Quand choisir une base de données vectorielle sur site dans le cloud ?




Résumé
- Le renforcement des lois sur la résidence des données et l'application du RGPD poussent les entreprises à reconsidérer leur infrastructure d'IA sur site.
- Les charges de travail Edge AI exigent une capacité hors ligne et une latence inférieure à 100 ms que les déploiements cloud ne peuvent pas toujours offrir.
- À grande échelle, les coûts liés à l'utilisation d'une base de données vectorielle dans le cloud peuvent dépasser le coût total de possession prévisible d'une solution sur site.
- Les stratégies hybrides concilient l'agilité du cloud pour le développement et le contrôle sur site pour la conformité et la production.
Pendant la majeure partie de la dernière décennie, le débat sur site cloud semblait clos. informatique dans le cloud moins coûteuse, plus rapide et plus facile à adopter. Les entreprises ont transféré leurs charges de travail de sur site vers des services cloud publics, s'appuyant sur les principaux fournisseurs de cloud pour gérer évolutivité, la maintenance et la sécurité.
En 2026, cette hypothèse est remise en cause, et des failles apparaissent dans les examens juridiques, les projets financiers et SLA . Les entreprises sont confrontées à une pression croissante en matière de réglementations en matière de résidence des données, d'une application plus stricte et d'un examen minutieux des modèles de sécurité du cloud. Les contraintes de conformité, les exigences en matière de sécurité des données, la prévisibilité des coûts et la latence obligent les équipes à reconsidérer sur site , informatique dans le cloud privée informatique dans le cloud et l'infrastructure cloud hybride.
Dans le même temps, l'IA se rapproche de l'endroit où les données sont générées. Les sites de fabrication, les magasins de détail et les environnements de soins de santé ont de plus en plus besoin de capacités hors ligne et d'une latence inférieure à 100 ms. Cette évolution explique pourquoi Oracle a lancé la base de données IA 26ai pourdéploiement sur site déploiement pourquoi Google pousse Gemini sur Distributed Cloud pour les environnements isolés. Ce changement indique que l'IA à grande échelle pour les entreprises ne s'intègre plus parfaitement dans les environnements cloud.
Dans cet article, nous examinerons pourquoi sur site connaît un regain d'intérêt, quels sont les compromis à connaître et comment prendre déploiement justifiées.
Qu'est-ce qui motive la sur site du sur site ?
Le regain d'intérêt pour sur site ne signifie pas un retour aux anciens systèmes. Il s'agit plutôt d'une réponse aux changements évidents dans la manière dont les systèmes d'IA sont construits et utilisés en 2025 et 2026. Pour de nombreuses entreprises, les bases de données vectorielles exclusivement basées sur le cloud ne répondent plus à leurs besoins en matière de conformité, de coût et de fiabilité.
De nombreux facteurs expliquent cette sur site actuelle sur site , mais dans cet article, nous nous intéresserons à quatre causes principales.
Les grands fournisseurs support désormais support sur site .
sur site n'est plus considérée comme un cas particulier par les principaux fournisseurs. La sortie de la base de données IA 26ai par Oracle et la décision de Google d'exécuter Gemini sur Distributed Cloud montrent un changement clair dans la manière dont l'IA d'entreprise est conçue et fournie.
Ces produits sont conçus pour les grandes entreprises, et non pour des expériences ou des projets de recherche à un stade précoce. Cette distinction est importante. Les grands fournisseurs n'investissent pas dans plateformes sur site complexes, plateformes en cas de demande forte et croissante de la part des clients. Ces annonces confirment que de nombreuses entreprises souhaitent exploiter des systèmes d'IA au sein de leurs propres environnements, à proximité de leurs données et sous leur contrôle opérationnel total. Pourquoi ?
La pression réglementaire est désormais un véritable obstacle
Les équipes avaient l'habitude de planifier les risques réglementaires comme une possibilité future. Aujourd'hui, c'est une réalité quotidienne. L'application du RGPD a atteint enregistrement en 2025, les sanctions les plus lourdes étant infligées pour insuffisance de la base juridique du traitement des données. Cette année-là, les autorités de régulation ont infligé près de 2 700 amendes pour un montant total de plusieurs milliards d'euros.
Du point de vue de la sécurité des données, l'application du RGPD a fondamentalement changé la manière dont les entreprises évaluent les services cloud. Bien que les fournisseurs de services cloud proposent des outils de conformité, les équipes juridiques se montrent de plus en plus réticentes à confier le stockage et le traitement de données sensibles à des fournisseurs tiers.
