Le coût caché des modèles de tarification des bases de données vectorielles





Résumé
- La tarification « basée sur l'utilisation » de Vector DB inclut désormais des minimums mensuels, transformant ainsi des charges de travail stables en hausses soudaines des coûts.
- Les coûts cachés (intégration, reclassement, sauvegardes, réindexation et sortie) peuvent doubler les dépenses réelles de production.
- requête augmentent souvent proportionnellement à la taille de l'index. Ainsi, une même recherche peut coûter 10 fois plus cher lorsque le volume de données passe de 10 Go à 100 Go.
- Lorsque requête est élevé et prévisible, l'auto-hébergement peut réduire les coûts de 50 à 75 % et améliorer la prévisibilité des dépenses.
- Choisissez les modèles de tarification dès le début : les mécanismes de facturation doivent influencer l'architecture et ne pas vous surprendre après le lancement.
Pendant longtemps, la tarification basée sur l'utilisation semblait être le moyen le plus sûr d'exploiter une nouvelle infrastructure. L'intérêt était de commencer modestement, de payer très peu et de ne laisser les coûts augmenter que si le produit faisait ses preuves. Pour les équipes qui expérimentaient la recherche sémantique ou les premiers systèmes de recherche, ce compromis était logique, en particulier lorsque les engagements fixes en matière d'infrastructure semblaient plus risqués que les modèles d'utilisation incertains.
Ce sentiment de sécurité a commencé à s'estomper en 2025, lorsque plusieurs fournisseurs de bases de données vectorielles ont introduit des prix planchers et des minimums. Pinecone a annoncé un minimum de 50 dollars par mois, Weaviate a mis en place un prix plancher de 25 dollars par mois, et des changements similaires se sont répercutés sur l'ensemble du marché des bases de données vectorielles gérées.
Les petites charges de travail régulières ont soudainement connu des changements radicaux en termes de coûts, sans augmentation correspondante de l'activité, une tendance qui reflète une évolution plus large dans le paysage SaaS. L'infrastructure de base de données vectorielle toujours active ne correspond plus à l'économie des tarifs mensuels à un chiffre. Les coûts d'abonnement SaaS de plusieurs grands fournisseurs ont augmenté de 10 % à 20 % en 2025, dépassant les prévisions de croissance du budget informatique de 2,8 %, selon Gartner.
Aujourd'hui, les bases de données vectorielles alimentent des systèmes de production à grande échelle. Elles exécutent des recherches sémantiques, des recommandations, des copilotes et des outils de connaissances internes. Les volumes de données restent relativement stables et les modèles de trafic suivent des courbes prévisibles. Pourtant, pour de nombreuses organisations, l'infrastructure de recherche vectorielle est devenue l'un des centres de coûts les plus volatils de la pile. Non pas parce que l'utilisation varie énormément, mais parce que les modèles de tarification des bases de données vectorielles se comportent différemment une fois que les systèmes ont atteint leur maturité.
TL;DR
- Les bases de données vectorielles natives du cloud affichent des prix minimaux bas et une flexibilité basée sur l'utilisation, mais les coûts de production racontent une autre histoire.
- Les frais cachés (intégration, réindexation, sauvegardes) peuvent doubler votre facture.
- requête évoluent en fonction de jeu de données , ce qui signifie qu'une même requête 10 fois plus coûteuse lorsque vous passez de 10 Go à 100 Go.
- Le changement tarifaire d'octobre 2025 a introduit un minimum de 50 dollars, entraînant une augmentation des coûts de 400 à 500 % pour les charges de travail stables.
- Avec 60 à 100 millions de requêtes par mois, l'auto-hébergement devient 50 à 75 % moins cher que le cloud.
- Le modèle de tarification doit être une décision architecturale, et non une réflexion après coup.
Ce que les pages de tarification omettent de mentionner
Les pages consacrées aux tarifs des bases de données vectorielles privilégient l'adoption plutôt que la modélisation des coûts à long terme. Leur objectif est de faciliter l'adoption, et non de vous expliquer comment la facture est calculée après la mise en service du système. La plupart des pages mettent en avant un ensemble de chiffres familiers : stockage par gigaoctet, unités de lecture et d'écriture, et un minimum mensuel peu élevé. Les niveaux gratuits sont présentés comme suffisants pour démarrer, ce qui donne l'impression que l'expérimentation comporte peu de risques.
