Les 5 meilleures bibliothèques Python pour les bases de données Python





Résumé
- Les problèmes de performance des bases de données vectorielles sont souvent dus à des incompatibilités au niveau des paquets logiciels, des API et de l'environnement, et non à la vitesse.
- L'architecture client (cloud, logiciels libres, Embarqué, extensions) a une incidence sur évolutivité déploiement .
- Facteurs clés : stabilité de l'API, fiabilité de l'installation, support de l'asynchronisme et clarté du débogage.
- Qdrant offre une grande similitude entre les environnements locaux et de production ; Pinecone simplifie l'utilisation du cloud.
- La base de données Actian VectorAI met l'accent sur la stabilité, la portabilité et déploiement adapté aux entreprises.
La plupart des comparaisons entre les bibliothèques de bases de données Python se concentrent sur la vitesse de recherche, les algorithmes d'indexation ou les résultats des tests de performance. Ces indicateurs ont certes leur importance, mais les défaillances en production découlent de divers facteurs : incohérences d'installation, différences entre les versions des paquets clients, rotation des versions et modifications inattendues de l'API. En réalité, une autre catégorie de problèmes apparaît dès que l'application quitte l'environnement du notebook pour s'exécuter au sein d'un service de production.
Les configurations Embarqué en sont un exemple typique. Un projet peut fonctionner parfaitement pendant la phase de développement, mais échouer en production avec une erreur telle que :
RuntimeError: Chroma running in http-only client modeUn conflit structurel entre le chromadb et chromadb-client L'utilisation de ces paquets provoque cette erreur, car le paquet « client-only » ne contient pas les fonctions d'intégration par défaut dont l'application a besoin. Le diagnostic de ce problème peut prendre des heures.
Ce sont les choix de configuration du client et les décisions relatives à la conception de la bibliothèque, et non la qualité de la recherche ou les performances d'indexation, qui sont à l'origine de ce type de défaillance.
Cet article compare les principales bibliothèques Python de bases de données Python sous cet angle, en examinant l'architecture client, la stabilité de l'installation, la conception de l'API et la maintenabilité à long terme, plutôt que de se limiter aux seuls résultats des tests de performance.
TL;DR
- ChromaDB : Configuration ultra-rapide pour le prototypage et les environnements de notebook, avec un minimum de réglages.
- Pinecone : solution entièrement géré , sans aucune charge administrative liée à la gestion de l'infrastructure.
- Qdrant : Aucune modification du code entre le développement local et la mise en production ; la meilleure option open source pour la stabilité des API.
- Weaviate : Recherche hybride combinant la similarité vectorielle et le filtrage par mots-clés à grande échelle.
- Base de données Actian VectorAI :déploiement sur site déploiement une architecture identique, de l'ordinateur portable à l'environnement de production ; Actian l'a conçu pour les environnements en périphérie et isolés.
Python : comprendre les différentes options
La relation entre une bibliothèque Python de base de données Python et son backend de stockage détermine la manière dont vous développerez, testerez et, à terme, ferez évoluer votre application. Un mauvais choix de bibliothèque entraîne souvent les défaillances spécifiques à l'environnement décrites ci-dessus, car chaque architecture gère différemment les environnements locaux et de production.
Ces différences se répartissent généralement en quatre catégories distinctes, chacune ayant sa propre approche de l'interaction entre l'infrastructure et le code.
Quatre architectures client
- Exclusivement sur le cloud (par exemple, Pinecone) : ces clients offrent une abstraction complète de l'API pour les environnements sans serveur. Leur principal avantage réside dans l'absence totale de gestion d'infrastructure, mais cela nécessite une connexion Internet active et une clé API pour tout le développement et les tests en local.
- Logiciels libres avec option de gestion (par exemple, Qdrant, Weaviate, Milvus) : cet ensemble d'outils utilise la même API tant pour les instances Docker auto-hébergées que pour les services cloud gérés. Cela garantit une excellente cohérence entre l'environnement de développement et celui de production, même si cela nécessite souvent de gérer un serveur local ou un conteneur Docker pendant la phase de développement.
- Embarqué (par exemple, ChromaDB, FAISS) : ces outils s'exécutent en cours de traitement et Embarquer logique de base de données directement dans votre Python . Bien qu'ils soient parfaits pour les notebooks et le prototypage rapide, leurs développeurs ne les ont jamais conçus pour des environnements de production distribués, et ils n'offrent pas de plan de migration bien défini à mesure que l'application évolue.
