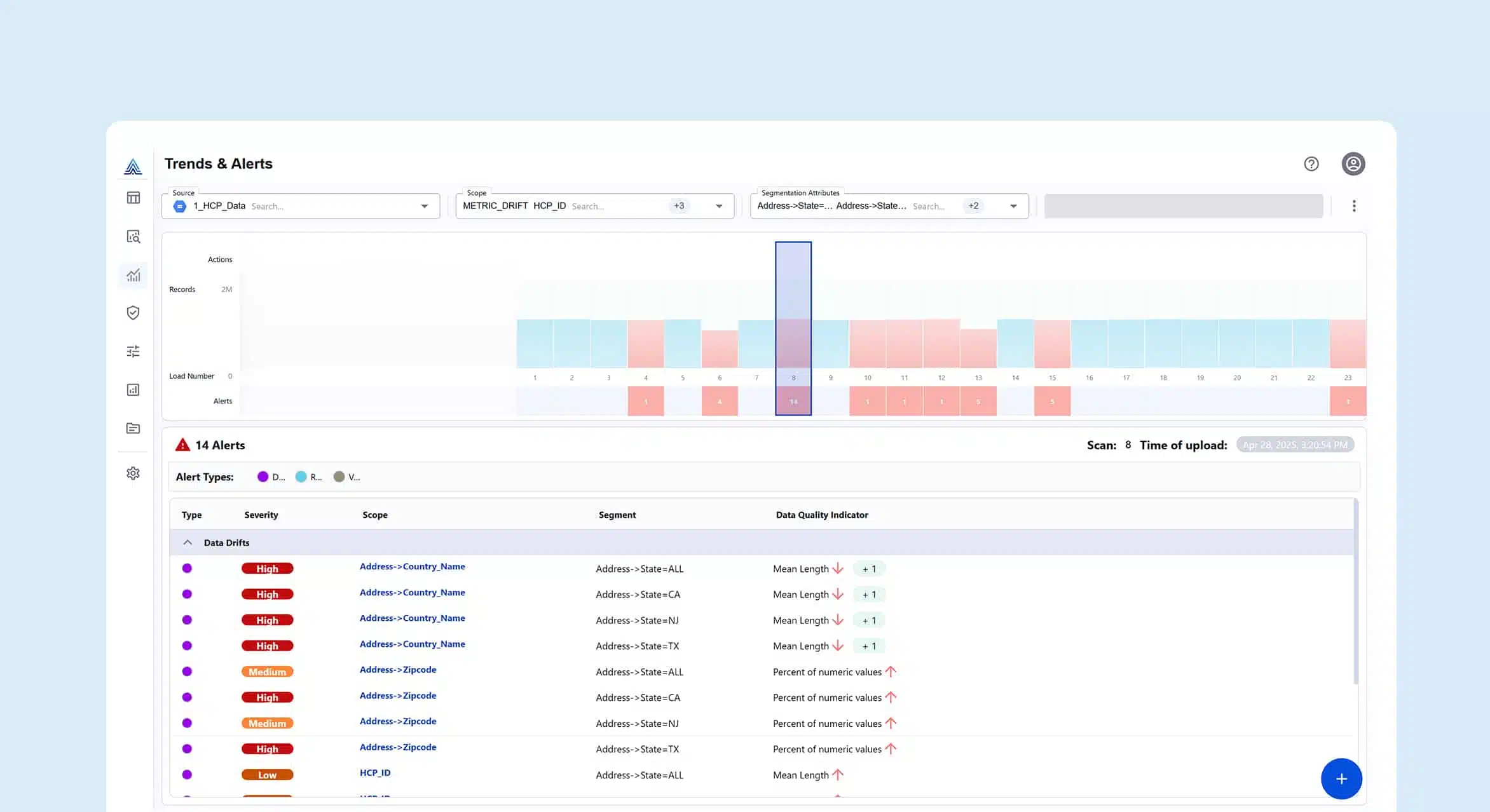
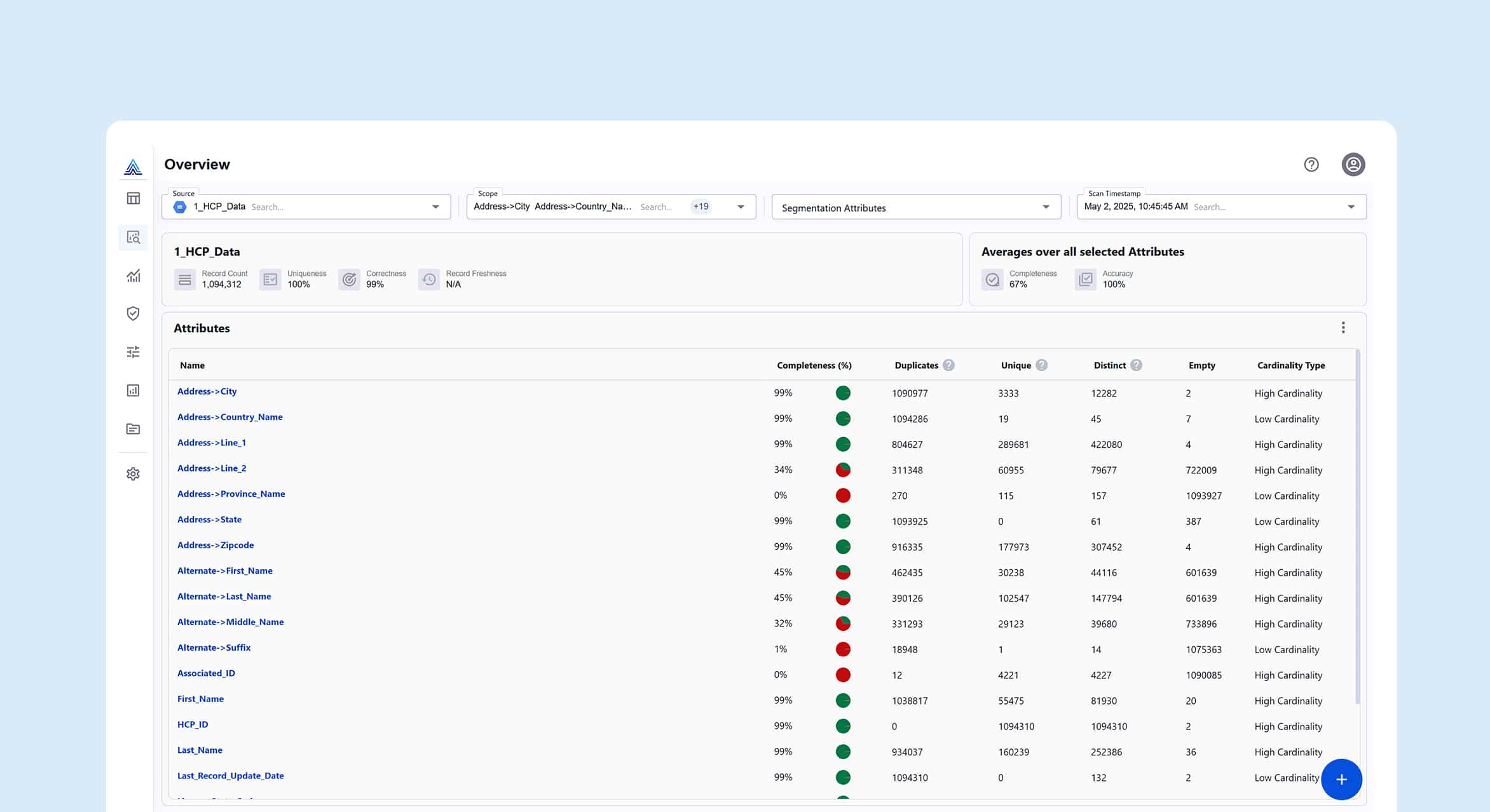
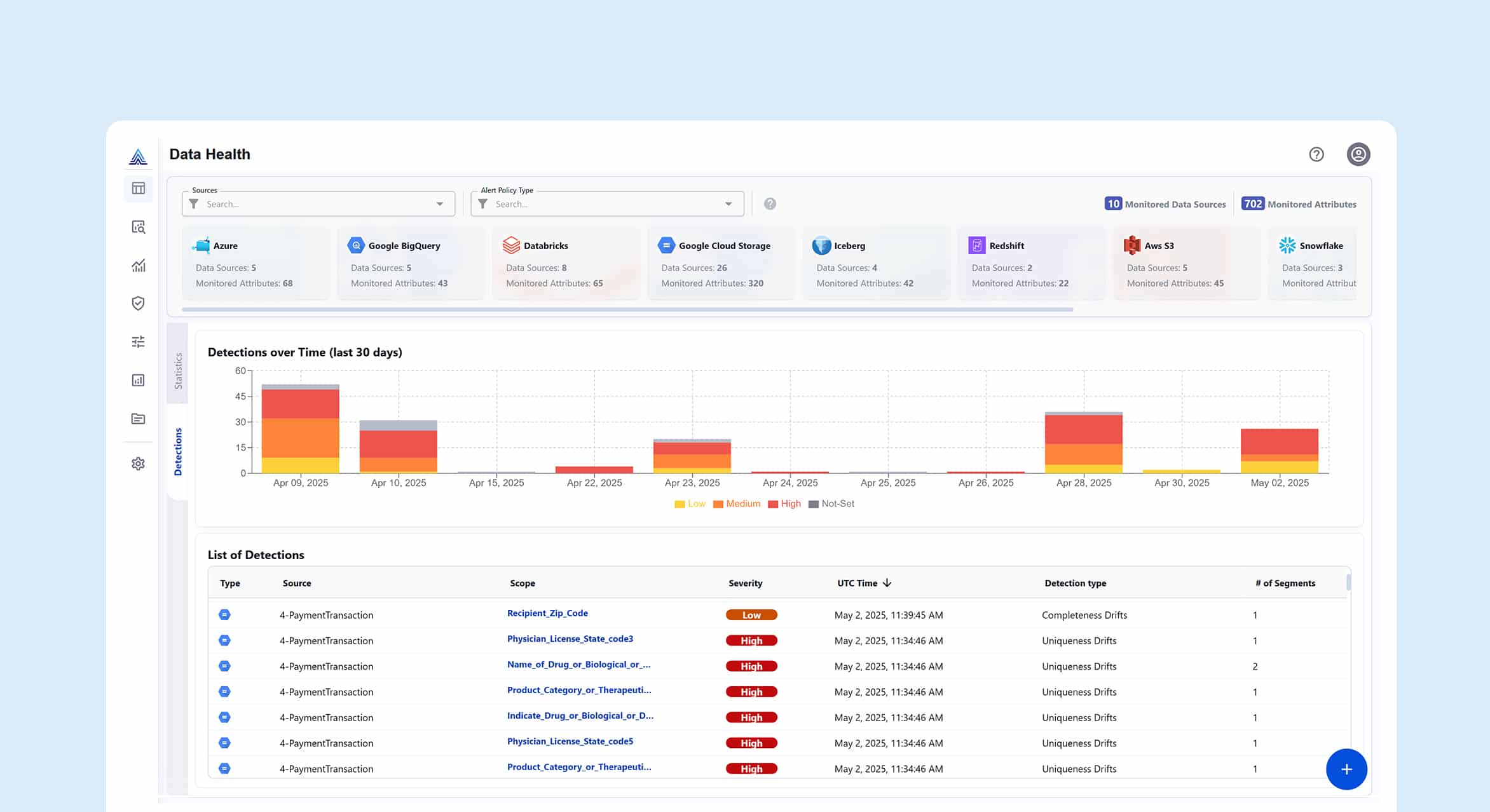
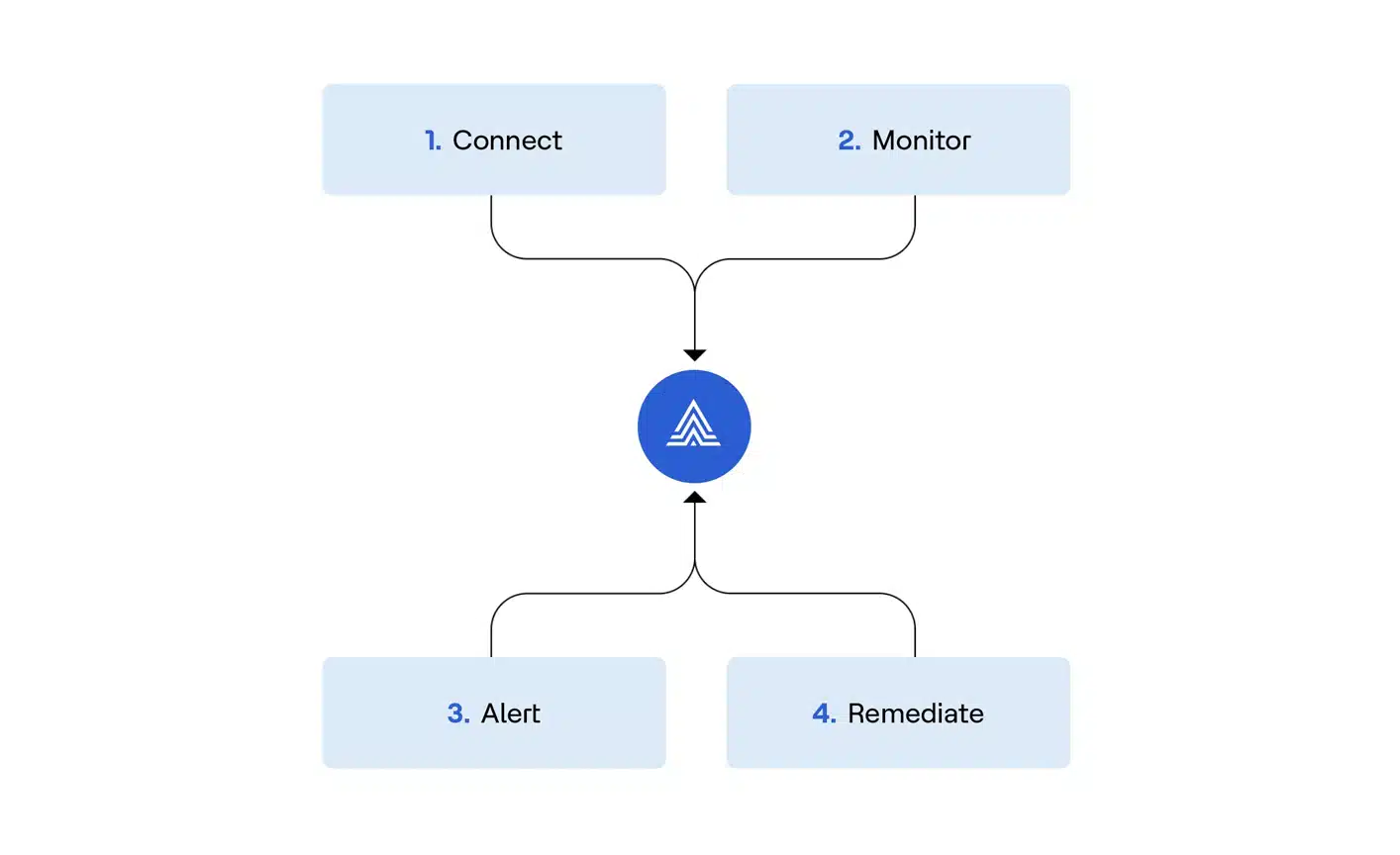
From Silos to Self-Service: Data Governance in the AI Era





Summary
- 60% of AI projects fail due to weak governance.
- Shift to data products improves quality and scalability.
- Federated governance balances autonomy and control.
- Active metadata and automation enable real-time governance.
- Actian helps embed governance into AI-driven workflows.
As enterprises double down on AI, many are discovering an uncomfortable truth: their biggest barrier isn’t technology. It’s their data governance model.
Gartner predicts that 60% of organizations will fall short of their goals because their governance frameworks can’t keep up.
