Comment évaluer les bases de données vectorielles en 2026




Résumé
- La plupart des tests de performance des bases de données vectorielles sont optimisés par les éditeurs et ne reflètent pas les conditions réelles de production, telles que simultanéité, le filtrage et l'ingestion en continu.
- Les principaux risques liés à la production comprennent la latence résiduelle (P95/P99), la dégradation des performances au fil du temps et l'augmentation du coût total de possession à grande échelle.
- Le secteur s'oriente vers le concept de « vecteur en tant que fonctionnalité », privilégiant plateformes intégrées plateformes PostgreSQL + pgvector ou Actian VectorAI DB plutôt que les bases de données vectorielles autonomes.
- Une évaluation efficace nécessite des tests en conditions réelles avec des données de grande dimension, des charges de travail simultanées et une modélisation des coûts à long terme.
En 2026, une crise liée aux performances des bases de données vectorielles met ce marché à rude épreuve. Une recherche sur GitHub avec les mots-clés « benchmark base de données vectorielle » fait apparaître des dépôts bien présentés, accompagnés de tableaux de bord et de graphiques de performances. Cependant, les fournisseurs développent souvent ces outils pour évaluer leurs propres produits et présenter les atouts propres à leur architecture comme des comparaisons objectives.
Zilliz gère VectorDBBench. Redis et Qdrant publient des suites de tests de performance qui mettent en avant leurs propres systèmes. Même les évaluations ANN (Approximate Nearest Neighbor) largement citées, telles que les ANN-Benchmarks, s'appuient sur jeux de données de faible dimension, jeux de données SIFT (Scale-Invariant Feature Transform) et GIST (Generalized Search Trees). Les embeddings des grands modèles linguistiques (LLM) modernes atteignent souvent 3 072 dimensions. Ces benchmarks ne reflètent pas cette réalité.
Les classements récompensent les performances dans des conditions statiques, alors que les systèmes de production doivent résister à des écritures en continu, à métadonnées et à simultanéité . Comme l’a si bien dit l’ingénieur logiciel Simon Frey dans un message devenu viral: « La meilleure base de données vectorielle est celle que vous possédez déjà. » Cette remarque résume bien l’évolution du marché en 2026, qui incite les équipes à délaisser les silos spécialisés au profit des bases de données auxquelles elles font déjà confiance et qu’elles exploitent déjà.
Ce guide adopte une approche axée sur la production. Nous définissons les cinq tests essentiels pour 2026 et examinons pourquoi votre base de données vectorielle optimale existe peut-être déjà au sein de votre architecture actuelle, qu'il s'agisse de PostgreSQL avec pgvector ou d'un moteur hybride d'entreprise tel qu'Actian VectorAI DB.
TL;DR
- Le biais : La plupart des suites de tests de performance proviennent de fournisseurs et sont optimisées pour offrir des avantages architecturaux limités.
- La réalité : Les charges de travail de production comprennent l'ingestion continue, métadonnées et simultanéité que les tests synthétiques ignorent.
- Le risque : la latence de queue (P99), la fragmentation des index et l'amplification des écritures dégradent les systèmes bien avant que le QPS moyen ne baisse.
- La courbe des coûts : Les services de gestion vectorielle proposent souvent une tarification non linéaire à mesure que jeu de données du jeu de données augmente.
- La tendance : En 2026, plateformes intégrées, allant des extensions relationnelles établies (PostgreSQL + pgvector) aux systèmes hybrides d'entreprise (Actian VectorAI DB), seront privilégiées par rapport aux silos « exclusivement vectoriels ».
Pourquoi tous les tests de performance que vous avez vus sont optimisés par les fournisseurs
Les benchmarks donnent une impression d'objectivité, mais reflètent souvent des a priori architecturaux. Des outils tels que VectorDBBench (Zilliz) favorisent la scalabilité distribuée, tandis que les suites Redis et Qdrant mettent l'accent sur in-memory . Pour obtenir des données objectives, les architectes doivent se tourner vers des conférences universitaires évaluées par des pairs, telles que NeurIPS et VLDB (Very Large Databases), qui privilégient la rigueur algorithmique plutôt que le marketing.
