Was uns Cloud von 37signals über KI-Infrastruktur gelehrt hat





Zusammenfassung
- Durch Cloud lassen sich in großem Maßstab Kosten in Millionenhöhe einsparen.
- KI-Workloads sorgen aufgrund der GPU- und Speicherkosten für zusätzliche Einsparungen.
- On-Premise- oder Hybridlösungen eignen sich für vorhersehbare Inferenzaufgaben mit hohem Datenaufkommen.
- Cloud eignet sich Cloud für sporadische Workloads wie Training von Modellen.
- Hybridstrategien sorgen für ein ausgewogenes Verhältnis zwischen Kosten, Leistung und Compliance.
Im Jahr 2023, 37signals gab bekannt, dass es die öffentliche Cloud vollständig verlassen habe, Cloud dokumentierte anschließend öffentlich seinen Prozess Cloud , wodurch es eines der anschaulichsten Beispiele aus der Praxis für On-Premises im großen Maßstab lieferte. Durch die Umkehrung seiner Cloud und die Verlagerung von Workloads in Cloud private Cloud konnte das Unternehmen seine jährlichen Ausgaben für Cloud um fast 2 Millionen Dollar.
Die Transparenz der Zahlen machte das Argument überzeugend. Im Jahr 2022 gab 37signals 3.201.564 US-Dollar für Cloud aus, was etwa 266.797 US-Dollar pro Monat entspricht. Diese detaillierten Kostenaufstellungen sowie die veröffentlichten Angaben zu Hardware-Investitionen und Amortisationszeiträumen gewährten einen seltenen Einblick in die finanziellen Mechanismen einer groß angelegten Cloud .
Bei Standard-SaaS-Workloads war die Rechnung eindeutig. Doch dieselbe Logik wirft für die nächste Generation rechenintensiver Systeme eine wichtige Frage auf: „Gilt dieses wirtschaftliche Argument auch für die KI-Infrastruktur?“ In diesem Artikel untersuchen wir, ob dieselbe wirtschaftliche Logik auch für die KI-Infrastruktur gilt.
TL;DR
- 37signals gab im Jahr 2022 etwa 3,2 Millionen Dollar pro Jahr für AWS aus.
- Nachdem die Workloads wieder in die eigene Infrastruktur verlagert worden waren, sanken Cloud bis 2024 auf rund 1,3 Mio. $.
- Das Unternehmen investierte etwa 700.000 bis 800.000 Dollar in Server und hatte diese in weniger als 18 Monaten abbezahlt.
- Die gesamte Infrastruktur wird nach wie vor von demselben 10-köpfigen Team betrieben. Es entstehen keine zusätzlichen Betriebskosten.
- Die wichtigste Erkenntnis ist, dass der Besitz von Infrastruktur bei großem Umfang deutlich kostengünstiger sein kann als deren Anmietung.
Das 37signals-Playbook: Was Hanson tatsächlich dokumentiert hat
Im Jahr 2022 gab jährlich 3,2 Millionen Dollar für AWS aus. Nach dem dem Ausstieg aus der Cloud 2023, waren ihre jährlichen Kosten bis 2024 auf etwa 1,3 Millionen Dollar gesunken, was einer Einsparung von fast 2 Millionen Dollar pro Jahr.
Die Umstellung erforderte eine Investition in Hardware in Höhe von etwa 600.000 US-Dollar in Dell-Server. Das Unternehmen hat die Investition in weniger als 18 Monaten vollständig amortisiert und die vollständige Amortisation in der zweiten Hälfte des Jahres 2023 erreicht, als die Verträge für die AWS Reserved Instances ausliefen. Von diesem Zeitpunkt an flossen die Einsparungen direkt in die operative Marge, anstatt die Investitionsausgaben auszugleichen.
37signals rechnete mit Hardwarekosten in Höhe von 1,5 Millionen Dollar und Betriebskosten von etwa 200.000 Dollar pro Jahr. Durch diese Umstellung werden die jährlich wiederkehrenden Kosten Cloud in Höhe von 1,3 Millionen Dollar durch eine einmalige Investition sowie einen Bruchteil der laufenden Betriebskosten ersetzt. Über einen Zeitraum von fünf Jahren korrigierte 37signals die prognostizierten Gesamteinsparungen von 7 Millionen Dollar auf über 10 Millionen Dollar nach oben.
