5 Edge AI Architecture Patterns for Disconnected Environments




Summary
- Disconnected environments require edge AI architectures that operate fully offline without cloud dependency.
- Five deployment patterns enable resilient edge AI: drone, factory, federated learning, store-and-forward, and mesh network.
- Edge-native designs support real-time inference, low latency, and reliable operations in remote or intermittent networks.
- Choosing the right architecture depends on connectivity stability, latency requirements, and hardware constraints.
A haul truck operating 200 miles from the nearest cellular tower does not pause when connectivity drops. An offshore wind turbine does not suspend fault detection because a satellite link fails in a storm. In these environments, inference, control loops, and safety systems must continue operating regardless of network status. Yet the dominant edge AI architecture still revolves around connectivity and cloud AI.
Disconnected environments demand edge-native, offline-first architectures designed for operational autonomy. Market signals reinforce this reality.
ABI Research projects edge server spending to reach $19B by 2027, with on-premises deployments accounting for nearly $10.5B. In 2025, organizations deployed approximately 815 million edge-enabled IoT devices globally.
Most operational environments are inherently distributed, generating data far from centralized cloud systems. Edge deployment strategies that depend on sending that data back and forth for processing cause IoT systems to miss critical insights, increase latency, and introduce data loss. Yet proposed edge architectures still treat offline readiness as an add-on rather than the default.
We present five edge AI deployment patterns that operate without assumed connectivity, covering their implementation tactics, real-world scenarios, trade-offs, and a decision framework for selecting the right pattern for your operational priorities.
TL;DR
Suitable use cases for each documented deployment pattern at a glance.
| Pattern | Best for |
| The drone (self-contained single-node edge AI) | Autonomous mobile systems with strict energy budgets and zero cloud connection |
| The factory (multi-node edge AI with optional cloud) | Facilities with local infrastructure in intermittent environments |
| Hierarchical federated learning (client-edge-cloud) | Privacy-sensitive distributed operations where data leakage risks are unacceptable |
| Store-and-forward disconnected inference | Operations with scheduled connectivity windows |
| The network (distributed edge-to-edge fabric) | Distributed coordination without cloud dependency |
Why Disconnected Environments are an Edge AI Problem
There is a structural blind spot for disconnected environments, driven by the assumption that industries using edge AI models are cloud-centric and operate under persistent connectivity. Where edge AI applications matter most, constant network access does not exist.
What disconnected actually means
Disconnected environments are settings with unreliable or nonexistent connectivity, ranging from airgapped scenarios with complete network isolation to intermittent setups with frequent connectivity degradation.
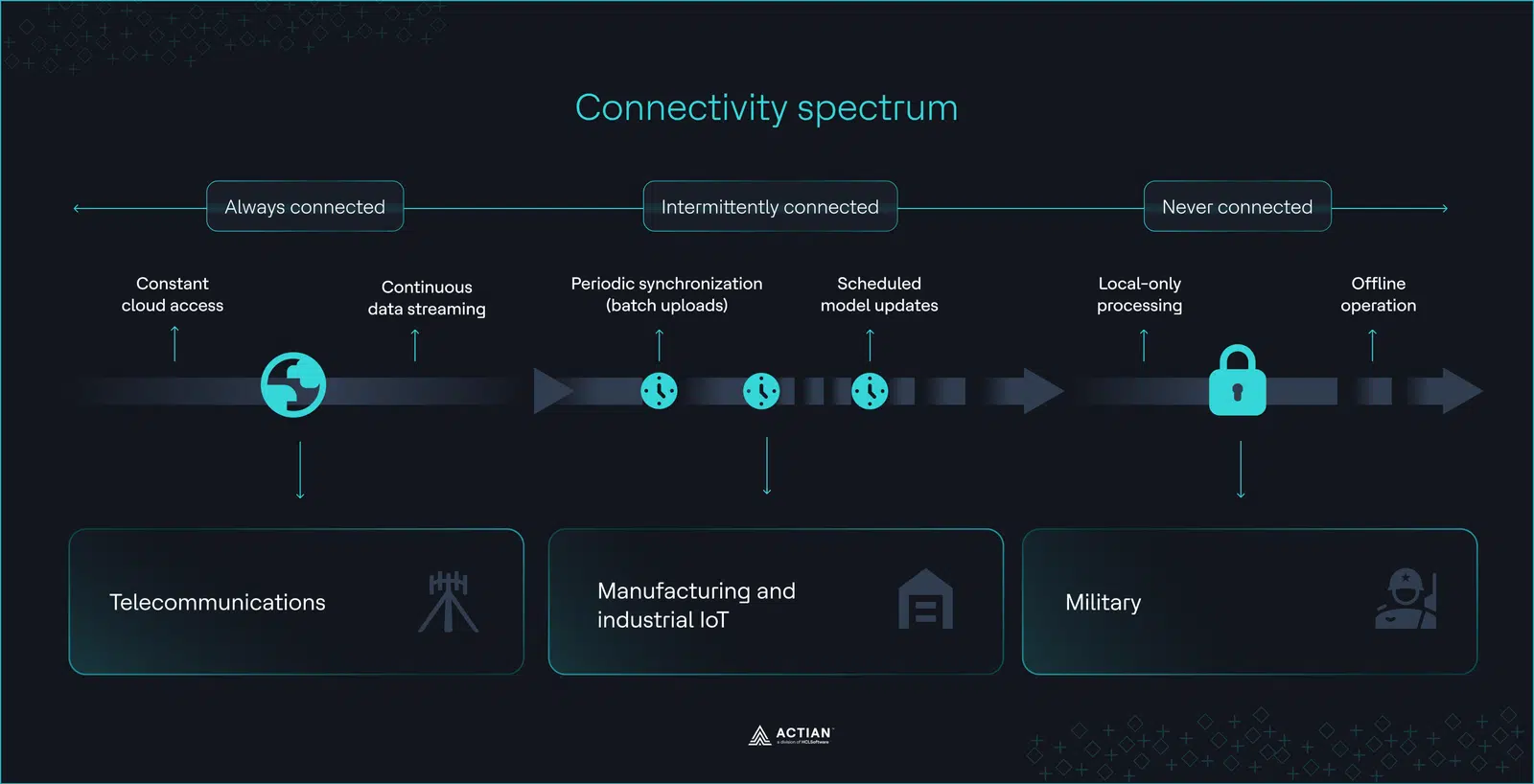
In these operational settings, edge AI capabilities truly shine because they support the real-time data processing, low latency, bandwidth optimization, and data governance that disconnected environments require.
Precedence Research estimates the global edge AI market will reach $143B by 2034, a potential 472% increase from $25B in 2025. For a significant portion of this market, constant cloud connectivity is not feasible. Yet inference, local data storage, and real-time decision-making must continue regardless of network status or location.
Disconnection is where edge AI earns its value
Disconnected environments such as mining sites, manufacturing plants, military operations, offshore wind farms, and smart cities expose the limitations of current edge AI deployment solutions.
Rio Tinto operates on mining sites up to 930 miles from cellular coverage, where operators cannot rely on a centralized infrastructure. They need autonomous inspection robots that use edge AI to track personnel and vehicles, interpreting data from 3D LiDAR, thermal imaging, and gas sensors in real-time.
