5 modèles d'architecture d'IA en périphérie pour les environnements hors réseau




Résumé
- Les environnements déconnectés nécessitent des architectures d'IA en périphérie capables de fonctionner entièrement hors ligne, sans dépendre du cloud.
- Cinq déploiement permettent une IA en périphérie résiliente : drones, usines, apprentissage fédéré, stockage et retransmission, et réseaux maillés.
- Les architectures natives de l'edge support l'inférence support , une faible latence et un fonctionnement fiable sur des réseaux distants ou instables.
- Le choix de l'architecture appropriée dépend de la stabilité de la connexion, des exigences en matière de latence et des contraintes matérielles.
Un camion de transport de minerais qui opère à plus de 300 km de l'antenne-relais la plus proche ne s'arrête pas lorsque la connexion est interrompue. Une éolienne en mer ne suspend pas la détection des défaillances parce qu'une liaison satellite est coupée lors d'une tempête. Dans ces environnements, les processus d'inférence, les boucles de contrôle et les systèmes de sécurité doivent continuer à fonctionner quel que soit l'état du réseau. Pourtant, l'architecture dominante de l'IA en périphérie reste axée sur la connectivité et l'IA dans le cloud.
Les environnements déconnectés exigent des architectures natives en périphérie et privilégiant le mode hors ligne, conçues pour garantir l'autonomie opérationnelle. Les signaux du marché confirment cette réalité.
Selon les prévisions d'ABI Research, les dépenses consacrées aux serveurs en périphérie devraient atteindre 19 milliards de dollars d'ici 2027, sur site représentant près de 10,5 milliards de dollars. En 2025, les entreprises auront déployé environ 815 millions d'appareils IoT compatibles avec la périphérie à l'échelle mondiale.
La plupart des environnements opérationnels sont intrinsèquement distribués, générant des données loin des systèmes cloud centralisés. déploiement en périphérie qui reposent sur l'échange constant de ces données pour leur traitement font que les systèmes IoT passent à côté d'informations cruciales, augmentent la latence et entraînent des pertes de données. Pourtant, les architectures de périphérie proposées continuent de considérer Préparation hors ligne Préparation une option complémentaire plutôt que comme la norme.
Nous présentons cinq déploiement de l'IA en périphérie qui fonctionnent sans connectivité présupposée, en abordant leurs stratégies de mise en œuvre, leurs cas d'utilisation concrets, leurs compromis, ainsi qu'un cadre décisionnel permettant de choisir le modèle le mieux adapté à vos priorités opérationnelles.
TL;DR
Aperçu des cas d'utilisation adaptés à chaque déploiement documenté.
| Motif | Idéal pour |
| Le drone (système d'IA de périphérie autonome à nœud unique) | Systèmes mobiles autonomes soumis à des contraintes énergétiques strictes et sans connexion au cloud |
| L'usine (IA en périphérie à plusieurs nœuds avec option cloud) | Installations dotées d'infrastructures locales dans des environnements soumis à des fluctuations |
| Apprentissage fédéré hiérarchique (client-périphérie-cloud) | Opérations distribuées sensibles en matière de confidentialité, pour lesquelles les risques de fuite de données sont inacceptables |
| Inférence déconnectée avec stockage et retransmission | Opérations avec des créneaux de connectivité planifiés |
| Le réseau (structure distribuée de bout en bout) | Coordination distribuée sans dépendance au cloud |
Pourquoi les environnements déconnectés constituent un problème pour l'IA en périphérie
Il existe un angle mort structurel concernant les environnements déconnectés, qui découle de l'hypothèse selon laquelle les secteurs utilisant des modèles d'IA en périphérie sont centrés sur le cloud et fonctionnent avec une connectivité permanente. Or, là où les applications d'IA en périphérie sont les plus cruciales, il n'y a pas d'accès réseau constant.
Ce que signifie réellement « déconnecté »
Les environnements déconnectés sont des environnements où la connectivité est instable ou inexistante, allant de scénarios en « air gap » (cloisonnement physique) avec isolement totale du réseau isolement des configurations intermittentes caractérisées par de fréquentes baisses de qualité de la connexion.
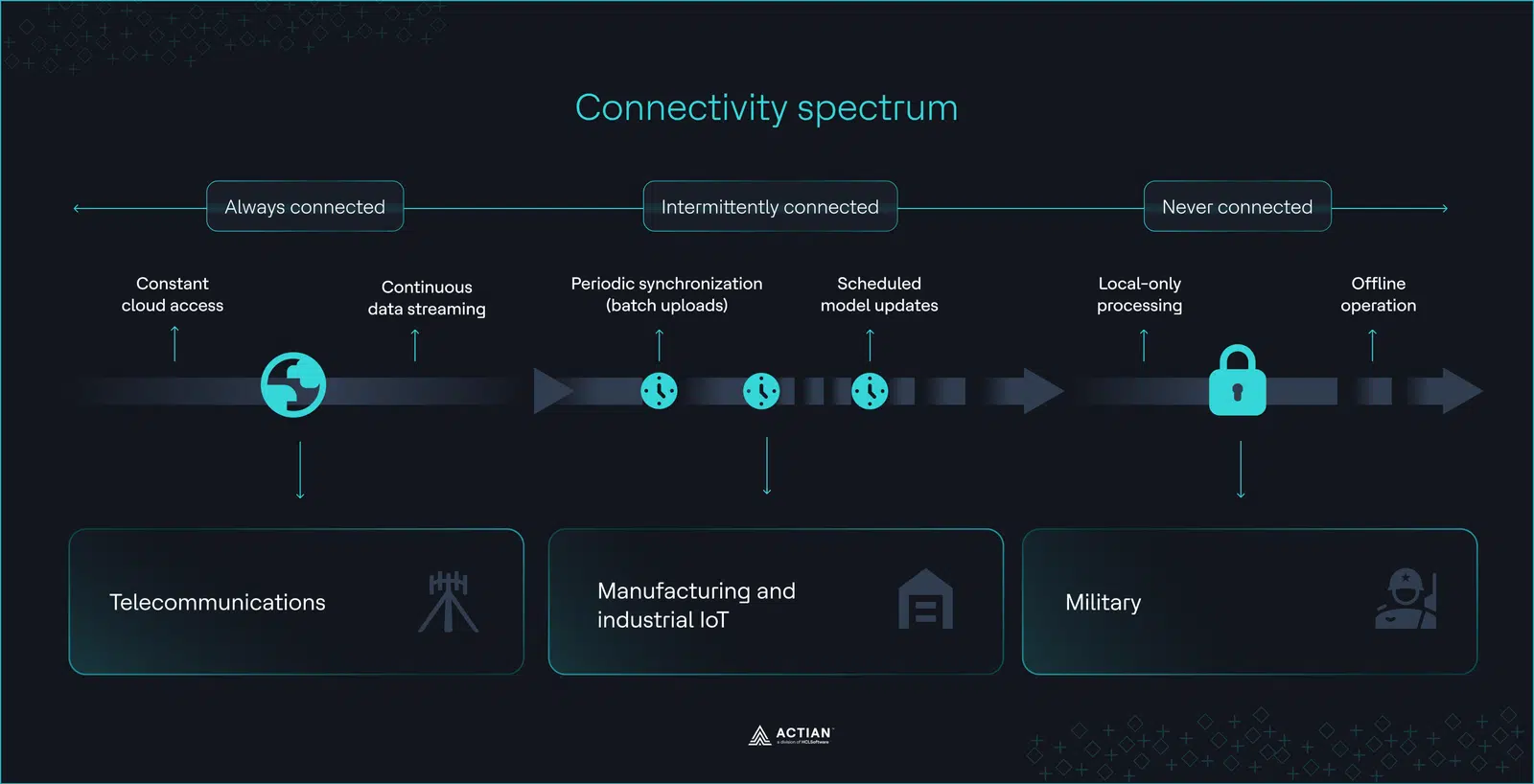
Dans ces contextes opérationnels, Fonctionnalités d'IA en périphérie prennent Fonctionnalités , car elles support traitement des données en temps réel, une faible latence, l'optimisation de la bande passante et gouvernance des données gouvernance indispensables gouvernance les environnements hors réseau.
Precedence Research estime que le marché mondial de l'IA en périphérie atteindra 143 milliards de dollars d'ici 2034, soit une augmentation potentielle de 472 % par rapport aux 25 milliards de dollars prévus pour 2025. Pour une part importante de ce marché, une connectivité permanente au cloud n'est pas envisageable. Pourtant, l'inférence, le stockage local des données et prise de décision en temps réel prise de décision se poursuivre indépendamment de l'état du réseau ou de l'emplacement.
C'est dans la déconnexion que l'IA en périphérie prend toute sa valeur
Les environnements isolés, tels que les sites miniers, les usines de fabrication, les opérations militaires, les parcs éoliens offshore et les villes intelligentes, mettent en évidence les limites des déploiement actuelles déploiement de l'IA en périphérie.
