Is Actian VectorAI DB the Best Lightweight Milvus Alternative?
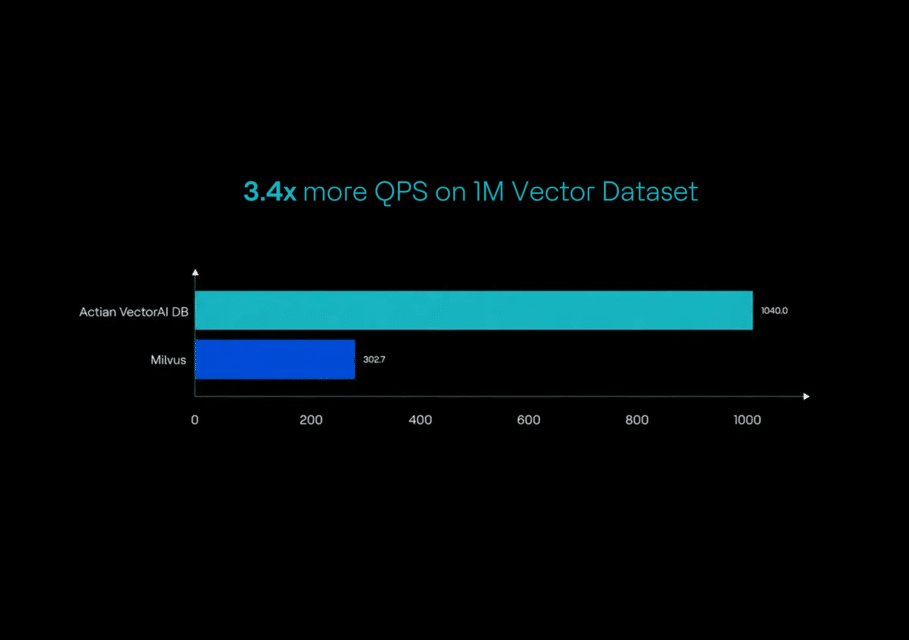




Summary
- The main difference between Milvus and VectorAI DB is operational complexity.
- Milvus is stronger for large-scale, distributed, cloud-native deployments with broader index and SDK options.
- VectorAI DB is simpler to run, using a single Docker container with no external dependencies.
- This makes VectorAI DB a better fit for self-hosted, air-gapped, edge, or compliance-constrained environments.
- The tradeoff is flexibility and ecosystem breadth versus simpler deployment and lower operational overhead.
The deciding factor between Milvus and Actian VectorAI DB is operational complexity. Milvus offers Lite and Standalone modes for development and small workloads. Production deployments typically require its Distributed architecture. That means Kubernetes, etcd, object storage such as MinIO, and a message queue before the system can serve a single query. Production clusters involve deploying dozens of pods and require hundreds of configuration parameters.
VectorAI DB deploys as a single Docker container with no external dependencies and runs without internet access. This model suits air-gapped and edge environments, as well as engineering teams that cannot or do not want to run a Kubernetes cluster. It eliminates the complexity wall and operates within existing constraints.
The comparison below focuses specifically on production deployment trade-offs: operational complexity, infrastructure requirements, and how each system behaves under constrained or self-hosted environments.
TL;DR
This table summarizes the difference between Milvus and VectorAI DB across key dimensions.
