Intégration d'Actian Zen et d'Apache Kafka à l'aide de Kafka Connect (JDBC)




Résumé
- Créez un pipeline de données financières en temps réel pipeline de données streaming les données streaming Zen vers Apache Kafka à l'aide des connecteurs JDBC Source et Sink.
- Les tables sources en mode « ajout uniquement » et les opérations « upsert » idempotentes permettent streaming d'événements financiers faible latence, reproductible et prêt pour l'audit.
- Avro, associé au registre de schémas, garantit gouvernance rigoureuse des schémas gouvernance une évolution sécurisée des charges de travail financières.
- Cette architecture modernise les systèmes par lots en les transformant en architectures streaming, sans pour autant remplacer les bases de données opérationnelles.
Les systèmes financiers modernes ne reposent plus sur des traitements par lots effectués pendant la nuit ni sur des tâches ETL périodiques. Les moteurs de tarification, les systèmes de saisie des transactions, les tableaux de bord de gestion des risques et plateformes de conformité dépendent plateformes de flux continus d'événements qui doivent être traités avec une faible latence, une grande fiabilité et observabilité totale.
Parallèlement, de nombreuses entreprises s'appuient déjà sur des bases de données opérationnelles éprouvées pour stocker leurs données transactionnelles et faire fonctionner leurs applications stratégiques. Le remplacement de ces systèmes n'est que rarement envisageable.
Ce guide technique explique comment Actian Zen et Apache Kafka peuvent fonctionner ensemble pour former un pipeline de donnéesen temps réel robuste, sans réécrire les applications ni introduire de code personnalisé complexe. À l'aide des connecteurs source et récepteur JDBC de Kafka Connect, nous transmettons en continu des données de type transactions financières depuis Zen vers Kafka, puis de nouveau vers Zen, créant ainsi un modèle architectural réutilisable adapté aux charges de travail financières réelles.
Pourquoi Streaming dans le secteur financier ?
Les données financières présentent un ensemble de caractéristiques qui leur sont propres :
- Urgence: Des données obsolètes peuvent invalider les décisions.
- Caractère sporadique: L'ouverture et la clôture des marchés ainsi que la volatilité génèrent des pics.
- Correctitude stricte: Les doublons ou les événements manquants ne sont pas acceptables.
- Traçabilité: Les équipes doivent pouvoir revenir sur leurs décisions passées et les expliquer.
Les architectures par lots traditionnelles peinent à répondre à ces exigences. En revanche, streaming traitent chaque enregistrement un événement immuable et permettent aux systèmes en aval de réagir en en temps réel.
Kafka est devenu la pierre angulaire des axé sur des événements , mais à lui seul, Kafka ne résout pas le problème de l'intégration des bases de données. Kafka Connect comble cette lacune en transférant les données entre les bases de données et Kafka à l'aide de configurations plutôt que de code personnalisé.
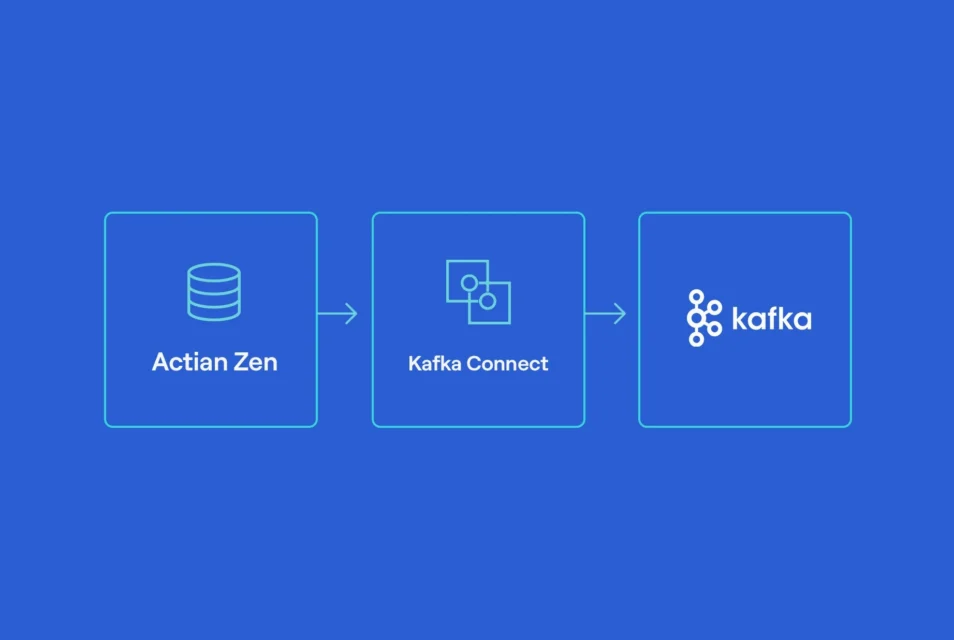
Ce que nous construisons
Ce pipeline montre comment des données de type financier peuvent être transmises en continu depuis une base de données Zen opérationnelle vers Kafka, puis réécrites dans une table Zen en aval à l'aide des connecteurs JDBC Source et Sink :
Le déroulement est le suivant :
- Un Python génère des données boursières synthétiques.