Rio Tinto exploite des sites miniers situés jusqu'à 1 500 km de toute couverture cellulaire, où les opérateurs ne peuvent pas compter sur une infrastructure centralisée. Ils ont besoin de robots d'inspection autonomes qui utilisent l'IA en périphérie pour suivre le personnel et les véhicules, en analysant en temps réel les données issues du LiDAR 3D, de l'imagerie thermique et des capteurs de gaz.
Au moins 300 camions de transport autonomes sont en service dans la région de Pilbara, exploitée par Rio Tinto. Chaque camion traite environ 5 To de données par jour dans des galeries souterraines où la connectivité est limitée, ce qui nécessite des réseaux LTE privés pour le traitement IoT directement sur les appareils.
Les parcs éoliens offshore sont confrontés à une contrainte similaire. Les éoliennes et les navires d'inspection se retrouvent hors service lorsque les liaisons satellites sont interrompues en raison de conditions météorologiques difficiles ou d'une obstruction de la ligne de visée, et chaque éolienne subit en moyenne environ 8,3 pannes par an. Ces parcs ont besoin de systèmes d'IA en périphérie capables de détecter les problèmes à un stade précoce, de surveiller le trafic maritime en temps réel, d'analyser les données SCADA locales et de déclencher des inspections en fonction des conditions de vent du moment.
Dans les environnements de production isolés, les directeurs d'usine ont également besoin de l'IA en périphérie pour automatiser les contrôles qualité, anticiper les pannes de machines et protéger la santé des employés.
Une exigence similaire en matière de traitement local et sécurisé est au cœur des opérations militaires, où les systèmes fonctionnent au sein de réseaux isolés physiquement (air-gapped) dans des environnements caractérisés par un accès refusé, perturbé, intermittent et limité (DDIL), afin de préserver la confidentialité et l'intégrité des données. Les soldats doivent communiquer avec les unités de commandement et analyser les données de combat en temps réel sans avoir recours à des centres de données dans le cloud ni à d'importantes ressources informatiques.
C'est dans ces environnements que déploiement de l'IA en périphérie déploiement le plus d'impact. Selon Dell, le traitement des données d'entreprise s'effectuera dans des centres de données distribués d'ici 2026, mais la plupart des architectures documentées continuent de privilégier le renvoi des données vers les centres de données dans le cloud.
Modèle déploiement basé sur des contraintes matérielles
Les exigences en matière de puissance de calcul pour l'IA et charge de travail en périphérie viennent également étayer les déploiement entre le cloud et la périphérie.
Un modèle d'apprentissage profond comportant 3 milliards de paramètres peut nécessiter jusqu'à 4 Go de mémoire vive, mais les appareils en périphérie, tels que les microcontrôleurs et les capteurs IoT, disposent généralement de moins d'1 Go au total pour le système d'exploitation, les charges de travail et le stockage. Les architectures d'environnements connectés tablent sur une importante capacité de calcul qui n'existe pas en périphérie.
Les architectures d'IA en périphérie doivent, dès le départ, partir du principe d'un fonctionnement hors ligne en priorité et tenir compte des limites matérielles. L'ajout a posteriori de capacités hors ligne aux systèmes cloud ne permettra pas de pallier les problèmes de connectivité et les ressources matérielles limitées. Nous présentons ci-dessous cinq modèles architecturaux spécialement conçus pour les environnements hors réseau.
Modèle 1 : Le Drone (IA de périphérie autonome à nœud unique)
Dans les environnements où la connectivité fait défaut et où la latence opérationnelle ne permet pas de supporter les allers-retours sur le réseau, la déploiement se réduit à un seul appareil. L'inférence ne peut être ni déléguée, ni synchronisée, ni différée. Les appareils en périphérie, tels que les drones, les véhicules sous-marins et les robots d'inspection à distance, doivent prendre des décisions en s'appuyant uniquement sur la puissance de calcul, la mémoire et les données des capteurs disponibles localement.
Cette contrainte définit l'architecture du drone. Toute la logique d'IA s'exécute sur un seul appareil, sans orchestration externe ni déchargement vers le cloud.
Lorsque l'appareil correspond à l'ensemble de la pile
Ce modèle avantage aux systèmes mobiles qui doivent fonctionner de manière autonome dans des environnements sans connexion.
En l'absence de couche d'orchestration externe, la collecte des données, le prétraitement, l'inférence, le stockage et la logique de contrôle s'effectuent au sein d'un ensemble autonome. Cet ensemble s'exécute sur un seul nœud, sans communication réseau avec d'autres nœuds ni répartition apprentissage des modèles.
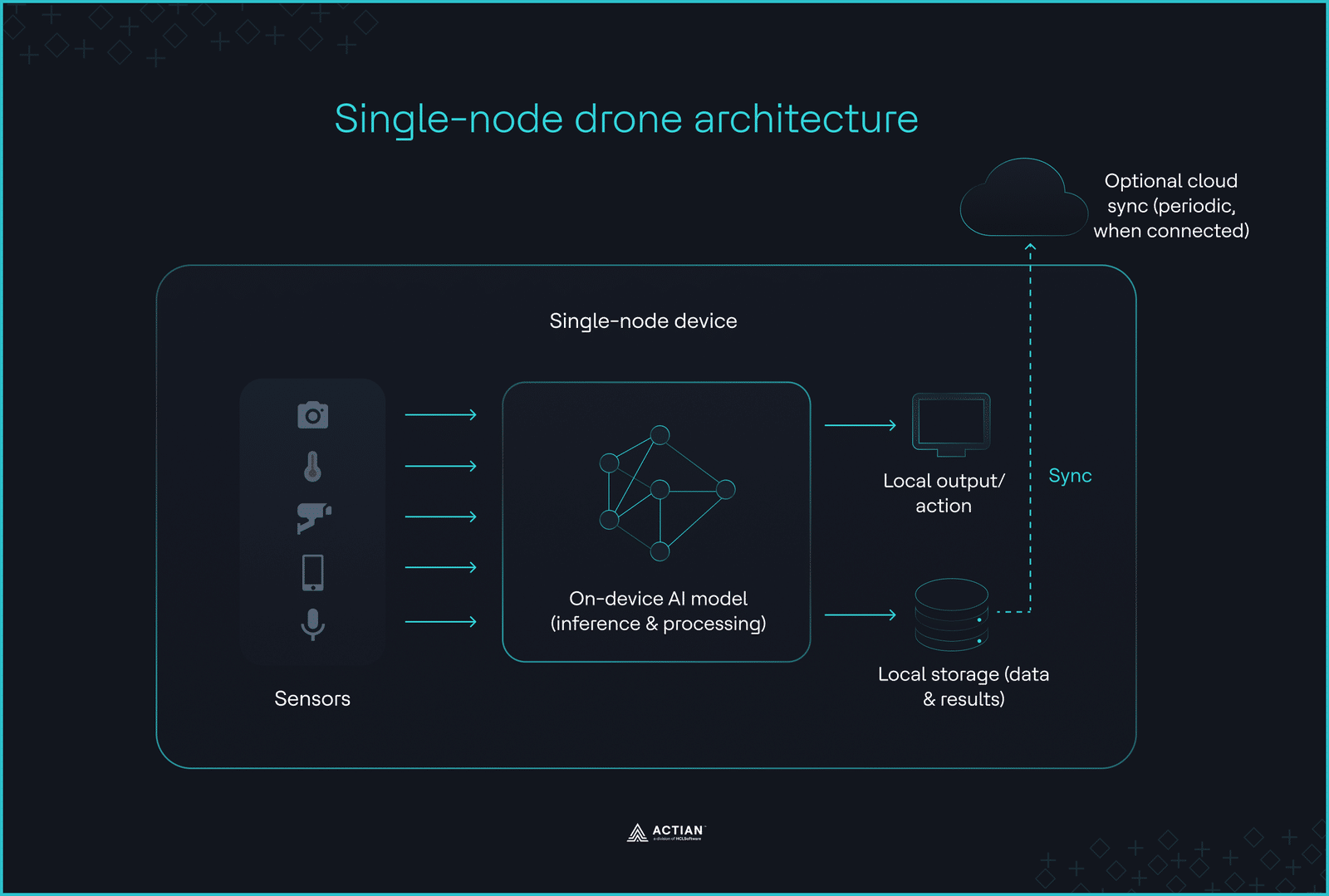
Grâce à la logique de décision intégrée, les appareils périphériques peuvent exécuter des opérations prédéfinies même lorsqu'ils sont hors connexion. Une fois que l'appareil a capturé les données, il filtre les informations redondantes et ne conserve que les données pertinentes en vue d'une consultation manuelle ultérieure.
Les drones autonomes chargés de la détection d'objets et de la classification du terrain dans les zones minières ne peuvent pas interrompre leur exécution en attendant une inférence externe. L'architecture de ces drones élimine la dépendance au réseau en privilégiant l'inférence embarquée.
Cela en fait le modèle le plus adapté aux environnements DDIL où la connectivité est activement bloquée ou dégradée. Les drones de défense ne peuvent pas partir du principe que le réseau va se rétablir ou qu’un signal de commande parviendra à destination. Toute coordination sur le champ de bataille doit pouvoir être exécutée à partir du dispositif seul.