- Approche par extension (par exemple, pgvector via Timescale Vector) : ce modèle ajoute Fonctionnalités de recherche vectorielle Fonctionnalités bases de données relationnelles traditionnelles. Il permet à l'infrastructure PostgreSQL existante de support la recherche par similarité support . Cependant, requête varient en fonction de la configuration des index, jeu de données et charge de travail ; certains scénarios avantage la base relationnelle, tandis que d'autres privilégient des architectures vectorielles spécialement conçues.
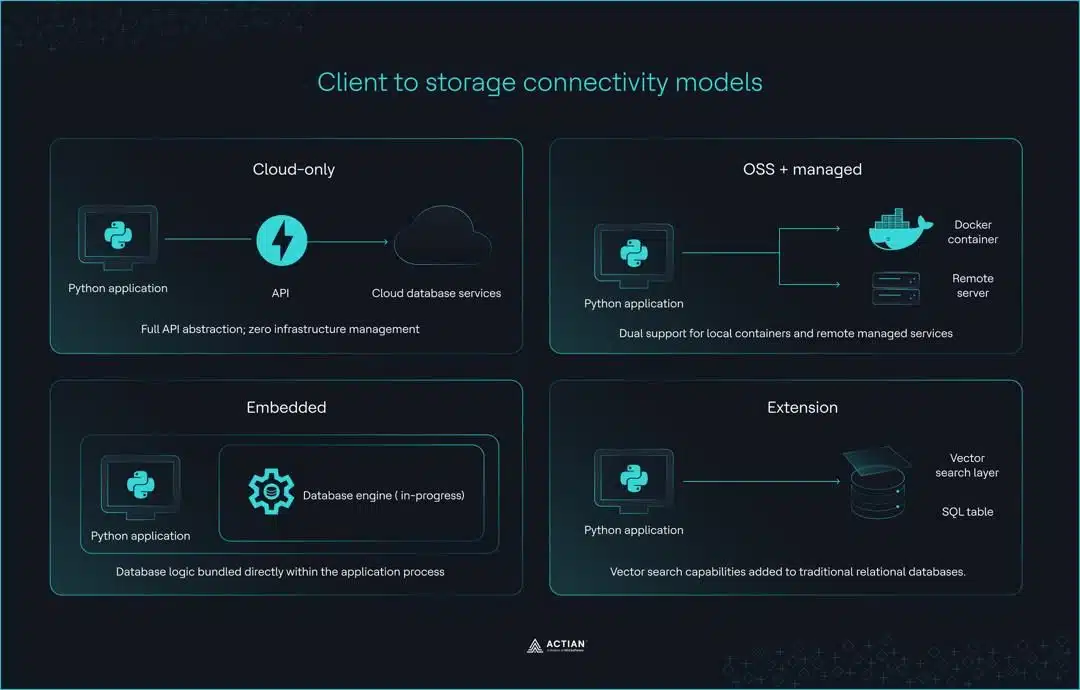
Ces quatre modèles décrivent la manière dont un client se connecte au stockage, mais ils mettent également en évidence une distinction concrète entre les bibliothèques de recherche autonomes et les systèmes de bases de données gérés. Le choix d'un modèle inadapté est à l'origine de certains des problèmes les plus récurrents en production dans les applications de recherche vectorielle.
Une base de données vectorielle fournit l'infrastructure nécessaire à Préparation la production, allant au-delà de ce qu'offrent les bibliothèques autonomes des développeurs. Des bibliothèques telles que FAISS ou Annoy sont in-memory statiques in-memory , conçus pour la recherche approximative du plus proche voisin dans jeux de données grands jeux de données. Elles sont très efficaces pour la recherche de similarités au sein d'un espace vectoriel fixe, mais ne permettent pas de gérer les données au fil du temps.
Des bases de données spécialisées telles que Pinecone, Qdrant ou Milvus vont encore plus loin en offrant support complète des opérations CRUD, un filtrage métadonnées et une persistance distribuée pour jeux de données grands jeux de données.
