For most of the last decade, the on-premises vs. cloud debate felt settled. Cloud computing was cheaper, faster, and easier to adopt. Enterprises moved workloads from on-premises infrastructure to public cloud services, relying on major cloud providers to handle scalability, maintenance, and security.
In 2026, that assumption is breaking, and cracks are showing up in legal reviews, financial projects, and SLA negotiations. Enterprises are facing an increasing pressure for data residency regulations, stricter enforcement, and scrutiny around cloud security models. Compliance constraints, data security requirements, cost predictability, and latency are forcing teams to reconsider on-premises solutions, private cloud computing, and hybrid cloud infrastructure.
At the same time, AI is moving closer to where data is generated. Manufacturing sites, retail stores, and healthcare environments increasingly require offline capability and sub-100ms latency. That shift helps explain why Oracle released AI Database 26ai for on-premises deployment and why Google is pushing Gemini onto Distributed Cloud for air-gapped environments. This shift signals that large-scale enterprise AI no longer fits neatly in cloud environments.
In this article, we’ll examine why on-premises infrastructure is resurging, what trade-offs you need to know, and how to make defensible deployment decisions.
What’s Driving the On-Premises Resurgence
The renewed interest in on-premises infrastructure is not about going back to old systems. It is a response to clear changes in how AI systems are being built and used in 2025 and 2026. For many enterprises, cloud-only vector databases no longer fit their compliance, cost, and reliability needs.
A lot of factors drive this current on-premises resurgence, but in this article, we will consider four key causes.
Large vendors now support on-premises AI
On-premises AI is no longer treated as an edge case by major vendors. Oracle’s release of AI Database 26ai and Google’s decision to run Gemini on Distributed Cloud show a clear shift in how enterprise AI is being packaged and delivered.
These products are built for large enterprises, not early-stage experiments or research projects. That distinction matters. Large vendors do not invest in complex on-premises AI platforms unless there is strong and growing customer demand. These announcements confirm that many enterprises want to run AI systems inside their own environments, close to their data, and under their full operational control. Why is this?
Regulatory pressure is now a real blocker
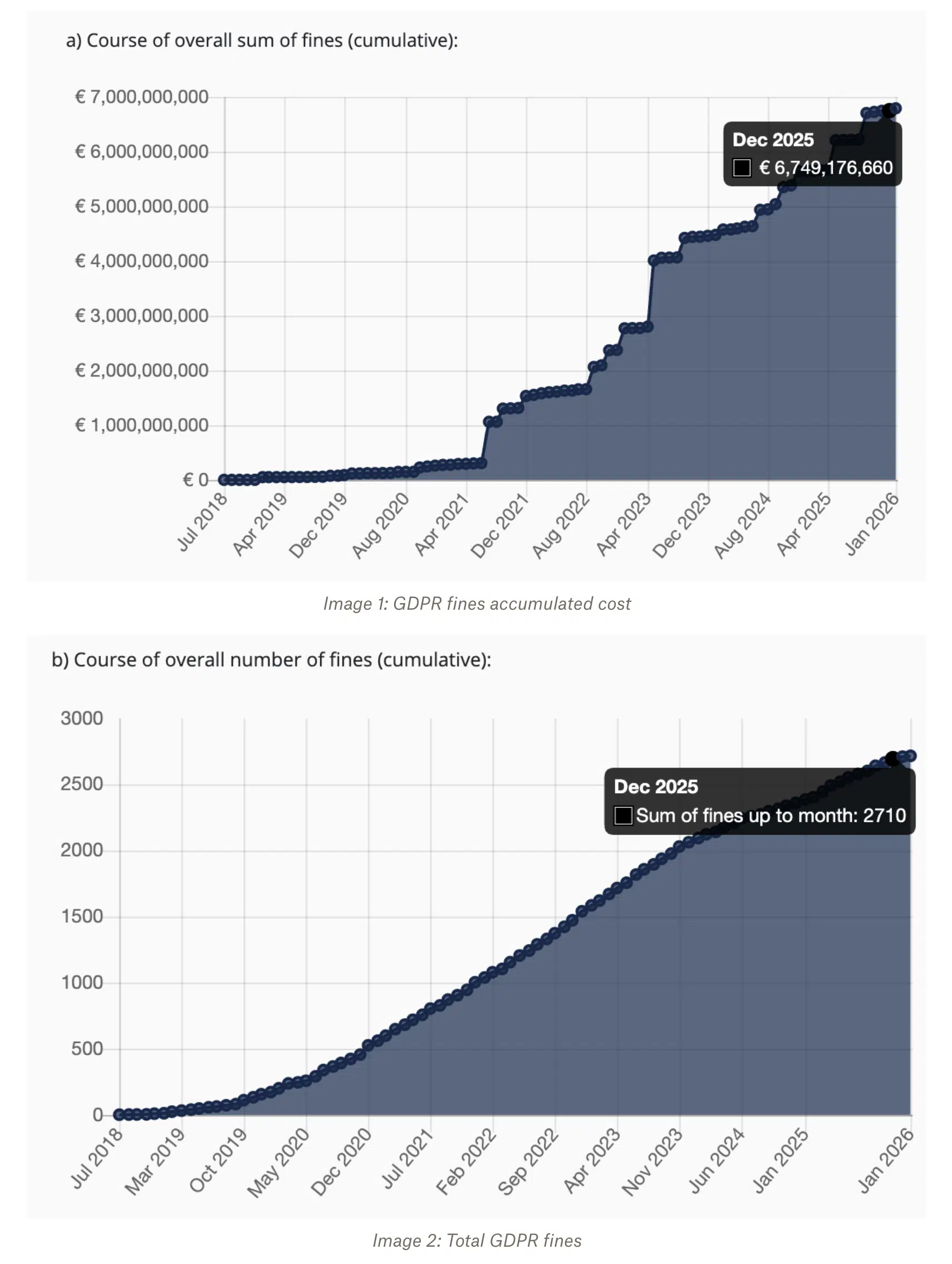
Teams used to plan for regulatory risk as a future possibility. Now it’s a day-to-day reality. GDPR enforcement reached record levels in 2025, with insufficient legal basis for data processing driving the largest penalties. That year alone, regulators issued nearly 2,700 fines totaling billions of euros.