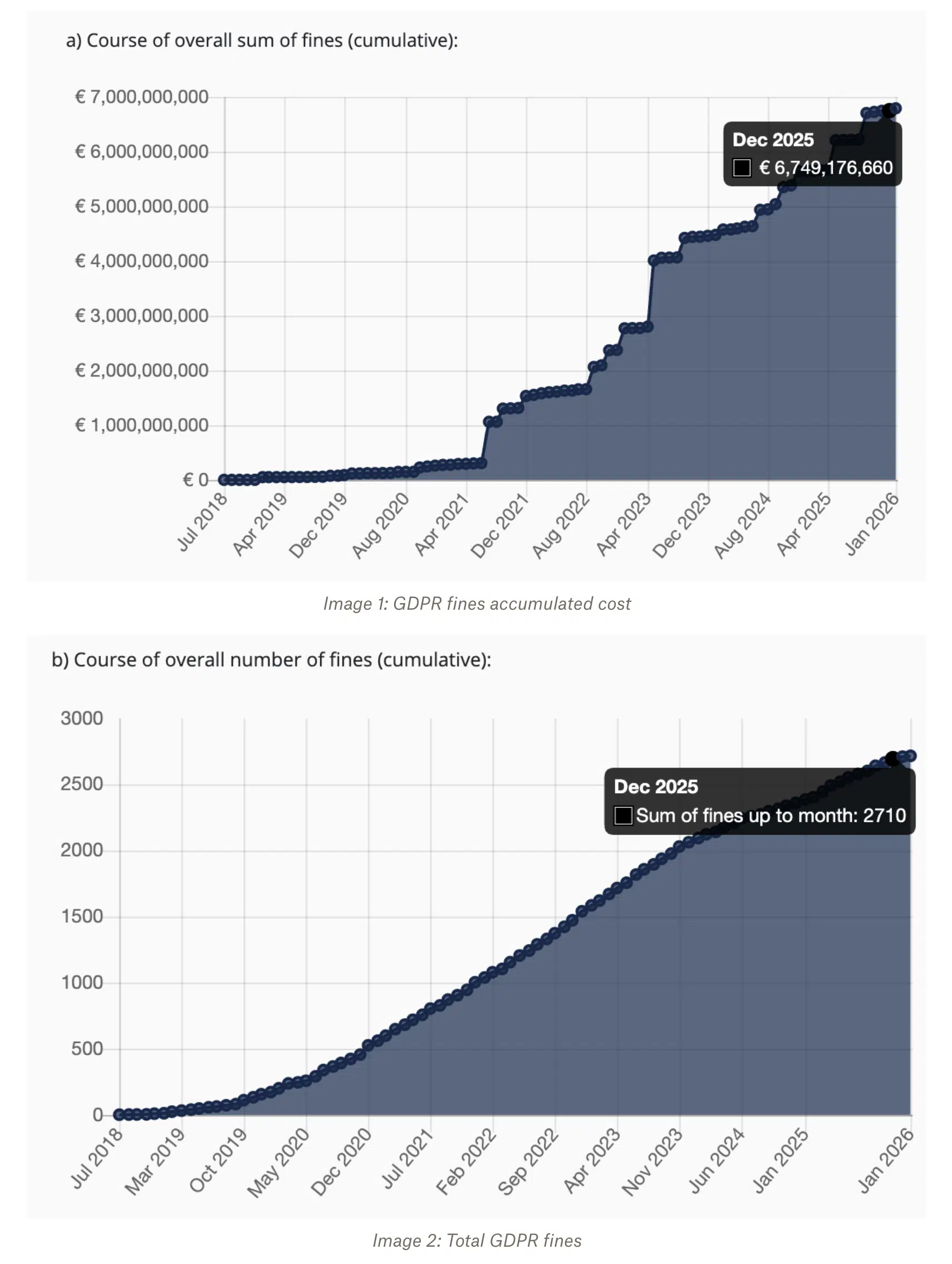
La loi HIPAA ajoute une couche supplémentaire de complexité. Par exemple, en Floride, les médecins doivent conserver les dossiers médicaux pendant cinq ans après le dernier contact avec le patient, tandis que les hôpitaux doivent les conserver pendant sept ans en vertu des exigences enregistrement de conservation de l'État. Cela rend les transferts de données répétés risqués et coûteux. Les services financiers et les prestataires du secteur public sont soumis à des exigences similaires en matière de souveraineté des données, qui limitent les lieux où les données peuvent être stockées et traitées. Dans ces situations, les déploiements dans le cloud ajoutent des contraintes en matière d'examen juridique, d'audit et de risque permanent. Conserver les données sur site souvent le moyen le plus simple de respecter ces obligations.
L'IA en périphérie nécessite un fonctionnement local et hors ligne.
Les charges de travail liées à l'IA sont de plus en plus souvent déployées à proximité du lieu où les données sont créées. Les sites de production peuvent fonctionner dans des environnements isolés ou des sites distants avec une connectivité limitée. Les systèmes de vente au détail doivent continuer à fonctionner pendant les pannes de réseau. Les applications de santé nécessitent souvent une latence très faible pour support la décision en temps réel.
Dans ces environnements, le recours à un service cloud distant comporte des risques. Les retards et les pannes réseau affectent directement la fiabilité du système. Les déploiements sur site en périphérie permettent d'exécuter localement la recherche vectorielle et l'inférence, sans dépendre d'un accès réseau constant. Dans de nombreux cas d'utilisation, cette exécution locale n'est pas une optimisation, mais une exigence.
Ensemble, ces changements expliquent pourquoi les bases de données sur site regagnent en popularité. Ce changement est motivé par les réalités pratiques du déploiement de systèmes d'IA de production soumis à des contraintes réglementaires, financières et de fiabilité réelles.
Le calcul de conformité
Pour de nombreuses entreprises, la conformité est le facteur décisif dans le débat sur site cloud. Bien que les fournisseurs de cloud proposent des certifications de conformité, le véritable défi n'est pas de savoir si une plateforme peut être conforme en théorie, mais si elle peut résister à un examen juridique, à des audits et à un contrôle opérationnel à long terme dans la pratique. Une fois que les bases de données vectorielles sont mises en production et commencent à stocker des données sensibles ou réglementées, ces questions deviennent inévitables.
Le RGPD et les limites des transferts transfrontaliers
La arrêt Schrems II a modifié la manière dont les données européennes peuvent être traitées en dehors de l'UE. Le bouclier de protection des données a été invalidé, laissant les clauses contractuelles types comme principal mécanisme juridique pour les transferts transfrontaliers de données. Dans les secteurs hautement réglementés tels que les services financiers et les soins de santé, de nombreuses équipes juridiques considèrent que les CCT sont insuffisantes en raison de l'incertitude quant à leur application et des contestations juridiques en cours.