Le tableau ci-dessous résume les cas d'utilisation courants pour lesquels chaque architecture est adaptée.
| Catégorie | Compromis principal | Parcours de migration vers la production |
| Uniquement sur le cloud | Aucune gestion d'infrastructure ; nécessite une connexion réseau et une authentification via l'API pour tous les environnements | Même code client pour les environnements de développement et de production |
| Logiciels libres + gestion | API identique pour les déploiements locaux et dans le cloud ; nécessite Docker ou la configuration d'un serveur | Aucune modification du code n'est nécessaire entre l'instance Docker locale et le service cloud géré |
| Embarqué | Exécution en cours de traitement avec une configuration minimale ; limitée à une architecture mono-machine | Il faut remplacer la classe client ; déploiement distribué déploiement repensé |
| Extension | S'intègre à l'infrastructure PostgreSQL ; les performances varient en fonction de la configuration | Cela dépend de la configuration actuelle de PostgreSQL et des exigences en matière d'évolutivité |
Comparaison des clients : analyse approfondie de l'expérience développeur
Certes, le choix du langage limite les options, mais l'expérience quotidienne de l'utilisation d'une bibliothèque Python pour bases de données Python dépend avant tout de la manière dont chaque client gère l'établissement de la connexion, la stabilité des versions et les difficultés rencontrées au cours du développement.
Nous comparons ci-dessous ces quatre clients en nous basant sur les réalités auxquelles les développeurs sont confrontés dans la pratique.
1. Python Pinecone Python
Pinecone offre l'une des expériences de connexion les plus abouties parmi les clients de bases de données vectorielles exclusivement basées sur le cloud, grâce à des indications de type détaillées et à un modèle d'initialisation simple.
from pinecone import Pinecone
pc = Pinecone(api_key="your-api-key")
index = pc.Index("your-index-name")Points forts :
- support étendue des indications de type et de la saisie semi-automatique dans l'IDE.
- Pinecone a introduit support d'AsyncIO support la version 6 via Pinecone Asyncio.
- Le mode gRPC offre un débit plus élevé pour les charges de travail exigeantes.
- Une documentation officielle bien tenue.
Points faibles :
- Pinecone a publié trois versions majeures en 18 mois (v5, v6 et v7), apportant des modifications incompatibles à la logique de connexion et renommant le paquet, qui est passé de « pinecone-client » à « pinecone ».
- Confusion historique entre les paquets « pinecone » et « pinecone-client ».
- Les opérations asynchrones de « requête » sous charge nécessitent un réglage du pool de threads.
2. Python Weaviate
Le client v4 de Weaviate constitue une avancée significative par rapport à la version v3, avec l'ajout de classes typées et support gRPC, support améliorent sensiblement requête .
import weaviate
client = weaviate.connect_to_local()
collection = client.collections.get("your-collection-name")Points forts :
- Le mode gRPC offre requête 40 à 70 % plus rapides que la version 3.
- Les classes de propriétés typées et DataType remplacent les dictionnaires non typés de la version 3.
- Fonction de recherche hybride intégrée combinant la recherche vectorielle et la recherche par mots-clés.
- support étendue support charges de travail en multi-locataires.
Points faibles :
- Weaviate a complètement abandonné l'API v3, et les équipes indiquent que la migration nécessite plusieurs semaines de travail.
- gRPC nécessite que le port 50051 soit ouvert, ce qui pose des problèmes dans les environnements réseau restreints.
- La refonte de l'API Batch a semé une grande confusion (problème n° 433).
- LangChain n'a pris support la version 4 support plusieurs mois après la sortie de Weaviate (problème n° 14531).
3. Python ChromaDB
ChromaDB offre l'une des expériences d'intégration les plus simples parmi les bibliothèques de bases de données Python , ce qui en fait un point de départ tout indiqué pour les notebooks et le prototypage en phase initiale.
import chromadb
client = chromadb.Client()Points forts :
- L'interface API la plus simple parmi tous les clients de ce comparatif.
- Une intégration LangChain aboutie, accompagnée d'exemples bien documentés.
- in-memory ne nécessite aucune configuration pour les environnements d'ordinateurs portables.
- Une communauté open source importante et dynamique.
Points faibles :
- Incompatibilité Python .13 (problème n° 3651).
- Instabilité de Windows au-delà de 99 enregistrements (problème n° 3058).
- Confondre chromadb et chromadb-client perturbe les déploiements en production.
- Erreurs de compilation hnswlib sur les processeurs Mac ARM.
- Nécessite SQLite 3.35 ou une version ultérieure, ce qui entraîne une charge de configuration spécifique à l'environnement.
