Ce que la « rapatriation » des services cloud de 37signals nous a appris sur l'infrastructure d'IA





Résumé
- La délocalisation hors du cloud peut permettre de réaliser des économies de plusieurs millions à grande échelle.
- Les charges de travail liées à l'IA permettent de réaliser des économies supplémentaires grâce à la réduction des coûts liés aux GPU et au stockage.
- Les déploiements sur site ou hybrides conviennent aux tâches d'inférence prévisibles et à haut débit.
- Le cloud reste adapté aux charges de travail en pics, comme apprentissage de modèles.
- Les stratégies hybrides permettent de concilier coûts, performances et conformité.
En 2023, 37signals a annoncé qu'elle avait complètement abandonné le cloud public et a ensuite publié un compte rendu de son processus de rapatriement du cloud, offrant ainsi l'un des exemples concrets les plus clairs de sur site à grande échelle. En inversant sa migration vers le cloud et en transférant ses charges de travail vers une infrastructure de cloud privé, l'entreprise a considérablement réduit ses dépenses annuelles en infrastructure cloud de près de 2 millions de dollars.
La transparence des chiffres a rendu l'argumentation convaincante. En 2022, 37signals a dépensé 3 201 564 dollars en services cloud, soit environ 266 797 dollars par mois. Ces ventilations détaillées des coûts, associées aux investissements matériels publiés et aux délais de rentabilité, ont offert un aperçu rare des mécanismes financiers d'une migration vers le cloud à grande échelle.
Pour les charges de travail SaaS standard, le calcul était simple. Mais cette même logique soulève une question importante pour la prochaine génération de systèmes à forte intensité de calcul : « Cet argument économique s'applique-t-il également aux infrastructures d'IA ? » Dans cet article, nous examinons si cette même logique économique s'applique aux infrastructures d'IA.
TL;DR
- En 2022, 37signals a dépensé environ 3,2 millions de dollars par an sur AWS.
- Après avoir rapatrié les charges de travail vers leur propre infrastructure, les dépenses liées au cloud ont chuté à environ 1,3 million de dollars en 2024.
- L'entreprise a investi entre 700 000 et 800 000 dollars dans des serveurs et a amorti cet investissement en moins de 18 mois.
- L'ensemble de l'infrastructure est toujours géré par la même équipe de dix personnes. Aucun coût opérationnel supplémentaire.
- En résumé, on peut retenir qu'à grande échelle, il peut être nettement moins coûteux de posséder ses propres infrastructures que de les louer.
Le Playbook de 37signals : ce que Hanson a réellement consigné
En 2022, 37signals a dépensé 3,2 millions de dollars par an sur AWS. Après avoir quitté le cloud en 2023, ses coûts annuels étaient tombés à environ 1,3 million de dollars en 2024, soit une réduction de près de 2 millions de dollars par an.
Cette transition a nécessité un investissement en matériel d'environ 600 000 dollars dans des serveurs Dell. L'entreprise a entièrement amorti cet investissement en moins de 18 mois, le retour sur investissement étant atteint au second semestre 2023, à l'expiration de ses contrats d'instances réservées AWS. À partir de ce moment-là, les économies réalisées ont directement contribué à la marge d'exploitation plutôt que de compenser les dépenses d'investissement.
37signals avait prévu 1,5 million de dollars de coûts matériels et environ 200 000 dollars par an de frais d'exploitation. Ce changement permet de remplacer une facture annuelle récurrente de 1,3 million de dollars pour le stockage dans le cloud par une dépense d'investissement ponctuelle, à laquelle s'ajoute une fraction des coûts d'exploitation courants. Sur cinq ans, 37signals a revu à la hausse ses prévisions d'économies totales, les faisant passer de 7 millions de dollars à plus de 10 millions de dollars.
Résultats financiers de 37signals liés à la sortie du cloud, par année
Pour illustrer l'impact financier du retrait de 37signals du cloud au fil du temps, le tableau ci-dessous présente la répartition des dépenses annuelles dépenses liées au cloud, les investissements sur site et les coûts d'exploitation, en mettant en évidence les économies nettes qui en résultent et les principales remarques opérationnelles.
