Flip the Script on Data Management With a Next-Gen Data Catalog
Phil Ostroff
October 29, 2024

As you’re probably experiencing firsthand, businesses are generating and handling more data than ever before, creating an urgent need for sophisticated tools to manage it all. Traditional data catalogs, while once effective, often fall short in providing the agility and accessibility needed by modern organizations. Managing, organizing, and making sense of your data requires easy-to-use tools that go beyond yesterday’s metadata management solutions to provide the speed, functionality, and features your business needs.
Enter next-generation data catalogs—innovative solutions that are designed to transform the way you discover, govern, and leverage your data. These cutting-edge data catalogs offer intuitive interfaces, advanced automation, and robust governance features that empower all users, making them essential for any company striving to harness the full power of its data assets.
As you focus on making data more accessible and actionable, next-generation data catalogs can help. They have emerged as a critical component in the modern data landscape.
How Next-Generation Data Catalogs Differ From Traditional Solutions
Traditional data catalogs have served businesses well for years, providing a repository to store and manage metadata and helping organizations locate critical data assets. However, these catalogs are often bulky, slow, and expensive, creating barriers to broader adoption, especially by non-technical users.
In addition, legacy data catalogs typically come with hefty license fees and require significant manual effort to classify and manage data. In contrast, next-generation data catalogs provide faster, more cost-effective, and user-friendly solutions designed to meet the needs of modern businesses. Next-gen data catalogs offer:
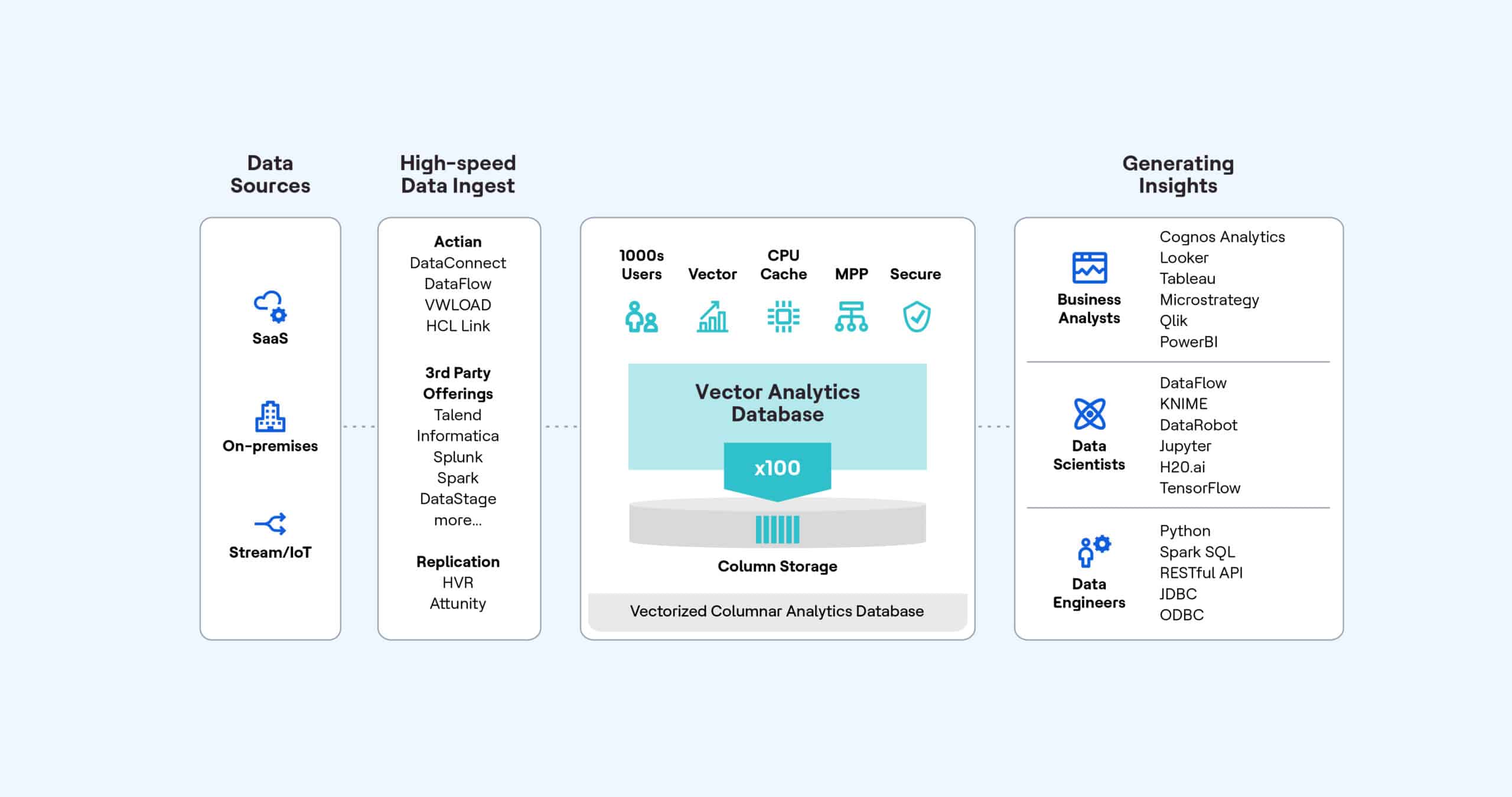
- Cloud-Native Architecture. Traditional data catalogs are often tied to on-premises systems, which can limit scalability and accessibility. Modern catalogs are built natively for the cloud, offering a flexible, scalable architecture that grows with your business.