At least 300 autonomous haul trucks operate in Rio Tinto’s Pilbara region. Each truck processes roughly 5TB of data daily through subterranean tunnels with limited connectivity, requiring private LTE networks for on-device IoT processing.
Offshore wind farms face a similar constraint. Turbines and inspection vessels go offline when satellite connections fail due to harsh weather or line-of-sight blockage, and each turbine averages approximately 8.3 failures per year. These farms need edge AI systems that detect issues early, monitor real-time maritime traffic, analyze local SCADA data, and trigger inspections based on immediate wind conditions.
In remote manufacturing environments, plant managers also need edge AI to automate quality inspections, predict machine failures, and protect workforce health.
A similar demand for local, secure processing drives military operations, where systems operate within airgapped networks in denied, disrupted, intermittent, and limited (DDIL) environments to maintain data confidentiality and integrity. Soldiers must communicate with command units and analyze real-time warfare data without relying on cloud data centers or large computing resources.
These are the environments where edge AI deployment delivers the most impact. According to Dell, enterprise data processing will shift to distributed data centers in 2026, but most documented architectures still emphasize transmitting data back to cloud data centers.
Constrained hardware shapes model deployment
The demands of AI compute and workload scaling at the edge also fuel the cloud-edge deployment recommendations.
A deep learning model with 3B parameters can require up to 4GB of RAM, but edge devices like microcontrollers and IoT sensors typically have less than 1GB for OS, workloads, and storage combined. Connected environment architectures assume large compute availability that doesn’t exist at the edge.
Edge AI architectures must start with offline-first assumptions and hardware ceilings from day one. Retrofitting offline capability into cloud systems will not compensate for connectivity gaps and limited hardware resources. Below, we detail five architectural patterns tailored for disconnected environments.
Pattern 1: The Drone (Self-Contained Single-Node Edge AI)
In environments where connectivity is unavailable, and operational latency cannot tolerate network round-trips, the deployment boundary collapses to a single device. Inference cannot be delegated, synchronized, or deferred. Edge devices like drones, underwater vehicles, and remote inspection robots must make decisions using only locally available compute, memory, and sensor input.
This constraint defines the drone architecture. All AI logic runs on a single device, without external orchestration or cloud offloading.
When the device is the entire stack
Mobile systems that must function autonomously in disconnected environments benefit most from this pattern.
With no external orchestration layer, data capturing, preprocessing, inference, storage, and control logic operate within a self-contained package. This package runs on a single node without networking with other nodes or distributing model training.
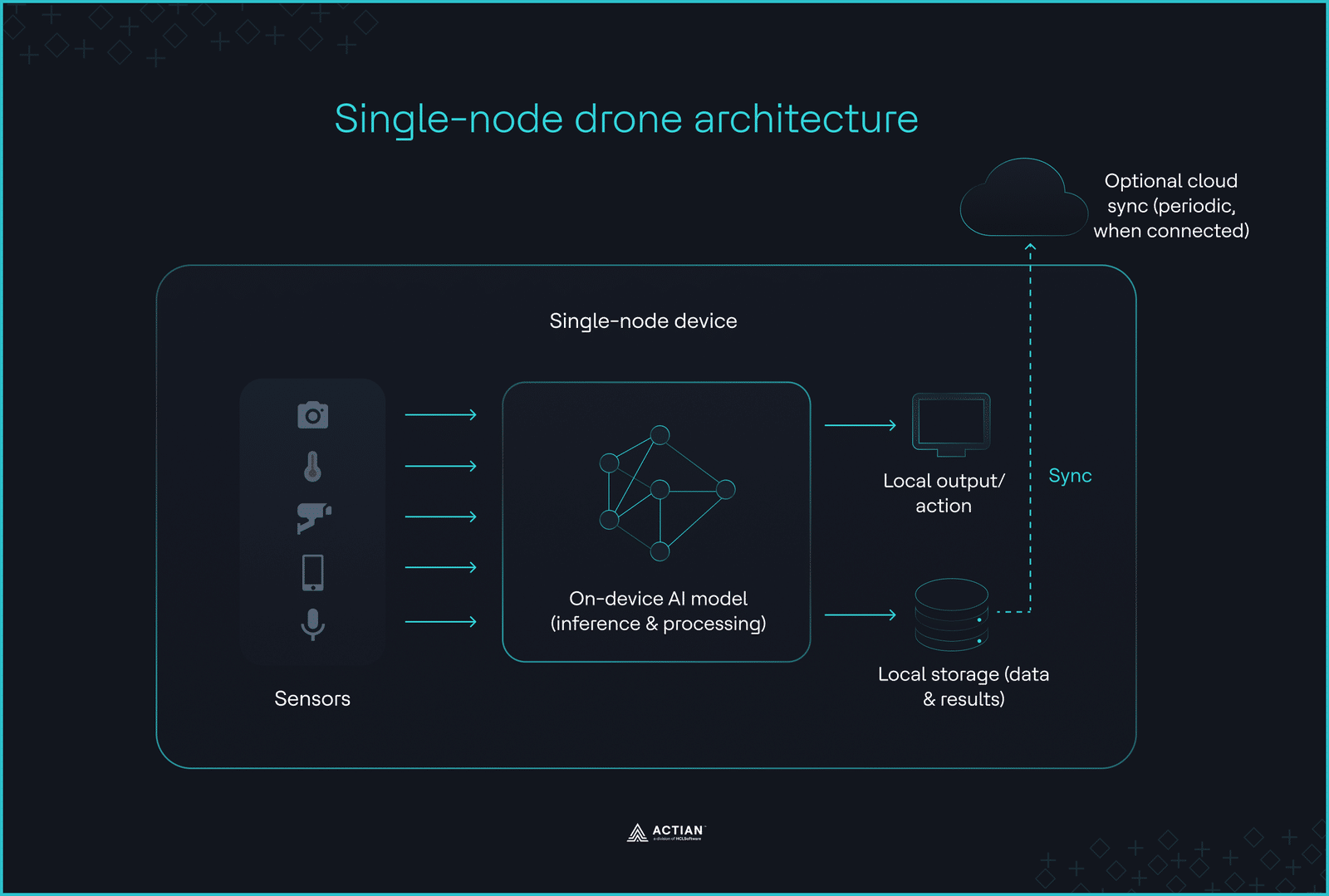
Onboard decision logic means edge devices can execute predefined operations even when disconnected. Once a device captures data, it filters out redundant information, retaining only relevant data for eventual manual retrieval.
Autonomous drones that perform object detection and terrain classification in mining zones cannot pause execution while awaiting external inference. The drone architecture removes network dependency by focusing on on-device inference.
This makes it the most viable pattern for DDIL environments where connectivity is actively denied or degraded. Defense drones cannot assume that the network will recover or that a command signal will arrive at all. Every battlefield coordination must be executable from the device alone.
GE Aerospace, which runs 45,000+ commercial aircraft engines and captures over 480,000 data snapshots daily per aircraft, implements this architecture at scale. Onboard AI models handle predictive maintenance in strict accordance with DO-178C, which requires GE Aerospace to verify every airborne system against all possible failure conditions before it ever leaves the ground. This quality assurance aligns with the drone’s architectural requirement of no external support after model deployment.
