hidden dragons of additional workload associated with the exit that required us to balloon the team, as some spectators speculated when we announced it. All the answers in our Big Cloud Exit FAQ continue to hold.
This directly challenges the common assumption that moving away from public cloud environments inevitably requires a significantly larger infrastructure team.
Execution followed a “criticality ladder” strategy where the team migrated lower-risk services first and more critical ones later. The team moved the HEY email system in stages, starting with caching, then database, and finally, job services. To minimize risk, they colocated infrastructure approximately one millisecond from the AWS region to preserve rollback capability during the cloud repatriation process. After stabilizing the system, they replaced managed services with substantial recurring costs, including RDS and managed Elasticsearch, which exceeded $500,000 together annually.
What makes 37signals’ case study consequential is the publicly documented cost efficiency. For organizations questioning long-term cloud adoption assumptions, particularly with regard to storage costs and managed services, the 37signals documentation provides a rare baseline for comparison.
Why AI Infrastructure Economics are Even More Extreme
The lessons from 37signals’ cloud repatriation take on a sharper edge when applied to AI infrastructure. Higher GPU costs, predictable inference workloads, massive embedding storage, and stricter data regulations create financial and operational pressures that amplify the advantages of on-premises or hybrid cloud solutions that allow you to move workloads where they make the most sense. Below, we break down the key drivers.
AI infrastructure cost comparison
To evaluate the cost implications of different AI infrastructure approaches, the table below compares upfront setup costs, monthly operating expenses at varying workloads, and expected break-even timelines for cloud, on-premises, and hybrid configurations.
| Setup | Setup cost | Monthly cost | Break-even |
| Cloud GPU rental (AWS/ Azure) | $0 | $2,900–3,500 (8h/day × $4–8/hour × 15 days) | N/A |
| Cloud inference APIs (Lambda Labs) | $0 | $1,800–2,500 (8h/day × $3.67/hour × 15 days) | N/A |
| Self-hosted GPU (8×H100 server) | $200K–400K | $1,500–2,000 (power + maintenance) | <12 months |
| Hybrid (Cloud training + On-Prem) | $200K–400K | Training only, inference minimal | <12 months |
Note: For cloud GPU rental, we estimate monthly cost assuming eight hours/day per GPU. The cost scales linearly with utilization; it is not directly per-query.
- GPU cloud markups are high
AI workloads depend heavily on GPUs, and cloud providers charge far steeper premiums for GPU capacity than for typical CPU compute. On-demand AWS P5 instances with H100 GPUs cost roughly $4–8 per GPU-hour, while comparable Azure H100 instances are about $3.67 per hour. By contrast, spot markets and alternative providers such as Lambda Labs offer similar GPU capacity for $1–2 per hour, or $1.85–2.49 per hour with reserved commitments.
The result is a 4–8× markup for on-demand hyperscaler GPU capacity relative to the spot or specialized GPU cloud market. In other words, the premium cloud providers charge for high-end AI compute is significantly larger than typical CPU cloud markups. For organizations running sustained inference workloads, this pricing gap quickly becomes the dominant cost driver in AI infrastructure.
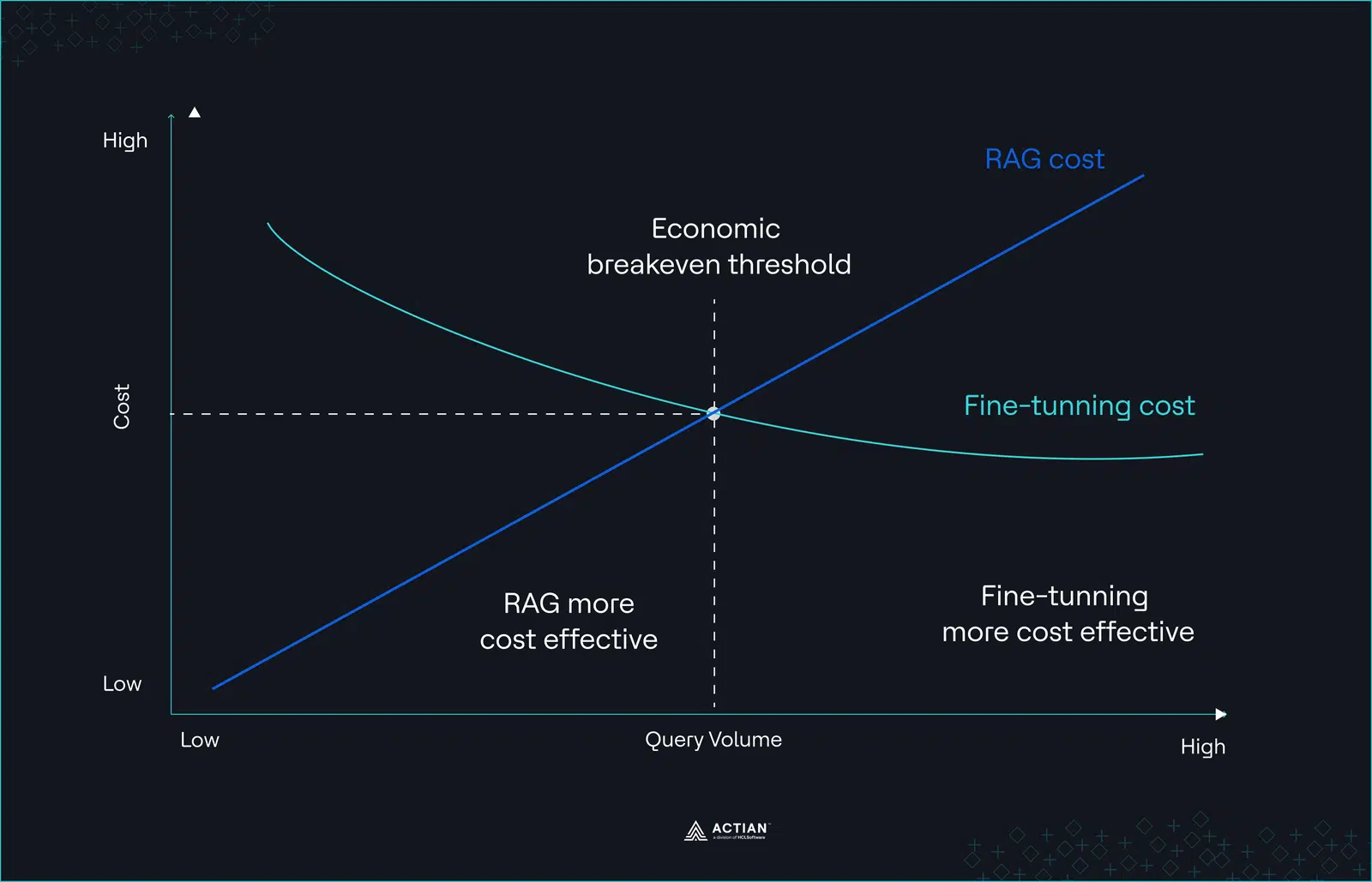
- Predictable inference makes GPU ownership economical
High GPU pricing becomes especially significant because AI inference workloads are unusually predictable. Purchasing H100 GPUs outright can be cost-efficient. A single GPU costs roughly $25K–40K, while a complete 8×H100 server ranges from $200K–400K. Lenovo’s analysis shows that six or more hours of sustained daily usage reaches payback against AWS within the first year.
