Die 5 besten Python -Bibliotheken für Python





Zusammenfassung
- Probleme bei der Produktion in Vektordatenbanken sind häufig auf Unstimmigkeiten bei der Paketierung, den APIs und der Umgebung zurückzuführen – nicht auf die Geschwindigkeit.
- Die Client-Architektur (Cloud, OSS, eingebettet, Erweiterung) wirkt sich auf Scalability Deployment aus.
- Entscheidende Faktoren: API-Stabilität, Zuverlässigkeit bei der Installation, Unterstützung für asynchrone Vorgänge und übersichtliche Fehlerbehebung.
- Qdrant bietet eine hohe Übereinstimmung zwischen lokalen und Produktionsumgebungen; Pinecone vereinfacht Cloud .
- Die Actian VectorAI DB legt besonderen Wert auf Stabilität, Portabilität und Deployment unternehmensgerechte Deployment.
Most comparisons of Python vector database libraries focus on retrieval speed, indexing algorithms, or benchmark results. These metrics matter, but production failures stem from various factors: installation inconsistencies, client packaging differences, version churn, and unexpected API changes. In reality, a different class of problems appears once the application leaves the notebook environment and runs inside a production service.
Ein typisches Beispiel hierfür sind Konfigurationen mit eingebettet . Ein Projekt funktioniert während der Entwicklung möglicherweise einwandfrei, schlägt jedoch in der Produktion mit einer Fehlermeldung wie der folgenden fehl:
RuntimeError: Chroma running in http-only client modeEin struktureller Konflikt zwischen den chromadb und chromadb-client Das Paket löst diesen Fehler aus, da dem reinen Client-Paket die Standard-Einbettungsfunktionen fehlen, auf die die Anwendung angewiesen ist. Die Fehlerbehebung kann Stunden dauern.
Diese Art von Fehlern ist auf die Wahl der Client-Pakete und Entscheidungen beim Bibliotheksdesign zurückzuführen, nicht auf die Qualität der Suchergebnisse oder die Indizierungsleistung.
Dieser Artikel vergleicht die führenden Python unter diesem Gesichtspunkt und untersucht dabei die Client-Architektur, die Installationsstabilität, das API-Design und die langfristige Wartbarkeit, anstatt sich allein auf Benchmark-Ergebnisse zu stützen.
TL;DR
- ChromaDB: Schnellste Einrichtung für Prototyping- und Notebook-Umgebungen mit minimalem Konfigurationsaufwand.
- Pinecone:voll gemanagt Cloud ohne Aufwand für die Infrastrukturverwaltung.
- Qdrant: Keine Codeänderungen vom lokalen Entwicklungsumgebung bis zur Produktion; die beste Open-Source-Option für API-Stabilität.
- Weaviate: Hybride Suche, die Vektorähnlichkeit und Stichwortfilterung in großem Maßstab kombiniert.
- Actian VectorAI DB:On-Premises Deployment einheitlicher Architektur vom Laptop bis zur Produktion; Actian hat sie für Edge- und Air-Gapped-Umgebungen entwickelt.
Die Python : Die verschiedenen Optionen verstehen
Die Beziehung zwischen einer Python und ihrem Speicher-Backend bestimmt, wie Sie Ihre Anwendung entwickeln, testen und schließlich skalieren werden. Die Wahl der falschen Bibliothek führt häufig zu den oben beschriebenen umgebungsspezifischen Fehlern, da jede Architektur lokal und in der Produktionsumgebung unterschiedlich gehandhabt wird.
Diese Unterschiede lassen sich im Allgemeinen in vier verschiedene Kategorien einteilen, von denen jede einen eigenen Ansatz für das Zusammenspiel zwischen Infrastruktur und Code verfolgt.
Vier Client-Architekturen
- Cloud(z. B. Pinecone): Diese Clients dienen als vollständige API-Abstraktion für serverlose Umgebungen. Der Hauptvorteil besteht darin, dass keinerlei Infrastrukturverwaltung erforderlich ist; allerdings sind für die gesamte lokale Entwicklung und das Testen eine aktive Internetverbindung sowie ein API-Schlüssel erforderlich.
- OSS mit Managed-Option (z. B. Qdrant, Weaviate, Milvus): Diese Tools nutzen dieselbe API sowohl für selbst gehostete Docker-Instanzen als auch für verwaltete Cloud . Dies sorgt für eine hervorragende Übereinstimmung zwischen Entwicklungs- und Produktionsumgebung, erfordert jedoch häufig die Verwaltung eines lokalen Servers oder eines Docker-Containers während der Entwicklung.
- eingebettet (z. B. ChromaDB, FAISS): Diese Tools laufen prozessintern und einbetten Datenbanklogik in Ihre Python einbetten . Sie eignen sich zwar ideal für Notebooks und Rapid Prototyping, wurden jedoch von ihren Entwicklern nie für verteilte Produktionsumgebungen konzipiert und bieten keinen klar definierten Migrationspfad für den Fall, dass die Anwendung skaliert wird.