Pour les bases de données vectorielles, cela est important car les intégrations contiennent souvent des données personnelles dérivées. Même si les enregistrements bruts sont masqués ou tokenisés, les intégrations peuvent toujours être considérées comme des données personnelles au sens du RGPD. Si les données doivent rester dans l'EEE ou dans un pays spécifique, les déploiements cloud qui s'appuient sur une infrastructure mondiale présentent un risque juridique. Dans ces cas, déploiement sur site dans la région déploiement une exigence plutôt qu'une préférence.
Conservation des données conformément à la loi HIPAA et coût réel du transfert de données
La loi HIPAA n'exige pas explicitement que les données restent sur site, mais elle impose des périodes de conservation longues et des contrôles d'accès stricts. Lorsque des encodages vectoriels sont créés à partir de ces données, ils héritent des mêmes exigences en matière de conservation. gouvernance des données HIPAA doit être appliquée lors de l'examen des bases de données vectorielles sur site dans le cloud.
L'impact sur les coûts devient évident lorsque les frais de sortie sont pris en compte. Prenons l'exemple d'un système stockant 100 To d'intégrations dans un environnement cloud. À un tarif de sortie courant de 0,09 $ par Go, le transfert de ces données hors du cloud sur une période de conservation de sept ans entraîne :
100 To × 0,09 $ par Go × 84 mois = plus de 750 000 $ rien qu'en coûts de sortie
Cela n'inclut pas les coûts liés au calcul, au stockage ou à l'indexation. Dans cette optique, les les entrepôts de données dans le cloud vraiment vous aider à réduire vos coûts ?
Services financiers et règles relatives à la souveraineté des données
Les institutions financières sont confrontées à des contraintes supplémentaires au-delà du RGPD. Des réglementations telles que GLBA, APRAet les mandats régionaux en matière de souveraineté des données exigent souvent un contrôle strict de l'endroit où les données des clients sont stockées et traitées. Les régulateurs peuvent exiger des preuves claires des limites géographiques, des contrôles d'accès et de l'auditabilité.
Les services cloud peuvent répondre à certaines de ces exigences, mais ils impliquent souvent des configurations complexes, des dépendances contractuelles et des contrôles de conformité continus. Pour de nombreuses banques et compagnies d'assurance,déploiement sur site déploiement les audits en conservant les données au sein d'une infrastructure contrôlée que les régulateurs connaissent déjà.
Contraintes imposées par le gouvernement et le secteur public
Les contrats gouvernementaux imposent certaines des exigences les plus strictes en matière d'infrastructure. Des normes telles que FedRAMP imposent souvent des infrastructures exclusivement américaines, un accès restreint et des environnements étroitement contrôlés.
Dans ces cas, les services de cloud public sont souvent interdits ou nécessitent des autorisations complexes.déploiement sur site déploiement souvent la seule option viable pour exécuter des bases de données vectorielles à support charges de travail gouvernementales.
Quand la conformité rend le cloud intenable
Si les équipes juridiques jugent les transferts transfrontaliers de données inacceptables, les déploiements dans le cloud deviennent rapidement impraticables. Une fois que la résidence des données est obligatoire,déploiement sur site déploiement plus une décision de compromis. Il s'agit d'une exigence de conformité.
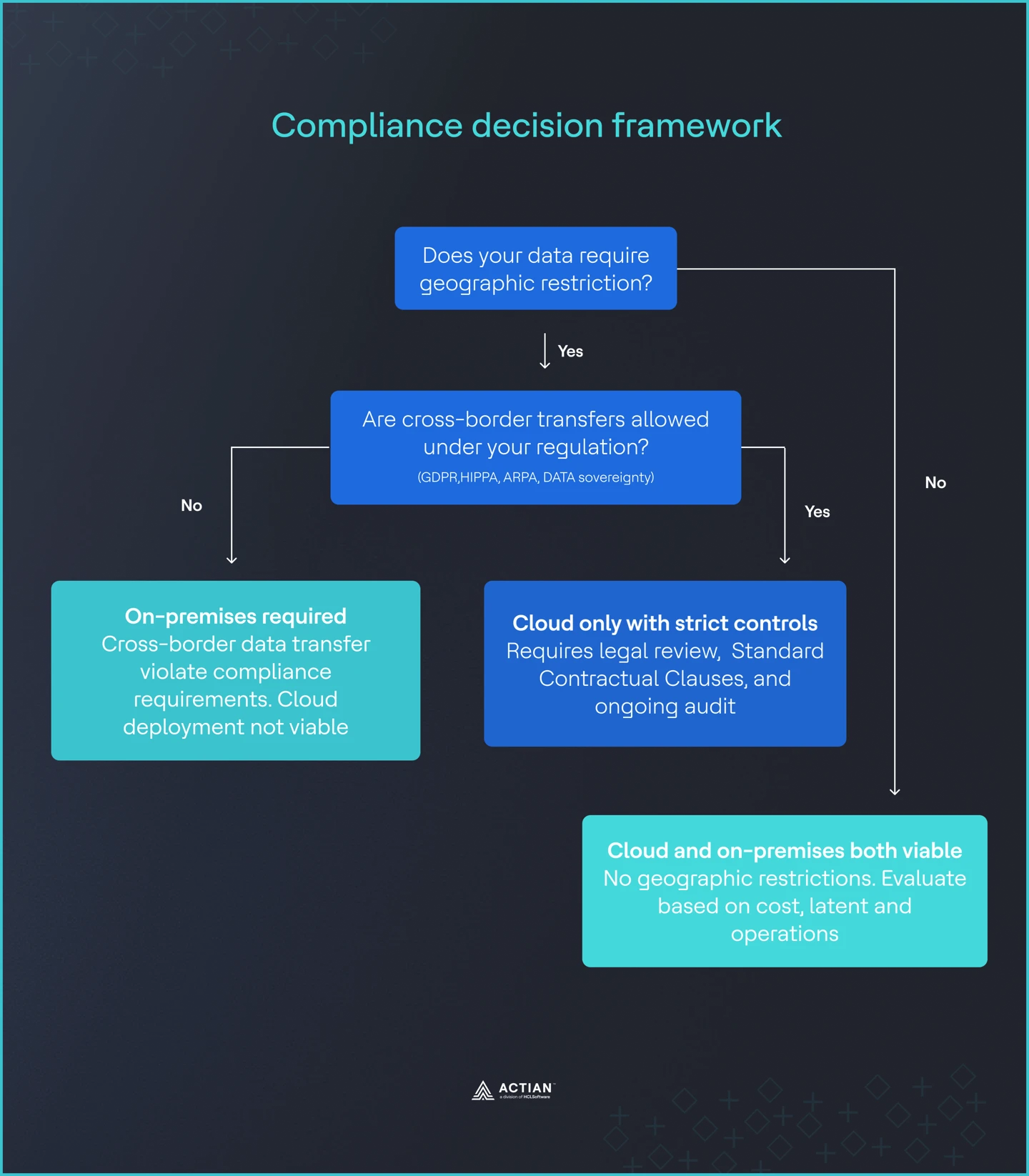
Image 3 : Cadre de conformité
Analyse détaillée des coûts
Le coût est souvent la raison pour laquelle les équipes réexaminent leur décision sur site cloud. Pour prendre une décision défendable, les équipes doivent comprendre où les coûts divergent et quand l'auto-hébergement devient économiquement rationnel.