The reason this break-even arrives so quickly is that AI inference workloads are unusually predictable. Unlike SaaS traffic which fluctuates throughout the day, production AI systems such as recommendation engines tend to process steady volumes of requests.
Predictability changes the economics. When infrastructure runs at consistent utilization, owned hardware can be amortized efficiently across the workload. Paying cloud premiums for burst capacity that teams rarely use becomes unnecessary.
For organizations running inference continuously, the hardware investment is often recouped in under 12 months. From that point forward, the savings resemble the same pattern documented by 37signals. Fixed infrastructure replacing an ongoing rental bill.
- Embedding storage requirements are massive
Even if GPU compute were optimized, AI systems introduce another rapidly growing cost layer: embedding storage. Vector databases store high-dimensional embeddings used for search, retrieval, and recommendation. As datasets scale into millions or billions of records, storage requirements expand quickly.
For instance, 10 million vectors at 1,536 dimensions require at least 58GB of raw storage, often 200–300GB with indexes and metadata. Cloud storage services like Pinecone charge $0.33/GB/month, meaning 500GB could cost $165/month before any queries. Self-hosted solutions like PostgreSQL with pgvector dramatically reduce cloud spending while keeping sensitive data under direct control. Over time, these storage requirements compound infrastructure costs alongside GPU compute, further reinforcing the economic advantages of self-hosted or hybrid architectures.
- Data sovereignty and compliance favor on-premises deployment
Data residency regulations and general compliance are priorities in the AI space with the industry becoming increasingly regulated. Notably, the EU AI Act introduced strict regulations for AI systems, with prohibitions on certain AI use cases which took effect in February 2025. On-premises deployment simplifies compliance.
For financial organizations navigating complex regulatory environments, solutions like the Actian Data Intelligence Platform helps enforce data governance and streamline compliance workflows.
The Cloud Infrastructure Case Studies 37signals Validated
As much as the financial transparency of 37signals’ cloud exit was radical, their repatriation was not an isolated occurrence. It was part of a growing trend by many organizations trying to regain cost control and optimize their cloud infrastructure. Many high-profile case studies illustrate the scale and economics of moving workloads back from public clouds to owned or hybrid infrastructure.
Dropbox
Dropbox pioneered enterprise cloud repatriation as early as 2015, completing the migration between 2016 and 2018. The company moved roughly 90% of customer data, reportedly over 500 petabytes, off AWS to three owned colocation facilities. The infrastructure investment totaled $53 million, yet Dropbox reported $74.6 million in operational savings over two years per its 2018 S‑1 filing. A small portion of workloads, primarily European customers and specialized services, remain in AWS. Internally, the initiative was known as “Magic Pocket,” and it exemplifies how a well-executed hybrid cloud approach can deliver substantial savings while aligning with long-term business objectives.
Ahrefs
Ahrefs, the SEO tools company, relied on a Singapore colocation setup with 850 servers. Their reported savings from avoiding public cloud were approximately $400 million over 2.5 years. Actual infrastructure cost: $39.5 million for 850 servers (~$1,500/server/month), versus an estimated $447.7 million if hosted entirely on AWS (~$17,557/server/month equivalent). As Ahrefs put it: “We wouldn’t be profitable, or even exist, if our products were 100% on AWS.” While critics argue that Ahrefs inflated AWS estimates, the directional savings were undeniable, illustrating that cloud repatriation challenges can be surmounted at scale with careful planning.
