What is Meant by an ETL Pipeline?
The ETL pipeline describes the components of a data pipeline that extracts source data, transforms it, and loads it into a target data warehouse.
Why Use ETL Pipelines?
ETL pipelines connect and automate data extraction, transformation and loading operations from data sources to a destination data warehouse. The key attribute is that it can be managed as a single end-to-end process.
What is a Data Pipeline?
A data pipeline is a broader process than ETL in that it describes general data movement beyond just ETL, such as setting up a data lake as an intermediate repository of raw data in a high-performing data store. For example, a complex data pipeline can be used to extract raw data from many operational systems into a staging data lake. An ETL process can then be used to transform and load the staged data into a data warehouse for data analysis or used to help train machine learning models.
What is the Difference Between ETL Pipeline and Data Pipeline?
An ETL process can be a subset of a more extensive data pipeline. Unlike ETL, parts of the broader data pipeline can consolidate data without any transformation to an intermediate destination such as a Hadoop data lake. For example, you may want to consolidate mainframe, CRM and website logs into a staging data lake on AWS S3 storage. Then, use an ETL process to extract the merged S3 data lake data into a series of data transformations before loading the analytics-worthy data into a data warehouse. This is where a data visualization tool like Tableau can be used to gain business insights.
How to Build an ETL Pipeline in Python
An ETL pipeline can be hand-scripted using Python or used to invoke operators from tools that support ETL. Data engineers commonly use Python to create ETL pipelines. This task is made easier using tools such as Luigi and open-source Apache Airflow to manage workflows. FTP or local file copy operations can be used to move data. Actian DataConnect jobs can be invoked from Python and used to profile, extract, transform, and load data.
Pygrametl is an open-source Python ETL framework that can represent dimension and fact tables as Python objects. To build an ETL pipeline in Pygrametl, follow these steps:
- Import data from form source files into Pygrametl dimension and fact tables.
- Use the psycopg2 Python module to connect to the target data warehouse.
- Use the SQLSource module to embed SQL SELECT statements into the Python source used to extract data.
- Perform data transformation on the extracted data one row at a time and insert the transformed data into the destination data warehouse.
Apache Airflow can be used to create ETL workflows by composing a directed acyclic graph (DAG), which expresses the relationships and dependencies between the ETL tasks.
With Airflow, you import the necessary libraries and define the default arguments for each task in the DAG. The DAG object definition can include parameters to schedule the owner, exception handling execution interval and retries.
Actian DataConnect is a comprehensive and scalable solution for building and operating sophisticated ETL pipelines. You can use its visual, point-and-click interface to connect, profile, clean, and map data sources to targets and build process workflows based on business rules. Once built, templated ETL pipelines can be reused. ETL pipelines can be run, monitored, and managed no matter where they are deployed, whether in Actian’s Cloud, your VPC, data center, or an embedded service.
Actian DataFlow can be used to create ETL pipelines. DataFlow uses an extended JavaScript dialect to orchestrate a series of data manipulation operations.
Below is an example of a DataFlow application for data extraction and transformation. These are the steps to take:
- Create a schema that defines the structure of the data to be read.
- Create a file reader and set the properties on the reader.
- Create a filter operator for the data that was read, defining the filter condition as a predicate expression.
- Handle the data that passes the filter condition by writing it to a local file.
- Handles the data that fails the filter condition by writing it to another local file.
- Explicitly executes the composed DataFlow application, providing a name that will be useful for debugging and profiling.

Actian DataFlow provides the following field-level data transformation operators:
- DeriveFields operator to compute new fields.
- DiscoverEnums operator to discover enumerated data types.
- MergeFields operator to merge fields.
- RemoveFields operator to remove fields.
- RetainFields operator to retain fields.
- SelectFields operator to select fields.
- RemapFields operator to rename fields.
- SplitField Operator to Split Fields.
- RowsToColumns Operator to Convert Rows to Columns (Pivot).
- ColumnsToRows Operator to Convert Columns to Rows (Unpivot).
Actian DataFlow provides data loaders that can directly load the Actian Data Platform as a stream from HDFS file types such as Apache AVRO. When using the direct load capability, the data is streamed from the input port directly into the Vector engine. Direct loading can run in parallel and supports execution within a cluster environment such as Hadoop. Direct loading can be used to copy data from HDFS into an Actian Data Platform instance. When run within a Hadoop cluster, the reading of the data, formatting and sending to the Actian Data Platform operations are run in a distributed environment, taking full advantage of the Hadoop resources.
What are the Benefits of ETL Pipelines?
- Deliver accurate, consistent data where your business needs it.
- ETL workflows can be managed and executed as a unit to reduce administration costs.
- Workflows can be templated to scale across a business, reduce learning times and errors.
- Tools such as DataConnect provide a low code data integration platform to deploy more complex use cases faster.
- Enforce data quality standards.
- Standardize ETL pipelines to tap into more reliable and governed data.
- Data integration tools like DataConnect provide a comprehensive library of pre-built connectors.