Ce que ces pages expliquent rarement, c'est comment ces éléments interagissent une fois que l'utilisation se stabilise. Elles ne modélisent généralement pas la façon dont requête évoluent à mesure que jeux de données , comment l'activité d'écriture s'accumule au fil du temps, ou comment des parties importantes du workflow entièrement en dehors de la base de données. Les exemples de tarification de Pinecone excluent l'importation initiale des données, l'inférence pour les intégrations et le reclassement, ainsi que l'utilisation de l'assistant. Le calculateur de prix de Weaviate omet de la même manière les coûts de sauvegarde et les frais de sortie des données. Les estimations de Qdrant ne tiennent pas compte des frais généraux liés à la réindexation. Les mêmes fournisseurs qui dominent toutes les listes de comparaison sont désormais confrontés à des questions sur la viabilité de leurs tarifs. Ces avertissements sont présents, mais faciles à ignorer lorsque l'on se concentre sur la livraison d'une preuve de concept.
Un schéma prévisible se répète. Quelqu'un utilise la calculatrice et établit un budget mensuel. Le système est mis en service. Quelques semaines plus tard, la facture est deux à quatre fois plus élevée que prévu. Rien n'est cassé, aucun pic de trafic n'est survenu. La base de données fonctionne exactement comme prévu. La page des tarifs ne décrivait tout simplement pas le coût total de son fonctionnement.
Comment fonctionne la tarification basée sur l'utilisation (et pourquoi elle devient coûteuse)
La tarification basée sur l'utilisation réduit les risques pendant la phase d'expérimentation, lorsque le trafic est inconnu. Le problème est que les bases de données vectorielles en production sont rarement imprévisibles.
Une fois qu'un système est opérationnel, la plupart des équipes d'ingénieurs ont une bonne compréhension de la taille des données et requête de base. Ce qui leur manque, c'est un moyen fiable de prévoir la facture du mois suivant, car les bases de données vectorielles gérées facturent simultanément plusieurs dimensions : stockage, écritures et requêtes.
Chaque coût suit sa propre courbe et aucun ne correspond exactement à utilisateur . Ce qui prend les équipes de développement au dépourvu, c'est requête . Dans de nombreux modèles, requête augmente à mesure que le jeu de données , même lorsque la requête reste inchangée.
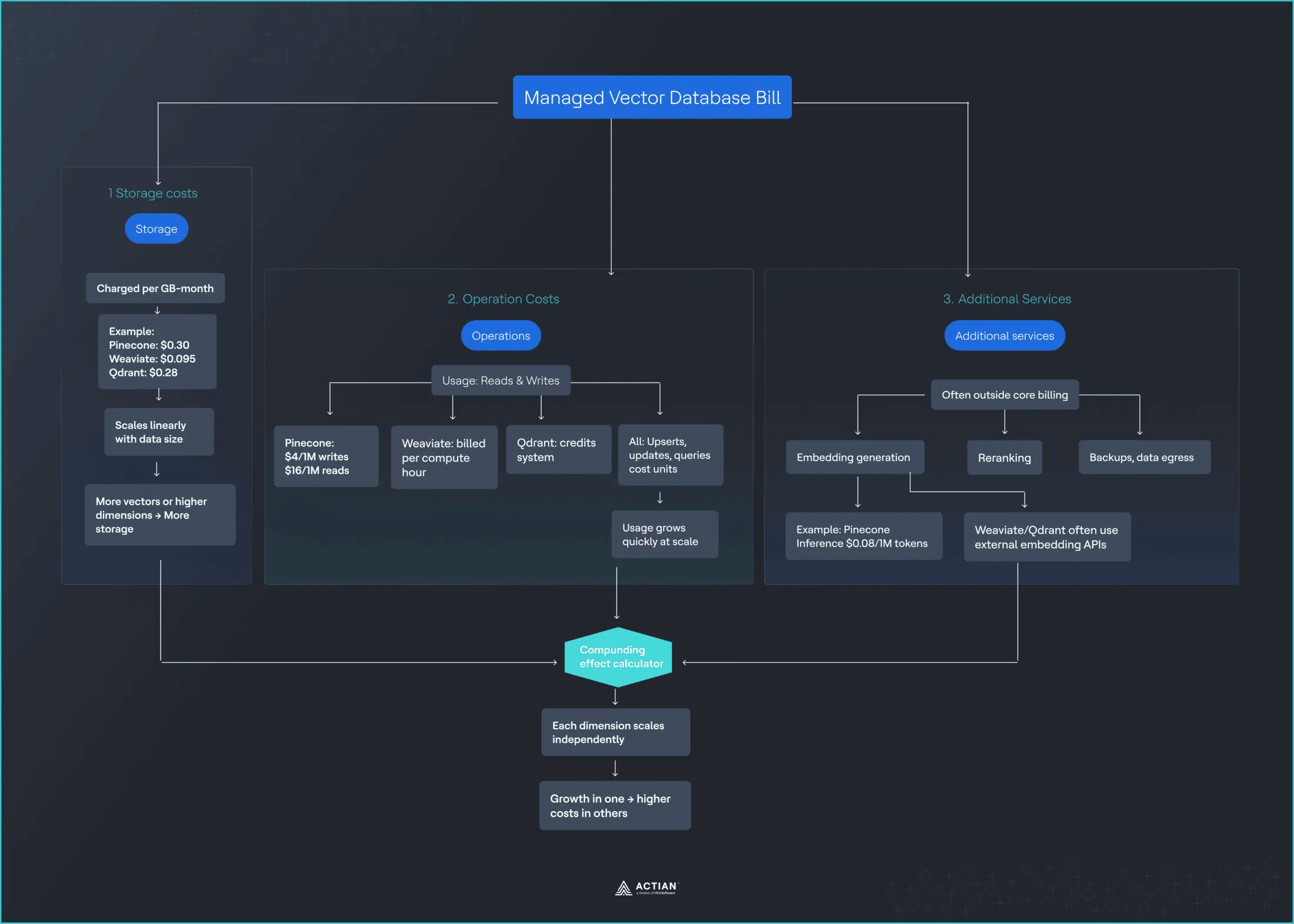
Les trois facteurs de coûts que vous payez réellement
Les bases de données vectorielles gérées facturent selon trois critères principaux, bien que les tarifs exacts varient selon les fournisseurs :
Stockage
- Pinecone : 0,30 $/Go/mois.
- Weaviate : 0,095 $/Go/mois.
- Qdrant : 0,28 $/Go/mois.
- Évolue de manière linéaire à mesure que votre jeu de données .