GEICO
GEICO spent a decade migrating to multiple cloud providers only for its costs to climb and exceed projections by 2.5×, reaching $300 million by 2022 across eight providers. In response, GEICO began moving workloads to a private cloud using OpenStack and Kubernetes, targeting over 50% repatriation by 2029. Early results show 50% reductions in compute and 60% reduction per gigabyte of storage costs compared with public cloud services, demonstrating how a hybrid cloud architecture can deliver efficiency, compliance, and alignment with long-term business objectives.
Akamai
Akamai was on the path to spending over $100 million on third-party cloud services before migrating compute workloads to its own global edge network of 350,000+ servers. The migration delivered savings of roughly $100 million per year, a testament to the economics of repatriation when existing infrastructure and scale align.
What these cases share is the same economic pattern documented by 37signals. Predictable, high-volume workloads eventually become cheaper to run on owned infrastructure than on hyperscaler clouds.
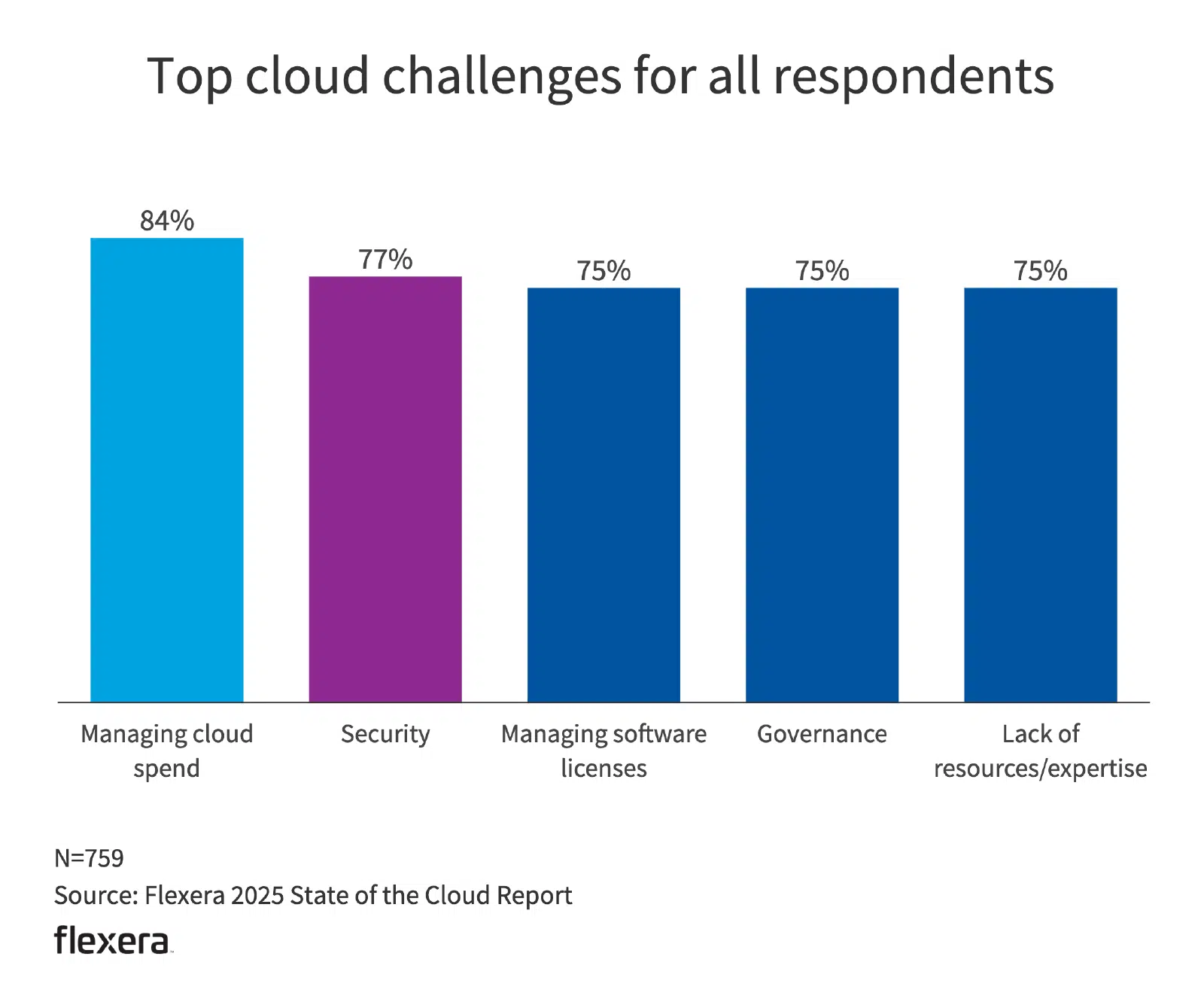
These examples reflect a broader shift occurring across enterprise infrastructure strategies. Barclays’ Chief Information Officers (CIO) surveys show cloud repatriation trending upward in recent years, with the sentiment peaking in the second half of 2024 with 86% of CIOs planning repatriation.
