Wie man ein HIPAA-konformes KI-Ökosystem ohne die Cloud aufbaut




Zusammenfassung
- Eine BAA gewährleistet nicht automatisch die Konformität von Cloud , da die größten Datenschutzrisiken häufig auf der Anwendungsebene liegen und nicht nur in der Infrastruktur des Anbieters.
- Der hier beschriebene sicherere Ansatz besteht darin, den gesamten RAG-Workflow auf der lokalen Krankenhausinfrastruktur zu belassen, einschließlich Erfassung, Abruf, Generierung und Protokollierung.
- Das System schützt Daten, indem es Inhalte vor der Erfassung anonymisiert, bei abfragen rollenbasierte Zugriffsrechte durchsetzt und den abteilungsübergreifenden Zugriff verhindert.
- Es nutzt eine lokale Vektordatenbank und lokale Modelle, sodass keine Patientendaten, Einbettungen, Eingabeaufforderungen oder Protokolle das Netzwerk verlassen.
- Die lokale Protokollierung ist unerlässlich, da sie eine lückenlose, überprüfbare Aufzeichnung liefert, wer wann und in welcher Rolle welche Abfrage durchgeführt hat.
Das Gesundheitswesen kann sich nicht auf Cloud verlassen, da Patientendaten Ihr Netzwerk verlassen und Ihr System diese außerhalb Ihrer Kontrolle protokolliert, speichert und offenlegt. Sie unterzeichnen eine Business Associate Agreement (BAA), verbinden Ihre Pipeline mit einer verwalteten Vektordatenbank und gehen davon aus, dass die Compliance damit gewährleistet ist. Diese Annahme ist falsch. Die BAA deckt die Infrastruktur des Anbieters ab. Sie deckt jedoch nicht ab, was Ihre Anwendung beim Abrufen und Erstellen von Daten sendet, protokolliert oder offenlegt.
Sie tragen weiterhin die Verantwortung für jeden Weg, über den Ihr System geschützte Gesundheitsdaten (PHI) übermittelt. Eine abfragen medizinisches Fachpersonal abfragen dazu abfragen , dass sensible Daten über Protokolle nach außen gelangen. Eine Systemmeldung kann Patientenkontext enthalten, den Ihr System außerhalb Ihrer Grenzen speichert. Eine unzureichende Zugriffskontrolle kann dazu führen, dass bei Suchergebnissen Datensätze abteilungsübergreifend offengelegt werden. Diese Risiken bestehen auf Ihrer Anwendungsebene und nicht im Zuständigkeitsbereich Cloud .
Die amerikanischen Aufsichtsbehörden nehmen nun diese Lücke ins Visier. Im Jahr 2026 wiesen sie auf Angriffsmuster wie die „Membership Inference“ hin, bei der ein Angreifer ein KI-System abfragt, um festzustellen, ob die Daten eines Patienten im Index vorhanden sind. Cloud Pipelines erhöhen dieses Risiko, da Abfragen und Einbettungen über externe Infrastrukturen laufen. Die Anforderungen an die Nachverfolgbarkeit verschärfen sich weiter, wenn Protokolle auf Systemen von Drittanbietern gespeichert werden.
In diesem Tutorial erstellen Sie einen klinischen Wissensassistenten, der vollständig auf der Infrastruktur Ihres Krankenhauses läuft. Er führt eine semantische Suche in klinischen Daten durch, wendet abfragen rollenbasierte Zugriffsrechte an und generiert Antworten mit eindeutigen Quellenangaben. Jede abfragen innerhalb Ihres Netzwerks, jeder Zugriff wird lokal protokolliert, und es sind keine externen API-Aufrufe erforderlich.
Warum BAA nicht ausreicht
Eine BAA schützt die Infrastruktur Cloud , nicht jedoch die Art und Weise, wie Ihr System bei Abfragen, dem Abruf und der Erstellung von PHI vorgeht. Sie bleiben für jeden Ort verantwortlich, an dem PHI innerhalb Ihrer Pipeline auftritt, übertragen oder gespeichert wird. Es gibt zahlreiche Fehlerquellen, die dazu führen können, dass Ihr System nicht konform ist, selbst wenn Sie eine BAA unterzeichnen.
Lücke bei der geteilten Verantwortung
Die BAA endet an der Infrastrukturgrenze. Ihr System steuert, welche Daten in eine Eingabeaufforderung gelangen, was protokolliert wird und was Ihr Netzwerk verlässt. Wenn abfragen durch einen Arzt personenbezogene Gesundheitsdaten (PHI) abfragen und Ihre Anwendung diese an einen externen Dienst protokolliert, tragen Sie die Verantwortung. Wenn Ihr Abrufschritt Datensätze abteilungsübergreifend ohne strenge Filter zurückgibt, haben Sie eine interne Datenpanne verursacht. Diese Fehler treten in Ihrem Code auf, nicht im Zuständigkeitsbereich Cloud .
Ein Beispiel: Ein Arzt gibt die Suchanfrage „Zeige mir ähnliche Fälle wie John Doe mit Lungenkrebs im Frühstadium“ ein. Ihre Anwendung protokolliert die vollständige abfragen zur Fehlerbehebung abfragen einem Cloud . Dieses Protokoll enthält nun geschützte Gesundheitsdaten außerhalb Ihres Netzwerks. Der Cloud hat diese Daten nicht weitergegeben. Ihre Anwendung hat sie übermittelt.
Zuständigkeit für das Prüfprotokoll
Die HIPAA schreibt ein lückenloses Protokoll für jeden Zugriff auf geschützte Gesundheitsdaten (PHI) vor. Wenn Ihre Vektordatenbank auf der Infrastruktur eines Drittanbieters läuft, speichert Ihr System abfragen und Abrufverläufe außerhalb Ihrer Kontrolle. Sie können weder Vollständigkeit noch Aufbewahrung oder isolation gewährleisten. Ihr Sicherheitsteam kann Zugriffsmuster nicht überprüfen, ohne auf das System eines anderen Anbieters angewiesen zu sein. Dies beeinträchtigt Ihre Fähigkeit, die Einhaltung der Vorschriften durchzusetzen und nachzuweisen.
Ein Beispiel: Ihr Compliance-Team fordert einen Bericht über alle Patientenakten aus der Onkologie der letzten 30 Tage an. Ihr Anbieter für Vektordatenbanken speichert abfragen auf seiner Plattform mit begrenzter Aufbewahrungsdauer. Einige Protokolle fehlen, und bei anderen fehlen Metadaten Nutzer. Sie können kein vollständiges Protokoll erstellen.