37signals: Finanzdaten Cloud nach Jahr
Um die finanziellen Auswirkungen Cloud von 37signals Cloud im Zeitverlauf zu veranschaulichen, werden in der folgenden Tabelle die jährlichen Cloud , Investitionen in On-Premises sowie die Betriebskosten aufgeschlüsselt und hebt die daraus resultierenden Nettoeinsparungen sowie wichtige betriebliche Anmerkungen hervor.
| Jahr | Cloud | Investitionen in Hardware | Betriebskosten | Anmerkungen |
| Ausgangswert 2022 | ca. 3,2 Mio. $ | $0 | In Cloud enthalten | Vollständige Cloud |
| Migration 2023 | ca. 2 Mio. $ | ca. 700.000–800.000 $ | Mäßig | Die Hardwarekosten haben sich in weniger als 18 Monaten amortisiert |
| 2024+ Nach der Rückführung | ca. 1,3 Mio. $ | ca. 1,5 Mio. $ (Lagerung) | ca. 200.000 $/Jahr | ~1,9 Mio. $ jährliche Einsparungen |
| 2025+ | Minimale Abhängigkeit von AWS | ca. 1,5 Mio. $ (Pure Storage, 18 PB) | ca. 200.000 $/Jahr | Prognostizierte Einsparungen von über 10 Millionen Dollar über einen Zeitraum von fünf Jahren |
Bemerkenswert ist, dass die Migration keine Erweiterung des Betriebs erforderte. Ein zehnköpfiges Infrastrukturteam bewältigte die gesamte Rückführung, ohne neue Mitarbeiter einzustellen. Auf eine häufig geäußerte Sorge hinsichtlich des betrieblichen Aufwands eingehend, merkte David Heinemeier Hansson, Mitbegründer von 37signals, an:
Wir sind nun seit etwas mehr als einem Jahr auf dem Markt, und das Team, das alles leitet, ist nach wie vor dasselbe. Es gab keine versteckten Fallstricke in Form von zusätzlichem Workload mit dem Markteintritt, die eine Aufstockung des Teams erforderlich gemacht hätten, wie einige Beobachter bei der Ankündigung spekuliert hatten. Alle Antworten in unseren häufig gestellten Fragen Cloud Big Cloud behalten weiterhin ihre Gültigkeit.
Dies stellt die weit verbreitete Annahme in Frage, dass die Abkehr von öffentlichen Cloud zwangsläufig ein deutlich größeres Infrastrukturteam erfordert.
Die Umsetzung erfolgte nach einer „Kritikalitätsleiter“-Strategie, bei der das Team zunächst Dienste mit geringerem Risiko und später die kritischeren Dienste migrierte. Das Team migrierte das HEY-E-Mail-System schrittweise, beginnend mit dem Caching, gefolgt von der Datenbank und schließlich den Job-Diensten. Um das Risiko zu minimieren, wurde die Infrastruktur etwa eine Millisekunde von der AWS-Region entfernt kolokiert, um während des Cloud die Rollback-Fähigkeit zu gewährleisten. Nach der Stabilisierung des Systems ersetzten sie Managed Services mit erheblichen wiederkehrenden Kosten, darunter RDS und Managed Elasticsearch, die zusammen jährlich 500.000 US-Dollar überstiegen.
Was case study von 37signals so case study macht, ist die öffentlich dokumentierte Kosteneffizienz. Für Unternehmen, die sich mit langfristigen AnnahmenCloud hinterfragen, insbesondere im Hinblick auf Speicherkosten und Managed Services, bietet die Dokumentation von 37signals eine seltene Vergleichsgrundlage.
Warum die wirtschaftlichen Aspekte der KI-Infrastruktur noch extremer sind
Die Erkenntnisse aus Cloud von 37signals gewinnen an Bedeutung, wenn man sie auf die KI-Infrastruktur anwendet. Höhere GPU-Kosten, vorhersehbare Inferenz-Workloads, massiver Speicherbedarf für Embeddings und strengere Datenschutzvorschriften führen zu finanziellen und betrieblichen Belastungen, die die Vorteile von On-Premises oder Cloud , die es Ihnen ermöglichen, Workloads dorthin zu verlagern, wo sie am sinnvollsten sind. Im Folgenden erläutern wir die wichtigsten Faktoren.
Kostenvergleich für KI-Infrastruktur
Um die finanziellen Auswirkungen verschiedener Ansätze für die KI-Infrastruktur zu bewerten, werden in der folgenden Tabelle die anfänglichen Einrichtungskosten, die monatlichen Betriebskosten bei unterschiedlicher Auslastung sowie die voraussichtlichen Amortisationszeiten für Cloud, On-Premises und Hybrid-Konfigurationen gegenübergestellt.
| Einrichtung | Einrichtungskosten | Monatliche Kosten | Gewinnschwelle |
| Cloud -Miete Cloud (AWS/Azure) | $0 | 2.900–3.500 $ (8 Stunden/Tag × 4–8 $/Stunde × 15 Tage) | Nicht zutreffend |
| Cloud -APIs (Lambda Labs) | $0 | 1.800–2.500 $ (8 Std./Tag × 3,67 $/Stunde × 15 Tage) | Nicht zutreffend |
| Selbst gehostete GPU (8×H100-Server) | 200.000–400.000 Dollar | 1.500–2.000 $ (Strom + Wartung) | <12 months |
| Hybrid (Cloud Training vor Ort) | 200.000–400.000 Dollar | Nur Training, minimale Inferenz | <12 months |
Hinweis: Bei der Anmietung Cloud schätzen wir die monatlichen Kosten auf der Grundlage von acht Stunden pro Tag und GPU. Die Kosten steigen linear mit der Auslastung; sie richten sich nicht direkt nachabfragen.