Single-node local processing requires machine learning models with small footprints.
Optimizing intelligence for the edge
Edge devices operate within strict memory and power ceilings measured in megabytes and milliwatts. When full-precision networks exceed available RAM or energy budgets, model capacity must be optimized before inference becomes feasible.
Not every edge workload needs a neural network. In constrained environments like offshore wind farms, classical statistical methods, such as Welford’s algorithm and linear regression often outperform neural networks on streaming data processing.
A microcontroller computing sensor data with Welford’s algorithm updates statistics sequentially, without retaining past data points, which keeps memory and power consumption low. Before pushing a neural network to its hardware limit, consider whether the model class itself is suitable for the use case.
When neural networks are the right fit for the workload, quantization addresses their hardware limitations by reducing the numerical precision of their weights, biases, and activations. Downsizing from 32-bit to 8-bit shrinks model size by approximately 75% with less than 1% accuracy loss.
Another model compression technique, pruning, eliminates redundant parameters that contribute minimally to output accuracy. Pruning an object detection model like YOLOv5 can reduce its parameter count and computational cost by 40% before deployment.
TinyML frameworks such as TensorFlow Lite for Microcontrollers, ONNX Runtime, and PyTorch Mobile support compact model deployment. The following code shows an example quantization scenario with TensorFlow Lite.
import tensorflow as tf
import numpy as np
# Post-training quantization using TFLite converter
# Converts 32-bit floats to 8-bit integers
def representative_dataset():
for i in range(100):
yield [X_train[i:i+1]]
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.representative_dataset = representative_dataset
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.inference_input_type = tf.int8
converter.inference_output_type = tf.int8
tflite_quant_model = converter.convert()
Start with quantization for higher speedup rates without significant accuracy loss, followed by pruning to compress the model’s size further. For the drone architecture, the target size on a single microcontroller is <1MB. Plumerai’s person detection model demonstrates how compression techniques can achieve this goal. The model achieved 737KB on an ARM Cortex-M7 microcontroller with less than 256KB of on-chip RAM using binarized neural networks.
At the hardware level, energy-efficient processors such as the NVIDIA Jetson Nano, Google Edge TPU, and ARM Cortex-M execute AI models directly on edge devices, purpose-built for computer vision and sensor fusion workloads. ARM Cortex-M variants deliver up to 600 giga-operations per second (GOPS) with an energy efficiency averaging 3 tera-operations per second per watt (TOPS/W), depending on configuration.
Drone deployment introduces an architectural rigidity. With limited runtime intervention, the architecture must anticipate every failure state during design. The DO-178C reinforces this constraint by requiring full system validation before deployment. Teams must engineer every model update and behavioral correction with no orchestration window.
Pattern 2: The Factory (Multi-Node Edge AI With Optional Cloud)
During network outages in manufacturing and large retail facilities, inference must continue in-house across multiple machines. The factory architecture meets this requirement by distributing AI workloads across on-premises edge clusters, keeping operational control within the facility boundary.
Cloud synchronization remains optional, used only for model retraining or batch analytics rather than as a runtime dependency. The priority is maintaining resilience and operational independence across all nodes, regardless of network availability.
Inference stays on the factory floor
The factory architecture centers on three components: edge gateways, compute nodes, and local storage.
An edge gateway routes sensor requests to edge nodes, which pull context from local edge databases like Actian Zen, act on model inference, and write the results back to the database. Decision-making and local computing stays on-premises. Cloud systems only handle model updates periodically or on trigger.
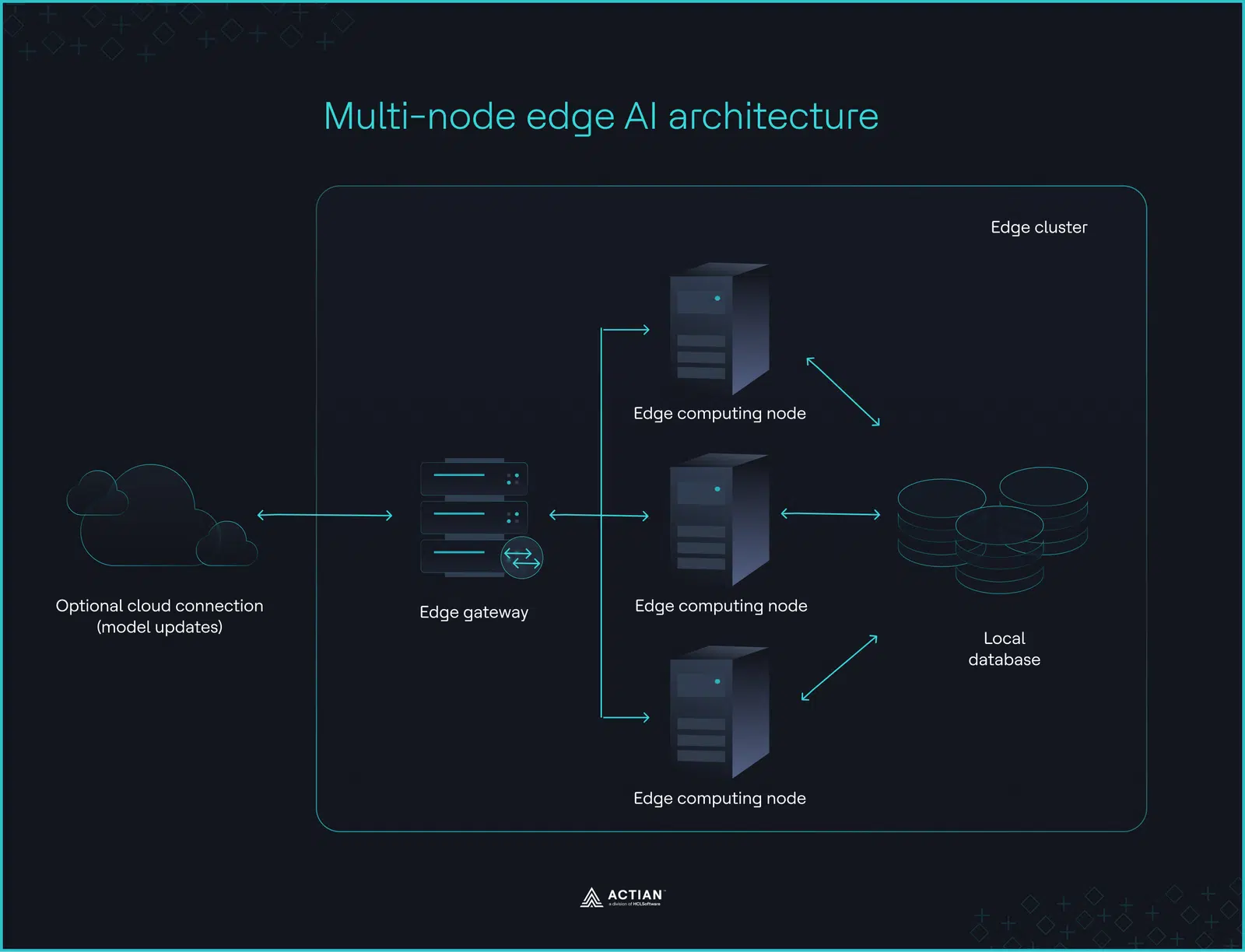
Industrial environments generate continuous, high-volume telemetry data from sensors, controllers, and inspection systems. Distributing inference across multiple edge nodes maintains high inference throughput. But without a local orchestration layer managing distribution and managing model lifecycle, edge nodes operate as isolated processors rather than a coordinated system.