Risiko der Ableitung von Mitgliedschaften
Angreifer können Ihr System mit gezielten Abfragen untersuchen, um festzustellen, ob die Daten eines bestimmten Patienten in Ihrem Index vorhanden sind. Diese Art von Angriffen ist mittlerweile ein regulatorisches Problem. Cloud Indizes erhöhen dieses Risiko, da sie eine Remote-Schnittstelle für wiederholte Abfragen offenlegen. Ein lokal gehosteter Index beseitigt diese externe Schnittstelle und beschränkt den Zugriff auf Ihr internes Netzwerk.
Ein Angreifer sendet beispielsweise wiederholt Abfragen wie „Mit HIV diagnostizierte Patienten im Jahr 2024, die mit Medikament X behandelt wurden“ und passt die Filter dabei jedes Mal leicht an. Er beobachtet dabei Veränderungen hinsichtlich der Zuverlässigkeit und des Inhalts der Antworten. Im Laufe der Zeit lässt er daraus schließen, ob Aufzeichnung einer bestimmten Person in Ihrem Datensatz Aufzeichnung .
Diese Ausfälle zeigen, dass ein BAA die Einhaltung der Vorschriften nicht gewährleistet. Bei einer On-Premises Deployment entfällt der Kontakt mit Drittanbietern vollständig, und Sie erhalten die volle Kontrolle über Datenfluss, Zugriff und Nachvollziehbarkeit.
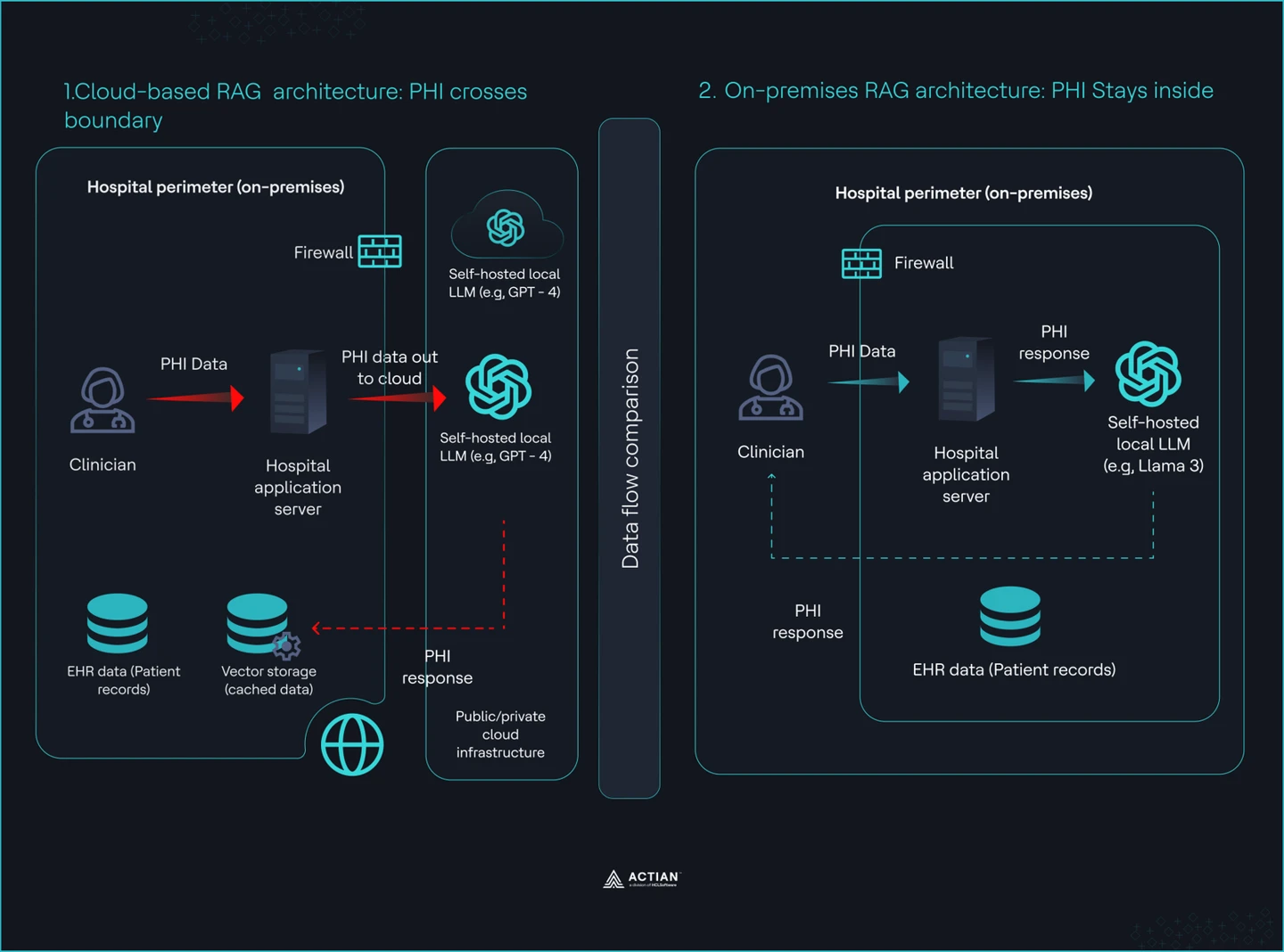
Doppelte Ansicht: Cloud . On-Premises -Architektur
Was du baust
In diesem Abschnitt erstellen Sie ein RAG-System mit drei Schichten:
Aufnahmeschicht
Sie laden klinische Notizen und Behandlungsprotokolle in einen kontrollierten Vektorindex mit strengen Datenhygienestandards. Vor jeder Verarbeitung anonymisieren Sie die Daten. HIPAA Safe Harbor schreibt die Entfernung von Identifikatoren vor, während „Expert Determination“ einen statistischen Ansatz zulässt. Sie wenden eine dieser Methoden vor der Erfassung an, nicht danach. Anschließend zerlegen Sie die Dokumente in Segmente von 512 Tokens mit einer Überlappung von 50 Tokens, generieren Einbettungen mithilfe eines lokalen Modells und speichern diese zusammen mit Metadaten in der VectorAI-Datenbank.
Für jede Aufzeichnung legen Sie ein strenges Schema fest. Jeder Datensatz enthält den Dokumenttyp, die Abteilung, das Datum und die Rolle des Autors. Diese Metadaten obligatorisch. Sie ermöglichen die Zugriffskontrolle bei abfragen und verhindern den abteilungsübergreifenden Informationsfluss. Speichern Sie keine unstrukturierten Rohdokumente.