- Chaque donnée est enregistrée dans une table source Zen (FinanceSource).
- Un connecteur source JDBC de Kafka Connect lit les nouvelles lignes de manière incrémentielle.
- Les enregistrements sont publiés sur Kafka sous forme de messages Avro (le registre de schémas gère les schémas).
- Un connecteur de destination JDBC Kafka Connect traite le sujet.
- Les enregistrements sont insérés ou mis à jour dans une table de destination Zen (Finance).
Ce modèle s'applique directement à ingestion de données de marché, à la réplication des transactions, à streaming et au reporting opérationnel.
Un aperçu de l'architecture
D'un point de vue général, l'architecture comporte trois couches :
- Génération de données et stockage opérationnel: Actian Zen stocke les données de cotation entrantes.
- Streaming : Kafka fournit un journal d'événements durable et rejouable.
- Intégration et livraison: Kafka Connect lit les données depuis Zen et les réécrit dans Zen.
Un principe clé de conception est le découplage : les producteurs ne dépendent pas des consommateurs, et la base de données reste le système enregistrement.
La conception de modèles de données en pratique
La conception du schéma est fondamentale. Cette démonstration utilise deux tables Zen dont les rôles sont clairement définis :
Table source : FinanceSource (en écriture seule)
CREATE TABLE FinanceSource ( id IDENTITY PRIMARY KEY, symbol VARCHAR(16) NOT NULL, trade_date DATE NOT NULL, trade_time TIME NOT NULL, price DECIMAL(18,6) NOT NULL, volume INTEGER NOT NULL, bid DECIMAL(18,6), ask DECIMAL(18,6), exchange VARCHAR(16), currency VARCHAR(8) DEFAULT 'USD', date_enregistrement TIMESTAMP NOT NULL );
Deux colonnes revêtent une importance particulière pour streaming:
- id fournit un curseur incrémental stable.
- recorded_at fournit l'heure de l'événement et permet des lectures incrémentielles sécurisées.
Tableau récapitulatif : Finances (situation actuelle)
CREATE TABLE Finance ( id INTEGER PRIMARY KEY, symbole VARCHAR(16), date_transaction DATE, heure_transaction TIME, prix DECIMAL(18,6), volume INTEGER, bid DECIMAL(18,6), ask DECIMAL(18,6), exchange VARCHAR(16), currency VARCHAR(8), recorded_at TIMESTAMP );
L'évier utilise id comme clé primaire, ce qui permet des mises à jour idempotentes lors de la relecture ou du redémarrage.
Générer des ticks boursiers avec Python
Le générateur simule un flux de données boursières en temps réel en insérant une nouvelle enregistrement deux secondes. Chaque événement comprend le symbole, le cours, les cours acheteur/vendeur, le volume, la bourse, la devise et les horodatages.
La fonction génératrice produit des données de marché réalistes :
def gen_tick(): symbol = random.choice(SYMBOLS) price = round(random.uniform(10, 1500), 6) spread = round(random.uniform(0.01, 0.50), 6) bid = round(price - spread/2, 6) ask = round(price + spread/2, 6) vol = random.randint(1, 5000) now = datetime.now() return { "symbol": symbol, "trade_date": date.today(), "trade_time": now.time().replace(microsecond=0), "price": price, "volume": vol, "bid": bid, "ask": ask, "exchange": random.choice(EXCHANGES), "currency": CURRENCY, "recorded_at": now, }
Instruction INSERT :
sql = """ INSERT INTO FinanceSource ( symbole, date_transaction, heure_transaction, cours, volume, cours_acheteur, cours_vendeur, bourse, devise, heure_enregistrement ) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?) """
Cette approche en ajout seul convient parfaitement à Kafka : chaque ligne est un événement immuable qui peut être diffusé en continu, rejoué et consommé par plusieurs services en aval.
Streaming vers Kafka à l'aide du connecteur source JDBC
Le connecteur source JDBC de Kafka Connect interroge FinanceSource et publie des messages vers Kafka.
Cartographie thématique :
- Nom du connecteur : demo-finance-source
- Préfixe du sujet : finance.
- Thème : finance.FinanceSource
Mode incrémental :
"mode" : "timestamp+incrementing", "timestamp.column.name" : "recorded_at", "incrementing.column.name" : "id", "poll.interval.ms" : "2000"
Ce mode lit uniquement les nouvelles lignes, évite les balayages complets et prend en charge les redémarrages en toute sécurité. Une interrogation toutes les deux secondes permet de maintenir une faible latence sans ajouter de charge inutile. Cette fréquence d'interrogation permet également d'équilibrer la latence et la charge pour les charges de travail de démonstration et modérées ; en production, elle doit être ajustée en fonction de la fréquence d'insertion des lignes et de la capacité de la base de données.