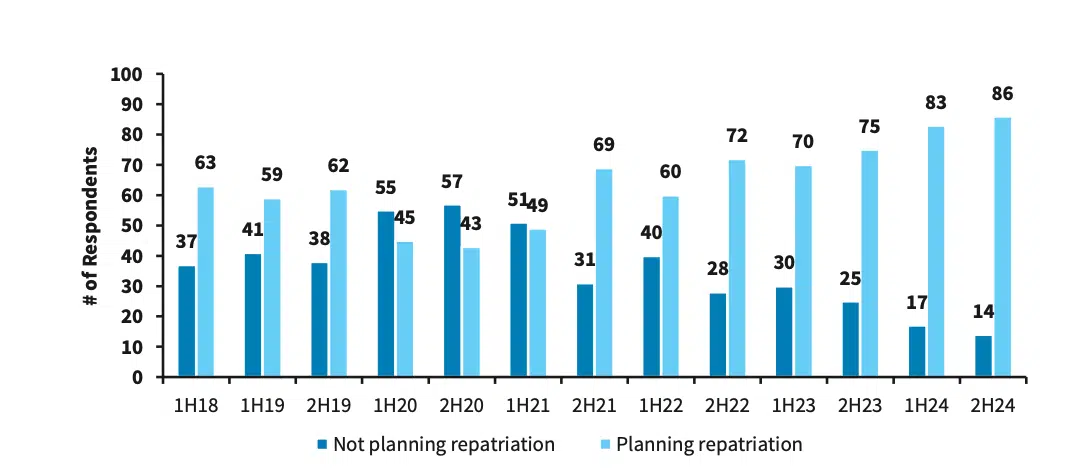
Barclay’s CIO survey showing 86% of CIOs planning cloud repatriation
However, this statistic does not mean that companies are abandoning public cloud environments completely. According to IDC, only 8–9% of companies favor full repatriation with most preferring a hybrid approach that combines public and private clouds. Hybrid cloud infrastructure allows organizations to optimize workload placement by strategically allocating sensitive data and mission-critical applications on-premises while leveraging public cloud services for less critical workloads. As such, it has become increasingly important for teams exploring similar transitions to understand the nuances of hybrid deployments and their associated risks.
Cloud Repatriation Statistics
Cloud repatriation is accelerating at the same time as public cloud spending keeps climbing. IDC projects global public cloud spend will reach $1.6 trillion in 2028, doubling from their 2024 prediction. Yet as mentioned earlier, 86% of CIOs are planning some form of repatriation according to Barclays. Both trends can be true because this is not a cloud exodus so much as a rebalancing. Enterprises are leaning towards a hybrid cloud model.
AI is likely to accelerate that shift. AI workloads account for less than 10% of total cloud compute today but Gartner projects that this figure will approach 50% by 2029. Hyperscalers are responding with enormous capital investment. There is an estimated $600 billion in infrastructure spend in 2026, roughly three-quarters of it tied to AI. The assumption is clear: Enterprises will rent that GPU capacity. But the 37signals math suggests that once AI workloads move from experimentation to steady production, ownership economics begin to dominate.
Cost pressure is already driving behavior. Flexera reports that 27% of cloud resources are wasted or underutilized, and 21% of workloads have already been repatriated. The primary reason cited is cost exceeding projections, followed by performance concerns. With GPUs, the margin for inefficiency is thinner. There are fewer optimization levers, higher hourly rates, and faster budget burn.
Regulation adds another layer. The EU AI Act, DORA for financial services, China’s PIPL, and India’s DPDP are tightening data governance requirements. Mimecast reports that 87% of organizations now factor data sovereignty into vendor decisions. For AI systems, sovereignty extends beyond data location to model provenance, audit trails, and compliance documentation. On-premises deployment does not eliminate regulatory complexity, but it centralizes control, and for many enterprises, that simplicity is becoming strategically attractive.
A bar chart showing why enterprises repatriate
The Counter-Arguments and When Cloud Providers Win
Not all observers agree that cloud repatriation is the best path for every organization. Public cloud environments still deliver value in certain circumstances. But arguments often do not hold strong in the case of AI workloads.
When cloud wins vs. when on-premises wins
| Component | Cloud advantage | On-prem advantage |
| Workload predictability | Handles spiky or unpredictable workloads | Predictable workloads cheaper to self-host |
| Team expertise | Requires minimal in-house infrastructure skill | Strong IT teams can optimize and reduce vendor reliance |
| Scale and growth | Rapid scaling and global expansion | Predictable growth enables cost-efficient hardware |
| Regulatory requirements | Managed compliance, geo-redundancy | Direct control simplifies regulatory alignment |
| Cost and margins | Pay-as-you-go reduces upfront spend | Long-term savings from owned infrastructure |
| Service quality | Cloud SLAs ensure availability and performance | Dedicated resources guarantee predictable uptime |
Cloud “wrong usage” argument
Jeremy Daly, a serverless advocate, argues that “37signals was using the cloud wrong.” By treating cloud environments as virtual colocation, running VMs and Kubernetes, they were paying cloud premiums without capturing the value of serverless, managed services, and instant scaling. As Daly notes, “In the cloud, we should be renting services, not servers.”
For SaaS workloads with highly variable or spiky traffic, this argument is compelling. Serverless infrastructure allows organizations to scale instantly and pay only for the compute they actually use.
However, AI inference workloads often behave very differently. Production inference systems, such as recommendation models, copilots, and document processing pipelines, tend to run at steady, sustained utilization rather than unpredictable bursts. In these cases, the economic advantage of elastic cloud scaling diminishes. The premium paid for burst capacity still exists, but the workload itself rarely needs that burst capacity.
Daly’s argument, therefore, holds for variable SaaS workloads, where elasticity is critical. For sustained AI inference workloads running at high utilization, paying a premium for burst capacity that is rarely used can make dedicated infrastructure or hybrid deployments more cost-efficient.