Quand l'auto-hébergement atteint le seuil de rentabilité
Les recherches menées par OpenMetal montrent un seuil de rentabilité constant pour les bases de données vectorielles Pinecone à grande échelle. Lorsque la charge de travail atteint environ 80 à 100 millions de requêtes par mois, les déploiements auto-hébergés ont tendance à être moins coûteux que les services cloud gérés. En dessous de cette fourchette, les tarifs cloud sont généralement compétitifs. Au-delà, la facturation à l'utilisation commence à dominer le coût total.
Ce seuil est important car de nombreux systèmes RAG d'entreprise le dépassent rapidement. support à la clientèle, de recherche de documents, détection des fraudes et les systèmes de recommandation traitent souvent des dizaines ou des centaines de millions de requêtes chaque mois une fois déployés dans les unités commerciales ou les régions.
Le coût caché des tarifs du cloud
La tarification du cloud se résume rarement à un simplerequête . Les bases de données vectorielles introduisent plusieurs facteurs de coût qui sont faciles à négliger lors de la planification.
Les frais de sortie constituent un facteur important. La plupart des fournisseurs de services cloud facturent environ 0,09 $ par Go pour les données qui quittent leur réseau. Le transfert d'intégrations entre régions, l'exportation de données à des fins d'analyse ou la migration vers un autre système entraînent tous ces frais. Au fil du temps, ils représentent une part importante des dépenses totales.
Enfin, la recherche vectorielle n'évolue pas de manière linéaire. À mesure que le nombre de vecteurs augmente et que la dimensionnalité s'accroît, requête augmentent plus rapidement que prévu. Ce qui semble abordable à 10 millions de vecteurs peut devenir coûteux à 500 millions, même si requête augmente de manière régulière.
sur site sont fixes et prévisibles.
sur site ont des coûts réels, mais ils se comportent différemment. Le matériel est généralement amorti sur trois à cinq ans. Les besoins en personnel sont stables une fois que le système est opérationnel. Les coûts liés aux installations et à l'électricité sont connus à l'avance.
La principale différence réside dans la prévisibilité. Les coûts n'augmentent pas en raison des habitudes d'utilisation ou des mouvements de données. Une fois que le système est correctement dimensionné, les dépenses mensuelles restent largement stables, même lorsque requête augmente.
Un exemple concret
Considérons une application de commerce électronique de production présentant les caractéristiques suivantes :
- 500 millions de vecteurs.
- 200 millions de requêtes chaque mois.
- Dimensions vectorielles 1024.
- 6M écrit tous les mois.
À cette échelle, une base de données vectorielle Pinecone gérée classique coûte environ 8 500 dollars par mois, une fois pris en compte les frais généraux liés au calcul, au stockage et à la reconstruction.
Coût mensuel estimé
Coût total estimé : 8 454 $ / mois
- Stockage
- Utilisation : 845 Go
- Coût : 279 $
- requête
- Configuration :
- 24 nœuds b1
- 4 fragments × 6 répliques
- Hypothèse : Sélectivité du filtre de 1 %.
- Coût estimé : 8 074 $
- Remarque : requête réel requête peut varier. Évaluez votre charge de travail DRN pour obtenir des estimations plus précises.