| Année | Dépenses liées au cloud | Investissement en matériel | Coûts d'exploitation | Notes |
| Référence 2022 | environ 3,2 millions de dollars | $0 | Inclus dans les dépenses liées au cloud | Dépendance totale au cloud |
| Migration 2023 | environ 2 millions de dollars | environ 700 000 à 800 000 dollars | Modéré | Amortissement complet du matériel en moins de 18 mois |
| 2024 et au-delà – Après le rapatriement | environ 1,3 million de dollars | environ 1,5 million de dollars (stockage) | environ 200 000 $ par an | environ 1,9 million de dollars d'économies annuelles |
| 2025+ | Dépendance minimale vis-à-vis d'AWS | Environ 1,5 million de dollars (Pure Storage, 18 Po) | environ 200 000 $ par an | Économies prévues sur cinq ans : plus de 10 millions de dollars |
Il convient de noter que cette migration n'a pas nécessité d'élargir les effectifs de l'équipe. Une équipe d'infrastructure composée de 10 personnes a géré l'ensemble du transfert sans recruter de nouveaux collaborateurs. Répondant à une préoccupation courante concernant les coûts opérationnels, David Heinemeier Hansson, cofondateur de 37signals, a déclaré :
Cela fait maintenant un peu plus d'un an que nous avons quitté le projet, et l'équipe qui gère l'ensemble reste inchangée. Contrairement à ce que certains observateurs avaient supposé lors de notre annonce, cette sortie n'a pas charge de travail supplémentaire insoupçonnée qui nous aurait obligés à agrandir l'équipe. Toutes les réponses fournies dans notre FAQ sur la sortie de Big Cloud restent d'actualité.
Cela remet directement en cause l'idée reçue selon laquelle l'abandon des environnements de cloud public nécessite inévitablement une équipe d'infrastructure beaucoup plus importante.
La mise en œuvre a suivi une stratégie dite « d'échelle de criticité », dans le cadre de laquelle l'équipe a d'abord migré les services présentant le moins de risques, puis ceux qui étaient les plus critiques. L'équipe a transféré le système de messagerie HEY par étapes, en commençant par la mise en cache, puis la base de données et enfin les services de tâches. Afin de minimiser les risques, elle a colocalisé l'infrastructure à environ une milliseconde de la région AWS pour préserver la capacité de retour en arrière pendant le processus de rapatriement vers le cloud. Après avoir stabilisé le système, elle a remplacé les services gérés générant des coûts récurrents importants, notamment RDS et Elasticsearch géré, dont le coût annuel cumulé dépassait 500 000 dollars.
Ce qui rend cas client de 37signals particulièrement cas client , c'est la rentabilité qui a été publiquement démontrée. Pour les organisations qui s'interrogent sur les , notamment en ce qui concerne les coûts de stockage et les services gérés, la documentation de 37signals offre une base de comparaison rare.
Pourquoi les enjeux économiques liés à l'infrastructure de l'IA sont encore plus extrêmes
Les enseignements tirés du retour sur site de 37signals prennent tout leur sens lorsqu'ils s'appliquent à l'infrastructure d'IA. La hausse des coûts des GPU, les charges de travail d'inférence prévisibles, les besoins massifs en stockage d'embeddings et les réglementations plus strictes en matière de données créent des pressions financières et opérationnelles qui amplifient les avantages de sur site ou hybrides, qui vous permettent de déplacer les charges de travail là où cela s’avère le plus judicieux. Nous détaillons ci-dessous les principaux facteurs.
Comparaison des coûts des infrastructures d'IA
Afin d'évaluer les implications financières des différentes approches en matière d'infrastructure d'IA, le tableau ci-dessous compare les coûts d'installation initiaux, les frais d'exploitation mensuels pour différentes charges de travail, ainsi que les délais de rentabilité prévus pour les configurations cloud, sur site et hybrides.
| Configuration | Frais d'installation | Coût mensuel | Seuil de rentabilité |
| Location de GPU dans le cloud (AWS/Azure) | $0 | 2 900–3 500 $ (8 h/jour × 4–8 $/heure × 15 jours) | Sans objet |
| API d'inférence dans le cloud (Lambda Labs) | $0 | 1 800–2 500 $ (8 h/jour × 3,67 $/heure × 15 jours) | Sans objet |
| GPU auto-hébergé (serveur 8×H100) | 200 000 à 400 000 dollars | 1 500 à 2 000 $ (électricité + entretien) | <12 months |
| Hybride ( apprentissage dans le cloud apprentissage sur site) | 200 000 à 400 000 dollars | apprentissage , inférence minimale | <12 months |
Remarque : pour la location de GPU dans le cloud, nous estimons le coût mensuel en partant du principe d'une utilisation de huit heures par jour et par GPU. Le coût évolue de manière linéaire en fonction de l'utilisation ; il n'est pas directement liérequête.
- Les marges sur les services GPU dans le cloud sont élevées
Les charges de travail liées à l'IA dépendent fortement des GPU, et les fournisseurs de cloud facturent des tarifs bien plus élevés pour la capacité GPU que pour processeur classiques. Les instances AWS P5 à la demande équipées de GPU H100 coûtent environ 4 à 8 dollars par heure-GPU, tandis que les instances Azure H100 comparables reviennent à environ 3,67 dollars de l'heure. En revanche, les marchés spot et les fournisseurs alternatifs tels que Lambda Labs proposent une capacité GPU similaire pour 1 à 2 dollars par heure, ou 1,85 à 2,49 dollars par heure avec des engagements réservés.