- Erweiterungsansatz (z. B. pgvector über Timescale Vector): Dieses Modell erweitert herkömmliche relationale Datenbanken Fähigkeiten . Es ermöglicht der bestehenden PostgreSQL-Infrastruktur, die Vektorähnlichkeitssuche zu unterstützen. abfragen hängt jedoch von der Indexkonfiguration, Datensatz und Workload ab; Nutzen einigen Szenarien Nutzen die relationale Grundlage Nutzen , während in anderen Fällen speziell entwickelte Vektorarchitekturen vorzuziehen sind.
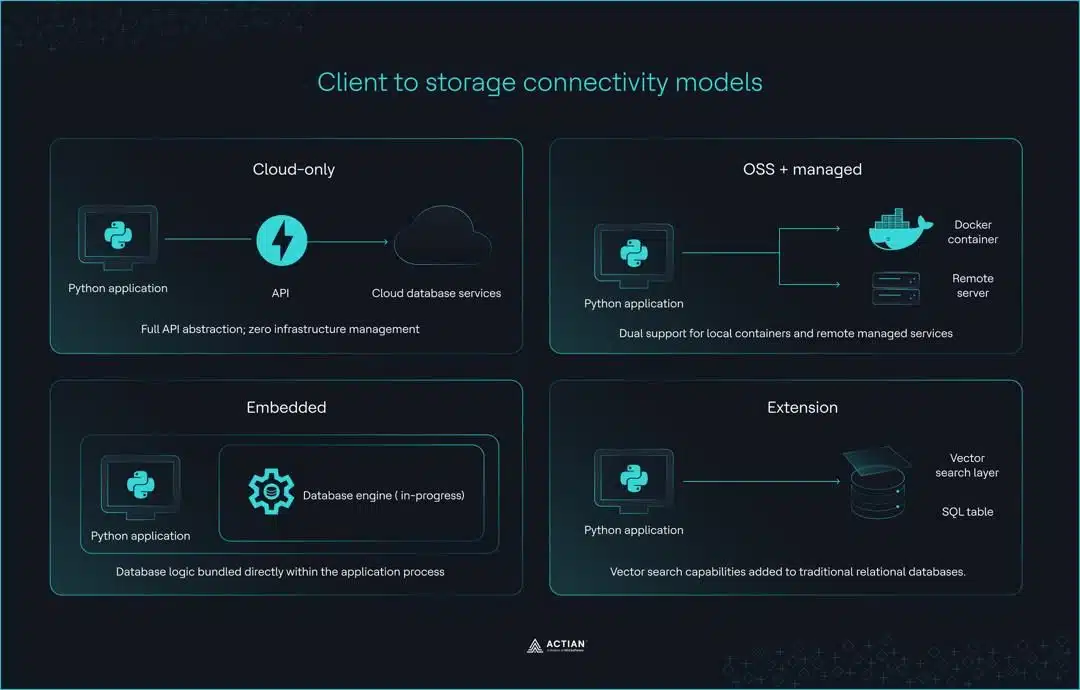
Diese vier Modelle beschreiben, wie ein Client eine Verbindung zum Speicher herstellt, verdeutlichen aber auch die praktische Unterscheidung zwischen eigenständigen Suchbibliotheken und verwalteten Datenbanksystemen. Die Wahl des falschen Modells führt zu einigen der hartnäckigsten Probleme im Produktivbetrieb von Vektorsuchanwendungen.
Eine Vektordatenbank bietet die für Bereitschaft erforderliche Infrastruktur und geht damit über das Angebot von Einzelbibliotheken für Entwickler hinaus. Bibliotheken wie FAISS oder Annoy sind statische, in-memory , die auf die ungefähre Suche nach dem nächsten Nachbarn in großen Datensätzen ausgerichtet sind. Sie sind äußerst effizient für die Ähnlichkeitssuche innerhalb eines festen Vektorraums, können jedoch keine verwalten im Zeitverlauf verwalten .
Spezialisierte Datenbanken wie Pinecone, Qdrant oder Milvus gehen noch einen Schritt weiter und bieten vollständige CRUD-Unterstützung, Metadaten Filterung sowie verteilte Persistenz für große Datensätze.