- Coûts de rédaction
- Volume d'écriture : 30 millions d'unités d'écriture (WU)
- Hypothèse : Chaque demande d'écriture consomme ≥ 5 WU
- Coût : 101 $
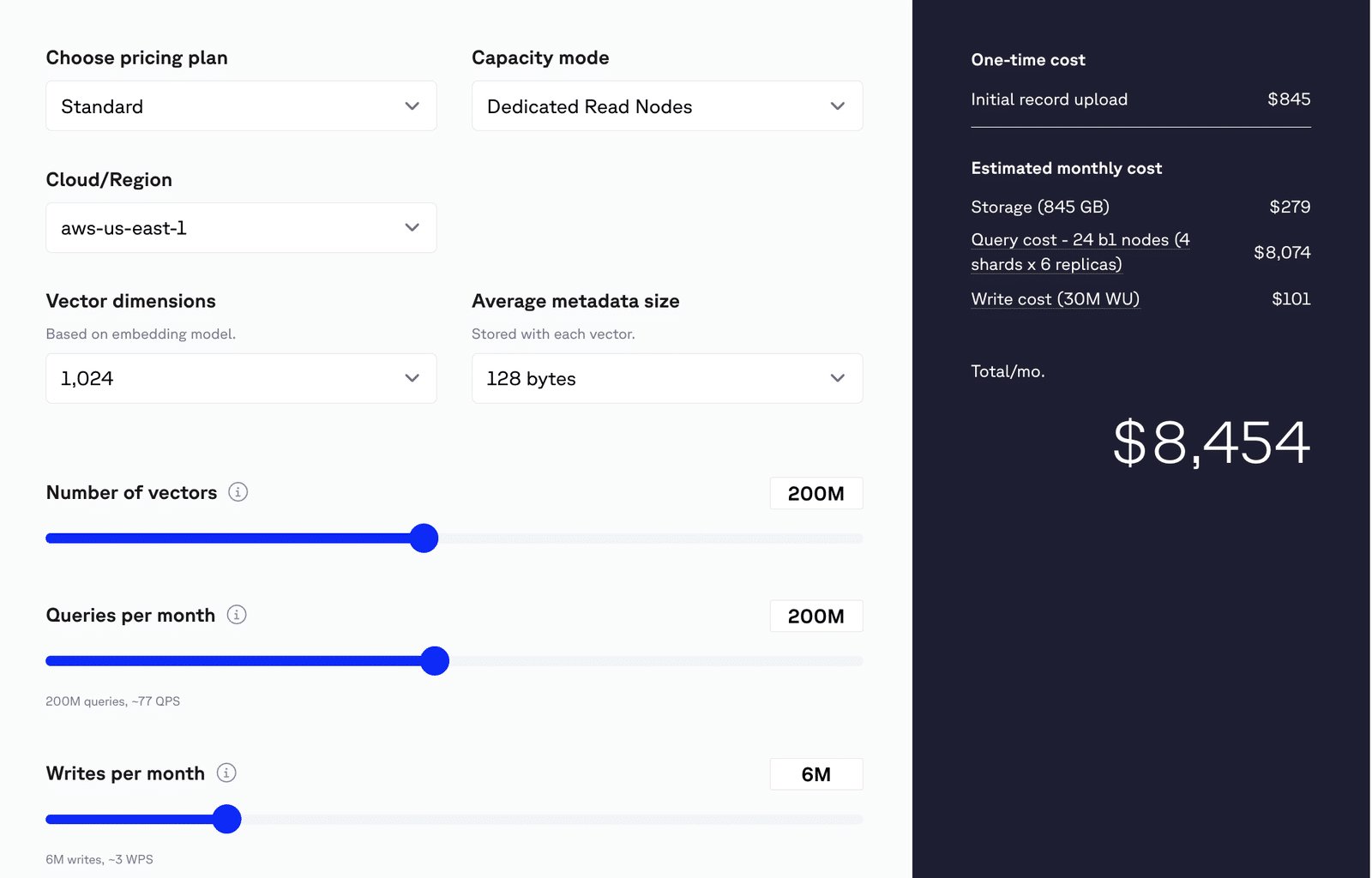
Image 4 : Estimation du coût d'une pomme de pin
déploiement sur site équivalentdéploiement coûter environ la moitié de ce montant après amortissement du matériel, en supposant une période de récupération de 18 mois et un à deux ingénieurs chargés de la maintenance du système. Après cette période de récupération, les coûts diminuent encore davantage tandis que la capacité reste disponible.
Une étude réalisée par Enterprise Storage Forum montre les projections de coûts des charges de travail sur site dans le cloud.
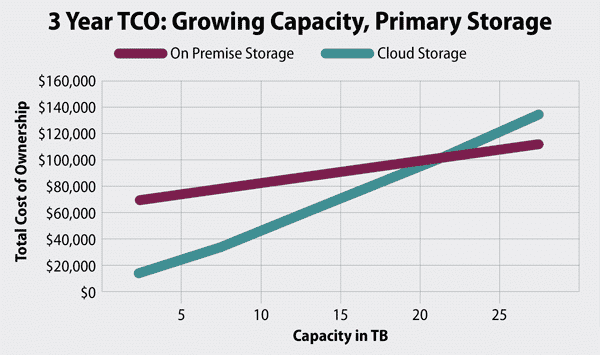
Image 5 : Forum sur le stockage d'entreprise TCO
Le coût à lui seul ne détermine pas chaque déploiement, mais une fois que les charges de travail vectorielles atteignent une certaine ampleur, les aspects économiques deviennent difficiles à ignorer. Il est essentiel de comprendre où se situe votre système sur cette courbe avant de vous engager dans une stratégie à long terme en matière de bases de données vectorielles.
Quand la latence et la connectivité comptent
La latence et la connectivité sont souvent considérées comme des préoccupations secondaires dans les décisions architecturales. Pour de nombreuses charges de travail liées à l'IA, elles sont pourtant déterminantes. Une fois que les bases de données vectorielles support les systèmes support , les allers-retours réseau et la dépendance à Internet peuvent rendre les déploiements dans le cloud impraticables ou dangereux.
Exigences en matière de réponse en temps réel
Certaines applications ont des délais de réponse très stricts. Dans le domaine de la santé, les systèmes support la décision clinique support de diagnostic exigent souvent des réponses en moins de 50 millisecondes. Ce budget comprend récupération des données, la recherche vectorielle et l'inférence de modèles. De même, les banques et les institutions financières exigent souvent une latence très faible pour utilisateur optimale.