Configuration complète du connecteur source :
"connector.class" : "io.confluent.connect.jdbc.JdbcSourceConnector", "connection.url" : "jdbc:pervasive://host.docker.internal:1583/DEMODATA", "dialect.name": "ZenDatabaseDialect", "mode": "timestamp+incrementing", "timestamp.column.name": "recorded_at", "incrementing.column.name": "id", "table.whitelist": "FinanceSource", "topic.prefix": "finance.", "poll.interval.ms": "2000", "value.converter": "io.confluent.connect.avro.AvroConverter"
Avro et le registre de schémas pour gouvernance des schémas
Les schémas financiers évoluent : de nouveaux indicateurs, de nouveaux identifiants ou des niveaux de précision ajustés entrent en jeu. Avro, associé au registre de schémas, offre un typage fort, une gestion centralisée des versions et des contrôles de compatibilité.
Configuration des connecteurs :
"value.converter" : "io.confluent.connect.avro.AvroConverter", "value.converter.schema.registry.url" : "http://schema-registry:8081"
Avec cette configuration, les schémas sont enregistrés automatiquement et les utilisateurs peuvent évoluer en toute sécurité au fil du temps. Le registre de schémas n'est nécessaire que lors de l'utilisation d'Avro (ou de Protobuf/JSON Schema) ; les convertisseurs JSON peuvent être utilisés pour des démonstrations plus légères, au détriment de gouvernance des schémas.
De Kafka vers Zen avec le connecteur de destination JDBC (Upsert)
Le connecteur Sink traite le sujet Kafka et écrit les données dans la table Finance.
Configuration d'Upsert :
"topics" : "finance.FinanceSource", "table.name.format" : "Finance", "insert.mode" : "upsert", "pk.mode" : "enregistrement", "pk.fields" : "id", "auto.create" : "false", "auto.evolve" : "true"
Upsert est un choix par défaut judicieux, car les redémarrages et les relectures restent idempotents, et les corrections apportées a posteriori peuvent mettre à jour les clés existantes.
déploiement orchestration
Tous les composants Kafka s'exécutent dans Docker : le broker Kafka, le registre de schémas, Kafka Connect et l'interface utilisateur Kafka (compatible avec Kafbat / AKHQ). Actian Zen s'exécute sur l'hôte.
Un seul script d'orchestration démarre la pile, initialise les tables, crée les connecteurs et lance le générateur. Ce modèle de « démonstration en une seule commande » est utile pour apprentissage, les preuves de concept et les tests reproductibles.
Points de contrôle généralement utilisés lors de la validation :
- Interface utilisateur de Kafbat : http://localhost:8080
- Kafka Connect REST : http://localhost:8083
- Registre de schémas : http://localhost:8081
Validation opérationnelle
Pour valider le flux de bout en bout :
- Vérifiez que le générateur affiche de nouvelles marques toutes les deux secondes.
- Vérifier l'état du connecteur via l'interface REST de Kafka Connect.
- Consultez les messages dans la finance.FinanceSource .
- requête table Zen Finance.
Appels de statut :
curl http://localhost:8083/connectors/demo-finance-source/status curl http://localhost:8083/connectors/demo-finance-sink/status
En cas de problème, les journaux de Kafka Connect sont généralement le premier indicateur : fichiers JAR JDBC manquants, problèmes liés au dialecte ou difficultés d'authentification.
Considérations relatives à la production
Cette démonstration est volontairement simple, mais l'architecture est évolutive. En production, il convient de tenir compte des éléments suivants :
- TLS et authentification pour Kafka et Connect.
- Segmentation des sujets à des fins de parallélisme (par exemple, par symbole).
- Files d'attente de messages non livrables pour les enregistrements problématiques.
- Application de la compatibilité des schémas dans le registre de schémas.
- Clusters Multi-worker Connect pour un débit élevé et une grande résilience.
- Surveillance (Prometheus/Grafana).
Le modèle de base — source en mode « ajout uniquement » + interrogation incrémentielle + Avro + opérations d'insertion/mise à jour idempotentes vers le récepteur — reste une référence solide.