Avant d'examiner les éléments essentiels de la production, il est utile de comprendre comment les outils de référence courants influencent les résultats.
| Outil de benchmark | Créateur principal | Priorité à l'optimisation | Biais typique |
|---|---|---|---|
| VectorDBBench | Zilliz (Milvus) | Mise à l'échelle à haut débit | Favorise les clusters de grande envergure ; pénalise les systèmes à nœud unique. |
| vector-db-benchmark | Redis/Qdrant | in-memory | Privilégie les architectures gourmandes en mémoire vive ; ne tient pas compte du coût total de possession de la mémoire. |
| ANN-Références | Universitaire | Efficacité brute de l'algorithme | Utilise jeux de données obsolètes et de faible dimension jeux de données SIFT/GIST). |
| NeurIPS / VLDB | Pairs universitaires | Robustesse algorithmique | Se concentre sur les mathématiques et la théorie ; fait abstraction deSLA et des accords de niveau de service (SLA . |
Les règles cachées de l'analyse comparative
Un obstacle majeur est la « clause DeWitt », une disposition juridique figurant dans de nombreux contrats utilisateur final (CLUF) qui interdit aux utilisateurs de publier des tests de performance indépendants sans l'autorisation du fournisseur. En 2024, BenchANT a constaté que 30 % des principales bases de données vectorielles interdisent légalement de révéler que leurs produits sont lents.
De plus, ces tests de performance s'effectuent souvent au « temps zéro », cette fenêtre artificielle qui suit immédiatement l'ingestion mais précède les mises à jour en temps réel. En production, les systèmes doivent constamment insérer et supprimer des données, ce qui oblige l'index à se réoptimiser en temps réel. Les tests de performance des fournisseurs omettent souvent les échecs dus à un manque de mémoire (OOM) qui en résultent.
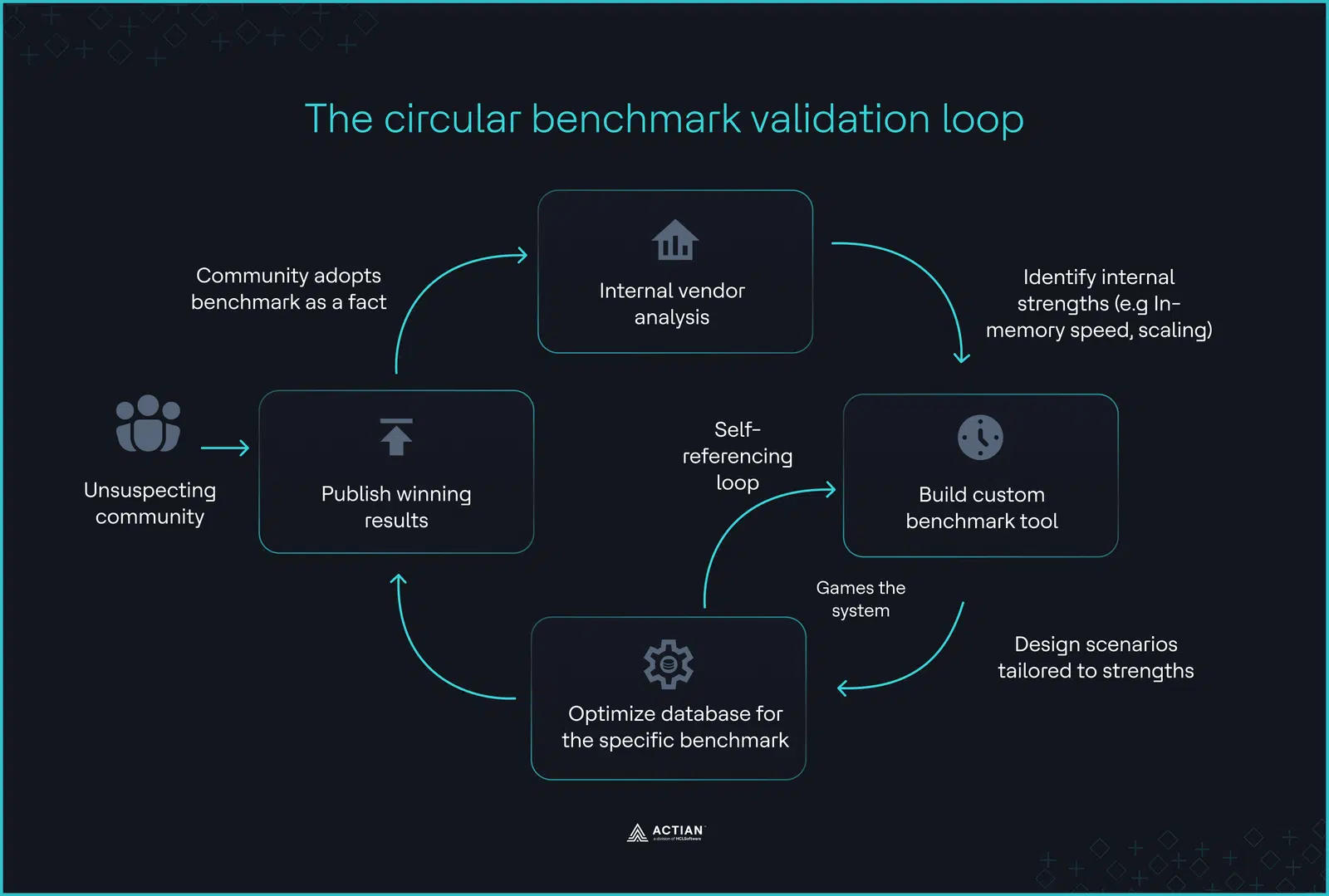
La boucle de validation circulaire
Les cinq tests de production qui comptent vraiment
La plupart des tests de performance évaluent les performances après le chargement des données, avant que des mises à jour réelles n'aient lieu. Or, l'environnement de production est un processus continu et imprévisible. Pour trouver une base de données capable de gérer des utilisateurs réels, vous devriez effectuer ces cinq tests de résistance.