GE Aerospace, qui gère plus de 45 000 moteurs d'avions commerciaux et recueille chaque jour plus de 480 000 instantanés de données par appareil, met en œuvre cette architecture à grande échelle. Les modèles d'IA embarqués gèrent la maintenance prédictive en stricte conformité avec la norme DO-178C, qui impose à GE Aerospace de vérifier chaque système embarqué par rapport à toutes les conditions de défaillance possibles avant même qu'il ne quitte le sol. Cette assurance qualité s'aligne sur l'exigence architecturale du drone, qui ne prévoit aucun support externe support déploiement du modèle.
Le traitement local sur un seul nœud nécessite des modèles d'apprentissage automatique peu volumineux.
Optimisation de l'intelligence en périphérie
Les appareils en périphérie fonctionnent avec des limites strictes en matière de mémoire et de consommation d'énergie, exprimées en mégaoctets et en milliwatts. Lorsque les réseaux à pleine précision dépassent la mémoire vive disponible ou les budgets énergétiques, la capacité des modèles doit être optimisée avant que l'inférence ne devienne réalisable.
Toutes charge de travail en périphérie ne charge de travail pas forcément un réseau neuronal. Dans des environnements soumis à des contraintes, comme les parcs éoliens offshore, les méthodes statistiques classiques, telles que l'algorithme de Welford et la régression linéaire, s'avèrent souvent plus performantes que les réseaux neuronaux pour le traitement streaming .
Un microcontrôleur qui traite les données des capteurs à l'aide de l'algorithme de Welford met à jour les statistiques de manière séquentielle, sans conserver les points de données antérieurs, ce qui permet de limiter la consommation de mémoire et d'énergie. Avant de pousser un réseau neuronal à ses limites matérielles, il convient de se demander si la classe de modèle elle-même est adaptée au cas d'usage
Lorsque les réseaux neuronaux sont adaptés à la charge de travail, la quantification permet de pallier leurs limites matérielles en réduisant la précision numérique de leurs poids, biais et activations. Le passage de 32 bits à 8 bits réduit la taille du modèle d'environ 75 %, avec une perte de précision inférieure à 1 %.
Une autre technique de compression, appelée « élagage », élimine les paramètres redondants qui contribuent très peu à la précision des résultats. L'élagage d'un modèle de détection d'objets tel que YOLOv5 peut réduire de 40 % le nombre de ses paramètres et sa charge de calcul avant déploiement.
frameworks TinyML frameworks que TensorFlow Lite for Microcontrollers, ONNX Runtime et PyTorch Mobile support déploiement de modèles support . Le code suivant présente un exemple de scénario de quantification avec TensorFlow Lite.
import tensorflow as tf
import numpy as np
#apprentissage à l'aide du convertisseur TFLite
# Convertit les nombres à virgule flottante 32 bits en entiers 8 bits
def representative_dataset():
for i in range(100):
yield [X_train[i:i+1]]
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.representative_dataset = representative_dataset
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.inference_input_type = tf.int8
converter.inference_output_type = tf.int8
tflite_quant_model = converter.convert()
Start with quantization for higher speedup rates without significant accuracy loss, followed by pruning to compress the model’s size further. For the drone architecture, the target size on a single microcontroller is <1MB. Plumerai’s person detection model demonstrates how compression techniques can achieve this goal. The model achieved 737KB on an ARM Cortex-M7 microcontroller with less than 256KB of on-chip RAM using binarized neural networks.
Au niveau matériel, des processeurs à faible consommation d'énergie tels que le NVIDIA Jetson Nano, le Google Edge TPU et l'ARM Cortex-M exécutent des modèles d'IA directement sur des appareils en périphérie, spécialement conçus pour les tâches de vision par ordinateur et de fusion de capteurs. Les variantes de l'ARM Cortex-M offrent jusqu'à 600 giga-opérations par seconde (GOPS) avec une efficacité énergétique moyenne de 3 téra-opérations par seconde et par watt (TOPS/W), selon la configuration.
déploiement de drones déploiement une certaine rigidité architecturale. Les possibilités d'intervention en cours d'exécution étant limitées, l'architecture doit anticiper tous les états de défaillance dès la phase de conception. La norme DO-178C renforce cette contrainte en exigeant une validation complète du système avant déploiement. Les équipes doivent concevoir chaque mise à jour de modèle et chaque correction de comportement sans disposer d'une fenêtre d'orchestration.
Modèle 2 : L'usine (IA en périphérie à plusieurs nœuds avec option cloud)
En cas de coupure de réseau dans les usines de fabrication et les grands magasins, les opérations d'inférence doivent se poursuivre interne plusieurs machines. L'architecture de l'usine répond à cette exigence en répartissant les charges de travail liées à l'IA entre les clusters sur site , ce qui permet de maintenir le contrôle opérationnel à l'intérieur du périmètre de l'installation.
La synchronisation dans le cloud reste facultative ; elle est utilisée uniquement pour le réentraînement des modèles ou l'analyse par lots, et non comme une dépendance d'exécution. La priorité est de garantir la résilience et l'autonomie opérationnelle de tous les nœuds, quelle que soit la disponibilité du réseau.
L'inférence reste dans l'atelier de production
L'architecture de l'usine s'articule autour de trois éléments : les passerelles périphériques, les nœuds de calcul et le stockage local.
Une passerelle périphérique achemine les requêtes des capteurs vers les nœuds périphériques, qui extraient le contexte de bases de données locales telles qu'Actian Zen, effectuent des inférences à partir de modèles et réinscrivent les résultats dans la base de données. prise de décision le traitement local restent sur site. Les systèmes cloud ne gèrent les mises à jour des modèles que de manière périodique ou en réponse à un déclencheur.
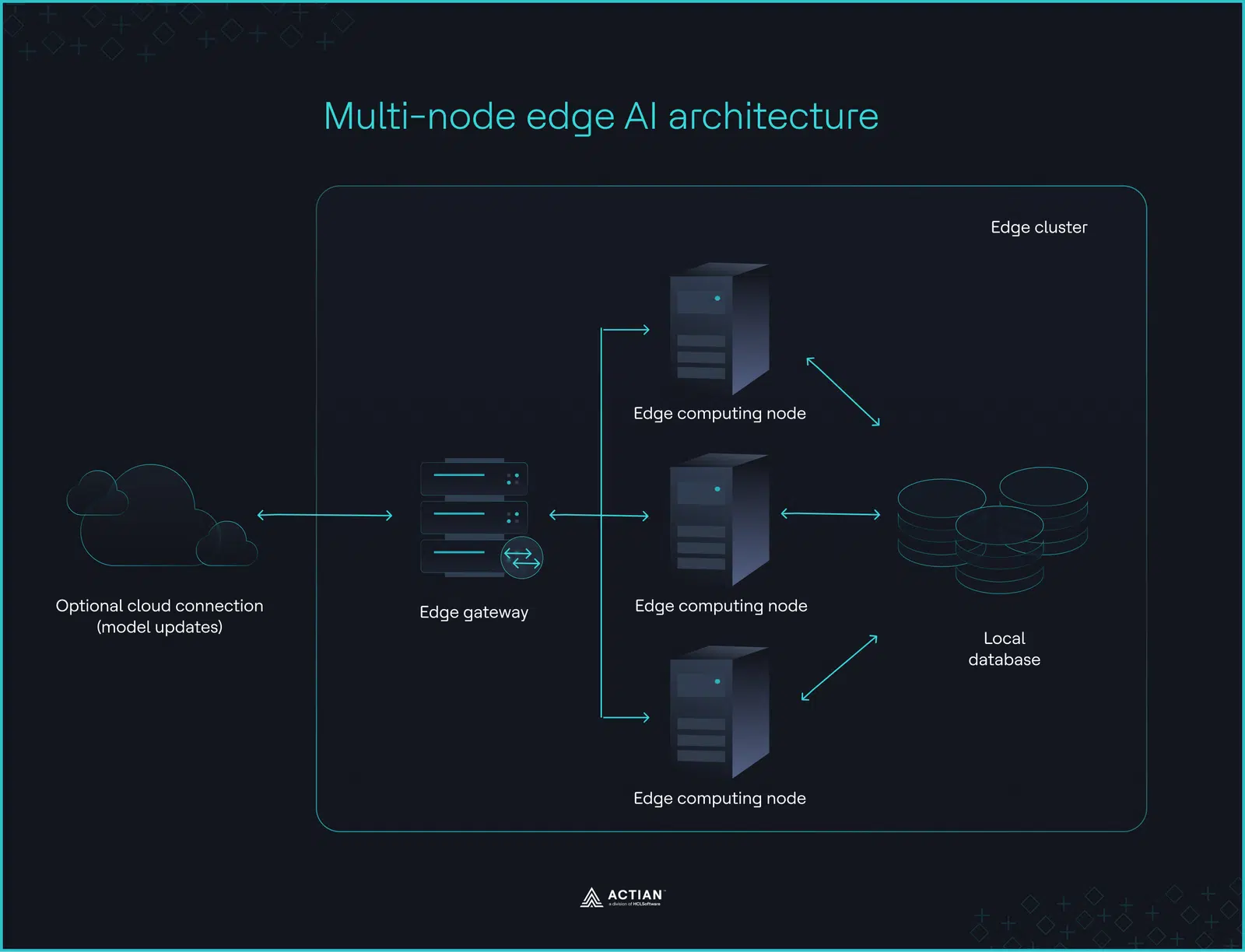
Les environnements industriels génèrent en continu de grands volumes de données de télémétrie provenant de capteurs, de contrôleurs et de systèmes d'inspection. La répartition des opérations d'inférence entre plusieurs nœuds périphériques permet de maintenir un débit d'inférence élevé. Cependant, en l'absence d'une couche d'orchestration locale chargée de gérer cette répartition et le cycle de vie des modèles, les nœuds périphériques fonctionnent comme des processeurs isolés plutôt que comme un système coordonné.