Il en résulte une majoration de 4 à 8 fois supérieure pour la capacité GPU à la demande des hyperscalers par rapport au marché du cloud GPU au comptant ou spécialisé. En d'autres termes, la majoration appliquée par les fournisseurs de cloud pour les ressources de calcul IA haut de gamme est nettement plus importante que les majorations habituelles processeur . Pour les entreprises qui exécutent des charges de travail d'inférence en continu, cet écart de prix devient rapidement le principal facteur de coût dans l'infrastructure IA.
- L'inférence prévisible rend l'utilisation d'un GPU rentable
Le coût élevé des GPU revêt une importance particulière, car les charges de travail liées à l'inférence IA sont exceptionnellement prévisibles. L'achat direct de GPU H100 peut s'avérer rentable. Un seul GPU coûte environ 25 000 à 40 000 dollars, tandis qu'un serveur complet équipé de 8 GPU H100 coûte entre 200 000 et 400 000 dollars. L'analyse de Lenovo montre qu'une utilisation quotidienne continue de six heures ou plus permet d'amortir le coût par rapport à AWS dès la première année.
Si ce seuil de rentabilité est atteint aussi rapidement, c'est parce que les charges de travail liées à l'inférence IA sont exceptionnellement prévisibles. Contrairement au trafic SaaS, qui fluctue tout au long de la journée, les systèmes d'IA en production, tels que les moteurs de recommandation, ont tendance à traiter des volumes de requêtes constants.
La prévisibilité modifie la donne économique. Lorsque l'infrastructure fonctionne à un taux d'utilisation constant, le matériel détenu en propre peut être amorti efficacement sur l'ensemble de la charge de travail. Il n'est alors plus nécessaire de payer des suppléments liés au cloud pour une capacité de pointe que les équipes utilisent rarement.
Pour les entreprises qui effectuent des opérations d'inférence en continu, l'investissement matériel est souvent amorti en moins de 12 mois. À partir de là, les économies réalisées suivent la même tendance que celle observée par 37signals : une infrastructure fixe remplace une facture de location récurrente.
- Les besoins en stockage pour les systèmes embarqués sont considérables
Même si le calcul sur GPU était optimisé, les systèmes d'IA introduisent un autre poste de coûts en forte croissance : le stockage des embeddings. Les bases de données vectorielles stockent des représentations de haute dimension utilisées pour la recherche, la récupération et la recommandation. À mesure que jeux de données à des millions ou des milliards d’enregistrements, les besoins en stockage augmentent rapidement.
Par exemple, 10 millions de vecteurs de 1 536 dimensions nécessitent au moins 58 Go de stockage brut, et souvent entre 200 et 300 Go si l'on tient compte des index et métadonnées. Les services de stockage dans le cloud tels que Pinecone facturent 0,33 $/Go/mois, ce qui signifie que 500 Go pourraient coûter 165 $/mois avant même toute requête. Les solutions auto-hébergées telles que PostgreSQL avec pgvector réduisent considérablement les dépenses liées au cloud tout en gardant les données sensibles sous contrôle direct. Au fil du temps, ces besoins en stockage alourdissent les coûts d'infrastructure parallèlement au calcul GPU, renforçant encore davantage les avantages économiques des architectures auto-hébergées ou hybrides.
- La souveraineté des données et la conformité favorisentdéploiement sur site
Les réglementations relatives à la localisation des données et la conformité générale constituent des priorités dans le domaine de l'IA, alors que le secteur fait l'objet d'une réglementation de plus en plus stricte. Il convient notamment de noter que la loi européenne sur l'IA a instauré des règles strictes pour les systèmes d'IA, avec des interdictions concernant certains cas d'utilisation de l'IA qui sont entrées en vigueur en février 2025.déploiement sur site déploiement la mise en conformité.
Pour les organismes financiers confrontés à des environnements réglementaires complexes, des solutions telles que le Actian Data Intelligence Platform contribuent à renforcer gouvernance des données gouvernance à rationaliser les processus de conformité.
Études de cas sur l'infrastructure cloud : 37signals validées
Si la transparence financière dont a fait preuve 37signals lors de son départ du cloud était sans précédent, son retour n’était pas un cas isolé. Il s’inscrivait dans une tendance croissante chez de nombreuses organisations qui cherchent à reprendre le contrôle de leurs coûts et à optimiser leur infrastructure cloud. De nombreuses études de cas très médiatisées illustrent l’ampleur et les avantages économiques du transfert de charges de travail depuis les clouds publics vers des infrastructures propres ou hybrides.
Dropbox
Dropbox a été l'un des premiers à mener une opération de rapatriement des données d'entreprise vers le cloud dès 2015, et a achevé cette migration entre 2016 et 2018. L'entreprise a transféré environ 90 % des données de ses clients, soit plus de 500 pétaoctets selon certaines sources, d'AWS vers trois centres de colocation qu'elle possède. L'investissement dans l'infrastructure s'est élevé à 53 millions de dollars, mais Dropbox a déclaré avoir réalisé 74,6 millions de dollars d'économies opérationnelles sur deux ans, selon son déclaration S-1 de 2018. Une petite partie des charges de travail, principalement celles des clients européens et des services spécialisés, reste sur AWS. En interne, cette initiative était connue sous le nom de « Magic Pocket » et illustre parfaitement comment une approche de cloud hybride peut générer des économies substantielles tout en s'alignant sur les objectifs commerciaux à long terme.