- Cloud bei GPU Cloud sind hoch
KI-Workloads sind stark von GPUs abhängig, und Cloud verlangen für GPU-Kapazitäten deutlich höhere Aufschläge als für herkömmliche CPU . On-Demand-Instanzen vom Typ AWS P5 mit H100-GPUs kosten etwa 4 bis 8 US-Dollar pro GPU-Stunde, während vergleichbare Azure-H100-Instanzen bei etwa 3,67 US-Dollar pro Stunde liegen. Im Gegensatz dazu bieten Spotmärkte und alternative Anbieter wie Lambda Labs ähnliche GPU-Kapazitäten für 1–2 US-Dollar pro Stunde oder 1,85–2,49 US-Dollar pro Stunde bei reservierten Kontingenten an.
Das Ergebnis ist ein Preisaufschlag von 4 bis 8 Mal für On-Demand-GPU-Kapazitäten bei Hyperscalern im Vergleich zum Spot- oder spezialisierten Cloud . Mit anderen Worten: Der Aufschlag, Cloud für High-End-KI-Rechenleistung verlangen, ist deutlich höher alsCloud üblichenCloud . Für Unternehmen, die kontinuierlich Inferenz-Workloads ausführen, wird diese Preisdifferenz schnell zum dominierenden Kostenfaktor in der KI-Infrastruktur.
- Dank vorhersehbarer Schlussfolgerungen lohnt sich der Kauf einer GPU
Die hohen Preise für GPUs gewinnen besonders an Bedeutung, da KI-Inferenz-Workloads ungewöhnlich gut vorhersehbar sind. Der direkte Kauf von H100-GPUs kann kosteneffizient sein. Eine einzelne GPU kostet etwa 25.000 bis 40.000 US-Dollar, während ein kompletter Server mit 8×H100 zwischen 200.000 und 400.000 US-Dollar kostet. Die Analyse von Lenovo zeigt, dass sich die Investition gegenüber AWS bereits im ersten Jahr amortisiert, wenn die tägliche Nutzungsdauer sechs oder mehr Stunden beträgt.
Der Grund dafür, dass diese Gewinnschwelle so schnell erreicht wird, liegt darin, dass KI-Inferenz-Workloads ungewöhnlich gut vorhersehbar sind. Im Gegensatz zum SaaS-Datenverkehr, der im Laufe des Tages Schwankungen unterliegt, verarbeiten KI-Produktionssysteme wie Empfehlungsmaschinen in der Regel ein konstantes Volumen an Anfragen.
Vorhersehbarkeit verändert die Wirtschaftlichkeit. Wenn die Infrastruktur mit konstanter Auslastung betrieben wird, lassen sich eigene Hardwarekosten effizient über die gesamte Workload verteilen. Es ist nicht mehr notwendig, Cloud für Spitzenkapazitäten zu zahlen, die von den Teams nur selten genutzt werden.
Für Unternehmen, die kontinuierlich Inferenzberechnungen durchführen, amortisieren sich die Hardware-Investitionen oft innerhalb von weniger als 12 Monaten. Ab diesem Zeitpunkt folgen die Einsparungen dem gleichen Muster, das von 37signals beschrieben wurde: Eine feste Infrastruktur ersetzt laufende Mietkosten.
- Der Speicherbedarf für Embedded-Systeme ist enorm
Selbst wenn die GPU-Rechenleistung optimiert würde, verursachen KI-Systeme eine weitere, rasch wachsende Kostenkomponente: den Speicherbedarf für Embeddings. Vektordatenbanken speichern hochdimensionale Einbettungen, die für die Suche, das Abrufen und Empfehlungen verwendet werden. Da Datensätze auf Millionen oder Milliarden von Datensätzen anwachsen, steigen die Speicheranforderungen rasch an.
Beispielsweise benötigen 10 Millionen Vektoren mit 1.536 Dimensionen mindestens 58 GB Rohspeicherplatz, oft sogar 200–300 GB einschließlich Indizes und Metadaten. Cloud wie Pinecone berechnen 0,33 $/GB/Monat, was bedeutet, dass 500 GB bereits vor der Durchführung von Abfragen 165 $/Monat kosten könnten. Selbst gehostete Lösungen wie PostgreSQL mit pgvector senken Cloud drastisch und behalten gleichzeitig sensible Daten unter direkter Kontrolle. Im Laufe der Zeit summieren sich diese Speicheranforderungen zusammen mit den GPU-Rechenkosten zu den Infrastrukturkosten, was die wirtschaftlichen Vorteile von selbst gehosteten oder hybriden Architekturen weiter verstärkt.
- Datensouveränität und Compliance sprechen fürDeployment On-Premises
Vorschriften zum Datenstandort und die allgemeine Einhaltung von Vorschriften haben im Bereich der KI oberste Priorität, da die Branche zunehmend reguliert wird. Insbesondere das EU-KI-Gesetz hat strenge Vorschriften für KI-Systeme eingeführt, darunter Verbote für bestimmte Anwendungsfälle von KI, die im Februar 2025 in Kraft getreten sind.Deployment On-Premises Deployment die Einhaltung der Vorschriften.