K3s, AWS IoT Greengrass, Azure IoT Edge et Siemens Industrial Edge sont des outils d'orchestration couramment utilisés pour la gestion des clusters en périphérie. Chacun d'entre eux se distingue par sa manière de gérer déploiement des modèles déploiement la gestion des nœuds.
K3s déploie des modèles conteneurisés sous forme de clusters de nœuds de travail, accompagnés d'un plan de contrôle permettant de surveiller leur état de santé. La configuration du paramètre de point de terminaison du magasin de données permet aux équipes de stocker les données locales dans sur site telles que PostgreSQL et Actian Zen, en remplacement de SQLite, qui est la valeur par défaut. Chick-fil-A utilise K3s en périphérie pour traiter les transactions en caisse dans plus de 3 000 restaurants.
AWS IoT Greengrass déploie des modèles d'IA compilés dans le cloud sous forme de composants dotés de fonctions d'inférence prédéfinies sur des cartes NVIDIA Jetson TX2, Intel Atom et des appareils équipés de Raspberry Pi. L'inférence s'effectue sur site, les données pouvant être exportées vers AWS IoT Core à des fins d'optimisation des modèles. Les sites de production de Pfizer utilisent AWS IoT Greengrass pour surveiller les bioréacteurs en temps quasi réel afin de minimiser les risques de contamination.
Siemens Industrial Edge déploie des modèles conteneurisés sous Docker directement sur le site de production, fournissant ainsi des informations en temps réel sur l'état des machines. L'usine Siemens Electronics d'Erlangen a réduit de 80 % déploiement des modèles et de 50 % lesfausses détections anomalie sur les cartes de circuits imprimés (PCB) grâce à cet orchestrateur. En effectuant l'inférence sur les images des PCB en local et en ne confiant au cloud que le réentraînement des modèles, l'usine a réduit ses coûts de stockage de données de 90 %.
Azure IoT Edge utilise un déploiement JSON pour spécifier les modèles conteneurisés à télécharger sur les périphériques en périphérie. Le traitement des données s'effectue en périphérie, Azure IoT Hub assurant une supervision centralisée tandis que les périphériques conservent leur autonomie. Thomas Concrete Group utilise Azure IoT Edge pour collecter des données provenant de capteurs Embarqué le béton frais, estimer le délai de prise du béton et envoyer des prévisions à Azure IoT Hub.
Le tableau ci-dessous met en évidence les différences entre chaque orchestrateur.
| Critères | K3s | Azure IoT Edge | AWS IoT Greengrass | Siemens Industrial Edge |
| Gestion des nœuds | Gère les nœuds via un plan de contrôle allégé | Gère les nœuds à distance via Azure IoT Hub | Gère les nœuds via AWS IoT Core | Gère les nœuds via la plateforme Siemens Industrial Edge Management |
| Modèle de déploiement | Déploie des modèles sous forme de pods Kubernetes à l'aide d'images de conteneurs standard | Configure les déploiements à l'aide d'un manifeste JSON qui définit quels modules, contenant les modèles entraînés, s'exécutent sur quels nœuds | Déploie les modèles sous forme de composants dotés de fonctions d'inférence prédéfinies | Déploie les modèles directement dans les ateliers sous forme de conteneurs Docker |
| Intégration dans le cloud | Peut être intégré à une infrastructure centrale | Prise en charge via Azure IoT Hub | S'intègre à AWS IoT Core | Prend en charge l'intégration avec les services AWS |
Lorsque le réseau OT constitue la frontière de sécurité
Les entreprises industrielles fusionnent leurs réseaux informatiques et leurs réseaux de technologies opérationnelles (OT) afin de support les intégrationssur site et de l'IoTsur site . Mais cette convergence élargit leur surface d'attaque. 75 % des attaques visant les réseaux OT proviennent d'environnements informatiques, et 80 % des fabricants signalent une augmentation des menaces de sécurité sur l'ensemble de leurs réseaux informatiques et OT.
Pour les équipes qui envisagent déploiement en usine déploiement des systèmes industriels, la segmentation du réseau doit devenir une priorité absolue. Les solutions d'IA en périphérie doivent fonctionner exclusivement au sein du réseau OT, conformément au modèle Purdue. Les données sensibles et les opérations d'inférence restent à proximité des machines, des capteurs et des automates programmables (PLC) qui en ont besoin. Cette barrière de sécurité réduit au minimum la propagation latérale des menaces provenant du réseau informatique.
Modèle 3 : Apprentissage fédéré hiérarchique (client-périphérie-cloud)
L'apprentissage fédéré hiérarchique (HFL) s'appuie sur une infrastructure à trois niveaux destinée aux équipes confrontées à des restrictions en matière de mobilité des données en périphérie.
Au niveau le plus bas, les appareils clients effectuent apprentissage local, optimisant les paramètres du modèle par la méthode du gradient descendant local. Les serveurs périphériques situés au niveau intermédiaire regroupent les poids de modèle mis à jour provenant de tous les appareils clients afin d'assurer la cohérence statistique. Un dernier cycle d'agrégation effectué par un serveur cloud constitue le niveau supérieur, produisant un modèle global que les serveurs périphériques redistribuent aux appareils clients. Étant donné que seules les mises à jour des paramètres transitent par cette hiérarchie, une connectivité intermittente n'interrompt pas apprentissage .
L'image ci-dessous illustre cette itération, qui se poursuit jusqu'à ce que le modèle global atteigne la précision souhaitée ou converge.
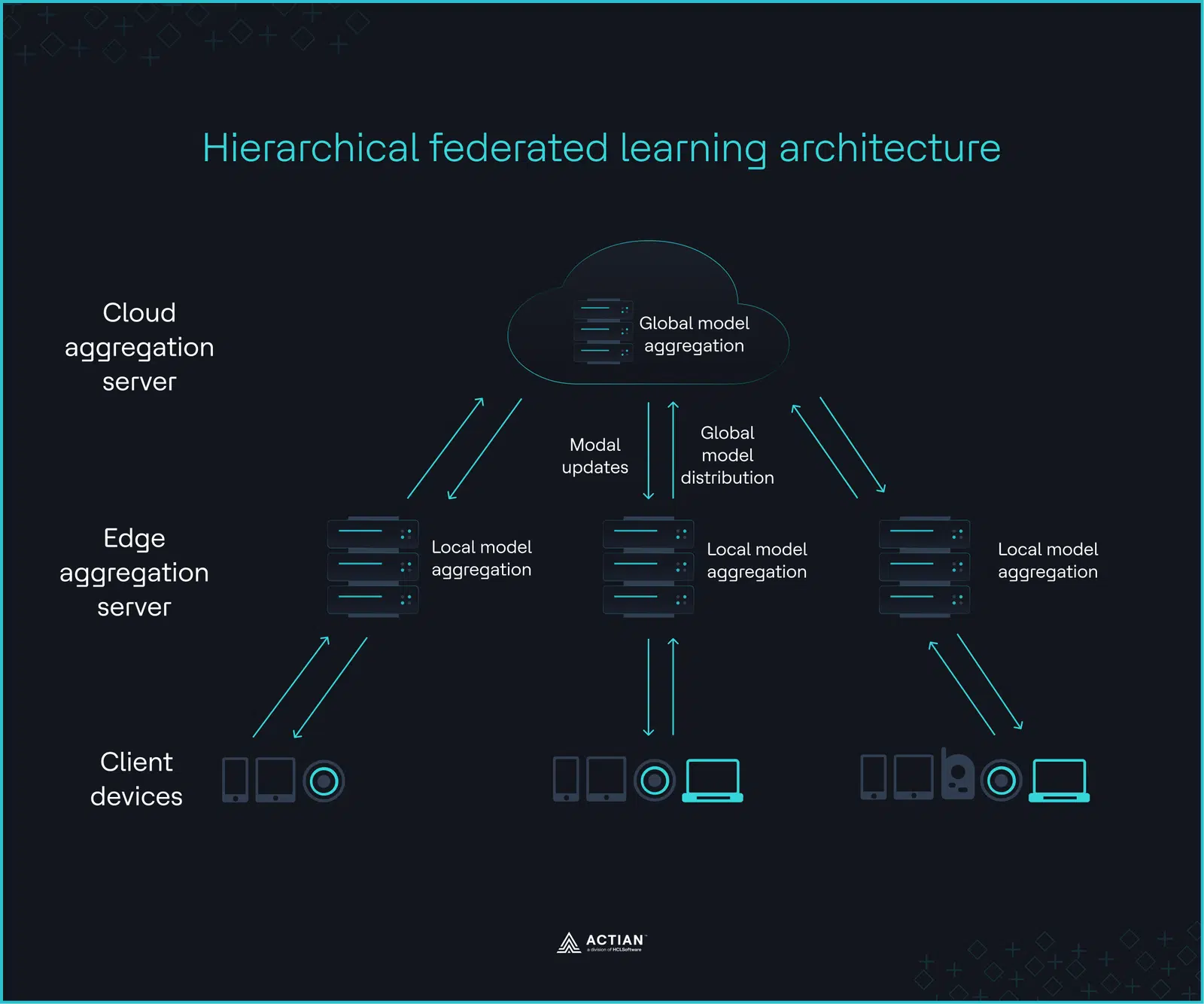
Les secteurs tels que la santé et les services financiers, où les données brutes sont liées à leur source en raison de contraintes de confidentialité, d'exigences réglementaires et de limitations de bande passante, constituent des cas d'utilisation idéaux pour la technologie HFL. Les exigences en matière de souveraineté des données et les tensions géopolitiques viennent s'ajouter à ces contraintes, limitant ainsi les lieux et les modalités de circulation des données au niveau de l'infrastructure.
