3 Erkenntnisse aus der Entwicklung mit VectorAI DB bei Hacklytics 2026





Zusammenfassung
- Ein Unternehmensdatenmarktplatz ist eine zentralisierte interne Plattform, auf der Teams Datenprodukte veröffentlichen, finden, analysieren und Zugriff darauf beantragen können.
- Ziel ist es, Datensilos aufzubrechen, indem Unternehmensdaten abteilungsübergreifend sichtbar, wiederverwendbar und vertrauenswürdiger gemacht werden.
- Zu den typischen Funktionen gehören Katalogisierung, Suche, Zugriffsworkflows, Qualitätsindikatoren und Nutzungserfassung.
- Zu den wichtigsten Vorteilen zählen eine schnellere Gewinnung von Erkenntnis, weniger doppelter Datenaufwand, eine strengere Datenverwaltung, eine bessere Datenqualität, mehr Self-Service und eine verbesserte Zusammenarbeit.
- Es hilft Unternehmen dabei, mehr Wert aus ihren Daten zu schöpfen, indem es verstreute Informationen in leicht zugängliche, gut verwaltete und geschäftsreife Datenprodukte umwandelt.
Eine einzige Änderung im Wortlaut führte zu einer abfragen der Datenbank für unerwünschte Ereignisse der FDA (FAERS) von 1.532 Ergebnissen auf nur ein einziges. Bei Hacklytics 2026, data science jährlichen data science der Georgia Tech, durchsuchte das RxGuard-Team die FAERS-Datenbank, die über 31 Millionen Berichte über Arzneimittelwechselwirkungen, nach Warfarin-Ibuprofen unter Verwendung von vier verschiedenen Formulierungen ab: generische Bezeichnungen, Markennamen, Salzformen und natürliche Sprache. Jede neue abfragen lieferte weniger Ergebnisse, da die FAERS-Datenbank sprachliche Variationen nicht verstehen konnte.
Diese Erkenntnis war eine von mehreren, die drei Teams an einem Wochenende bei der Entwicklung mit der Actian VectorAI DB gewonnen haben. Jedes Team wählte einen use case aus use case befasste sich mit den damit verbundenen Herausforderungen in den Bereichen Datenabruf, Vorhersage und Generierung. Hier sind die von ihnen identifizierten Probleme im Gesundheitswesen und die von ihnen entwickelten Lösungen.
Apotheker, die die FAERS-Datenbank nach Wechselwirkungen zwischen Medikamenten durchsuchen, übersehen wichtige Sicherheitssignale, da das System nur exakte Übereinstimmungen mit Suchbegriffen erkennt. RxGuard schließt diese Lücke mit einer semantischen Suchmaschine, die Untersuchungsberichte zu gefährlichen Wechselwirkungen liefert, die in der Datenbank erfasst sind. Die openFDA-API ruft historische Berichte über unerwünschte Ereignisse für 70 Arzneimittelklassen ab, all-MiniLM-L6-v2 Die Berichte werden als 384-dimensionale dichte Vektoren eingebettet, und Actian VectorAI DB speichert diese Einbettungen. Eine einzige Vultr-Instanz mit Docker Compose bildet die Grundlage für den gesamten Stack. Wenn Apotheker die vorgeschlagene Medikation und Vorerkrankungen eines Patienten eingeben, ruft RxGuard die zehn semantisch ähnlichsten Fälle von unerwünschten Arzneimittelwirkungen aus der VectorAI DB ab, zusammen mit Risikobewertungen zum Schweregrad und Empfehlungen für alternative Medikamente.
Die Diagnose von Autoimmunerkrankungen dauert vier bis sieben Jahre und erfordert den Einsatz von vier oder mehr Fachärzten. Aura ist eine lokal auswertende RAG-Engine für die klinische Triage. Ein XGBoost-Modell, das anhand öffentlicher Daten von 100.000 Patienten vortrainiert wurde, erkennt anhand von Krankenakten frühe Anzeichen von Autoimmunerkrankungen mit einer AUC von 0,90. VectorAI DB dient als lokale Abrufebene und speichert PubMed-Datensätze, eingebettet pritamdeka/S-PubMedBert-MS-MARCO, als 768-dimensionale Einbettungen. Ein quantisiertes Modell mit 8 Milliarden Parametern, das anhand allgemeiner medizinischer Daten und Patientenzusammenfassungen feinabgestimmt wurde, erstellt klinische Berichte mit Zitaten aus PubMed-Zeitschriften.
