Erweitern Sie Ihre FastAPI-App mit der Vektorsuche von VectorAI DB




Zusammenfassung
- Erstellen Sie eine semantische Suche in FastAPI mit einer einfachen lokalen Konfiguration anstelle eines schwerfälligen Cloud .
- Erstellen Sie einen Import-Endpunkt, der Produktbeschreibungen einbindet und diese zusammen mit Metadaten speichert.
- Erstellen Sie einen Such-Endpunkt, der Produkte anhand ihres Inhalts und nicht nur anhand exakter Suchbegriffe zurückgibt.
- Fügen Sie strukturierte Filter wie „Kategorie“ direkt in die Vektorsuche ein.
- Die nächsten Schritte sind die Unterstützung asynchrer Vorgänge, die hybride Suche und erweiterte Filterfunktionen für den produktiven Einsatz.
Die Integration der semantischen Suche in eine FastAPI-Anwendung ist oft mit anfänglichen Schwierigkeiten verbunden. Die meisten Anleitungen lenken Entwickler entweder zu Cloud , für die eine Kontoeinrichtung und API-Schlüssel erforderlich sind, oder zu lokalen Stacks, die von mehreren Diensten abhängig sind, bevor man überhaupt nützlichen Code schreiben kann.
Dieser Mehraufwand entsteht bereits, bevor die Funktion überhaupt entwickelt wurde, wodurch sich der Aufwand von der API-Entwicklung hin zur Einrichtung der Infrastruktur verlagert.
Dieses Tutorial verfolgt einen einfacheren Ansatz. Actian VectorAI DB läuft als einzelner Docker-Container und lässt sich über einen Python JavaScript-Client verbinden. Für die frühe Entwicklungsphase und die Erstellung von Prototypen benötigen Sie weder ein Cloud noch API-Schlüssel oder mehrere Dienste. Installieren Sie die Datenbank und den Client, um mit der Erstellung Ihrer API zu beginnen. Im Vergleich zu Setups, die auf Managed Services oder Multi-Container-Stacks basieren, reduziert dies den Zeitaufwand für die Einrichtung, die Kosten und die Anzahl der zu verwaltenden Komponenten.
In diesem Tutorial erstellen Sie eine kleine Produktsuch-API, um dies zu veranschaulichen. Das Ziel ist es, Nutzern die Suche nach Sinnzusammenhängen statt nach exakten Suchbegriffen zu ermöglichen. So sollte beispielsweise eine abfragen „etwas Warmes zum Anziehen im Winter“ Jacken oder Pullover als Ergebnis liefern, auch wenn diese genauen Begriffe nicht in der Produktbeschreibung vorkommen.
Am Ende dieses Tutorials verfügen Sie über eine funktionierende FastAPI-Anwendung mit semantischer Suche, die lokal läuft – und zwar mit einer Konfiguration, die Sie ohne zusätzliche Infrastruktur ausführen, testen und erweitern können.
Einrichtung
In diesem Abschnitt starten Sie VectorAI DB und richten Ihr FastAPI-Projekt mit uv ein. Am Ende verfügen Sie über eine laufende Vektordatenbank und eine Python , die für die Verbindung mit dieser bereit ist.
Voraussetzungen
Um mitzumachen, installieren Sie bitte die folgenden Tools in Ihrem lokalen Netzwerk:
Actian VectorAI DB starten
Führen Sie VectorAI DB als einzelnen Docker-Container aus. Erstellen Sie eine Datei „docker-compose.yml“ mit folgendem Inhalt:
services:
vectorai:
image: williamimoh/actian-vectorai-db:latest
platform: linux/amd64
container_name: vectorai_db
ports:
- "50051:50051"
volumes:
# vector data persists across restarts
- ./data:/app/data
environment:
- VECTORAI_LOG_LEVEL=info
restart: unless-stoppedDen Dienst starten:
docker compose up -d
VectorAI DB läuft nun lokal auf Port 50051.
Erstellen Sie Ihr FastAPI-Projekt mit Uv
Richte nun dein Python ein. Falls du uv noch nicht installiert hast, installiere es zuerst.
