Actian Vector Data Ingestion





Action Vector 7.0 is renamed to Actian Analytics Engine beginning with version 8.0
The usefulness of an analytic database is closely tied to its ability to ingest, store, and process vast quantities of data. Data is typically ingested from multiple sources such as operational databases, CSV files, and continuous data streams. In most cases, daily data loads are measured in tens or hundreds of millions of rows, so the traditional SQL INSERT mechanism is not well-suited for these data volumes.
In this blog post, we’ll look at Actian Vector, our columnar database ideally suited for analytic applications, and evaluate a variety of CSV data ingestion options that operate at the required data rates. In future posts, we’ll examine Actian VectorH executing in a Hadoop environment and ingestion from streaming data sources.
The purpose of this exercise is not to benchmark data ingestion performance but to evaluate the relative speed of various methods in the same hardware environment. We’ll evaluate SQL INSERT as a baseline, SQL COPY TABLE, command line vwload, and ETL/workflow tools Pentaho Data Integration (aka Kettle), Talend Open Studio for Data Integration, and Apache NiFi. Talend and Pentaho are traditional ETL tools that have evolved to include a variety of bulk loaders and other so-called big data tools and technologies; both are based on the Eclipse UI. NiFi was open-sourced to the Apache Foundation by the U.S. National Security Agency (NSA) and is a general-purpose tool for automating the flow of data between software systems; it utilizes a web-based user interface.
All three implement some concept of a directed graph with data flowing from one operator to the next with operators executing in parallel. Pentaho and Talend have community and subscription editions while NiFi is open source from Apache.
The Vector server is a desktop class AMD Opteron 6234 hex core processor, 64 GB memory and SATA spinning disks (hardware cost ~ $2,500) running single node Vector version 5.0.
For a basis of comparison, we’ll be inserting approximately 24 million records into the TPCH benchmark lineitem table. The structure of this table is:
l_orderkey bigint NOT NULL, l_partkey INT NOT NULL, l_suppkey INT NOT NULL, l_linenumber INT NOT NULL, l_quantity NUMERIC(19,2) NOT NULL, l_extendedprice NUMERIC(19,2) NOT NULL, l_discount NUMERIC(19,2) NOT NULL, l_tax NUMERIC(19,2) NOT NULL, l_returnflag CHAR(1) NOT NULL, l_linestatus CHAR(1) NOT NULL, l_shipdate DATE NOT NULL, l_commitdate DATE NOT NULL, l_receiptdate DATE NOT NULL, l_shipinstruct CHAR(25) NOT NULL, l_shipmode CHAR(10) NOT NULL, l_comment VARCHAR(44) NOT NULL
SQL INSERT
As Vector is ANSI SQL compliant, perhaps the most obvious ingestion mechanism is the standard SQL INSERT construct. This is generally the least performant option as it results in singleton insert operations. Inserts can be optimized to some extent by making use of parameterization and inserting records in batches, but even that may not provide the level of performance required.
For the SQL INSERT test, we’ll construct a simple Pentaho workflow with two steps, one to read the CSV data file and the other to insert those rows into a Vector database. We’ll also execute the workflow on the same node as the Vector instance as well as a remote node to gauge the effect of network overhead.

In this situation, loading from a remote node performs marginally better than loading from the local node and performance generally improves with an increasing batch size up to roughly 100K records and then flattens out. This is not to suggest that 100K is always the optimal batch size; it most likely varies based on the row size.
Vector COPY TABLE
The Vector COPY TABLE construct is used to bulk load data from a CSV file into the database. If executed from a remote node, this approach requires a Vector Client Runtime installation, namely Ingres Net and the Ingres SQL terminal monitor. The Client Runtime is freely available and has no licensing requirements. Both Pentaho and Talend have built in support for this construct, although the implementation is slightly different. Pentaho uses named pipes to flow data into the operator while Talend creates an intermediate disk file and then calls the operator.
