Actian Vector ingestion de données





Résumé
- Actian Vector utilizes a highly optimized execution engine that allows organizations to ingest massive, high-velocity datasets with minimal latency.
- The platform handles real-time data streaming and continuous bulk loading without locking tables or degrading active analytical query performance.
- Vector memory management structures stream updates directly into disk-based storage blocks to maximize transactional throughput and reliability.
- Integrating parallel loading streams into the database architecture enables teams to ingest and analyze multi-gigabyte data files simultaneously.
Action Vector 7.0 est rebaptisé Actian Analytics Engine à partir de la version 8.0
L'utilité d'une base de données analytique est étroitement liée à sa capacité à ingérer, stocker et traiter de vastes quantités de données. Les données proviennent généralement de multiples sources, telles que des bases de données opérationnelles, des fichiers CSV et des flux de données en continu. Dans la plupart des cas, les chargements quotidiens de données se chiffrent en dizaines ou en centaines de millions de lignes ; le mécanisme SQL INSERT traditionnel n'est donc pas adapté à de tels volumes de données.
In this blog post, we’ll look at Actian Vector, our columnar database ideally suited for analytic applications, and evaluate a variety of CSV data ingestion options that operate at the required data rates. In future posts, we’ll examine Actian VectorH executing in a Hadoop environment and ingestion from streaming data sources.
Le but de cet exercice n'est pas de comparer ingestion de données , mais d'évaluer la vitesse relative de différentes méthodes dans un même environnement matériel. Nous évaluerons la commande SQL INSERT comme référence, ainsi que la commande SQL COPY TABLE, l'outil vwload en ligne de commande etworkflow Pentaho Data Integration (alias Kettle), Talend Open Studio for Data Integration et Apache NiFi. Talend et Pentaho sont des outils ETL traditionnels qui ont évolué pour inclure divers chargeurs en masse et d’autres outils et technologies dits « big data » ; tous deux sont basés sur l’interface utilisateur Eclipse. NiFi a été open-sourcé à la Fondation Apache par l’Agence nationale de sécurité américaine (NSA) et constitue un outil polyvalent permettant d’automatiser le flux de données entre les systèmes logiciels ; il utilise une utilisateur web.
Ces trois solutions mettent en œuvre un concept de graphe orienté, dans lequel les données circulent d'un opérateur à l'autre, les opérateurs s'exécutant en parallèle. Pentaho et Talend proposent des éditions communautaires et des éditions sur abonnement, tandis que NiFi est une solution open source développée par Apache.
Le serveur Vector est équipé d'un processeur AMD Opteron 6234 à six cœurs de classe bureau, de 64 Go de mémoire et de disques durs SATA (coût du matériel : environ 2 500 $) ; il exécute la version 5.0 de Vector sur un seul nœud.
À titre de référence, nous allons insérer environ 24 millions d'enregistrements dans la table « lineitem » du benchmark TPCH. La structure de cette table est la suivante :
l_orderkey bigint NOT NULL, l_partkey INT NOT NULL, l_suppkey INT NOT NULL, l_linenumber INT NOT NULL, l_quantity NUMERIC(19,2) NOT NULL, l_extendedprice NUMERIC(19,2) NOT NULL, l_discount NUMERIC(19,2) NOT NULL, l_tax NUMERIC(19,2) NOT NULL, l_returnflag CHAR(1) NOT NULL, l_linestatus CHAR(1) NOT NULL, l_shipdate DATE NOT NULL, l_commitdate DATE NOT NULL, l_receiptdate DATE NOT NULL, l_shipinstruct CHAR(25) NOT NULL, l_shipmode CHAR(10) NOT NULL, l_comment VARCHAR(44) NOT NULL
SQL INSERT
Vector étant conforme à la norme ANSI SQL, le mécanisme d'insertion le plus évident est sans doute la instruction SQL INSERT standard. Il s'agit généralement de l'option la moins performante, car elle donne lieu à des opérations d'insertion individuelles. Les insertions peuvent être optimisées dans une certaine mesure en recourant à la paramétrisation et en insérant les enregistrements par lots, mais même cela peut ne pas suffire à atteindre le niveau de performance requis.