Die folgende Tabelle gibt einen Überblick darüber, für welche gängigen Anwendungsfälle die einzelnen Architekturen geeignet sind.
| Kategorie | Hauptkompromiss | Migrationspfad für die Produktion |
| Nur Cloud | Keine Infrastrukturverwaltung; erfordert Netzwerkverbindung und API-Authentifizierung für alle Umgebungen | Einheitlicher Client-Code für Entwicklung und Produktion |
| OSS + verwaltet | Identische API für lokale und Cloud ; erfordert Docker oder eine Serverkonfiguration | Keine Codeänderungen zwischen der lokalen Docker-Instanz und Cloud verwalteten Cloud |
| eingebettet | Ausführung während des laufenden Prozesses mit minimalem Rüstaufwand; beschränkt auf eine Ein-Rechner-Architektur | Ersatz der Client-Klasse erforderlich; Deployment verteilte Deployment neu gestaltet werden |
| Erweiterung | Lässt sich in die PostgreSQL-Infrastruktur integrieren; die Leistung hängt von der Konfiguration ab | Hängt von der bestehenden PostgreSQL-Konfiguration und den Anforderungen an die Skalierbarkeit ab |
Kundenvergleich: Ein tiefer Einblick in die Entwicklererfahrung
Die Architektur schränkt zwar die Auswahlmöglichkeiten ein, doch im Arbeitsalltag mit einer Python kommt es letztlich darauf an, wie der jeweilige Client den Verbindungsaufbau, die Versionsstabilität und die Reibungspunkte während der aktiven Entwicklung handhabt.
Im Folgenden vergleichen wir die vier Clients anhand der Herausforderungen, mit denen Entwickler in der Praxis konfrontiert sind.
1. Pinecone Python
Pinecone bietet unter den Cloud Vektordatenbank-Clients eine der ausgereiftesten Schnittstellen, mit umfangreichen Typhinweisen und einem unkomplizierten Initialisierungsmuster.
from pinecone import Pinecone
pc = Pinecone(api_key="your-api-key")
index = pc.Index("your-index-name")Stärken:
- Umfassende Typ-Hinweise und Unterstützung für die Autovervollständigung in der IDE.
- Pinecone hat in Version 6 über „Pinecone Asyncio“ die Unterstützung für AsyncIO eingeführt.
- Der gRPC-Modus bietet einen höheren Durchsatz für anspruchsvolle Workloads.
- Sorgfältig gepflegte offizielle Dokumentation.
Schwachstellen:
- Pinecone hat innerhalb von 18 Monaten drei Hauptversionen veröffentlicht (v5, v6 und v7), wobei grundlegende Änderungen an der Verbindungslogik vorgenommen und das Paket von „pinecone-client“ in „pinecone“ umbenannt wurden.
- Historische Verwechslungen zwischen den Paketen „pinecone“ und „pinecone-client“.
- Asynchrone Operationen abfragen unter Last erfordern eine Optimierung des Thread-Pools.
2. Weaviate Python
Der v4-Client von Weaviate stellt einen bedeutenden Fortschritt gegenüber v3 dar und bietet nun typisierte Klassen sowie gRPC-Unterstützung, wodurch sich abfragen spürbar verbessert.
import weaviate
client = weaviate.connect_to_local()
collection = client.collections.get("your-collection-name")Stärken:
- Der gRPC-Modus bietet abfragen um 40–70 % schnellere abfragen als v3.
- Typisierte Eigenschaften und DataType-Klassen ersetzen die untypisierten v3-Wörterbücher.
- Integrierte Hybridsuche, die Vektor- und Stichwortsuche kombiniert.
- Umfassende Unterstützung für Multi-Tenancy-Workloads.
Schwachstellen:
- Weaviate hat die v3-API vollständig eingestellt, und Teams berichten, dass die Migration mehrere Wochen Arbeit in Anspruch nimmt.
- gRPC erfordert, dass Port 50051 offen ist, was in eingeschränkten Netzwerkumgebungen zu Problemen führt.
- Die Neugestaltung der Batch-API führte zu erheblicher Verwirrung (Issue #433).
- LangChain hat die Unterstützung für Version 4 erst mehrere Monate nach der Veröffentlichung von Weaviate bereitgestellt (Issue #14531).
3. ChromaDB Python
ChromaDB bietet unter Python eine der benutzerfreundlichsten Einführungserfahrungen und ist damit ein idealer Ausgangspunkt für Notebooks und Prototypen in der frühen Entwicklungsphase.
import chromadb
client = chromadb.Client()Stärken:
- Die einfachste API-Oberfläche aller in diesem Vergleich getesteten Clients.
- Ausgereifte LangChain-Integration mit gut dokumentierten Beispielen.
- In-memory erfordert in Notebook-Umgebungen keinerlei Konfiguration.
- Eine große und aktive Open-Source-Community.
Schwachstellen:
- Inkompatibilität Python .13 (Problem #3651).
- Windows-Instabilität bei mehr als 99 Datensätzen (Problem Nr. 3058).
- Wenn man „chromadb“ mit „chromadb-client“ verwechselt, führt dies zu Fehlern bei der Produktionsbereitstellung.
- Kompilierungsfehler bei hnswlib auf ARM-Mac-Prozessoren.
- Erfordert SQLite 3.35 oder höher, was einen umgebungsspezifischen Einrichtungsaufwand mit sich bringt.