Für Finanzinstitute, die sich in einem komplexen regulatorischen Umfeld bewegen, bieten Lösungen wie die Actian Data Intelligence-Plattform dabei, Data Governance durchzusetzen Data Governance Compliance-Workflows zu optimieren.
Fallstudien zur Cloud : 37signals bestätigt
So radikal die finanzielle Transparenz Cloud von 37signals Cloud auch war, so war ihre Rückverlagerung doch kein Einzelfall. Sie war Teil eines wachsenden Trends bei vielen Unternehmen, die versuchen, die Kostenkontrolle zurückzugewinnen und ihre Cloud zu optimieren. Zahlreiche viel beachtete Fallstudien veranschaulichen das Ausmaß und die wirtschaftlichen Vorteile der Rückverlagerung von Workloads aus öffentlichen Clouds in eigene oder hybride Infrastrukturen.
Dropbox
Dropbox war bereits 2015 Vorreiter bei Cloud von Unternehmensdaten Cloud und schloss die Migration zwischen 2016 und 2018 ab. Das Unternehmen verlegte rund 90 % der Kundendaten, angeblich über 500 Petabyte, von AWS in drei eigene Colocation-Zentren. Die Investitionen in die Infrastruktur beliefen sich auf insgesamt 53 Millionen US-Dollar, doch Dropbox meldete laut seiner S-1-Einreichung von 2018. Ein kleiner Teil der Workloads, vor allem europäische Kunden und spezialisierte Dienste, verbleibt bei AWS. Intern war die Initiative unter dem Namen „Magic Pocket“ bekannt und veranschaulicht, wie ein gut umgesetzter Hybrid Cloud erhebliche Einsparungen erzielen und gleichzeitig langfristige Geschäftsziele unterstützen kann.
Ahrefs
Das SEO-Tool-Unternehmen Ahrefs nutzte eine Colocation-Lösung in Singapur mit 850 Servern. Die gemeldeten Einsparungen durch den Verzicht auf Cloud Public Cloud über einen Zeitraum von 2,5 Jahren Cloud rund 400 Millionen US-Dollar. Tatsächliche Infrastrukturkosten: 39,5 Millionen US-Dollar für 850 Server (~1.500 US-Dollar/Server/Monat), gegenüber geschätzten 447,7 Millionen US-Dollar bei einer vollständigen Hosting-Lösung auf AWS (~17.557 US-Dollar/Server/Monat). Wie Ahrefs es formulierte: „Wir wären nicht profitabel oder würden gar nicht existieren, wenn unsere Produkte zu 100 % auf AWS laufen würden.“ Während Kritiker argumentieren, dass Ahrefs die AWS-Schätzungen übertrieben habe, waren die Einsparungen unbestreitbar und verdeutlichten, dass die Herausforderungen Cloud mit sorgfältiger Planung in großem Maßstab bewältigt werden können.
GEICO
GEICO verbrachte ein Jahrzehnt damit, auf mehrere Cloud umzusteigen, doch die Kosten stiegen und übertrafen die Prognosen um das 2,5-Fache, sodass sie bis 2022 bei acht Anbietern insgesamt 300 Millionen US-Dollar erreichten. Als Reaktion darauf begann GEICO, Workloads Cloud OpenStack und Kubernetes in eine Private Cloud zu verlagern, mit dem Ziel, bis 2029 über 50 % der Ressourcen zurückzuführen. Erste Ergebnisse zeigen eine Reduzierung der Rechen- und 60 % Reduzierung der Speicherkosten pro Gigabyte im Vergleich zu öffentlichen Cloud , was verdeutlicht, wie eine Hybrid Cloud Effizienz, Compliance und die Ausrichtung auf langfristige Geschäftsziele gewährleisten kann.
Akamai
Akamai war auf dem auf dem Weg, über 100 Millionen Dollar für Cloud von Drittanbietern ausgeben, bevor das Unternehmen seine Rechen-Workloads auf sein eigenes globales Edge-Netzwerk mit mehr als 350.000 Servern migrierte. Die Migration brachte Einsparungen von rund 100 Millionen US-Dollar pro Jahr, was die Wirtschaftlichkeit einer Rückverlagerung belegt, wenn die vorhandene Infrastruktur und die erforderliche Skalierung zusammenpassen.
All diesen Fällen ist das gleiche wirtschaftliche Muster gemeinsam, das von 37signals dokumentiert wurde: Vorhersehbare Arbeitslasten mit hohem Volumen lassen sich auf einer eigenen Infrastruktur letztendlich kostengünstiger betreiben als in den Clouds der Hyperscaler.