4. Python Qdrant
Les développeurs apprécient Qdrant pour la parité entre l'environnement de développement et la production. Le même code client s'exécute sur une in-memory pendant le développement et sur un déploiement entièrement géré déploiement production, sans nécessiter aucune modification.
from qdrant_client import QdrantClient
client = QdrantClient(":memory:")Points forts :
- Le mode :memory: permet un workflow de l'environnement local vers la production sans aucune modification du code.
- Qdrant a lancé un client AsyncQdrantClient natif destinésimultanéité .
- Sécurité des types de modèles Pydantic dans toute l'interface client.
- Une implémentation basée sur Rust qui nécessite moins de mémoire que les solutions basées sur la JVM.
Points faibles :
- Les développeurs doivent explicitement définir prefer_grpc=True pour activer gRPC, une étape qu'ils ont souvent tendance à oublier.
- La répartition des ports entre REST (6333) et gRPC (6334) nécessite une configuration réseau minutieuse.
- Contraintes de version de Pydantic : v1.10.x ou v2.21 et versions ultérieures uniquement.
- Problèmes de connexion au cloud (problème n° 112).
Quand choisir Qdrant :
- La parité entre l'environnement local et l'environnement de production est une priorité, et il est essentiel qu'aucune modification du code ne soit nécessaire d'un environnement à l'autre.
- Les charges de travailsimultanéité nécessitent support native d'AsyncQdrantClient.
- Vous préférez une déploiement de données vectorielle open source hébergée en interne déploiement un service cloud géré.
- La recherche hybride combinant des vecteurs denses et clairsemés est une exigence fondamentale.
Quand éviter Qdrant :
- L'équipe n'a aucune expérience de Docker et a besoin d'une configuration locale plus simple.
- L'environnement cible ne support pas support la configuration réseau support .
- Les contraintes de version de Pydantic entrent en conflit avec les dépendances existantes du projet.
Gestion de l'installation et de l'environnement
Dans des conditions idéales, l'installation d'une bibliothèque Python de base de données Python est simple. Dans la pratique, la plateforme cible, Python et les dépendances existantes des paquets introduisent chacune des variables susceptibles de transformer une simple installation via pip en une session de débogage de plusieurs heures. Il vaut la peine de procéder à une vérification rapide de la compatibilité avant de s'engager auprès d'un client, car la plupart de ces problèmes n'apparaissent qu'une fois l'installation terminée.
Le tableau de compatibilité
Le tableau suivant présente le comportement des clients sous Python . Python à 3.13 sur macOS ARM, Windows et Linux.
| Client | macOS ARM (M1/M2) | Fenêtres | Linux (Debian) | Python .13 |
| Pomme de pin | ✓ support complète | ✓ support complète | ✓ support complète | ✓ Pris en charge |
| Weaviate | ✓ support complète | ✓ support complète | Nécessite Docker pour gRPC | ✓ Pris en charge |
| ChromaDB | Erreurs de compilation hnswlib | Instabilité au-delà de 99 enregistrements (n° 3058) | Nécessite Debian Bookworm+ | ✗ Ne fonctionne pas (#3651) |
| Qdrant | ✓ support complète | ✓ support complète | ✓ support complète | ✓ Pris en charge |
ChromaDB est le client qui présente le plus de problèmes de compatibilité parmi ceux comparés ici. Sous macOS avec des processeurs ARM, hnswlib génère des erreurs de compilation lors de l'installation, ce qui oblige les développeurs à fixer manuellement Python 3.11 ou 3.12.
Sous Windows, ChromaDB devient instable dès qu'une collection dépasse 99 enregistrements, ce qui rend le Embarqué inadapté à toute utilisation au-delà du prototypage initial. Sous Linux, les distributions basées sur Debian nécessitent Bookworm ou une version ultérieure pour installer et exécuter ChromaDB correctement.
Bonnes pratiques en matière d'environnements virtuels
python -m venv venv
source venv/bin/activate # On Windows: venv\Scripts\activate
pip install chromadbIl est tout aussi important de spécifier la version du client dans un fichier requirements.txt, car plusieurs de ces clients ont déjà introduit des modifications incompatibles entre deux versions mineures.
chromadb==0.4.x
qdrant-client==1.7.x
pinecone==3.x
weaviate-client==4.xL'architecture à deux paquets de ChromaDB sème la confusion chez de nombreux développeurs. Lorsqu'un utilisateur installe chromadb-client à la place de chromadb, l'application renvoie cette erreur dès la première tentative d'appel de la fonction d'intégration par défaut.