Les déploiements dans le cloud public ajoutent une latence réseau inévitable. Même au sein d'une même région, la latence aller-retour ajoute généralement 20 à 80 millisecondes avant le début de tout travail de calcul. Pour les applications avec des objectifs de latence stricts, cette surcharge peut à elle seule dépasser le temps de réponse total autorisé. sur site suppriment ce saut réseau, permettant aux systèmes de répondre de manière cohérente aux exigences en temps réel.
Systèmes devant fonctionner hors ligne
De nombreux environnements ne peuvent pas compter sur une connectivité constante. Les systèmes de point de vente au détail doivent continuer à fonctionner pendant les pannes de réseau. Les installations de fabrication sont souvent situées dans des zones éloignées où les connexions sont instables. Les déploiements militaires et maritimes peuvent opérer dans des environnements totalement déconnectés ou classifiés.
Dans ces scénarios, la dépendance au cloud constitue un point de défaillance unique. Si le réseau tombe en panne, le système d'IA cesse de fonctionner. Les déploiements sur site en périphérie permettent d'exécuter localement la recherche vectorielle et l'inférence, garantissant ainsi le fonctionnement continu du système même en cas d'indisponibilité de la connectivité externe.
Le coût des temps d'arrêt
Ce n'est pas une nouveauté que temps d'arrêt fournisseurs de services cloud ont augmenté. Le 18 novembre 2025, la panne de Cloudflare a perturbé une grande partie de l'Internet, provoquant des temps d'arrêt plateformes principales plateformes, notamment X, Amazon Web Services, Spotify, etc. L'impact des pannes de connectivité n'est pas théorique. Dans le secteur manufacturier, temps d'arrêt moyen temps d'arrêt est estimé à 260 000 dollars par heure. Lorsque les systèmes d'IA support le contrôle support , la maintenance prédictive ou l'automatisation des processus, toute panne affecte directement la production.
Une architecture exclusivement basée sur le cloud introduit un risque difficile à justifier dans ces environnements. Même de brèves interruptions du réseau peuvent entraîner des pertes financières importantes. sur site réduisent ce risque en supprimant les dépendances externes des chemins d'exécution critiques.
Pour les charges de travail avec des objectifs de latence stricts ou une connectivité limitée, le choix est souvent évident. Les bases de données vectorielles basées sur le cloud peuvent fonctionner pendant le développement, mais elles ne répondent pas aux exigences opérationnelles en production.
La question de la complexité opérationnelle
Le principal argument en faveur des bases de données vectorielles dans le cloud est leur simplicité opérationnelle. Les services gérés éliminent le besoin de fournir du matériel, de gérer des clusters, d'appliquer des correctifs ou de gérer les pannes. Pour les petites équipes ou les projets en phase de démarrage, cet avantage est réel et souvent décisif. Les déploiements dans le cloud permettent aux ingénieurs de se concentrer sur la logique des applications plutôt que sur l'infrastructure.
Il est également important de reconnaître que sur site modernes sont très différents de ceux d'il y a dix ans. Nous ne sommes plus à l'époque du provisionnement manuel des serveurs et des scripts fragiles. Kubernetes, l'infrastructure en tant que code et déploiement automatisés ont considérablement réduit les frais généraux opérationnels. Les mises à niveau progressives, la mise à l'échelle automatisée et la surveillance sont désormais des pratiques courantes dans sur site ainsi que dans le cloud.
De nombreuses entreprises adoptent des approches hybrides pour trouver un équilibre entre rapidité et contrôle. Le développement et l'expérimentation se font dans le cloud, où les équipes peuvent agir rapidement et itérer. Les systèmes de production fonctionnent sur site, où les coûts sont prévisibles et la conformité plus facile à appliquer. Ce modèle permet aux équipes de tirer le meilleur parti des deux modèles sans s'engager pleinement dans l'un ou l'autre.
Cadre décisionnel : huit questions
Le moyen le plus rapide de prendre une déploiement défendable déploiement consiste à passer en revue une petite série de questions fermées (oui ou non) avec les services techniques, juridiques, financiers et opérationnels.
- Vos données nécessitent-elles des restrictions géographiques ?
Les réglementations telles que le RGPD, l'HIPAA et les règles relatives aux services financiers peuvent limiter les lieux où les données peuvent être stockées ou traitées.
Si oui, une solution sur site être sérieusement envisagée, car elle offre un contrôle total sur l'emplacement des données. Si non, déploiement dans le cloud déploiement envisageable.
- Avez-vous requête prévisibles et à haut volume ?
Les coûts liés à la base de données vectorielle dans le cloud varient en fonction de l'utilisation. Il suffit de multiplier le nombre de requêtes mensuelles par le coût unitaire.
Si l'utilisation dépasse environ 80 à 100 millions de requêtes par mois, une solution sur site souvent plus économique. En dessous de cette fourchette, les tarifs du cloud sont généralement plus avantageux.
- Avez-vous besoin d'une fonctionnalité hors ligne ?
Certains systèmes doivent continuer à fonctionner sans accès au réseau, comme dans les environnements de fabrication, de vente au détail ou périphériques.
Si oui, une installation sur site nécessaire. Si non, le cloud reste une option.
- Pouvez-vous tolérer une latence supplémentaire ?
Les déploiements dans le cloud ajoutent une latence réseau, souvent comprise entre 50 et 100 millisecondes.
Si votre application ne peut pas tolérer cela,déploiement sur site déploiement nécessaire. Si elle le peut, les performances du cloud peuvent être acceptables.
- Disposez-vous déjà d'équipes chargées des infrastructures ?
La capacité opérationnelle est importante.
Si vous utilisez déjà sur site , la charge supplémentaire est limitée. Sinon, les services gérés dans le cloud offrent un avantage opérationnel évident.
- La prévisibilité des coûts est-elle importante ?
La facturation basée sur l'utilisation introduit une variabilité des coûts.
