Should You Use RAG or Fine-Tune Your LLM?




Summary
- RAG dominates enterprise AI due to flexibility, but fine-tuning excels at scale, latency, and structured outputs.
- RAG adds recurring costs from context and retrieval, while fine-tuning shifts cost upfront with stable per-query pricing.
- Hybrid approaches combine retrieval with fine-tuning for higher accuracy and better reasoning.
- Choosing the right approach depends on data volatility, query volume, and team capabilities.
The debate over retrieval augmented generation (RAG) vs. fine-tuning appears simple at first glance. RAG pulls in external data at inference time. Fine-tuning modifies model weights during training. In production systems, that distinction is insufficient.
According to the Menlo Ventures 2024 State of Generative AI in the Enterprise report, 51 percent of enterprise AI deployments use RAG in production. Only nine percent rely primarily on fine-tuning. Yet research such as the RAFT study from UC Berkeley shows that hybrid systems combining retrieval and fine-tuning outperform either approach alone across benchmarks.
If hybrid systems can produce better results, why does industry adoption favor only RAG? In this article, we’ll compare RAG, fine-tuning, and a hybrid architecture to understand the trade-offs and where each approach excels.
TL;DR
- RAG: Best for frequently changing knowledge and moderate traffic; easy to update without retraining.
- Fine-tuning: Best for stable domains and high-volume or low-latency tasks; improves task-specific accuracy and formatting.
- Hybrid/RAFT: Combines up-to-date retrieval with optimized model behavior for the highest accuracy.
- Key trade-off: Choice depends on query volume, how often knowledge changes, and team expertise.
Why the Standard RAG vs. Fine-Tuning Comparison Fails
RAG is a method where the model dynamically pulls in external data at inference time. Each query retrieves relevant documents or knowledge chunks, which the system appends to the prompt, allowing the model to produce answers grounded in current information.
Fine-tuning is the process of modifying a model’s weights during training using labeled data. Instead of relying on external retrieval, the model internalizes patterns directly, producing consistent outputs without querying external sources.
While these definitions are technically correct, most standard comparisons miss the factors that actually drive decisions in production. In real-world systems, the choice between RAG and fine-tuning depends on variables like scale, query volume, and how often your data changes.
Missing variable 1: Context expansion at scale
In many production RAG systems, every request appends hundreds of tokens. That added context changes how the model allocates attention and prioritizes weights.
Large retrieved contexts compete for attention with the prompt and instructions, which can dilute signal quality. Small retrieval errors or loosely relevant chunks can introduce formatting drift, or shift reasoning in subtle ways. The system’s output becomes tightly coupled to retrieval quality.
Fine-tuning works differently. Instead of injecting large volumes of text at inference time, it embeds patterns and constraints directly into the model during training. The distinction affects how the system behaves under real workloads.
Missing variable 2: Retraining frequency
The common advice says “use RAG if knowledge changes frequently” and “use fine-tuning if behavior is stable.” But how frequently is “frequently”?
If your knowledge base changes daily, retraining pipelines may introduce operational friction. Evaluation cycles, dataset versioning, and deployment validation all add delay.
Data preparation also matters. If your organization lacks structured, versioned, and clean datasets, the hidden cost of preparing training data can exceed compute costs.
The Cost Math of RAG vs. Fine-Tuning
Surface-level comparisons of RAG and fine-tuning often ignore the cost curves that determine long-term viability. In production systems, financial estimations are crucial in architectural decisions. To evaluate RAG vs. fine-tuning realistically, we need to examine three cost layers:
- Token cost and context expansion.
- Retrieval infrastructure cost.
- Training infrastructure cost.
The cost structure of RAG
RAG systems introduce a recurring operational cost because each query retrieves external information and injects it into the model’s prompt. That additional context is billed on every request.
Context expansion
Production RAG systems append around 500 tokens of retrieved context to each query. The provider bills those tokens on every request.
Using pricing similar to GPT-5.2 at 1.750 dollars per million input tokens, the incremental monthly cost becomes:
Cost per query
500 tokens × $1.75/1,000,000 = $0.000875 per query
At a small scale, this cost appears negligible. However, because it applies to every query, the total overhead grows linearly with traffic.