- Data can be profiled early in the pipeline to maintain higher data quality for confident downstream decision-making.
- Schedule data movements to match the requirements of source data sets and target data warehouses.
- ETL pipelines can be used as components within larger data pipelines.
What is an ETL Pipeline?
We need high-quality data in a database to perform useful data analytics. Getting raw data from more than one source into a form that supports business decisions uses a three-step Extract, Transform, and Load process, also known as ETL.
Learn more about the suite of Actian products and solutions and how they can help your business handle data management headaches.
Actian and the Data Intelligence Platform
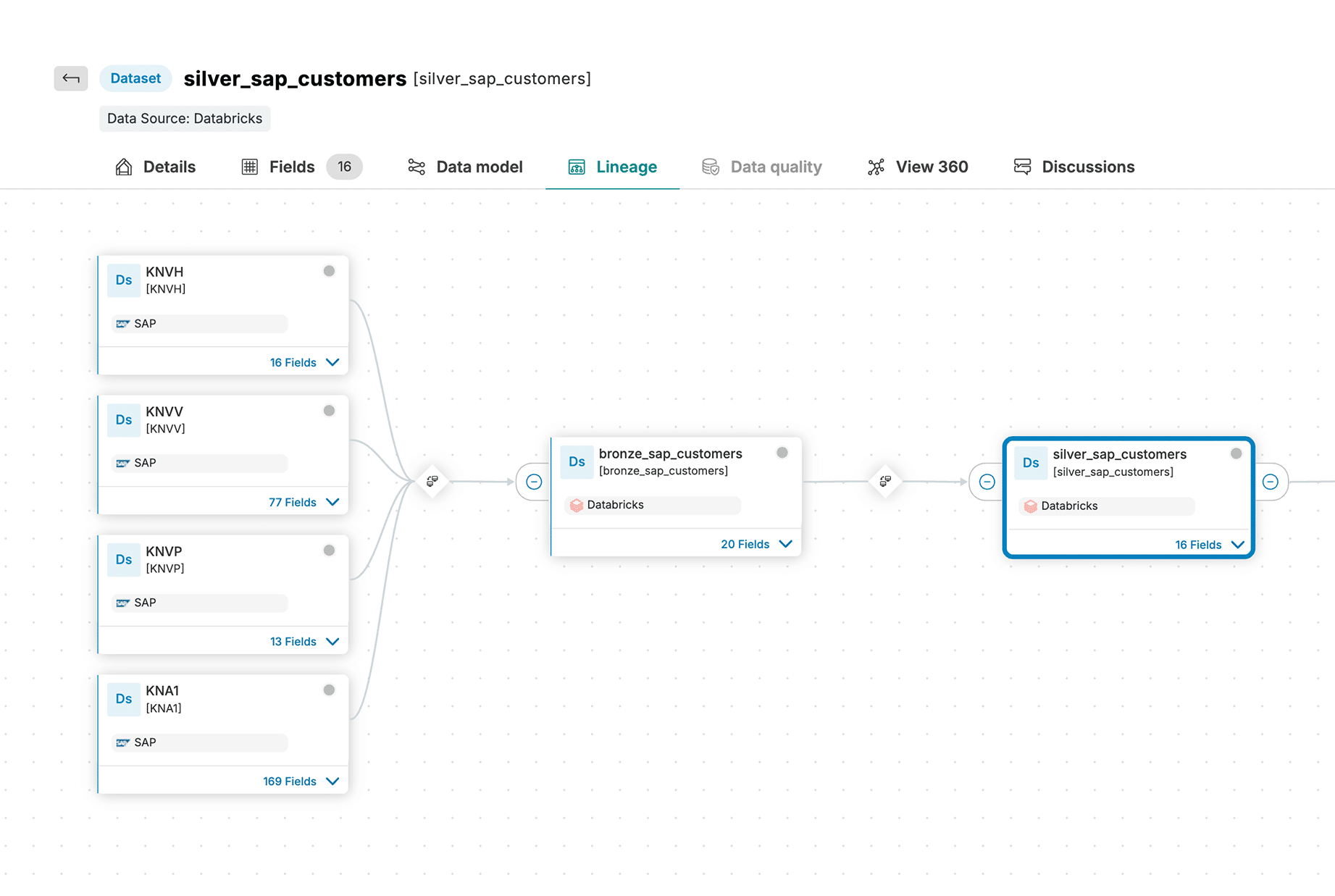
Actian Data Intelligence Platform is purpose-built to help organizations unify, manage, and understand their data across hybrid environments. It brings together metadata management, governance, lineage, quality monitoring, and automation in a single platform. This enables teams to see where data comes from, how it’s used, and whether it meets internal and external requirements.
Through its centralized interface, Actian supports real-time insight into data structures and flows, making it easier to apply policies, resolve issues, and collaborate across departments. The platform also helps connect data to business context, enabling teams to use data more effectively and responsibly. Actian’s platform is designed to scale with evolving data ecosystems, supporting consistent, intelligent, and secure data use across the enterprise. Request your personalized demo.