- Plus de dimensions vectorielles = facture plus élevée.
Opérations
- Pinecone : unités d'écriture (4 $/million), unités de lecture (16 $/million).
- Weaviate : par heure d'unité de calcul (variable).
- Qdrant : Système basé sur le crédit.
- Chaque upsert, mise à jour et requête des unités.
- Les opérations de recherche vectorielle s'accumulent rapidement à grande échelle.
Services supplémentaires
- Génération d'intégration : Pinecone Inference (0,08 $/million de jetons).
- Weaviate/Qdrant : nécessite des services externes (OpenAI, Cohere).
- Le reclassement, les sauvegardes et le transfert de données sont facturés séparément.
- Ajoute une autre relation fournisseur et un autre flux de coûts.
Chaque dimension de coût évolue indépendamment, et leur interaction crée des effets cumulatifs que les calculateurs de prix capturent rarement. Pour comprendre pourquoi ces coûts se cumulent, il faut examiner le fonctionnement réel de la recherche vectorielle, en particulier l'indexation HNSW.
Pourquoi les coûts augmentent à mesure que vous évoluez
Les augmentations de coût découlent directement du fonctionnement interne de la recherche vectorielle.
Comment fonctionne HNSW
La plupart des bases de données vectorielles de production utilisent des algorithmes de voisinage approximatif (ANN) tels que HNSW (Hierarchical Navigable Small World) afin de faciliter les recherches à grande échelle.
HNSW construit un graphe multicouche dans lequel chaque couche représente des vecteurs à différents niveaux de granularité, organisant ainsi des millions de dimensions vectorielles en une structure efficace.
L'impact sur les coûts
La documentation de Pinecone indique qu'une requête 1 RU par 1 Go d'espace de noms, avec un minimum de 0,25 RU par requête. À mesure que votre jeu de données , le graphique s'agrandit également :
| jeu de données | RU par requête | Coût : 16 $/M RU | Même requête, coût différent |
|---|---|---|---|
| 10 Go | 10 RU | $0.00016 | Référence |
| 100 Go | 100 RU | $0.0016 | 10 fois plus cher |
| 1 To | 1 000 RU | $0.016 | 100 fois plus cher |
Résultat : un coût dix fois plus élevé pour la même requête, avec une qualité de résultat identique.
À 16 dollars par million d'unités lues, les coûts augmentent de manière linéaire avec la croissance des données, mais les fonctionnalités offertes aux utilisateurs restent les mêmes. requête de recherche requête le même nombre de résultats avec la même précision, que votre index soit de 10 Go ou de 100 Go. Vos utilisateurs ne voient aucune différence, mais vous payez 10 fois plus. C'est à ce moment-là que la croissance commence à être perçue comme une pénalité. La structure du graphe doit traverser davantage de dimensions vectorielles à mesure que votre index s'étend, et vous payez pour chaque opération supplémentaire.