Si les coûts prévisibles sont importants, sur site une certaine stabilité. Si la flexibilité est plus importante, les tarifs cloud peuvent être plus adaptés.
- Vous étendez l'infrastructure informatique existante ?
déploiement influe sur la décision.
Si vous étendez des systèmes existants, sur site des investissements actuels. Si vous construisez quelque chose de nouveau, le cloud peut être plus rapide à déployer.
- Quelle est l'ampleur de votre empreinte numérique ?
volume de données la fréquence d'accès influencent le coût à long terme.
Si vous gérez plus de 10 To avec des accès fréquents, une solution sur site intéressante. Si vos données sont moins volumineuses, le cloud est souvent suffisant.
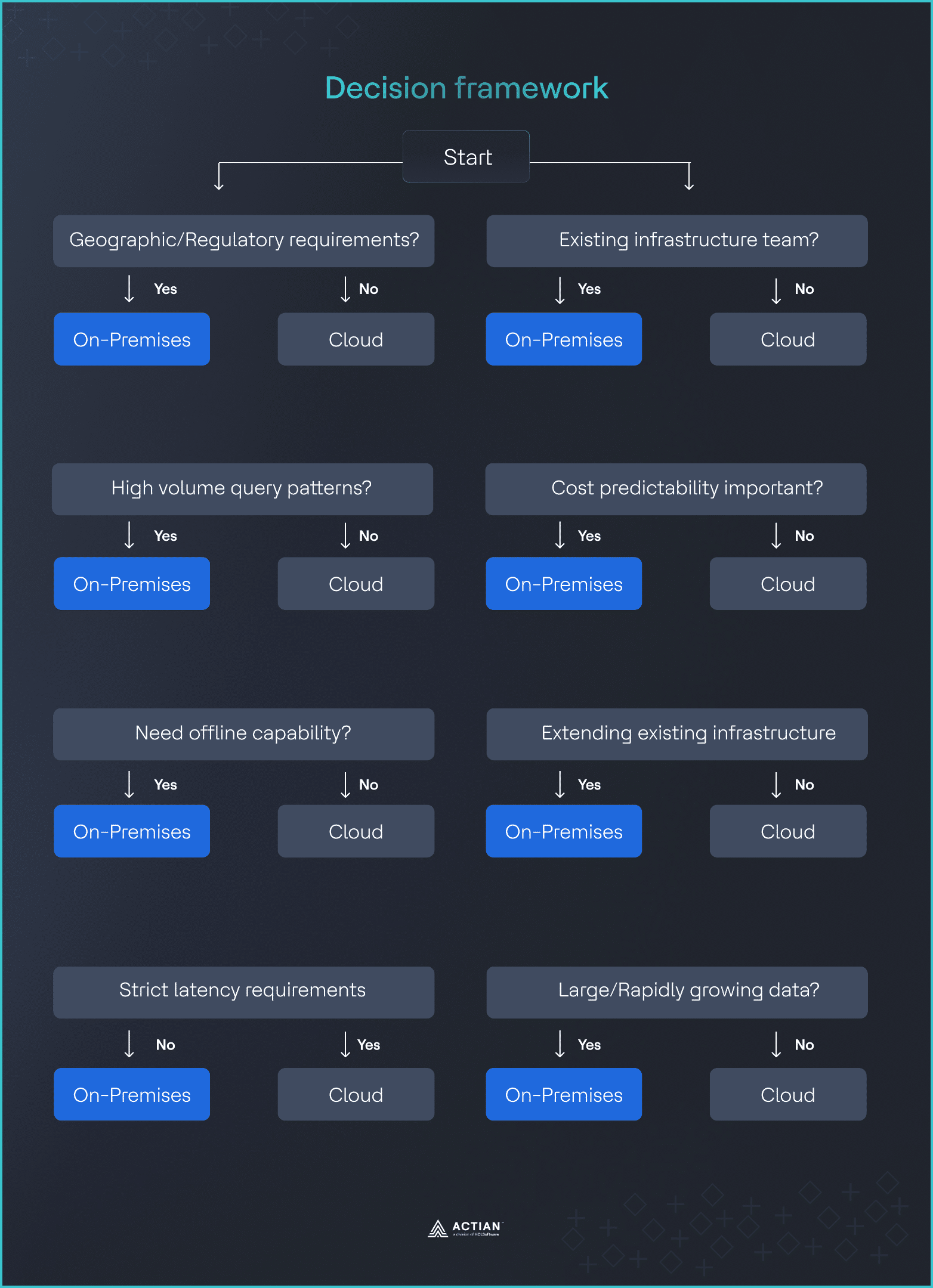
Image 6 : Cadre décisionnel
Lorsque plusieurs réponses vont dans le même sens, la décision devient facile à expliquer et à défendre auprès des équipes techniques, juridiques, financières et opérationnelles.
Quand le cloud prend tout son sens
déploiement sur site déploiement pas toujours la bonne solution. Dans de nombreux cas, les bases de données vectorielles basées sur le cloud restent le meilleur choix. Il est important de bien comprendre ces cas afin d'éviter toute suringénierie.
- Évolutivité imprévisible : les start-ups et les nouveaux produits sont souvent confrontés à une croissance incertaine. plateformes cloud plateformes une évolutivité rapide sans engagement à long terme en matière d'infrastructure, ce qui réduit les risques lorsque la demande est incertaine.
- Petits volumes de données : lorsque le volume total de données est inférieur à 10 To et que requête reste inférieur à environ 50 millions par mois, la tarification du cloud fonctionne généralement bien et est plus simple que l'auto-hébergement.
- Expérimentation rapide : les preuves de concept, les projets de recherche et les premiers prototypes avantage une mise en place rapide et avantage un démontage facile. Les services cloud support une itération support avec un minimum d'efforts opérationnels.