Une étude menée par BARC a révélé que 19 % des entreprises prévoient d'augmenter leurs sur site , motivées par ce besoin de souveraineté des données. HFL permet à un modèle partagé de s'améliorer à travers des nœuds distribués sans que les données sous-jacentes ne franchissent jamais de frontière juridictionnelle.
Une récente expérience apprentissage en ligne (HFL) apprentissage la santé a atteint un taux de précision de 94,23 % sur un jeu de données modifié de l'Institut national des normes et des technologies (NIST), tout en conservant les données sur les appareils des utilisateurs. Seules les informations agrégées pertinentes sont transmises au cloud afin de préserver la confidentialité et de limiter les risques de fuite de données.
Dans le cadre déploiement dans le secteur de la santé, les appareils portables (couche inférieure) transmettent des données brutes au serveur périphérique local de l'hôpital (couche intermédiaire), qui regroupe les données provenant de plusieurs appareils portables et les envoie à un institut de recherche régional (couche supérieure) pour une agrégation finale, sans divulguer les données des patients.
Le modèle HFL est le plus complexe à mettre en œuvre. support outils support fragmentés et, contrairement aux autres modèles évoqués, il ne bénéficie actuellement d'aucun support natif support l'écosystème Actian. Les équipes doivent donc évaluer soigneusement la charge de travail liée à cette mise en œuvre avant de s'engager dans cette architecture.
L'architecture HFL comporte trois variantes selon la couche qui gère les décisions relatives aux données.
1. Apprentissage fédéré hiérarchique orchestré dans le cloud
Le serveur cloud central coordonne le apprentissage , les communications entre les clients et la périphérie, les calendriers de synchronisation et la topologie globale, sans qu'il soit nécessaire de procéder à des cycles d'agrégation supplémentaires au niveau des serveurs périphériques.
Le HFL orchestré dans le cloud convient aux institutions financières, où une connectivité fiable, même ponctuelle, suffit à maintenir la boucle de coordination. Dans le cadre d'déploiement détection des fraudes , plusieurs établissements bancaires peuvent entraîner à partir de données transactionnelles, en envoyant des mises à jour vers le cloud, qui agrège, valide et redistribue le modèle amélioré aux banques.
2. Apprentissage fédéré hiérarchique orchestré en périphérie
Les serveurs périphériques gèrent de manière autonome les attributions des clients locaux, en regroupant les mises à jour de ces derniers afin de produire un modèle amélioré localement, sans aller-retour vers le cloud. Les systèmes cloud support intervalles réguliers pour le réentraînement en masse des modèles. Ce sont les environnements tels que les parcs éoliens offshore, où une connectivité instable est la norme, avantage de cette variante. Les éoliennes envoient les mises à jour des modèles à un serveur périphérique local, qui se charge de l'agrégation et de l'amélioration autonome des modèles.
3. Agrégation entre pairs
Cette variante s'appuie sur un modèle de type « gossip » sans orchestrateur central. Les clients échangent les poids de leur modèle avec d'autres nœuds, ce qui réduit les conflits de gradients dans le cas de données hétérogènes.
Alors que le modèle HFL de base réduit les coûts de transmission de données via des mises à jour agrégées, l'agrégation entre pairs permet de maintenir à la fois apprentissage l'agrégation au sein des nœuds participants. Dans des environnements distribués tels que les villes intelligentes, les capteurs de trafic échangent directement des mises à jour anomalie avec les appareils voisins jusqu'à ce qu'ils parviennent naturellement à un modèle amélioré à l'échelle du réseau.
Ces trois variantes se distinguent par leurs exigences fonctionnelles, comme le montre le tableau ci-dessous.
| Fonctionnalités | Orchestré dans le cloud | Orchestré en périphérie | Agrégation entre pairs |
| Modèle d'orchestration | Le cloud coordonne l'ensemble des opérations d'agrégation et de distribution des modèles | Le serveur périphérique effectue des agrégations au niveau local et se synchronise régulièrement avec le cloud | Pas d'orchestrateur ; les mises à jour se propagent entre les clients jusqu'à convergence |
| Niveau de confidentialité | Moyen ; le cloud gère les mises à jour du modèle | Élevé ; les données brutes restent sur les serveurs périphériques locaux | Élevé ; aucun organisme central ne supervise les mises à jour agrégées |
| Besoins en bande passante | Élevé ; toutes les mises à jour sont envoyées vers le cloud | Moyen ; seules les mises à jour agrégées sont transmises au cloud | Faible ; les mises à jour ne circulent qu'entre les pairs voisins |
| Tolérance à la déconnexion | Faible ; la rupture de la connexion avec les nuages perturbe la coordination | Élevé ; le serveur périphérique fonctionne de manière autonome en cas de panne | Moyen ; convergence lente des partitions de réseau |
L'infrastructure en couches de HFL prend en charge apprentissage de modèles à grande échelle apprentissage répartissant les tâches de calcul et de communication entre plusieurs nœuds de la hiérarchie. Le défi lié à cette architecture à plusieurs niveaux réside dans la gestion de la surcharge de communication, des modèles globaux obsolètes et des reconfigurations des nœuds.
Dans le HFL, le coût de communication est directement proportionnel à la taille de la mise à jour du modèle. Les techniques de compression des gradients, telles que la raréfaction aléatoire et l'arrondi stochastique, permettent de réduire la taille des données de mise à jour jusqu'à 98 % avant leur transmission.
Le cycle de mise à jour asynchrone de HFL, dans lequel le modèle global intègre les mises à jour des clients au fur et à mesure de leur arrivée, augmente également le risque de voir les paramètres du modèle devenir obsolètes. L'agrégation pondérée limite l'influence des mises à jour obsolètes, empêchant ainsi les appareils les plus lents de nuire à la qualité du modèle global.
Les changements de topologie constituent un défi supplémentaire. Les clients sont réaffectés à différents serveurs périphériques, les rôles s'inversent entre les nœuds clients et les nœuds agrégateurs, et de nouveaux appareils rejoignentapprentissage. Chaque reconfiguration ralentit la convergence et réduit la précision si les nouveaux serveurs périphériques ne disposent pas apprentissage antérieur.
Modèle 4 : Inférence déconnectée de type « store-and-forward »
Dans les environnements sans connexion, les périodes d'interruption peuvent durer des heures, voire des jours. L'architecture de stockage et de retransmission tient compte de cette réalité : elle permet d'assurer le traitement et le stockage des données à grande échelle pendant temps d'arrêt, puis de transmettre les résumés vers le cloud dès que le système est reconnecté.
Dans les environnements d'automatisation industrielle, tels que les sites pétroliers et gaziers isolés et les navires opérant à des kilomètres des antennes-relais, cette architecture résout le problème fondamental du maintien de la continuité des données malgré les interruptions de réseau.
L'inférence n'attend pas le cloud
déploiement « store-and-forward » déploiement une approche hybride. apprentissage dans le cloud, mais l'exécution est transférée vers la périphérie une fois le modèle déploiement. En cas de perte de connexion, prise de décision, les boucles de contrôle et le déclenchement des alarmes se poursuivent localement sans interruption, et le système met en mémoire tampon les résultats horodatés dans une base de données Edge locale base de données Edge la reprise de la synchronisation.
Une fois le réseau rétabli, la passerelle périphérique transfère tous les événements mis en mémoire tampon vers une infrastructure cloud centrale, fournissant ainsi les données nécessaires pour déployer des modèles mis à jour et optimiser les pipelines d'IA.
