Comment Actian Vector vous aide à éliminer les cubes OLAP




Actian Vector a été rebaptisé Actian Analytics Engine en 2026.
Les cubes OLAP (traitement analytique en ligne) sont aujourd’hui largement utilisés, car plateformes nombreuses plateformes de bases de données plateformes analyser rapidement de grands volumes de données. Cela s’explique par le fait que la plupart des logiciels de bases de données n’exploitent pas pleinement la puissance de calcul et la mémoire pour offrir des performances optimales. Voici quelques-uns des symptômes de ce problème :
- Les requêtes volumineuses finissent par monopoliser les ressources du serveur.
- La réponse devient plus lente à mesure que le volume de données et le nombre d'utilisateurs augmentent.
- Il devient difficile, voire impossible, de prendre en charge les requêtes simultanées.
- Les tables agrégées ou matérialisées supplémentaires, les index et parfois même les data marts individuels ne parviennent pas à offrir les performances et simultanéité requises.
cube OLAP ont été créés pour répondre au besoin utilisateurBI d'agréger, de découper et d'analyser rapidement de grandes quantités de données pour répondre à un ensemble de questions prédéfinies. Nous allons maintenant voir comment utiliser Actian Vector, notre base de données analytique en colonnes à haute vitesse, pour éliminer l'utilisation des cubes OLAP.
Quels sont les inconvénients liés à l'utilisation cube OLAP ?
- Investissements supplémentaires en matériel et logiciels, ainsi que frais de maintenance courants.
- Il faut acquérir des compétences totalement nouvelles en langage MDX (Multi-Dimensional Expressions) pour requête cubes OLAP.
- Il impose un schéma rigide (en étoile ou en flocon de neige), alors que certains entrepôts de données de nouvelle génération support les tables support (ou les modèles ROLAP). Mais c'est toujours le schéma en étoile qui offre les meilleures performances.
- Ils limitent requête ad hoc. La conception d'cube OLAP nécessite une réflexion approfondie. Une fois le cube créé, seules les lignes et les colonnes qui y figurent peuvent faire l'objet d'une requête. Souvent, il faut créer un nouveau cube pour chaque nouvelle requête.
- Cela allonge considérablement les délais de traitement et crée goulots d’étranglement nouveaux goulots d’étranglement le cycle de vie de la BI. utilisateur de la BI utilisateur perdre un temps considérable si le cube OLAP mal conçu. La fraîcheur des données est compromise, car celles-ci doivent transiter des systèmes opérationnels vers l’entrepôt de données, cube OLAP vers le cube OLAP enfin vers outils bi.
Regarder sous le capot
Voyons ce à quoi vous renoncez avec un cube OLAP. Voici un exemple simple où les données brutes de la base de données relationnelle sous-jacente se présentent comme suit :
| Date de vente | Année | mois | décennie | ville _id | nom_de_la_ville | État | Région _id | Nom de la région | ID du produit | Nom du produit | Chiffre d'affaires |
| 1990 | 1990 | janvier | 1990-2000 | 1 | Palo Alto | CA | 1 | Ouest des États-Unis | 1 | Boulons | 20 |
| 1990 | 1990 | janvier | 1990-2000 | 1 | Palo Alto | CA | 1 | Ouest des États-Unis | 1 | Boulons | 23 |
| 1990 | 1990 | janvier | 1990-2000 | 1 | Palo Alto | CA | 1 | Ouest des États-Unis | 1 | Boulons | 15 |
| 1993 | 1993 | janvier | 1990-2000 | 1 | Palo Alto | CA | 1 | Ouest des États-Unis | 2 | marteau | 14 |
| 1993 | 1994 | mai | 1990-2000 | 2 | La Jolla | CA | 2 | Ouest des États-Unis | 3 | vis | 60 |
| 2003 | 2003 | janvier | 2000-2010 | 3 | Dallas | TX | 1 | Sud des États-Unis | 1 | Boulons | 12 |