4. Qdrant Python
Entwickler schätzen Qdrant wegen seiner Übereinstimmung zwischen Entwicklungs- und Produktionsumgebung. Der gleiche Client-Code läuft während der Entwicklung auf einer in-memory undDeployment der Produktion auf einer voll gemanagt Deployment , ohne dass Änderungen erforderlich sind.
from qdrant_client import QdrantClient
client = QdrantClient(":memory:")Stärken:
- Der :memory:-Modus ermöglicht einen Workflow vom lokalen Umfeld zur Produktion ohne Codeänderungen.
- Qdrant hat einen nativen AsyncQdrantClient fürZustimmung eingeführt.
- Typensicherheit nach dem Pydantic-Modell in der gesamten Client-Schnittstelle.
- Eine auf Rust basierende Implementierung mit geringerem Speicherbedarf im Vergleich zu JVM-basierten Alternativen.
Schwachstellen:
- Entwickler müssen „prefer_grpc=True“ ausdrücklich festlegen, um gRPC zu aktivieren – ein Schritt, den sie oft übersehen.
- Die Aufteilung des Ports zwischen REST (6333) und gRPC (6334) erfordert eine sorgfältige Netzwerkkonfiguration.
- Versionsbeschränkungen für Pydantic: Nur v1.10.x oder v2.21 und höher.
- Probleme Cloud (Problem Nr. 112).
Wann sollte man sich für Qdrant entscheiden:
- Die Übereinstimmung zwischen lokaler und Produktionsumgebung hat oberste Priorität, und es ist wichtig, dass zwischen den Umgebungen keinerlei Codeänderungen erforderlich sind.
- Zustimmung WorkloadsZustimmung erfordern native Unterstützung durch den AsyncQdrantClient.
- Sie bevorzugen eine selbst gehostete Open-Source-Vektordatenbank Deployment einem verwalteten Cloud .
- Eine Hybrid-Suche, die dichte und spärliche Vektoren kombiniert, ist eine zentrale Anforderung.
Wann man Qdrant vermeiden sollte:
- Das Team hat keine Erfahrung mit Docker und benötigt eine einfachere lokale Konfiguration.
- Die Zielumgebung unterstützt keine gRPC-Netzwerkkonfiguration.
- Die Versionsbeschränkungen von Pydantic stehen im Konflikt mit bestehenden Projektabhängigkeiten.
Installation und Umgebungsmanagement
Unter idealen Bedingungen ist die Installation einer Python unkompliziert. In der Praxis führen jedoch die Zielplattform, Python und bestehende Paketabhängigkeiten zu Unwägbarkeiten, die eine einfache „pip install“-Installation zu einer mehrstündigen Debugging-Sitzung machen können. Eine kurze Kompatibilitätsprüfung vor der endgültigen Bereitstellung für einen Kunden lohnt sich, da die meisten dieser Probleme erst nach Abschluss der Einrichtung zutage treten.
Die Kompatibilitätsmatrix
Die folgende Matrix zeigt das Client-Verhalten unter Python .8–3.13 auf macOS ARM, Windows und Linux.
| Kunde | macOS ARM (M1/M2) | Windows | Linux (Debian) | Python .13 |
| Tannenzapfen | ✓ Umfassende Unterstützung | ✓ Umfassende Unterstützung | ✓ Umfassende Unterstützung | ✓ Unterstützt |
| Weaviate | ✓ Umfassende Unterstützung | ✓ Umfassende Unterstützung | Erfordert Docker für gRPC | ✓ Unterstützt |
| ChromaDB | hnswlib-Kompilierungsfehler | Instabilität bei mehr als 99 Datensätzen (Nr. 3058) | Erfordert Debian Bookworm+ | ✗ Defekt (#3651) |
| Qdrant | ✓ Umfassende Unterstützung | ✓ Umfassende Unterstützung | ✓ Umfassende Unterstützung | ✓ Unterstützt |
ChromaDB hat von allen in diesem Vergleich getesteten Clients die größten Kompatibilitätsprobleme. Unter macOS mit ARM-Prozessoren verursacht hnswlib bei der Installation Kompilierungsfehler, sodass Entwickler Python manuell Python Version 3.11 oder 3.12 festlegen müssen.
Unter Windows kommt es bei ChromaDB zu Instabilitäten, sobald eine Sammlung mehr als 99 Datensätze umfasst, wodurch sich der eingebettet nur für erste Prototypen eignet. Unter Linux benötigen Debian-basierte Distributionen Bookworm oder eine neuere Version, um ChromaDB fehlerfrei zu installieren und auszuführen.
Bewährte Verfahren für virtuelle Umgebungen
python -m venv venv
source venv/bin/activate # On Windows: venv\Scripts\activate
pip install chromadbEs ist ebenso wichtig, die Client-Version in einer „requirements.txt“-Datei festzuhalten, da einige dieser Clients in der Vergangenheit bereits zwischen Minor-Releases kompatibilitätsbrechende Änderungen eingeführt haben.
chromadb==0.4.x
qdrant-client==1.7.x
pinecone==3.x
weaviate-client==4.xDie Zwei-Paket-Architektur von ChromaDB verwirrt viele Entwickler. Wenn jemand „chromadb-client“ anstelle von „chromadb“ installiert, gibt die Anwendung bei ihrem ersten Versuch, die Standard-Einbettungsfunktion aufzurufen, diesen Fehler aus.