| Capability | Milvus | VectorAI DB | Pinecone | Qdrant | Weaviate | ChromaDB | pgvector |
| Deployment model | Distributed (Kubernetes/Cloud) | Single-node Docker | SaaS (Cloud only) | Single-node / Distributed | Single-node / Distributed | Single-node / Distributed | SQL Extension |
| Kubernetes required | Yes (for Distributed) | No | No (managed by Pinecone) | No (for Single-node) | No (for Single-node) | No | No |
| Air-gap capable | Yes (Complex) | Yes (Native) | No | Enterprise Tier | Enterprise Tier | Yes | Yes |
| Min. production setup | 20+ Pods, etcd, MinIO | 1 Docker Container | Managed Service | 1 Docker Container | 1 Docker Container | 1 Docker Container | 1 Postgres Instance |
| Open-source | Yes | No | No | Yes | Yes | Yes | Yes |
| Minimum cost | Free (OSS) / $99+ Cloud | Free / ~$417/month for 1M vectors | Free / Usage-based | Free / $25+ Cloud | Free / $25+ Cloud | Free | Free |
| Scales beyond node | Yes | No | Yes | Yes | Yes | Yes | Yes (via Postgres) |
Why Operational Complexity is the Deciding Factor
Operational complexity in Milvus becomes most visible at production scale. While the system supports flexible scaling of compute and storage, that flexibility depends on a full distributed stack in practice. Teams must operate Kubernetes, etcd, external object storage such as MinIO, and a message queue before the system can reliably serve vector workloads in production traffic.
At scale, this translates into multi-service coordination, frequent configuration management, and infrastructure ownership that extends beyond the database itself. This aligns with the Milvus team’s own positioning of the system as “cloud-native” and “cloud-only,” where Kubernetes or managed platforms form the primary deployment path.