Découvrez le guide visuel
Les captures d'écran suivantes montrent le pipeline en action, depuis la génération des données jusqu'à la table de destination finale, en passant par Kafka :
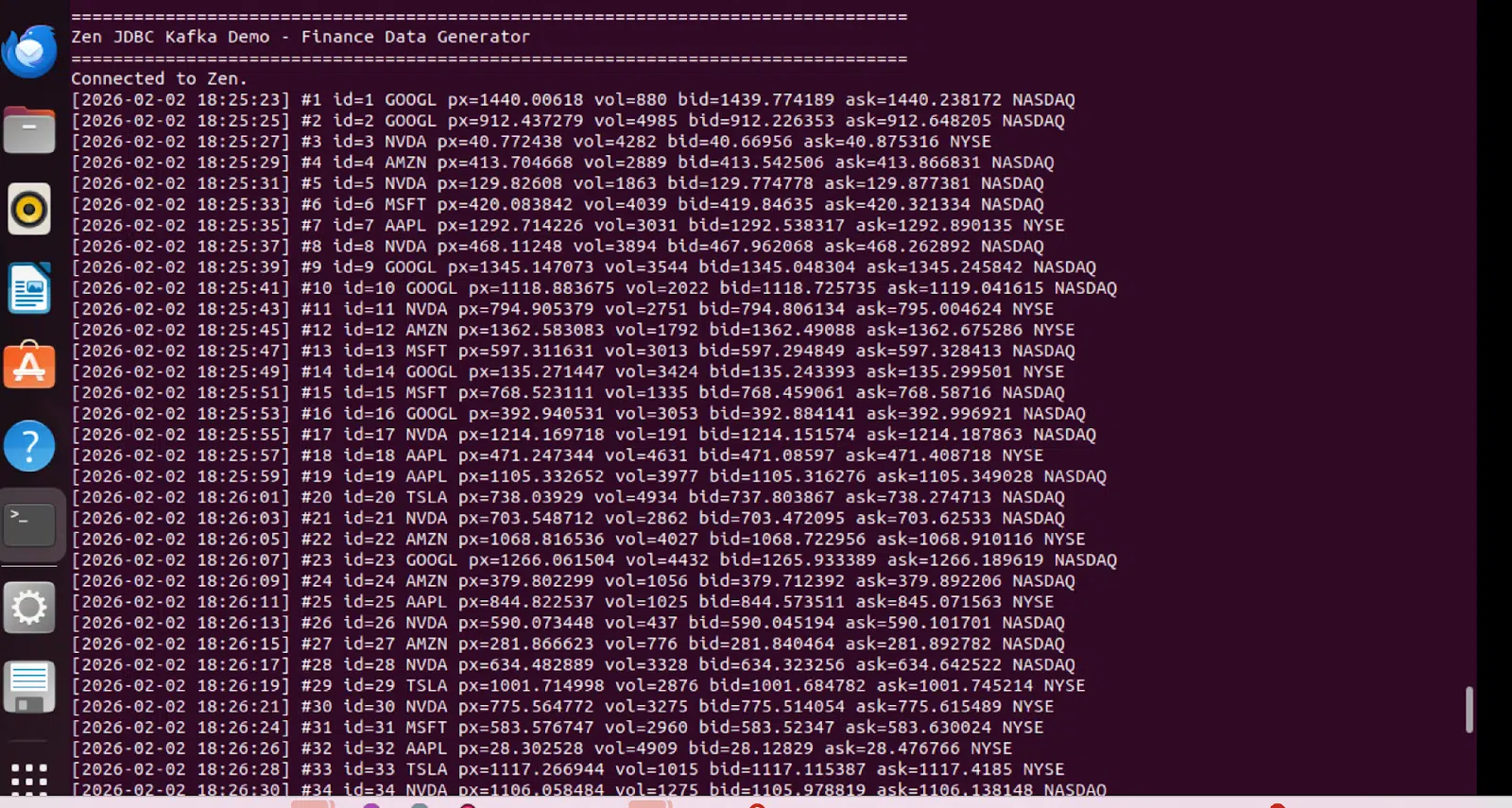
Sortie du générateur de données
Python produit en continu des ticks boursiers synthétiques toutes les deux secondes, simulant ainsi les données de marché en temps réel :
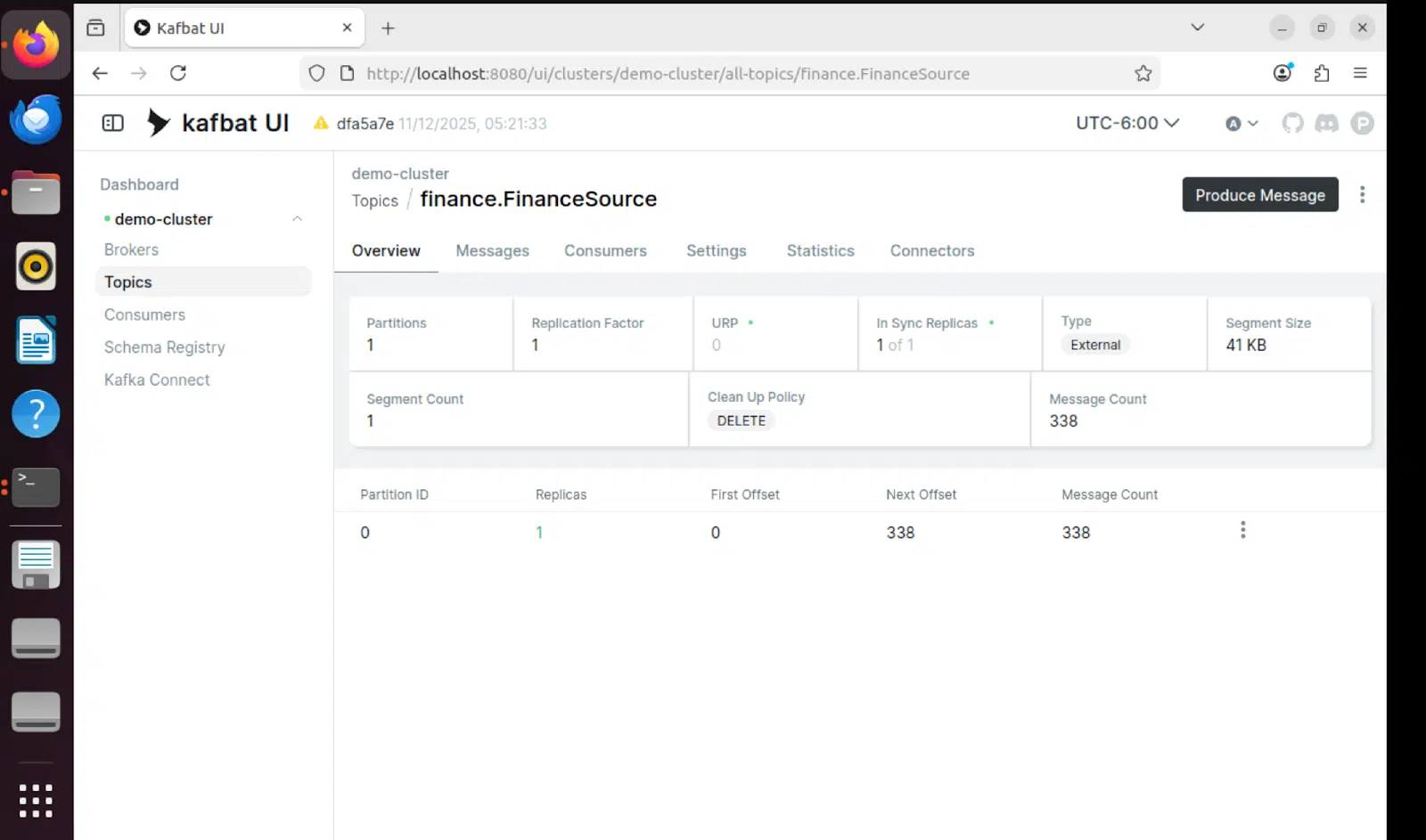
Interface utilisateur de Kafbat – Affichage par sujet
L'interface utilisateur Kafbat offre une visibilité en temps réel sur les sujets Kafka, en affichant les messages transitant par le pipeline :
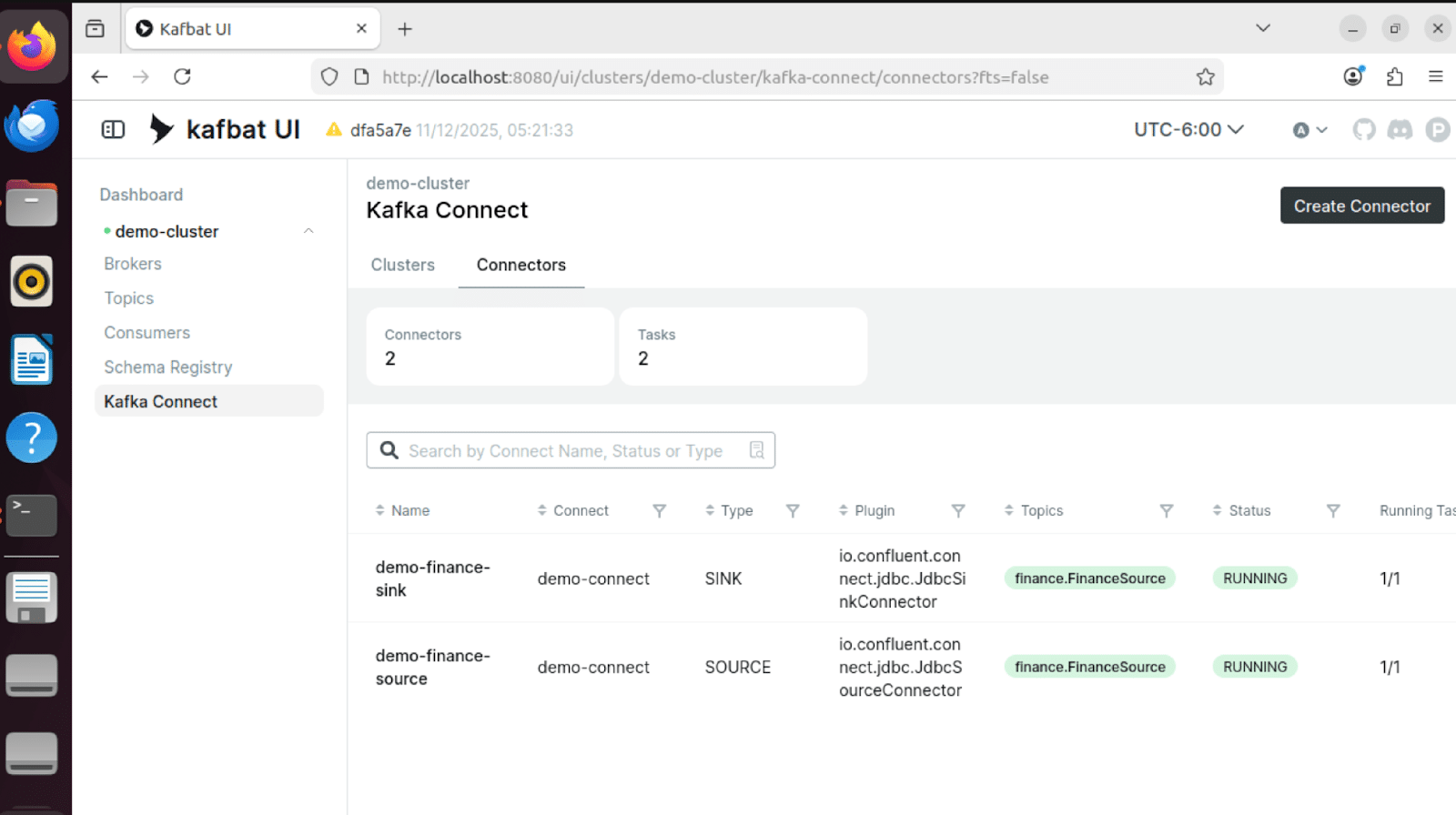
État du connecteur
Les connecteurs source et récepteur affichent tous deux l'état « RUNNING », ce qui confirme que le pipeline est opérationnel :