Ahrefs
Ahrefs, l'éditeur d'outils de référencement, s'est appuyé sur une infrastructure de colocation à Singapour comprenant 850 serveurs. L'entreprise a déclaré avoir économisé environ 400 millions de dollars sur deux ans et demi en évitant le cloud public. Coût réel de l'infrastructure : 39,5 millions de dollars pour 850 serveurs (environ 1 500 dollars par serveur et par mois), contre un coût estimé à 447,7 millions de dollars si l'hébergement avait été entièrement assuré par AWS (soit l'équivalent d'environ 17 557 dollars par serveur et par mois). Comme le dit Ahrefs: « Nous ne serions pas rentables, ni même n'existerions, si nos produits étaient 100 % sur AWS. » Bien que les détracteurs affirment qu'Ahrefs a gonflé les estimations d'AWS, les économies réalisées sont indéniables, ce qui montre que les défis liés au rapatriement du cloud peuvent être surmontés à grande échelle grâce à une planification minutieuse.
GEICO
GEICO a passé une décennie à migrer vers plusieurs fournisseurs de cloud, mais ses coûts ont grimpé en flèche et ont dépassé les prévisions de 2,5 fois, atteignant 300 millions de dollars en 2022 pour l'ensemble des huit fournisseurs. En réponse, GEICO a commencé à transférer ses charges de travail vers un cloud privé utilisant OpenStack et Kubernetes, avec pour objectif de rapatrier plus de 50 % de ses ressources d'ici 2029. Les premiers résultats montrent une réduction de 50 % des coûts de calcul et une réduction de 60 % des coûts de stockage par gigaoctet par rapport aux services de cloud public, démontrant ainsi comment une architecture de cloud hybride peut garantir efficacité, conformité et alignement avec les objectifs commerciaux à long terme.
Akamai
Akamai était en passe en passe de dépenser plus de 100 millions de dollars en services cloud tiers avant de migrer ses charges de travail informatiques vers son propre réseau mondial en périphérie, composé de plus de 350 000 serveurs. Cette migration a permis de réaliser des économies d'environ 100 millions de dollars par an, ce qui témoigne de la rentabilité de la réinternalisation lorsque l'infrastructure existante et l'échelle d'activité sont adaptées.
Ces cas ont en commun le même schéma économique mis en évidence par 37signals. À terme, il revient moins cher d'exécuter des charges de travail prévisibles et à fort volume sur une infrastructure propre que sur les clouds des hyperscalers.
Ces exemples reflètent une évolution plus générale qui touche l'ensemble des stratégies d'infrastructure des entreprises. Les enquêtes menées par Barclays auprès des directeurs informatiques (CIO) montrent que la tendance au rapatriement du cloud est à la hausse ces dernières années, avec un pic d’intérêt prévu au second semestre 2024, où 86 % des DSI prévoient de rapatrier leurs ressources.
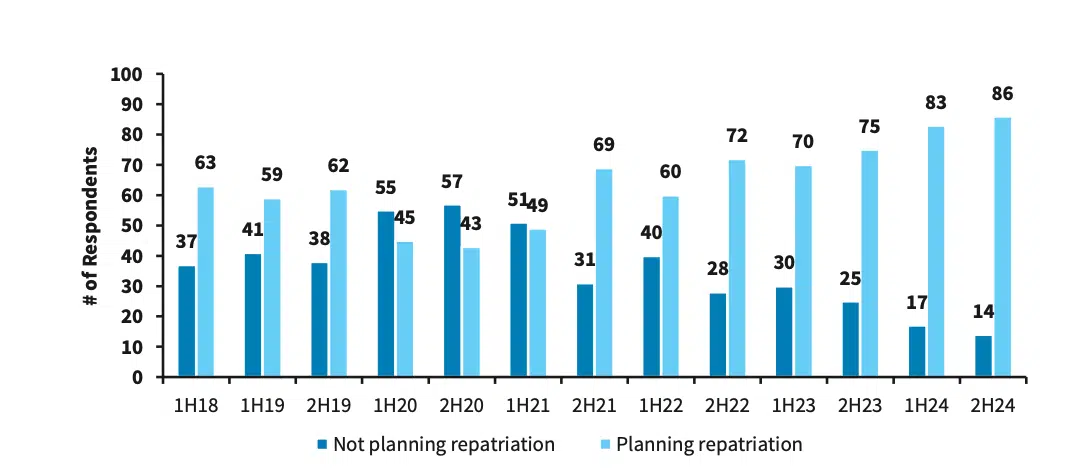
Une enquête de Barclay auprès des DSI révèle que 86 % d'entre eux prévoient de rapatrier leurs applications dans leur propre infrastructure
Cependant, cette statistique ne signifie pas pour autant que les entreprises abandonnent complètement les environnements de cloud public. Selon IDC, seules 8 à 9 % des entreprises privilégient un rapatriement complet, la plupart préférant une approche hybride combinant cloud public et cloud privé. L'infrastructure cloud hybride permet aux organisations d'optimiser charge de travail en allouant stratégiquement les données sensibles et les applications critiques sur site tirant parti des services de cloud public pour les charges de travail moins critiques. De ce fait, il est devenu de plus en plus important pour les équipes envisageant des transitions similaires de comprendre les nuances des déploiements hybrides et des risques qui y sont associés.