Abfrageebene
Sie bearbeiten Anfragen von Klinikpersonal über eine kontrollierte Abruf-Pipeline. Jede abfragen eine rollenbasierte Zugriffskontrolle, bevor sie den Index erreicht. Ein Nutzer aus der Kardiologie Nutzer nur kardiologische Daten abrufen. Ein Terminplanungs-Bot hat keinen Zugriff auf Diagnosevermerke. Dies setzen Sie mithilfe eines „MUST“-Filters auf Abteilungs- oder Patientenkohortenebene auf Datenbankebene durch.
Führen Sie eine hybride Suche durch. Die Vektorähnlichkeit liefert semantisch relevante Textabschnitte. Metadaten schränken die Ergebnismenge ein. Leiten Sie den gefilterten Kontext an ein lokales LLM weiter. Das Modell generiert eine Antwort ausschließlich auf der Grundlage der abgerufenen Daten und fügt Quellenangaben hinzu. Das Modell darf keine Informationen erfinden oder aus externen Wissensquellen beziehen.
Prüfungsebene
Protokollieren Sie jede Interaktion lokal mit vollständiger Rückverfolgbarkeit. Jede abfragen einen Aufzeichnung einen Zeitstempel, Nutzer , die Abteilung, abfragen und die Referenzen der abgerufenen Dokumente enthält. Dieses Protokoll wird auf Ihrer Infrastruktur gespeichert und unterliegt festgelegten Aufbewahrungs- und Zugriffsrichtlinien. Sie sind nicht auf externe Protokollierungssysteme angewiesen.
Anhand dieses Protokolls können Sie jedes Zugriffsereignis rekonstruieren. Sie können feststellen, wer wann und in welcher Rolle auf welche Daten zugegriffen hat. Dies erfüllt die Anforderungen an die Nachverfolgbarkeit und verschafft Ihrem Sicherheitsteam direkten Einblick in das Systemverhalten.
Das gesamte System läuft auf handelsüblicher Hardware innerhalb des Krankenhausnetzwerks. Die End-to-End-Architektur des Systems ist in der Abbildung dargestellt:
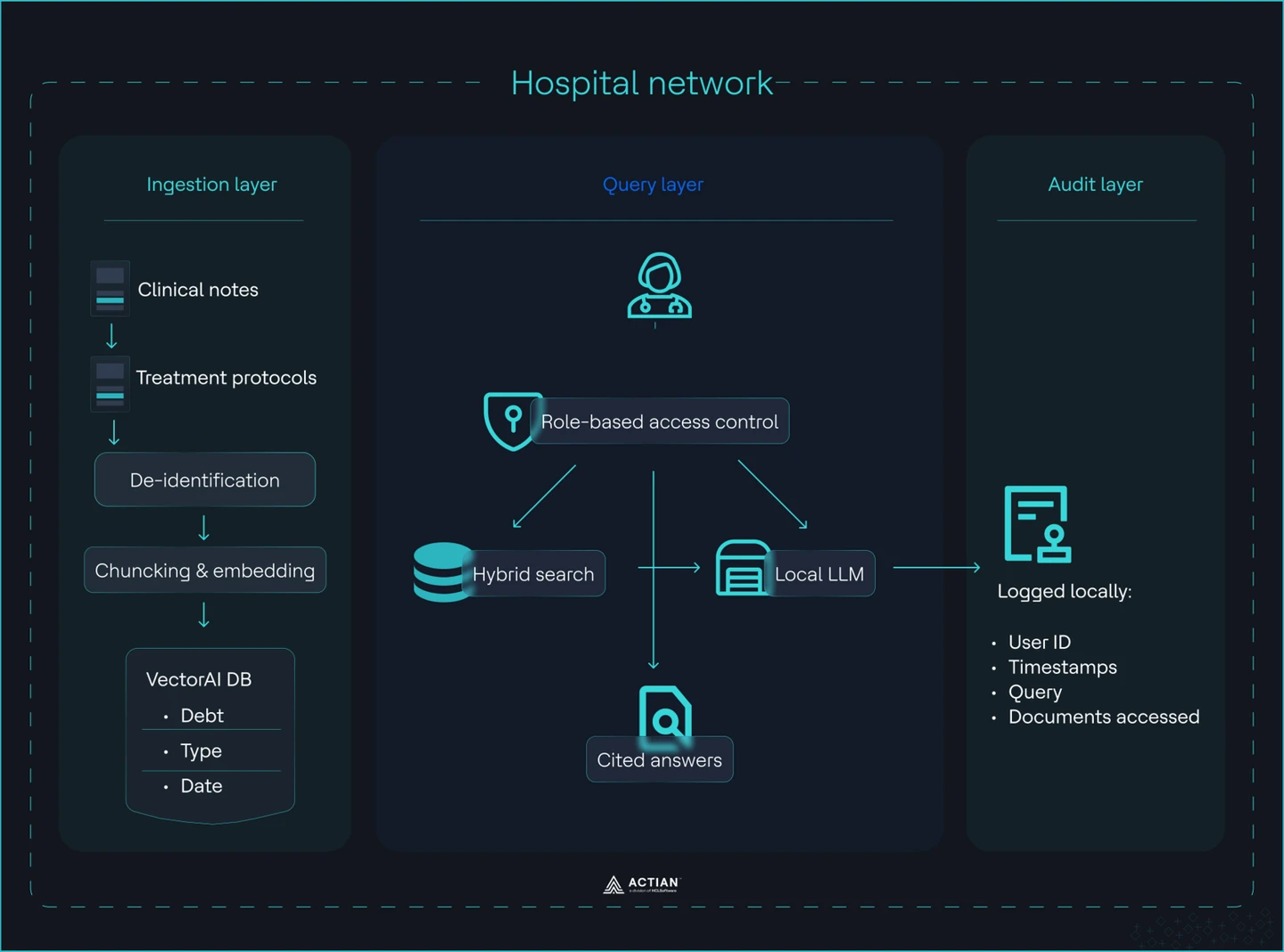
Systemarchitektur des RAG-Systems im Krankenhaus
Aufbau eines HIPAA-konformen RAG-Workflows
In diesem Abschnitt erstellen Sie ein vollständig lokal betriebenes RAG-System, das klinische Daten erfasst, Zugriffskontrollen durchführt, Abfragen beantwortet und jede Interaktion protokolliert.
Voraussetzungen
Um mitzumachen, installieren Sie bitte die folgenden Tools in Ihrem lokalen Netzwerk:
- Docker und Docker Compose sind installiert.
- Python .10 oder höher.
- PIP oder UV: In dieser Anleitung wird UV verwendet.