From a data security perspective, GDPR enforcement has fundamentally changed how enterprises evaluate cloud services. While cloud service providers offer compliance tooling, legal teams are increasingly wary of relying on third-party providers for sensitive data storage and processing.
HIPAA adds another layer of complexity. For example, in Florida, physicians must maintain medical records for five years after the last patient contact, whereas hospitals must maintain them for seven years under state record-retention requirements. This makes repeated data movement risky and expensive. Financial services and government contractors face similar data sovereignty requirements that limit where data can be stored and processed. In these situations, cloud deployments add legal review, audit work, and ongoing risk. Keeping data on-premises is often the most straightforward way to meet these obligations.
Edge AI requires local and offline operation
AI workloads are increasingly deployed close to where data is created. Manufacturing facilities may operate in air-gapped environments or remote locations with limited connectivity. Retail systems must continue working during network outages. Healthcare applications often require very low latency for real-time decision support.
In these environments, relying on a remote cloud service introduces risk. Network delays and outages directly affect system reliability. On-premises and edge deployments allow vector search and inference to run locally, without depending on constant network access. For many use cases, this local execution is not an optimization but a requirement.
Together, these shifts explain why on-premises vector databases are gaining traction again. The change is driven by the practical realities of deploying production AI systems under real regulatory, cost, and reliability constraints.
The Compliance Calculus
For many enterprises, compliance is the deciding factor in the on-premises versus cloud debate. While cloud providers offer compliance certifications, the real challenge is not whether a platform can be compliant in theory, but whether it can withstand legal review, audits, and long-term operational scrutiny in practice. Once vector databases move into production and begin storing sensitive or regulated data, these questions become unavoidable.
GDPR and the limits of cross-border transfers
The Schrems II ruling changed how European data can be processed outside the EU. Privacy Shield was invalidated, leaving Standard Contractual Clauses as the primary legal mechanism for cross-border data transfers. In highly regulated industries such as financial services and healthcare, many legal teams consider SCCs insufficient due to enforcement uncertainty and ongoing legal challenges.
For vector databases, this matters because embeddings often contain derived personal data. Even if raw records are masked or tokenized, embeddings can still be considered personal data under GDPR. If data must remain within the EEA, or within a specific country, cloud deployments that rely on global infrastructure introduce legal risk. In these cases, on-premises or in-region deployment becomes a requirement rather than a preference.