Statistiques sur le rapatriement des données du cloud
La rapatriation des données vers des infrastructures sur site s'accélère alors que les dépenses dans le cloud public ne cessent d'augmenter. IDC prévoit que les dépenses mondiales en cloud public atteindront 1 600 milliards de dollars en 2028, soit le double de ses prévisions pour 2024. Pourtant, comme mentionné précédemment, 86 % des DSI prévoient une forme ou une autre de rapatriement selon Barclays. Ces deux tendances peuvent coexister, car il ne s'agit pas tant d'un exode du cloud que d'un rééquilibrage. Les entreprises s'orientent vers un modèle de cloud hybride.
L'IA devrait accélérer cette évolution. Les charges de travail liées à l'IA représentent aujourd'hui moins de 10 % de la puissance de calcul totale dans le cloud, mais Gartner prévoit que ce chiffre avoisinera les 50 % d'ici 2029. Les hyperscalers réagissent en réalisant d'énormes investissements en capital. On 600 milliards de dollars de dépenses en infrastructures en 2026, dont environ les trois quarts liés à l'IA. L'hypothèse est claire : les entreprises loueront cette capacité de GPU. Mais les calculs de 37signals suggèrent qu'une fois que les charges de travail liées à l'IA passeront de la phase d'expérimentation à une production régulière, les arguments économiques en faveur de la propriété commenceront à prévaloir.
La pression sur les coûts influence déjà les comportements. Selon Flexera, 27 % des ressources cloud sont gaspillées ou sous-utilisées, et 21 % des charges de travail ont déjà été rapatriées. La principale raison invoquée est le dépassement des prévisions de coûts, suivi par des préoccupations liées aux performances. Avec les GPU, la marge d’inefficacité est plus étroite. Il y a moins de leviers d’optimisation, des tarifs horaires plus élevés et une consommation plus rapide du budget.
La réglementation ajoute une couche supplémentaire. La loi européenne sur l'IA, la directive DORA pour les services financiers, la loi chinoise PIPL et la loi indienne DPDP renforcent gouvernance des données. Mimecast indique que 87 % des organisations prennent désormais en compte la souveraineté des données dans leurs décisions relatives aux fournisseurs. Pour les systèmes d'IA, la souveraineté va au-delà de la localisation des données pour englober la provenance des modèles, les pistes d'audit et la documentation de conformité.déploiement sur site déploiement la complexité réglementaire, mais il centralise le contrôle, et pour de nombreuses entreprises, cette simplicité devient stratégiquement attrayante.
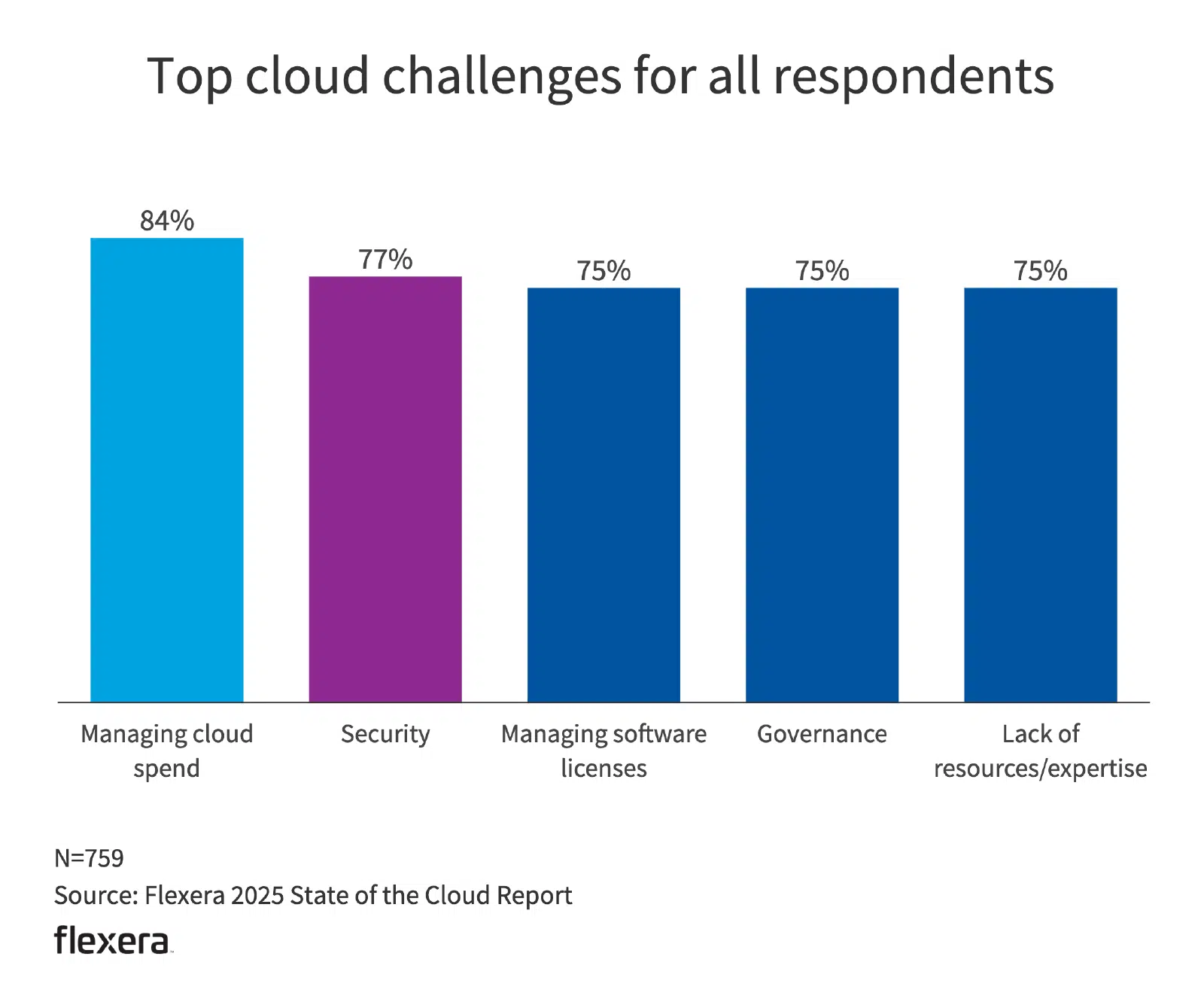
Un diagramme à barres illustrant les raisons pour lesquelles les entreprises rapatrient leurs fonds
Les contre-arguments et les cas où les fournisseurs de services cloud l'emportent