Siloed data, ad hoc quality practices, and reactive compliance efforts create bottlenecks that stifle innovation and limit effective data governance. The future demands a different approach: data treated as a product, AI-enabled data governance embedded in data processes including self-service experiences, and decentralized teams empowered by active metadata and intelligent automation.
From Data Silos to Data Products: Why Change is Urgent
Traditional data governance frameworks were not designed for today’s reality. Enterprises operate across hundreds, sometimes thousands, of data sources: cloud warehouses, lakehouses, SaaS applications, on-premises systems, and AI models all coexist in sprawling ecosystems.
Without a modern approach to managing and governing data, silos proliferate. Governance becomes reactive—enforced after problems occur—rather than proactive. And AI initiatives stumble when teams are unable to find trusted, high-quality data at the speed the business demands.
Treating data as a product offers a way forward. Instead of managing data purely as a siloed, domain-specific asset, organizations shift toward delivering valuable and trustworthy data products to internal and external consumers. Each data product has an owner and clear expectations for quality, security, and compliance.
This approach connects governance directly to business outcomes. Organizations drive more accurate analytics, more precise AI models, and faster, more confident decision-making.
Enabling Domain-Driven Governance: Distributed, Not Fragmented
Achieving this future requires rethinking the traditional governance model. Centralized governance teams alone cannot keep pace with the volume, variety, and velocity of data creation. Likewise, fully decentralized models, where each domain sets its own standards without alignment, can’t keep pace either.
The solution is federated governance, a model in which responsibility is distributed to domain teams but coordinated through a shared framework of policies, standards, and controls.
In a federated model:
- Domain teams own their data products, from documentation to quality assurance to access management.
- Central governance bodies set enterprise-wide guardrails, monitor compliance, and enable collaboration across domains.
- Data intelligence platforms serve as the connective tissue, providing visibility, automation, and context across the organization.
This balance of autonomy and alignment ensures that an organization’s AI-enabled data governance scales with the organization, without becoming a bottleneck to innovation.
The Rise of Active Metadata and Intelligent Automation
Active metadata is the fuel that powers modern governance. Unlike traditional data catalogs and metadata repositories that are often static and siloed, active metadata is dynamic, continuously updated, and operationalized into business processes.