Die meisten Arztrechnungen enthalten Fehler, doch um diese anzufechten, sind Kenntnisse über CPT-Codes, die Vergütungssätze von Medicare sowie Verweise auf Bundesgesetze erforderlich – Kenntnisse, über die viele Patienten nicht verfügen. PayBack ist ein Multi-Agenten-System zur Bearbeitung von Streitfällen bei Arztrechnungen, das auf einer LangGraph-Pipeline basiert. Gemini 2.0 Flash extrahiert CPT-Codes aus hochgeladenen Rechnungen und vergleicht diese mit Datensatz preislich transparenten Datensatz von DoltHub, wobei entweder ein Abgleich mit dem Versicherungsträger oder ein Rückgriff auf den Marktdurchschnitt erfolgt. Eine Regel-Engine kennzeichnet Unregelmäßigkeiten bei der Abrechnung, während all-MiniLM-L6-v2 erzeugt lokal 384-dimensionale Einbettungen für historische Streitfälle. VectorAI DB speichert diese Einbettungen und ruft die drei relevantesten Präzedenzfälle als Kontext für Gemini 2.5 Pro ab, damit dieses die Streitfallschreiben entwerfen kann.
Im Folgenden berichten wir über die Erkenntnisse aus ihrem Entwicklungsprozess, die entscheidenden Suchbeschränkungen, die sie mit VectorAI DB gelöst haben, und was ihre Anwendungsfälle über Vektordatenbanken im realen Deployment aussagen.
Die Stichwortsuche weist unsichtbare Verzerrungen auf
Für Demos reicht die Stichwortsuche aus. Wenn echte Nutzer jedoch abfragen domänenspezifisches Korpus mit synonymen Vokabularen abfragen , sinkt die Trefferqualität rapide. Dies ist das Problem der Vokabularinkongruenz, das bei der Stichwortsuche zutage tritt.
In Bereichen wie dem Gesundheitswesen, dem Finanzwesen und dem Rechtswesen wird dieselbe Terminologie auf vielfältige Weise ausgedrückt. Das RxGuard-Team hat dies am eigenen Leib am Datensatz erfahren: „Dasselbe Medikament taucht in 11,5 Millionen Meldungen unter Dutzenden von Namensvarianten, Salzformen, ausländischen Schreibweisen und Tippfehlern auf. Amerikanische Forscher, die nach ‚gastrointestinal hemorrhage‘ suchen, erhalten keine Ergebnisse, da der korrekte MedDRA-Begriff die britische Schreibweise verwendet.“
Die schlagwortbasierte Suche kann keine Umschreibungen, thematische Ähnlichkeiten oder Äquivalenzen zwischen Ausdrücken erkennen. Wie das RxGuard-Team es formuliert: „Die Schlagwortsuche liefert nicht nur weniger Ergebnisse – sie liefert eine systematisch verzerrte Teilmenge, und diese Verzerrung ist für den Suchenden nicht erkennbar. Niemand weiß, was ihm entgeht, da die fehlenden Fälle nie auftauchen.“ Support-Teams , die Tickets durchsehen, Vertriebsmitarbeiter, die nach Produktspezifikationen suchen, und Ingenieure, die interne Wikis durchforsten, stehen alle vor derselben Herausforderung. Die Lösung ist das semantische Matching.