The architecture allows you to integrate a wide range of cloud platforms, applications, and on-premises systems seamlessly for a connected ecosystem. A cloud-native architecture also makes it easier to manage data in hybrid or multi-cloud environments, ensuring the catalog can adapt as your infrastructure evolves.
- Ease of Use. One key differentiator of next-generation data catalogs is their focus on ease of use. Traditional solutions often require specialized skills to navigate, limiting their usability to data professionals and technical users. Next-gen catalogs, on the other hand, are designed with the non-technical user in mind.
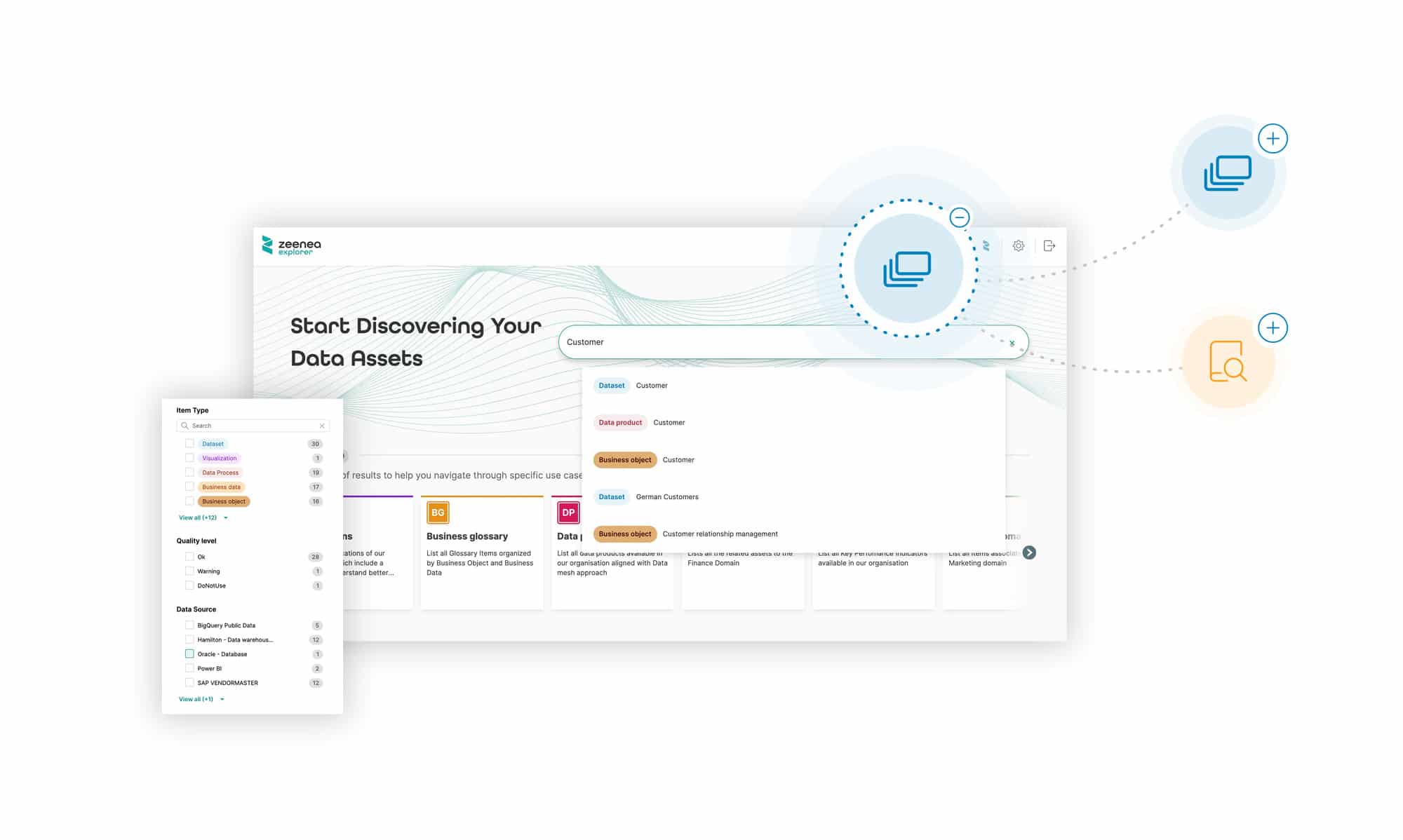
These modern catalogs feature intuitive user interfaces and automated workflows that simplify the process of finding, accessing, and utilizing data, making them accessible to a broader range of users within your organization. Whether it’s through natural language search or user-friendly data lineage displays, these catalogs empower you to work with data without requiring deep technical expertise. Ultimately, this helps democratize the data flow process.