ValueError: You must provide an embedding functionFonctionnalités supplémentaires et dépendances facultatives
# Pinecone with gRPC support
pip install pinecone[grpc]
# Qdrant with FastEmbed for local embedding generation
pip install qdrant-client[fastembed]
# ChromaDB with sentence-transformers for local embedding support
pip install chromadb sentence-transformersgRPC est l'option qui a le plus d'impact sur requête . Weaviate constate que les requêtes sont 40 à 70 % plus rapides avec gRPC qu'avec REST, tandis que Qdrant gagne environ 15 % en requête . En contrepartie, gRPC nécessite une configuration réseau supplémentaire, ce qui peut s'avérer impossible dans certains environnements soumis à des restrictions.
FastEmbed et sentence-transformers permettent tous deux de générer des vecteurs d'encodage en local sans dépendre d'une API externe, ce qui réduit la latence et les coûts d'encodage pour les tâches de recherche sémantique et de recherche par similarité.
Le client natif AsyncQdrantClient de Qdrant et PineconeAsyncio de Pinecone permettent d'augmenter le débit de 3 à 5 fois dans le cadre desimultanéité .
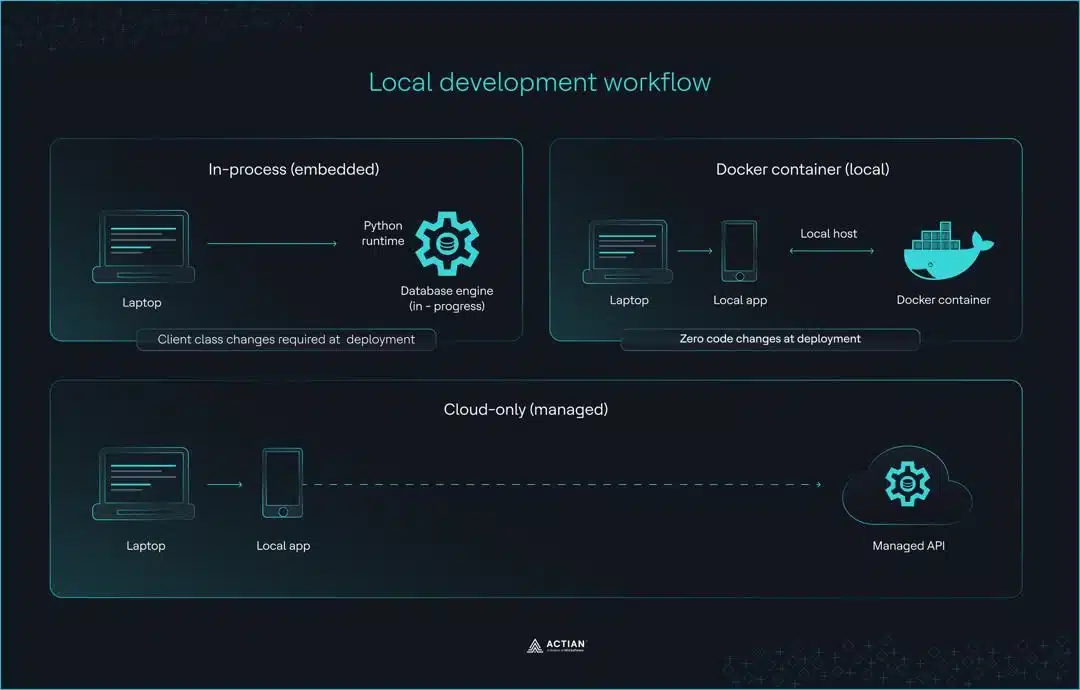
Workflows de développement local
Les développeurs prennent la plupart de leurs décisions concernant les bases de données vectorielles dans leur environnement de développement local. La question cruciale est la suivante : quel client nécessite le moins de modifications du code lors du passage en production ?
Le parcours de migration
Voici comment chaque client gère le passage du déploiement local déploiement la production.