RxGuard nutzte die Vektorsuche über die VectorAI-Datenbank als primären Abrufmechanismus, wobei optional eine Vorabfilterung nach Schweregrad und ein Abgleich mit Medikamentennamen als Einschränkungen angewendet wurden, wie unten dargestellt. Durch die Einbettungen werden Synonyme und Aliasbezeichnungen im Vektorraum nahe beieinander platziert, sodass das System erkennt, dass „(…) ‚Coumadin‘, ‚Warfarin‘ und ‚Blutverdünner‘ alle dasselbe bedeuten.“
def search_faers(
query: str,
top_k: int = 10,
min_severity: int = 0,
drug_filter: str | None = None,
) -> list[dict]:
model = _get_model()
query_vector = model.encode(query).tolist()
f = Filter()
if min_severity > 0:
f = f.must(Field("severity_score").gte(min_severity))
fetch_k = top_k * 3 if drug_filter else top_k
with CortexClient(config.VECTORDB_ADDRESS) as client:
results = client.search(
config.VECTORDB_COLLECTION,
query=query_vector,
top_k=fetch_k,
filter=f if not f.is_empty() else None,
with_payload=True,
)
output = []
for r in results:
payload = r.payload or {}
# Post-filter by drug name if requested
if drug_filter:
drugs = payload.get("drugs", [])
if not any(drug_filter.lower() in d.lower() for d in drugs):
continue
output.append({
"rank": len(output) + 1,
"score": round(r.score, 4),
"doc_id": payload.get("doc_id", ""),
"text": payload.get("text", ""),
"drugs": payload.get("drugs", []),
"reactions": payload.get("reactions", []),
"severity_score": payload.get("severity_score", 0),
"patient_age": payload.get("patient_age", -1),
"patient_sex": payload.get("patient_sex", "unknown"),
})
if len(output) >= top_k:
break