Tous les observateurs ne s'accordent pas à dire que la « rapatriation » du cloud soit la meilleure solution pour toutes les entreprises. Les environnements de cloud public continuent d'apporter de la valeur ajoutée dans certaines circonstances. Mais ces arguments ne tiennent souvent pas la route lorsqu'il s'agit de charges de travail liées à l'IA.
Quand le cloud l'emporte vs. quand l'installation sur site
| Composant | Avantages du cloud | Avantage de l'installation sur site |
| charge de travail | Gère les charges de travail irrégulières ou imprévisibles | Les charges de travail prévisibles reviennent moins cher lorsqu'elles sont hébergées en interne |
| Expertise de l'équipe | Nécessite des compétences minimales interne | Des équipes informatiques performantes peuvent optimiser les processus et réduire la dépendance vis-à-vis des fournisseurs |
| Envergure et croissance | Croissance rapide et expansion mondiale | Une croissance prévisible permet de disposer d'un matériel rentable |
| Exigences réglementaires | Gestion de la conformité, redondance géographique | Le contrôle direct facilite l'harmonisation réglementaire |
| Coûts et marges | Le paiement à l'utilisation réduit les dépenses initiales | Économies à long terme grâce à une infrastructure propre |
| Qualité du service | Les accords de niveau de service (SLA) dans le cloud garantissent la disponibilité et la performance | Des ressources dédiées garantissent une disponibilité prévisible |
L'argument de la « mauvaise utilisation » du cloud
Jeremy Daly, défenseur du « serverless », affirme que « 37signals utilisait le cloud à mauvais escient. » En traitant les environnements cloud comme de la colocation virtuelle, en exécutant des machines virtuelles et Kubernetes, ils payaient des frais supplémentaires liés au cloud sans tirer parti de la valeur du serverless, des services gérés et de la mise à l'échelle instantanée. Comme le note Daly, « Dans le cloud, nous devrions louer des services, pas des serveurs. »
Pour les charges de travail SaaS caractérisées par un trafic très variable ou ponctuel, cet argument est convaincant. L'infrastructure sans serveur permet aux entreprises de s'adapter instantanément et de ne payer que pour la puissance de calcul qu'elles utilisent réellement.
Cependant, les charges de travail liées à l'inférence IA se comportent souvent de manière très différente. Les systèmes d'inférence en production, tels que les modèles de recommandation, les copilotes et les pipelines de traitement de documents, ont tendance à fonctionner à un niveau d'utilisation constant et soutenu plutôt qu'à des pics imprévisibles. Dans ces cas-là, l'avantage économique de la mise à l'échelle élastique dans le cloud s'amenuise. Le surcoût lié à la capacité de pointe persiste, mais la charge de travail a rarement besoin de cette capacité de pointe.