Schritt 1: Eine Vektordatenbank bereitstellen
Sie stellen eine lokale Instanz der Actian VectorAI DB mit persistenter Speicherung sowohl für Vektordaten als auch für Audit-Protokolle bereit.
Erstellen Sie eine docker-compose.yaml Datei:
services:
vectorai:
image: williamimoh/actian-vectorai-db:latest
platform: linux/amd64
container_name: vectorai_db
ports:
- "50052:50051"
volumes:
# vector data persists across restarts
- ./data:/app/data
# audit log lives on host — not inside the container
- ./audit_logs:/app/audit_logs
environment:
- VECTORAI_LOG_LEVEL=info
restart: unless-stopped
Den Dienst starten:
docker-compose up -dDie Datenbank wird gestartet und stellt Port 50051 für den lokalen Zugriff bereit. Vektordaten werden im Verzeichnis ./data gespeichert. Audit-Protokolle werden in ./audit_logs auf dem Host, der alle Zugriffsprotokolle innerhalb Ihrer Netzwerkgrenzen speichert.
Hinweis:
- Auf M3/M4-Apple-Silicon-Prozessoren kann es zu einem GRPC-Verbindungsabbruch kommen, ohne dass dies in den Container -Protokollen vermerkt wird . Deaktivieren Sie in diesem Fall Rosetta in Docker Desktop.
- VectorAI DB befindet sich derzeit in der aktiven Entwicklung.
Schritt 2: Aufbau der Erfassungspipeline
Installieren Sie die Client-Bibliothek und führen Sie die Erfassungspipeline aus, um klinische Dokumente in Embeddings umzuwandeln und diese in Ihrer lokalen Vektordatenbank zu speichern.
Verwenden Sie uv für das Abhängigkeitsmanagement und die Ausführung. Es ist schnell, reproduzierbar und vermeidet Python globalen Python .
Laden Sie die Actian VectorAI-Client-Paket. Dadurch wird eine Datei erstellt actian_vectorai-0.1.0b2-py3-none-any
Richte dein Projekt wie folgt ein:
uv init .
uv venvInstallieren Sie nach der Initialisierung das Actian VectorAI-Paket wie folgt:
uv pip3 install actian_vectorai-0.1.0b2-py3-none-anyFüge die Abhängigkeit des Einbettungsmodells hinzu:
uv add sentence-transformersDatei erstellen ingest.py mit folgendem Inhalt:
import re
import hashlib
from actian_vectorai import VectorAIClient, Distance, VectorParams, PointStruct
from sentence_transformers import SentenceTransformer
# ── Config ────────────────────────────────────────────────────────────────────
VECTORAI_HOST = "localhost:50052"
COLLECTION = "clinical_docs"
EMBED_MODEL = "sentence-transformers/all-MiniLM-L6-v2" # 384-dim
VECTOR_DIM = 384
CHUNK_TOKENS = 512
OVERLAP_TOKENS = 50
# ── Synthetic clinical notes (replace with real de-identified corpus) ─────────
RAW_NOTES = [
{
"document_id": "card_note_001",
"document_type": "clinical_note",
"department": "cardiology",
"date": "2025-03-15",
"author_role": "attending_physician",
"text": """
Patient: [NAME REDACTED], DOB: [DATE REDACTED], MRN: [MRN REDACTED]
Chief Complaint: Chest pain radiating to left arm, onset 2 hours ago.
Assessment: Acute ST-elevation myocardial infarction confirmed on ECG.
History: Hypertension and type 2 diabetes. Started on aspirin 325 mg,
clopidogrel 600 mg loading dose, and heparin infusion per ACS protocol.
Plan: Emergency PCI. Beta-blocker therapy with metoprolol succinate
25 mg daily post-procedure. ACE inhibitor ramipril 5 mg daily initiated
24 hours post-PCI. Follow-up echocardiography in 6 weeks.
""",
},
{
"document_id": "card_protocol_001",
"document_type": "treatment_protocol",
"department": "cardiology",
"date": "2025-01-10",
"author_role": "department_head",
"text": """
Cardiology Protocol — Heart Failure with Reduced EF (HFrEF)
First-line therapy:
- ACE inhibitor: ramipril 2.5–10 mg daily (or ARB if ACE-intolerant).
- Beta-blocker: bisoprolol 1.25–10 mg daily, carvedilol 3.125–25 mg BID,
or metoprolol succinate 12.5–200 mg daily. Titrate every 2 weeks.
- MRA: spironolactone 25–50 mg daily for NYHA class II–IV
if eGFR > 30 and K+ < 5.0.
Target: Symptomatic improvement. Reassess LVEF at 3–6 months.
Device therapy (ICD/CRT) if LVEF ≤ 35% after 3 months optimal therapy.
""",
},
{
"document_id": "psych_note_001",
"document_type": "clinical_note",
"department": "psychiatry",
"date": "2025-03-18",
"author_role": "psychiatrist",
"text": """
Psychiatry intake note — [NAME REDACTED], [AGE REDACTED]-year-old.
Presenting with major depressive episode, PHQ-9 score 18 (severe).
No current suicidal ideation. Started sertraline 50 mg daily.
Psychotherapy referral placed. Follow-up in 2 weeks.
Safety plan documented. Family support confirmed present.
""",
},
{
"document_id": "onco_note_001",
"document_type": "clinical_note",
"department": "oncology",
"date": "2025-03-20",
"author_role": "oncologist",
"text": """
Oncology note — [NAME REDACTED].
Diagnosis: Stage IIIA non-small cell lung cancer, adenocarcinoma.
EGFR mutation positive (exon 19 deletion).
Plan: Osimertinib 80 mg daily (first-line EGFR-targeted therapy).
Baseline CT chest/abdomen/pelvis completed. Brain MRI negative.
Next imaging review in 8 weeks. Antiemetics PRN, skin care for rash.