HIPAA retention and the real cost of data movement
HIPAA does not explicitly require data to stay on-premises, but it does require long retention periods and strict access controls. When vector embeddings are built on top of this data, they inherit the same retention requirements. HIPAA data governance must be enforced when considering on-premises or cloud vector databases.
The cost impact becomes clear when egress fees are included. Consider a system storing 100 TB of embeddings in a cloud environment. At a common egress rate of $0.09 per GB, moving that data out of the cloud over a seven-year retention period results in:
100 TB × $0.09 per GB × 84 months = over $750,000 in egress costs alone
This does not include compute, storage, or indexing costs. With this in mind, will cloud data warehouses really help you cut costs?
Financial services and data sovereignty rules
Financial institutions face additional constraints beyond GDPR. Regulations such as GLBA, APRA, and regional data sovereignty mandates often require strict control over where customer data is stored and processed. Regulators may demand clear evidence of geographic boundaries, access controls, and auditability.
Cloud services can meet some of these requirements, but they often introduce complex configurations, contractual dependencies, and ongoing compliance reviews. For many banks and insurers, on-premises deployment simplifies audits by keeping data within a controlled infrastructure that regulators already understand.
Government and public sector constraints
Government contracts introduce some of the strictest infrastructure requirements. Standards such as FedRAMP often mandate US-only infrastructure, restricted access, and tightly controlled environments.
In these cases, public cloud services are frequently disallowed or require extensive approvals. On-premises deployment is often the only viable option for running vector databases in support of government workloads.
When compliance makes cloud untenable
If legal teams flag cross-border data transfers as unacceptable, cloud deployments quickly become impractical. Once data residency is mandatory, on-premises deployment is no longer a trade-off decision. It is a compliance requirement.
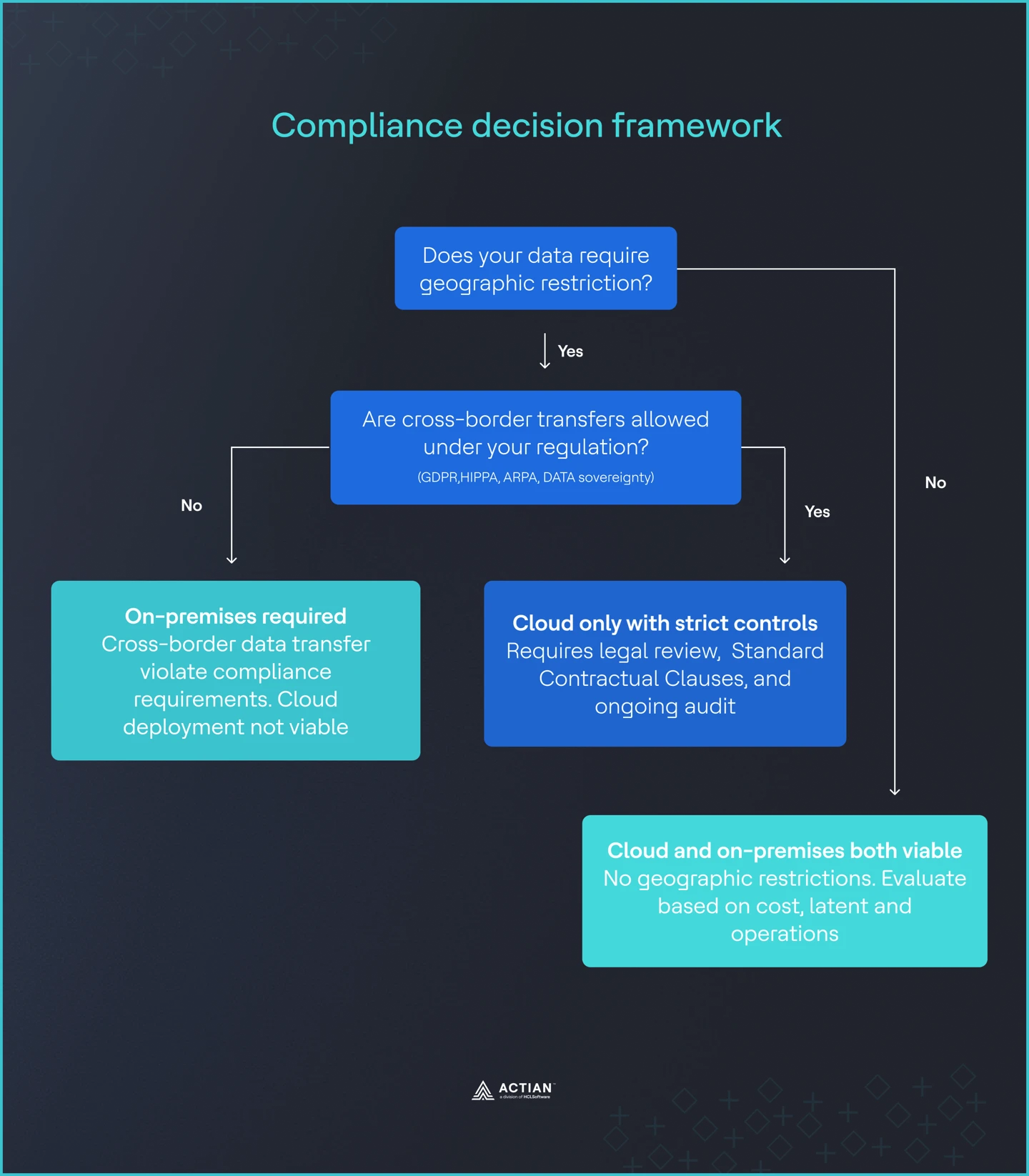
Image 3: Compliance framework
The Cost Breakdown Analysis
Cost is often the reason teams revisit the on-premises versus cloud decision. To make a defensible decision, teams need to understand where costs diverge and when self-hosting becomes economically rational.