Diese Beispiele spiegeln einen allgemeinen Wandel wider, der sich in den Strategien zur Unternehmensinfrastruktur vollzieht. Umfragen unter den Chief Information Officers (CIOs) von Barclays zeigen, dass Cloud in den letzten Jahren zugenommen hat, wobei die Stimmung in der zweiten Hälfte des Jahres 2024 ihren Höhepunkt erreichen wird: 86 % der CIOs planen eine Rückverlagerung.
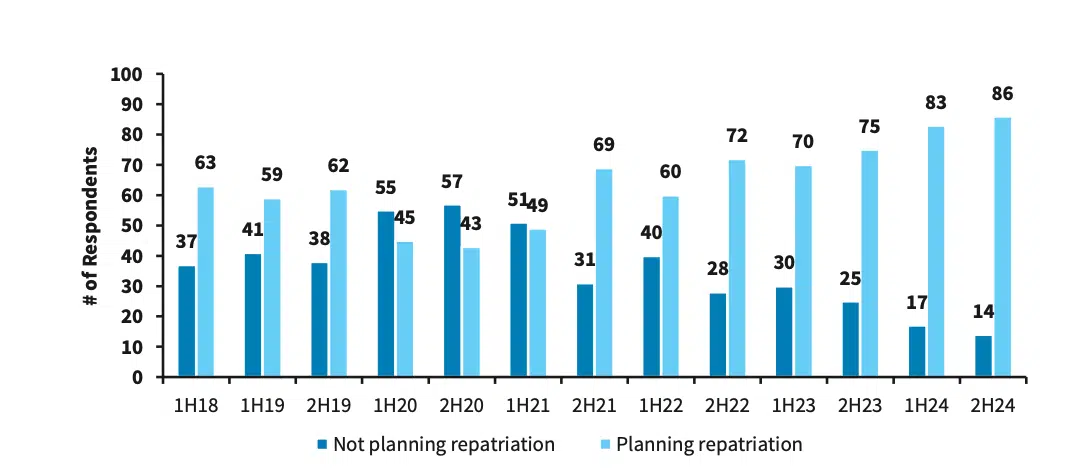
Laut einer Umfrage von Barclays unter CIOs planen 86 % der CIOs Cloud
Diese Statistik bedeutet jedoch nicht, dass Unternehmen öffentliche Cloud vollständig aufgeben. Laut IDCbefürworten nur 8–9 % der Unternehmen eine vollständige Rückführung, während die meisten einen hybriden Ansatz bevorzugen, der öffentliche und private Clouds kombiniert. Cloud ermöglicht es Unternehmen, Workload zu optimieren, indem sie sensible Daten und geschäftskritische Anwendungen strategisch On-Premises bereitstellen On-Premises öffentliche Cloud für weniger kritische Workloads nutzen. Daher wird es für Teams, die ähnliche Umstellungen in Betracht ziehen, immer wichtiger, die Feinheiten von hybrider Bereitstellungen und der damit verbundenen Risiken zu verstehen.
Statistiken Cloud
Cloud nimmt zu, während Cloud für öffentliche Cloud weiter steigen. IDC prognostiziert, dass Cloud weltweiten Cloud öffentliche Cloud im Jahr 2028 1,6 Billionen US-Dollar erreichen werden, was einer Verdopplung gegenüber der Prognose für 2024 entspricht. Doch wie bereits erwähnt, planen 86 % der CIOs laut Barclays irgendeine Form der Rückverlagerung laut Barclays. Beide Trends können zutreffen, da es sich hierbei weniger um einen Cloud als vielmehr um eine Neugewichtung handelt. Unternehmen tendieren zu einem Cloud .
KI dürfte diesen Wandel beschleunigen. KI-Workloads machen derzeit weniger als 10 % der gesamten Cloud aus, doch prognostiziert Gartner , dass dieser Anteil bis 2029 auf fast 50 % steigen wird. Hyperscaler reagieren darauf mit enormen Kapitalinvestitionen. Es wird geschätzte Infrastrukturausgaben in Höhe von 600 Milliarden US-Dollar im Jahr 2026 veranschlagt, wobei etwa drei Viertel davon auf KI entfallen. Die Annahme ist klar: Unternehmen werden diese GPU-Kapazität mieten. Die Berechnungen von 37signals deuten jedoch darauf hin, dass, sobald KI-Workloads vom Experimentierstadium in den regulären Produktionsbetrieb übergehen, die Wirtschaftlichkeit des Eigentums an Bedeutung gewinnt.
Der Kostendruck beeinflusst bereits das Verhalten. Flexera berichtet, dass 27 % der Cloud verschwendet oder nicht voll ausgelastet sind, und 21 % der Workloads bereits zurückverlagert wurden. Als Hauptgrund werden Kosten genannt, die die Prognosen übersteigen, gefolgt von Bedenken hinsichtlich der Leistung. Bei GPUs ist der Spielraum für Ineffizienz geringer. Es gibt weniger Optimierungshebel, höhere Stundensätze und einen schnelleren Budgetverbrauch.