Le niveau gratuit qui n'est pas vraiment gratuit
Le niveau gratuit permet une expérimentation précoce, mais ne permet pas de prédire la rentabilité de la production. Lorsque vous atteignez les limites, les coûts de migration ne sont plus théoriques. La migration est perçue comme coûteuse, et les gens acceptent des prix qu'ils auraient remis en question auparavant.
| Fournisseur | Limites du niveau gratuit | Réalité de la production | Il est temps de dépasser |
|---|---|---|---|
| Pomme de pin | 2 Go, 1 million de lectures, 2 millions d'écritures (une seule région) | Plus de 60 Go, plus de 5 millions de lectures en moyenne | 2 à 4 semaines |
| Weaviate | 1 million de vecteurs, calcul limité | Plus de 10 millions de vecteurs standard | 1 à 3 semaines |
| Qdrant | 1 Go de stockage | Plus de 60 Go de stockage commun | 1 à 2 semaines |
Le changement de tarification d'octobre 2025 qui a tout changé
Ces problèmes structurels sont devenus impossibles à ignorer lorsque Pinecone a procédé à un changement significatif de sa tarification. À la fin de l'année 2025, les changements de tarification opérés par les principaux fournisseurs de bases de données vectorielles ont clairement montré que le modèle de paiement à l'utilisation (PAYG) ne tenait pas toujours une fois que les systèmes atteignaient une production stable. Le signal le plus visible est apparu en octobre, lorsque Pinecone a mis en place un minimum mensuel de 50 dollars pour tous les forfaits Standard payants.
Pour les organisations qui dépensaient déjà bien plus que ce montant, le changement est passé presque inaperçu. Pour les charges de travail plus modestes mais stables, la situation était différente. Certains groupes avaient délibérément conçu leur utilisation de manière à rester en dessous de 10 dollars par mois.
Il ne s'agissait pas de projets abandonnés, mais d'outils internes, de fonctionnalités de production préliminaires et de systèmes destinés à un petit nombre de clients qui étaient déjà stabilisés. Leur utilisation est restée stable, mais dans certains cas, l'introduction de prix minimums a entraîné une multiplication par cinq à dix des coûts mensuels.
Ce qui a rendu ce moment important, ce n'était pas le montant en dollars. C'était l'introduction d'un seuil minimum fixe dans un modèle commercialisé comme étant basé sur la consommation. Une faible utilisation ne garantissait plus un faible coût. Une fois cette hypothèse remise en cause, les minimums ont cessé d'être considérés comme des cas particuliers et ont commencé à apparaître comme un risque structurel.
| Coût mensuel précédent | Nouveau minimum | Augmenter |
|---|---|---|
| $8 | $50 | 525% |
| $12 | $50 | 317% |
| $25 | $50 | 100% |
La migration forcée
Pour tous ceux qui se situaient en dessous du nouveau minimum de 50 dollars, la migration était rarement planifiée. Elle était réactive. Les propriétaires de plateformes devaient évaluer les alternatives, exporter les données, reconstruire les index et valider requête dans l'urgence. Dans certains cas, l'effort d'ingénierie nécessaire à la migration dépassait les économies annuelles réalisées grâce au changement de fournisseur. Beaucoup ont tout de même décidé de migrer, car l'alternative consistait à s'engager dans une tarification qui ne correspondait plus à la charge de travail.
L'impact du changement de tarification s'est fait sentir dans toutes les communautés de développeurs. L'un d'entre eux a rendu publique son expérience de migration, indiquant qu'il avait réussi à maintenir ses factures sous la barre des 10 dollars par mois en ne stockant que les données essentielles dans la base de données vectorielle. L'annonce faite en septembre 2025 d'un minimum mensuel de 50 dollars, quelle que soit l'utilisation réelle, a immédiatement déclenché la recherche d'alternatives.
Le calcul de migration s'est avéré difficile. Le passage à Chroma Cloud a été retenu, mais le processus a révélé des préoccupations plus profondes concernant les modèles de tarification sans serveur. Comme l'a fait remarquer le développeur, ils recherchaient une solution véritablement sans serveur dans laquelle les coûts évoluent de manière linéaire en fonction de l'utilisation, à partir de 0 $. Le minimum de 50 $ a éliminé cette possibilité.
Ce schéma s'est répété sur les fils Reddit et les forums de développeurs. Un fil de discussion intitulé « Le nouveau minimum de 50 $ par mois de Pinecone vient de mettre fin à mon projet amateur » a bien résumé le sentiment général. Les équipes gérant des charges de travail stables et à faible volume ont dû faire un choix : accepter une augmentation des coûts de 400 à 500 % ou investir du temps d'ingénierie dans la migration.