Erstellen Sie ein neues Projekt in Ihrem aktuellen Verzeichnis, indem Sie folgenden Befehl ausführen:
uv init . uv venv
Installieren Sie FastAPI, den Python für die VectorAI-Datenbank und die Abhängigkeit für das Einbettungsmodell:
uv add fastapi uvicorn sentence-transformers
Registrieren Sie sich für die Actian VectorAI DB Community Edition.Nach der Registrierung erhalten Sie Anweisungen zur Einrichtung des Clients – je nach Wunsch entweder durch Herunterladen der Binärdatei oder durch Ausführen in einem Docker-Container.
Installieren Sie Python VectorAI DB Python wie folgt:
uv add actian-vectorai-client
Verbindung überprüfen
Erstellen Sie ein einfaches Skript „test_connection.py , um zu überprüfen, ob Ihre App eine Verbindung zur VectorAI-Datenbank herstellt:
from actian_vectorai import VectorAIClient
VECTORAI_HOST = "localhost:50051"
with VectorAIClient(VECTORAI_HOST) as client:
# Health check
info = client.health_check()
print(f"Connected to {info['title']} v{info['version']}")Testen Sie diese Verbindung wie folgt:
uv run test_connection.py
Wenn alles funktioniert, sollte eine Meldung angezeigt werden, dass die Verbindung erfolgreich hergestellt wurde.

Verbindung prüfen
Sie können nun Ihr Datenmodell definieren und mit der Erstellung Ihrer API beginnen.
Den Ingest-Endpunkt einrichten
Sie erstellen einen POST /ingest -Endpunkt erstellen, der eine Liste von Produkten akzeptiert, jede Beschreibung einbettet und die Ergebnisse in der VectorAI-Datenbank speichert. So können Sie eine JSON-Liste von Produkten an Ihre API senden und diese für die Suche bereitstellen.
Beginnen Sie mit der Einrichtung des Datenmodells und der Sammlung. Erstellen Sie eine Datei main.py mit folgendem Inhalt:
from fastapi import FastAPI
from pydantic import BaseModel
from sentence_transformers import SentenceTransformer
from actian_vectorai import VectorAIClient, VectorParams, Distance, PointStruct, CollectionExistsError
from typing import List
from contextlib import asynccontextmanager
COLLECTION = "products_collection"
DIMENSION = 384 # all-MiniLM-L6-v2 produces 384-dimensional vectors
model = SentenceTransformer("all-MiniLM-L6-v2")
class Product(BaseModel):
id: int
name: str
description: str
category: str
price: float
@asynccontextmanager
async def lifespan(app: FastAPI):
# Startup
with VectorAIClient("localhost:50051") as client:
try:
client.collections.create(
COLLECTION,
vectors_config=VectorParams(size=DIMENSION, distance=Distance.Cosine)
)
except CollectionExistsError:
pass
yield
app = FastAPI(lifespan=lifespan)Verwenden all-MiniLM-L6-v2 . Es handelt sich um ein Modell mit 22,7 Millionen Parametern, das auf CPU läuft CPU 384-dimensionale Vektoren erzeugt. Es bietet ausreichende Geschwindigkeit für die lokale Entwicklung und hohe Genauigkeit für die Produktsuche. Die Sammlung verwendet den Kosinusabstand, der den Winkel zwischen Vektoren misst und nicht deren Größe. Dies eignet sich gut für Text-Embeddings, da der Fokus auf der Bedeutung und nicht auf der Länge der Beschreibung liegt.
Erstellen Sie nun die Ingest-Endpunkt Endpunkt.
@app.post("/ingest")
def ingest(products: List[Product]):
descriptions = [p.description for p in products]
embeddings = model.encode(descriptions, convert_to_numpy=True)
points = [
PointStruct(
id=p.id,
vector=embeddings[i].tolist(),
payload={
"name": p.name,
"category": p.category,
"price": p.price,
}
)
for i, p in enumerate(products)
]
with VectorAIClient("localhost:50051") as client:
client.points.upsert(COLLECTION, points)
return {"inserted": len(points)}Das bewirkt Folgendes:
- Extrahiert alle Produktbeschreibungen in eine Liste, damit Sie einbetten in einem Durchgang einbetten können.
- Erzeugt Einbettungen unter Verwendung des all-MiniLM-L6-v2 .
- Wandelt jedes Produkt in ein PointStruct mit einer ID, einem Vektor und einer Nutzlast.
- Speichert nützliche Metadaten Name, Kategorie und Preis zusammen mit dem Vektor.