1. Filtrage sous charge simultanée
Les recherches par similarité vectorielle pure sont rares dans la pratique. En production, on recherche plutôt quelque chose comme « Recommandations de produits OÙ la catégorie est « chaussures » ET le stock > 0 ».
L'équipe d'ingénieurs de Reddit, qui gère plus de 340 millions de vecteurs, a identifié métadonnées comme le principal goulot d'étranglement en termes de performances dans le cadre de son déploiement de 2025. Elle a constaté qu'à mesure que le nombre d'utilisateurs simultanés augmentait, la base de données consacrait plus de temps à résoudre métadonnées qu'à calculer les distances de similarité.
- La réalité : en production, cela signifie plus d'une centaine de clients simultanés accédant à différents métadonnées .
- La lacune : VectorDBBench ne réalise ses tests qu'avec un seul client. Dans des conditions réelles, le transfert de données entre le graphe vectoriel et le métadonnées relationnel peut multiplier par dix la latence P99, car le processeur les opérations d'E/S sur le disque.
2. Baisse des performances au fil du temps
Si les systèmes de génération augmentée par la recherche dans les archives (RAG) peuvent techniquement utiliser des bases de connaissances statiques, les applications destinées à la production en 2026 devront refléter des données en temps réel, telles que les tickets clients ou les stocks de produits. Comme l’a admis l’équipe d’ingénieurs de Milvus: « Les tests de performance sont effectués une fois ingestion de données , mais le flux de données de production ne s’arrête jamais. » Si la base de données ne peut pas réindexer aussi rapidement qu’elle ingère les données, votre IA risque de fournir des réponses obsolètes ou incorrectes pendant des heures.
Les tests de performance qui ne comprennent pas de testrequêteen continu pendant 72 heuresrequêten'ont aucune valeur. Vous devez vérifier si requête se dégradent après six mois de maintenance continue des index.
3. Latence de queue sous charge (P95/P99)
La latence moyenne peut être trompeuse et ne reflète pas l'expérience réelle des utilisateurs. Par exemple, un temps de réponse moyen de 10 ms n'est d'aucune utilité si le 1 % des requêtes les plus lentes (P99) prend 800 ms. Cela donne agents IA votre agents IA lente et peu fiable. Seulssimultanéité permettent de mettre en évidence ces pics, qui surviennent souvent lors du ramassage des déchets ou du verrouillage des index.
4. Coût total de possession (TCO)
En 2025, les fournisseurs de services gérés ont mis en place une tarification complexe basée sur les « unités de lecture ». Cela a entraîné une « pénalité de croissance » : si votre index passe de 10 Go à 100 Go, vous risquez de payer 10 fois plus cher pour le même requête .
| Échelle métrique | Base de données vectorielle gérée (facturée à l'utilisation) | Plateforme intégrée/hybride | Impact sur le coût total de possession |
|---|---|---|---|
| Initial (10 Go) | Élevé (frais de plateforme + frais d'utilisation) | Modéré (ressources fixes) | Le coût intégré est inférieur d'environ 40 % |
| Croissance (100 Go) | Élevé (proportionnel au volume) | Faible (mise à l'échelle verticale) | un écart de coût de 8 fois |
| Entreprise (1 To et plus) | Prohibitif (croissance linéaire) | Optimisé (capacité réservée) | Plus de 90 % d'économies à long terme |
C'est principalement cette réalité économique qui motive l'évolution du marché vers le modèle « Vector as a Feature », dans lequel les équipes privilégient sur siteFonctionnalités une évolutivité prévisible plutôt que des silos basés sur l’utilisation.
5. Maturité opérationnelle
Les comparatifs ne tiennent pas compte de la « Support opérationnel », qui quantifie le coût et les risques liés à la maintenance d'une infrastructure spécialisée. Il est facile de trouver un expert en PostgreSQL, car la communauté existe depuis 30 ans, mais recruter quelqu'un maîtrisant une base de données vectorielle de niche lancée il y a seulement trois ans pose souvent un problème.
Évaluer l'écosystème : la base de données est-elle compatible avec les outils de sauvegarde standard ? Peut-elle s'intégrer à Prometheus ? Combien de temps faut-il pour reconstruire un index après une panne ?