| 1993 | 1993 | mai | 2000-2010 | 4 | Atlanta | GA | 2 | Sud des États-Unis | 3 | Vis | 34 |
| 2004 | 2004 | octobre | 2000-2010 | 5 | New York | New York | 1 | Est des États-Unis | 1 | Boulons | 35 |
| 2004 | 2004 | novembre | 2000-2010 | 6 | Boston | MA | 1 | Est des États-Unis | 1 | Boulons | 37 |
| 2004 | 2004 | décembre | 2000-2010 | 1 | Palo Alto | CA | 1 | Ouest des États-Unis | 1 | Boulons | 39 |
| 2004 | 2004 | janvier | 2000-2010 | 1 | Palo Alto | CA | 1 | Ouest des États-Unis | 1 | Boulons | 42 |
| 2004 | 2004 | février | 2000-2010 | 7 | Madison | WI | 1 | Centre des États-Unis | 1 | Boulons | 44 |
| 2004 | 2004 | mars | 2000-2010 | 8 | Chicago | IL | 1 | Centre des États-Unis | 2 | marteau | 46 |
| 2011 | 2011 | avril | 2010-2020 | 9 | Salt Lake City | UT | 2 | Ouest des États-Unis | 3 | vis | 49 |
| 2012 | 2012 | mai | 2010-2020 | 1 | Palo Alto | CA | 2 | Ouest des États-Unis | 1 | Boulons | 51 |
| 2013 | 2013 | juin | 2010-2020 | 2 | La Jolla | CA | 2 | Ouest des États-Unis | 3 | Vis | 53 |
| 2014 | 2014 | juillet | 2010-2020 | 10 | Jersey City | NJ | 2 | Est des États-Unis | 1 | Boulons | 56 |
Si un utilisateur créer un cube OLAP simple cube OLAP les ventes à partir des données ci-dessus et que les indicateurs qui l'intéressent sont les montants des ventes agrégés par décennie, par année, par produit et par région, ce cube OLAP les données suivantes :
| Décennie | Année | Nom_de_la_région | Nom du produit | Montant des ventes | Prix moyen |
| 1990-2000 | 1994 | Ouest des États-Unis | Vis | $60.00 | $19.33 |
| 1990-2000 | 1993 | Sud des États-Unis | Vis | $34.00 | $14.00 |
| 1990-2000 | 2003 | Sud des États-Unis | Boulons | $12.00 | $60.00 |
| 2000-2010 | 2004 | Centre des États-Unis | Boulons | $44.00 | $34.00 |
| 2000-2010 | 2004 | Centre des États-Unis | Marteau | $46.00 | $12.00 |
| 2000-2010 | 2004 | Est des États-Unis | Boulons | $72.00 | $44.00 |
| 2000-2010 | 2004 | Ouest des États-Unis | Boulons | $81.00 | $46.00 |
| 2000-2010 | 2011 | Ouest des États-Unis | Vis | $49.00 | $36.00 |
| 2010-2020 | 2012 | Ouest des États-Unis | Boulons | $51.00 | $40.50 |
| 2010-2020 | 2013 | Ouest des États-Unis | vis | $53.00 | $49.00 |
| 2010-2020 | 2014 | Est des États-Unis | Boulons | $56.00 | $51.00 |
| 2010-2020 | 1994 | Ouest des États-Unis | Vis | $60.00 | $53.00 |
Les données sont agrégées par décennie, année, nom_de_région et nom_de_produit. Les détails au niveau transactionnel sont perdus. C'est pourquoi certains cube OLAP les plus aboutis proposent une fonctionnalité d'exploration en profondeur permettant utilisateur consulter les données détaillées. Toutefois, les performances peuvent se dégrader si le volume de données sous-jacent à l'agrégation est important.
Une requête MDX type requête extraire ces données du cube ressemblerait à ceci, en fonction de ce que utilisateur voir apparaître dans les lignes, les colonnes et les points de données.
WITH
MEMBER[measures].[prix_moyen] AS
'[measures].[montant_des_ventes] / [measures].[nombre_de_ventes]'
SELECT
{[measures].[sales_sum],[measures].[avg price]} ON COLUMNS,
{[product].members, [year].members} ON ROWS
FROM SALES_CUBE
La mesure « Avg_price » est une mesure calculée. Notez que les mesures calculées peuvent être spécifiées dans la cube OLAP ou définies dans la requête MDX. L'un des avantages des mesures calculées définies dans les cubes OLAP est que, si la requête modifiée pour inclure un filtre ou si une dimension supplémentaire est ajoutée, la mesure calculée est automatiquement recalculée en fonction des nouveaux paramètres.