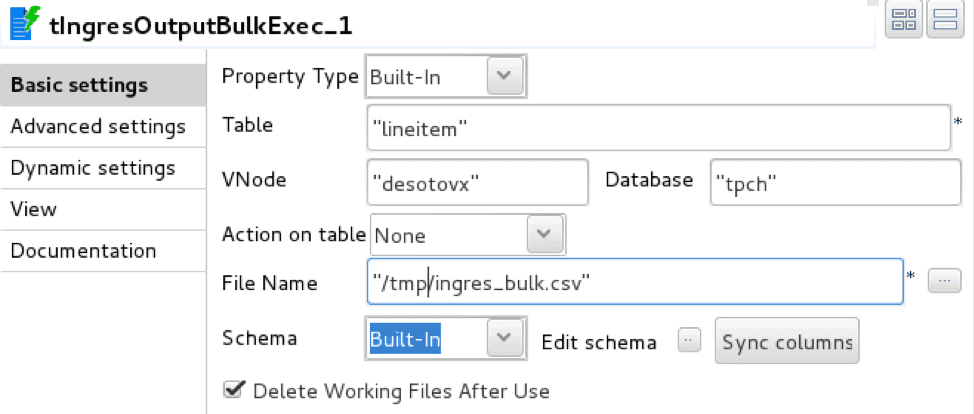
The Talend implementation makes use of two operators, tFileInputDelimited, delimited file reader, and tIngresOutputBulkExec, Ingres/Vector COPY TABLE loader

The loader is configured with database connection details, target table, and intermediate staging file.
The Pentaho implementation uses two equivalent operators, CSV file input, delimited file reader, and Ingres VectorWise Bulk Loader, database table loader.

The loader is configured with a Vector connection and target table. Unlike Talend, the Pentaho loader does not use an intermediate staging file.

Performance for both tools is essentially the same but on the order of 6x faster than SQL INSERT. Apache NiFi does not provide native Vector COPY TABLE support and simulating this approach by launching the terminal monitor separately and connecting with named pipes is relatively cumbersome.
Vector vwload
The Vector supplied vwload utility is a high-performance bulk loader for both Actian Vector and VectorH. It is a command line utility designed to load one or more files into a Vector or VectorH table from the local filesystem or from HDFS. We’ll explore the HDFS variant in a future post.
Vwload can be invoked standalone or as the data load mechanism for the workflow streams generated by Pentaho, Talend, or NiFi. Pentaho has built-in vwload support while Talend and NiFi provide a mechanism to direct workflow data streams to vwload without first persisting to disk.
The Talend implementation uses the tFileInputDelimited to read the source CSV file and tFileOutputDelimited to write the source file rows to a named pipe. To load the data stream into Vector we need to execute vwload with the same named pipe as the source file.
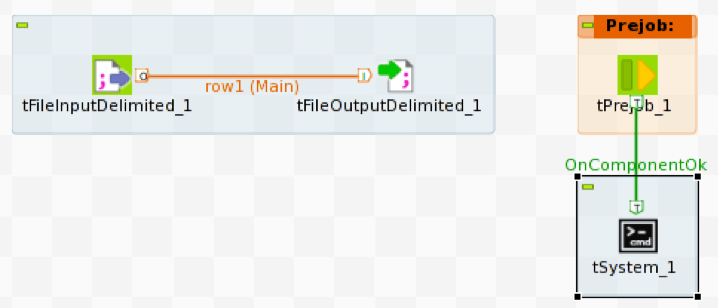
To start vwload we use the Prejob construct to trigger the tSystem operator, tSystem is the mechanism to execute OS level commands or shell scripts. The Prejob operator is triggered automatically at job start before any other workflow operator and is configured to trigger the tSystem operator.