Die Regulierung sorgt für eine weitere Ebene. Das EU-KI-Gesetz, DORA für Finanzdienstleistungen, Chinas PIPL und Indiens DPDP verschärfen Data Governance . Mimecast berichtet , dass 87 % der Unternehmen die Datenhoheit mittlerweile bei der Auswahl von Anbietern berücksichtigen. Bei KI-Systemen erstreckt sich die Hoheit über den Datenstandort hinaus auf die Herkunft der Modelle, Protokolle und Compliance-Dokumentation.Deployment On-Premises Deployment die regulatorische Komplexität, zentralisiert jedoch die Kontrolle, und für viele Unternehmen wird diese Einfachheit strategisch attraktiv.
Ein Balkendiagramm, das zeigt, warum Unternehmen Gewinne ins Inland zurückführen
Die Gegenargumente und wann Cloud die Oberhand behalten
Nicht alle Beobachter sind der Meinung, dass Cloud für jedes Unternehmen der beste Weg ist. Öffentliche Cloud bieten unter bestimmten Umständen nach wie vor Vorteile. Im Falle von KI-Workloads sind diese Argumente jedoch oft nicht stichhaltig.
Wann Cloud – und wann On-Premises
| Komponente | Cloud | Vorteil der lokalen Installation |
| Workload | Bewältigt sprunghafte oder unvorhersehbare Arbeitslasten | Vorhersehbare Workloads lassen sich kostengünstiger selbst hosten |
| Kompetenz des Teams | Erfordert nur minimale in-house | Kompetente IT-Teams können Prozesse optimieren und die Abhängigkeit von Anbietern verringern |
| Umfang und Wachstum | Schnelles Wachstum und weltweite Expansion | Vorhersehbares Wachstum ermöglicht kosteneffiziente Hardware |
| Gesetzliche Vorschriften | Verwaltete Compliance, geografische Redundanz | Eine direkte Kontrolle vereinfacht die Angleichung an die Vorschriften |
| Kosten und Margen | Das Pay-as-you-go-Modell reduziert die Vorabkosten | Langfristige Einsparungen durch eigene Infrastruktur |
| Servicequalität | Cloud gewährleisten Verfügbarkeit und Leistung | Speziell zugewiesene Ressourcen garantieren eine verlässliche Verfügbarkeit |
Das Argument der Cloud Nutzung“ Cloud
Jeremy Daly, ein Verfechter der Serverless-Technologie, argumentiert, dass „37signals die Cloud genutzt hat.“ Indem sie Cloud als virtuelle Colocation behandelten und dort VMs und Kubernetes betrieben, zahlten sie Cloud , ohne den Wert von Serverless, Managed Services und sofortiger Skalierung zu nutzen. Wie Daly bemerkt: „In der Cloud sollten wir Dienste mieten, nicht Server.“
Für SaaS-Workloads mit stark schwankendem oder sprunghaftem Datenverkehr ist dieses Argument überzeugend. Dank serverloser Infrastruktur können Unternehmen ihre Kapazitäten sofort skalieren und zahlen nur für die tatsächlich genutzte Rechenleistung.
KI-Inferenz-Workloads verhalten sich jedoch oft ganz anders. Produktions-Inferenzsysteme wie Empfehlungsmodelle, Copilots und Pipelines zur Dokumentenverarbeitung laufen in der Regel mit einer konstanten, gleichbleibenden Auslastung und nicht in unvorhersehbaren Spitzen. In diesen Fällen schwindet der wirtschaftliche Vorteil der elastischen Cloud . Der Aufpreis für Spitzenkapazität bleibt zwar bestehen, doch die Workload benötigt diese Spitzenkapazität nur selten.
Daly’s Argument gilt daher für variable SaaS-Workloads, bei denen Elastizität von entscheidender Bedeutung ist. Bei dauerhaften KI-Inferenz-Workloads, die mit hoher Auslastung laufen, kann es kosteneffizienter sein, eine Prämie für selten genutzte Spitzenkapazität zu zahlen, als auf dedizierte Infrastruktur oder Hybrid-Bereitstellungen zu setzen.
Umfassende Kostenanalyse
Einige Kritiker stellen zudem die finanziellen Annahmen hinter dem Ansatz von 37signals in Frage. Sie weisen darauf hin darauf hin, dass Hardware und Software normalerweise nur etwa 20 % der IT-Kosten ausmachen, während der Rest für Strom, Kühlung, physische Sicherheit, Rack-Einrichtung, unterbrechungsfreie Stromversorgung (USV) und Opportunitätskosten anfällt. Die Analyse von David Heinemeier Hanson berücksichtigte nicht alle diese Gemeinkosten, da 37signals Colocation-Einrichtungen anstelle von eigenen Rechenzentren nutzte. Dennoch lässt sich angesichts der Zahlen von 37signals der Schluss ziehen, dass die Anmietung von Colocation-Flächen immer noch weitaus günstiger sein kann als die Nutzung von Cloud .