K3s, AWS IoT Greengrass, Azure IoT Edge, and Siemens Industrial Edge are popular orchestration tools for managing edge clusters. Each differs in how they handle model deployment and node management.
K3s deploys containerized models as clusters of worker nodes with a control plane for health visibility. Configuring its datastore endpoint parameter enables teams to store local data in on-premises databases like PostgreSQL and Actian Zen, replacing the default SQLite. Chick-fil-A uses K3s at the edge to process point-of-sale transactions across 3,000+ restaurants.
AWS IoT Greengrass deploys cloud-compiled AI models as components with predefined inference functions to NVIDIA Jetson TX2, Intel Atom boards, and Raspberry Pi-powered devices. Inference remains on-premises, with data exported optionally to AWS IoT Core for model optimization. Pfizer manufacturing sites use AWS IoT Greengrass for near-real-time bioreactor monitoring to minimize contamination risk.
Siemens Industrial Edge deploys Docker-containerized models directly on the shop floor, delivering real-time machine status. Siemens Electronics Factory Erlangen reduced model deployment time by 80% and false anomaly detection on printed circuit boards (PCBs) by 50% using this orchestrator. By running inference on PCB images locally and outsourcing only model retraining to the cloud, the factory has saved data storage costs by 90%.
Azure IoT Edge uses a JSON deployment manifest to specify which containerized models to download to edge devices. Data processing happens at the edge with Azure IoT Hub providing centralized oversight while the devices maintain autonomy. Thomas Concrete Group uses Azure IoT Edge to collect data from sensors embedded in wet concrete, estimate the concrete’s hardening timeline, and send predictions to Azure IoT Hub.
The table below highlights the differences between each orchestrator.
| Criteria | K3s | Azure IoT Edge | AWS IoT Greengrass | Siemens Industrial Edge |
| Node management | Manages nodes via a lightweight control plane | Manages nodes remotely through Azure IoT Hub | Manages nodes via AWS IoT Core | Manages nodes via the Siemens Industrial Edge Management platform |
| Model deployment | Deploys models as Kubernetes pods using standard container images | Configures deployments via a JSON manifest that defines which modules, containing the trained models, run on which nodes | Deploys models as components with predefined inference functions | Deploys models directly on shop floors as Docker containers |
| Cloud integration | Can be integrated with a central infrastructure | Supported via Azure IoT Hub | Integrates with AWS IoT Core | Supports integration with AWS services |
When the OT network is the security boundary
Industrial companies converge their IT and operational technology (OT) networks to support on-premises AI and IoT integrations. But this convergence expands their attack surface area. 75% of OT attacks originate in IT environments, and 80% of manufacturers report increasing security threats across their IT/OT networks.
For teams considering factory deployment for industrial systems, network segmentation must become a top priority. Edge AI solutions should operate solely within the OT network in compliance with the Purdue model. Sensitive data and inference stay close to the machines, sensors, and Programmable Logic Controllers (PLCs) that need them. This security boundary minimizes lateral movement of threats from the IT network.
Pattern 3: Hierarchical Federated Learning (Client-Edge-Cloud)
Hierarchical federated learning (HFL) builds on a three-layer infrastructure for teams navigating data mobility restrictions at the edge.
At the lowest layer, client devices perform local training, optimizing model parameters through local gradient descent. Edge servers at the intermediate layer aggregate updated model weights from all client devices for statistical coherence. A final aggregation round by a cloud server marks the top layer, producing a global model that the edge servers distribute back to the client devices. Since only parameter updates traverse this hierarchy, intermittent connectivity does not halt training progress.
The image below captures this iteration, which continues until the global model reaches the desired accuracy or converges.
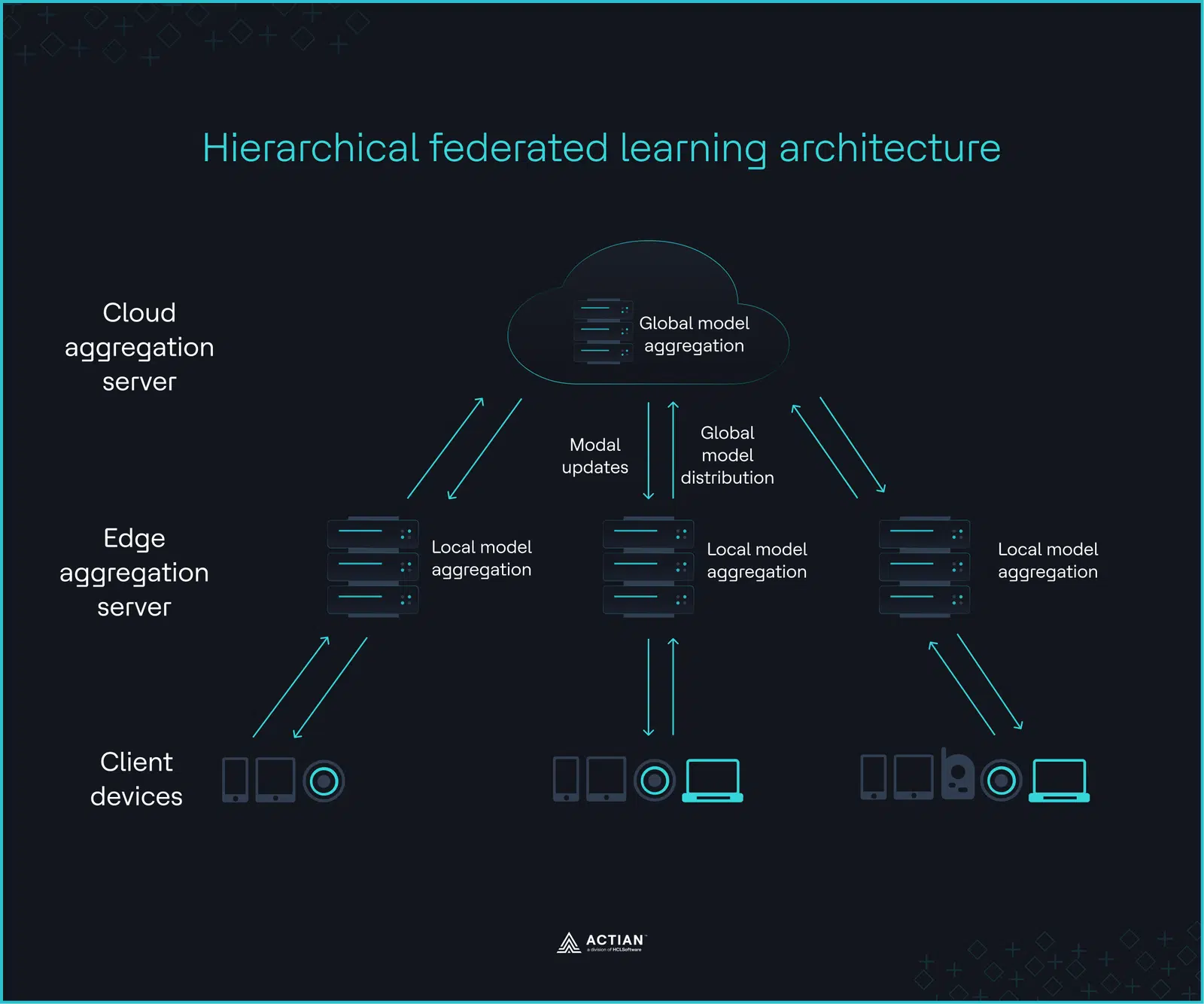
Domains such as healthcare and financial services, where raw data is bound to its origin by privacy constraints, regulatory requirements, and bandwidth limitations, are ideal HFL use cases. Data sovereignty mandates and geopolitical tensions add another layer to this constraint, restricting where and how data flows at the infrastructure level.