At different traffic levels:
| Monthly queries | Context cost |
| 10 million | $8,750 |
| 50 million | $43,750 |
| 100 million | $87,500 |
This is context overhead alone. It does not include output tokens or base prompt tokens. At a sustained scale, what appears flexible and inexpensive becomes a significant recurring expense.
Vector database and retrieval cost
Token cost is only one component of RAG costs. RAG also relies on a vector database for semantic search. The system must store, index, and query embeddings efficiently.
Public pricing of Pinecone lists:
- Storage at approximately 0.33 dollars per gigabyte per month.
- Read units at approximately 16 dollars per million.
- Write units at approximately four dollars per million.
For example, consider a system handling 50 million queries per month, where each query performs a single vector search (assuming a 1,024-dimension vector). That would result in 50 million read operations monthly. If the system also writes approximately six million records per month, the combined read and write activity would bring the total estimated monthly cost to around $1,532.
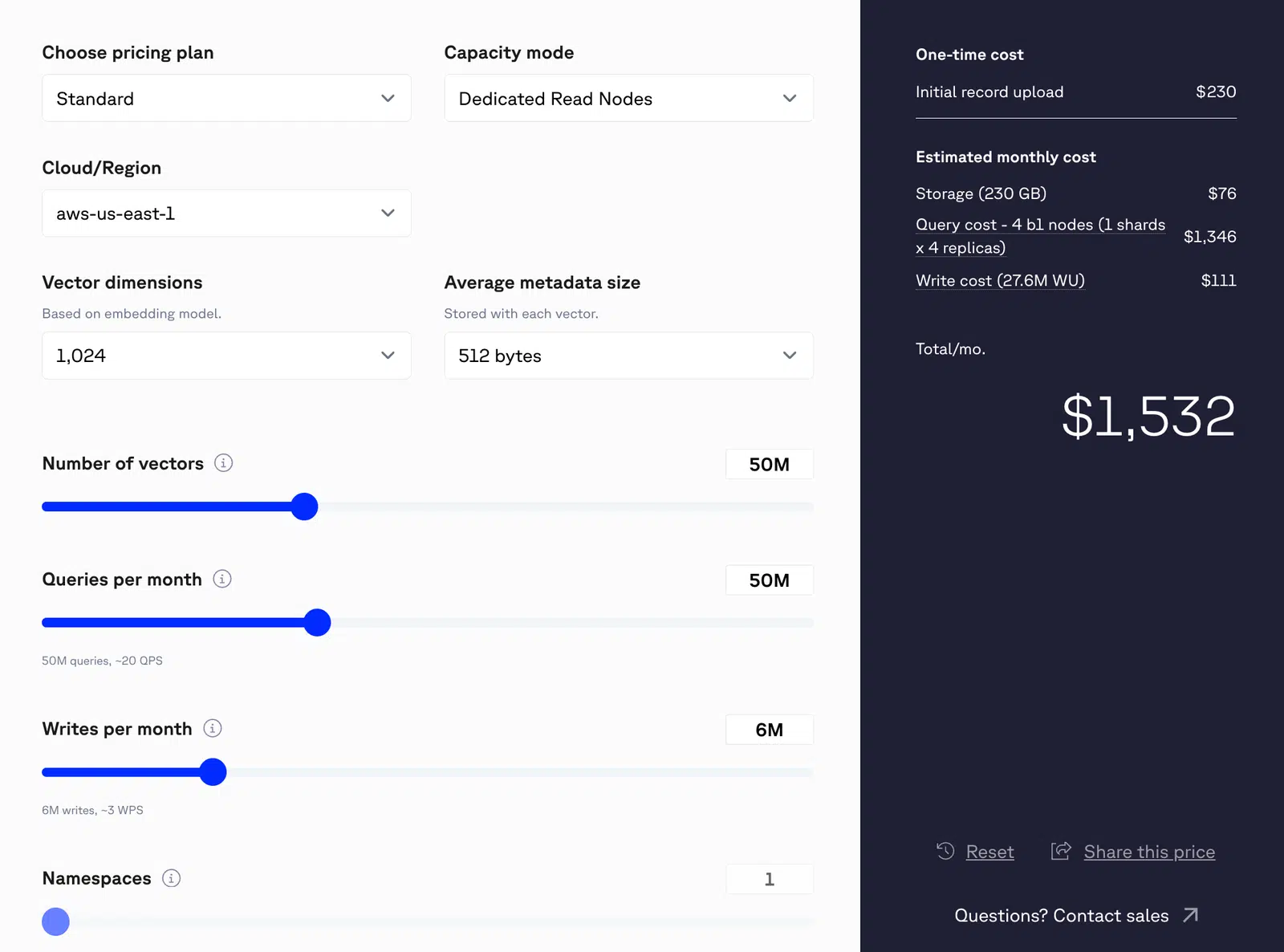
Figure 1: Pinecone pricing for 50M vectors
At 200 million queries per month, the total expenses rises to $9,000 per month.