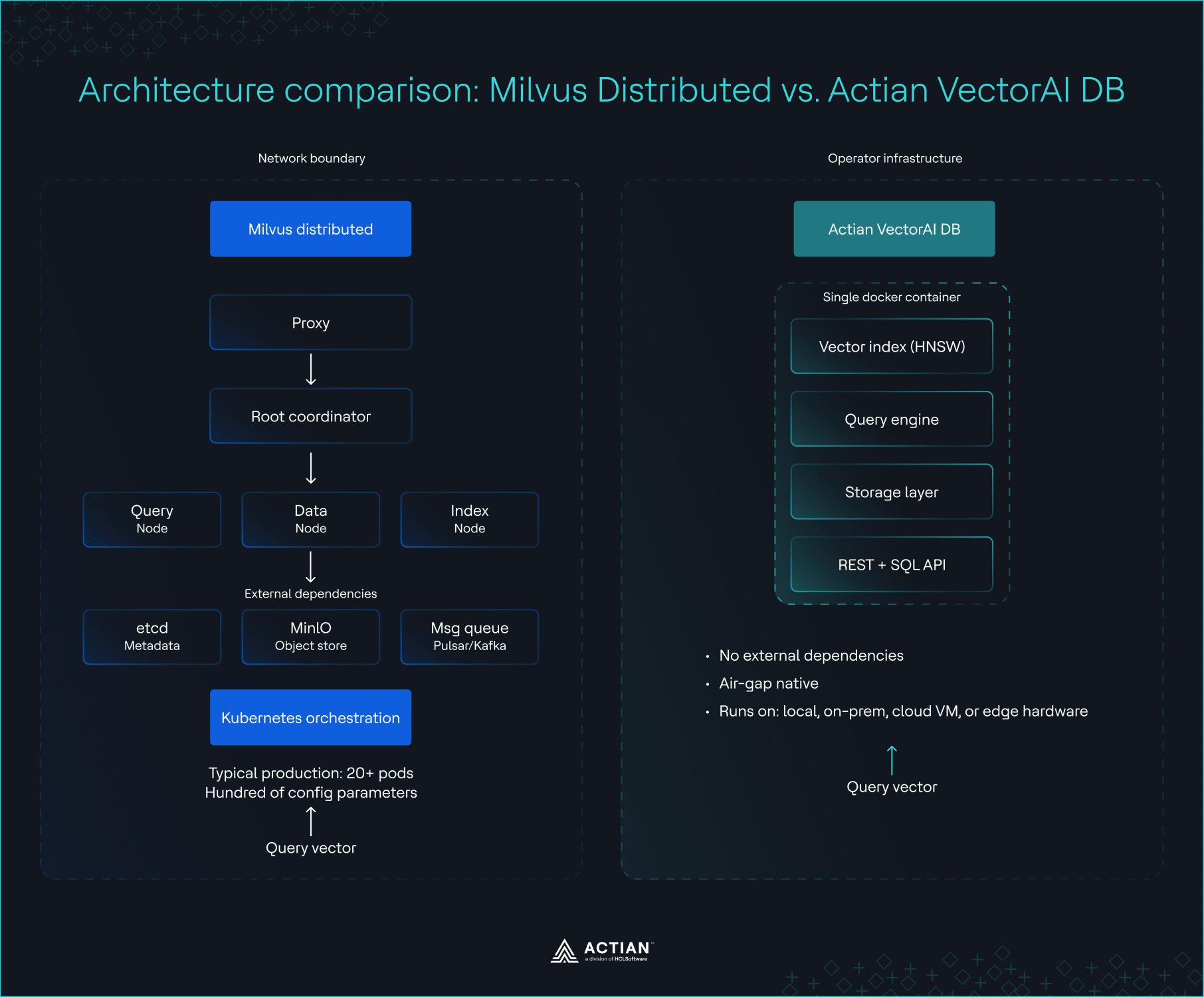
Architecture comparison between Milvus Distributed (left) and Actian VectorAI DB (right)
VectorAI DB avoids this operational layer by collapsing deployment into a single Docker runtime. Instead of introducing additional infrastructure components, it runs as a self-contained unit that teams deploy directly onto existing hardware. This approach shifts the focus away from distributed system management and toward direct execution within constrained environments, where infrastructure support is limited or unavailable.
Performance at 1 Million Vectors
We conducted benchmarking in April 2026, comparing how Actian VectorAI DB and Milvus translate architectural differences into raw throughput. The tests ran on identical self-hosted hardware using a dataset of one million vectors with 768 dimensions.
The results show that Milvus achieves slightly higher recall, while Actian VectorAI DB demonstrates higher operational efficiency and query performance during index creation and query execution.
Benchmark results
- Queries per second (QPS): Actian VectorAI achieved 1,040 QPS, outperforming Milvus (302.7 QPS) by a factor of 3.4.
- Recall: Milvus (0.9983) edged out Actian VectorAI DB (0.9948) in retrieval accuracy.
- Load duration: Actian VectorAI DB loaded the index in 1,242 seconds, a 73% reduction from the 4,680 seconds Milvus needed.
- Serial latency (p99): Actian recorded a 99th percentile latency of 12.7ms, while Milvus recorded 13.7ms.