Le problème ne résidait pas dans le montant absolu en dollars. Pour de nombreuses équipes, 50 dollars par mois restaient abordables. Le problème était le précédent. Si un fournisseur pouvait introduire sans préavis un minimum qui quintuplait les coûts, qu'est-ce qui empêcherait de nouvelles augmentations à l'avenir ? Le changement de tarification a transformé le choix du fournisseur d'une décision technique en un calcul de gestion des risques.
Quelques tendances se sont répétées au cours de ces migrations. La prévisibilité des prix a commencé à primer sur la commodité gérée. Les options open source et auto-hébergées ont refait surface dans les discussions qui, auparavant, se concentraient exclusivement sur le cloud. Le risque lié aux prix pratiqués par les fournisseurs est devenu une préoccupation architecturale de premier ordre. Ces migrations n'ont pas été motivées par une insatisfaction vis-à-vis des fonctionnalités ou des performances. Elles ont été motivées par des considérations économiques.
Ce que cela révèle sur le pouvoir de fixation des prix des fournisseurs
Une fois qu'une base de données vectorielle est déployée en production, les fournisseurs peuvent ajuster leurs tarifs d'une manière qui affecte considérablement les clients, même si l'utilisation reste inchangée.
La tarification basée sur l'utilisation réduit les obstacles à l'adoption, mais elle augmente les coûts de transition au fil du temps, à mesure que les API deviennent Embarqué, que les formats de données se solidifient et que les migrations deviennent coûteuses.
Pour le leadership en ingénierie, la question d'évaluation change :
- Était : « Combien cela coûte-t-il aujourd'hui ? »
- Devenu : « Dans quelle mesure sommes-nous exposés aux variations de prix une fois que cela sera en production ? »
Scénarios de coûts réels (ce que vous paierez réellement)
Comprendre ces dynamiques de manière abstraite est une chose. Voir comment elles se manifestent dans les systèmes de production réels en est une autre.
Pour avoir une vue d'ensemble, examinons trois scénarios de production courants et comparons les coûts des principaux fournisseurs.
Scénario 1 : Système support à la clientèle
Imaginez un support à la clientèle basé sur l'historique des tickets, la documentation interne et les articles d'aide. À ce stade, vous pourriez avoir à traiter environ 10 millions de vecteurs (généralement 768 ou 1536 dimensions vectorielles) et environ cinq millions de requêtes par mois.
| Coût mensuel précédent | Nouveau minimum | Augmenter |
|---|---|---|
| $8 | $50 | 525% |
| $12 | $50 | 317% |
| $25 | $50 | 100% |
Conclusion principale : même à petite échelle, les coûts réels sont 3 à 5 fois plus élevés que les estimations de base du calculateur en raison des minimums et des structures tarifaires complexes.
Scénario 2 : Moteur de recommandation pour le commerce électronique
À mesure que les systèmes se développent, la dynamique des coûts devient plus prononcée. Avec environ 100 millions de vecteurs et des dizaines de millions de requêtes par mois, les coûts augmentent rapidement. Les catalogues de produits, les intégrations utilisateur et la personnalisation en temps réel génèrent un trafic soutenu et des mises à jour fréquentes.
| Fournisseur | Stockage | Requêtes | Écrit | Intégrations | Frais généraux | Total |
|---|---|---|---|---|---|---|
| Pomme de pin | $180 | $192 | $8 | 200 à 300 dollars | 50 à 80 dollars | 1 500 à 2 500 dollars |
| Weaviate | $57 | Calcul : 800 à 1 000 dollars | Inclus | 200 à 300 dollars | 40 à 60 dollars | 1 400 $ à 2 200 $ |
| Qdrant | $168 | Crédits : 600 à 900 dollars | Inclus | 200 à 300 dollars | 40 à 60 dollars | 1 300 $ à 2 100 $ |
Conclusion principale : à moyenne échelle, les coûts convergent entre les différents fournisseurs. Les frais d'intégration dépassent souvent les coûts de base de la base de données.