Where self-hosting breaks even
Research from OpenMetal shows a consistent breakeven point for Pinecone vector databases at scale. Once workloads reach roughly 80 to 100 million queries per month, self-hosted deployments tend to be cheaper than managed cloud services. Below this range, cloud pricing is usually competitive. Above it, usage-based billing begins to dominate total cost.
This threshold matters because many enterprise RAG systems cross it quickly. Customer support, document search, fraud detection, and recommendation systems often serve tens or hundreds of millions of queries each month once deployed across business units or regions.
The hidden cost in cloud pricing
Cloud pricing is rarely just a per-query fee. Vector databases introduce several cost drivers that are easy to overlook during planning.
Egress fees are a major factor. Most cloud providers charge around $0.09 per GB for data leaving their network. Moving embeddings between regions, exporting data for analytics, or migrating to another system all incur these fees. Over time, they become a meaningful portion of total spend.
Finally, vector search does not scale linearly. As vector counts grow and dimensionality increases, query costs rise faster than expected. What looks affordable at 10 million vectors can become expensive at 500 million, even if query volume grows steadily.
On-premises costs are fixed and predictable
On-premises deployments have real costs, but they behave differently. Hardware is typically amortized over three to five years. Staffing requirements are stable once the system is running. Facilities and power costs are known in advance.
The key difference is predictability. Costs do not spike because of usage patterns or data movement. Once the system is sized correctly, monthly spend remains largely flat, even as query volume increases.
A real-world example
Consider a production e-commerce application with the following scale:
- 500M vectors.
- 200M queries every month.
- 1024 vector dimensions.
- 6M writes monthly.
At this scale, a typical managed Pinecone vector database costs around $8,500 per month once compute, storage, and rebuild overhead are included.
Estimated monthly cost
Total Estimated Cost: $8,454 / month
- Storage
- Query Costs
- Configuration:
- 24 b1 nodes
- 4 shards × 6 replicas
- Assumption: 1% filter selectivity
- Estimated Cost: $8,074
- Note: Actual query cost may vary. Benchmark your workload on DRN for more accurate estimates.