- Fügt alle Punkte mit einer einzigen Abfrage in die VectorAI-Datenbank ein.
Such-Endpunkt erstellen
Um die fünf ähnlichsten Produkte zu ermitteln, enthält die Implementierung eine GET /search Endpunkt, der eine abfragen einen optionalen Kategoriefilter akzeptiert. Der Endpunkt bettet die abfragen ein, führt eine Vektorsuche in der VectorAI-Datenbank durch und gibt die relevantesten Ergebnisse zurück.
Mit diesem Schritt ist der Suchablauf abgeschlossen: In einem einzigen Suchvorgang wird von der Eingabe von Rohtext zu semantisch gewichteten Ergebnissen übergegangen.
Warum dieser Filter wichtig ist
Der Kategoriefilter ist der Bereich, in dem VectorAI DB die Entwicklererfahrung verbessert. Bei FAISS führt man in der Regel zunächst eine vollständige Vektorsuche durch und filtert die Ergebnisse anschließend in Python. Das bedeutet, dass Rechenleistung für Ergebnisse verschwendet wird, die man später verworfen hat.
VectorAI DB filtert bereits während des Suchvorgangs. Bei der Ergebnisausgabe werden nur übereinstimmende Vektoren berücksichtigt. Dadurch bleibt die Suche effizient und leichter nachvollziehbar.
Den Endpunkt implementieren
Füge die folgenden Importe und den Endpunkt zu deiner main.py hinzu:
from actian_vectorai import FilterBuilder, Field
@app.get("/search")
def search(query: str, category: str = None, top_k: int = 5):
query_vector = model.encode([query], convert_to_numpy=True)[0].tolist()
search_filter = None
if category:
search_filter = FilterBuilder().must(Field("category").eq(category)).build()
with VectorAIClient("localhost:50051") as client:
results = client.points.search(
COLLECTION,
vector=query_vector,
limit=top_k,
filter=search_filter
)
return [
{
"id": r.id,
"score": round(r.score, 4),
"name": r.payload["name"],
"category": r.payload["category"],
"price": r.payload["price"],
}
for r in results
]So funktioniert es
- Wandle Nutzer abfragen “abfragen eine Einbettung um.
- Erstelle einen Filter nur, wenn eine Kategorie angegeben ist.
- Übergeben Sie sowohl den Vektor als auch den Filter in einer einzigen Anfrage an VectorAI DB.
- Gib die besten Ergebnisse mit Ähnlichkeitswerten und Metadaten zurück.
Die Filterobjekte sind typisierte Python . Dies hilft FastAPI dabei, Fehler frühzeitig zu erkennen, und sorgt für abfragen einheitliche abfragen Ihrer abfragen .
Wenn keine Kategorie angegeben wird, bleibt `search_filter` auf `None` gesetzt. Die Suche wird dann für alle Produkte durchgeführt.
Los geht's
Starten Sie VectorAI DB und anschließend FastAPI. Zwei Befehle.
docker-compose up -d
uv run uvicorn main:app –reload
Öffnen Sie ein weiteres Terminalfenster und laden Sie drei Beispielprodukte ein:
curl -X POST http://localhost:8000/ingest \
-H "Content-Type: application/json" \
-d '[
{"id": 1, "name": "Cashmere Scarf", "description": "Soft cashmere scarf, ideal for cold weather", "category": "clothing", "price": 49.00},
{"id": 2, "name": "Bluetooth Speaker", "description": "Portable waterproof speaker with 12-hour battery", "category": "electronics", "price": 59.99},
{"id": 3, "name": "Trail Mix", "description": "Mixed nuts and dried fruit, high-energy snack", "category": "food", "price": 8.50}
]'Du erhältst eine Antwort:
{“inserted”: 3}
Führen Sie eine semantische Suche mit einem Kategoriefilter durch:
curl "http://localhost:8000/search?query=something+warm+for+winter&category=clothing"Sie sollten folgende Antwort erhalten:

Suche nach abfragen Kategorie
Führen Sie dieselbe abfragen Filter aus, um alle Kategorien nach Relevanz sortiert anzuzeigen:
curl -s "http://localhost:8000/search?query=something+warm+for+winter" | jqDer Schal erzielt nach wie vor die höchste Punktzahl. Der Lautsprecher und das Studentenfutter erzielen niedrigere Punktzahlen, da ihre Beschreibungen weniger semantische Überschneidungen mit den abfragen aufweisen.