Voici comment les résultats des tests de performance se comparent à la réalité en conditions réelles.
| Métrique | Point fort de la référence | Réalité de la production |
|---|---|---|
| Ingestion | QPS statique après achèvement | QPS constant pendant les écritures en continu |
| Latence | Latence moyenne | Latence des filtres P95/P99 sous charge simultanée |
| Filtrage | Recherche filtrée pour un seul client | Plus de 100 requêtes simultanées métadonnées |
| Coût | Coût d'infrastructure par requête | Coût total de possession (TCO) pour plus de 100 millions de requêtes par mois |
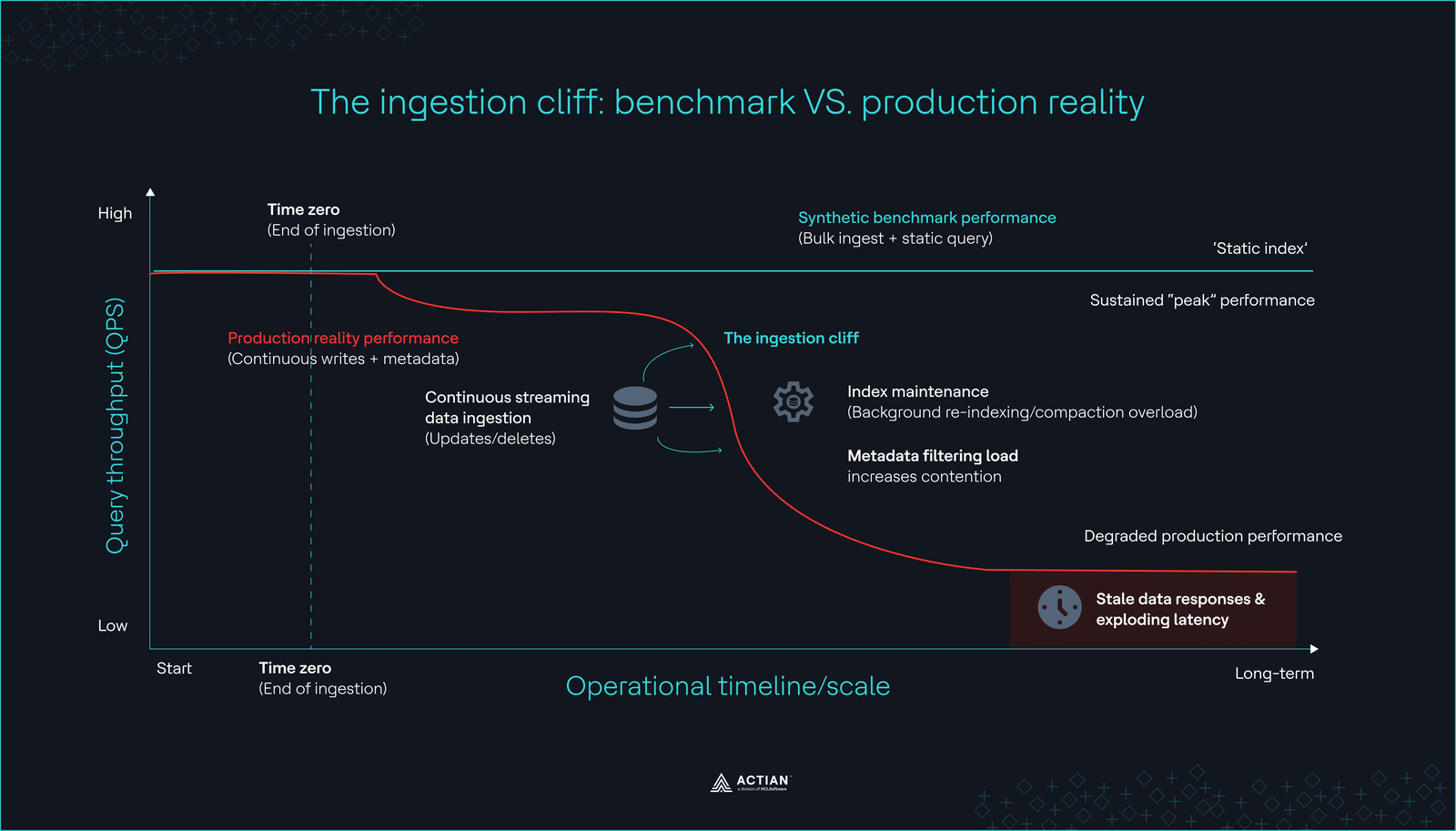 La chute d'ingestion
La chute d'ingestionIdentifier ces goulots d’étranglement cachés goulots d’étranglement la première étape pour mettre en place un système robuste. En 2026, la solution consiste rarement à recourir à une base de données plus rapide et spécialisée. Au contraire, les ingénieurs intègrent ces fonctionnalités aux outils qu’ils connaissent déjà et auxquels ils font confiance.