""",
},
]
# ── Step 1: De-identification ─────────────────────────────────────────────────
# For production use Presidio:
# from presidio_analyzer import AnalyzerEngine
# from presidio_anonymizer import AnonymizerEngine
# analyzer, anonymizer = AnalyzerEngine(), AnonymizerEngine()
# result = analyzer.analyze(text=raw, entities=[...], language="en")
# clean = anonymizer.anonymize(text=raw, analyzer_results=result).text
#
# This demo applies lightweight regex to already-synthetic notes.
_HIPAA_PATTERNS = [
(r"\b\d{3}-\d{2}-\d{4}\b", "[SSN]"), # SSN
(r"\bMRN[-:\s]*\d{4,10}\b", "[MRN]"), # medical record #
(r"\b\d{1,2}/\d{1,2}/\d{2,4}\b", "[DATE]"), # dates
(r"\b[A-Z][a-z]+ [A-Z][a-z]+\b", "[NAME]"), # names (simple)
(r"\b\d{3}[-.\s]\d{3}[-.\s]\d{4}\b", "[PHONE]"), # phone
(r"\b[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.\w+\b","[EMAIL]"), # email
(r"\b\d{5}(?:-\d{4})?\b", "[ZIP]"), # zip
(r"\b(?:https?://)\S+", "[URL]"), # URLs
(r"\b\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\b", "[IP]"), # IP addresses
]
def deidentify(text: str) -> str:
"""Remove HIPAA Safe Harbor identifiers from text."""
for pattern, replacement in _HIPAA_PATTERNS:
text = re.sub(pattern, replacement, text)
return text.strip()
# ── Step 2: Chunking ──────────────────────────────────────────────────────────
def chunk(text: str, size: int = CHUNK_TOKENS, overlap: int = OVERLAP_TOKENS) -> list[str]:
"""Split text into overlapping token windows (whitespace tokenisation)."""
tokens = text.split()
chunks, start = [], 0
while start < len(tokens):
end = min(start + size, len(tokens))
chunks.append(" ".join(tokens[start:end]))
if end == len(tokens):
break
start += size - overlap
return chunks
# ── Step 3: Embedding ─────────────────────────────────────────────────────────
print(f"Loading embedding model: {EMBED_MODEL}")
_model = SentenceTransformer(EMBED_MODEL)
def embed(texts: list[str]) -> list[list[float]]:
return _model.encode(texts, normalize_embeddings=True).tolist()
# ── Step 4: Ingest into VectorAI DB ──────────────────────────────────────────
def _chunk_id(doc_id: str, idx: int) -> int:
"""Stable integer ID from (document_id, chunk_index)."""
h = hashlib.sha256(f"{doc_id}:{idx}".encode()).hexdigest()
return int(h[:15], 16)
def ingest(notes: list[dict]) -> None:
with VectorAIClient(VECTORAI_HOST) as client:
# Health check
info = client.health_check()
print(f"VectorAI DB connected version={info['version']}")
# Create collection (skip if already exists)
try:
client.collections.create(
name=COLLECTION,
vectors_config=VectorParams(size=VECTOR_DIM, distance=Distance.Cosine),
)
print(f"Collection '{COLLECTION}' created dim={VECTOR_DIM}")
except Exception as e:
if "exists" in str(e).lower():
print(f"Collection '{COLLECTION}' already exists — skipping create")
else:
raise
total_chunks = 0
for note in notes:
# De-identify FIRST — before chunking or embedding
clean_text = deidentify(note["text"])
# Chunk second
chunks = chunk(clean_text)
# Embed third
vectors = embed(chunks)
# Build PointStruct records with strict metadata schema
# All four metadata fields are REQUIRED — no optional fields.
points = [
PointStruct(
id=_chunk_id(note["document_id"], i),
vector=vectors[i],
payload={
# ── strict schema ──────────────────────────────────────
"document_type": note["document_type"], # required
"department": note["department"], # required — RBAC filter key
"date": note["date"], # required
"author_role": note["author_role"], # required
# ── retrieval helpers ──────────────────────────────────
"document_id": note["document_id"],
"chunk_index": i,
"text": chunks[i], # de-identified chunk text
},
)
for i in range(len(chunks))
]
client.points.upsert(COLLECTION, points)
total_chunks += len(chunks)
print(f" ✓ {note['document_id']} dept={note['department']} chunks={len(chunks)}")
print(f"\nIngestion complete — {len(notes)} documents, {total_chunks} chunks total")
if __name__ == "__main__":
ingest(RAW_NOTES)
Diese Datei führt folgende Aktionen aus:
- Anonymisierung von Daten: Das System entfernt vor der Verarbeitung alle HIPAA-Identifikatoren aus dem Rohtext. Namen, Daten und andere sensible Felder werden durch Platzhalter ersetzt, um zu verhindern, dass geschützte Gesundheitsdaten (PHI) in die System-Pipeline gelangen.
- Aufteilung des Textes in Segmente: Das System teilt den bereinigten Text in Segmente von jeweils 512 Token auf, wobei sich die Segmente um jeweils 50 Token überlappen. Durch diese Überlappung bleibt der Kontext über die Segmentgrenzen hinweg erhalten, was die Genauigkeit der Suchergebnisse verbessert.
- Einbettung der Chunks: Das Modell wandelt jeden Chunk mithilfe eines lokalen „Sentence Transformers“-Modells in einen numerischen Vektor um. Dieser Prozess erfasst die semantische Bedeutung, während die gesamte Verarbeitung innerhalb des Netzwerks erfolgt.
- Datensätze mit Metadaten: Das System speichert jeden Datenblock und seinen Vektor in der VectorAI-Datenbank, zusammen mit den erforderlichen Feldern wie document_type, department, date und author_role. Diese Felder ermöglichen eine strenge Zugriffskontrolle bei Abfragen.
Führen Sie das Skript wie folgt aus:
uv run ingest.py
Nach Ausführung des Befehls sollten folgende Ergebnisse angezeigt werden:
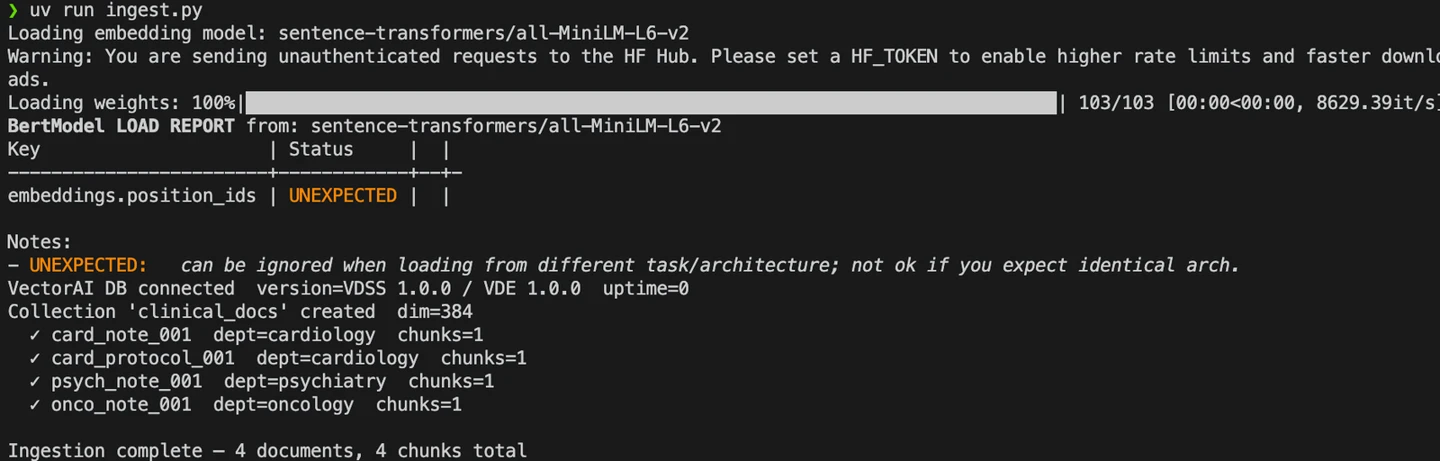
Ausführung von ingest.py
Aus den Protokollen geht hervor, dass die Erfassungspipeline Blöcke in die VectorAI-Datenbank schreibt.