- Serial latency (p95): Actian maintained its lead with a p95 latency of 11.3ms against 12.4ms for Milvus.
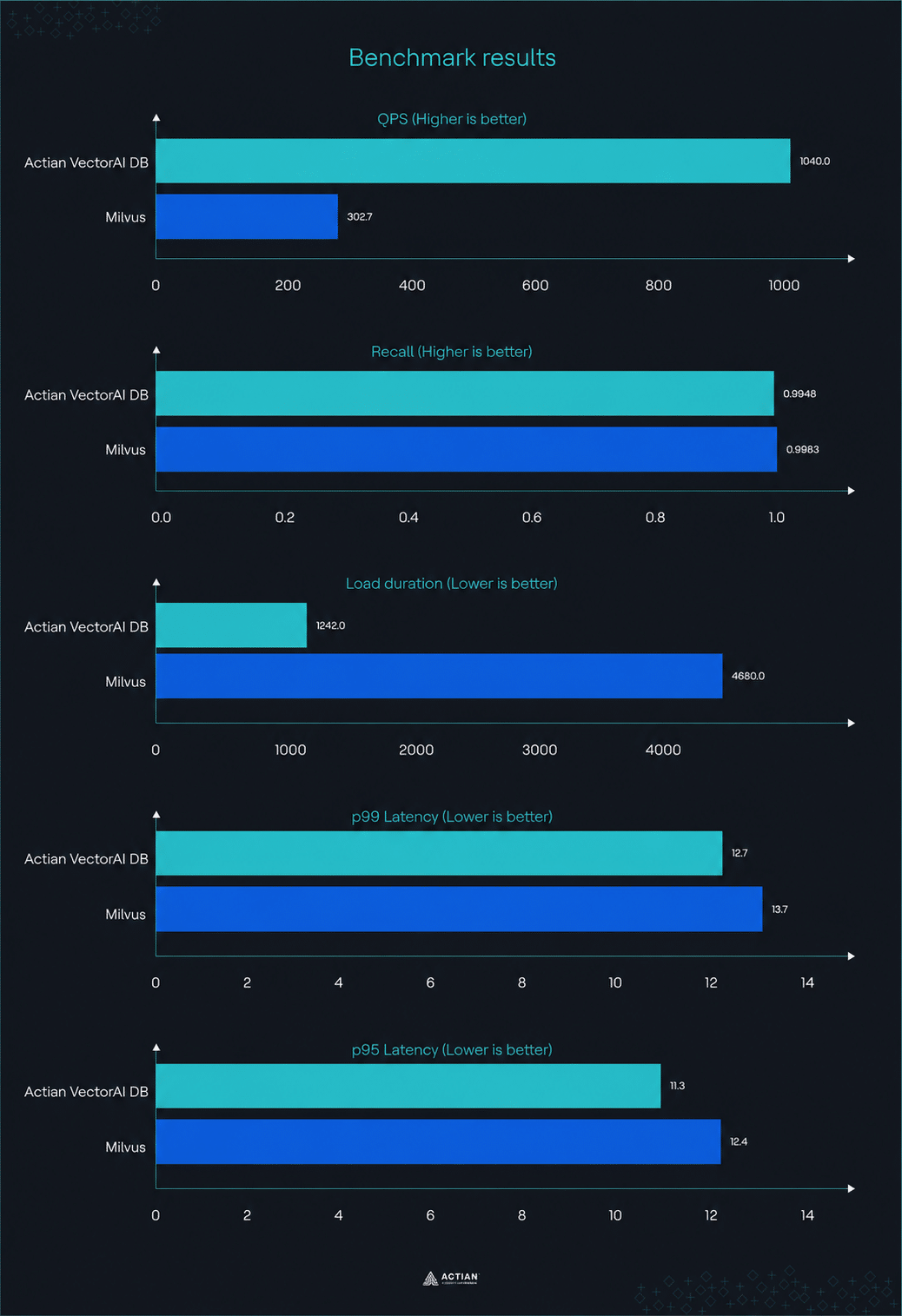
Benchmark statistics
These tests compared VectorAI DB against a standard Milvus setup rather than Milvus Distributed. The test conditions did not include data for Milvus v3.0 or Milvus 2.6 with RaBitQ, as those versions were unavailable for these specific benchmarks.
These initial VectorAI DB benchmark results reflect raw performance without vendor-specific tuning like segment compaction or quantization. While Milvus holds a slight lead in recall, VectorAI DB’s scaling characteristics are more resilient. In larger 10M vector tests, VectorAI DB retained 72% of its throughput. While tuning improves results on both sides, these baseline differences suggest strong scaling efficiency at production workloads without carrying the overhead of a distributed cluster. The team continues to validate results under fully optimized environments.
When Milvus has the Advantage in Vector Search
Choose Milvus when scale and architectural flexibility are non-negotiable. At scale, its distributed design becomes a strength, enabling horizontal scaling across compute and storage layers.
Milvus is the stronger option when teams need broad SDK coverage at launch for their machine learning models. Its support for Python, Java, Go, Node.js, and C++, along with mature integrations across the ML ecosystem, makes it well-suited for heterogeneous engineering environments where multiple languages and frameworks coexist.