- Enhanced Data Governance and Compliance. While traditional catalogs have long supported data governance, next-generation catalogs take it a step further by automating much of the data governance process. These solutions offer role-based access controls, automatic metadata tagging, and support for business glossaries, making it easier to manage sensitive information and ensure compliance with regulations like the General Data Protection Regulation (GDPR) or California Consumer Privacy Act (CCPA).
Some next-gen catalogs even incorporate advanced capabilities to automatically detect and classify sensitive data. They can then provide real-time alerts and insights to prevent data breaches.
- Cost-Effective Solutions. The pricing model of traditional data catalogs has been a significant barrier for many organizations, with enterprise licenses costing upwards of $150,000 annually, according to a report from Eckerson Group “Next-Generation Data Catalogs.” In contrast, modern catalogs offer competitive pricing models, often at a fraction of the cost.
For example, the report notes that the annual cost for next-gen data catalogs typically ranges from $70,000 to $90,000. Lower costs, combined with new features and reduced manual effort, make these catalogs an attractive option for businesses of all sizes.
5 Ways the Actian Data Intelligence Platform Stands Out for Its Next-Generation Data Catalog
Among the modern data catalogs on the market, the Actian Data Intelligence Platform stands out as a modern solution for modernizing your data management practices. It offers an ideal platform and data catalog for data-driven organizations like yours to democratize data, centralize and unify all enterprise metadata, and offer a single source of truth.
Five key reasons to use the Actian Data Intelligence Platform include:
- A Focus on Simplicity and User Experiences. Actian Data Intelligence Platform is focused on delivering simplicity—and this is reflected in the platform’s clean and intuitive user interface. The platform offers two user interfaces: Actian Explorer for business users who need to discover and explore data, and Actian Studio for data stewards responsible for managing and governing data assets. This separation of interfaces ensures that both technical and non-technical users can interact with the data catalog in ways that are most relevant to their roles.
- Enterprise Data Marketplace Integration. What sets Actian apart from many of its competitors is its Enterprise Data Marketplace. This feature allows business domains within your organization to share data products seamlessly, enabling greater collaboration and data democratization across departments. When users look to access a data product, the platform routes those requests through third-party workflow systems, like those from Jira or ServiceNow, to ensure governance policies are followed while maintaining ease of use.
- Advanced Metadata Management and Federation. The Actian Data Intelligence Platform is built on a knowledge graph that supports multiple metamodels, allowing each business domain to create its own data catalog tailored to its specific needs. These domain-specific catalogs can then be combined into an enterprise catalog, providing a holistic view of your data landscape. This flexibility is crucial when operating across multiple business units or geographies because it allows you to maintain a unified data catalog while accommodating the unique requirements of each domain.
- Seamless Integration and Interoperability. With more than 70 proprietary data connectors, the Actian solution integrates with a wide range of data platforms, cloud applications, and on-premises systems. This ensures that the catalog can pull metadata from virtually any source within your organization, providing a comprehensive view of your data ecosystem. Additionally, by integrating with third-party applications such as Monte Carlo and Soda, you benefit from data quality monitoring to maintain high levels of data accuracy and reliability.
- Future-Ready Without the Hype. While many next-gen data catalogs are rushing to integrate AI features, Actian takes a measured approach, only adopting new technologies that have proven value to customers. For example, the Actian platform uses GenAI to summarize long descriptions and improve usability in targeted areas. This approach ensures that the platform remains cutting-edge without overwhelming users with unproven features.
A Strategic Investment in Data-Driven Success
As you continue to navigate the complexities of the digital age, the need for robust, scalable, and user-friendly data management solutions is more critical than ever. Next-generation data catalogs, like the one from the Actian Data Intelligence Platform, offer a powerful alternative to traditional solutions, providing enhanced usability, governance, and cost-efficiency.
Investing in a next-generation data catalog is not just a smart choice—it’s a strategic imperative. Actian Data Intelligence Platform, with its focus on simplicity, integration, and innovation, is well-positioned to help you gain maximum value from your data and drive meaningful business outcomes.
“The Actian Data Intelligence Platform is more than just a data catalog: it bundles at no cost a data marketplace for publishing and consuming data products, putting Actian on the cutting-edge of all data catalogs,” according to the Eckerson Group.
Experience the platform for yourself with an Actian product tour.

Subscribe to the Actian Blog
Subscribe to Actian’s blog to get data insights delivered right to you.
- Stay in the know – Get the latest in data analytics pushed directly to your inbox.
- Never miss a post – You’ll receive automatic email updates to let you know when new posts are live.
- It’s all up to you – Change your delivery preferences to suit your needs.