A study by BARC found that 19% of companies plan to increase their on-premises investments, driven by this need for data sovereignty. HFL allows a shared model to improve across distributed nodes without the underlying data ever crossing a jurisdictional boundary.
A recent experimental HFL training in healthcare achieved 94.23% accuracy on a modified National Institute of Standards and Technology dataset, while keeping data on client devices. Only relevant aggregated information ever reaches the cloud to preserve privacy and curtail data leakage risks.
In healthcare deployment, wearable devices (lowest layer) transmit raw data to a hospital’s local edge server (intermediate layer), which aggregates data from multiple wearables and sends it to a regional research institution (top layer) for final aggregation without exposing patient data.
HFL is the most complex pattern to implement. Tooling support remains fragmented, and unlike other patterns discussed, it currently lacks native support within the Actian ecosystem. Teams should weigh this implementation overhead before committing to this architecture.
The HFL architecture has three variants depending on which layer orchestrates data decisions.
1. Cloud-orchestrated hierarchical federated learning
The central cloud server coordinates the training process, client-edge communications, synchronization schedules, and the overall topology, with no additional aggregation rounds from the edge servers.
Cloud-orchestrated HFL fits financial institutions, where occasional reliable connectivity can sustain the coordination loop. In a fraud detection deployment, multiple banking institutions might train models using transaction data, sending updates to the cloud, which aggregates, validates, and redistributes the improved model back to the banks.
2. Edge-orchestrated hierarchical federated learning
Edge servers autonomously manage local client assignments, aggregating client updates to produce a locally improved model without cloud round-trips. Cloud systems only support at interval for bulk model retraining. Environments like offshore wind farms, where unstable connectivity is the baseline, benefit most from this variant. Turbines send model updates to a local edge server, which handles aggregation and independent model improvement.
3. Peer-to-peer aggregation
This variant focuses on a gossip-like model with no central orchestrator. Clients exchange their model weights with other nodes, reducing gradient conflicts under heterogeneous data.
Where the core HFL pattern reduces cloud ingress fees through aggregated updates, peer-to-peer aggregation keeps both training and aggregation within participating nodes. In distributed environments like smart cities, traffic sensors exchange anomaly-detection updates directly with neighboring devices until they converge on an improved model across the network organically.
All three variants differ in their functional requirements, highlighted in the table below.
| Feature | Cloud-orchestrated | Edge-orchestrated | Peer-to-peer aggregation |
| Orchestration model | Cloud coordinates all aggregation and model distribution | Edge server aggregates locally, syncs with cloud periodically | No orchestrator; updates propagate between clients until convergence |
| Privacy level | Medium; the cloud controls model updates | High; raw data remains on local edge servers | High; no central point oversees aggregated updates |
| Bandwidth requirements | High; all updates are sent to the cloud | Medium; only aggregated updates reach cloud | Low; updates only travel between neighboring peers |
| Disconnection tolerance | Low; cloud disconnection breaks coordination | High; edge server operates independently during outages | Medium; network partitions slow convergence |
HFL’s layered infrastructure supports large-scale model training by distributing computation and communication across multiple nodes in the hierarchy. The challenge with this multi-tier design lies in navigating communication overhead, stale global models, and node reconfigurations.
In HFL, communication cost is directly proportional to the model update size. Gradient compression techniques such as random sparsification and stochastic rounding shrink update payloads by up to 98% before transmission.
The asynchronous update cycle of HFL, where the global model incorporates client updates as they arrive, also amplifies the likelihood of stale model parameters. Weighted aggregation limits the influence of stale updates, preventing slower devices from degrading the global model.
Topology shifts add another challenge. Clients get reassigned to different edge servers, roles shift between client and aggregator nodes, and new devices join mid-training. Each reconfiguration stalls convergence and degrades accuracy if new edge servers lack prior training history.
Pattern 4: Store-and-Forward Disconnected Inference
In disconnected environments, intermittent connectivity can stretch for hours or days. Store-and-forward architecture accounts for this reality, sustaining large-scale data processing and storage during downtime, and forwarding summaries to the cloud once the system reconnects.
For industrial automation environments, such as remote oil and gas operations and maritime vessels operating miles from cellular towers, this architecture solves the core problem of maintaining data continuity despite network disruption.
Inference doesn’t wait for the cloud
Store-and-forward deployment follows a hybrid approach. Training begins in the cloud, but execution shifts to the edge after model deployment. When connectivity drops, decision-making, control loops, and alarm triggers continue locally without interruption, and the system buffers timestamped results to a local edge database until synchronization resumes.
Upon network restoration, the edge gateway offloads all buffered events to a central cloud infrastructure, providing the data required to push updated models and optimize AI pipelines.