Teams also choose Milvus when multiple index types are a core requirement. Milvus supports a wide range of indexing algorithms, including DiskANN, IVF variants, RaBitQ, and GPU-accelerated options. This gives teams control over performance tuning and recall trade-offs when managing high-dimensional vector data in production workloads.
For teams already operating Kubernetes and invested in a cloud-native infrastructure stack, Milvus offers a more established open-source ecosystem and a larger community for vector data applications. In environments where teams already manage operational complexity, Milvus serves as a foundation for large-scale systems.
Operational Costs at Production Scale
The financial commitment required for vector search varies significantly based on the architectural footprint of the chosen platform. Milvus production costs depend heavily on the deployment model. On managed infrastructure, Zilliz Cloud starts at $99 per gigabyte per month for dedicated clusters. Alternatively, usage-based compute models charge $0.04 per gigabyte per month for storage, alongside additional compute fees.
While self-hosted Milvus is free, it demands substantial hardware for large storage volumes. These hidden costs in data volumes, infrastructure management, and memory usage quickly accumulate as significant operational expenses for distributed environments.
In contrast, VectorAI DB eliminates that operational overhead by collapsing deployment into a single Docker container. Teams handle deployment, tuning, and ongoing maintenance through one runtime instead of a distributed stack. For production-grade environments, VectorAI DB uses a commercial licensing model that scales with the compute and storage the single-container engine consumes.
Actian VectorAI DB has a starter tier of approximately $417/month (billed annually) for up to one million vectors, designed for small AI applications.The tiers scale up to an enterprise level that supports 10 million+ vectors. Custom edge plans are also available for specialized deployments. Visit the Actian VectorAI DB pricing page and use the interactive estimator to find the right tier.
Ecosystem and Integration Maturity
Milvus ecosystem includes:
- SDKs for Python, Java, Go, Node.js, and C++
- Native integration with LangChain, LlamaIndex, and HuggingFace
- 15+ indexing methods for similarity search
VectorAI DB support includes:
- Python and JavaScript SDKs.
- REST and SQL for complex queries.
- Integration with LangChain and LlamaIndex.
While a maturity gap exists across diverse data types, VectorAI DB provides similarity search through SQL, which keeps the query surface familiar for developers already working with relational databases.
The code snippet below shows how to connect to a local Milvus vector database.
from pymilvus import connections, Collection
# Connect to Milvus Standalone
connections.connect(
alias="default",
host="localhost",
port="19530"
)
# Load existing collection
collection = Collection("demo_collection")
collection.load()
# vector
query_vector = [0.01] * 768
# Perform vector search
results = collection.search(
data=[query_vector],
anns_field="embedding",
param={"metric_type": "L2", "params": {"nprobe": 10}},
limit=5
)
print(results)Python initialization snippet for Milvus
This code connects to a local Milvus vector database server running on port 19530, loads an existing collection named demo_collection, and performs a vector similarity search. The query_vector is a 768-dimensional embedding used to search against vectors stored in the embedding field. The search uses the L2 (Euclidean distance) metric with nprobe=10 to control search accuracy and speed. The query returns the five nearest matching vectors from the collection.
from actian_vectorai import VectorAIClient, VectorParams, Distance, PointStruct
with VectorAIClient("localhost:50051") as client:
# Health check
info = client.health_check()
print(f"Connected to {info['title']} v{info['version']}")
# Create collection
client.collections.create(
"demo_collection",
vectors_config=VectorParams(size=128, distance=Distance.Cosine),
)
# Insert points
client.points.upsert("demo_collection", [
PointStruct(id=1, vector=[0.1] * 128, payload={"name": "Widget"}),
PointStruct(id=2, vector=[0.2] * 128, payload={"name": "Gadget"}),
PointStruct(id=3, vector=[0.3] * 128, payload={"name": "Gizmo"}),
])
# Search
results = client.points.search("demo_collection", vector=[0.15] * 128, limit=5)
for r in results:
print(f" id={r.id} score={r.score:.4f} payload={r.payload}")Python initialization snippet for VectorAI DB
This code demonstrates how to use VectorAI DB for vector storage and similarity search. It first connects to a local VectorAI DB server, performs a health check, and creates a collection configured for 128-dimensional vectors using cosine similarity. The code inserts three sample vectors with metadata payloads into the collection. Finally, the code searches for the vectors most similar to the query vector [0.15] * 128 and prints the matching IDs, similarity scores, and associated payload data.