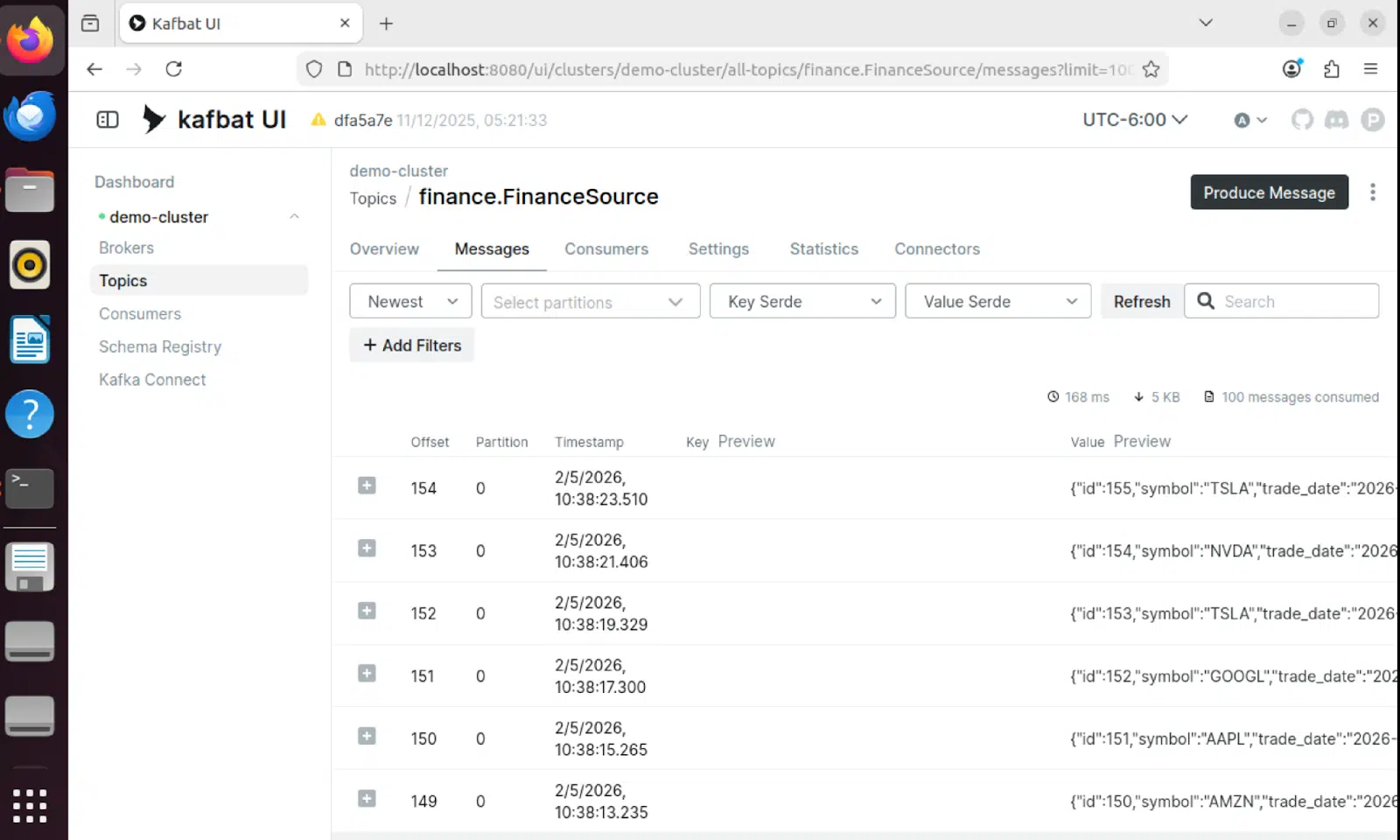
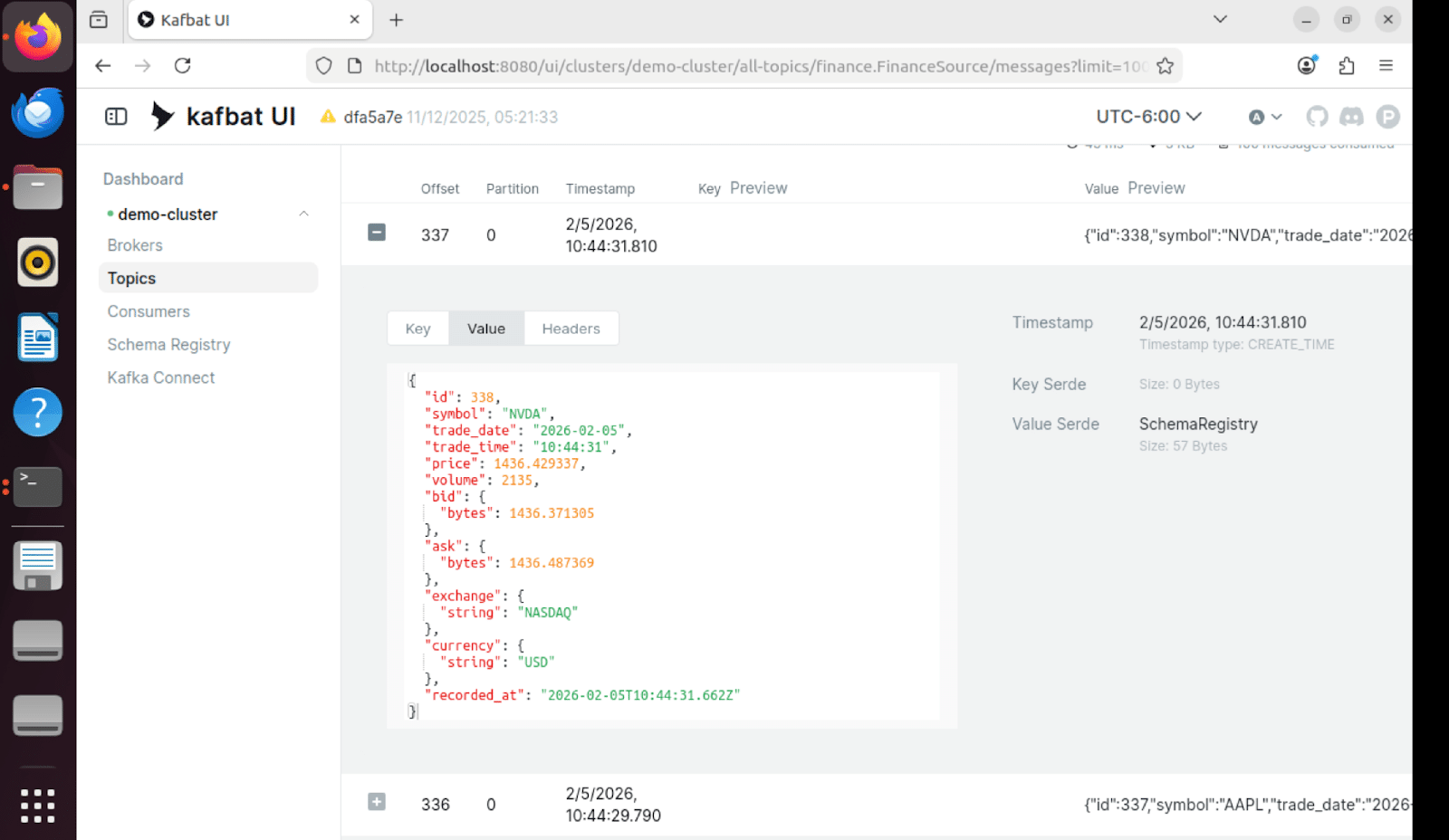
Contenu du message
Les messages individuels dans Kafka contiennent l'intégralité des données de cotation boursière au format Avro, avec gestion des versions du schéma :
Résultats du test de la table d'évier
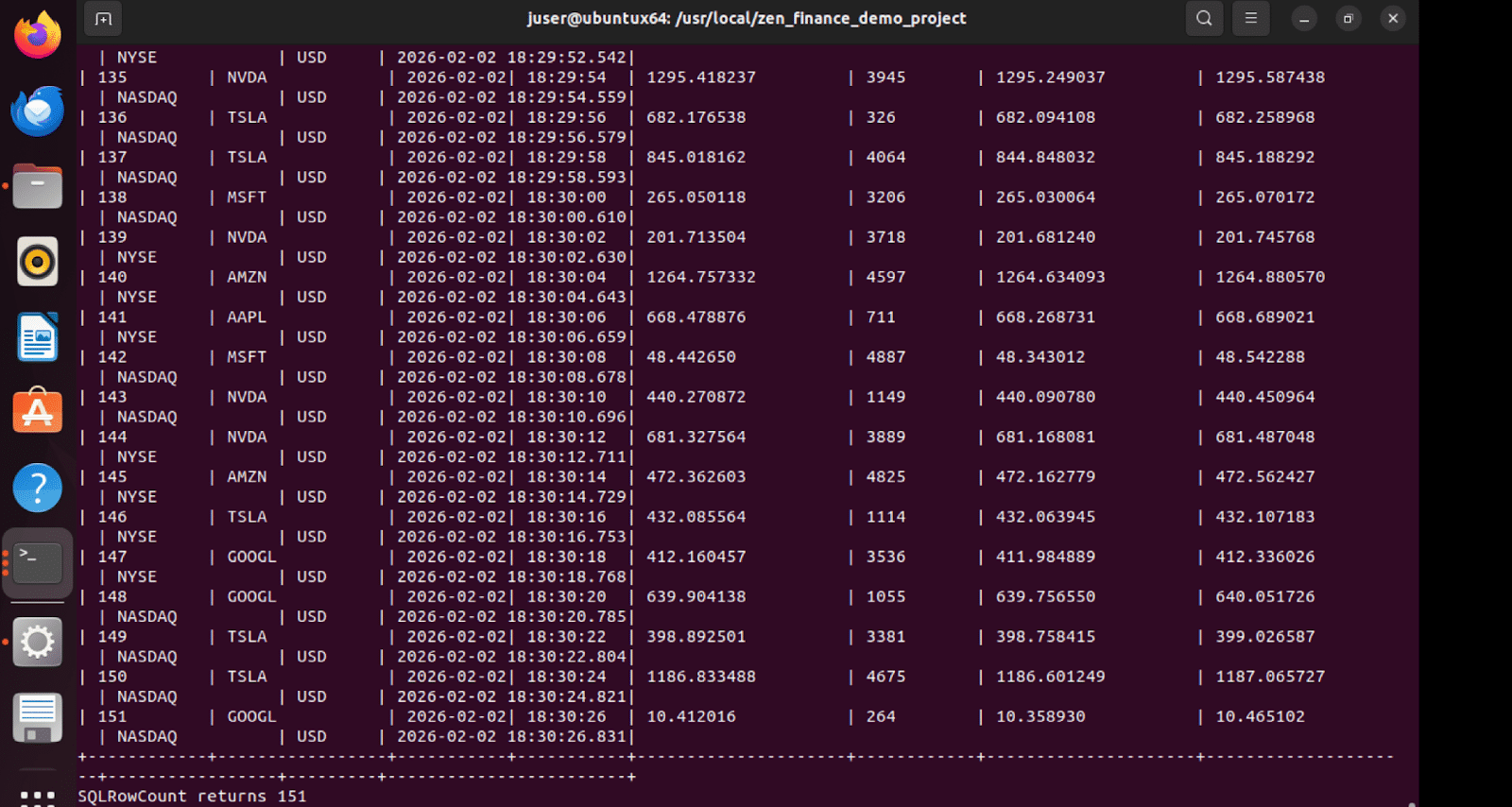
La table de collecte « Finance » dans Zen reçoit les données transmises en continu, ce qui prouve la réussite du flux de bout en bout.
Pour commencer
La démo comprend un script d'orchestration complet qui automatise l'ensemble du processus de configuration. Pour lancer la démo, il suffit d'exécuter un seul Python .
Démonstration du lancement en une seule commande
L'orchestrateur gère automatiquement cinq étapes clés :
- Démarrer la pile Docker Compose (Kafka, Schema Registry, Connect, interface utilisateur).