- Write Costs
- Write Volume: 30 million Write Units (WU)
- Assumption: Each write request consumes ≥ 5 WU
- Cost: $101
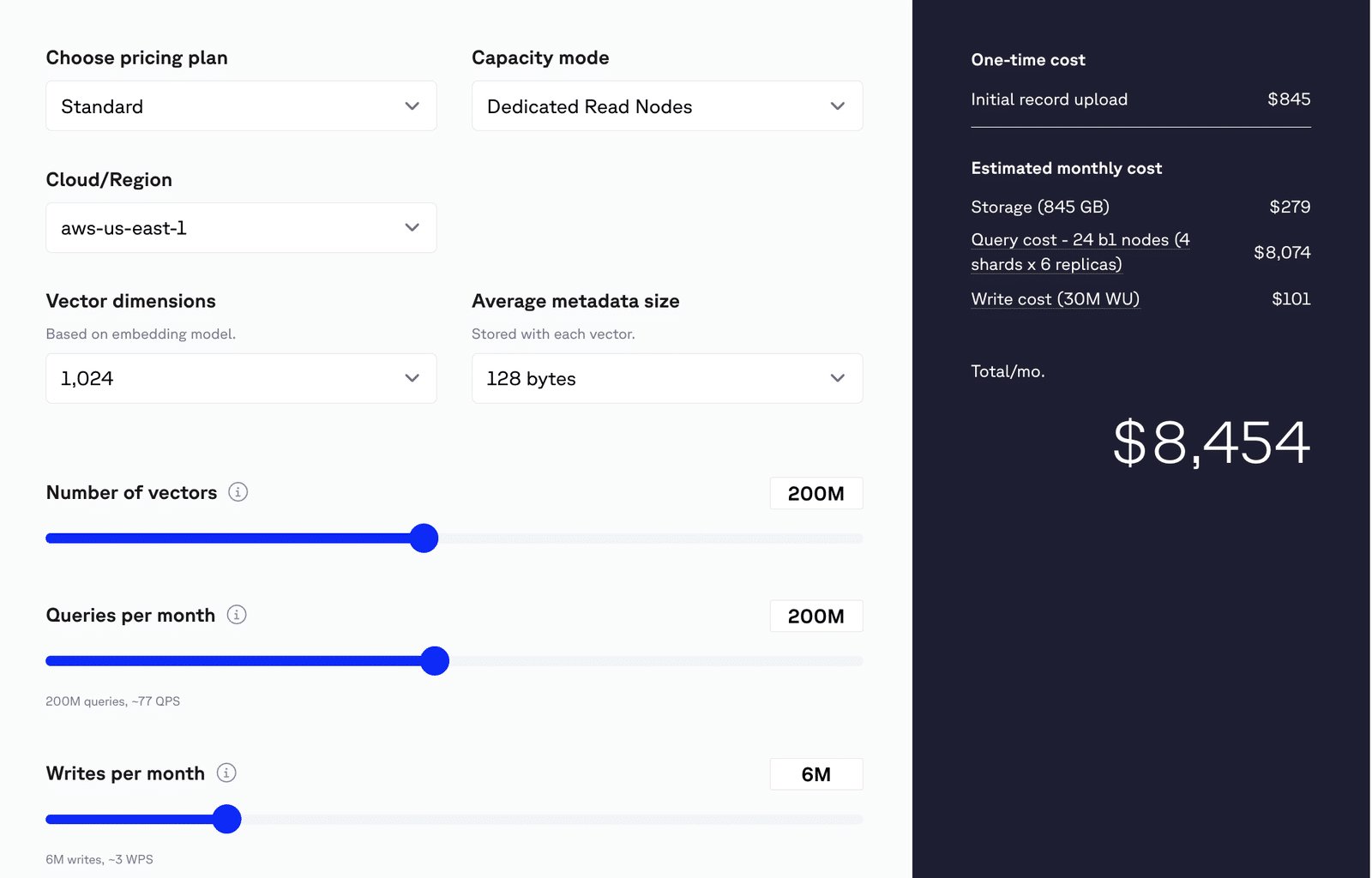
Image 4: Pinecone cost estimation
An equivalent on-premises deployment might cost approximately half of that after hardware amortization, assuming an 18-month payback period and one to two engineers supporting the system. After that payback period, costs drop further while capacity remains available.
A study by Enterprise Storage Forum shows the cost projection of on-premises and cloud workloads.
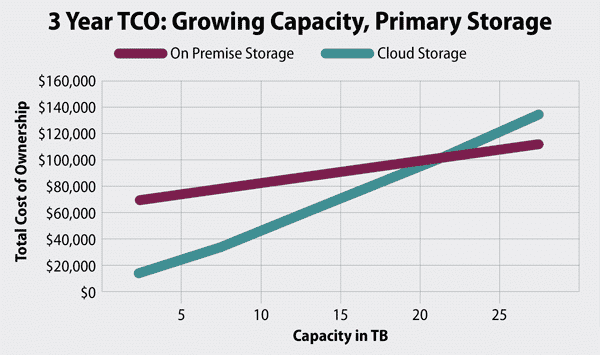
Image 5: Enterprise storage forum TCO
Cost alone does not decide every deployment, but once vector workloads reach scale, the economics become difficult to ignore. Understanding where your system sits on this curve is essential before locking in a long-term vector database strategy.