How Other Vector Databases Compare
Pinecone operates primarily as a managed service. Its BYOC (Bring Your Own Cloud) deployment runs the data plane inside the customer’s cloud VPC, while the control plane remains on Pinecone’s infrastructure. Teams requiring total local control over both planes may find this split limiting.
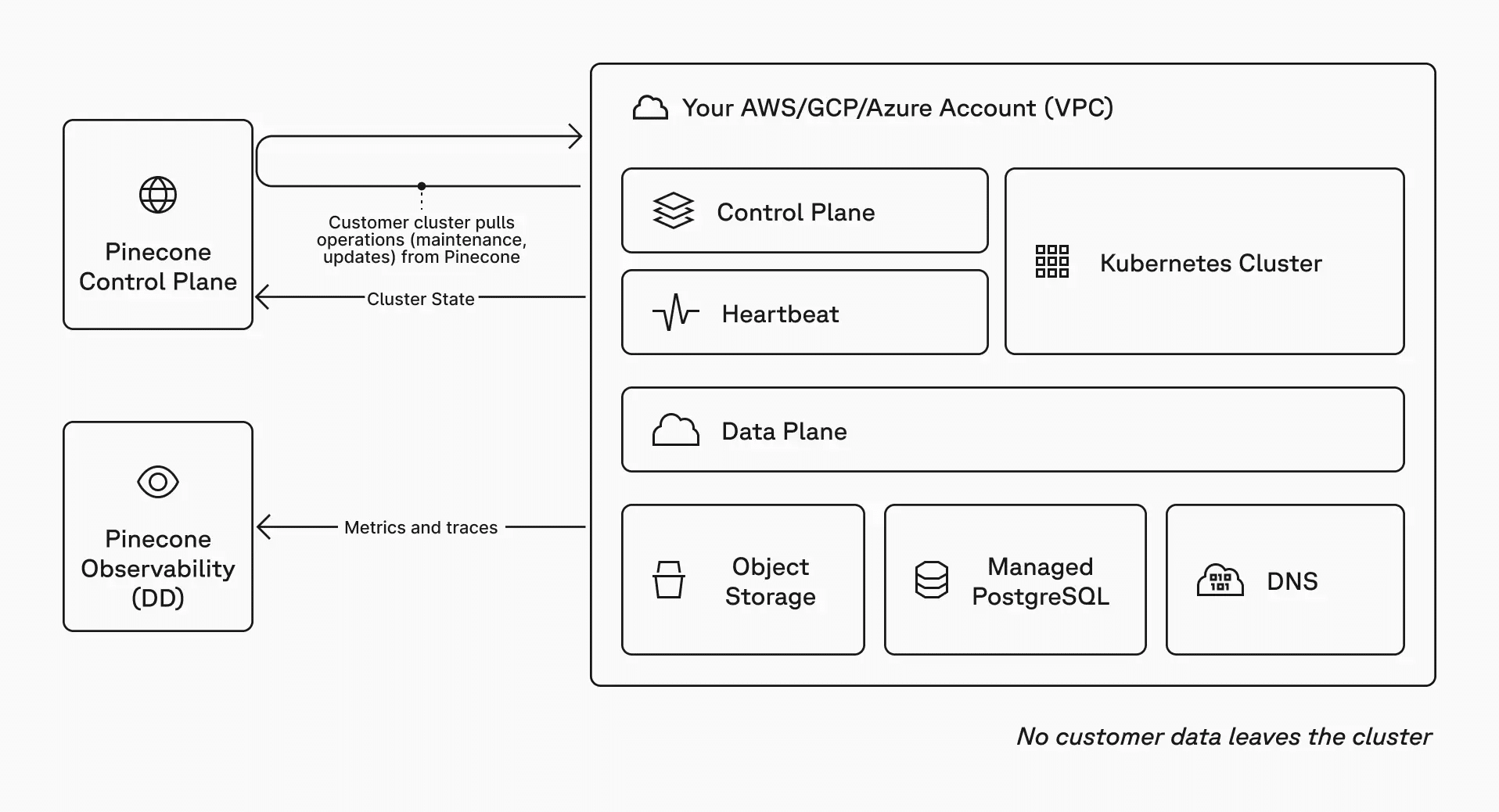
Pinecone BYOC
Qdrant supports self-hosting with simpler operational requirements than Milvus and does not depend on etcd or MinIO. The private cloud air-gap tier for vector search requires enterprise pricing. This puts air-gapped deployment out of reach for teams operating on a tight budget.
Weaviate allows self-hosting via Docker or Kubernetes with a cleaner dependency chain for vector data. Because the HNSW index must reside entirely in memory, it does not suit constrained hardware environments. This memory requirement offsets the simpler architectural footprint compared to other platforms offering hybrid search or specialized key features.
ChromaDB functions as a single-node system with no distributed architecture for managing vector data. This makes it the lightest option in the category for rapid prototyping and initial vector similarity search tests. However, scaling tops out at a single machine’s capacity, which may hinder growth.
pgvector adds zero operational overhead for teams already running PostgreSQL. While it facilitates efficient vector search within existing relational workflows, it requires a full Postgres instance as a prerequisite. This dependency prevents it from serving as a standalone, purpose-built engine for AI applications.

Decision flowchart for choosing between Milvus and VectorAI DB