Scénario 3 : Plateforme SaaS multi-locataires
L'économie change radicalement à l'échelle de l'entreprise. Avec 500 millions de vecteurs et 100 millions de requêtes par mois, la tarification basée sur l'utilisation devient structurelle. Ces grands jeux de données des intégrations vectorielles à haute dimension pour de nombreux clients.
| Fournisseur | Stockage | Requêtes | Écrit | Intégrations | Support | Total |
|---|---|---|---|---|---|---|
| Pomme de pin | $921 | $1,200 | 100 à 150 dollars | 500 à 700 dollars | 300 à 500 dollars | 2 500 à 4 000 $ et plus |
| Weaviate | $292 | Calcul : 2 000 à 3 000 dollars | Inclus | 500 à 800 dollars | 200 à 400 dollars | 3 000 à 4 500 dollars |
| Qdrant | $860 | Crédits : 1 500 à 2 200 dollars | Inclus | 500 à 800 dollars | 200 à 400 dollars | 2 900 $ à 4 200 $ |
Conclusion principale : à l'échelle de l'entreprise, les coûts annuels atteignent 30 000 à 54 000 dollars. C'est là que l'autohébergement devient économiquement intéressant.
Comparaison côte à côte des fournisseurs
Pour clarifier les aspects économiques, voici comment les principaux fournisseurs de bases de données vectorielles se positionnent selon les critères les plus importants pour les déploiements en production :
| Fonctionnalités | Pomme de pin | Weaviate | Qdrant | PostgreSQL + pgvector |
|---|---|---|---|---|
| Modèle de tarification | Basé sur l'utilisation | Basé sur l'utilisation | Basé sur l'utilisation | Auto-hébergé (fixe) |
| Minimum mensuel | $50 | $25 | Aucun | Aucun |
| Coût de stockage | 0,30 $/Go | 0,095 $/Go | 0,28 $/Go | Coût du matériel uniquement |
| requête | Échelles avec données | Basé sur le calcul | Basé sur le crédit | Gratuit dans la limite des capacités disponibles |
| Coût supplémentaire | Beaucoup | Modéré | Certains | Aucun |
| Prévisibilité des coûts | Faible | Faible-Moyen | Moyen | Haut |
| Coût du scénario 1 | 350 à 500 dollars | 300 à 400 dollars | 280 à 380 dollars | Environ 200 à 300 dollars |
| Coût du scénario 2 | 1 500 à 2 500 dollars | 1 400 $ à 2 200 $ | 1 300 $ à 2 100 $ | Environ 800 à 1 200 dollars |
| Coût du scénario 3 | 2 500 à 4 000 $ et plus | 3 000 à 4 500 dollars | 2 900 $ à 4 200 $ | Environ 1 500 à 2 000 dollars |
| Idéal pour | Prototypage rapide | Recherche hybride | Équipes natives K8s | Stable, haut volume |
Les frais cachés qui ne figurent pas dans le calculateur
Ces scénarios révèlent une tendance constante : les prix annoncés reflètent rarement le coût total. Les systèmes de recherche vectorielle de production entraînent des coûts qui sont rarement pris en compte de manière exhaustive par les calculateurs. Il est essentiel de comprendre ces coûts cachés pour établir un budget précis.
Frais d'intégration et d'inférence
Pinecone Inference facture 0,08 $ par million de jetons pour la génération d'intégrations vectorielles. Weaviate et Qdrant ne fournissent pas de services d'intégration natifs, vous obligeant à recourir à des fournisseurs externes tels que OpenAI (à partir de 0,10 $ par million de jetons) ou Cohere.
La conversion de documents en vecteurs entraîne des coûts supplémentaires qui s'ajoutent aux opérations de base de données sur toutes plateformes. Le reclassement entraîne des frais supplémentaires par demande. Cohere-rerank-v3.5 ne propose aucune demande gratuite, quel que soit le niveau, ce qui signifie que chaque opération de reclassement est facturée.
Ces coûts d'intégration et d'inférence peuvent égaler ou dépasser le coût de la base de données elle-même, en fonction du taux de rotation des données et requête . Chaque fois que vous générez de nouvelles intégrations vectorielles ou que vous mettez à jour celles qui existent déjà, vous payez en plus de vos coûts de stockage vectoriel de base.
Coûts de réindexation (le tueur silencieux)
L'impact financier devient particulièrement important lorsque vous devez changer d'approche. Lorsque vous changez de modèle d'intégration, vous devez revectoriser toutes les données. Pour un jeu de données de 100 millions de vecteurs, cela peut signifier :
- Coûts d'intégration : 8 000 à 15 000 dollars (coût unique).
- Augmentation des unités d'écriture pendant la migration.
- Temps de traitement et surcoût informatique.