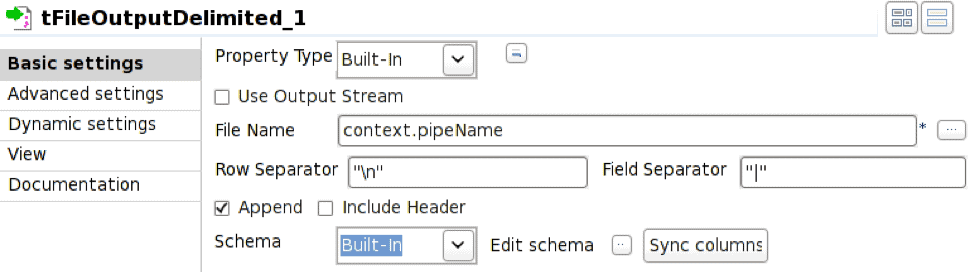
The tFileOutputDelimited operator is configured to write to the named pipe defined by the environment variable context.pipeName. The named pipe must exist at job execution time and Append needs to be checked.
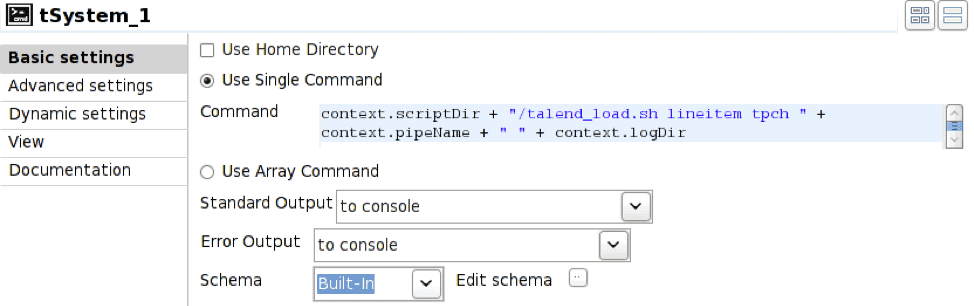
In this case the tSystem operator executes shell script talend_load.sh passing parameters for table name, database name, pipe name, and resulting log file directory. The context. notation is the mechanism for referencing environment variables associated with the job; this allows jobs to be parameterized. The shell script is:
#!/bin/bash nohup vwload -m -t $1 $2 $3 > $4/log_`date +%Y%m%d_%H%M%S`.log 2>&1 &
The resulting execution sequence is:
- Execute Prejob operator
- Prejob triggers tSystem operator
- tSystem operator executes shell script
- Shell script launches vwload in the background and returns; vwload is now reading from the named pipe waiting for rows to arrive
- Start tFileInputDelimited to read rows from the source file
- Start tFileOutputDelimited to receive incoming rows and write to named pipe
The Pentaho implementation uses the CSV file input and Ingres VectorWise Loader operators as in the COPY TABLE case, but bulk loader is configured to use vwload instead.
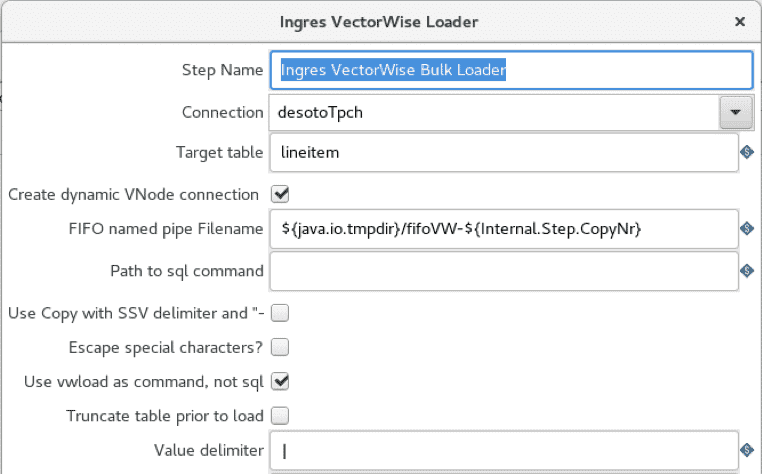
The “use vwload” option is selected, and the “Path to sql command” field is blanked out. This is the way to invoke the vwload utility.
The Apache NiFi implementation makes use of three operators: GetFile, which is a directory listener, FetchFile, which reads the actual file, and ExecuteStreamCommand, which passes the file streaming data to the background vwload process.