return outputDieser Code-Block zeigt, wie das System abfragen in natürlicher Sprache abfragen eine nach Relevanz geordnete Liste von Fällen unerwünschter Ereignisse umwandelt. VectorAI DB führt eine Ähnlichkeitssuche in der gespeicherten FAERS-Sammlung durch und liefert standardmäßig die 10 relevantesten Fälle, unabhängig von der Formulierung des Medikamentennamens. Metadaten grenzen die Ergebnisse vor der Abfrage nach Schweregrad ein, sodass nur klinisch relevante Fälle angezeigt werden. Die vollständige Code-Implementierung finden Sie im GitHub-Repository.
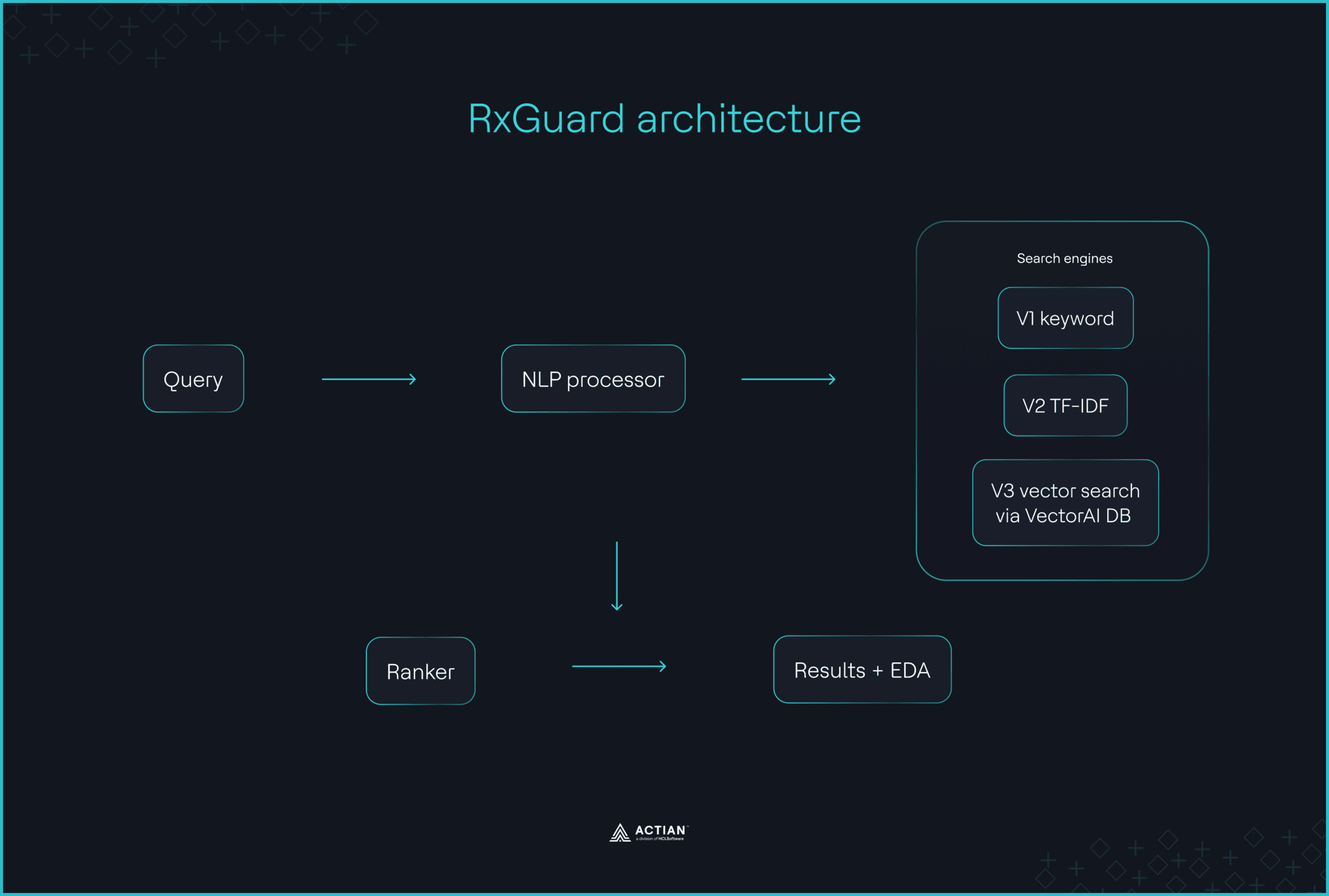
Die Stichwortsuche beschränkt sich auf die Übereinstimmung expliziter Wörter, doch die Effizienz der Ergebnisse hängt von der Berücksichtigung von Synonymen ab. Und die Lösung ist keineswegs neu. Wie das RxGuard-Team es formuliert: „(…) die Bausteine für diese Lösung gibt es schon seit Jahren: Sentence Transformer, Vektordatenbanken und die openFDA-API. Das Problem war nicht technischer Natur. Es lag vielmehr darin, dass niemand diese Komponenten bisher mit diesem konkreten use case verknüpft hatte.“
Die Vektorsuche erfüllt eine einzige Aufgabe
Die natürliche Funktion der Vektorsuche in Produktionssystemen besteht darin, als Abrufmechanismus zu dienen. Durch eingebettete Modelle und approximative Indizierungsmethoden wird die Ähnlichkeitssuche zu einem probabilistischen Verfahren. Sie liefert zwar konzeptionell ähnliche Dokumente, kann jedoch weder die Spezifität gewährleisten noch erklären, warum diese Dokumente relevant sind. In Branchen mit hohem Risiko, in denen „nahe genug“ nicht ausreicht und Erklärbarkeit unverzichtbar ist, sollte die Vektorsuche allein nicht als Entscheidungsgrundlage dienen.
Die praktische RAG- und Such-Pipeline für Deployment produktiven Deployment der Vektorsuche für das Abrufen von Embeddings, deterministischen Regeln für Entscheidungsfindung und einem LLM zur Generierung von Antworten. PayBack und Aura haben diese Pipeline in unterschiedlichen Anwendungsbereichen entwickelt.