L'expérimentation avec des modèles devient extrêmement coûteuse, ce qui crée un verrouillage sur les choix d'intégration initiaux. Le coût de la génération d'intégrations vectorielles à grande échelle rend risquée l'amélioration de votre système.
support
Support entraînent des coûts importants pour tous les fournisseurs gérés. L'assistance de Pinecone support sont des forums communautaires gratuits à 499 $ par mois pour une couverture 24h/24 et 7j/7. Weaviate facture 500 $ par mois pour son support professionnelle. support aux entreprises de Qdrant support à des niveaux similaires.
| Niveau | Pomme de pin | Weaviate | Qdrant |
|---|---|---|---|
| Gratuit | Communauté uniquement | Communauté uniquement | Communauté uniquement |
| Développeur | 29 $ par mois | Sans objet | Sans objet |
| Pro/Entreprise | 499 $ par mois | 500 $ par mois | Personnalisé |
Coûts de distribution géographique
déploiement multirégional déploiement l'optimisation de la latence ajoute des coûts de transfert de données, des frais généraux liés à l'infrastructure régionale et peut augmenter les coûts de base de 30 à 50 % selon la configuration. L'exécution d'une recherche vectorielle dans plusieurs régions de fournisseurs de cloud ajoute à ces dépenses.
Quand l'auto-hébergement devient 75 % moins cher
Compte tenu de ces coûts cachés et de la volatilité des prix, de nombreuses équipes finissent par se retrouver à la croisée des chemins. À un certain stade, le prix des bases de données vectorielles cesse d'être une question de commodité pour devenir une question économique. Ce stade est généralement atteint plus tôt que beaucoup ne le pensent.
Les benchmarks de Timescale montrent que PostgreSQL + pgvector est 75 % moins cher que Pinecone, tout en offrant une latence P95 28 fois plus rapide que le niveau optimisé pour le stockage de Pinecone. Le seuil à partir duquel l'auto-hébergement devient nettement moins cher se situe généralement entre 60 et 100 millions de requêtes par mois.
Le point de croisement des coûts
- Moins de 10 millions de requêtes par mois :
- 10 à 60 millions de requêtes par mois :
- 60 à 100 millions de requêtes par mois : l'auto-hébergement devient 50 à 75 % moins cher. À ce volume, le calcul devient difficile à ignorer.
Ce que coûte réellement l'auto-hébergement
- Serveur : 400 à 800 $ par mois.
- Configuration : environ 40 heures de travail initial (4 000 à 8 000 dollars en une seule fois).
- Maintenance continue : 10 à 15 heures/mois (1 500 à 2 250 dollars/mois en temps d'ingénierie).
- Pile de surveillance : 50 à 200 $ par mois.
- Stockage de sauvegarde : 100 à 300 $ par mois.
Total : environ 2 050 à 3 550 dollars par mois, contre 5 000 à 10 000 dollars ou plus pour Pinecone à l'échelle de l'entreprise.
Économies nettes : 2 950 $ à 6 450 $ par mois = 35 000 $ à 77 000 $ par an.
Les calculs deviennent plus convaincants à mesure que vous évoluez. Avec jeux de données grands jeux de données des centaines de millions de dimensions vectorielles, l'écart se creuse considérablement.
Avantages en termes de performances au-delà du coût
Les arguments économiques sont solides, mais les performances comptent également. Les benchmarks de Timescale démontrent que PostgreSQL avec pgvector atteint une latence P95 28 fois inférieure à celle du niveau de stockage de Pinecone : 63 ms contre 1 763 ms. De plus, PostgreSQL atteint requête 16 fois supérieur avec un rappel de 99 %.
Au-delà des performances, l'auto-hébergement offre :
- Contrôle : optimiser votre charge de travail spécifique charge de travail les dimensions du vecteur.
- Pas de limitation ni de restriction de débit.
- Avantages en matière de souveraineté des données et de conformité.
- Évolutivité prévisible où les coûts sont liés à la capacité et non à l'utilisation.
- Flexibilité de recherche hybride permettant de combiner la recherche vectorielle avec les requêtes traditionnelles.
Le coût caché du gratuit et du sans serveur
Les niveaux gratuits et la tarification sans serveur sont conçus pour inspirer confiance. Ils réduisent les frictions, diminuent l'engagement initial et facilitent le démarrage de la création. Dans la pratique, ils retardent souvent la visibilité des coûts plutôt que de l'éliminer.
Le « serverless » ne signifie pas que l'infrastructure est gratuite. Cela signifie que l'infrastructure est abstraite et facturée indirectement en fonction de l'utilisation. Pour les charges de travail régulières, cette abstraction a généralement un coût élevé. Chaque requête, chaque vecteur stocké, chaque actualisation d'intégration et chaque opération en arrière-plan est mesurée. Au fil du temps, la commodité remplace la prévisibilité.