ValueError: You must provide an embedding functionZusatzfunktionen und optionale Abhängigkeiten
# Pinecone with gRPC support
pip install pinecone[grpc]
# Qdrant with FastEmbed for local embedding generation
pip install qdrant-client[fastembed]
# ChromaDB with sentence-transformers for local embedding support
pip install chromadb sentence-transformersgRPC hat den größten Einfluss auf abfragen bei optionaler Installation. Weaviate verzeichnet bei gRPC um 40 bis 70 % schnellere Abfragen als bei REST, während Qdrant abfragen von etwa 15 % erzielt. Der Nachteil ist, dass gRPC eine zusätzliche Netzwerkkonfiguration erfordert, was in eingeschränkten Umgebungen unter Umständen nicht möglich ist.
Sowohl FastEmbed als auch Sentence-Transformers ermöglichen die lokale Erzeugung von Embeddings ohne Abhängigkeit von externen APIs, wodurch die Latenz und die Kosten für Embeddings bei Workloads für die semantische Suche und die Ähnlichkeitssuche gering gehalten werden.
Der native AsyncQdrantClient von Qdrant und der PineconeAsyncio von Pinecone erzielen beiZustimmung eine 3- bis 5-fache Steigerung des Durchsatzes.
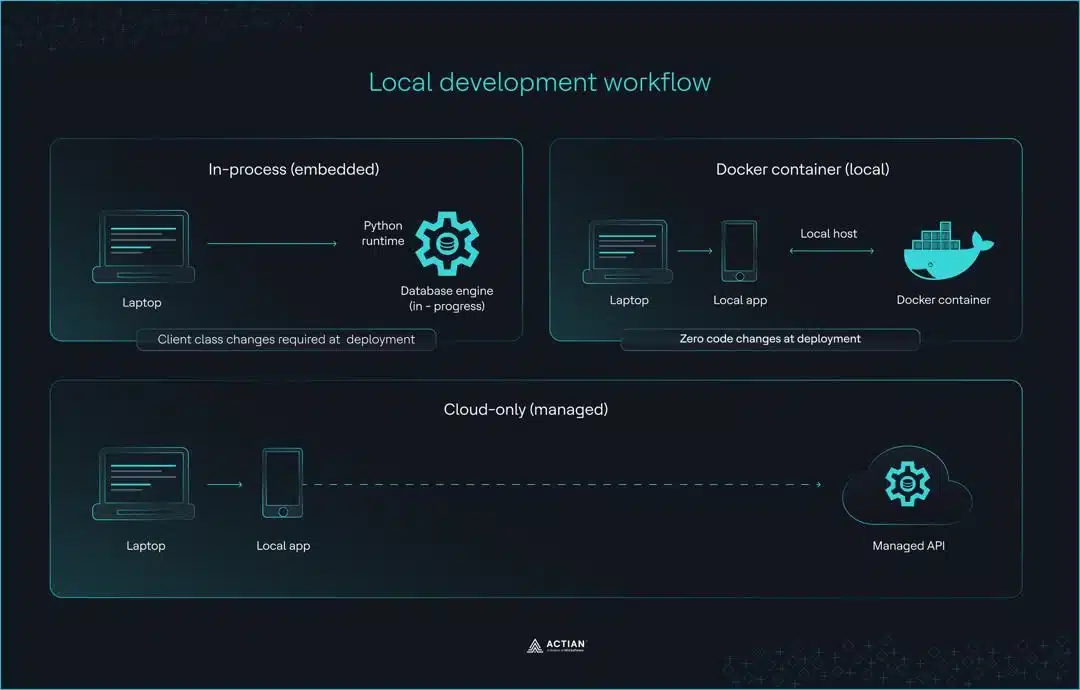
Workflows für die lokale Entwicklung
Entwickler treffen die meisten Entscheidungen bezüglich Vektordatenbanken in der lokalen Entwicklungsumgebung. Die entscheidende Frage lautet: Welcher Client erfordert beim Übergang in die Produktion die geringsten Codeänderungen?
Der Migrationspfad
So handhabt jeder Kunde den Übergang von Deployment lokalen Deployment Produktion.
# Qdrant - zero code changes required
client = QdrantClient(":memory:") # Development
client = QdrantClient( # Production
url="https://your-cluster-url",
api_key="your-api-key"
)
# ChromaDB - client class change required
client = chromadb.Client() # Development
client = chromadb.HttpClient( # Production
host="your-host",
port=8000
)
# Pinecone - same code in both environments
pc = Pinecone(api_key="your-api-key") # Development and production
index = pc.Index("your-index-name")
Qdrant :memory: Dieser Modus überträgt den identischen Client-Code von der lokalen Entwicklung bis hin zur Produktion. Die Konfiguration des Vektorspeichers, die Einstellungen für die Kosinusähnlichkeit und die HNSW-Indexparameter bleiben in allen Umgebungen unverändert.