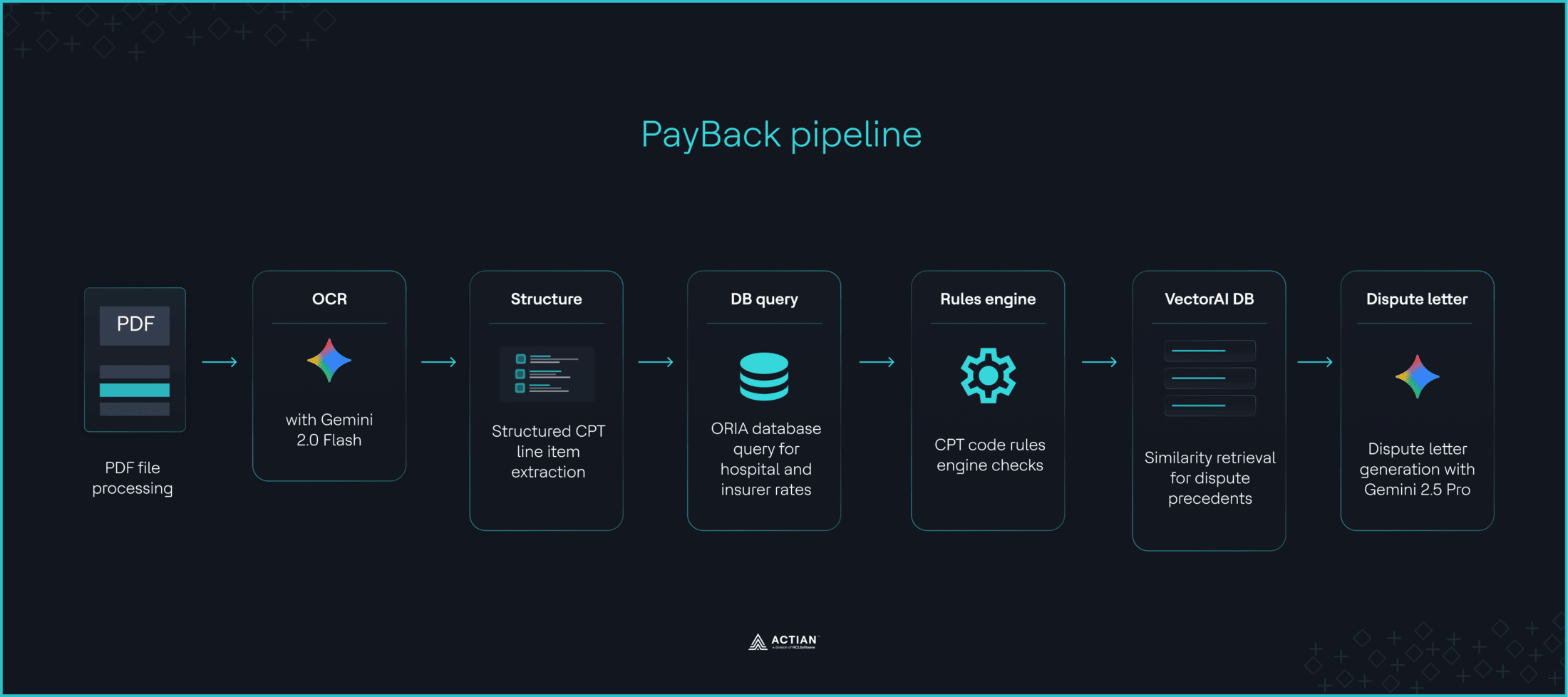
PayBack nutzte eine Python Engine, die „Doppeleinträge, Mengenabweichungen, extreme Aufschläge, Einrichtungsgebühren, Selbstüberweisungen und Abrechnungen am Entlassungstag“ kennzeichnet. VectorAI DB fungierte als Ebene für semantische Abfrage und Kontexterweiterung, die „die drei ähnlichsten historischen Streitfälle abruft und diese als Kontext in die Gemini-Prompts einfügt“. Gemini 2.5 Pro „generiertedaraufhin eine formelle Beanstandung unter Berufung auf Markierungen, DoltHub-Benchmarks und Formulierungen aus Präzedenzfällen“. DieserCodeausschnitt zeigt die Übergabe zwischen der Regel-Engine von PayBack und der Vektorsuche. Den vollständigen Code finden Sie im GitHub-Repo.
if line_items:
try:
query = _build_precedent_query(line_items)
precedents = search_precedents(query, top_k=3)
similar_cases_context = _format_similar_cases(precedents)
print(f"[rules_engine] Fetched {len(precedents)} similar cases for context")
except PrecedentServiceError as exc:
print(f"[rules_engine] Precedent search unavailable, proceeding without: {exc}")Das Aura-Team kombinierte die Vektorsuche mit einem auf XGBoost basierenden hierarchischen Dual-Scorer. Das Modell ordnet strukturierte Patientenmerkmale Krankheitsclustern zu und ermittelt innerhalb des vorhergesagten Cluster eine wahrscheinliche Erkrankung. Diese Klassifizierung sorgt für die Nachvollziehbarkeit des Systems, da Aura nachvollziehen kann, welche Patientendaten die Vorhersage und den Konfidenzwert beeinflusst haben.