L'argument de Daly s'applique donc aux charges de travail SaaS variables, pour lesquelles l'élasticité est essentielle. Pour les charges de travail d'inférence IA continues fonctionnant à un taux d'utilisation élevé, payer un supplément pour une capacité de pointe rarement utilisée peut rendre les infrastructures dédiées ou les déploiements hybrides plus rentables.
Analyse complète des coûts
Certains critiques remettent également en question les hypothèses financières qui sous-tendent l'approche de 37signals. Ils soulignent que le matériel et les logiciels ne représentent généralement qu’environ 20 % des coûts informatiques, le reste couvrant l’électricité, le refroidissement, la sécurité physique, les racks, l’alimentation sans coupure (UPS) et les coûts d’opportunité. L’analyse de David Heinemeier Hanson n’incluait pas tous ces frais généraux, car 37signals utilisait des installations de colocation plutôt que des centres de données en pleine propriété. Malgré tout, au vu des chiffres de 37signals, il est raisonnable de conclure que la location d’un espace de colocation peut rester bien moins coûteuse que le recours aux services cloud.
Cadre « Compétences contre croissance »
Le modèle de Forrest Brazeal opposant les compétences informatiques aux aspirations de croissance apporte une nuance supplémentaire. Il place 37signals dans la quadrant « Compétences élevées / Faible croissance », , idéal pour l'auto-hébergement. « Toutes les entreprises ne possèdent pas les compétences (élevées) ou les aspirations de croissance (faibles) de 37signals », observe-t-il. Les start-ups dont la charge de travail est incertaine ou irrégulière avantage la flexibilité du cloud, mais les entreprises d’IA exécutant des inférences de production à grande échelle combinent souvent une compétence opérationnelle élevée avec une croissance régulière. De tels profils (croissance régulière et compétence élevée) sont bien adaptés à la réinternalisation.
Mise en œuvre du guide pratique pour l'infrastructure d'IA
Si 37signals a fourni le cadre économique, l'infrastructure d'IA permet de concrétiser ces aspects économiques. La décision n'est plus abstraite. Elle se transforme en une évaluation structurée fondée sur charge de travail , le taux d'utilisation et les risques réglementaires.
Un cadre pratique en quatre questions permet de transposer la logique de 37signals en termes d'IA :
1. Votre charge de travail est-elle charge de travail et constante ?
Contrairement aux pics de trafic observés dans le SaaS, la plupart des systèmes d'IA en production, tels que les moteurs de recommandation, les pipelines RAG ou détection des fraudes , traitent des volumes réguliers qui augmentent progressivement.
2. Les taux d'utilisation prévus des GPU sont-ils supérieurs à 60-70 % ?
À ce stade, l'amortissement du matériel en propre revient généralement moins cher que les tarifs des GPU dans le cloud public dès la première année.
3. Traitez-vous plus de 10 à 50 millions de requêtes par mois ?
À cette échelle,requête par jeton etrequête liés aux API cloud s'accumulent rapidement.
4. Êtes-vous confronté à des exigences en matière de souveraineté des données ou de conformité stricte ?
Dans les secteurs des services financiers, de la santé ou des administrations publiques, les exigences réglementaires peuvent faire pencher la balance en faveur d'environnements contrôlés.
Si la réponse est « oui » à trois ou quatre de ces questions, les aspects économiques liés au rapatriement penchent généralement en faveurdéploiement sur site déploiement l'inférence en production.
Matrice de décision
| charge de travail | Configuration recommandée | Justification |
| apprentissage automatique | Cloud public | Tâches nécessitant une grande puissance de calcul ; les GPU dans le cloud gèrent les pics de charge de travail de manière rentable |
| Expérimentation et prototypage | Cloud public | Une mise en service flexible et rapide pour les premières itérations |
| Déduction de production | sur site hybride | Charges de travail stables ; matériel en propre plus économique avec un taux d'utilisation des GPU de 60 à 70 % ou plus |
| Stockage vectoriel (représentations) | Sur site | Réduit les coûts récurrents liés aux services gérés et garantit le contrôle des données |
Le modèle d'IA hybride
Dans la pratique, la plupart des entreprises spécialisées dans l'IA adoptent un modèle hybride plutôt qu'une transition radicale. apprentissage dans le cloud. L'inférence se rapproche davantage de l'infrastructure propre à l'entreprise.
Lenovo a estimé que apprentissage 3.1 à très grande échelle (39,3 millions d'heures de GPU) dans le cloud coûterait plus de 483 millions de dollars. C'est précisément dans ce type de scalabilité élastique à court terme que le cloud public excelle. L'inférence est différente. Une fois qu'un modèle est entraîné, son exploitation pendant trois à cinq ans devient une tâche régulière et prévisible. C'est là que l'amortissement du matériel prend le dessus.