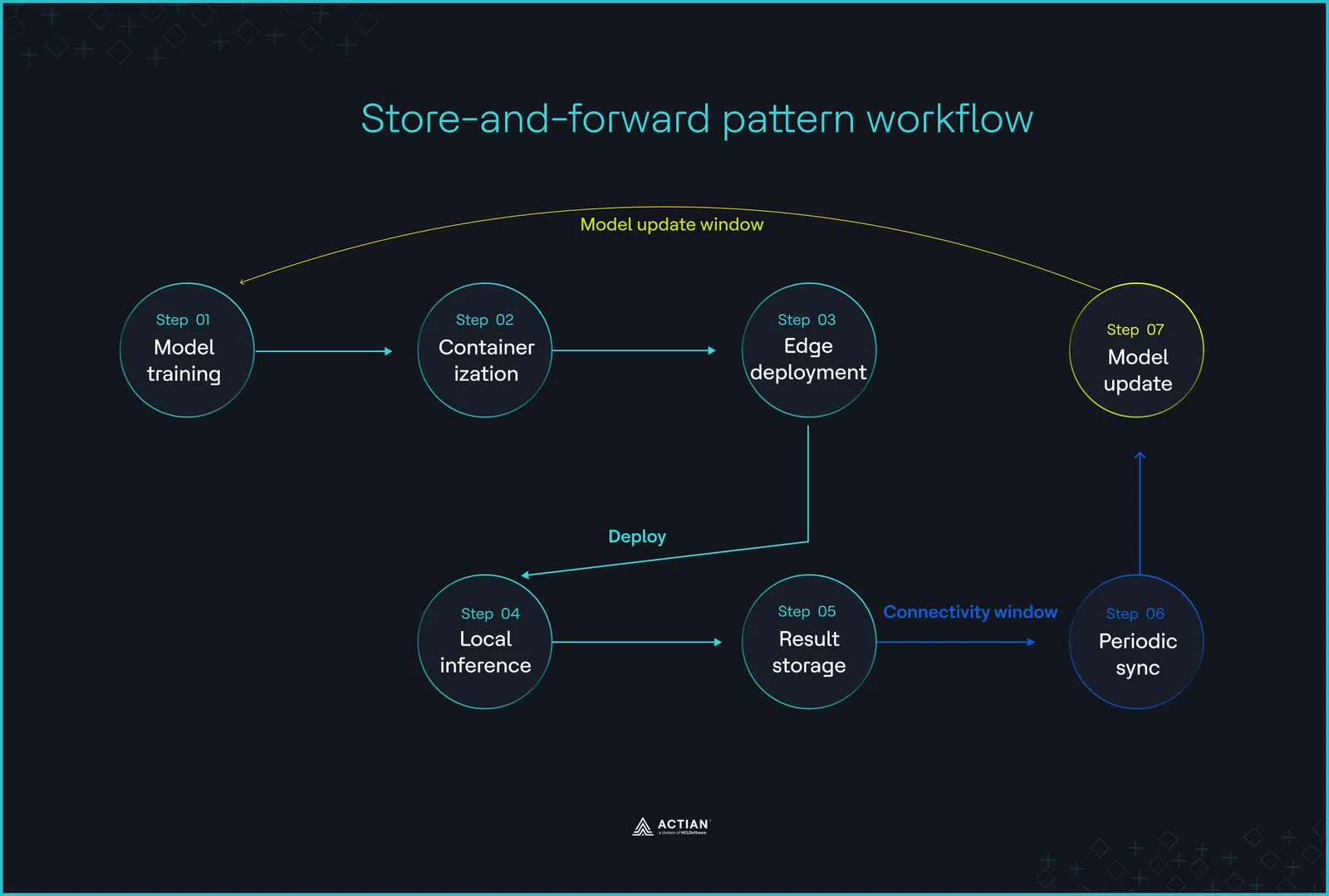
Store-and-forward architecture creates a feedback loop that prevents data loss during disconnection. In manufacturing plants, SCADA systems continue collecting data from PLCs, Remote Terminal Units (RTUs), and edge gateways until connection resumes.
When the data finally moves
The “forward” part of this architecture relies on lightweight communication protocols like Message Queuing Telemetry Transport (MQTT), designed for unstable networks and bandwidth-limited environments.
MQTT’s publish-subscribe model routes queued updates from edge gateways to the cloud through brokers like Mosquitto. Publishers (sensors) send messages to a topic (temperature), and subscribers (cloud servers) receive messages from their registered topics. Messages replay in the exact chronological order they were received.
The Python code snippet below illustrates a starting-point implementation using the Paho MQTT library. It uses Quality of Service (QoS) 1, a persistent session that enables Mosquitto to queue messages while the subscriber is offline.
# pip install paho-mqtt
import paho.mqtt.publish as publish
import sys
if len(sys.argv) < 3:
print("Usage: publisher.py <topic> <message>")
sys.exit(1)
# Production code will add retry logic, local queue persistence, and message deduplication
topic = sys.argv[1]
message = sys.argv[2]
publish.single(topic, message, hostname="localhost", qos=1)
To initiate data transfer after reconnection, the script below creates a persistent session using clean_session=False and loop_forever().
import paho.mqtt.client as mqtt
import sys
if len(sys.argv) < 2:
print("Usage: subscriber.py <topic>")
sys.exit(1)
topic = sys.argv[1]
client_id = "test-client"
def on_connect(client, userdata, flags, rc):
print(f"Connected with result code {rc}")
client.subscribe(topic, qos=1)
def on_message(client, userdata, msg):
print(f"{msg.topic}: {msg.payload.decode()}")
client = mqtt.Client(client_id=client_id, clean_session=False)
client.on_connect = on_connect
client.on_message = on_message
client.connect("localhost", 1883, 60)
client.loop_forever()
Store-and-forward architecture can introduce data replication inconsistencies during gateway synchronization. The system requires an arbitration policy, such as last-write-wins, which applies changes based on each update’s timestamp. When timestamps are identical, data structures like Conflict-free Replicated Data Types (CRDTs) merge copies to achieve a consistent final state across all edge gateways.
Delta sync further improves CRDTs’ results. Where full dataset replication triggers on every record change, delta sync resolves conflicts at the property level, addressing only the modified fields.
Pattern 5: The Network (Distributed Edge-to-Edge Fabric)
The network deployment pattern addresses the lack of fault tolerance and distributed processing prevalent in disconnected multi-site operations such as logistics networks and smart grids.
Coordinating edge devices across multiple locations through a cloud system quickly breaks outside network coverage. This is why the network architecture follows an east-west communication pattern, enabling edge nodes to exchange data directly with peers without central coordination.
Mesh communication handles distributed intelligence
The network deployment pattern adopts a non-hierarchical design, connecting multiple IoT devices through a mesh network to improve system uptime during outages. Each node dynamically communicates with its neighbors, forming a bidirectional network that relays data to remote environments via multi-hop paths.