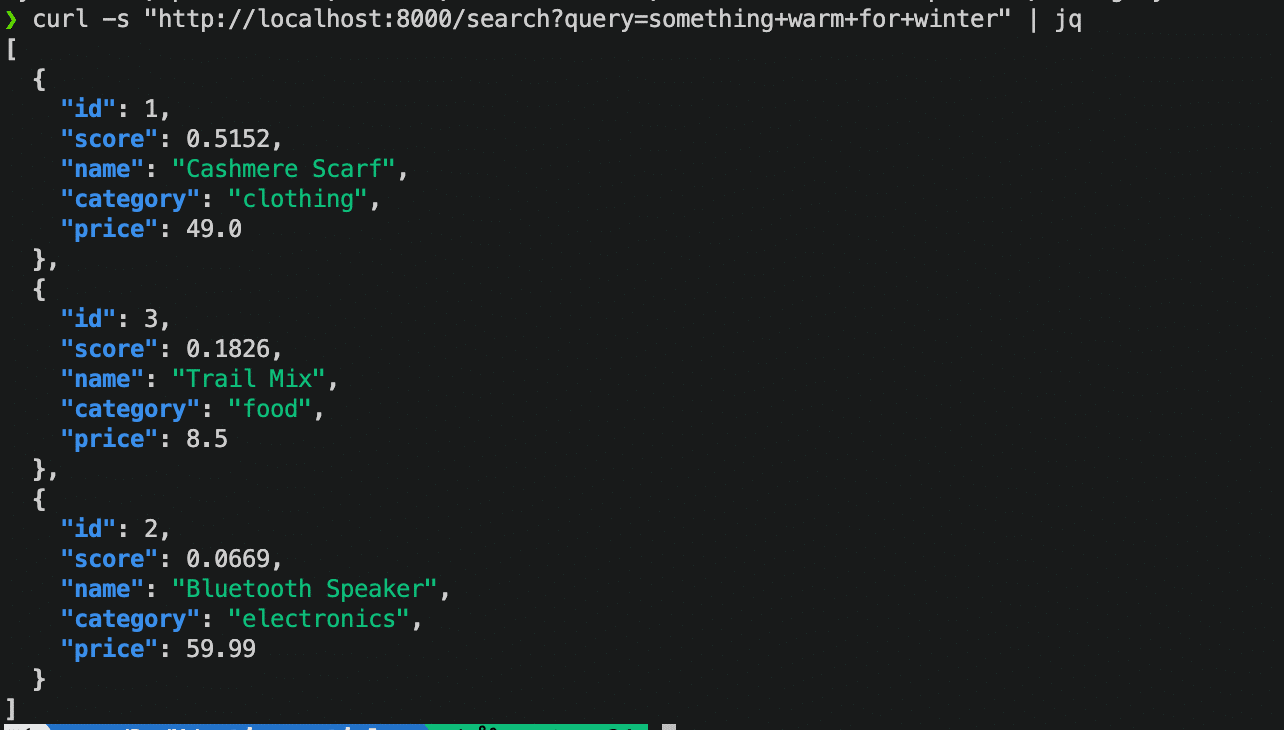
Suche nach abfragen Kategorie
Bis jetzt haben Sie die Architektur wie in der Abbildung dargestellt aufgebaut.