Two RAG systems serving identical traffic can therefore have materially different cost structures depending on how the vector database is designed and optimized.
Infrastructure cost
RAG systems require storage and compute infrastructure to generate embeddings, store and index vectors, execute retrieval queries, and run inference. Each of these stages consumes compute resources, typically provisioned through cloud servers that must scale with traffic.
For real-time or high-throughput applications, additional capacity is required to maintain low latency and system reliability. Replication, autoscaling, monitoring, and failover mechanisms all add operational complexity. These infrastructure layers are essential for production-grade RAG, but they expand the total cost footprint beyond token usage alone.
The cost structure of fine-tuning
Fine-tuning introduces a different economic model from RAG systems. Instead of paying incremental costs on every request for external context, you invest upfront to modify the model’s internal behavior.
That upfront investment can be broken into four primary cost categories: data, training compute, experimentation, and operational maintenance.
Data preparation costs
High-quality labeled data is the foundation of effective fine-tuning. This includes collecting domain-specific examples, cleaning inconsistencies, formatting inputs and outputs correctly, and validating annotation quality.
In many organizations, data preparation consumes 20 to 40 percent of the total fine-tuning budget. Poorly curated data directly degrades model performance, leading to additional retraining cycles and wasted compute.
Training compute costs
OpenAI lists fine-tuning at roughly $25 per million training tokens for GPT-4.1. A run using 20 million tokens would cost about $500 in direct training fees, with larger datasets or multiple runs increasing this total.
For self-hosted training, costs depend on model size and hardware. High-performance GPUs such as A100 clusters can cost thousands of dollars per training epoch. Because fine-tuning is rarely a single-pass process, multiple epochs, evaluations, and retraining cycles are common, which further increases the overall cost.
Experimentation and validation costs