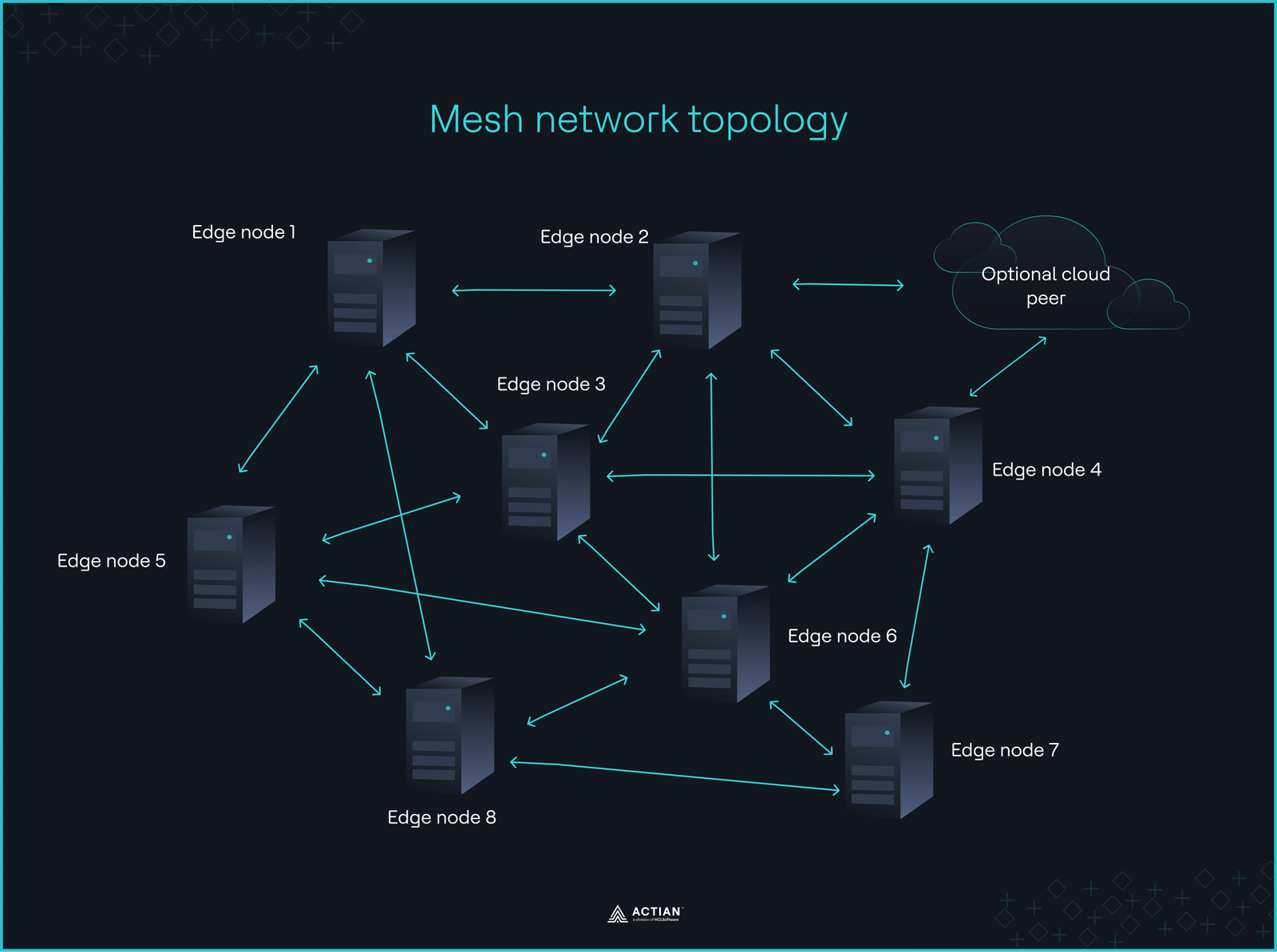
The cloud only joins as a peer for optional sync, but core computing remains on the network, working without centralized control.
Smart grids are well-suited for this architecture, where teleprotection demands 10–20ms latency. A network of transmission substations continuously tracks electricity flow and consumption patterns in real-time to detect imbalances before they escalate. That real-time visibility supports dynamic load redistribution and autonomous microgrid management.
Military uncrewed aerial vehicles (UAVs) are another use case. When GPS fails in DDIL environments, UAVs relay ISR data between each other through mesh networks. Adaptive interference routing ensures reliable data flow, while line-of-sight transmission reduces latency.
This deployment pattern optimizes for network redundancy. Gossip protocol and distributed consensus algorithms like Raft eliminate single points of failure. When a node loses connection, the network remains operational, rerouting its data through other nodes.
Gossip protocol enables live peer discovery through continuous, lightweight information exchanges. Each node always has a current view of its local network. Raft follows a leader-based approach where an elected leader node handles all writes, and log replication ensures follower nodes maintain a shared state. Edge databases replicate data across multiple nodes to improve consistency.
Treating Gossip and Raft as competing options overlooks what actually matters. The focus should be on understanding where each sits in the CAP theorem and the trade-offs they introduce to a distributed network.
The consistency vs. availability trade-off
When network partitions split the mesh, Raft ensures strong data consistency, while Gossip provides availability fallback and eventual consistency when paired with approaches like CRDTs.
In edge computing, where connection is limited and nodes are numerous, partition tolerance is non-negotiable. Edge AI systems must choose whether to prioritize consistency or availability when implementing the network architecture.
Availability is often optimal, as edge nodes continue to function independently after disconnection. Consistency-focused designs like Raft risk write suspensions and stale reads during network partitions.
| Feature | Raft | Gossip |
| Architecture | Leader election and log replication | Peer-to-peer |
| Latency | Moderate; requires at least a quorum of nodes in a network to become available | Low; messages travel quickly but propagation rounds can slow down speed |
| Consistency guarantees | Strong consistency | Eventual consistency |
| Partition tolerance | Moderate; might not survive a partition | High; heals partitions faster |
Speed and data delivery trade-offs are another critical constraint of the network architecture. Mesh networking adds latency with each hop as the node count increases. If your system needs data back in <50ms or your latency requirements can tolerate >100ms, this trade-off should shape your design decision.
Choosing the Right Edge AI Deployment Pattern
There’s no specific “right” edge AI deployment pattern for disconnected environments. A solid architecture implementation begins with a clear grasp of the specific constraints, goals, and characteristics of your target application. This means envisioning the full workload lifecycle, including connectivity profile, available compute resources, and latency requirements.
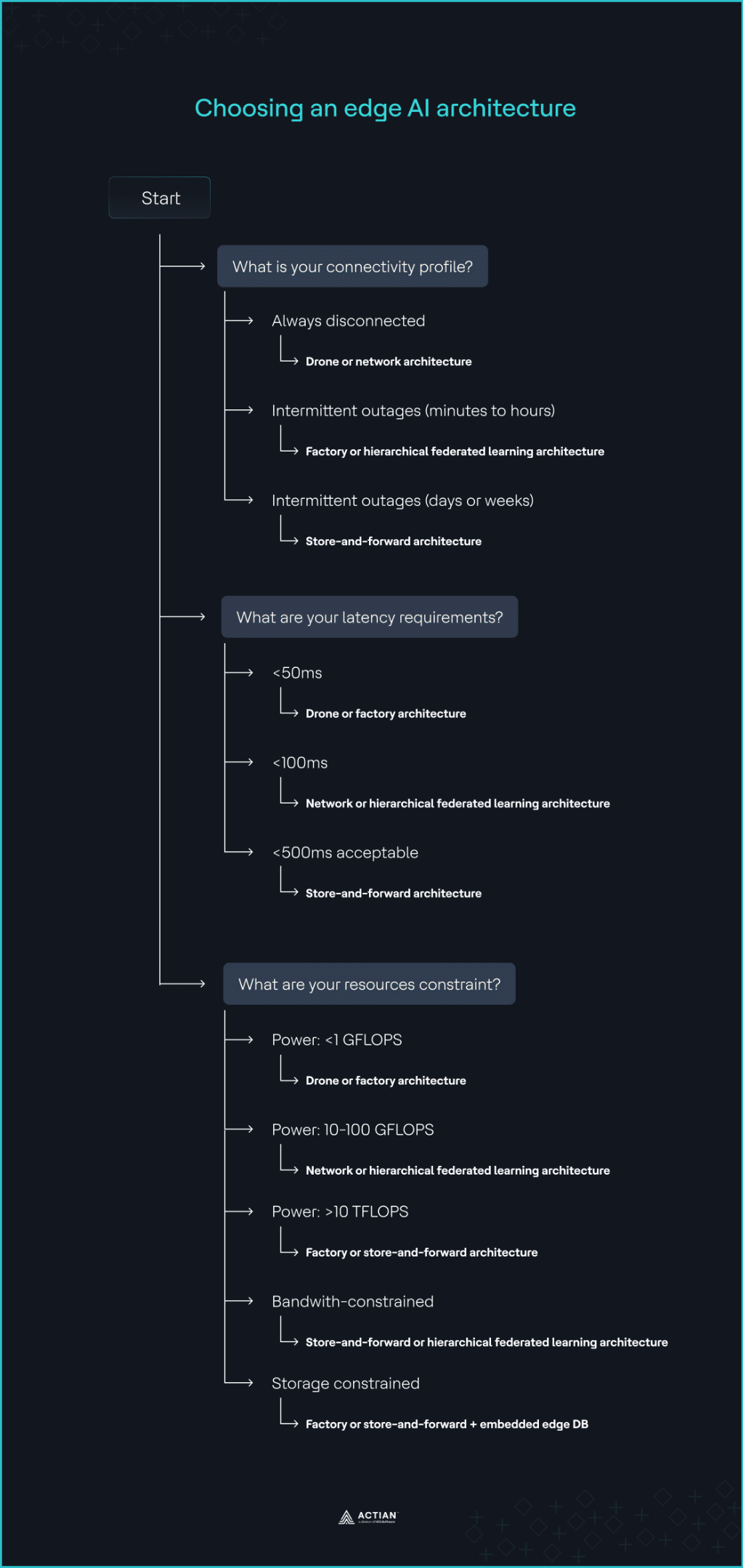
1. Evaluate network stability
Network stability is the primary driver of any edge AI deployment strategy. Determine how much resilience must be engineered into the edge nodes based on the expected duration of disconnection.