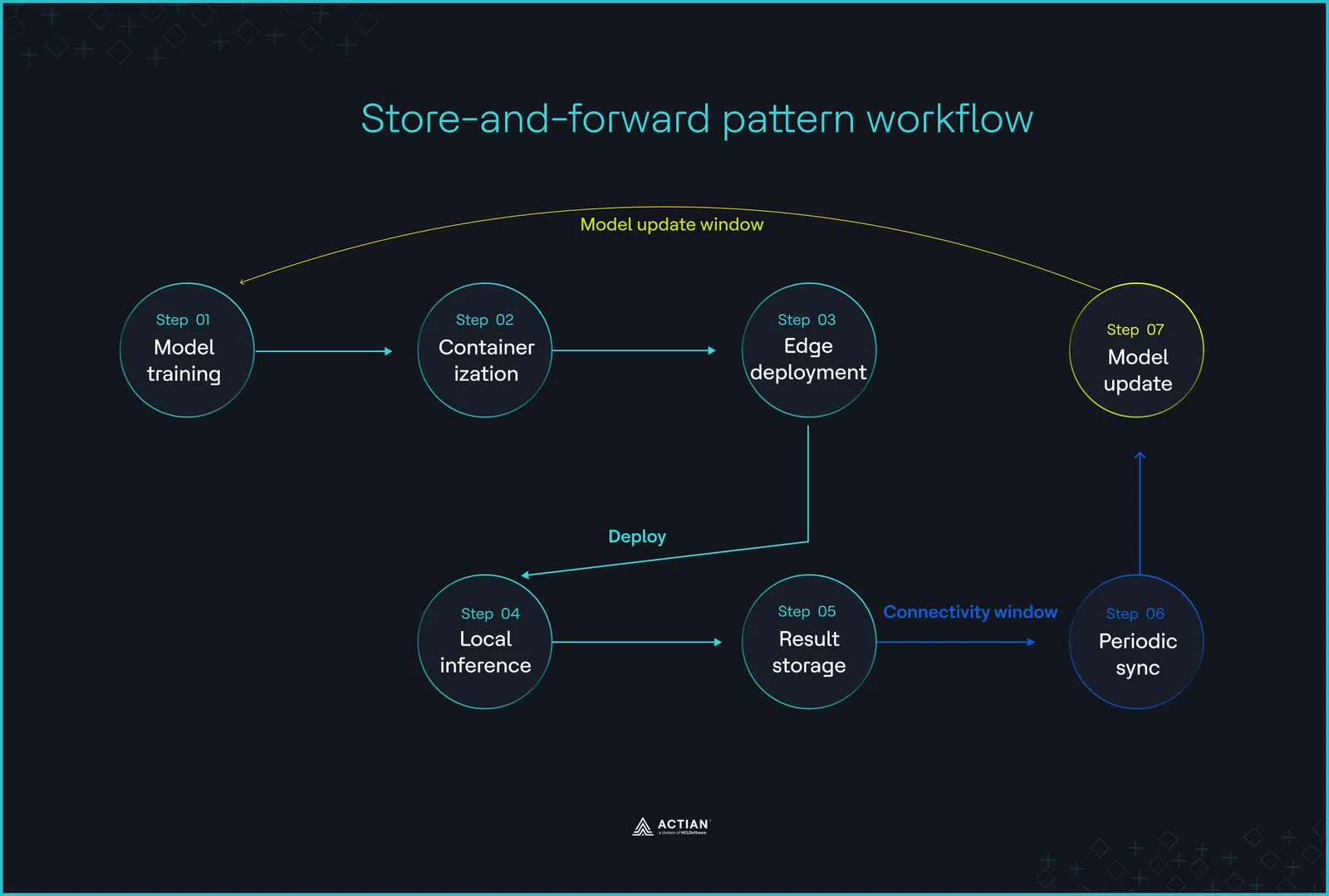
L'architecture « store-and-forward » crée une boucle de rétroaction qui empêche la perte de données en cas de déconnexion. Dans les usines de fabrication, les systèmes SCADA continuent de collecter des données provenant des automates programmables (PLC), des unités terminales distantes (RTU) et des passerelles périphériques jusqu'à ce que la connexion soit rétablie.
Lorsque les données sont enfin transférées
La partie « frontale » de cette architecture s'appuie sur des protocoles de communication légers tels que le Message Queuing Telemetry Transport (MQTT), conçus pour les réseaux instables et les environnements à bande passante limitée.
Le modèle de publication-abonnement de MQTT achemine les mises à jour mises en file d'attente depuis les passerelles périphériques vers le cloud via des brokers tels que Mosquitto. Les émetteurs (capteurs) envoient des messages vers un sujet (température), et les abonnés (serveurs cloud) reçoivent les messages correspondant aux sujets auxquels ils sont abonnés. Les messages sont diffusés dans l'ordre chronologique exact de leur réception.
L'extrait Python ci-dessous présente une implémentation de base utilisant la bibliothèque Paho MQTT. Il utilise la qualité de service (QoS) 1, une session persistante qui permet à Mosquitto de mettre les messages en file d'attente lorsque l'abonné est hors ligne.
# pip install paho-mqtt
import paho.mqtt.publish as publish
import sys
if len(sys.argv) < 3:
print("Usage: publisher.py <topic> <message>")
sys.exit(1)
# Production code will add retry logic, local queue persistence, and message deduplication
topic = sys.argv[1]
message = sys.argv[2]
publish.single(topic, message, hostname="localhost", qos=1)
Pour lancer le transfert de données après la reconnexion, le script ci-dessous crée une session persistante à l'aide de clean_session=False et loop_forever().
import paho.mqtt.client as mqtt
import sys
if len(sys.argv) < 2:
print("Usage: subscriber.py <topic>")
sys.exit(1)
topic = sys.argv[1]
client_id = "test-client"
def on_connect(client, userdata, flags, rc):
print(f"Connected with result code {rc}")
client.subscribe(topic, qos=1)
def on_message(client, userdata, msg):
print(f"{msg.topic}: {msg.payload.decode()}")
client = mqtt.Client(client_id=client_id, clean_session=False)
client.on_connect = on_connect
client.on_message = on_message
client.connect("localhost", 1883, 60)
client.loop_forever()
L'architecture « store-and-forward » peut entraîner des incohérences dans la réplication des données lors de la synchronisation des passerelles. Le système nécessite une politique d'arbitrage, telle que « last-write-wins », qui applique les modifications en fonction de l'horodatage de chaque mise à jour. Lorsque les horodatages sont identiques, des structures de données telles que les types de données répliqués sans conflit (CRDT) fusionnent les copies afin d'obtenir un état final cohérent sur l'ensemble des passerelles périphériques.
La synchronisation delta améliore encore les performances des CRDT. Alors que jeu de données complète jeu de données se déclenche à chaque enregistrement , la synchronisation delta résout les conflits au niveau des propriétés, en ne traitant que les champs modifiés.
Modèle 5 : Le réseau (structure distribuée de bout en bout)
déploiement réseau remédie au manque de tolérance aux pannes et de traitement distribué qui caractérise les opérations multisites déconnectées, telles que les réseaux logistiques et les réseaux électriques intelligents.
La coordination des périphériques de périphérie répartis sur plusieurs sites via un système cloud entraîne rapidement une perte de couverture réseau. C'est pourquoi l'architecture réseau suit un modèle de communication est-ouest, permettant aux nœuds de périphérie d'échanger des données directement avec leurs pairs sans coordination centrale.
La communication en maillage permet une intelligence distribuée
déploiement du réseau repose sur une architecture non hiérarchique, reliant plusieurs appareils IoT via un réseau maillé afin d'améliorer la disponibilité du système en cas de panne. Chaque nœud communique de manière dynamique avec ses voisins, formant ainsi un réseau bidirectionnel qui achemine les données vers des environnements distants via des chemins à plusieurs sauts.