Ainsi, le cube OLAP une solution partielle à un problème : celui des bases de données relationnelles orientées lignes, qui ne sont tout simplement pas assez rapides pour les requêtes analytiques. Que demanderaient vos utilisateurs OLAP s'ils pouvaient avoir tout ce qu'ils souhaitent ? Voici les exigences que nous rapportent les utilisateurs :
- Une vitesse comparable à celle d'un système OLAP, voire supérieure, avecsupport complète requête ad hoc
- la possibilité d'utiliser le modèle de données de leur choix
- Tous leurs outils bi préférés
- Les données les plus récentes disponibles
- Accéder à toutes les données détaillées dans la même requête, sans compromettre les performances
Cela vous semble impossible ? Ce n'est pas le cas. Actian Vector peut vous offrir tout cela, et bien plus encore. Comment est-ce possible ? Poursuivez votre lecture !
Remplacer les cubes OLAP par Vector
Actian Vector est particulièrement bien placé pour remplacer les cubes OLAP. Nous l'avons entièrement conçu en intégrant de nombreuses optimisations visant à améliorer considérablement les performances des requêtes analytiques. Voici un bref aperçu de ce que nous avons mis au point :
- Traitement vectoriel: la vectorisation fait passer la parallélisation à un niveau supérieur en envoyant une seule instruction à plusieurs points de données, ce qui permet d'obtenir une réponse en temps quasi réel.
- stockage en colonnes: Le stockage en colonnes réduit considérablement les opérations d'E/S en ne chargeant requête mémoire que les colonnes requises par une requête , au lieu de charger toutes les colonnes en mémoire puis de sélectionner celles nécessaires pour répondre à la requête.
- Optimisation in-memory: l'utilisation avancée du cache du processeur et de la mémoire principale, ainsi que in-memory et la décompression in-memory , accélèrent le processus.
- Flexibilité: Vector prend en charge tous les modèles de données – en étoile, en flocon de neige, en 3NF et dénormalisés –, ce qui évite d'avoir à créer une quelconque matérialisation des données. Comme utilisateur BI utilisateur à partir de la source des données, requête n'est pas compromise.
- Richesse fonctionnelle: les fonctions OLAP/Windows avancées permettent à utilisateur poser un large éventail de questions complexes.
Passer de Cubes à Actian Vector
Pour migrer des rapports BI à partir de cubes OLAP, il est important de bien comprendre les fonctionnalités des cubes qui doivent être migrées. Il s'agit notamment :
- cube OLAP – Comprendre le modèle de données du cube lui-même et le mettre en correspondance avec le modèle SGBDR .
- les requêtes MDX, les mesures calculées et les filtres utilisés.
- KPI – Indicateurs clés de performance.
- Analyse de scénarios pour différents cas de figure.
cube OLAP
Examinez le cube OLAP déterminez sur quel type de modèle de données il repose : ROLAP, HOLAP ou MOLAP. Les modèles ROLAP s'appuient sur des modèles de données de troisième forme normale (3NF), dans lesquels les données sont fortement normalisées. En général, l'utilisation de modèles ROLAP dans les cubes entraîne une perte de performances.
HOLAP est un modèle hybride qui combine les modèles en étoile ou en flocon de neige, la dénormalisation et la 3NF. Cela entraîne également des pertes de performances.
Le MOLAP est le modèle sous-jacent le plus recherché : il utilise un modèle de données en étoile ou en flocon de neige et offre les meilleures performances. Généralement, dans un cycle de vie de la BI, les données sources sont en 3NF et doivent subir un long processus de transformation pour être converties en schéma en étoile . Il faut accepter cette contrainte initiale pour bénéficier de meilleures performances par la suite.
Si une requête utilisée au niveau de la source de données, il convient d'examiner les facteurs suivants :
- Dimensions : comment sont-elles calculées dans le Cube ? En particulier pour les modèles ROLAP et HOLAP.
- Mesures : mesures calculées et mesures standard.
- Concrètement : s'agit-il d'une seule table ou d'un ensemble de tables ?