# Qdrant - zero code changes required
client = QdrantClient(":memory:") # Development
client = QdrantClient( # Production
url="https://your-cluster-url",
api_key="your-api-key"
)
# ChromaDB - client class change required
client = chromadb.Client() # Development
client = chromadb.HttpClient( # Production
host="your-host",
port=8000
)
# Pinecone - same code in both environments
pc = Pinecone(api_key="your-api-key") # Development and production
index = pc.Index("your-index-name")
Qdrant :memory: Ce mode transfère le même code client depuis l'environnement de développement local jusqu'à la production. La configuration du magasin vectoriel, les paramètres de similarité cosinus et les paramètres d'indexation hnsw restent identiques d'un environnement à l'autre.
Le passage en production de ChromaDB nécessite une modification de la classe client. Plus le code source utilise cette classe client, plus cette modification aura un impact sur l'application.
Pinecone utilise le même code en environnement de développement et en production, car tout s'exécute dans le cloud, quelle que soit la phase.
Ces différences en matière de migration découlent de trois approches distinctes de développement local : Embarqué , Docker et le cloud uniquement.
Embarqué
Embarqué par défaut de ChromaDB stocke les données uniquement en mémoire. Lorsque l'application cesse de fonctionner, les données sont perdues. Pour les développements impliquant des collections persistantes, PersistentClient enregistre plutôt les données sur le disque.
# In-memory only: data lost when process ends
client = chromadb.Client()
collection = client.create_collection("my_collection")
collection.add(documents=["doc1", "doc2"], ids=["1", "2"])
# Persistent local storage
client = chromadb.PersistentClient(path="/local/path")
Qdrant’s :memory: Ce mode utilise la même interface client qu'un déploiement en production. Tout code fonctionnant en local fonctionne également en production sans aucune modification.
client = QdrantClient(":memory:")
client.create_collection(
collection_name="my_collection",
vectors_config=VectorParams(size=384, distance=Distance.COSINE)
)
Ces deux clients conviennent parfaitement au prototypage initial et aux environnements de portables, et leurs différences n'apparaissent qu'au stade de la production.
Docker pour le développement local
Docker exécute la base de données vectorielle dans un conteneur local isolé, en utilisant la même configuration que celle d'un déploiement en production. Qdrant et Weaviate sont deux bases de données vectorielles open source qui support approche.
# Qdrant
docker run -p 6333:6333 qdrant/qdrant
# Weaviate
docker run -p 8080:8080 -p 50051:50051 cr.weaviate.io/semitechnologies/weaviate:latest
Une fois le conteneur lancé, le client se connecte à localhost de la même manière qu'il le ferait à une base de données Vector auto-hébergée en production.
# Qdrant
client = QdrantClient(url="https://localhost:6333")
# Weaviate
client = weaviate.connect_to_local()
Le principal avantage réside dans le fait que la configuration des index vectoriels se comporte de la même manière en environnement de test qu'en production, et que les problèmes qui apparaissent en environnement de test sont de véritables problèmes et non des anomalies liées à l'environnement.
En contrepartie, il faut compter avec la charge liée à l'installation de Docker et à la configuration des ports, notamment l'exigence de Weaviate concernant ces deux ports 8080 and 50051.
Développement exclusivement sur le cloud
Écosystème d'intégration : LangChain et LlamaIndex
from langchain_pinecone import PineconeVectorStore
from langchain_chroma import Chroma
from langchain_qdrant import QdrantVectorStore
from langchain_weaviate import WeaviateVectorStore
from llama_index.vector_stores.qdrant import QdrantVectorStore- Le client publie une nouvelle version comportant des modifications incompatibles.
- Mise à jour concernant LangChain et LlamaIndex à venir.
- Les canalisations subissent des ruptures temporaires.
Considérations relatives aux performances : au-delà de la vitesse brute
La plupart des comparaisons de clients négligent trois facteurs qui influent considérablement sur les performances des bases de données vectorielles : le choix du protocole, la qualité de support asynchrone et la mise en pool des connexions.
Choix du protocole : REST ou gRPC
gRPC et REST sont les deux protocoles de transport disponibles pour ces clients. Comme indiqué précédemment, Weaviate constate une accélération des requêtes de 40 à 80 % avec gRPC, tandis que Qdrant gagne environ 15 % en requête lorsque gRPC est activé. Dans les environnements réseau restreints où le port 50051 n'est pas accessible, REST est l'option la plus pratique.
support asynchrone
La plupart des équipes développent des applications LLM de production sur FastAPI ou frameworks asynchrones similaires, ce qui fait de support des clients asynchrones support facteur de performance important. L'utilisation d'un client synchrone au sein d'une application asynchrone entraîne des appels bloquants, ce qui réduit considérablement le débit.