Fine-tuning is an iterative process that requires experimentation with hyperparameters, evaluation against baseline models, and testing across edge cases. These workflows require engineering time, infrastructure, and structured evaluation frameworks. Unlike prompt engineering, fine-tuning introduces a full ML lifecycle, adding ongoing operational overhead.
This creates a non-linear cost curve. Fine-tuning concentrates cost at the beginning, while marginal cost per request remains relatively stable as traffic grows.
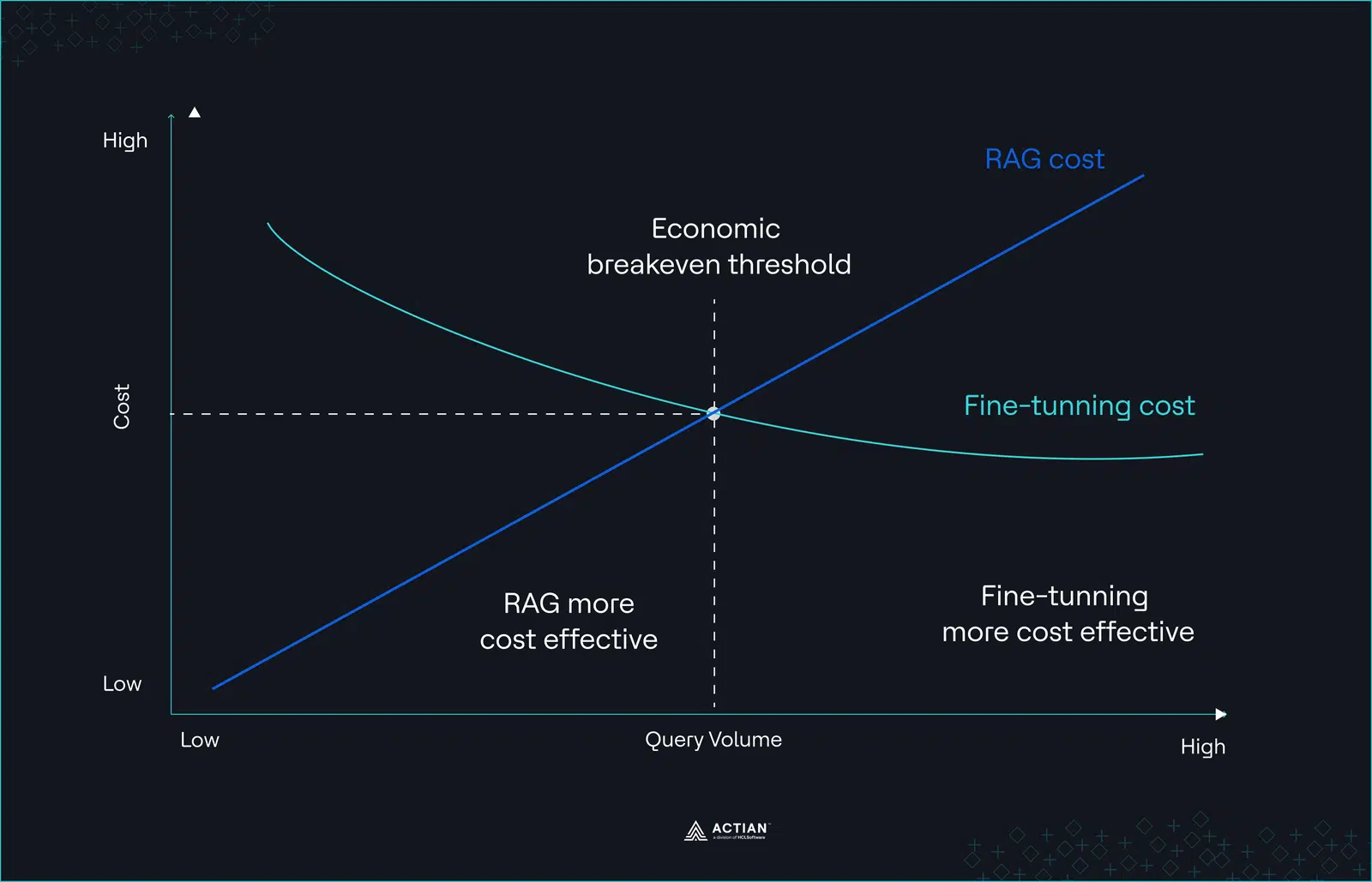
Figure 2: Non-linear cost curve
Whether that trade-off is advantageous depends on three variables: query volume, knowledge stability, and retraining frequency. Without modeling those explicitly, cost comparisons between RAG and fine-tuning remain incomplete.
When RAG Wins
Despite its scaling trade-offs, RAG remains the dominant production choice for a reason. In certain operating conditions, it is structurally more flexible, faster to iterate, and operationally safer than fine-tuning. RAG is suitable in the following scenarios:
- When knowledge changes frequently
If your domain knowledge changes weekly or daily, fine-tuning becomes operationally expensive. Dataset updates, retraining, evaluation, and deployment introduce delays that can stretch from hours to weeks, depending on governance requirements.
Teams frequently underestimate the operational overhead of keeping a fine-tuned model synchronized with a rapidly evolving knowledge base. In these environments, RAG shifts the problem from model retraining to data indexing.
- When you have extensive unstructured data but limited labeled data
Many organizations possess terabytes of internal documents but lack high-quality supervised datasets. Building labeled training corpora requires annotation workflows, domain experts, and quality validation pipelines. In practice, this often becomes the most expensive part of fine-tuning projects.
RAG bypasses this constraint by allowing models to operate directly on existing document corpora without constructing large labeled datasets.
- When governance and data residency requirements are strict
Once sensitive information is embedded in model weights, deletion and auditing become difficult. Removing a specific record from a fine-tuned model often requires retraining or maintaining complex dataset lineage.
RAG architectures avoid this issue by keeping sensitive information in external storage systems where standard governance controls already exist.