Le tournant de la consolidation : Vector en tant que fonctionnalité
Corey Quinn, économiste en chef spécialisé dans le cloud, a déclaré un jour : « Le vecteur est une fonctionnalité, pas un produit. » Cette prédiction façonne le marché de 2026. Les équipes délaissent les bases de données spécialisées « uniquement vectorielles » au profit de plateformes intégrées « également vectorielles ». Le transfert de données entre une base de données principale et une base de données vectorielle distincte pose souvent plus de problèmes qu’il n’en résout.
La renaissance de PostgreSQL
Sur plateformes Hacker News, les ingénieurs affirment souvent qu’environ 80 % des cas d’utilisation du RAG (en particulier ceux dont les vecteurs d’intégration sont inférieurs à 2 Mo) ne nécessitent pas de base de données vectorielle spécialisée. Pour ces charges de travail, les silos autonomes génèrent souvent davantage de frictions opérationnelles qu’ils n’apportent de gains de performances. Instacart a validé cette hypothèse à grande échelle en migrant d'Elasticsearch vers PostgreSQL, réalisant ainsi 80 % d'économies et réduisant charge de travail en écriture charge de travail 10 fois après avoir éliminé la nécessité de coordonner et de réconcilier les données entre des architectures fragmentées.
Récemment, pgvectorscale a atteint un débit de 471 requêtes par seconde avec un taux de rappel de 99 % sur 50 millions de vecteurs, surpassant ainsi les 41 QPS de Qdrant sur un matériel AWS identique. Les tests de performance des fournisseurs omettent souvent ce résultat, car il démontre que la plupart des applications RAG ne nécessitent pas de faire appel à un fournisseur spécialisé.
| Indicateur de performance | PostgreSQL (pgvector + pgvectorscale) | Qdrant (spécialisé) | Le Delta |
|---|---|---|---|
| Débit (QPS) | 471.57 | 41.47 | 11,4 fois plus rapide dans Postgres |
| Latence P95 | 60,42 ms | 36,73 ms | Qdrant est 39 % plus rapide en fin de traitement |
| Latence P99 | 74,60 ms | 38,71 ms | Qdrant est 48 % plus rapide en fin de traitement |
| Matériel | AWS r6id.4xlarge (16 vCPU) | AWS r6id.4xlarge (16 vCPU) | Parité |
Le fossé de l'entreprise intégrée
Pour les charges de travail qui dépassent les capacités des extensions de base, Actian VectorAI DB comble cette lacune en intégrant un de haute performance avec support native des vecteurs. Les équipes peuvent ainsi effectuer métadonnées et une recherche par similarité au sein d'un même système, ce qui réduit les mouvements de données et simplifie requête .
| Plateforme | Stratégie architecturale | Capacités prévues en matière d'IA |
|---|---|---|
| Base de données Actian VectorAI | de haute performance | Conçu pour l'analyse intégrée et support native des vecteurs. |
| PostgreSQL | Fonctionnalité intégrée | Leviers pgvector dans le cadre du SQL standard. |
| Vecteurs AWS S3 | Axé sur le stockage | Conçu pour requête vecteurs dans un système de stockage d'objets. |
| MongoDB Atlas | API unifiée pour les documents et les vecteurs | Intègre la recherche vectorielle native directement dans le workflow actuel du référentiel de documents. |
À mesure que le marché se consolide, notre façon d'évaluer les bases de données évolue. Les équipes ne se demandent plus « Qui propose le graphe le plus rapide ? », mais « Quelle architecture offre le requête le plus fiable ? ». Il n'y a pas de solution universelle. Les équipes doivent plutôt faire face à toute une gamme de compromis entre la rapidité spécialisée et la fiabilité intégrée.
Le processus d'évaluation accorde désormais davantage d'importance à la robustesse opérationnelle, à la flexibilité en conditions réelles et à support la recherche hybride. La fiabilité requête devient la priorité absolue, notamment compte tenu de la demande croissante en matière de recherche hybride.
La réalité de la recherche hybride que les tests de performance vectoriels purs masquent
La recherche vectorielle pure échoue souvent au test de « fiabilité », qui évalue dans quelle mesure la réponse d'une IA s'appuie strictement sur les données fournies. Un score de fiabilité élevé garantit que le modèle de langage à grande échelle (LLM) évite les inventions et respecte scrupuleusement vos données internes.
Selon une analyse publiée sur le blog Microsoft Azure DevBlog, la recherche vectorielle pure présente à elle seule des difficultés en matière d'exactitude factuelle, avec une note médiocre de 2,79 sur 5 pour la pertinence. La solution réside dans la recherche hybride, qui combine la similarité vectorielle sémantique avec la correspondance traditionnelle par mots-clés (BM25).