Pour le test SQL INSERT, nous allons créer un workflow Pentaho simple workflow deux étapes : l'une pour lire le fichier de données CSV et l'autre pour insérer ces lignes dans une base de données Vector. Nous exécuterons également ce workflow le même nœud que l'instance Vector, ainsi que workflow un nœud distant, afin d'évaluer l'impact de la charge réseau.

Dans ce contexte, le chargement à partir d'un nœud distant offre des performances légèrement supérieures à celles du chargement à partir du nœud local ; les performances s'améliorent généralement à mesure que la taille des lots augmente, jusqu'à environ 100 000 enregistrements, puis stagnent. Cela ne signifie pas pour autant que 100 000 enregistrements constituent toujours la taille de lot optimale ; celle-ci varie très probablement en fonction de la taille des lignes.
Vector COPY TABLE
La construction Vector COPY TABLE sert à charger en masse des données depuis un fichier CSV vers la base de données. Si elle est exécutée à partir d'un nœud distant, cette approche nécessite l'installation du Vector Client Runtime, à savoir Ingres Net et le moniteur de terminal Ingres SQL. Le Client Runtime est disponible gratuitement et ne nécessite aucune licence. Pentaho et Talend prennent tous deux support construction, bien que leur implémentation diffère légèrement. Pentaho utilise des canaux nommés pour acheminer les données vers l'opérateur, tandis que Talend crée un fichier intermédiaire sur le disque, puis appelle l'opérateur.
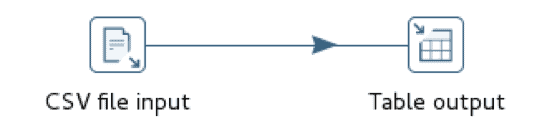
L'implémentation Talend utilise deux opérateurs : tFileInputDelimited, un lecteur de fichiers délimités, et tIngresOutputBulkExec, un chargeur COPY TABLE pour Ingres/Vector

Le chargeur est configuré avec les informations de connexion à la base de données, la table cible et le fichier intermédiaire.
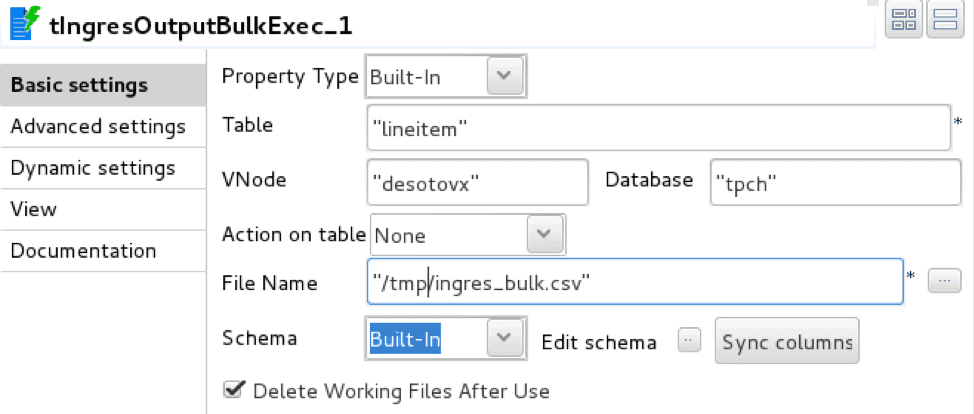
La mise en œuvre de Pentaho utilise deux opérateurs équivalents : l'importation de fichiers CSV (lecteur de fichiers délimités) et le chargeur en masse Ingres VectorWise (chargeur de tables de base de données).

Le chargeur est configuré avec une connexion Vector et une table cible. Contrairement à Talend, le chargeur Pentaho n'utilise pas de fichier intermédiaire.