- Attendez que tous les services soient opérationnels (45 à 60 secondes).
- Initialiser les tables FinanceSource et Finance dans Zen.
- Créer et configurer des connecteurs source et de sortie JDBC.
- Lancez le générateur de données en arrière-plan.
Logique d'orchestration principale :
def run(self): # Étape 1 : Démarrer Docker Compose self.start_docker_compose() # Étape 2 : Attendre que les services soient opérationnels self.wait_for_services() # Étape 3 : Initialiser les bases de données self.initialize_databases() # Étape 4 : Configurer les connecteurs self.setup_connectors() # Étape 5 : Démarrer le générateur de données self.start_data_generator() # Afficher l'état et continuer l'exécution self.show_status()
Le script affiche des messages d'état clairs à chaque étape et effectue le nettoyage en cas d'interruption (Ctrl+C).
Initialisation de la table
Le script d'initialisation crée les deux tables avec les schémas appropriés et supprime les tables existantes afin de garantir un état vierge :
def create_finance_source(conn) : exec_sql(conn, "DROP TABLE IF EXISTS FinanceSource") create_sql = """ CREATE TABLE FinanceSource ( id IDENTITY PRIMARY KEY, symbol VARCHAR(16) NOT NULL, trade_date DATE NOT NULL, trade_time TIME NOT NULL, price DECIMAL(18,6) NOT NULL, volume INTEGER NOT NULL, bid DECIMAL(18,6), ask DECIMAL(18,6), exchange VARCHAR(16), currency VARCHAR(8) DEFAULT 'USD', recorded_at TIMESTAMP NOT NULL ) """ exec_sql(conn, create_sql)
Mettre en place et avantage un pipeline financier en temps réel
Cette solution présente une méthode concrète pour mettre en place un pipeline financier en temps réel à l'aide d'Actian Zen et de Kafka Connect :
- Zen stocke les données opérationnelles et fait office de système d'enregistrement.
- Kafka fournit un flux durable et réutilisable.
- Kafka Connect assure un transfert fiable des données grâce à sa configuration.
- Avro et le registre de schémas garantissent la sécurité des schémas.
- La table de consolidation fournit un état matérialisé pouvant faire l'objet de requêtes.
Pour les entreprises qui modernisent leurs flux de données financières, cette architecture offre une transition claire du traitement par lots vers des architectures streaming, sans pour autant renoncer aux investissements déjà réalisés dans les bases de données.
Pour en savoir plus, consultez notre blog série destinée à aider les développeurs Embarqué à se familiariser avec Actian Zen.

Restez connecté
Des informations exploitables à votre disposition.
(par exemple, sales@..., support)