La perte de performance de 20 à 40 %
La recherche hybride nécessite une puissance de calcul importante. La base de données doit classer les résultats provenant de deux moteurs différents, par exemple lexical et sémantique, puis les fusionner à l'aide d'un algorithme de fusion. En production, on observe généralement une perte de performance de 20 à 40 % lors du passage d'une recherche vectorielle pure à une recherche hybride. La fusion réciproque des classements (RRF) est à l'origine de la majeure partie de ce « coût de fusion » qui, selon les recherches d'Elastic, peut augmenter considérablement requête par rapport aux recherches sur un seul index.
Les bases de données qui intègrent la recherche vectorielle, le filtrage, la recherche en texte intégral et requête au sein d'un seul moteur exécutent les requêtes hybrides en une seule instruction atomique. requête peut évaluer simultanément métadonnées , les conditions de recherche en texte intégral et la similarité vectorielle. Cela permet à l'optimiseur de générer de meilleurs plans d'exécution et de déplacer moins de données.
À l'inverse, les silos vectoriels spécialisés fragmentent le requête . Les applications acheminent les requêtes vers plusieurs systèmes et fusionnent les résultats en dehors de la base de données. Cela accroît la complexité du système et entraîne une latence imprévisible en cas de charge élevée.
plateformes hybrides plateformes qu'Actian VectorAI DB résolvent ce problème en intégrant la recherche vectorielle au cœur du moteur de base de données. Cette conception élimine les jointures entre systèmes, simplifie les opérations et réduit la charge architecturale à long terme.
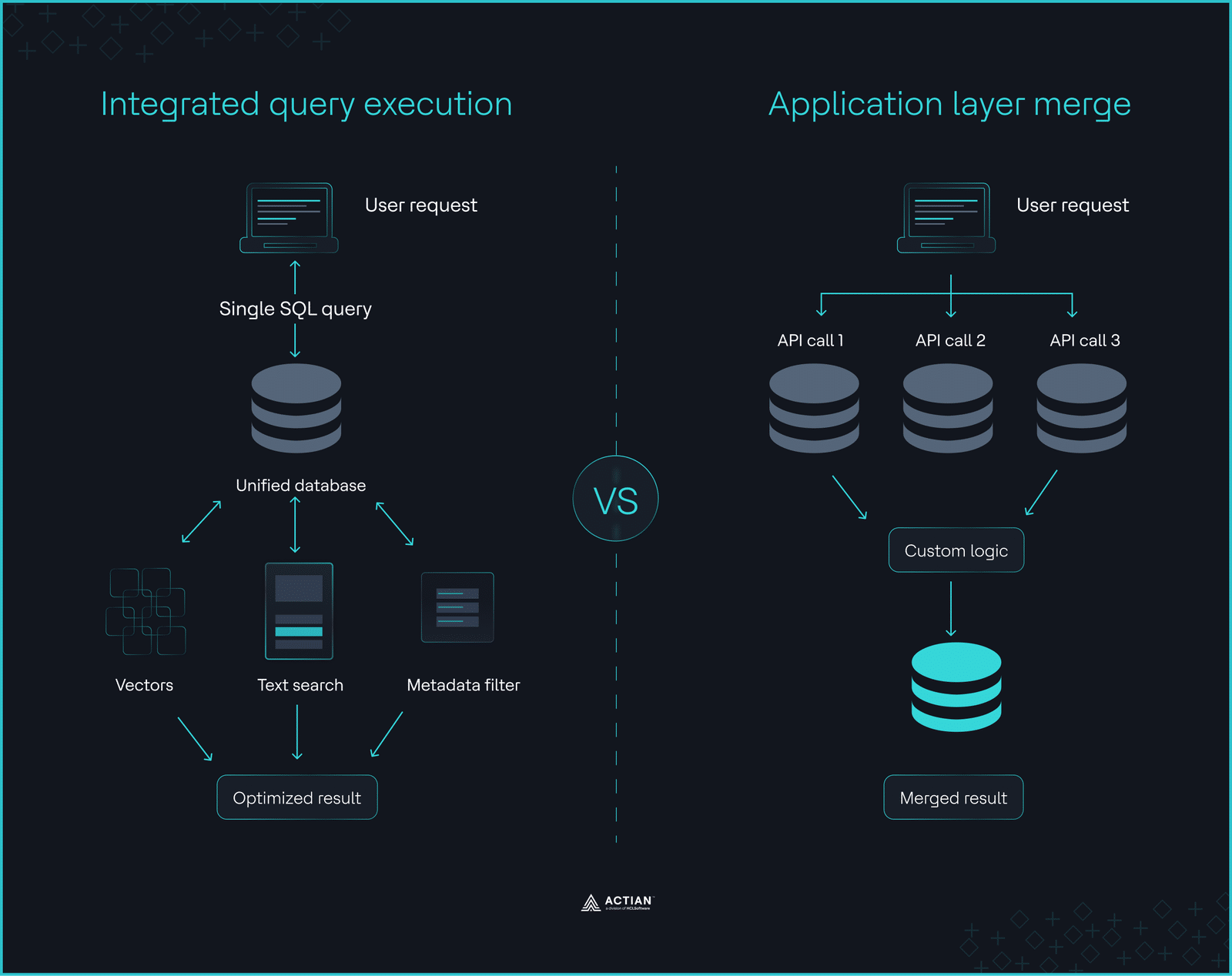 requête intégrée requête vs fusion au niveau de la couche applicative
requête intégrée requête vs fusion au niveau de la couche applicativeCréez votre propre cadre d'évaluation
Cessez de vous demander quelle base de données arrive en tête du classement GitHub. Demandez-vous plutôt quelle architecture s'adapte à vos contraintes. En 2026, ces contraintes porteront principalement sur la localisation des données, l'évolutivité et l'expertise de l'équipe.