Cette architecture segmentée réduit également les risques liés à la migration des données. Au lieu de déplacer d'un seul coup l'ensemble des pipelines d'IA, les entreprises peuvent migrer progressivement les charges de travail d'inférence en production, tout en conservant les phases d'expérimentation et apprentissage initial apprentissage des environnements cloud. Un processus de migration contrôlé et par étapes minimise les perturbations opérationnelles tout en garantissant une intégration transparente entre apprentissage basées sur le cloud apprentissage les couches sur site .
Économie de l'inférence en auto-hébergement
La rentabilité de l'inférence en mode auto-hébergé dépend fortement du taux d'utilisation et du volume de jetons. D'après déploiement en entreprise, un modèle de 7 milliards de paramètres fonctionnant sur un GPU H100 avec un taux d'utilisation d'environ 70 % coûte environ 10 000 dollars par an en nœuds spot ou en amortissement du matériel. L'électricité coûte environ 300 dollars par an, ce qui porte le coût total à environ 10 300 dollars.
En revanche, les API LLM publiques facturent généralement au million de jetons ; en 2025, les tarifs pour les entreprises varieront entre 0,25 et 15 dollars par million de jetons d'entrée et entre 1,25 et 75 dollars par million de jetons de sortie, selon le niveau du modèle et le fournisseur.
Lorsque l'utilisation est faible, les API restent l'option la plus économique, car l'infrastructure reste inutilisée. Cependant, la rentabilité évolue à mesure que les charges de travail augmentent. Selon des analyses du secteur, déploiement en interne déploiement à atteindre le seuil de rentabilité à environ deux millions de jetons par jour ; au-delà de ce seuil, le coût fixe de l'infrastructure propre à l'entreprise est amorti sur un volume important d'inférences.
À grande échelle, l'inférence en mode auto-hébergé peut permettre de réduire les coûts jusqu'à 78 %. L'analyse d'Artefact a révélé que le seuil de rentabilité se situait autour de 8 000 conversations par jour. En dessous de ce seuil, les API cloud gérées restent plus économiques. Au-delà, l'autogestion permet de réaliser des économies supplémentaires. Ce schéma reflète celui de 37signals : charge de travail prévisible charge de travail une utilisation plus élevée équivaut à un retour sur investissement rapide.
Bases de données vectorielles
Instacart a décrit sa migration d’Elasticsearch et FAISS vers PostgreSQL avec pgvector, réalisant ainsi 80 % d’économies et une réduction par dix de l’amplification d’écriture. Les tests de performance de pgvectorscale de Timescale montrent des coûts réduits d'environ 75 % par rapport aux services vectoriels gérés tels que Pinecone, pour des performances comparables.
Pour les systèmes RAG traitant des millions de requêtes chaque mois, une infrastructure vectorielle auto-hébergée permet de réaliser des économies similaires à celles observées dans le cas de 37signals et S3 : les factures de stockage récurrentes élevées sont remplacées par du matériel amorti et des outils open source.
La souveraineté des données en tant que moteur structurel
Grandview Research indique que le marché du cloud souverain représentait 648,87 milliards de dollars en 2025 et devrait atteindre 648,87 milliards de dollars d'ici 2033. De plus, selon Gartner, environ 60 % des entreprises financières hors des États-Unis devraient adopter sur site souverains ou sur site d'ici 2028.
Frameworks que la loi européenne sur l'IA, la loi chinoise sur la protection des données personnelles (PIPL) et la loi indienne sur la protection des données (DPDP) imposent la localisation et la traçabilité des données. Pour les organisations qui traitentjeux de données apprentissage sensiblesjeux de données des journaux d'inférence propriétaires,déploiement sur site réponddéploiement aux exigences de résidence, car les données ne quittent jamais les limites de la juridiction.
Le bilan
37signals a démontré que les équipes chargées de la migration hors cloud peuvent mesurer, modéliser et justifier leurs décisions à l'aide de chiffres concrets. Avec une infrastructure d'IA, les avantages économiques peuvent être encore plus marqués. Si la migration hors cloud a permis à Basecamp d'économiser environ 10 millions de dollars, une entreprise spécialisée dans l'IA menant des opérations d'inférence en production à une échelle comparable pourrait réaliser des économies plusieurs fois supérieures à ce montant, compte tenu du coût nettement plus élevé du calcul sur GPU et de l'infrastructure d'intégration.
Pour les organisations qui choisissent d'exécuter des charges de travail d'IA dans des environnements contrôlés, plateformes Actian VectorAI DB offrent une base de données vectorielle spécialement conçue pour les charges de travail de recherche vectorielle à haut débit et d'inférence IA. Elle peut être déployée sur site dans le cloud, ce qui permet aux organisations de placer leur infrastructure vectorielle là où elle répond le mieux à leurs exigences opérationnelles et économiques.
Rejoignez la communauté et découvrez-en plus sur Actian.

Restez connecté
Des informations exploitables à votre disposition.
(par exemple, sales@..., support)