- Aucune contrainte de conformité : si la résidence des données, la souveraineté et les exigences réglementaires ne posent pas de problème, déploiement dans le cloud déploiement les complexités juridiques et accélère la livraison.
- Expertise limitée en matière d'infrastructure : les équipes qui se concentrent sur la logique applicative plutôt que sur les opérations peuvent s'appuyer sur des services gérés au lieu de gérer elles-mêmes les bases de données, les clusters et le matériel.
Dans ces cas, le cloud est l'option la plus efficace et la plus pratique.
déploiement hybride
Les déploiements hybrides constituent un compromis idéal pour les entreprises qui ont besoin à la fois de rapidité et de contrôle. Plutôt que de considérer le cloud et sur site deux options mutuellement exclusives, les équipes placent chaque partie du système là où elle est la plus performante.
Cloud pour l'itération, sur site pour l'évolutivité
Une pratique courante consiste à développer et tester dans le cloud, où les services gérés et l'infrastructure élastique permettent une itération rapide. Une fois que les modèles, les index ou les pipelines sont stables, ils sont transférés vers des environnements sur site afin de répondre aux exigences en matière de conformité, de latence et d'exploitation. Cela permet de préserver la vitesse de développement sans compromettre les garanties de production.
Séparation des données en fonction des risques et de la réglementation
Les architectures hybrides permettent également aux organisations de séparer les charges de travail en fonction du profil de risque. Les données sensibles ou réglementées restent sur site, tandis que l'analyse, apprentissage ou la recherche sur les données dérivées s'effectuent dans le cloud. La même logique s'applique au niveau régional : les données de l'UE peuvent rester sur site dans des environnements souverains, tandis que les charges de travail américaines s'exécutent dans des régions de cloud public, évitant ainsi que les systèmes mondiaux ne soient soumis aux contraintes des juridictions les plus strictes.
Coût et flexibilité de migration
L'optimisation des coûts est un autre facteur déterminant. Les vecteurs fréquemment utilisés ou faible latence peuvent être moins coûteux et plus prévisibles sur site, tandis que le stockage à froid et les charges de travail irrégulières avantage tarifs avantage cloud. De nombreuses équipes commencent par privilégier le cloud, puis transfèrent de manière sélective certains composants sur site les contraintes d'échelle ou de conformité s'intensifient. L'approche hybride permet une évolution contrôlée plutôt qu'une refonte disruptive.
Les études menées dans le secteur montrent qu'il s'agit d'un modèle opérationnel stable. Google Distributed Cloud et plateformes similaires présentent plateformes l'hybride comme une stratégie à long terme, reconnaissant que les systèmes modernes sont conçus pour couvrir plusieurs environnements, et non pour les réduire à un seul.
L'approche d'Actian en matière de bases de données sur site
Pour les équipes qui concluent que déploiement sur site déploiement approprié, la question suivante est : quelle plateforme peut réellement répondre à ces exigences ? L'approche d'Actian d'Actian est spécialement conçue pour ce public, sans présumer que le cloud est la solution par défaut ou l'état final.
Actian fournit une base de données vectorielle de niveau entreprise qui fonctionne entièrement dans votre propre centre de données ou dans des environnements contrôlés. Vous gardez un contrôle total sur le placement des données, la mise en réseau et les opérations. Il n'y a aucune dépendance forcée vis-à-vis de services cloud externes, ce qui simplifie les audits et la conception du système à long terme.
Les exigences de conformité sont considérées comme des contraintes de base. En conservant les données localement et en éliminant les chemins de sortie, Actian se conforme au RGPD, à la loi HIPAA, au FedRAMP et à frameworks réglementaires similaires. Cela réduit le besoin de contrôles compensatoires ou de solutions juridiques complexes.
Le comportement des coûts est également prévisible. Actian évite les modèles de tarification basés sur l'utilisation qui évoluent en fonction du nombre de requêtes ou de vecteurs. Cela simplifie la budgétisation et élimine les surprises à mesure que la charge de travail augmente.
support périphérique support également pris en compte. L'architecture d'Actian prend en charge le fonctionnement hors ligne et l'inférence locale, ce qui la rend adaptée aux sites de fabrication, aux points de vente au détail et à d'autres environnements où la connectivité est limitée ou peu fiable. Le système est conçu pour continuer à fonctionner même lorsque le réseau ne fonctionne pas.
Réflexions finales
Choisir entre le cloud et sur site les bases de données vectorielles revient à comprendre vos priorités. Le cloud fonctionne bien pour les petites charges de travail, les expérimentations rapides et les équipes qui ne disposent pas d'une expertise approfondie en matière d'infrastructure. sur site pertinent lorsque la conformité, la latence, la prévisibilité des coûts ou l'évolutivité sont essentielles.
De nombreuses entreprises considèrent qu'une approche hybride est le meilleur compromis, combinant la flexibilité du cloud et sur site . La clé réside dans la prise de décisions réfléchies basées sur vos données, vos charges de travail et vos besoins réglementaires plutôt que dans le fait de suivre les tendances.
Actian permet aux entreprises de gérer et de contrôler leurs données à grande échelle en toute confiance. Les organisations font confiance aux solutions gestion des données d'intelligence des données d'Actian pour rationaliser les environnements de données complexes et accélérer la fourniture de données prêtes pour l'IA. En tant que division données et IA de HCLSoftware, Actian aide les entreprises à gérer et à contrôler leurs données à grande échelle dans des environnements sur site, cloud et hybrides. En savoir plus sur Actian et comment elle s'intègre dans votre stratégie sur site .
Restez connecté
Des informations exploitables à votre disposition.
(par exemple, sales@..., support)