Schritt 3: Führen Sie Ihre Abfragen aus
Führen Sie Abfragen in Ihrem lokalen RAG-System durch und überprüfen Sie die Datenabfrage, die Zugriffskontrolle und die Protokollierung.
Datei erstellen query.py mit folgendem Inhalt:
import json
import datetime
import urllib.request
import urllib.error
from pathlib import Path
from actian_vectorai import VectorAIClient
from actian_vectorai import FilterBuilder, Field
from sentence_transformers import SentenceTransformer
# ── Config ─────────────────────────────────────────────────────────────────────
VECTORAI_HOST = "localhost:50052"
COLLECTION = "clinical_docs"
EMBED_MODEL = "sentence-transformers/all-MiniLM-L6-v2"
AUDIT_LOG = Path("./audit_logs/queries.jsonl") # volume-mounted path
# Ollama settings — set OLLAMA_ENABLED=True once `ollama serve` is running
OLLAMA_ENABLED = False # flip to True when Ollama is ready
OLLAMA_URL = "https://localhost:11434/api/generate"
OLLAMA_MODEL = "mistral" # or "llama3.2:3b" for lower hardware
# ── RBAC: role → allowed departments ──────────────────────────────────────────
# Access is enforced as a MUST filter at the database level.
# A scheduling_bot cannot reach clinical notes; cardiology cannot see psychiatry.
ROLE_PERMISSIONS = {
"cardiology_clinician": ["cardiology"],
"oncology_clinician": ["oncology"],
"general_practitioner": ["cardiology", "oncology", "general"],
"admin": ["cardiology", "oncology", "psychiatry", "general"],
"scheduling_bot": ["scheduling"], # no clinical note access
}
class AccessDeniedError(Exception):
pass
def allowed_departments(role: str) -> list[str]:
if role not in ROLE_PERMISSIONS:
raise AccessDeniedError(f"Unknown role '{role}' — access denied by default.")
return ROLE_PERMISSIONS[role]
# ── Embedding (reuse the same model as ingest.py) ─────────────────────────────
print(f"Loading embedding model: {EMBED_MODEL}")
_model = SentenceTransformer(EMBED_MODEL)
def embed(text: str) -> list[float]:
return _model.encode([text], normalize_embeddings=True).tolist()[0]
# ── Step 5: Search with department MUST filter ─────────────────────────────────
def retrieve(query_vec: list[float], departments: list[str], top_k: int = 5) -> list[dict]:
"""
Hybrid retrieval: vector similarity + metadata MUST filter.
Results from departments outside the allowed list are impossible —
the filter is applied at the database level, not in application code.
"""
results = []
with VectorAIClient(VECTORAI_HOST) as client:
for dept in departments:
hits = client.points.search(
collection_name=COLLECTION,
vector=query_vec,
limit=top_k,
# MUST filter — department equality enforced at DB level
filter=FilterBuilder().must(Field("department").eq(dept)).build(),
)
for hit in hits:
payload = getattr(hit, "payload", {}) or {}
results.append({
"score": round(getattr(hit, "score", 0.0), 4),
"document_id": payload.get("document_id"),
"document_type": payload.get("document_type"),
"department": payload.get("department"),
"date": payload.get("date"),
"author_role": payload.get("author_role"),
"chunk_index": payload.get("chunk_index"),
"text": payload.get("text", ""),
})
results.sort(key=lambda r: r["score"], reverse=True)
return results[:top_k]
# ── Step 6: LLM answer via Ollama ─────────────────────────────────────────────
_RAG_SYSTEM = (
"You are a clinical decision support assistant. "
"Answer ONLY using the context passages below. "
"Do NOT use external knowledge or make assumptions. "
"Cite each fact as [Doc N]. "
"If the context is insufficient, say: 'I cannot answer from the available documents.'"
)
def build_context(chunks: list[dict]) -> str:
return "\n\n".join(
f"[Doc {i+1}] ({c['document_type']}, dept={c['department']}, "
f"date={c['date']}, role={c['author_role']})\n{c['text']}"
for i, c in enumerate(chunks)
)
def generate(query_text: str, chunks: list[dict]) -> str:
if not OLLAMA_ENABLED:
# Return raw retrieved context when LLM is disabled
return "[LLM disabled — set OLLAMA_ENABLED=True]\n\n" + build_context(chunks)
context = build_context(chunks)
prompt = f"{_RAG_SYSTEM}\n\nContext:\n{context}\n\nQuestion: {query_text}\n\nAnswer:"
payload = json.dumps({
"model": OLLAMA_MODEL,
"prompt": prompt,
"stream": False,
"options": {"num_predict": 400},
}).encode()
try:
req = urllib.request.Request(
OLLAMA_URL,
data=payload,
headers={"Content-Type": "application/json"},
method="POST",
)
with urllib.request.urlopen(req, timeout=30) as resp:
data = json.loads(resp.read())
return data.get("response", "").strip()
except urllib.error.URLError as e:
return f"[Ollama unreachable: {e}]\n\nRetrieved context:\n{build_context(chunks)}"
def write_audit(record: dict) -> None:
AUDIT_LOG.parent.mkdir(parents=True, exist_ok=True)
with open(AUDIT_LOG, "a", encoding="utf-8") as f:
f.write(json.dumps(record, ensure_ascii=False) + "\n")
# ── Public query entry point ───────────────────────────────────────────────────
def query(user_id: str, role: str, query_text: str, top_k: int = 5) -> dict:
"""
Execute a role-gated RAG query.