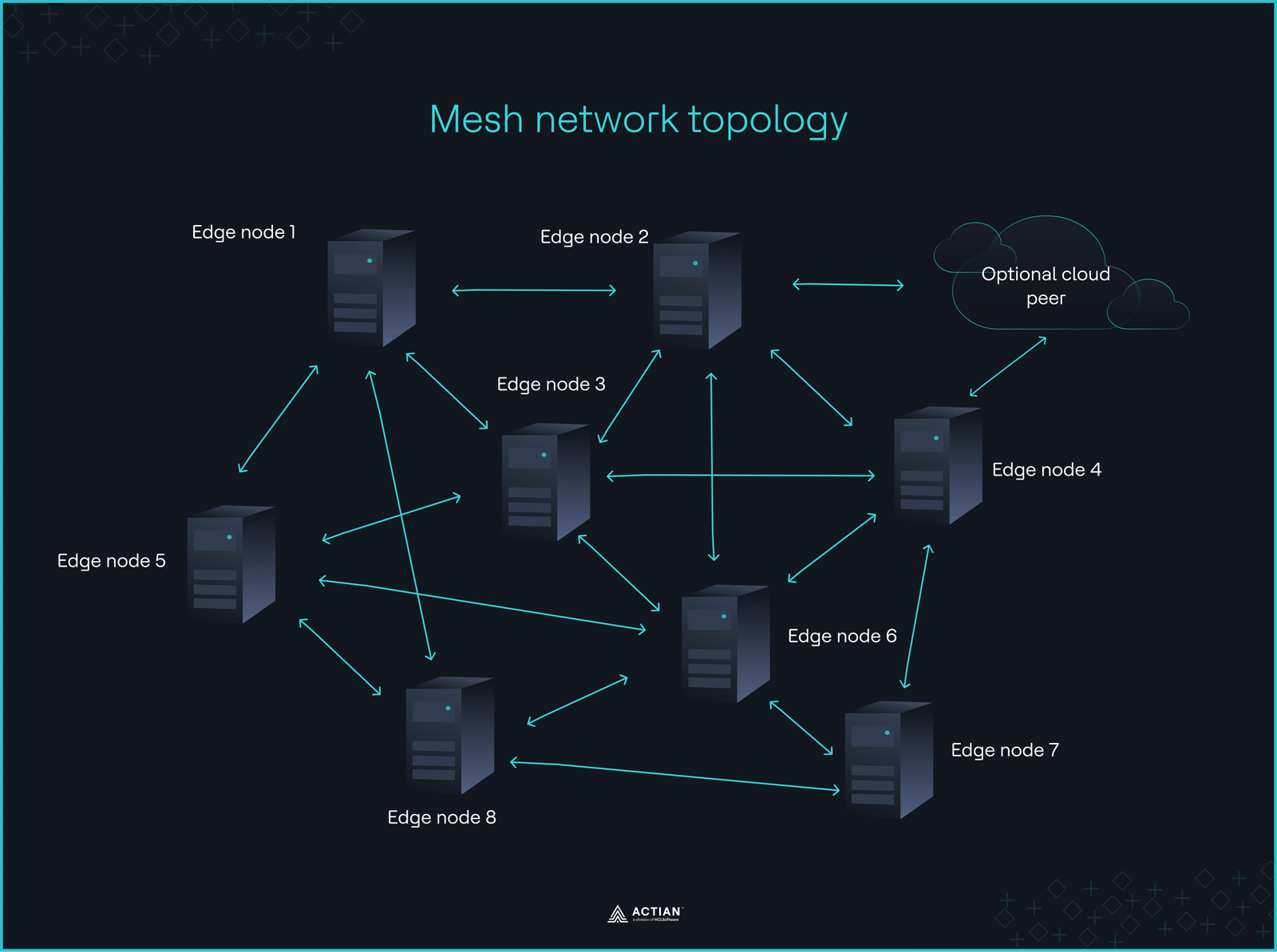
Le cloud ne se connecte qu'en tant que pair pour une synchronisation facultative, mais le cœur du traitement reste sur le réseau et fonctionne sans contrôle centralisé.
Les réseaux intelligents sont parfaitement adaptés à cette architecture, où la téléprotection exige un temps de latence de 10 à 20 ms. Un réseau de postes de transport suit en permanence, en temps réel, les flux d'électricité et les schémas de consommation afin de détecter les déséquilibres avant qu'ils ne s'aggravent. Cette visibilité en temps réel permet une redistribution dynamique de la charge et une gestion autonome des micro-réseaux.
Les drones militaires constituent cas d'usage autre cas d'usage. Lorsque le GPS ne fonctionne pas dans des environnements DDIL, les drones se transmettent mutuellement des données ISR via des réseaux maillés. Le routage adaptatif des interférences garantit un flux de données fiable, tandis que la transmission en ligne de visée réduit la latence.
Ce déploiement est optimisé pour assurer la redondance du réseau. Le protocole Gossip et les algorithmes de consensus distribués tels que Raft éliminent les points de défaillance uniques. Lorsqu'un nœud perd la connexion, le réseau reste opérationnel et achemine ses données via d'autres nœuds.
Le protocole Gossip permet la découverte en temps réel des pairs grâce à des échanges d'informations continus et légers. Chaque nœud dispose en permanence d'une vue actualisée de son réseau local. Raft suit une approche basée sur un leader, dans laquelle un nœud leader élu gère toutes les écritures, tandis que la réplication du journal garantit que les nœuds suiveurs maintiennent un état partagé. Les bases de données en périphérie répliquent les données sur plusieurs nœuds afin d'améliorer cohérence.
Considérer Gossip et Raft comme des options concurrentes revient à passer à côté de l'essentiel. Il convient plutôt de s'attacher à comprendre la place de chacun dans le théorème CAP et les compromis qu'ils impliquent pour un réseau distribué.
Le compromis cohérence et disponibilité
Lorsque des partitions réseau fragmentent le maillage, Raft garantit cohérence forte des données, tandis que Gossip offre une solution de secours en matière de disponibilité et cohérence éventuelle cohérence est associé à des approches telles que les CRDT.
Dans le domaine de l'edge computing, où la connectivité est limitée et les nœuds nombreux, la tolérance aux pannes est une exigence incontournable. Les systèmes d'IA en périphérie doivent choisir entre privilégier cohérence la disponibilité lors de la mise en œuvre de l'architecture réseau.
La disponibilité est souvent optimale, car les nœuds périphériques continuent de fonctionner de manière autonome après la déconnexion. Les architectures cohérence, comme Raft, s'exposent à des suspensions d'écriture et à des lectures obsolètes en cas de partition du réseau.
| Fonctionnalités | Radeau | Potins |
| Architecture | Élection du leader et réplication du journal | De pair à pair |
| Latence | Modéré ; nécessite qu'au moins un quorum de nœuds du réseau soit disponible | Faible ; les messages circulent rapidement, mais les cycles de propagation peuvent ralentir la vitesse |
| cohérence | cohérence grande cohérence | cohérence finale |
| Tolérance aux pannes | Modéré ; risque de ne pas résister à une partition | Élevé ; accélère la réparation des partitions |
Speed and data delivery trade-offs are another critical constraint of the network architecture. Mesh networking adds latency with each hop as the node count increases. If your system needs data back in <50ms or your latency requirements can tolerate >100ms, this trade-off should shape your design decision.
Choisir le bon déploiement de l'IA en périphérie
Il n'existe pas déploiement « idéal » pour l'IA en périphérie dans les environnements hors réseau. Une mise en œuvre solide de l'architecture commence par une compréhension claire des contraintes, des objectifs et des caractéristiques spécifiques de votre application cible. Cela implique d'envisager l'ensemble charge de travail , y compris le profil de connectivité, ressources de calcul disponibles et les exigences en matière de latence.
1. Évaluer la stabilité du réseau
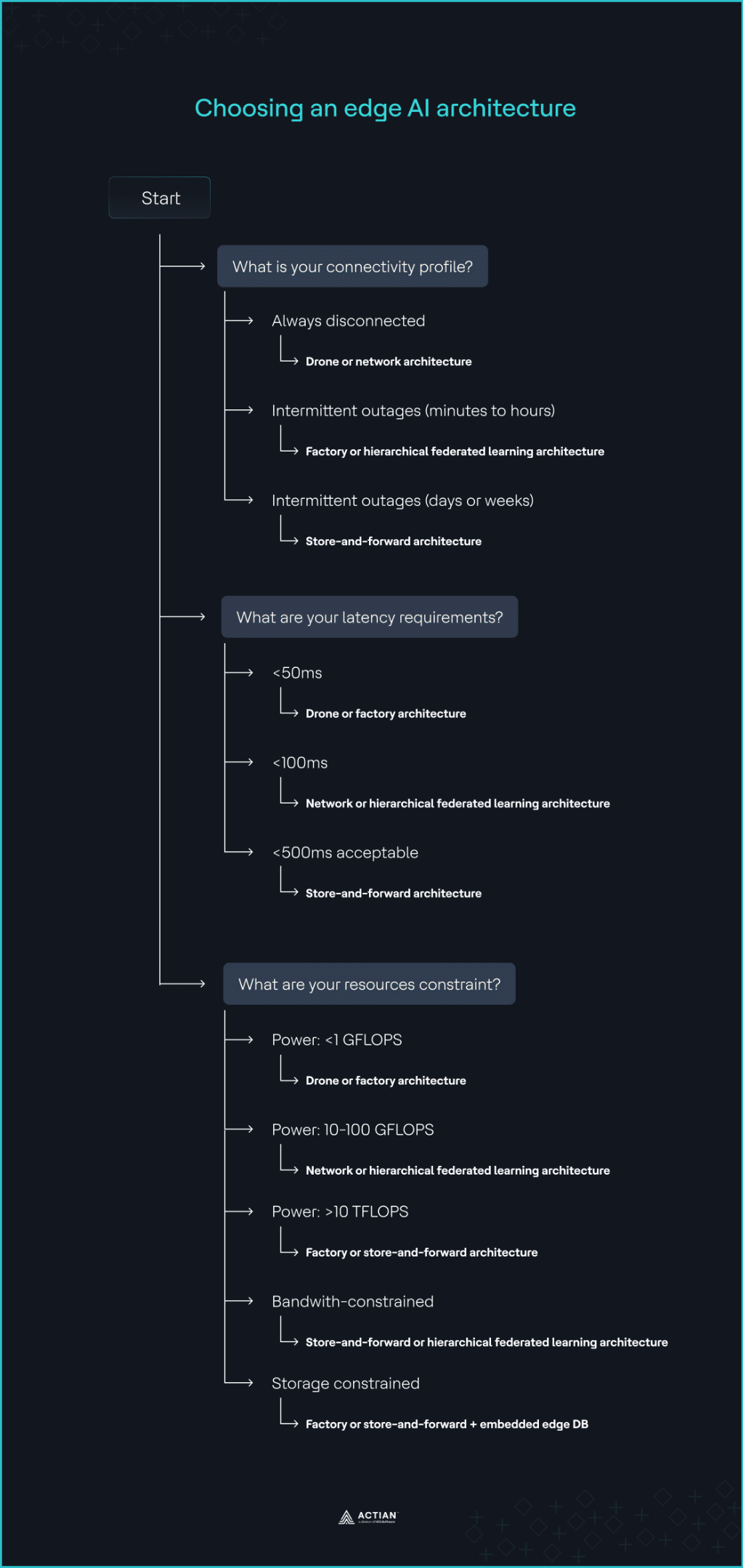
La stabilité du réseau est le facteur déterminant de toute déploiement de l'IA en périphérie. Déterminez le niveau de résilience à intégrer dans les nœuds périphériques en fonction de la durée prévue de la déconnexion.