By tapping into active metadata, organizations can:
- Automatically capture lineage, quality metrics, and usage patterns across diverse systems.
- Enforce data contracts between producers and consumers to ensure shared expectations.
- Enable intelligent access controls based on data sensitivity, user role, and regulatory requirements.
- Proactively detect anomalies, schema changes, and policy violations before they cause downstream issues.
When governance processes are fueled by real-time, automated metadata, they no longer slow the business down. They accelerate it.
Embedding Governance into Everyday Work
The ultimate goal of modern governance is to make high-quality data products easily discoverable, understandable, and usable, without requiring users to navigate bureaucratic hurdles.
This means embedding governance into self-service experiences with:
- Enterprise data marketplaces where users browse, request, and access data products with clear SLAs and usage guidelines.
- Business glossaries that standardize and enforce consistent data definitions across domains.
- Interactive lineage visualizations that trace data from its source through each transformation stage in the pipeline.
- Automated data access workflows that enforce granular security controls while maintaining compliance.
In this model, governance becomes an enabler, not an obstacle, to data-driven work.
Observability: Enabling Ongoing Trust
Data observability is a vital component of an AI data governance framework because it ensures the quality, integrity, and transparency of the data that powers AI models. By integrating data observability, organizations reduce AI failure rates, accelerate time-to-insight, and deliver reliable data to AI models.
Data observability improves data intelligence and helps to:
- Ensure high-quality data is used for AI model training by continuously monitoring data pipelines and quickly detecting anomalies, errors, or bias before they impact AI outputs.
- Provide transparency and traceability of data flows and transformations, which are essential for building trust, ensuring regulatory compliance, and demonstrating accountability in AI systems.
- Reduce model bias by monitoring data patterns and lineage. Data observability helps identify and address potential biases in datasets and model outputs. This is key to ensuring AI systems are fair, ethical, and do not perpetuate discrimination.
- Improve model explainability by making it easier to understand and explain AI model behavior, providing insights into the data that influences model predictions.
The Foundations of Data Observability: What to Include in an AI Data Governance Framework
How does data observability deliver key benefits? The foundation of a strong data observability framework typically includes these five core components:
1. Data Quality Monitoring
Continuous tracking of freshness, completeness, accuracy, and other quality dimensions, supported by automated rules and anomaly detection. This ensures issues are caught early.
2. Pipeline and Workflow Monitoring
Monitoring job performance, data volumes, schema changes, and pipeline failures provides early warning signals when transformations or dependencies break at any point in the data lifecycle.
3. Data Lineage and Metadata Management
End-to-end lineage paired with rich metadata gives essential context for understanding data flows, dependencies, and the root causes of issues.
4. Log and Event Monitoring
Centralized logs and event streams from data platforms and orchestration tools allow engineers to investigate operational anomalies and trace unexpected behavior.
5. Alerting and Incident Management
Actionable alerts, clear escalation paths, and integrated incident workflows ensure quicker recovery and continuous improvement across the data ecosystem.
Building for the Future: Adaptability is Key
The pace of technological change—especially in AI, machine learning, and data infrastructure—shows no signs of slowing. Regulatory environments are also evolving rapidly, from GDPR to CCPA to emerging AI-specific legislation.
To stay ahead, organizations must build governance frameworks with data intelligence tools that are flexible by design:
- Flexible metamodeling capabilities to customize governance models as business needs evolve.
- Open architectures that connect seamlessly across new and legacy systems.
- Scalable automation to handle growing data volumes without growing headcount.
- Cross-functional collaboration between governance, engineering, security, and business teams.
By building adaptability into the core of their governance strategy, enterprises can future-proof their investments and support innovation for years to come.
Actian Data Intelligence Platform Turns Governance into a Competitive Advantage
Data governance is no longer about meeting minimum compliance requirements. It’s about driving business value and building a data-driven culture. Organizations that treat data as a product, empower domains with ownership, and activate metadata across their ecosystems will set the pace for AI-driven innovation.
Those that rely on outdated, centralized models will struggle with slow decision-making, mounting risks, and declining trust. The future will be led by enterprises that embed governance into the fabric of how data is created, shared, and consumed, turning trusted data into a true business advantage.
Actian Data Intelligence Platform helps businesses transform the way they handle and automate data governance. Backed by federated knowledge graph technology, the platform allows businesses to democratize their data, trust that data’s accuracy, and activate data into usable products. To see how innovative data governance works, schedule a personalized demonstration today.

Stay connected
Data insights delivered to you.
(i.e. sales@..., support@...)