Kompetenz vs. Wachstum – Framework
Forrest Brazeals Framework „IT-Kompetenz versus Wachstumsambitionen“ liefert zusätzliche Nuancen. Er ordnet 37signals in das Quadrant „Hohe Kompetenz/Geringes Wachstum“ , ideal für Selbsthosting. „Nicht jedes Unternehmen verfügt über die Kompetenz (hoch) oder die Wachstumsambitionen (niedrig) von 37signals“, stellt er fest. Startups mit ungewissen oder sprunghaften Arbeitslasten Nutzen Cloud , aber KI-Unternehmen, die Inferenz in großem Maßstab betreiben, verbinden oft hohe operative Kompetenz mit stetigem Wachstum. Solche Profile (stetiges Wachstum & hohe Kompetenz) eignen sich gut für die Rückverlagerung.
Anwendung des Playbooks auf die KI-Infrastruktur
Während 37signals den wirtschaftlichen Rahmenplan lieferte, macht die KI-Infrastruktur die wirtschaftlichen Aspekte greifbarer. Die Entscheidung ist nicht mehr abstrakt. Sie wird zu einer strukturierten Bewertung, die auf Workload , der Auslastung und den regulatorischen Risiken basiert.
Ein praktischer Framework mit vier Fragen Framework , die Logik von 37signals in KI-Begriffe zu übersetzen:
1. Ist Ihr Workload und beständig?
Im Gegensatz zu den Traffic-Spitzen bei SaaS-Diensten verarbeiten die meisten KI-Systeme in der Produktion, wie Empfehlungsmaschinen, RAG-Pipelines oder Betrugserkennung , konstante Datenmengen mit allmählichem Wachstum.
2. Liegen die prognostizierten GPU-Auslastungsraten über 60–70 %?
Ab diesem Schwellenwert liegen die Abschreibungskosten für eigene Hardware in der Regel bereits im ersten Jahr unter den Preisen Cloud öffentlichen Cloud .
3. Verarbeiten Sie mehr als 10 bis 50 Millionen Abfragen pro Monat?
In dieser Größenordnung summieren sichabfragen pro Token undabfragen bei Cloud schnell.
4. Sind Sie mit Anforderungen hinsichtlich der Datenhoheit oder strengen Compliance-Vorgaben konfrontiert?
Bei Workloads in den Bereichen Finanzdienstleistungen, Gesundheitswesen oder öffentliche Verwaltung können gesetzliche Vorschriften dazu führen, dass die Entscheidung zugunsten kontrollierter Umgebungen ausfällt.
Wenn drei oder vier dieser Fragen mit „Ja“ beantwortet werden, sprechen die wirtschaftlichen Aspekte der Rückführung eher fürDeployment On-Premises Deployment die Inferenz in der Produktion.
Entscheidungsmatrix
| Workload | Empfohlene Systemvoraussetzungen | Begründung |
| Modell Training | Öffentliche Cloud | Rechenintensiv; Cloud bewältigen Spitzenauslastungen kosteneffizient |
| Experimentieren und Prototypenentwicklung | Öffentliche Cloud | Flexible, schnelle Bereitstellung für Iterationen in der Anfangsphase |
| Schlussfolgerung zur Produktion | On-Premises Hybrid | Konstante Auslastung; eigene Hardware ist bei einer GPU-Auslastung von 60–70 %+ kostengünstiger |
| Vektorspeicherung (Einbettungen) | On-Premises | Reduziert wiederkehrende Kosten für Managed Services und gewährleistet die Kontrolle über die Daten |
Das hybride KI-Modell
In der Praxis entscheiden sich die meisten KI-Unternehmen für ein Hybridmodell statt für einen vollständigen Umstieg. Das Training findet weiterhin in der Cloud statt. Die Inferenz wird hingegen näher an die eigene Infrastruktur verlagert.
Lenovo hat dokumentiert, , dass Training 3.1 im Hyperscale-Maßstab (39,3 Millionen GPU-Stunden) in der Cloud von über 483 Millionen US-Dollar Cloud . Genau bei dieser Art von elastischer, kurzfristiger Skalierung Cloud Public Cloud . Bei der Inferenz sieht es anders aus. Sobald ein Modell trainiert ist, wird sein Betrieb über drei bis fünf Jahre hinweg zu einer beständigen, vorhersehbaren Aufgabe. Hier hat die amortisierte Hardware-Ökonomie die Oberhand.
Diese geteilte Architektur verringert zudem das Risiko bei der Datenmigration. Anstatt ganze KI-Pipelines auf einmal zu verlagern, können Unternehmen Produktions-Inferenz-Workloads schrittweise migrieren, während Experimente und Training in der Anfangsphase weiterhin Training Cloud verbleiben. Ein kontrollierter, schrittweiser Migrationsprozess minimiert Betriebsunterbrechungen und gewährleistet gleichzeitig eine nahtlose Integration zwischen Training Cloud Training On-Premises .