When Latency and Connectivity Matter
Latency and connectivity are often treated as secondary concerns in architecture decisions. For many AI workloads, they are decisive. Once vector databases support real-time systems, network round-trips, and internet dependency can make cloud deployments impractical or unsafe.
Real-time response requirements
Some applications have strict response time limits. In healthcare, clinical decision support and diagnostic systems often require responses in under 50 milliseconds. This budget includes data retrieval, vector search, and model inference. Similarly, banks and financial institutions often require very low latency for maximum user experience.
Public cloud deployments add unavoidable network latency. Even within the same region, round-trip latency typically adds 20 to 80 milliseconds before any compute work begins. For applications with tight latency targets, this overhead alone can exceed the total allowed response time. On-premises deployments remove that network hop, allowing systems to meet real-time requirements consistently.
Systems that must work offline
Many environments cannot rely on constant connectivity. Retail point-of-sale systems must continue operating during network outages. Manufacturing facilities are often located in remote areas with unstable connections. Military and maritime deployments may operate in fully disconnected or classified environments.
In these scenarios, a cloud dependency is a single point of failure. If the network goes down, the AI system stops working. On-premises and edge deployments allow vector search and inference to run locally, ensuring the system continues to function even when external connectivity is unavailable.
The cost of downtime
It is no news that there has been an increase in downtime from cloud providers. On November 18, 2025, Cloudflare outage disrupted large portions of the internet, causing downtime across major platforms, including X, Amazon Web Services, Spotify, and so on. The impact of connectivity failures is not theoretical. In manufacturing, average downtime costs are estimated at $260,000 per hour. When AI systems support quality control, predictive maintenance, or process automation, any outage directly affects production.
A cloud-only architecture introduces risk that is hard to justify in these environments. Even short network disruptions can lead to significant financial loss. On-premises deployments reduce this risk by removing external dependencies from critical execution paths.
For workloads with strict latency targets or limited connectivity, the choice is often clear. Cloud-based vector databases may work during development, but they fail to meet operational requirements in production.
The Operational Complexity Question
The strongest argument for cloud vector databases is operational simplicity. Managed services remove the need to provision hardware, manage clusters, apply patches, or handle failures. For small teams or early-stage projects, this advantage is real and often decisive. Cloud deployments allow engineers to focus on application logic rather than infrastructure.
It is also important to recognize that modern on-premises deployments look very different from those of a decade ago. This is not the world of manual server provisioning and fragile scripts. Kubernetes, infrastructure-as-code, and automated deployment pipelines have reduced operational overhead significantly. Rolling upgrades, automated scaling, and monitoring are now standard practices in on-premises environments as well as in the cloud.
Many enterprises adopt hybrid approaches to balance speed and control. Development and experimentation happen in the cloud, where teams can move quickly and iterate. Production systems run on-premises, where costs are predictable, and compliance is easier to enforce. This pattern allows teams to get the best of both models without committing fully to either.
Decision Framework: Eight Questions
The fastest way to make a defensible deployment decision is to walk through a small set of yes or no questions with engineering, legal, finance, and operations.
- Does your data require geographic restrictions?
Regulations such as GDPR, HIPAA, and financial services rules may limit where data can be stored or processed.
If yes, on-premises should be strongly considered because it provides full control over data location. If no, cloud deployment remains viable.
- Do you have predictable, high-volume query patterns?
Cloud vector database costs scale with usage. A simple check is monthly queries multiplied by the unit cost.
If usage exceeds roughly 80 to 100 million queries per month, on-premises is often cheaper. Below that range, cloud pricing is usually more economical.
- Do you need offline capability?
Some systems must continue working without network access, such as in manufacturing, retail, or edge environments.
If yes, on-premises is required. If no, cloud remains an option.
- Can you tolerate additional latency?
Cloud deployments add network latency, often 50 to 100 milliseconds.
If your application cannot tolerate this, on-premises deployment is necessary. If it can, cloud performance may be acceptable.
- Do you have existing infrastructure teams?
Operational capacity matters.
If you already run on-premises systems, the added burden is limited. If not, cloud-managed services provide a clear operational advantage.
- Is cost predictability important?
Usage-based billing introduces cost variability.
If predictable costs matter, on-premises provides stability. If flexibility matters more, cloud pricing may be a better fit.