Les arguments en faveur du modèle hybride et du travail sur site
La localisation des données n'est plus une option pour les entreprises internationales. Les sanctions prévues par la loi européenne sur l'IA pouvant atteindre 35 millions d'euros ou 7 % du chiffre d'affaires mondial, les bases de données vectorielles exclusivement hébergées dans le cloud constituent une option juridiquement inenvisageable pour les secteurs réglementés.
- Souveraineté : 60 % des entreprises financières hors des États-Unis prévoient d'adoptersur site solutionssur site d'ici 2028.
- Coût : lorsque requête atteint 100 millions par mois, la « taxe cloud » commence à se faire sentir. L'auto-hébergement ou l'utilisation plateformes hybrides plateformes Actian peut réduire de moitié vos frais d'infrastructure.
- Maturité : si vous gérez déjà une base de données relationnelle, votre équipe dispose déjà de 90 % des compétences requises.
L'arbre de décision pour l'architecture 2026
- Les données doivent-elles être sur site pour des raisons de conformité ? → Privilégiez la base de données Actian VectorAI ou PostgreSQL en hébergement autonome.
- Votre requête dépasse-t-il les 100 millions par mois ? → Évitez la tarification gérée basée sur l'utilisation ; optez plutôt pour une solution auto-hébergée ou une capacité réservée.
- Avez-vous besoin métadonnées complexe métadonnées ? → Un moteur relationnel/vectoriel intégré est indispensable.
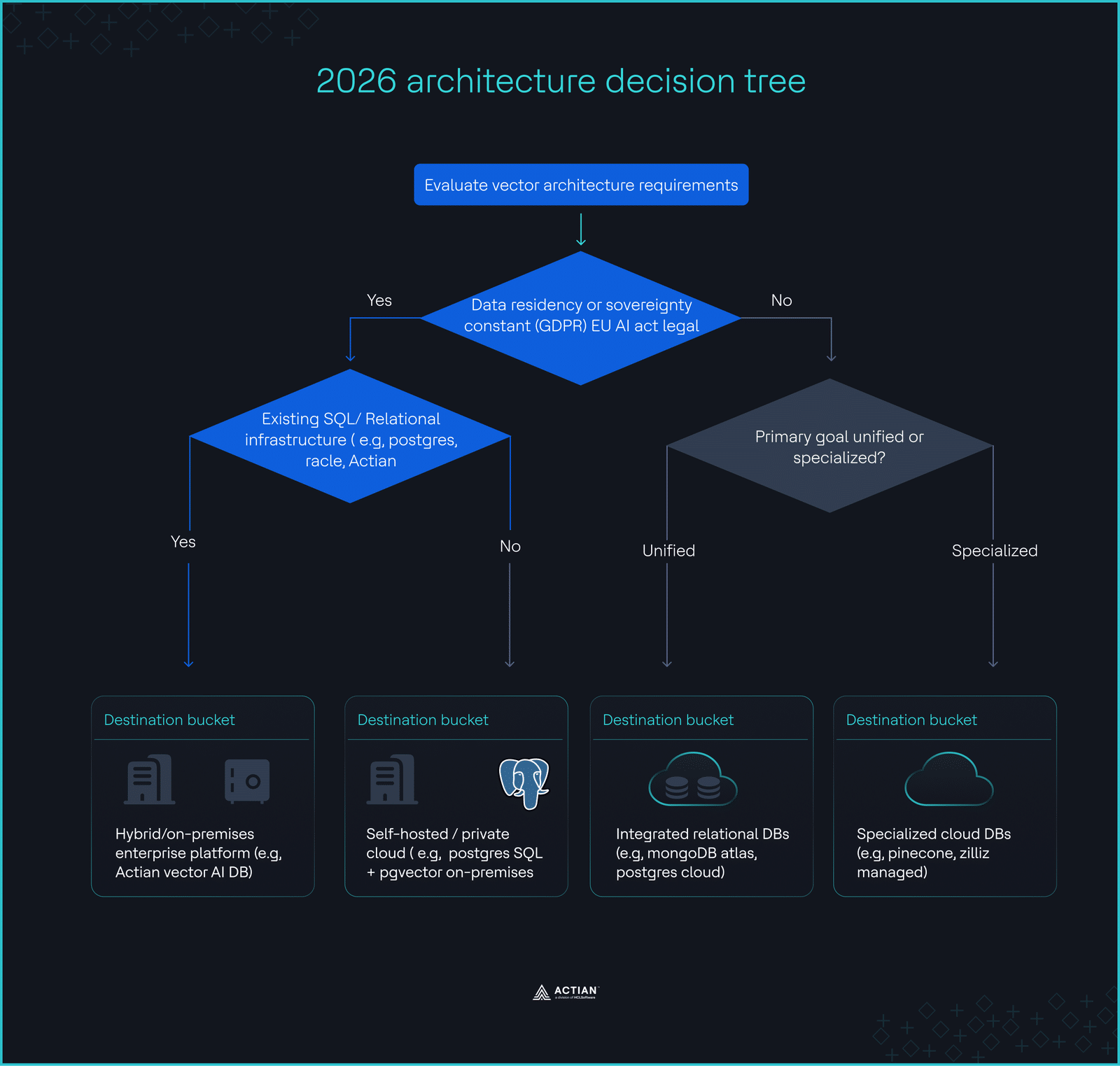 L'arbre de décision pour l'architecture 2026
L'arbre de décision pour l'architecture 2026Comment évaluer les évaluateurs
Pour éviter de vous laisser induire en erreur par les benchmarks des fournisseurs, examinez l'outil d'évaluation avec le même soin que vous accordez à la base de données. Pour repérer un test biaisé, ne vous arrêtez pas aux chiffres de QPS présentés en gros titres et vérifiez les conditions exactes dans lesquelles ils ont été obtenus.
Utilisez la grille d'évaluation suivante pour examiner tout rapport de référence avant qu'il n'influence vos décisions architecturales.
| Indicateur d'évaluation | Drapeau rouge (Ignorer le résultat) | Drapeau vert (résultat fiable) |
|---|---|---|
| État d'ingestion | Les requêtes sont exécutées sur un index statique et immuable, sans aucune écriture en arrière-plan. | Les tests « Read-while-Write », dans lesquels les requêtes s'exécutent pendant ingestion de données continue ingestion de données. |