Bei der Umstellung auf die Produktionsumgebung ist eine Änderung an der Client-Klasse erforderlich. Je häufiger der Client in der Codebasis verwendet wird, desto größere Teile der Anwendung sind von dieser Änderung betroffen.
Pinecone verwendet sowohl in der Entwicklungs- als auch in der Produktionsumgebung denselben Code, da alles Cloud von der Phase in der Cloud läuft.
Diese Unterschiede bei der Migration sind auf drei unterschiedliche lokale Entwicklungsansätze zurückzuführen: eingebettet , Docker und Cloud.
eingebettet
eingebettet standardmäßige eingebettet von ChromaDB speichert Daten ausschließlich im Arbeitsspeicher. Wenn die Anwendung beendet wird, gehen die Daten verloren. Für Entwicklungen, die persistente Sammlungen beinhalten, PersistentClient schreibt die Daten stattdessen auf die Festplatte.
# In-memory only: data lost when process ends
client = chromadb.Client()
collection = client.create_collection("my_collection")
collection.add(documents=["doc1", "doc2"], ids=["1", "2"])
# Persistent local storage
client = chromadb.PersistentClient(path="/local/path")
Qdrant’s :memory: Der Modus nutzt dieselbe Client-Schnittstelle wie eine Deployment. Jeder Code, der lokal funktioniert, funktioniert auch in der Produktion ohne Änderungen.
client = QdrantClient(":memory:")
client.create_collection(
collection_name="my_collection",
vectors_config=VectorParams(size=384, distance=Distance.COSINE)
)
Beide Clients eignen sich gut für die frühe Prototypenentwicklung und den Einsatz auf Notebooks; Unterschiede treten erst an der Produktionsgrenze zutage.
Docker für die lokale Entwicklung
Docker führt die Vektordatenbank in einem isolierten lokalen Container aus, wobei dieselbe Konfiguration wie bei einem Deployment verwendet wird. Qdrant und Weaviate sind beides Open-Source-Vektordatenbanken, die diesen Ansatz unterstützen.
# Qdrant
docker run -p 6333:6333 qdrant/qdrant
# Weaviate
docker run -p 8080:8080 -p 50051:50051 cr.weaviate.io/semitechnologies/weaviate:latest
Sobald der Container läuft, stellt der Client eine Verbindung zu „localhost“ her, genauso wie er es bei einer selbst gehosteten Vektordatenbank in der Produktionsumgebung tun würde.
# Qdrant
client = QdrantClient(url="https://localhost:6333")
# Weaviate
client = weaviate.connect_to_local()
Der Hauptvorteil besteht darin, dass sich die Konfiguration des Vektorindexes lokal und in der Produktionsumgebung identisch verhält und Probleme, die lokal auftreten, echte Probleme sind und keine umgebungsspezifischen Artefakte.
Der Nachteil ist der Aufwand für die Installation von Docker und die Portkonfiguration, insbesondere die Anforderung von Weaviate, dass beide Ports verfügbar sein müssen 8080 and 50051.
Entwicklung Cloud
Integrations-Ökosystem: LangChain und LlamaIndex
from langchain_pinecone import PineconeVectorStore
from langchain_chroma import Chroma
from langchain_qdrant import QdrantVectorStore
from langchain_weaviate import WeaviateVectorStore
from llama_index.vector_stores.qdrant import QdrantVectorStore- Der Kunde veröffentlicht eine neue Version mit inkompatiblen Änderungen.
- Zu LangChain und LlamaIndex später mehr.
- Rohrleitungen fallen vorübergehend aus.
Überlegungen zur Leistung: Mehr als nur reine Geschwindigkeit
Bei den meisten Client-Vergleichen werden drei Faktoren übersehen, die die Leistung von Vektordatenbanken erheblich beeinflussen: die Wahl des Protokolls, die Qualität der asynchronen Unterstützung und das Connection-Pooling.
Protokollauswahl: REST vs. gRPC
gRPC und REST sind die beiden Transportprotokolle, die für diese Clients verfügbar sind. Wie bereits erwähnt, verzeichnet Weaviate bei gRPC um 40 bis 80 % schnellere Abfragen, und Qdrant erzielt bei aktiviertem gRPC abfragen um etwa 15 % höhere abfragen . In eingeschränkten Netzwerkumgebungen, in denen der Port 50051 nicht verfügbar ist, ist REST die praktischere Option.
Qualität der Async-Unterstützung
Die meisten Teams entwickeln LLM-Anwendungen für den Produktionsbetrieb auf Basis von FastAPI oder ähnlichen asynchronen Frameworks, weshalb die Unterstützung asynchroner Clients ein wichtiger Faktor für die Leistung ist. Die Verwendung eines synchronen Clients in einer asynchronen Anwendung führt zu blockierenden Aufrufen, was den Durchsatz erheblich verringert.