- Are you extending the existing IT infrastructure?
Deployment context affects the decision.
If you are extending existing systems, on-premises leverages current investments. If you are building something new, cloud may be faster to deploy.
- How large is your data footprint?
Data volume and access frequency influence long-term cost.
If you manage more than 10 TB with frequent access, on-premises becomes attractive. If your data is smaller, cloud is often sufficient.
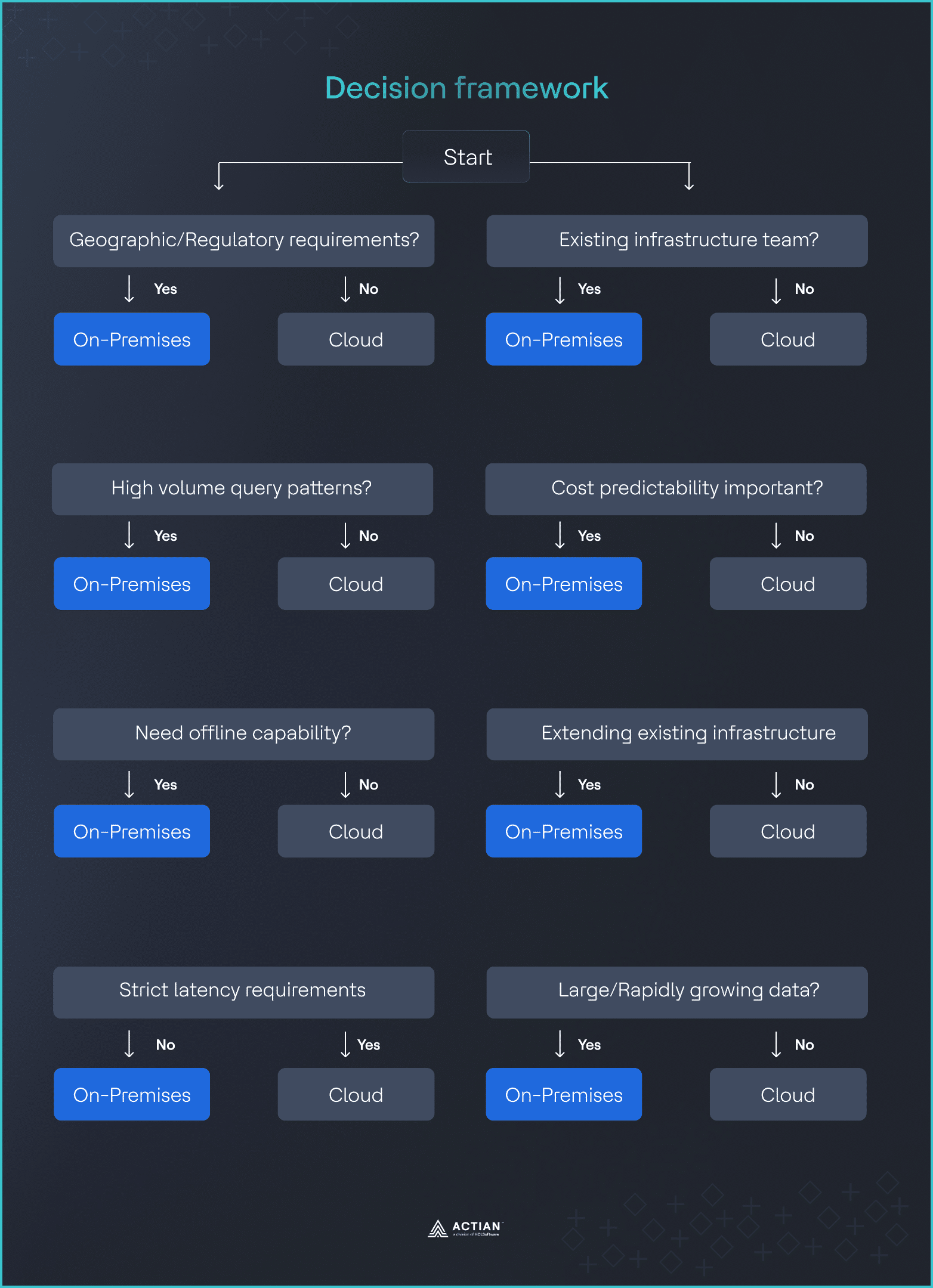
Image 6: Decision framework
When several answers point in the same direction, the decision becomes easy to explain and defend across engineering, legal, finance, and operations teams.