Returns:
{answer, retrieved_docs, access_denied, error}
"""
timestamp = datetime.datetime.now(datetime.timezone.utc).isoformat()
# RBAC check — before anything else
try:
departments = allowed_departments(role)
except AccessDeniedError as e:
write_audit({
"timestamp": timestamp, "user_id": user_id, "role": role,
"department": "DENIED", "query_text": query_text,
"retrieved_docs": [], "answer_provided": False, "access_denied": True,
"denial_reason": str(e),
})
return {"answer": f"Access denied: {e}", "retrieved_docs": [], "access_denied": True}
# Embed → retrieve (with MUST filter) → generate
q_vec = embed(query_text)
chunks = retrieve(q_vec, departments, top_k)
answer = generate(query_text, chunks)
doc_refs = [
{"document_id": c["document_id"], "chunk_index": c["chunk_index"],
"department": c["department"], "document_type": c["document_type"],
"score": c["score"]}
for c in chunks
]
# Audit log — every query, regardless of outcome
write_audit({
"timestamp": timestamp,
"user_id": user_id,
"role": role,
"department": ",".join(departments),
"query_text": query_text,
"retrieved_docs": doc_refs,
"answer_provided": True,
"access_denied": False,
})
return {"answer": answer, "retrieved_docs": doc_refs, "access_denied": False}
# ── Demo runs ─────────────────────────────────────────────────────────────────
if __name__ == "__main__":
separator = "─" * 60
# ── Query 1: authorised cardiology query ────────────────────────────────
print(f"\n{separator}")
print("QUERY 1 — cardiology_clinician (authorised)")
print(separator)
r1 = query(
user_id="dr_chen_007",
role="cardiology_clinician",
query_text="What beta-blocker is recommended for heart failure with reduced ejection fraction?",
)
print(f"\nAnswer:\n{r1['answer']}\n")
print("Retrieved sources:")
for d in r1["retrieved_docs"]:
print(f" score={d['score']} [{d['document_type']}] dept={d['department']} "
f"doc={d['document_id']} chunk={d['chunk_index']}")
# ── Query 2: scheduling bot tries to access clinical notes ───────────────
print(f"\n{separator}")
print("QUERY 2 — scheduling_bot (attempting clinical note access)")
print(separator)
r2 = query(
user_id="bot_sched_01",
role="scheduling_bot",
query_text="What are the diagnosis notes for cardiology patients?",
)
if r2["access_denied"]:
print(f"\n✗ Access denied (as expected): {r2['answer']}")
else:
print(f"\nAnswer:\n{r2['answer']}")
print("Sources:", r2["retrieved_docs"])
# ── Query 3: cardiology query that must NOT return psychiatry notes ───────
print(f"\n{separator}")
print("QUERY 3 — cardiology_clinician (RBAC must exclude psychiatry)")
print(separator)
r3 = query(
user_id="dr_chen_007",
role="cardiology_clinician",
query_text="antidepressant dosing and patient management",
)
departments_returned = {d["department"] for d in r3["retrieved_docs"]}
cross_leak = "psychiatry" in departments_returned
print(f"\nDepartments in results: {departments_returned or 'none'}")
print(f"Cross-department leak: {'✗ LEAK DETECTED' if cross_leak else '✓ none — RBAC working correctly'}")
# ── Show audit log tail ───────────────────────────────────────────────────
print(f"\n{separator}")
print("AUDIT LOG → {AUDIT_LOG}")
print(separator)
if AUDIT_LOG.exists():
lines = AUDIT_LOG.read_text().strip().splitlines()
for line in lines[-3:]: # show last 3 entries
entry = json.loads(line)
print(json.dumps({
"timestamp": entry["timestamp"],
"user_id": entry["user_id"],
"role": entry["role"],
"query_text": entry["query_text"][:60] + "…",
"docs_accessed": len(entry["retrieved_docs"]),
"access_denied": entry["access_denied"],
}, indent=2))
else:
print("No audit log found — run ingest.py first.")
Das Skript führt drei Kernvorgänge in einem einzigen Ablauf durch.
- Setzt die Zugriffskontrolle durch: Das System überprüft die Rolle Nutzer, bevor Daten abgerufen werden. Jede Rolle ist bestimmten Abteilungen zugeordnet und wird auf Datenbankebene als obligatorischer Filter durchgesetzt. Die Autorisierungsebene blockiert und protokolliert nicht autorisierte Rollen sofort.
- Antworten abrufen und generieren: Das System bettet die abfragen ein abfragen ruft relevante Dokumentausschnitte mithilfe einer Vektorsuche ab, wobei strenge Abteilungsfilter angewendet werden. Die Ergebnisse werden dann an ein lokales LLM weitergeleitet. Ist das LLM deaktiviert, wird der abgerufene Kontext direkt zurückgegeben.
- Protokollierung von Zugriffen: Das System protokolliert jede abfragen , einschließlich der Nutzer , der Rolle, abfragen , der aufgerufenen Dokumente und des Zugriffsstatus. Dadurch entsteht ein vollständiges Protokoll Compliance- und Überprüfungszwecke.