Full cost critique
Some critics also question the financial assumptions behind 37signals’ approach. They point out that hardware and software normally account for only about 20% of IT costs, with the remainder covering electricity, cooling, physical security, racking, Uninterruptible Power Supply (UPS), and opportunity costs. David Heinemeier Hanson’s analysis did not include all of these overheads because 37signals used colocation facilities rather than fully owned data centers. Even so, considering 37signals’ figures, it is reasonable to conclude that renting colocation space can still be far cheaper than relying on cloud services.
Competence vs. growth framework
Forrest Brazeal’s IT competence versus growth aspirations framework provides additional nuance. He places 37signals in the High Competence/Low Growth quadrant, ideal for self-hosting. “Not every company has the competence (high) or growth aspirations (low) of 37signals,” he observes. Startups with uncertain or spiky workloads benefit from cloud flexibility, but AI companies running production inference at scale often combine high operational competence with steady growth. Such profiles (steady growth & high competence) are well-suited to repatriation.
Applying the Playbook to AI Infrastructure
If 37signals provided the economic blueprint, AI infrastructure makes the economics more concrete. The decision is no longer abstract. It becomes a structured assessment grounded in workload behavior, utilization, and regulatory exposure.
A practical four-question framework helps translate the 37signals logic into AI terms:
1. Is your inference workload predictable and sustained?
Unlike SaaS traffic spikes, most production AI systems such as recommendation engines, RAG pipelines, or fraud detection models process steady volumes with gradual growth.
2. Are projected GPU utilization rates above 60–70%?
At this threshold, owned hardware amortization typically undercuts public cloud GPU pricing within the first year.
3. Are you processing more than 10–50 million queries per month?
At this scale, per-token and per-query pricing from cloud APIs compound rapidly.
4. Do you face data sovereignty or strict compliance requirements?
For financial services, healthcare, or government workloads, regulatory mandates can tilt the decision toward controlled environments.
If the answer is “yes” to three or four of these, the repatriation economics tend to favor on-premises deployment for production inference.
Decision matrix
| Workload stage | Recommended environment | Rationale |
| Model training | Public cloud | Compute-intensive; cloud GPUs handle burst workloads cost-effectively |
| Experimentation and prototyping | Public cloud | Flexible, fast provisioning for early-stage iteration |
| Production inference | On-premises / Hybrid | Steady workloads; owned hardware cheaper at 60–70%+ GPU utilization |
| Vector storage (embeddings) | On-premises | Reduces recurring managed-service costs and ensures data control |
The hybrid AI pattern
In practice, most AI organizations adopt a hybrid model rather than an all-or-nothing shift. Training remains in the cloud. Inference moves closer to owned infrastructure.
Lenovo documented that training Llama 3.1 at hyperscale (39.3 million GPU hours) in the cloud would exceed $483 million. That type of elastic, short-term scale is exactly where public cloud excels. Inference is different. Once a model is trained, serving it for three to five years becomes steady, predictable work. That is where amortized hardware economics has the upper hand.
This split architecture also simplifies data migration risk. Instead of relocating entire AI pipelines at once, organizations can migrate production inference workloads gradually while leaving experimentation and early-stage training in cloud environments. A controlled, phased migration process reduces operational disruption while ensuring seamless integration between cloud-based training and on-premises serving layers.
Self-hosted inference economics
The economics of self-hosted inference depend heavily on utilization and token volume. According to enterprise deployment benchmarks, a 7B-parameter model running on an H100 GPU at roughly 70% utilization costs about $10,000 per year in spot nodes or hardware amortization. Power costs about $300 annually, bringing the total costs to about $10,300.
Public LLM APIs, by contrast, typically charge per million tokens, with enterprise pricing in 2025 ranging from $0.25–$15 per million input tokens and $1.25–$75 per million output tokens depending on model tier and provider.
At low usage levels, APIs remain the more economical option because infrastructure sits idle. However, the economics change as workloads scale. Industry analyses suggest that self-hosted deployment begins to break even at roughly two million tokens per day, after which the fixed cost of owned infrastructure is amortized across a large inference volume.
At high volumes, self-hosted inference can reduce costs by up to 78%. Artefact’s analysis found break-even around 8,000 conversations per day. Below that threshold, managed cloud APIs remain more economical. Above it, ownership compounds savings. The pattern mirrors 37signals: predictable workload plus high utilization equals rapid payback.
Vector databases
Instacart documented migrating from Elasticsearch plus FAISS to PostgreSQL with pgvector, achieving 80% cost savings and a 10× reduction in write amplification. Timescale’s pgvectorscale benchmarks show approximately 75% lower costs than managed vector services like Pinecone at comparable performance.
For RAG systems handling millions of queries monthly, self-hosted vector infrastructure produces savings that resemble the 37signals S3 case: large recurring storage bills replaced by amortized hardware and open-source tooling.
Data sovereignty as a structural driver
Grandview research reports that the sovereign cloud market was worth 648.87 billion USD in 2025 and is projected to reach USD 648.87 billion by 2033. Also, according to Gartner, around 60% of financial firms outside the United States are expected to adopt sovereign or on-premises deployments by 2028.
Frameworks such as the EU AI Act, China’s PIPL, and India’s DPDP mandate data localization and traceability. For organizations processing sensitive training datasets or proprietary inference logs, on-premises deployment inherently satisfies residency requirements because data never leaves jurisdictional boundaries.