| Parité matérielle | Instances « optimisées » du fournisseur de cloud vs instances « par défaut » locales ou non adaptées de la concurrence. | Nous avons vérifié que les configurations processeur, de la mémoire vive et des E/S disque étaient identiques sur tous les systèmes testés. |
| Sélectivité des données | Des filtres à « haute sélectivité » (supprimant 99 % des données) qui masquent les inefficacités liées aux jointures et aux analyses. | Tests de « faible sélectivité » (10 à 20 % filtrés) qui obligent le moteur à gérer des parcours d'index à grande échelle. |
| Dimensionnalité | Tests effectués sur jeux de données historiques à 128 dimensions jeux de données SIFT/GIST). | Tests effectués sur des vecteurs de 1 536 ou 3 072 dimensions qui correspondent aux résultats des grands modèles de langage (LLM) actuels. |
| Mesure de la latence | Se concentre exclusivement sur la « latence moyenne » ou le « temps de réponse moyen ». | Indique clairement les temps de latence P95 et P99 en cas de charge simultanée élevée. |
Liste de contrôle préalable à l'engagement
- Test avec des représentations de haute dimension (3 072 dimensions ou plus) représentatives de l'environnement de production.
- Mesurer la latence de la mesure P99 avec plus de 100 utilisateurs simultanés appliquant divers métadonnées .
- Calculez le coût total de possession (TCO) sur trois ans, en tenant compte de l'augmentation des besoins en stockage, des frais de sortie de données et des frais de réindexation.
- Assurez-vous que votre équipe est en mesure de gérer observabilité les sauvegardes de la nouvelle pile.
Réflexions finales
Une évaluation fiable nécessite de réaliser des tests avec vos propres données, vos propres modèles et à votre échelle. Importez des données représentatives de votre environnement de production, effectuez un test de stabilité d'une semaine sous charge simultanée, puis mesurez la latence P99 et le coût total de possession (TCO).
Si votre charge de travail une conformité, déploiement hybride ou une maturité opérationnelle de niveau production que les bases de données vectorielles gérées ne peuvent offrir, alors l'accès anticipé à Actian VectorAI DB est la prochaine étape qu'il vous faut.
Rejoignez la communauté Actian sur Discord pour échanger sur l'architecture vectorielle avec des ingénieurs qui s'attaquent à de véritables problèmes de production.

Restez connecté
Des informations exploitables à votre disposition.
(par exemple, sales@..., support)