- Si le système est toujours hors ligne : utilisez des architectures de type « drone » ou en réseau, car elles sont conçues pour fonctionner entièrement hors ligne, quel que soit l'état de la connexion.
- Si l'interruption ne dure que quelques minutes ou quelques heures : utilisez l'architecture d'usine ou l'architecture HFL pour poursuivre l'agrégation des données et l'inférence sans interruption. Le système reste opérationnel pendant la panne, car toutes les dépendances nécessaires existent déjà au sein du périmètre opérationnel.
- Si les interruptions de connexion durent plusieurs jours ou plusieurs semaines : utilisez l'architecture « store-and-forward » pour mettre en mémoire tampon localement les résultats d'inférence et les données opérationnelles jusqu'à ce que la fenêtre de connexion prévue soit à nouveau disponible.
2. Évaluer les exigences en matière de latence
Déterminez la latence maximale acceptable pour votre application en tenant compte des sauts de réseau, de la disponibilité des nœuds et de la proximité géographique des nœuds périphériques. Les seuils indiqués ci-dessous correspondent à déploiement courants. Vérifiez-les en fonction de votre matériel et de votre configuration réseau spécifiques.
- If the system requires <50ms latency: Use the drone deployment pattern. Its single-node architecture keeps inference directly on sensors, cameras, or gateways, enabling near-real-time responses. Factory architecture also minimizes latency by running on edge servers within the same facility or on the factory floor.
- If the system requires <100ms latency: Use the network or HFL architecture to distribute model improvement workloads across multiple nodes.
- If <500ms latency is acceptable: Use store-and-forward architecture for non-critical IoT data that requires batch processing or long-term analytics. It batch-offloads data-intensive tasks to the cloud.
3. Évaluer les contraintes en matière de ressources
Les applications d'IA en périphérie varient en termes de puissance de traitement, de capacité de stockage et de consommation de bande passante, ce qui a une incidence sur la vitesse d'inférence, l'agrégation analyses des données en temps réel données et analyses des données en temps réel. Évaluez chaque limite de ressource séparément :
- Power constraint: For compute power <1 GFLOPS, common in microcontrollers used for sensor inference, the drone architecture is most suitable. It runs on constrained IoT devices using lightweight, inference-only models. At 10–100 GFLOPS, common in edge gateways, HFL and network architectures become more effective as they handle data aggregation needs well at this level. For edge GPU clusters that scale to >10 TFLOPS, factory and store-and-forward architecture support clustered inference pipelines, since they run on-premises.
- Limitation de bande passante : utilisez une architecture de stockage et de retransmission ou le protocole HFL pour stocker et traiter les données brutes en grand volume en périphérie, en ne transmettant au cloud que les mises à jour synthétiques si nécessaire.
- Contrainte de stockage des données : utilisez des architectures de type « factory » ou « store-and-forward » associées à Embarqué pour stocker localement les données chronologiques et évoluer verticalement au sein de l'installation. Des bases de données telles qu'Actian Zen sont optimisées pour les cas d'utilisation de l'IA en périphérie et peuvent également se synchroniser avec le cloud une fois la connectivité rétablie.
4. Envisager une approche hybride
Les systèmes industriels combinent souvent les atouts de plusieurs architectures au sein d'un système coordonné qui offre résilience et flexibilité. Les activités minières de Rio Tinto illustrent ce à quoi déploiement hybride à grande échelle.
À la mine de minerai de fer de Greater Nammuldi, plus de 50 camions autonomes circulent sur des itinéraires prédéfinis, utilisant des capteurs embarqués pour détecter les obstacles, ce qui illustre l'architecture de type « drone ». Répartis sur 17 sites en Australie-Occidentale, ces camions transmettent des données opérationnelles au centre d'opérations de Rio Tinto à Perth, ce qui reflète l'architecture de réseau. Enfin, un système ferroviaire autonome transporte le minerai extrait, en se synchronisant avec le centre d'opérations à son arrivée aux installations portuaires. Cela correspond à l'architecture de type « stockage et retransmission ».
Rio Tinto démontre que déploiement ne s'excluent pas mutuellement. Si votre cas d'usage plusieurs architectures, envisagez de les déployer au niveau du système qui leur convient le mieux, plutôt que d'imposer une architecture unique à l'ensemble de l'opération.
Le tableau ci-dessous met en correspondance différents déploiement avec leur déploiement optimal déploiement d'IA en périphérie hors connexion, afin de vous aider à prendre une décision.
| déploiement | Modèle recommandé | Justification |
| Drones d'inspection autonomes au-dessus des champs pétroliers ou des parcs éoliens offshore | Drone (système autonome à nœud unique) | Un moteur d'inférence autonome doté d'un stockage Embarqué élimine le calcul distribué pour s'adapter aux contraintes matérielles |
| Chaînes de montage automobiles équipées de systèmes de détection des défauts | Usine (IA en périphérie à plusieurs nœuds) | Le recours au cloud présente un risque trop élevé au regard des exigences de disponibilité ; c'est pourquoi les clusters en périphérie sont exploités au sein même du site |
| Réseaux hospitaliers dans lesquels les données des patients ne peuvent pas sortir des établissements individuels, conformément à la loi HIPAA | Apprentissage fédéré hiérarchique | Les modèles entraîner , seules les mises à jour des poids étant transmises au cloud, de sorte que les données brutes restent sur le site local, conformément aux principes de souveraineté des données et de confidentialité |
| Les navires de transport de marchandises en mer synchronisent leurs données opérationnelles au port | Stockage et retransmission | Une mémoire tampon locale garantit qu'aucun résultat d'inférence ni aucun événement opérationnel n'est perdu lors d'interruptions de connexion pouvant durer plusieurs jours |
| Gestion intelligente du trafic urbain sur des carrefours dispersés, sans dépendance vis-à-vis d'un serveur central | Réseau (structure distribuée de bout en bout) | Les nœuds communiquent entre eux en peer-to-peer par le biais d'un consensus ; ainsi, la perte d'un nœud réduit la capacité sans perturber le fonctionnement global du réseau |
Le bilan
Les secteurs d'activité opérant dans des environnements isolés, souterrains, maritimes ou géographiquement dispersés ont besoin d'architectures natives de la périphérie qui permettent de collecter informations en temps réel d'assurer le bon fonctionnement des ressources critiques sans dépendre du cloud.
déploiement évoqués privilégient les aspects les plus importants dans les environnements déconnectés : l'inférence locale, l'absence de latence liée à la centralisation, la réduction des coûts de communication et l'autonomie du système.
Avant de vous engager sur un modèle, vérifiez trois éléments dans votre propre environnement : combien de temps votre système peut supporter une interruption du réseau avant que la perte de données n'ait un impact significatif sur les opérations ; si votre matériel en périphérie est capable de répondre aux exigences de calcul de l'architecture choisie sans nuire à la qualité de l'inférence ; et si votre équipe dispose des outils nécessaires pour gérer le cycle de vie du modèle en périphérie sans dépendre du cloud. Évaluez vos contraintes à l'aune du cadre décisionnel présenté ci-dessus.
La bonne réponse n'est peut-être pas un modèle unique. Il ne faut adopter des approches hybrides que lorsque les gains en matière de résilience justifient la complexité opérationnelle.
Chaque modèle repose sur une infrastructure de données capable de fonctionner, de stocker et de synchroniser l'intégralité des données en périphérie. Pour les équipes qui souhaitent aller au-delà du stockage structuré et effectuer des recherches sémantiques sur leurs données locales sans exporter les représentations vectorielles vers un serveur cloud, Actian VectorAI DB est optimisé pour ce cas d'usage. Inscrivez-vous sur la liste d'attente pour bénéficier d'un accès anticipé.
Rejoignez la communauté Actian sur Discord pour discuter des modèles d'architecture d'IA en périphérie avec des ingénieurs qui déploient leurs solutions dans des environnements hors réseau.

Restez connecté
Des informations exploitables à votre disposition.
(par exemple, sales@..., support)