Die Ökonomie selbst gehosteter Inferenzmodelle
Die Wirtschaftlichkeit einer selbst gehosteten Inferenz hängt stark von der Auslastung und dem Token-Volumen ab. Laut Deployment in Unternehmen kostet ein Modell mit 7 Milliarden Parametern, das auf einer H100-GPU bei einer Auslastung von etwa 70 % läuft , kostet etwa 10.000 US-Dollar pro Jahr für Spot-Nodes oder Hardware-Abschreibungen. Die Stromkosten belaufen sich auf etwa 300 US-Dollar pro Jahr, womit sich die Gesamtkosten auf etwa 10.300 US-Dollar belaufen.
Öffentliche LLM-APIs hingegen berechnen in der Regel pro Million Token, wobei die Preise für Unternehmen im Jahr 2025 je nach Modellstufe und Anbieter zwischen 0,25 und 15 US-Dollar pro Million Eingabetoken und zwischen 1,25 und 75 US-Dollar pro Million Ausgabetoken liegen.
Bei geringer Auslastung sind APIs weiterhin die wirtschaftlichere Option, da die Infrastruktur ungenutzt bleibt. Mit steigendem Arbeitsaufkommen ändert sich die Wirtschaftlichkeit jedoch. Branchenanalysen deuten darauf hin, dass Deployment selbst gehostete Deployment ab etwa zwei Millionen Token pro Tag rentiert; danach verteilen sich die Fixkosten der eigenen Infrastruktur auf ein großes Inferenzvolumen.
Bei hohem Datenaufkommen kann eine selbst gehostete Inferenz die Kosten um bis zu 78 % senken. Die Analyse von Artefact ergab eine Gewinnschwelle bei etwa 8.000 Konversationen pro Tag. Unterhalb dieser Schwelle sind verwaltete Cloud weiterhin wirtschaftlicher. Oberhalb dieser Schwelle sorgen eigene Systeme für zusätzliche Einsparungen. Das Muster spiegelt das von 37signals wider: Vorhersehbare Workload hohe Auslastung ergibt eine schnelle Amortisation.
Vektordatenbanken
Instacart hat dokumentiert, die Migration von Elasticsearch plus FAISS zu PostgreSQL mit pgvector und erzielte dabei Kosteneinsparungen von 80 % sowie eine 10-fache Reduzierung der Schreibamplifikation. Die pgvectorscale-Benchmarks von Timescale zeigen etwa 75 % niedrigere Kosten als bei verwalteten Vektordiensten wie Pinecone bei vergleichbarer Leistung.
Bei RAG-Systemen, die monatlich Millionen von Abfragen verarbeiten, führt eine selbst gehostete Vektorinfrastruktur zu Einsparungen, die dem Fall von 37signals mit S3 ähneln: Hohe wiederkehrende Speicherkosten werden durch abgeschriebene Hardware und Open-Source-Tools ersetzt.
Datenhoheit als struktureller Treiber
Grandview Research berichtet, dass der Cloud für souveräne Cloud im Jahr 2025 einen Wert von 648,87 Milliarden US-Dollar hatte und bis 2033 voraussichtlich 648,87 Milliarden US-Dollar erreichen wird. Außerdem laut Gartnerwird erwartet, dass bis 2028 rund 60 % der Finanzunternehmen außerhalb der Vereinigten Staaten auf souveräne oder On-Premises umsteigen werden.
Rahmenwerke wie das EU-KI-Gesetz, Chinas PIPL und Indiens DPDP schreiben Datenlokalisierung und Rückverfolgbarkeit vor. Für Organisationen, die sensible Training oder proprietäre Inferenzprotokolle verarbeiten, erfülltDeployment On-Premises Deployment die Anforderungen an den Datenaufbewahrungsort, da die Daten die Grenzen des jeweiligen Rechtsraums nie verlassen.
Die Quintessenz
37signals hat gezeigt, dass Teams, die sich mit Cloud befassen, Entscheidungen anhand konkreter Zahlen messen, modellieren und begründen können. Mit einer KI-Infrastruktur lassen sich die wirtschaftlichen Vorteile noch deutlicher machen. Wenn Cloud Basecamp etwa 10 Millionen Dollar eingespart hat, könnte ein vergleichbares KI-Unternehmen, das Produktionsinferenz in ähnlichem Umfang betreibt, ein Vielfaches dieses Betrags einsparen, da die Kosten für GPU-Rechenleistung und die Einbettungsinfrastruktur deutlich höher sind.
Für Unternehmen, die sich dafür entscheiden, KI-Workloads in kontrollierten Umgebungen auszuführen, bieten Plattformen wie Actian VectorAI DB eine speziell entwickelte Vektordatenbank, die für umfangreiche Vektorsuchen und KI-Inferenz-Workloads ausgelegt ist. Sie kann On-Premises in der Cloud bereitgestellt werden, sodass Unternehmen die Vektorinfrastruktur dort platzieren können, wo sie ihren betrieblichen und wirtschaftlichen Anforderungen am besten entspricht.
Werden Sie Teil der Community und erfahren Sie mehr über Actian.

Bleiben Sie in Verbindung
Datenanalysen, die Ihnen geliefert werden.
(z. B. sales@..., support@...)