- When query volume is moderate
As shown in the earlier cost analysis, context expansion overhead grows with query volume, reaching approximately $43,750 per month at 50 million queries. At moderate traffic, RAG’s per-request costs are typically lower than the amortized expenses of fine-tuning, including training and ongoing maintenance. This makes RAG an attractive choice for organizations that want high-quality outputs without front-loading infrastructure and compute investments.
Use cases
Large-scale examples illustrate RAG’s effectiveness at this volume. Notion’s Q&A assistant is effectively a large-scale RAG system over workspace data. The difficult engineering problem was not retrieval itself, but enforcing identity and access controls during retrieval. When a user queries the assistant, the system must ensure the model only retrieves documents that the user is permitted to see.
LinkedIn leveraged RAG and knowledge graphs to preserve the structure of their support cases. This system retrieved relevant subgraphs rather than isolated text chunks, improving retrieval accuracy by 77.6% and reducing median issue resolution time by 28.6%.
For systems at this scale, RAG combines cost efficiency with flexibility, allowing teams to update knowledge sources rapidly without retraining models, while still delivering high-quality results.
When Fine-Tuning Wins
Fine-tuning becomes structurally advantageous under different conditions. These conditions typically involve scale, stability, and behavioral precision.
- When query volume exceeds 100 million per month
At very high traffic levels (100M+ queries per month), RAG’s per-request context overhead becomes significant. Each query adds hundreds of retrieved tokens that the model processes, causing costs to scale linearly with traffic. Large context windows can also increase latency, reduce throughput, and complicate infrastructure reliability.
If domain knowledge is relatively stable, fine-tuning can become more efficient. By embedding knowledge directly into the model, organizations avoid repeated retrieval and token costs, leading to more predictable per-query expenses, better consistency, and simpler operations at scale.