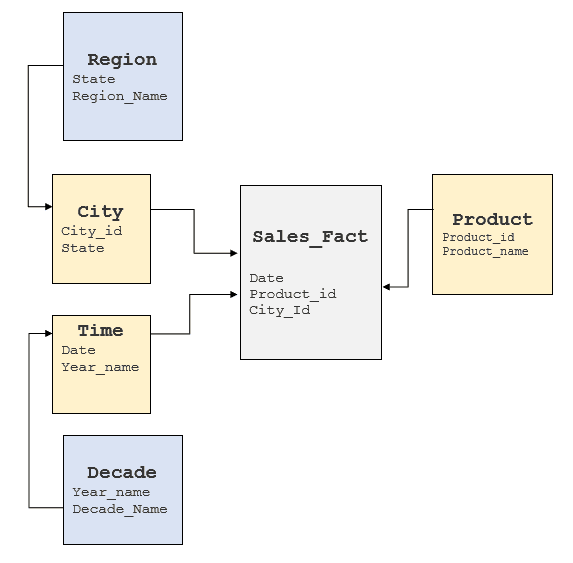
Il est important d'examiner les facteurs susmentionnés afin de bien comprendre le SGBDR sous-jacent et de déterminer où ces éléments peuvent être obtenus. En général, les entrepôts de données utilisent des modèles en étoile ou en flocon de neige, mais certains ont tendance à adopter un modèle fortement normalisé. Pour le cube ci-dessus, un modèle en flocon de neige typique se présenterait comme suit :
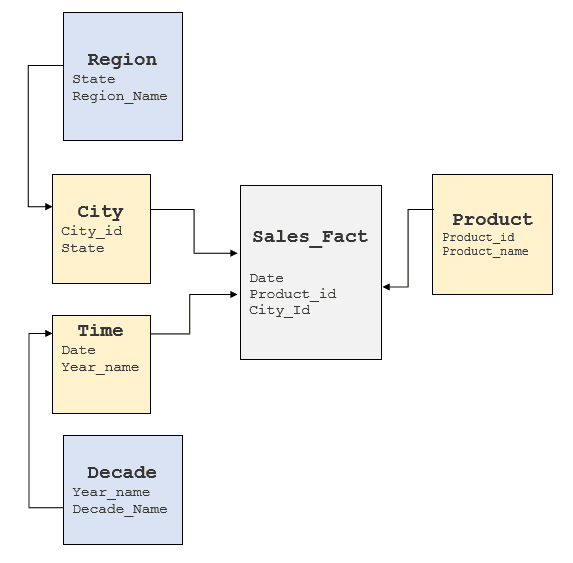
Conversion des requêtes MDX en SQL
Examinez la requête MDX requête identifiez les éléments suivants dans le cube OLAP requête MDX. Si nécessaire, consultez un tutoriel de base sur le langage MDX. Voici ce que vous devez savoir :
- Dimensions
- Mesures
- Mesures calculées
- Extraits de données ou filtres (Exemple : si utilisateur connaître les ventes concernant uniquement les « boulons » ou uniquement pour le mois de janvier.)
Prenons comme exemple la requête MDX requête la section précédente :
WITH
MEMBER[measures].[prix_moyen] AS
'[measures].[montant_des_ventes] / [measures].[nombre_de_ventes]'
SELECT
{[measures].[sales_sum],[measures].[avg price]} ON COLUMNS,
{[product].members, [year].members} ON ROWS
FROM SALES_CUBE
Où ?
- Le prix moyen est une valeur calculée
- Sales_amt est une mesure définie dans le cube
- [product].members correspond à la dimension « produit »
- [Year].members correspond à la dimension « Année »
Vous souhaitez maintenant convertir les requêtes MDX en requêtes SQL en vous basant sur le modèle ci-dessus. La requête MDX requête être réécrite en SQL comme suit :
Sélectionner year_name, product_name, sum(sales_amt) sous le nom sales, avg(sales_amt) sous le nom avg_sales à partir de Sales FT joindre Time_Dimension TD sur FT.date = TD.date joindre Month_Dimension MD sur month(TD.date) = MD.month joindre Year_Dimension YD sur year(date) = YD.year join City_Dimension RD sur FT.city_id = RD.city_id join State_Dimension SD sur FT.state_id= RD.state_id join Product PD sur FT.product_id = PD.Product_id groupé par year_name, product_name
ou bien, simplifiez requête davantage la requête en supprimant les tables de dimensions si celles-ci n'ont été introduites que pour créer le cube :
Sélectionner date_part(year, sale_date) comme year_name, product_name, sum(sales_amt) comme sales, avg(sales_amt) comme avg_sales à partir de Sales FT joint à Product PD où FT.product_id = PD.Product_id regroupé par decade, year_name, region_name, product_name
Remarque : cela ne signifie pas pour autant que les jointures avec d'autres tables puissent être totalement supprimées. Seules les tables qui ont été créées uniquement pour respecter le schéma en étoile ou en flocon de neige peuvent être supprimées.