VectorAI DB blieb auf dem Abrufpfad und nutzte den Kontext der Patientenmerkmale, um die fünf relevantesten PubMed-Literaturquellen anzuzeigen, die die Ergebnisse von XGBoost mit klinischen Belegen untermauern. Hier ist ein Ausschnitt, der zeigt, wie das Aura-Team VectorAI DB so konfiguriert hat, dass PubMed-Ausschnitte mit Metadaten gespeichert und gefiltert werden, anstatt bei abfragen die gesamte Literatur zu durchsuchen.
with CortexClient(ACTIAN_HOST) as client:
client.create_collection(
name=COLLECTION_NAME,
dimension=EMBEDDING_DIM,
distance_metric=DistanceMetric.COSINE,
)
for batch_start in range(0, total, EMBED_BATCH):
batch_end = min(batch_start + EMBED_BATCH, total)
texts = rows["text"][batch_start:batch_end]
embeddings = model.encode(
texts,
batch_size=EMBED_BATCH,
normalize_embeddings=True,
).tolist()
for sub_start in range(0, len(texts), UPSERT_BATCH):
sub_end = min(sub_start + UPSERT_BATCH, len(texts))
i = batch_start + sub_start
client.batch_upsert(
COLLECTION_NAME,
ids=list(range(i, i + (sub_end - sub_start))),
vectors=embeddings[sub_start:sub_end],
payloads=[
{
"chunk_id": rows["chunk_id"][i + k],
"doi": rows["doi"][i + k],
"journal": rows["journal"][i + k],
"year": rows["year"][i + k],
"section": rows["section"][i + k],
"cluster_tag": rows["cluster_tag"][i + k],
"text": rows["text"][i + k],
"pmc_id": rows["pmc_id"][i + k],
}
for k in range(sub_end - sub_start)
],
)Ein Übersetzungsmodell erstellte die endgültige Patientenzusammenfassung und den klinischen SOAP-Bericht unter Verwendung von DOI-Zitaten aus der aus PubMed abgerufenen Literatur. Die nachstehende Darstellung der Pipeline von Aura verdeutlicht, wie XGBoost die eigentliche Diagnosevorhersage generiert und die Vektorsuche eine Begründung hinzufügt. Die vollständige Code-Implementierung finden Sie auf GitHub.
Nutzen Sie die Vektorsuche, um abfragen zu erfassen, potenzielle Treffer in die engere Wahl zu nehmen und die Antworten des LLM zu ergänzen. Fügen Sie explizite Logik hinzu, wenn Sie Präzision und Nachverfolgbarkeit der Ergebnisse benötigen. Wenn Sie diese Trennung aufheben, sinkt die Genauigkeit der Suchpipeline im Produktivbetrieb.
Für sensible Daten gibt es eine lokale Lösung
Die Vektorsuche gehört On-Premises, wo sich die Daten bereits befinden. Vorschriften wie HIPAA und DSGVO stellen strenge Anforderungen daran, wo personenbezogene Daten (PII) und geschützte Gesundheitsdaten (PHI) gespeichert werden müssen. Für viele Branchen bedeutet dies, dass sie innerhalb des internen Netzwerks gespeichert werden müssen.