- When output structure is critical
Fine-tuned models often excel in tasks that require strict adherence to structure or formal constraints. For example, Cosine, which is an AI software engineering assistant that’s able to autonomously resolve bugs and build features, was able to achieve a SOTA score of 43.8% on the SWE-bench verified benchmark.
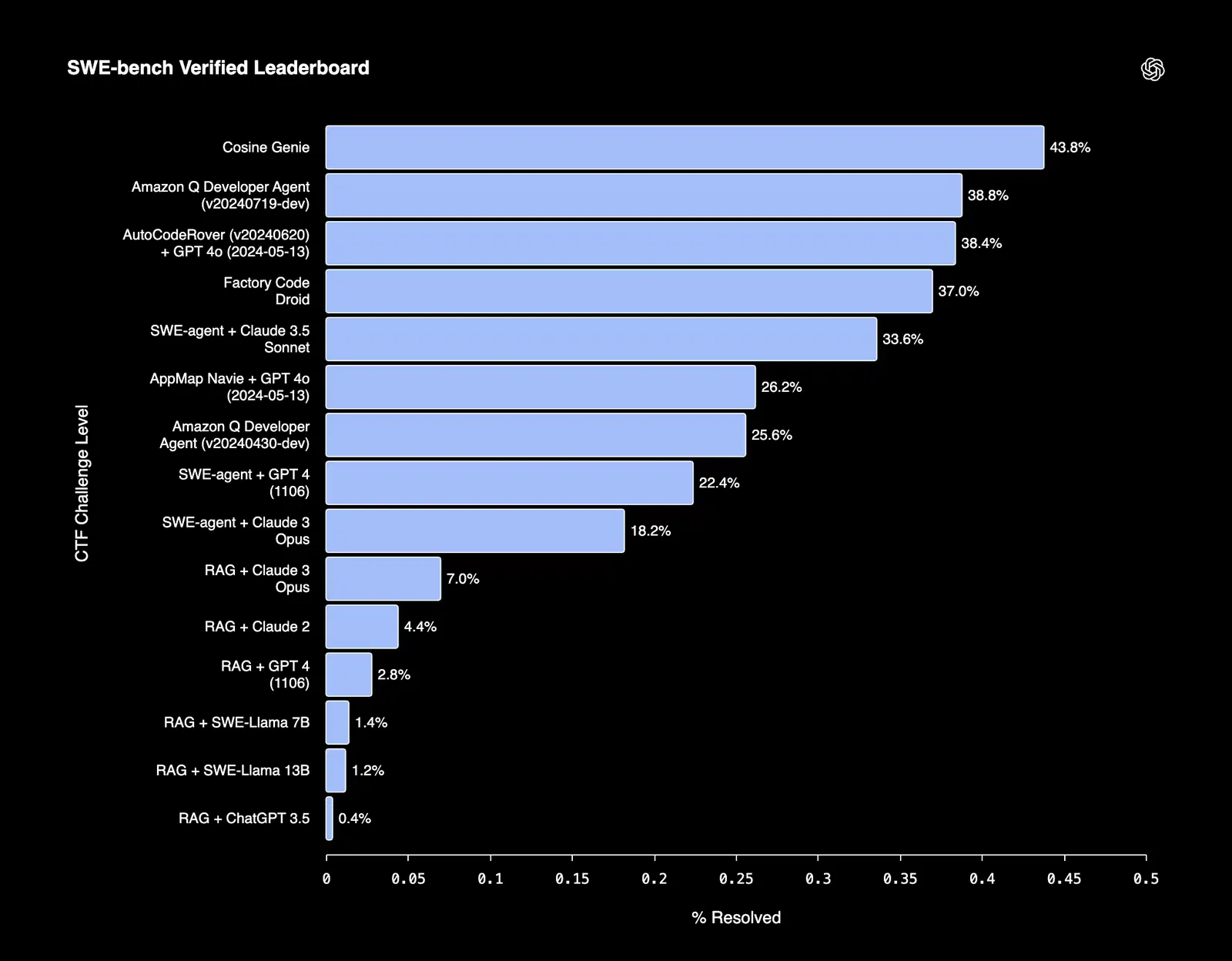
Figure 3: SWE-bench leaderboard
Similarly, Distyl secured the top position on the BIRD-SQL benchmark, widely regarded as the premier evaluation for text-to-SQL performance. Its fine-tuned GPT-4o model reached an execution accuracy of 71.83% on the leaderboard.
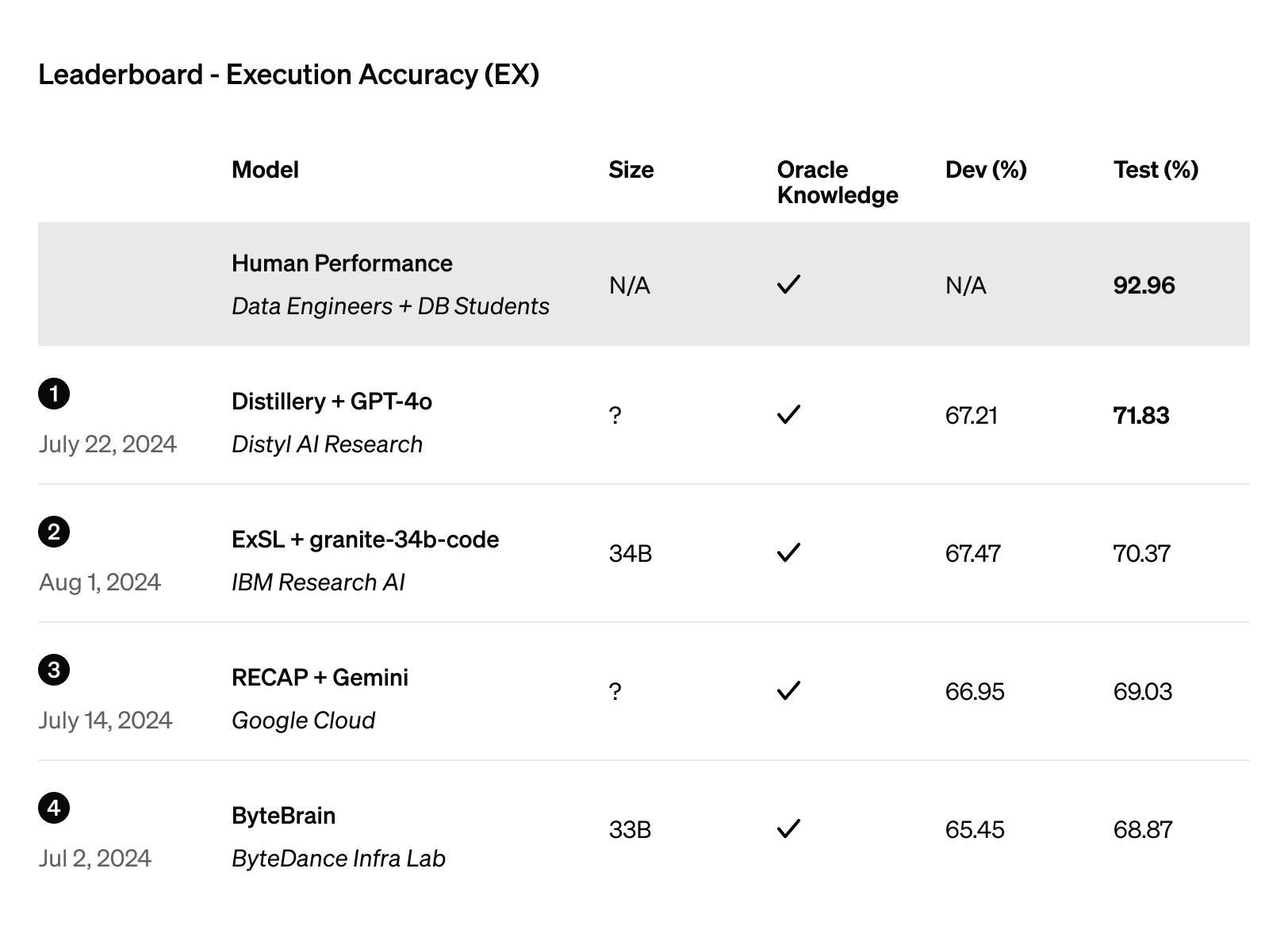
Figure 4: Execution accuracy leaderboard
In applications where errors propagate downstream, into financial calculations, automated APIs, or compliance documents, behavioral consistency is mandatory. In these contexts, fine-tuning provides the reliability needed to minimize risk and maintain trust in automated outputs.
- When latency requirements are strict
RAG adds multiple steps to the inference pipeline that increase response time. Each query must go through embedding generation, vector search, and context injection before reaching the model.
Fine-tuned models skip retrieval entirely. All necessary knowledge and reasoning patterns are internalized, allowing the model to generate outputs immediately. In applications where sub-100ms responses are required, such as live recommendation engines or high-frequency trading systems, removing the retrieval pipeline eliminates a major bottleneck.
- When deep domain reasoning matters more than freshness
A domain-specific agriculture benchmark study found that fine-tuning improved model accuracy from 75% to 81%, while hybrid systems (fine-tuning + retrieval) reached 86%. Because the dataset focused on specialized agricultural knowledge and reasoning tasks, the improvement primarily reflects stronger domain reasoning, not simply better access to external information.