Führen Sie das Skript wie folgt aus:
uv run query.py
Nach Ausführung des Befehls sollten folgende Ergebnisse angezeigt werden:
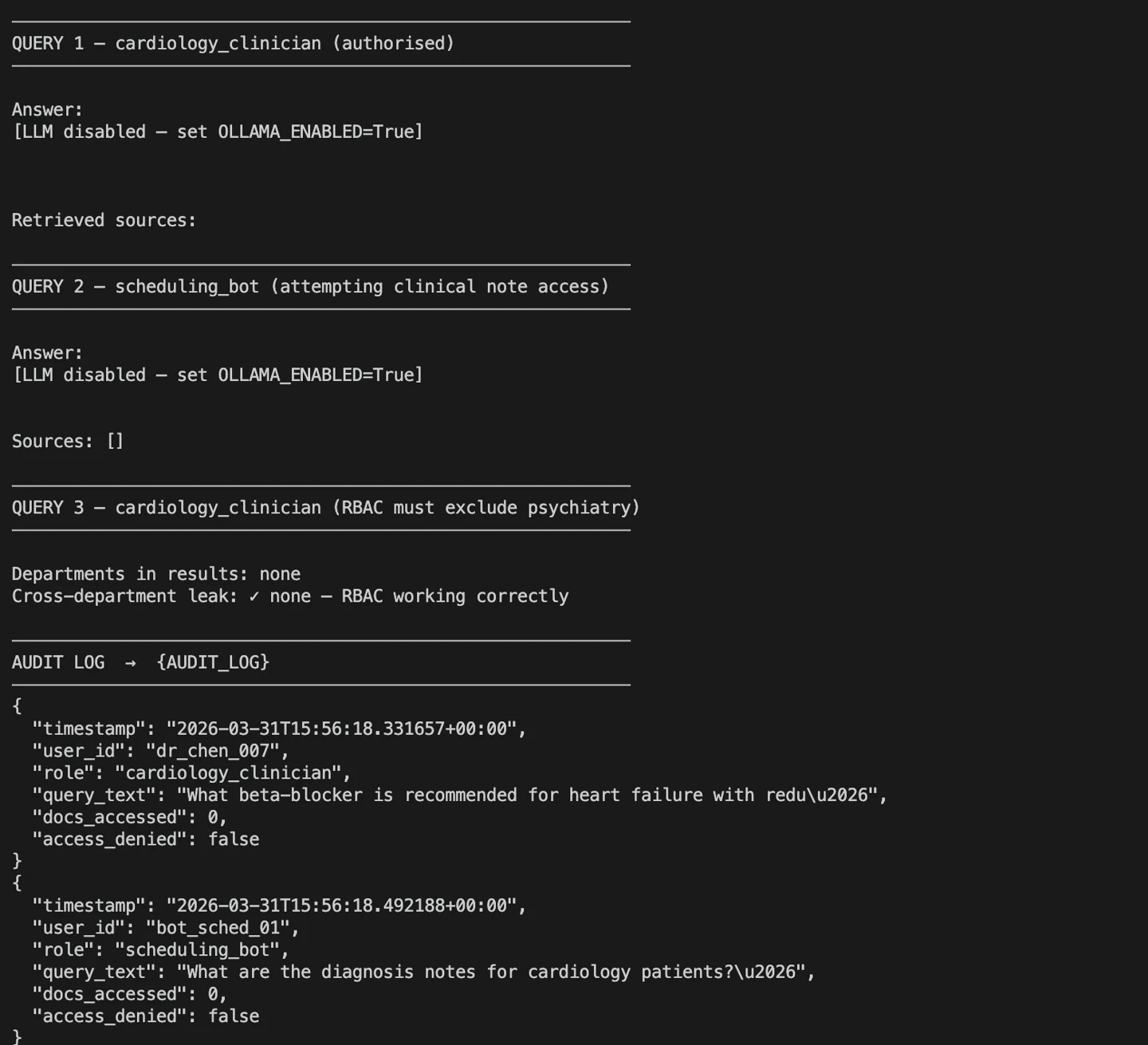
Ausführung von abfragen.py“
Die Ausgabe zeigt drei Testfälle: einen mit einer gültigen abfragen eines Klinikmitarbeiters, einen abgelehnten Zugriffsversuch und eine Überprüfung auf abteilungsübergreifende Datenlecks. Diese bestätigen, dass RBAC und die Protokollierung ordnungsgemäß funktionieren, bevor Sie in die Produktion übergehen.
Schritt 4: Konfigurieren Sie das Überwachungsprotokoll
Speichern Sie alle abfragen , indem Sie die bei Deployment definierte Datenträgerzuordnung verwenden.
Die Docker-Konfiguration bindet den Ordner „./audit_logs“ von Ihrem Host in den Container ein. Wenn Sie Abfragen ausführen, wird dadurch ein lokaler Ordner namens „audit_logs“ mit einer Datei namens „queries.jsonl“ erstellt.
Die Datei enthält folgende Einträge:
{"timestamp": "2026-03-31T15:56:02.552088+00:00", "user_id": "dr_chen_007", "role": "cardiology_clinician", "department": "cardiology", "query_text": "What beta-blocker is recommended for heart failure with reduced ejection fraction?", "retrieved_docs": [], "answer_provided": true, "access_denied": false}
{"timestamp": "2026-03-31T15:56:03.098346+00:00", "user_id": "bot_sched_01", "role": "scheduling_bot", "department": "scheduling", "query_text": "What are the diagnosis notes for cardiology patients?", "retrieved_docs": [], "answer_provided": true, "access_denied": false}
{"timestamp": "2026-03-31T15:56:03.663767+00:00", "user_id": "dr_chen_007", "role": "cardiology_clinician", "department": "cardiology", "query_text": "antidepressant dosing and patient management", "retrieved_docs": [], "answer_provided": true, "access_denied": false}
{"timestamp": "2026-03-31T15:56:18.331657+00:00", "user_id": "dr_chen_007", "role": "cardiology_clinician", "department": "cardiology", "query_text": "What beta-blocker is recommended for heart failure with reduced ejection fraction?", "retrieved_docs": [], "answer_provided": true, "access_denied": false}
{"timestamp": "2026-03-31T15:56:18.492188+00:00", "user_id": "bot_sched_01", "role": "scheduling_bot", "department": "scheduling", "query_text": "What are the diagnosis notes for cardiology patients?", "retrieved_docs": [], "answer_provided": true, "access_denied": false}
{"timestamp": "2026-03-31T15:56:18.569824+00:00", "user_id": "dr_chen_007", "role": "cardiology_clinician", "department": "cardiology", "query_text": "antidepressant dosing and patient management", "retrieved_docs": [], "answer_provided": true, "access_denied": false}Jede Zeile steht für ein einzelnes abfragen . Das Protokoll erfasst, wer die Anfrage gestellt hat, welche Rolle diese Person innehat, welchen Abteilungsbereich die Anfrage betrifft, den abfragen sowie, ob der Zugriff gewährt wurde. Diese Datei befindet sich vollständig auf Ihrer Infrastruktur und bietet Ihnen ein lückenloses, überprüfbares Protokoll jede Interaktion mit geschützten Gesundheitsdaten.
Zum Abschluss
Eine BAA reichte nie aus, da sie nicht regelt, wie Ihre Anwendung mit geschützten Gesundheitsdaten umgeht. Sie haben dieses Problem gelöst, indem Sie alle Daten, Abfragen und Protokolle innerhalb Ihres Netzwerks aufbewahren.
Sie verfügen nun über ein RAG-System, das rollenbasierten Zugriff gewährleistet, nur autorisierte Daten abruft und jede Interaktion lokal protokolliert – ganz ohne externe APIs oder die Einbindung von Drittanbietern.
Wenden Sie dieses Muster auf andere regulierte Systeme an. Informationen zu Aktualisierungen und Details zur Implementierung finden Sie in der VectorAI-DB-Dokumentation und auf GitHub Lager.
Werden Sie Teil der Communityund erfahren Sie mehr über Actian.

Bleiben Sie in Verbindung
Datenanalysen direkt bei Ihnen.
(z. B. sales@..., support@...)