Les performances des deux outils sont pratiquement identiques, mais environ six fois supérieures à celles d'une instruction SQL INSERT. Apache NiFi ne prend pas support nativement support Vector COPY TABLE, support simuler cette approche en lançant le moniteur de terminal séparément puis en établissant une connexion via des canaux nommés s'avère relativement fastidieux.
Vector vwload
L'utilitaire vwload fourni par Vector est un de haute performance à la fois avec Actian Vector et VectorH. Il s'agit d'un utilitaire en ligne de commande conçu pour charger un ou plusieurs fichiers dans une table Vector ou VectorH à partir du système de fichiers local ou de HDFS. Nous aborderons la variante HDFS dans un prochain article.
Vwload peut être exécuté de manière autonome ou servir de mécanisme de chargement des données pour les workflow générés par Pentaho, Talend ou NiFi. Pentaho intègre support de vwload, support Talend et NiFi proposent un mécanisme permettant de diriger les flux workflow vers vwload sans les enregistrer au préalable sur le disque.
L'implémentation Talend utilise le composant tFileInputDelimited pour lire le fichier CSV source et le composant tFileOutputDelimited pour écrire les lignes du fichier source dans un canal nommé. Pour charger le flux de données dans Vector, il faut exécuter vwload en utilisant le même canal nommé que celui du fichier source.
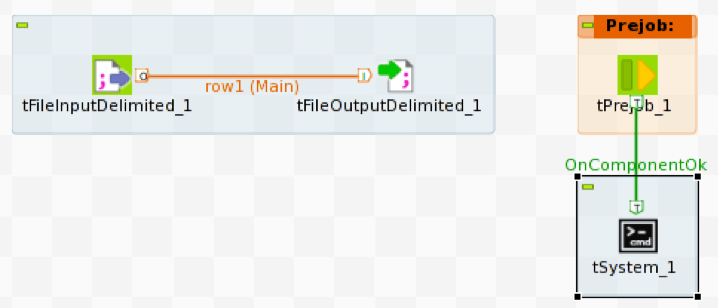
Pour lancer vwload, nous utilisons l'opérateur Prejob afin de déclencher l'opérateur tSystem. tSystem est le mécanisme permettant d'exécuter des commandes au niveau du système d'exploitation ou des scripts shell. L'opérateur Prejob est déclenché automatiquement au démarrage du job, avant tout autre workflow , et est configuré pour déclencher l'opérateur tSystem.
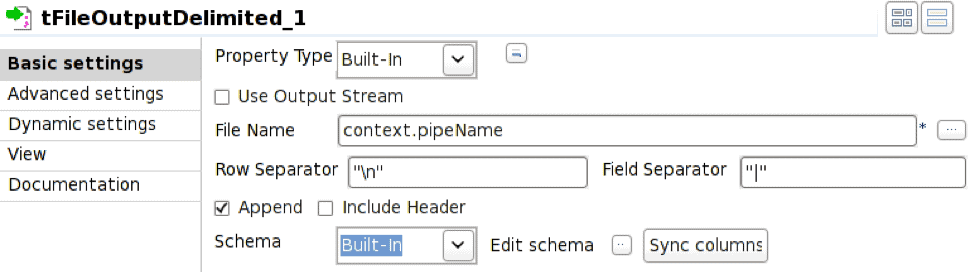
L'opérateur tFileOutputDelimited est configuré pour écrire dans le canal nommé défini par la variable d'environnement context.pipeName. Ce canal nommé doit exister au moment de l'exécution du travail et l'option Append doit être cochée.