In domains such as legal analysis or medical decision support, reasoning patterns can be complex. Fine-tuning enables models to internalize domain expertise rather than rely solely on retrieved context.
The Hybrid Approach
While RAG and fine-tuning each have clear advantages, research shows that combining them effectively can produce superior results, but only when done correctly. The RAFT (Retrieval Augmented Fine-Tuning) approach, developed by UC Berkeley, Microsoft, and Meta Research, demonstrates how to do this in practice.
RAFT trains a model to operate in an “open-book” setting. It learns to process retrieved context, identify relevant passages, ignore distractors, and cite evidence accurately. Without this explicit training, simply layering RAG on top of a fine-tuned model often fails. For instance, a model fine-tuned on medical reasoning may retrieve irrelevant journal articles if it hasn’t learned to filter and prioritize context, resulting in hallucinations or incorrect recommendations.
RAFT addresses this with a structured 80/20 training split. 80% of training examples include oracle documents that the model should use, and 20% do not, forcing the model to learn when to trust retrieved data and when to rely on internalized knowledge. This operational detail is crucial for engineers evaluating whether their team can implement a hybrid approach successfully. It is not enough to just combine RAG and fine-tuning. The model must be trained to reason over the retrieved context.
A common and practical pattern is “fine-tune for format, RAG for knowledge.” Fine-tuning shapes the model’s internal behavior, enforcing domain-specific reasoning, output structure, and style. RAG provides dynamic access to external information that changes frequently or is too large to store in the model weights. In healthcare, for example, fine-tuning ensures the model understands medical terminology, follows proper diagnostic reasoning, and formats outputs according to clinical documentation standards. RAG supplements this by retrieving the latest research, newly published treatment guidelines, or patient-specific records, keeping recommendations current without retraining the entire model.