Natif de Qdrant AsyncQdrantClient, disponible depuis la version 1.61, offre une implémentation asynchrone éprouvée. Pinecone a introduit PineconeAsyncio dans la version 6, apportant support asynchrone adéquate support charges de travail de recherche vectorielle exclusivement sur le cloud. Weaviate a ajouté support asynchrone support la version 4.7, ce qui en fait le plus récent des quatre à proposer Fonctionnalités prêt pour la production . support asynchrone de ChromaDB support limitée sur l’ensemble des quatre solutions.
La différence de débit est considérable. Pour les charges de travail dépendantes des E/S où la latence réseau constitue le goulot d'étranglement, les clients asynchrones offrent généralement un débit 3 à 5 fois supérieur à celui de leurs équivalents synchrones.
Pool de connexions et gestion des ressources
Il s'agit là d'un des domaines de configuration où les paramètres par défaut ont tendance à s'avérer insuffisants en environnement de production. Qdrant et Pinecone proposent tous deux des paramètres permettant de mieux contrôler la gestion des connexions en cas de trafic de production soutenu.
# Qdrant connection pool configuration
client = QdrantClient(
url="https://your-cluster-url",
api_key="your-api-key",
timeout=30,
pool_size=10
)
# Pinecone connection pool configuration
index = pc.Index(
"your-index-name",
pool_threads=30,
connection_pool_maxsize=30
)
Pour Pinecone, query_namespaces nécessite un réglage pool_threads et connection_pool_maxsize pour les charges de travail de production. Pour Qdrant, l'augmentation pool_size Une valeur supérieure à celle par défaut réduit les conflits de connexion pour les applications qui traitent en parallèle de grands volumes de documents intégrés.
Les équipes qui optimiser paramètres avant déploiement un temps considérable à déboguer l'application lorsqu'elle fonctionne sous charge.
Gestion des erreurs et débogage
Les bibliothèques de bases de données vectorielles gèrent en interne de nombreux aspects complexes. En cas de défaillance, la rapidité avec laquelle les équipes peuvent y remédier dépend de la clarté avec laquelle le client signale cette défaillance.
Qualité des messages d'erreur
La qualité des messages d'erreur varie considérablement d'un client à l'autre.
Pinecone génère des messages d'erreur clairs et exploitables qui proposent généralement une solution en plus de la description de l'incident, ce qui permet aux équipes de passer moins de temps à rechercher la cause profonde.
Les messages d'erreur de Qdrant sont utiles et indiquent directement la source du problème. L'exception UnexpectedResponse comprend un champ « reason » spécifique qui identifie précisément le paramètre dont la validation a échoué.
qdrant_client.http.exceptions.UnexpectedResponse: Status 400, reason: "Wrong input: Vector dimension error: expected dim: 384, got 768"Les messages d'erreur de ChromaDB sont souvent vagues et nécessitent une recherche sur GitHub pour être diagnostiqués. Lorsque la confusion entre les deux paquets se produit, ChromaDB génère une erreur « ValueError » signalant l'absence de fonctions d'intégration, au lieu d'indiquer la cause réelle du problème. L'exigence relative à la version de SQLite produit une erreur tout aussi peu utile :
RuntimeError: Your system has an unsupported version of sqlite3. Chroma requires sqlite3 >= 3.35.0.Cette erreur constitue un obstacle courant pour Python qui déploient leurs applications sur des environnements Amazon Linux 2 ou Streamlit plus anciens.
Weaviate v3 générait des erreurs silencieuses, renvoyant des objets nuls ou des dictionnaires contenant une clé « errors » que les développeurs devaient vérifier manuellement. La refonte de la version v4 a remédié à ce problème grâce à des exceptions typées, telles que WeaviateQueryError et WeaviateGRPCUnavailableError.
Journalisation et observabilité
Fonctionnalités observabilité Fonctionnalités selon les quatre clients.
- Qdrant prend en charge la journalisation structurée, le traçage distribué et les métriques sans configuration supplémentaire, ce qui en fait une solution idéale pour les applications de machine learning en production qui nécessitent une visibilité sur les performances des moteurs de recherche vectorielle.