Les niveaux gratuits suivent un schéma similaire. Ils sont utiles pour l'expérimentation, mais ne sont pas représentatifs de l'économie de production. Lorsque les limites sont atteintes, le travail d'intégration est déjà terminé, les API sont Embarqué et la migration semble coûteuse. À ce stade, les équipes ont tendance à accepter des tarifs qu'elles auraient contestés auparavant.
Une méthode pratique pour choisir
Une fois que la volatilité des prix apparaît, la question n'est plus de savoir quelle base de données est la moins chère aujourd'hui. Il devient évident quel modèle de tarification fonctionne encore une fois que le système se stabilise.
Trois facteurs sont les plus importants :
- Échelle : nombre de vecteurs stockés, nombre de requêtes exécutées par mois et vitesse à laquelle ces chiffres augmentent.
- Prévisibilité : l'utilisation est-elle irrégulière et incertaine, ou stable et prévisible pour les six à douze prochains mois ?
- Contrôle : la quantité de responsabilités opérationnelles que votre équipe peut réellement assumer et la sensibilité de l'entreprise aux écarts budgétaires.
Au début, les services cloud gérés sont généralement pertinents. Ils optimisent la vitesse, l'expérimentation et la demande inconnue. À mesure que les charges de travail se stabilisent et que requête atteignent des dizaines de millions par mois, la tarification basée sur l'utilisation commence à perdre son avantage. Les coûts augmentent plus rapidement que la valeur, et les prévisions deviennent plus difficiles, et non plus faciles.
Au-delà d'environ 60 à 100 millions de requêtes par mois, de nombreuses équipes atteignent un point de basculement. À cette échelle, sur site auto-hébergés ou sur site sont souvent nettement moins coûteux et beaucoup plus prévisibles, même après prise en compte des frais généraux liés à l'infrastructure et à l'exploitation.
Quand chaque option convient
Les services gérés dans le cloud fonctionnent mieux lorsque :
- Le trafic est imprévisible ou très irrégulier.
- La vitesse d'itération est plus importante que le coût à long terme.
- La capacité DevOps est limitée.
- Les charges de travail sont encore à l'étude.
sur site auto-hébergés ou sur site sont pertinents lorsque :
- requête est élevé et stable.
- La prévisibilité des coûts est une exigence commerciale.
- Les budgets doivent être défendus à l'avance.
- La conformité ou la résidence des données sont importantes.
- Les objectifs de performance sont stricts.
Le bon choix dépend de l'adéquation entre votre modèle de tarification et votre comportement réel en matière de production.
Déclencheurs de décision utiles
Au lieu de débattre sans cesse de l'architecture, de nombreuses équipes définissent des déclencheurs clairs :
- Si les dépenses mensuelles liées à la base de données vectorielles dépassent 1 500 $, réévaluez déploiement .
- Si requête dépasse 50 millions par mois, modélisez le coût total de possession pour l'infrastructure détenue.
- Si les variations de prix dépassent 20 %, réévaluez le risque fournisseur.
- Si les objectifs de latence ne sont systématiquement pas atteints, évaluez d'autres solutions.
Ces déclencheurs transforment la tarification d'une surprise en un point de décision planifié.
Le bilan
Au premier abord, la tarification des bases de données vectorielles semble simple. Les niveaux gratuits, les minimums bas et la facturation à l'utilisation suggèrent que vous ne payez que ce que vous utilisez. En production, la situation économique change. Les coûts s'accumulent entre le stockage, les requêtes, les intégrations et les opérations en arrière-plan.
La même requête plus coûteuse à mesure que jeux de données , même si elle offre la même valeur. La prévisibilité disparaît au moment où elle est le plus importante. Pour les charges de travail soutenues, il existe un point de basculement clair où la propriété devient moins coûteuse et plus facile à justifier. Les équipes qui évitent les factures exorbitantes ne sont pas celles qui ont négocié de meilleures remises, mais celles qui ont considéré très tôt la tarification comme une décision architecturale.
Pour les organisations qui accordent de l'importance aux budgets fixes, aux dépenses prévisibles et au contrôle à long terme, c'est la raison pour laquelle les bases de données sur site font à nouveau l'objet de discussions architecturales sérieuses. La base de données sur site d'Actian, conçue autour d'un système de licences transparent plutôt que d'une volatilité basée sur l'utilisation, reflète cette évolution.
Faites le calcul des coûts avant d'avoir besoin de migrer. C'est toujours moins cher ainsi.
Restez connecté
Des informations exploitables à votre disposition.
(par exemple, sales@..., support)