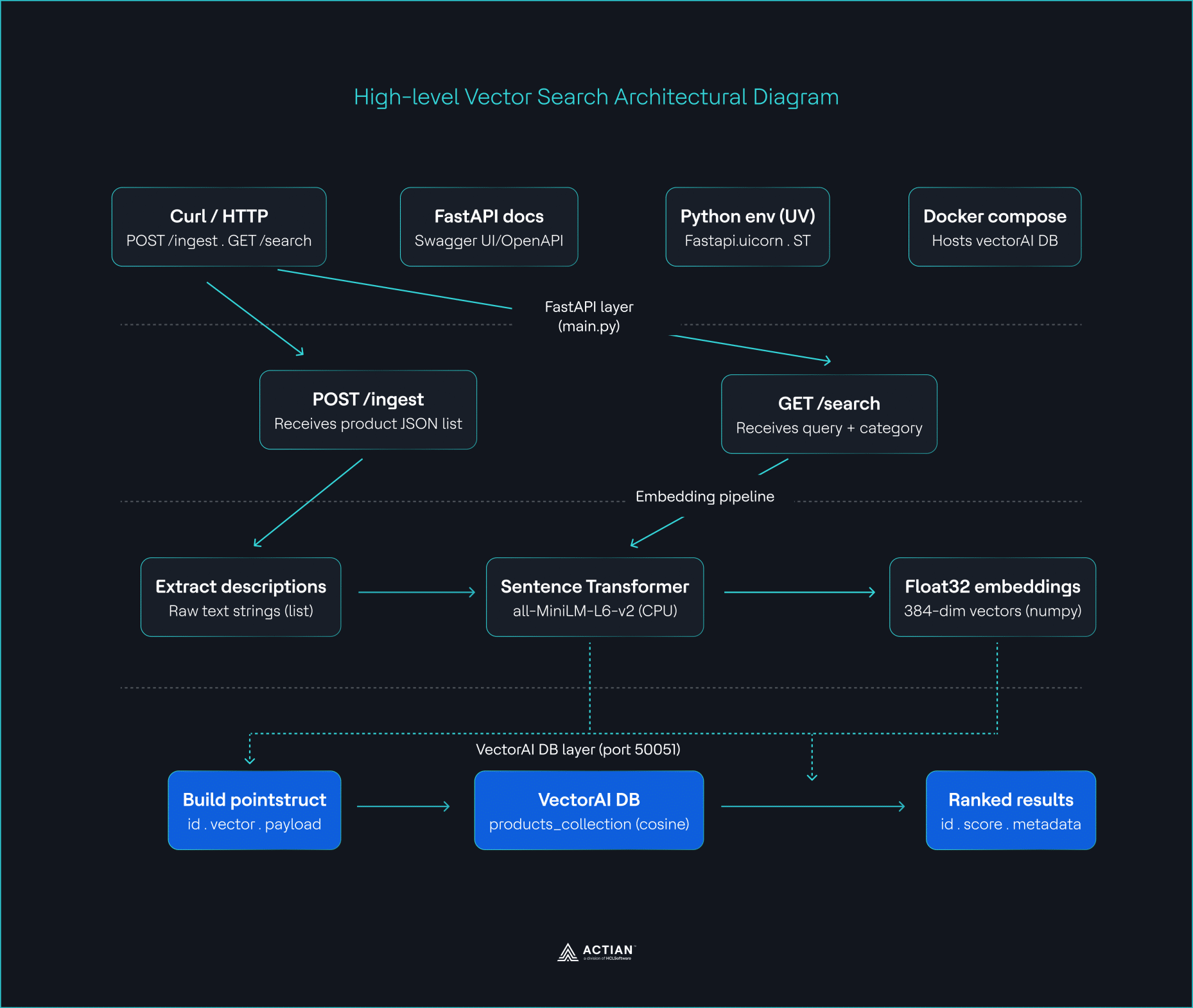
Übersichtsschema
Schauen wir uns an, was wir als Nächstes entwickeln.
Was soll ich als Nächstes bauen?
Diese Konfiguration eignet sich gut für die lokale Entwicklung und kleinere Arbeitslasten. Der nächste Schritt besteht darin, sie für einen höheren Durchsatz und komplexere Suchmuster vorzubereiten.
Verwenden Sie den Async-Client für Produktions-Workloads
Die derzeitige Implementierung nutzt einen synchronen Client, der sich zwar gut für die lokale Entwicklung und kleine Tests eignet, jedoch den Durchsatz bei Zustimmung einschränkt. Jeder Datenbankaufruf blockiert den Anfragethread bis zu seinem Abschluss, was die Gesamtleistung unter Last beeinträchtigt.
VectorAI DB stellt einen AsyncVectorAIClient bereit, der diesen Engpass beseitigt. Er lässt sich in das Async-Modell von FastAPI integrieren, sodass Endpunkte andere Anfragen bearbeiten können, während sie auf Datenbankoperationen warten. Dieser Ansatz ist besonders wichtig für parallele Suchvorgänge, die Stapelverarbeitung und Datenaktualisierungen im Hintergrund.
In einer Produktionsumgebung lässt sich diese Änderung zudem gut mit dem Einsatz mehrerer uvicorn-Worker kombinieren. Zusammen ermöglichen sie eine horizontale Skalierung Ihres Dienstes, ohne dass Sie Ihre Kernlogik ändern müssen.