| Capability | Milvus | VectorAI DB | Pinecone | Qdrant | Weaviate | ChromaDB | pgvector |
| Deployment model | Distributed (Kubernetes/Cloud) | Single-node Docker | SaaS (Cloud only) | Single-node / Distributed | Single-node / Distributed | Single-node / Distributed | SQL Extension |
| Kubernetes required | Yes (for Distributed) | No | No (managed by Pinecone) | No (for Single-node) | No (for Single-node) | No | No |
| Air-gap capable | Yes (Complex) | Yes (Native) | No | Enterprise Tier | Enterprise Tier | Yes | Yes |
| Min. production setup | 20+ Pods, etcd, MinIO | 1 Docker Container | Managed Service | 1 Docker Container | 1 Docker Container | 1 Docker Container | 1 Postgres Instance |
| Open-source | Yes | No | No | Yes | Yes | Yes | Yes |
| Minimum cost | Free (OSS) / $99+ Cloud | Free / ~$417/month for 1M vectors | Free / Usage-based | Free / $25+ Cloud | Free / $25+ Cloud | Free | Free |
| Scales beyond node | Yes | No | Yes | Yes | Yes | Yes | Yes (via Postgres) |
Wrapping Up
Milvus demands a distributed system to operate at production scale. VectorAI DB removes that layer entirely and runs as a self-contained unit within existing constraints.
For teams seeking to avoid the operational overhead of managing distributed systems like Milvus, VectorAI DB provides a streamlined alternative. VectorAI DB operates as a single unit within existing infrastructure, cutting deployment time and operational overhead while preserving query performance.
Refer to the VectorAI DB documentation and GitHub repository for updates and implementation details.
Sign up for the Actian VectorAI DB Community Edition and begin building today.

Stay connected
Data insights delivered to you.
(i.e. sales@..., support@...)