Similarly, Harvey AI fine-tuned on 10 billion case law tokens, but still leverages RAG to handle current cases and updates. This pattern is widely used in other domains too. Legal systems fine-tune for statutory reasoning and citation style, then layer RAG to retrieve the most current case law; finance models fine-tune for portfolio analysis rules, then layer RAG for market updates and regulatory changes. It’s a way to balance the stability of learned behavior with the adaptability of retrieval.
A Quantified Decision Framework for RAG vs. Fine-Tuning
The question is no longer “Which approach is better?” It is “Under what conditions does each approach make economic and operational sense?”
Instead of defaulting to architectural preference, evaluate three measurable variables:
- Knowledge change frequency.
- Monthly query volume.
- Infrastructure capability and governance constraints.
When those variables are quantified, the decision becomes far clearer.
Step 1: Measure knowledge volatility
Knowledge change frequency is often the fastest way to eliminate one option. If your domain knowledge changes weekly or daily, RAG is structurally favored. Updating an index is far simpler than retraining a fine-tuned model. The separation between model weights and external data enables real-time data retrieval without redeployment cycles.
If knowledge remains stable for months at a time, fine-tuning becomes economically viable. Retraining frequency drops, and training cost can be amortized over longer intervals. In these environments, embedding domain-specific knowledge directly into model parameters may reduce long-term inference overhead.
As a practical threshold:
- Knowledge changes more than monthly → prioritize RAG.
- Knowledge stable for multiple months → evaluate fine-tuning.
Step 2: Calculate context expansion cost
The next variable is query volume. Large-scale RAG systems append hundreds of tokens to every query, and this context overhead scales linearly with traffic.
Quantitative triggers
| Monthly queries | Guidance |
| <10M | RAG is cheaper |
| 10–50M | Evaluate fine-tuning vs. RAG |
| 50–100M | Fine-tuning or hybrid |
| >100M | Fine-tuning or hybrid |
Step 3: Assess infrastructure maturity
Even if economics favor one approach, infrastructure capability may dictate feasibility.
RAG requires:
- Strong data engineering.
- Reliable data pipelines.
- Efficient vector database architecture.
- Observability and monitoring.
Fine-tuning requires:
- High-quality labeled data.
- Machine learning expertise.
- Compute resource allocation.
- Evaluation discipline.
When teams ignore their actual capabilities, architecture decisions collapse under scale. Many production failures blamed on “model quality” are just traits of immature infrastructure.
Decision matrix
The following matrix translates the analysis into practical guidance.
| Scenario | Monthly queries | Knowledge update frequency | Recommendation | Rationale |
| Domain knowledge updates weekly, moderate traffic | 10–50M | Weekly/Daily | RAG | Immediate indexing and low recurring cost |
| High-scale traffic, knowledge stable | 50–100M+ | <1 update/month | Fine-tuning | Avoids recurring context injection, reduces latency |
| Structured output or code generation required | Any | Any | Fine-tuning | Embeds domain-specific rules and formatting internally |
| Specialized reasoning + frequent updates | 10–50M | Weekly/Daily | Hybrid | Combines internalized reasoning with dynamic knowledge |
| Multi-domain systems with diverse knowledge update cycles | 10–100M | Mixed | Hybrid | Fine-tuning stabilizes core domains, RAG handles rapidly changing sources |
Using this matrix, it becomes easier to make the decision whether to utilize RAG, fine-tune your LLMs, or use the hybrid approach.
Final Thoughts
The debate between RAG and fine-tuning is often framed as a binary choice, but the more useful question is “If hybrid systems demonstrably outperform either approach alone, why does industry adoption still overwhelmingly favor RAG?”
Hybrid requires both ML and data engineering capabilities simultaneously, a combination few organizations have. RAG remains the practical default, offering agility and transparency with less upfront complexity.
The key takeaway is to choose the architecture that matches your knowledge volatility, query scale, and team capability. For teams exploring enterprise-scale retrieval systems, platforms like Actian VectorAI DB provide purpose-built vector database capabilities designed for performance and scalability.
Join the Discord community and learn how Actian fits into your AI strategy.

Stay connected
Data insights delivered to you.
(i.e. sales@..., support@...)