Aura, PayBack und RxGuard stießen unabhängig voneinander an diese Grenze hinsichtlich der Datenlokalisierung. Das Aura-Team hatte während des Hackathons Schwierigkeiten, Daten zu beschaffen, weil „Patientendaten werden von Krankenhäusern gemäß den HIPAA-Vorschriften streng vertraulich behandelt.“ PayBack lief all-MiniLM-L6-v2 lokal, wobei die Einbettungen innerhalb derselben Grenzen wie die Quelldokumente bleiben. RxGuard plant eine „Langfristig gesehen ist Deployment On-Premises vorgesehen, Deployment die HIPAA-Konformität verlangt, dass Abfragen zu Patientenmedikamenten das Netzwerk niemals verlassen – und genau für diese Architektur wurde die Actian VectorAI DB entwickelt.“
Drei Teams kamen zu derselben architektonischen Entscheidung. Die Vektorsuche muss vom ersten Tag an in einer kontrollierten Umgebung laufen, und VectorAI DB sorgt dafür, dass diese architektonische Anforderung schlank bleibt. Aura hat VectorAI DB lokal mit drei Befehlen gestartet:
git clone https://github.com/hackmamba-io/actian-vectorAI-db-beta
cd actian-vectorAI-db-beta
docker compose up -dDas Team betonte: „Es verlassen keine Patientendaten das Gerät. Die Vektordatenbank, die Modellinferenz und die Berichterstellung laufen alle auf dem Rechner Nutzer. Das ist bei medizinischer KI ein absolutes Muss.“
RxGuard führte NLP , die Erzeugung von Embeddings, die Vektorsuche und den Abruf von DailyMed-Kennzeichnungen auf einer einzigen Vultr-Instanz durch, wobei VectorAI DB über Docker Compose ausgeführt wurde. Wenn Compliance-Vorgaben das Senden vertraulicher Daten an eine externe API einschränken oder interne Richtlinien vorschreiben, dass die Inferenz lokal ausgeführt werden muss, istDeployment ähnlicheDeployment am sinnvollsten.
Eine lokale Docker-Instanz gibt Ihnen die volle Kontrolle darüber, wie sensible Daten von der Erfassung über die Indizierung bis hin zum Abruf und zur Generierung von Antworten verarbeitet werden. Der Zugriff auf den Vektorspeicher wird durch Rollen geregelt, und jede abfragen Protokoll. Ohne ausdrückliche Genehmigung verlassen keine vertraulichen Daten die Netzwerkgrenzen.
Was diese Projekte über Ihr nächstes Bauprojekt aussagen
Arzneimittelsicherheit, die Erkennung von Autoimmunerkrankungen und Streitigkeiten über Arztrechnungen – das sind drei Probleme in einer Branche. Das Gesundheitswesen und die Biowissenschaften stützen sich auf jahrzehntelang gesammelte strukturierte klinische Daten, strenge regulatorische Rahmenbedingungen und eine uneinheitliche Terminologie. Diese drei Teams haben an einem Wochenende funktionsfähige Systeme entwickelt. Die von ihnen ausgewählten Anwendungsfälle stellen nur einen Bruchteil dessen dar, was diese Branche benötigt.
Jedes Projekt nutzte bereits vorhandene Architekturkomponenten für produktionsreife Suchsysteme. Wie das RxGuard-Team feststellte: „Die Bausteine für diese Lösung gibt es schon seit Jahren. Das Problem war, dass niemand sie bisher mit diesem konkreten use case in Verbindung gebracht hatte.“ Die Einbettung von Modellen, die Vektorsuche, deterministische Regel-Engines und Deployment lokale Deployment nichts Neues. Diese Teams erkannten, wo jedes Werkzeug hingehörte, und setzten es unter den richtigen Rahmenbedingungen ein.
Die gleichen Probleme, auf die sie gestoßen sind, bestehen auch in Ihrem Bereich. Terminologische Diskrepanzen treten in jedem Korpus mit uneinheitlicher Terminologie auf, die Rückverfolgbarkeit von Ergebnissen ist für Systeme wichtig, die jede Ausgabe begründen müssen, und die Datenlokalisierung ist in regulierten Branchen eine zwingende Voraussetzung.
Wenn Sie VectorAI DB als domänenspezifisches Suchwerkzeug oder als RAG-Engine für den Umgang mit sensiblen Daten in Betracht ziehen, haben diese drei Teams die von Ihnen in Betracht gezogene Architektur bereits getestet. Testen Sie Actian VectorAI DB mit Ihren Daten anhand der Anleitung zur lokalen Installation im GitHub-Repository.
Treten Sie der Actian-Community auf Discord und tauschen Sie sich mit anderen Entwicklern aus, die die Vektorsuche lokal implementieren.

Bleiben Sie in Verbindung
Datenanalysen direkt bei Ihnen.
(z. B. sales@..., support@...)