Hybridsuche hinzufügen
Die Vektorähnlichkeit allein funktioniert gut, wenn die abfragen vage oder beschreibend abfragen , da sie sich eher auf die Bedeutung als auf exakte Wortlaute konzentriert. In Fällen, in denen es auf Präzision ankommt – insbesondere bei Produktnamen, Modellnummern oder Markennamen –, kann sie jedoch an ihre Grenzen stoßen.
VectorAI DB kombiniert Vektorähnlichkeit mit dem Abgleich von Schlüsselwörtern in einer einzigen abfragen. Die Vektorkomponente erfasst die semantische Bedeutung, während die Schlüsselwortkomponente sicherstellt, dass exakte Begriffe bei der Übersetzung nicht verloren gehen. Beide Signale fließen in das endgültige Ranking ein.
Die hybride Suche ist in realen Szenarien hilfreich, in denen Nutzer in ein und derselben abfragen sowohl eine semantische Absicht als auch präzise Suchkriterien kombinieren. Eine Suche wie „Nike-Laufschuhe Größe 42“ enthält beispielsweise sowohl eine semantische Absicht (Laufschuhe für den Sport) als auch exakte Suchkriterien (Nike und Größe 42). Die hybride Suche stellt sicher, dass keines dieser beiden Signale verloren geht, was die Qualität der Ergebnisse verbessert, ohne dass Sie zusätzliche Logik implementieren müssen.
Erweiterung der Filter- und Bewertungslogik
Derzeit filtert Ihre Suche nur nach Kategorien, was für eine einfache Demo ausreicht. In realen Anwendungen wird die Filterung jedoch dynamischer, da Nutzer erwarten, die Ergebnisse anhand mehrerer Kriterien einzugrenzen.
Sie können Ihre Filter erweitern, um beispielsweise Preisspannen, Lagerverfügbarkeit, Markennamen oder andere strukturierte Attribute in Ihrem Datensatz zu berücksichtigen. Das typisierte Filtersystem von VectorAI DB erleichtert dies, da Sie Filter als strukturierte Python erstellen, anstatt abfragen zu verwenden. Dies verringert Fehler und sorgt dafür, dass Ihre Suchlogik mit dem Rest Ihrer FastAPI-Anwendung konsistent bleibt.
Mit Datensatz des Datensatz werden diese Filter unverzichtbar, um den Ergebnisraum vor der Rangfolge zu steuern. Die Vektorsuche sorgt weiterhin für die Relevanz, während die Filterung den Datensatz Datensätze einschränkt, die Nutzer entsprechen.
Zum Abschluss
In diesem Tutorial haben Sie ein vollständiges semantisches Suchsystem mit FastAPI und VectorAI DB erstellt. Sie haben aus einem leeren Projekt eine funktionsfähige API entwickelt, die Anfragen in natürlicher Sprache versteht und relevante Ergebnisse liefert, die auf der Bedeutung und nicht nur auf Schlüsselwörtern basieren.
Sie haben eine Erfassungspipeline erstellt, die Produktbeschreibungen mithilfe von all-MiniLM-L6-v2 und diese in einer Vektorsammlung mit Metadaten speichert. Anschließend haben Sie einen Such-Endpunkt erstellt, der Nutzer einbettet und die relevantesten Produkte anhand der Vektorähnlichkeit abruft, mit optionaler Filterung nach strukturierten Einschränkungen wie der Kategorie.
Um eine FastAPI-Anwendung um eine Vektorsuche zu erweitern, sind weder ein komplexer Stack noch Cloud externer Cloud erforderlich. VectorAI DB läuft als einzelner Container und lässt sich direkt über einen Python integrieren, sodass der Übergang von der Einrichtung zur Implementierung schnell und einfach vonstattengeht.
Von hier aus können Sie das System um asynchrone Clients, eine Hybrid-Suche und umfangreichere Filterlogik erweitern, wenn Ihre Anwendung zu produktionsbereit heranwächst.
Aktuelle Informationen und Details zur Implementierung finden Sie in der DokumentationVektor-KI und Lager GitHub.
Registrieren Sie sich für die Actian VectorAI DB Community Edition und legen Sie noch heute los.

Bleiben Sie in Verbindung
Datenanalysen direkt bei Ihnen.
(z. B. sales@..., support@...)