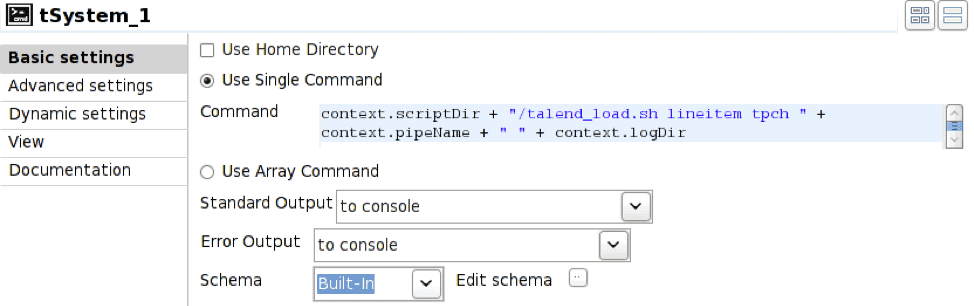
Dans ce cas, l'opérateur tSystem exécute le script shell talend_load.sh en lui transmettant les paramètres relatifs au nom de la table, au nom de la base de données, au nom du canal et au répertoire du fichier journal résultant. La notation « context. » permet de faire référence aux variables d'environnement associées au job ; cela permet de paramétrer les jobs. Le script shell est le suivant :
#!/bin/bash nohup vwload -m -t $1 $2 $3 > $4/log_`date +%Y%m%d_%H%M%S`.log 2>&1 &
La séquence d'exécution obtenue est la suivante :
- Exécuter l'opérateur de pré-traitement
- Déclencheurs pré-tâche de l'opérateur tSystem
- L'opérateur du système exécute un script shell
- Le script Shell lance vwload en arrière-plan puis se termine ; vwload lit désormais les données provenant du canal nommé en attendant l'arrivée des lignes
- Lancez tFileInputDelimited pour lire les lignes du fichier source
- Lancez tFileOutputDelimited pour recevoir les lignes entrantes et les écrire dans un canal nommé
La mise en œuvre de Pentaho utilise les opérateurs d'importation de fichiers CSV et Ingres VectorWise Loader, comme dans le cas de COPY TABLE, mais le chargeur en masse est configuré pour utiliser vwload à la place.
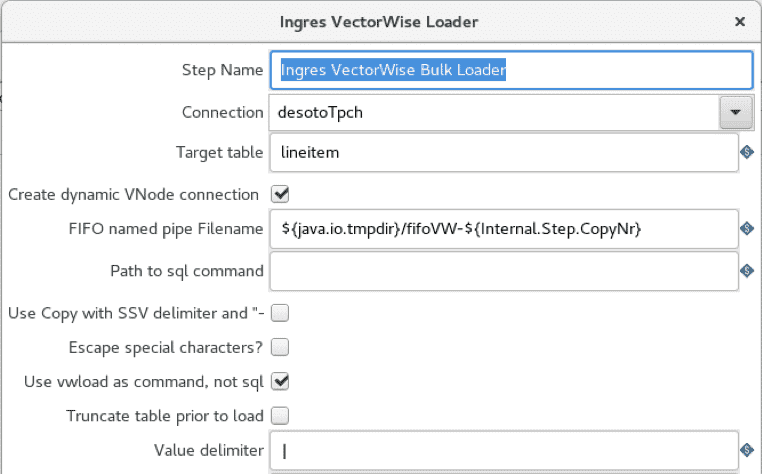
L'option « use vwload » est sélectionnée et le champ « Path to sql command » est vide. C'est ainsi que l'on lance l'utilitaire vwload.
L'implémentation Apache NiFi utilise trois opérateurs : GetFile, qui est un écouteur de répertoire, FetchFile, qui lit le fichier proprement dit, et ExecuteStreamCommand, qui transmet les streaming du fichier au processus vwload s'exécutant en arrière-plan.
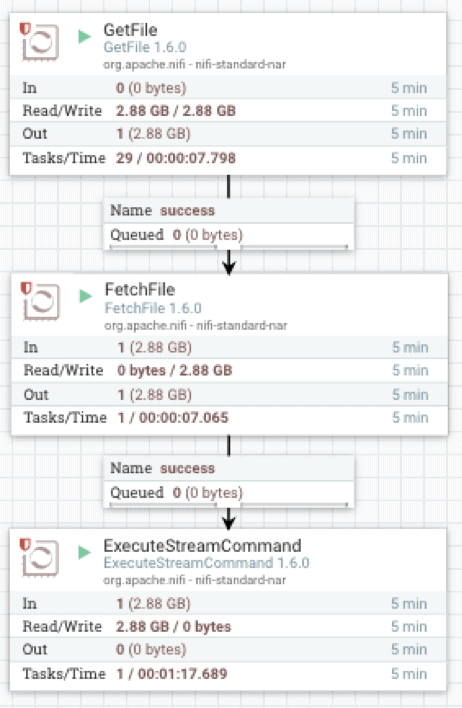
FetchFile transmet le flux de données source à ExecuteStreamCommand, qui est configuré pour exécuter un script shell.