- If the system is always disconnected: Use drone or network architectures as they are designed to operate completely offline regardless of connectivity status.
- If the interruption persists for only minutes or hours: Use factory or HFL architecture to continue data aggregation and inference without interruption. The system remains functional during the outage because all required dependencies already exist within the operational perimeter.
- If intermittent connectivity lasts for days or weeks: Use the store-and-forward architecture to buffer inference results and operational data locally until the scheduled connectivity window becomes available again.
2. Assess latency requirements
Define the maximum acceptable latency for your specific application by considering network hops, node availability, and geographical proximity of the edge nodes. The thresholds below reflect typical deployment patterns. Validate them against your specific hardware and network conditions.
- If the system requires <50ms latency: Use the drone deployment pattern. Its single-node architecture keeps inference directly on sensors, cameras, or gateways, enabling near-real-time responses. Factory architecture also minimizes latency by running on edge servers within the same facility or on the factory floor.
- If the system requires <100ms latency: Use the network or HFL architecture to distribute model improvement workloads across multiple nodes.
- If <500ms latency is acceptable: Use store-and-forward architecture for non-critical IoT data that requires batch processing or long-term analytics. It batch-offloads data-intensive tasks to the cloud.
3. Evaluate resource constraints
Edge AI applications differ in processing power, storage, and bandwidth consumption, which impacts inference speed, data aggregation, and real-time analytics. Evaluate each resource limit independently:
- Power constraint: For compute power <1 GFLOPS, common in microcontrollers used for sensor inference, the drone architecture is most suitable. It runs on constrained IoT devices using lightweight, inference-only models. At 10–100 GFLOPS, common in edge gateways, HFL and network architectures become more effective as they handle data aggregation needs well at this level. For edge GPU clusters that scale to >10 TFLOPS, factory and store-and-forward architecture support clustered inference pipelines, since they run on-premises.
- Bandwidth constraint: Use store-and-forward architecture or HFL to store and process raw, high-volume data at the edge, forwarding only summarized updates to the cloud if required.
- Data storage constraint: Use factory or store-and-forward architectures paired with embedded databases to store time-series data locally and scale vertically within the facility. Databases like Actian Zen are optimized for edge AI use cases and can also sync with the cloud once connectivity is restored.
4. Consider a hybrid approach
Industrial systems often combine the strengths of multiple architectures into a coordinated system that delivers resilience and flexibility. Rio Tinto’s mining operations illustrate what hybrid deployment looks like at scale.
At the Greater Nammuldi iron ore mine, more than 50 autonomous trucks operate on predefined routes, using onboard sensors to detect obstacles, an example of the drone architecture. Across 17 sites in Western Australia, these trucks transmit operational data to Rio Tinto’s Operations Centre in Perth, reflecting the network architecture. Finally, an autonomous rail system transports mined ore, synchronizing with the Operations Centre upon reaching port facilities. This fits the store-and-forward architecture.
Rio Tinto demonstrates that deployment patterns are not mutually exclusive. If your use case requires multiple architectures, consider running them on the layer of the system where they’re best suited, rather than forcing a single architecture across the entire operation.
The following table maps specific deployment scenarios to their optimal disconnected edge AI deployment pattern to inform your decision.
| Deployment scenarios | Recommended pattern | Rationale |
| Autonomous inspection drones over oil fields or offshore wind farms | Drone (single-node self-contained) | A self-contained inference runtime with embedded local storage eliminates distributed computation to meet hardware limitations |
| Automotive assembly lines running defect detection models | Factory (multi-node edge AI) | Cloud dependency is too risky for uptime requirements, so edge clusters run within the facility |
| Hospital networks where patient data cannot leave individual facilities under HIPAA | Hierarchical federated learning | Models train locally, sharing only weight updates to the cloud, so raw data remains on the local site in compliance with data sovereignty and privacy |
| Cargo vessels at sea syncing operational data at port | Store-and-forward | A local buffer ensures no inference result or operational event is lost across connectivity gaps that can last days |
| Smart city traffic management across distributed intersections with no central server dependency | Network (distributed edge-to-edge fabric) | Nodes communicate peer-to-peer via consensus, so node loss reduces capacity without disrupting overall network operation |
The Bottom Line
Industries operating across remote, underground, maritime, and geographically dispersed terrain need edge-native architectures that capture real-time insights and keep critical assets running without cloud dependency.
The deployment patterns discussed prioritize what matters most for disconnected environments: local inference, no centralization latency, lower communication costs, and system autonomy.
Before committing to a pattern, validate three things in your own environment: how long your system can tolerate network outage before data loss becomes operationally significant, whether your edge hardware can sustain the compute demands of your chosen architecture without degrading inference quality, and whether your team has the tooling maturity to manage model lifecycle at the edge without cloud dependency. Map your constraints against the decision framework above.
The right answer might not be a single pattern. Layer in hybrid approaches only when the resilience gains justify the operational complexity.
Each pattern depends on a data infrastructure that can operate, store, and sync entirely at the edge. For teams that need to go beyond structured storage and perform semantic search on their local data without exporting vector embeddings to a cloud server, Actian VectorAI DB is optimized for this use case. Join the waitlist for early access.
Join the Actian community on Discord to discuss edge AI architecture patterns with engineers deploying in disconnected environments.

Stay connected
Data insights delivered to you.
(i.e. sales@..., support@...)