Qdrants native AsyncQdrantClient, verfügbar seit Version 1.61, bietet eine bewährte Async-Implementierung. Pinecone führte PineconeAsyncio In Version 6 wurde eine umfassende Asynchron-Unterstützung für Cloud Vektorsuch-Workloads eingeführt. Weaviate fügte die Asynchron-Unterstützung in Version 4.7 hinzu und ist damit das jüngste der vier Produkte, das produktionsbereit Fähigkeiten erreicht hat. Die Asynchron-Unterstützung von ChromaDB ist bei allen vier Produkten nach wie vor eingeschränkt.
Der Unterschied im Durchsatz ist erheblich. Bei I/O-gebundenen Workloads, bei denen die Netzwerklatenz den Engpass darstellt, erzielen asynchrone Clients in der Regel einen 3- bis 5-mal höheren Durchsatz als ihre synchronen Pendants.
Verbindungspooling und Ressourcenverwaltung
Dies ist einer der Konfigurationsbereiche, in denen die Standardeinstellungen im Produktionsbetrieb oft nicht ausreichen. Sowohl Qdrant als auch Pinecone bieten Parameter, die eine bessere Kontrolle über das Verbindungsmanagement bei anhaltendem Produktionsdatenverkehr ermöglichen.
# Qdrant connection pool configuration
client = QdrantClient(
url="https://your-cluster-url",
api_key="your-api-key",
timeout=30,
pool_size=10
)
# Pinecone connection pool configuration
index = pc.Index(
"your-index-name",
pool_threads=30,
connection_pool_maxsize=30
)
Für Pinecone, query_namespaces muss eingestellt werden pool_threads und connection_pool_maxsize für Produktions-Workloads. Für Qdrant bedeutet eine Erhöhung pool_size Ein Wert über dem Standardwert verringert die Verbindungsüberlastung bei Anwendungen, die große Mengen an Dokumenteneinbettungen parallel verarbeiten.
Teams, die feinabstimmen Einstellungen vor Deployment feinabstimmen , Deployment erheblichen Debugging-Aufwand, wenn die Anwendung unter Last läuft.
Fehlerbehandlung und Fehlerbehebung
Vektordatenbank-Bibliotheken bewältigen intern eine Vielzahl komplexer Vorgänge. Wenn ein Fehler auftritt, hängt es davon ab, wie klar der Client diesen Fehler meldet, wie schnell Teams ihn beheben können.
Qualität der Fehlermeldungen
Die Qualität der Fehlermeldungen variiert bei den vier Clients erheblich.
Pinecone generiert klare, umsetzbare Fehlermeldungen, die in der Regel neben der Fehlerbeschreibung auch einen Lösungsvorschlag enthalten, wodurch sich der Zeitaufwand der Teams für die Suche nach der Ursache verringert.
Qdrant-Fehlermeldungen sind hilfreich und weisen direkt auf die Ursache des Problems hin. Die Ausnahme „UnexpectedResponse“ enthält ein Feld „reason“, das genau angibt, bei welchem Parameter die Validierung fehlgeschlagen ist.
qdrant_client.http.exceptions.UnexpectedResponse: Status 400, reason: "Wrong input: Vector dimension error: expected dim: 384, got 768"Fehlermeldungen von ChromaDB sind oft vage und erfordern eine Suche auf GitHub, um die Ursache zu ermitteln. Wenn es zu einer Verwechslung der beiden Pakete kommt, löst ChromaDB einen „ValueError“ wegen fehlender Einbettungsfunktionen aus, anstatt die eigentliche Ursache zu melden. Die Anforderung an die SQLite-Version führt zu einem ähnlich wenig hilfreichen Fehler:
RuntimeError: Your system has an unsupported version of sqlite3. Chroma requires sqlite3 >= 3.35.0.Dieser Fehler stellt für Python , die auf älteren Amazon Linux 2- oder Streamlit-Umgebungen bereitstellen, ein häufiges Hindernis dar.
Weaviate v3 schlug stillschweigend fehl und gab Null-Objekte oder Wörterbücher mit einem „errors“-Schlüssel zurück, die Entwickler manuell überprüfen mussten. Die Neuprogrammierung in v4 behob dieses Problem durch typisierte Ausnahmen, wie zum Beispiel WeaviateQueryError und WeaviateGRPCUnavailableError.
Protokollierung und Beobachtbarkeit
Fähigkeiten Beobachtbarkeit Fähigkeiten bei den vier Kunden.
- Qdrant unterstützt strukturiertes Logging, verteilte Tracing-Funktionen und Metriken ohne zusätzliche Konfiguration und eignet sich daher hervorragend für Maschinelles Lernen , bei denen Einblicke in die Leistung der Vektorsuchmaschine erforderlich sind.
- Pinecone bietet über seine verwaltete Infrastruktur grundlegende Protokollierungsfunktionen.