- Pinecone propose des fonctionnalités de journalisation de base via son infrastructure gérée.
- ChromaDB dispose d'une journalisation limitée sans sortie structurée, ce qui complique considérablement le diagnostic des problèmes dans les applications d'IA en production.
Pièges courants et solutions
Trois types d'erreurs reviennent systématiquement chez les quatre clients dans les environnements de production.
- Les incompatibilités entre versions client entraînent des pannes fréquentes et imprévues, notamment dans le cadre des trois versions publiées par Pinecone en 18 mois et de la migration de Weaviate de la version 3 à la version 4. Les équipes peuvent remédier à ce problème en verrouillant les versions client dans un
requirements.txtfichier. - Un décalage de dimensions d'intégration survient lorsque les dimensions requête ne correspondent pas aux spécifications de la collection. déploiement cela, il convient de vérifier, avant déploiement , que la taille de sortie du modèle d'intégration correspond bien à la configuration de la collection.
- La limitation de débit s'applique aux déploiements exclusivement sur le cloud sur Pinecone et Weaviate Cloud. La mise en œuvre d'un recul exponentiel pour les appels API constitue la solution standard pour les charges de travail en production qui s'approchent des limites de débit en cas de trafic soutenu.
La fréquence à laquelle des problèmes de version apparaissent, l'ampleur des incompatibilités entre plateformes et la clarté des messages d'erreur signalant les défaillances déterminent ensemble le coût réel de maintenance d'un client en environnement de production.
Les changements de version successifs sur Pinecone, Weaviate et ChromaDB ont conduit de nombreuses équipes de production à rechercher un client qui privilégie la stabilité opérationnelle plutôt que la rapidité d'introduction de nouvelles fonctionnalités. Actian VectorAI DB répond directement à ce besoin.
Base de données Actian VectorAI
- Une architecture identique dans tous les environnements.
- déploiement basé sur Docker.
- Indexation HNSW.
- Indexation en temps réel.
- SDK Python JavaScript.
- Intégration native de LangChain et LlamaIndex.
Guide de décision : choisir votre Python
Matrice de décision
| Critères | Pomme de pin | Qdrant | Weaviate | ChromaDB | Base de données Actian VectorAI |
| Stabilité de l'API | Moyen | Bien | Améliorer | Faible | Haut |
| Développement local | ✗ Pas de mode local | ✓ Mode :mémoire: | Docker requis | ✓ Embarqué | ✓ :mémoire: + SQLite |
| Compatibilité avec les plateformes | ✓ Uniquement sur le cloud | ✓ Toutes plateformes | ✓ Toutes plateformes | ✗ Problèmes sur ARM, Windows | ✓ Toutes plateformes |
| support asynchrone | ✓ v6 et versions ultérieures | ✓ Natif | ✓ v4.7 et versions ultérieures | ✗ Limité | ✓ Natif |
| Coût | 50 à 500 $ et plus par mois | Gratuit / Auto-hébergé | Gratuit / Géré | Gratuit | Tarifs pour les entreprises |
Réflexions finales
La défaillance de production de ChromaDB évoquée dans l'exemple d'introduction est due à des problèmes de packaging côté client que les développeurs ne constatent qu'après déploiement. Cette comparaison permet d'éviter des défaillances similaires : incompatibilités entre plateformes, modifications majeures liées aux migrations de version et refontes de classes client qui se répercutent sur l'ensemble des bases de code.
ChromaDB permet de démarrer rapidement des projets, mais ses limites apparaissent souvent dès que l'application passe en production. Pinecone est une solution aboutie et bien gérée, mais la fréquence des mises à jour et les dépendances permanentes au cloud représentent un coût réel. Qdrant est la meilleure option open source pour les équipes qui souhaitent une parité entre l'environnement local et la production sans avoir à modifier le code. Le client v4 de Weaviate apporte des améliorations significatives par rapport à la v3 et convient parfaitement aux équipes qui ont besoin d'une recherche hybride à grande échelle.
Pour les équipes pour lesquelles la stabilité des API et la compatibilité des plateformes sont essentielles, les clients de niveau entreprise tels qu'Actian VectorAI DB offrent prêt pour la production ainsi qu'support multiplateforme vérifiée.
Découvrez Actian VectorAI DB pour une stabilité de production garantie.

Restez connecté
Des informations tirées des données, à votre service.
(par exemple : sales@..., support)