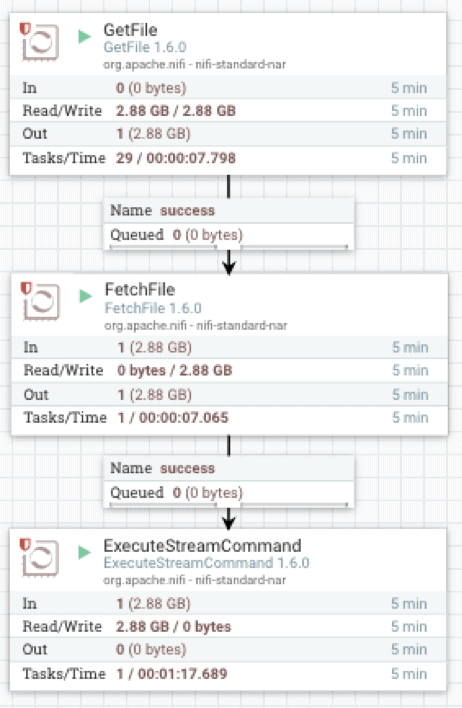
FetchFile feeds the source data stream to ExecuteStreamCommand, which is configured to execute a shell script.
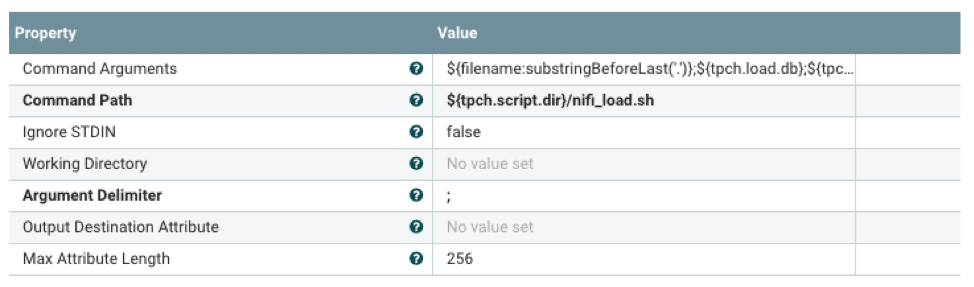
The shell script will launch vwload in the background and direct the data stream to vwload via a named pipe. The ${} notation is the mechanism to reference properties configured with an external properties file. This allows flow processor configuration at runtime.
#!/bin/bash tableName=$1 dbName=$2 loadPipe=$3 logDir=$4 echo "`date +%Y-%m-%d\ %H:%M:%S` vwload -m -t $tableName db $dbName $loadPipe " >> $logDir/load.log vwload -uactian -m -t $tableName $dbName $loadPipe >> $logDir/load.log 2>&1 & cat /dev/stdin >>$loadPipe
Command line vwload is used as the load mechanism in the preceding Pentaho, Talend, and NiFi workflows. As a point of comparison, we also load the same dataset using standalone vwload on the local Vector machine as well as from the remote client using Ingres Net.

Specific elapsed times and ingestion rates will vary widely based on hardware and row size.
In summary, data ingestion options, in order of increasing performance, are SQL INSERT, SQL COPY TABLE, and vwload. For significant data volumes, vwload used with the appropriate ETL tool is generally the right choice. ETL tool choice is typically driven by performance and functionality. At a minimum, there should be a mechanism to interface with the ingestion method of choice. Functionality requirements are mainly driven by the amount and type of transformation that needs to be performed on the incoming data stream. Even if incoming data is to be loaded as is, an ETL tool can still be useful for incoming file detection, job scheduling, and error reporting.
The workflows above are the trivial case for CSV file ingestion, typically just reading a source data file and loading into Vector. As such they also represent the best-case performance for each of the ingestion methods. Most real-life use cases will involve some degree of transformation logic in the workflow, with data flow rates decreasing as a function of transformation complexity. Measuring the workflow data rates allows us to select the ingestion method that meets those requirements.
Learn More About Actian Vector
You can learn more about Actian Vector by visiting the following resources:
Learn more about our Actian Vector community editions on:
Stay connected
Data insights delivered to you.
(i.e. sales@..., support@...)