Si l'outil BI ne propose pas de fonctions d'analyse par fenêtre, veuillez vous reporter auxfonctions analytiques etaux fonctions de fenêtre fournies par Vector afin de pouvoir les exécuter directement dans la base de données.
Si utilisateur explorer plus en détail un ensemble spécifique de lignes, l'agrégation peut être supprimée et la requête être exécutée directement dans la base de données. Par exemple, si utilisateur examiner de plus près les chiffres de vente de janvier 1993 pour le produit « Bolts », il peut utiliser la requête SQL suivante :
SELECT DATE_PART(year, sale_date) AS year_name, product_name, sales_amt AS sales FROM Sales FT JOIN Product PD ON FT.product_id = PD.Product_id WHERE Product_name = « Bolts » AND DATE_PART(year, sale_date) = « 1993 » et Date_part(month, sale_date) = « January »
Indicateurs clés de performance
Dans le jargon des affaires, un indicateur clé de performance (KPI) est un paramètre quantifiable permettant d'évaluer la réussite d'une entreprise.
Un objet KPI simple se compose des éléments suivants : des informations de base, l'objectif, la valeur réelle atteinte, une valeur d'état, une valeur de tendance et un dossier dans lequel le KPI est consulté. Les informations de base comprennent le nom et la description du KPI. Dans un cube Microsoft SQL Server Analysis Services, l'objectif est une expression MDX qui donne un résultat chiffré. La valeur réelle est une expression MDX qui donne un résultat chiffré. Les valeurs de statut et de tendance sont des expressions MDX qui donnent un résultat chiffré. Le dossier est un emplacement suggéré pour la présentation du KPI au client.
Si certains cube OLAP offrent effectivement des interfaces élégantes et conviviales pour stocker et mettre en œuvre des indicateurs clés de performance (KPI) et des actions, celles-ci peuvent tout aussi bien être mises en œuvre en combinant des fonctionnalités de base de données plus courantes et du code d'application.
Analyse de scénarios pour différents cas de figure
Certaines plateformes de cubes Fonctionnalités d'analyse de scénarios avec des interfaces conviviales. Il est également possible de mettre cela en œuvre à l'aide des fonctionnalités de la base de données et du code de l'application, moyennant un certain effort.
Ce type d'analyse nécessite de stocker divers scénarios et d'évaluer l'impact de la situation actuelle de l'entreprise par rapport à ces différents scénarios. Cette méthode est couramment utilisée dans le secteur des services financiers et du trading pour évaluer en permanence les risques et les conséquences des opérations de trading.
Il faudrait procéder à une analyse détaillée des besoins, ce qui dépasse quelque peu le cadre de cet article de blog.
Résumé
Pour les utilisateurs OLAP qui souhaitent simplifier le cycle de vie de la BI, la base de données analytique Actian Vector base de données analytique une alternative viable aux cubes OLAP grâce à sa technologie révolutionnaire, ses performances supérieures et Fonctionnalités analytiques intégrées à la base de données. La migration présente avantage réduire les coûts et d'améliorer utilisateur en matière de BI grâce à requête .
Ne vous contentez pas de me croire sur parole. Essayez-le par vous-même. Nous avons préparé un guide et une version d'évaluation de Vector, ainsi que tous les documents nécessaires pour tester Vector en une heure environ. Vous pouvez poser vos questions à notre communauté Vector très active ici.
Restez connecté
Des informations tirées des données, à votre service.
(par exemple : sales@..., support)