When Cloud Makes Sense
On-premises deployment is not always the right answer. In many situations, cloud-based vector databases remain the better choice. Being clear about these cases helps avoid over-engineering.
- Unpredictable scaling: Startups and new products often face uncertain growth. Cloud platforms allow rapid scaling without long-term infrastructure commitments, which reduces risk when demand is unclear.
- Small data volumes: When total data is under 10 TB and query volume stays below about 50 million queries per month, cloud pricing usually works well and is simpler than self-hosting.
- Rapid experimentation: Proofs-of-concept, research projects, and early prototypes benefit from fast setup and easy teardown. Cloud services support quick iteration with minimal operational effort.
- No compliance constraints: If data residency, sovereignty, and regulatory requirements are not an issue, cloud deployment avoids legal complexity and speeds up delivery.
- Limited infrastructure expertise: Teams focused on application logic rather than operations can rely on managed services instead of maintaining databases, clusters, and hardware.
In these cases, cloud is the most effective and practical option.
Hybrid Deployment Strategies
Hybrid deployments act as the middle ground for enterprises that need both speed and control. Rather than treating cloud and on-premises as mutually exclusive, teams place each part of the system where it performs best.
Cloud for iteration, on-prem for scale
A common pattern is to develop and test in the cloud, where managed services and elastic infrastructure enable rapid iteration. Once models, indexes, or pipelines are stable, they are promoted into on-premises production environments to meet compliance, latency, and operational requirements. This preserves developer velocity without compromising production guarantees.
Data segregation by risk and regulation
Hybrid architectures also allow organizations to separate workloads by risk profile. Sensitive or regulated data stays on-premises, while analytics, training, or search over derived data runs in the cloud. The same logic applies regionally: EU data may remain on-premises or in sovereign environments, while US workloads run in public cloud regions, avoiding global systems being constrained by the strictest jurisdiction.
Cost and migration flexibility
Cost optimization is another driver. Frequently accessed vectors or low-latency services can be cheaper and more predictable on-premises, while cold storage and bursty workloads benefit from cloud pricing. Many teams start cloud-first, then selectively move components on-premises as scale or compliance pressures grow. Hybrid makes this a controlled evolution rather than a disruptive rewrite.
Industry research shows this is a stable operating model. Google Distributed Cloud and similar platforms explicitly frame hybrid as a long-term strategy, recognizing that modern systems are designed to span environments, not collapse them into one.
Actian’s Approach To On-Premises Vector Databases
For teams that conclude that on-premises is the right deployment model, the next question is: which platform can actually meet these requirements? Actian’s approach is built specifically for this audience, without assuming the cloud is the default or the end state.
Actian delivers an enterprise-grade vector database that runs fully in your own data center or controlled environments. You retain full control over data placement, networking, and operations. There is no forced dependency on external cloud services, which simplifies audits and long-term system design.
Compliance requirements are treated as baseline constraints. By keeping data local and eliminating egress paths, Actian aligns with GDPR, HIPAA, FedRAMP, and similar regulatory frameworks. This reduces the need for compensating controls or complex legal workarounds.
Cost behavior is also predictable. Actian avoids usage-based pricing models that scale with queries or vector counts. This makes budgeting simpler and removes surprises as workloads grow.
Edge support is also taken into consideration. Actian’s architecture supports offline operation and local inference, making it suitable for manufacturing sites, retail locations, and other environments where connectivity is limited or unreliable. The system is designed to keep working even when the network does not.
Final Thoughts
Choosing between cloud and on-premises for vector databases is about understanding your priorities. Cloud works well for small workloads, rapid experimentation, and teams without deep infrastructure expertise. On-premises makes sense when compliance, latency, cost predictability, or scale are critical.
Many enterprises find a hybrid approach is the best balance, combining cloud flexibility with on-premises control. The key is making intentional decisions based on your data, workloads, and regulatory needs rather than following trends.
Actian empowers enterprises to confidently manage and govern data at scale. Organizations trust Actian data management and data intelligence solutions to streamline complex data environments and accelerate the delivery of AI-ready data. As the data and AI division of HCLSoftware, Actian helps enterprises manage and govern data at scale across on-premises, cloud, and hybrid environments. Learn more about Actian and how it fits into your on-premises AI strategy.