The Bottom Line
37signals showed that cloud repatriation teams can measure, model, and defend decisions with hard numbers. With AI infrastructure, the economics can be even more pronounced. If cloud repatriation saved roughly $10 million for Basecamp, an equivalent AI company running production inference at a comparable scale could save multiples of that amount, given the much higher cost of GPU compute and embedding infrastructure.
For organizations choosing to run AI workloads in controlled environments, platforms like Actian VectorAI DB provide a purpose-built vector database designed for high-volume vector search and AI inference workloads. It can be deployed on-premises or in the cloud, allowing organizations to place vector infrastructure where it best fits their operational and economic requirements.
Join the community and learn more about Actian.

Stay connected
Data insights delivered to you.
(i.e. sales@..., support@...)







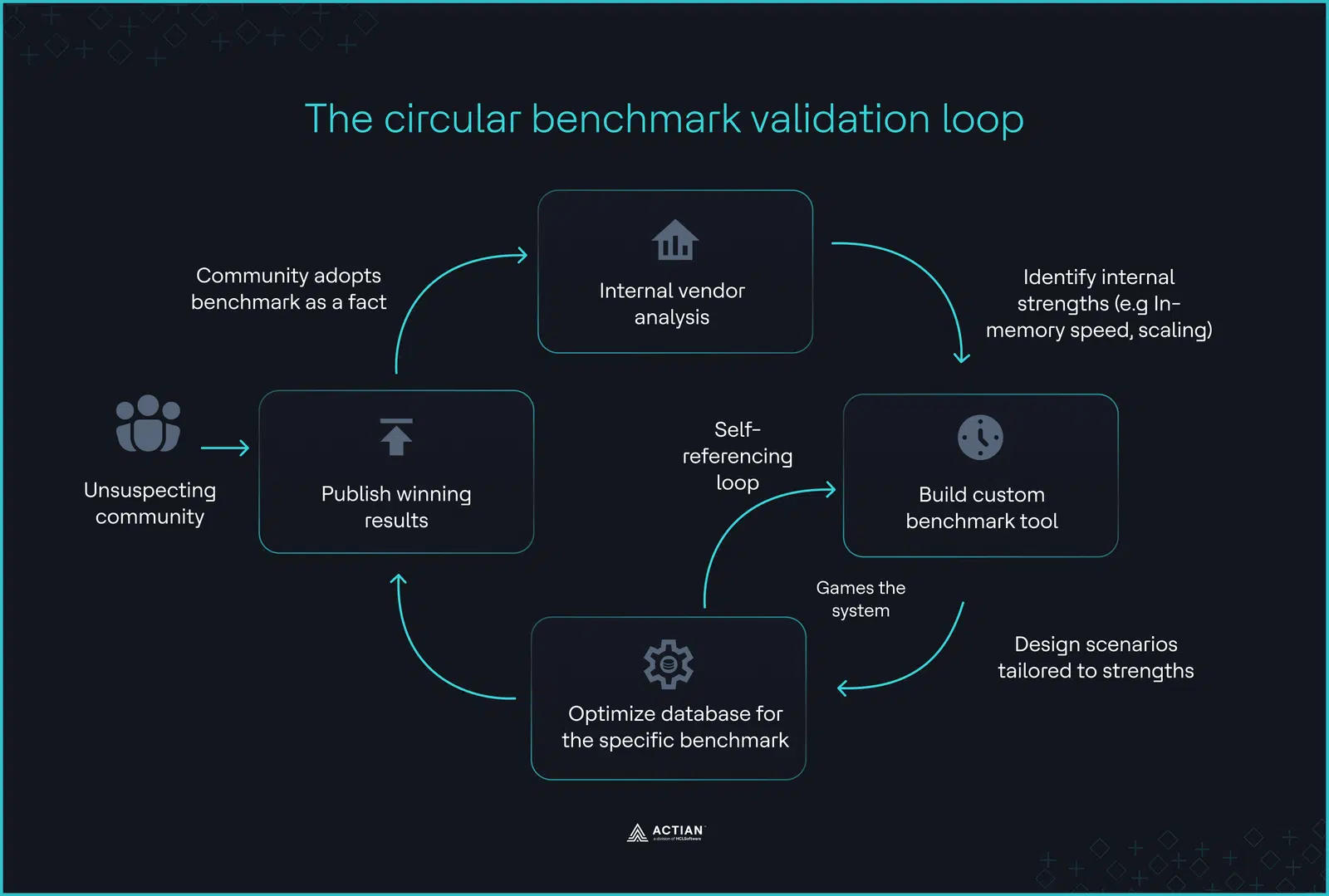
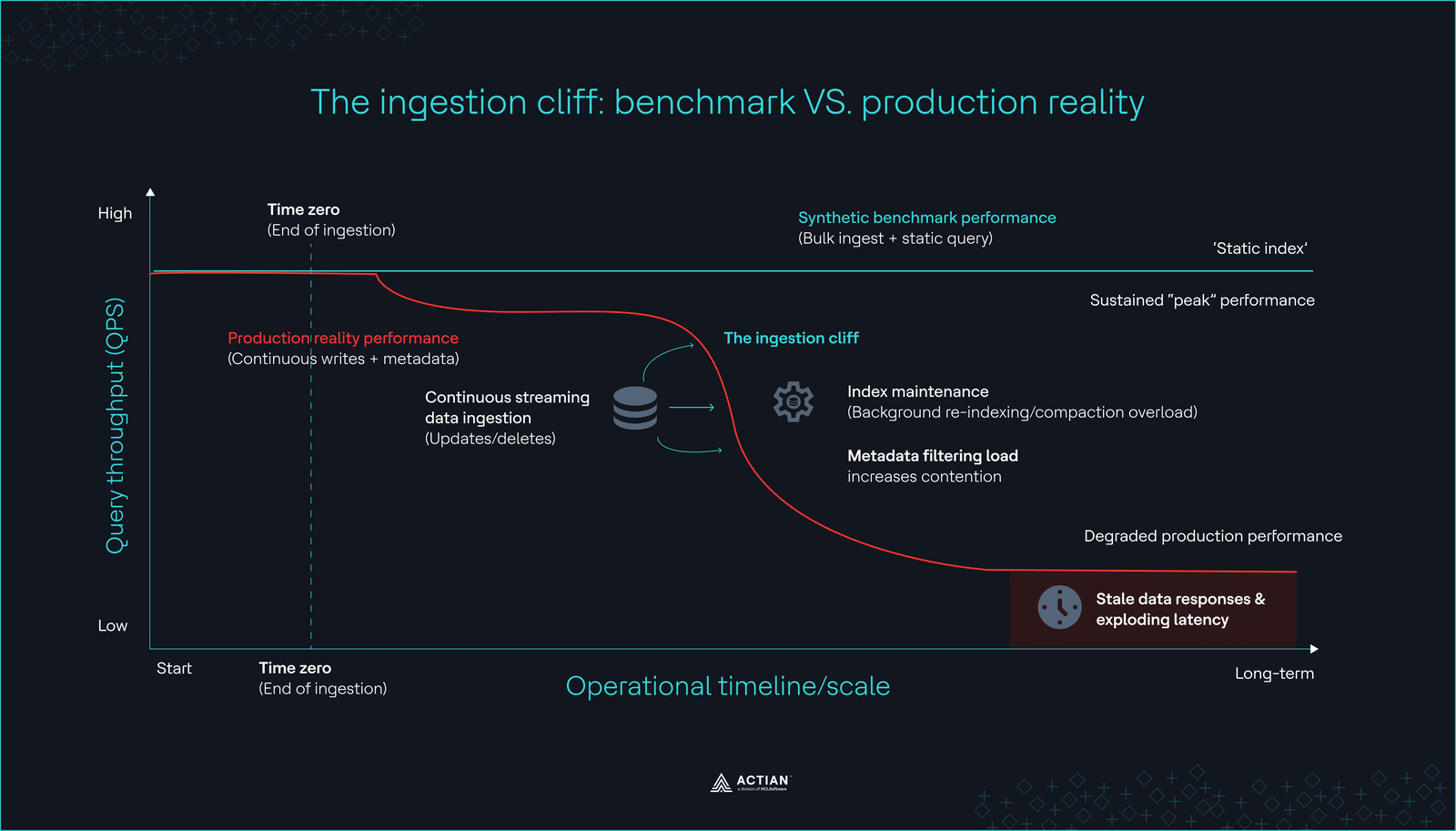 The ingestion cliff
The ingestion cliff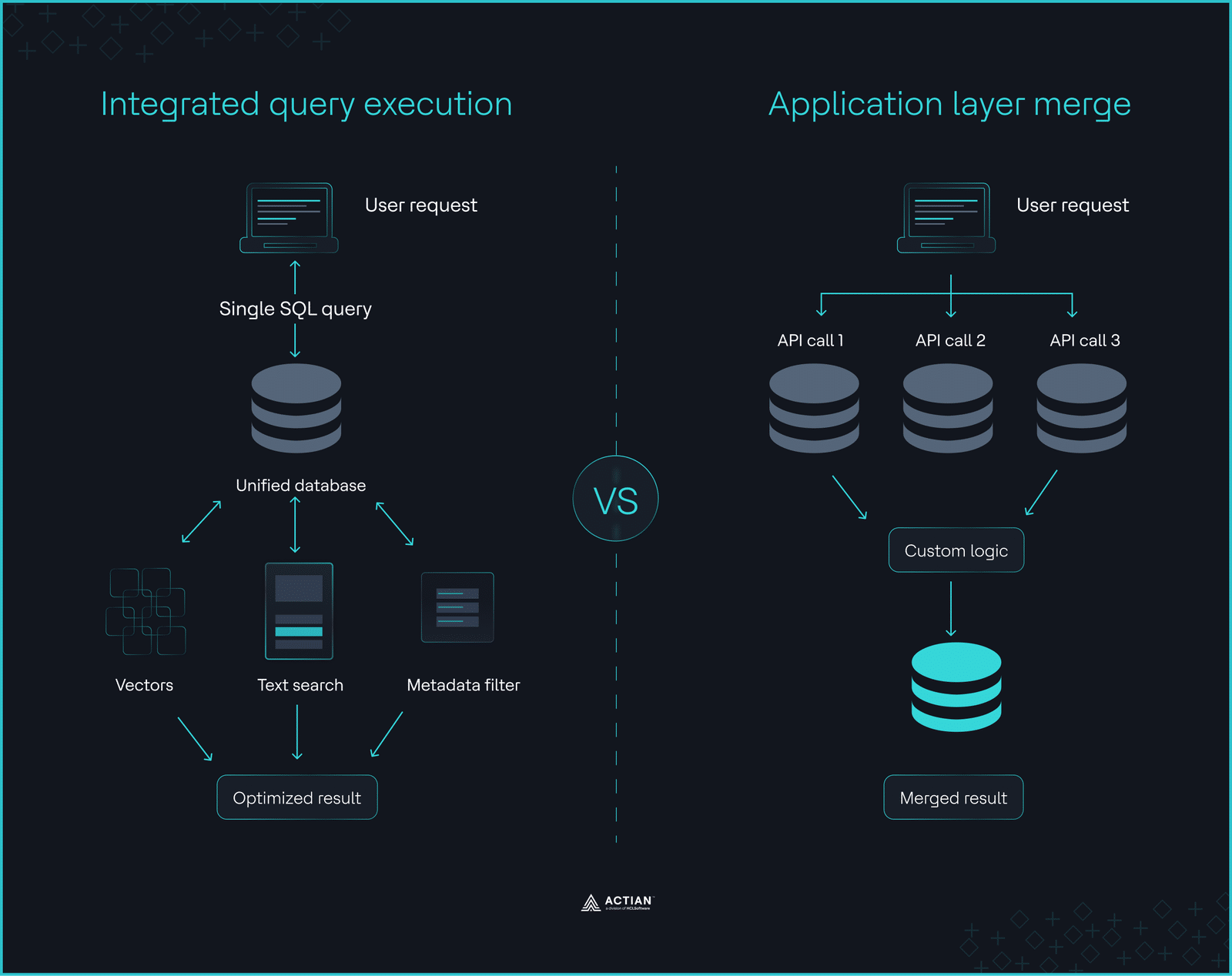 Integrated query execution vs. application layer merge
Integrated query execution vs. application layer merge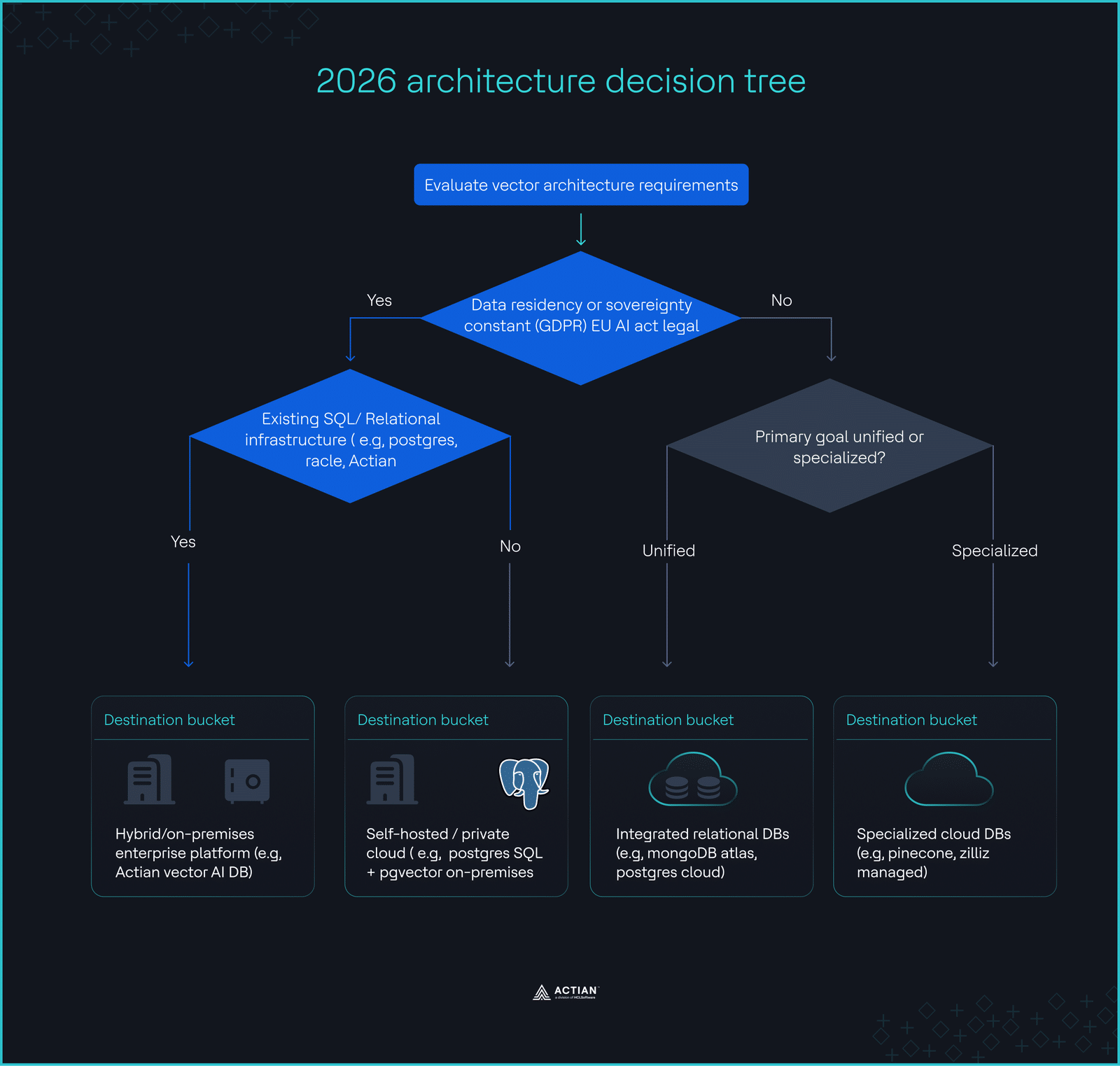 The 2026 architecture decision tree
The 2026 architecture decision tree