- ChromaDB verfügt nur über eine eingeschränkte Protokollierung ohne strukturierte Ausgabe, was die Fehlerdiagnose in KI-Anwendungen in der Produktion erheblich erschwert.
Häufige Fallstricke und Lösungen
Drei Fehlermuster treten bei allen vier Clients in Produktionsumgebungen immer wieder auf.
- Inkompatible Client-Versionen führen häufig zu unerwarteten Ausfällen, insbesondere angesichts der drei Releases von Pinecone innerhalb von 18 Monaten und der Migration von Weaviate von Version 3 auf Version 4. Teams können dies kontrollieren, indem sie Client-Versionen in einer
requirements.txtDatei. - Eine Diskrepanz bei den Einbettungsdimensionen tritt auf, wenn die abfragen nicht den Erwartungen der Sammlung entsprechen. Dies Deployment , indem vor Deployment überprüft wird, ob die Ausgabegröße des Einbettungsmodells mit der Konfiguration der Sammlung übereinstimmt.
- Die Ratenbegrenzung wirkt sich auf Cloud-Bereitstellungen auf Pinecone und Weaviate Cloud aus. Die Implementierung eines exponentiellen Backoffs bei API-Aufrufen ist die Standardlösung für Produktions-Workloads, die bei anhaltendem Datenverkehr an die Ratenbegrenzung stoßen.
Wie oft Versionskonflikte auftreten, wie weit sich Plattforminkompatibilitäten ausbreiten und wie klar Fehlermeldungen Fehler kommunizieren – all dies bestimmt die tatsächlichen Wartungskosten eines Kunden im Produktivbetrieb.
Die häufigen Versionswechsel bei Pinecone, Weaviate und ChromaDB haben dazu geführt, dass viele Produktionsteams nach einer Datenbank suchen, bei der die Betriebsstabilität Vorrang vor der Geschwindigkeit der Funktionsentwicklung hat. Actian VectorAI DB geht genau auf dieses Problem ein.
Actian VectorAI DB
- Einheitliche Architektur in allen Umgebungen.
- Docker-basierte Deployment.
- HNSW-Indizierung.
- Indizierung in Echtzeit.
- Python JavaScript-SDKs.
- Native Integration von LangChain und LlamaIndex.
Framework: Auswahl Ihres Python
Entscheidungsmatrix
| Kriterien | Tannenzapfen | Qdrant | Weaviate | ChromaDB | Actian VectorAI DB |
| API-Stabilität | Mittel | Gut | Verbesserung | Niedrig | Hoch |
| Lokale Entwicklung | ✗ Kein lokaler Modus | ✓ :memory: Modus | Docker erforderlich | ✓ eingebettet | ✓ :memory: + SQLite |
| Plattformkompatibilität | ✓ Cloud | ✓ Alle Plattformen | ✓ Alle Plattformen | ✗ Probleme unter ARM, Windows | ✓ Alle Plattformen |
| Unterstützung für asynchrone Vorgänge | ✓ Version 6 oder höher | ✓ Muttersprachler | ✓ v4.7+ | ✗ Begrenzt | ✓ Muttersprachler |
| Kosten | 50–500+ $/Monat | Kostenlos / Selbst gehostet | Kostenlos / Verwaltet | Kostenlos | Preise für Unternehmen |
Abschließende Überlegungen
Der ChromaDB-Produktionsausfall aus dem einleitenden Beispiel ist auf Probleme bei der Client-Paketierung zurückzuführen, auf die Entwickler erst nach Deployment stoßen. Dieser Vergleich hilft dabei, ähnliche Ausfälle zu vermeiden: Plattforminkompatibilitäten, grundlegende Änderungen durch Versionsmigrationen und Neugestaltungen von Client-Klassen, die sich auf die gesamte Codebasis auswirken.
ChromaDB ermöglicht einen schnellen Projektstart, stößt jedoch oft an seine Grenzen, sobald die Anwendung in die Produktion geht. Pinecone ist ausgereift und gut verwaltet, doch häufige Versionswechsel und dauerhafte Cloud verursachen erhebliche Kosten. Qdrant ist die beste Open-Source-Option für Teams, die eine vollständige Übereinstimmung zwischen lokaler und Produktionsumgebung ohne Codeänderungen anstreben. Der v4-Client von Weaviate stellt eine deutliche Verbesserung gegenüber v3 dar und eignet sich gut für Teams, die eine hybride Suche in großem Maßstab benötigen.
Für Teams, bei denen API-Stabilität und Plattformkompatibilität von entscheidender Bedeutung sind, bieten Clients der Enterprise-Klasse wie Actian VectorAI DB produktionsbereit mit geprüfter plattformübergreifender Unterstützung.
Entdecken Sie Actian VectorAI DB für garantierte Produktionsstabilität.

Bleiben Sie in Verbindung
Datenanalysen direkt bei Ihnen.
(z. B. sales@..., support@...)