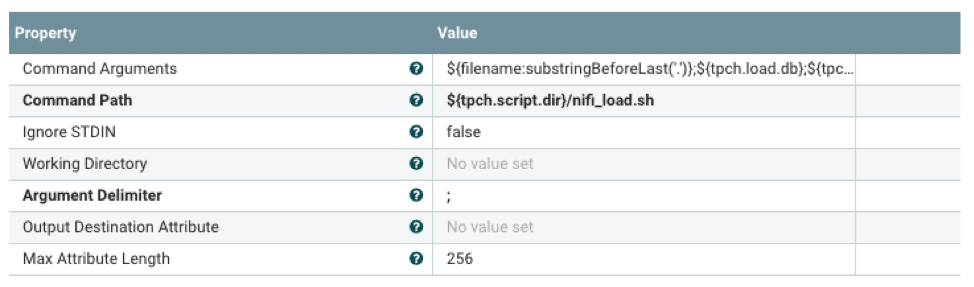
Le script shell lancera vwload en arrière-plan et acheminera le flux de données vers vwload via un canal nommé. La notation ${} permet de faire référence aux propriétés configurées dans un fichier de propriétés externe. Cela permet de configurer le processeur de flux lors de l'exécution.
#!/bin/bash tableName=$1 dbName=$2 loadPipe=$3 logDir=$4 echo "`date +%Y-%m-%d\ %H:%M:%S` vwload -m -t $tableName db $dbName $loadPipe " >> $logDir/load.log vwload -uactian -m -t $tableName $dbName $loadPipe >> $logDir/load.log 2>&1 & cat /dev/stdin >>$loadPipe
La commande vwload est utilisée comme mécanisme de chargement dans les workflows Pentaho, Talend et NiFi mentionnés précédemment. À titre de comparaison, nous chargeons également le même jeu de données vwload en mode autonome sur la machine Vector locale, ainsi à partir du client distant via Ingres Net.

Les durées d'exécution et les vitesses d'ingestion varient considérablement en fonction du matériel utilisé et de la taille des lignes.
En résumé, ingestion de données , par ordre croissant de performances, sont SQL INSERT, SQL COPY TABLE et vwload. Pour des volumes de données importants, vwload, associé à l'outil ETL approprié, constitue généralement le choix le plus judicieux. Le choix de l'outil ETL dépend généralement des performances et des fonctionnalités. Il faut au minimum disposer d'un mécanisme permettant de s'interfacer avec la méthode d'ingestion choisie. Les exigences fonctionnelles dépendent principalement de la quantité et du type de transformations à effectuer sur le flux de données entrant. Même si les données entrantes doivent être chargées telles quelles, un outil ETL peut tout de même s'avérer utile pour la détection des fichiers entrants, la planification des tâches et le signalement des erreurs.
Les workflows ci-dessus correspondent au cas le plus simple d'ingestion de fichiers CSV : il s'agit généralement de lire un fichier de données source et de le charger dans Vector. À ce titre, ils représentent également les performances optimales pour chacune des méthodes d'ingestion. La plupart des cas d'utilisation réels impliqueront une certaine logique de transformation dans le workflow, les débits de données diminuant en fonction de la complexité de cette transformation. La mesure des débits workflow nous permet de sélectionner la méthode d'ingestion qui répond à ces exigences.
En savoir plus sur Actian Vector
Pour en savoir plus sur Actian Vector, consultez les ressources suivantes :
Pour en savoir plus sur nos éditions communautaires d'Actian Vector, rendez-vous sur :
Restez connecté
Des informations tirées des données, à votre service.
(par exemple : sales@..., support)