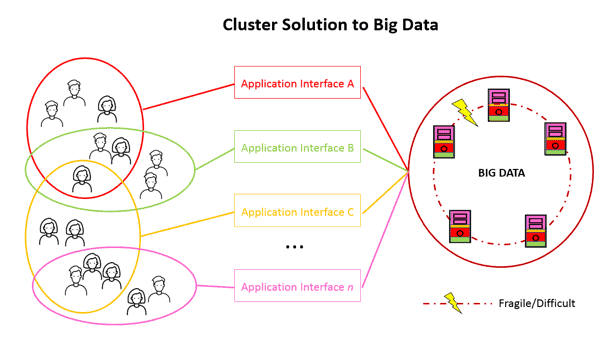
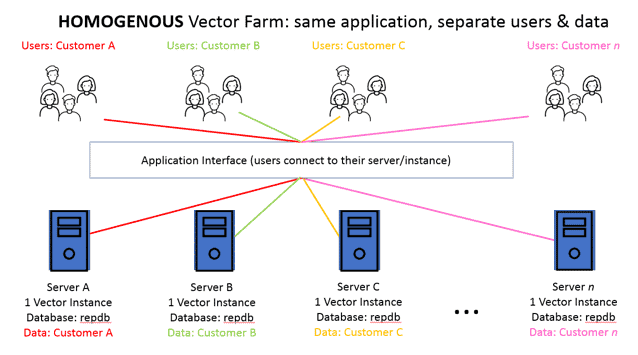
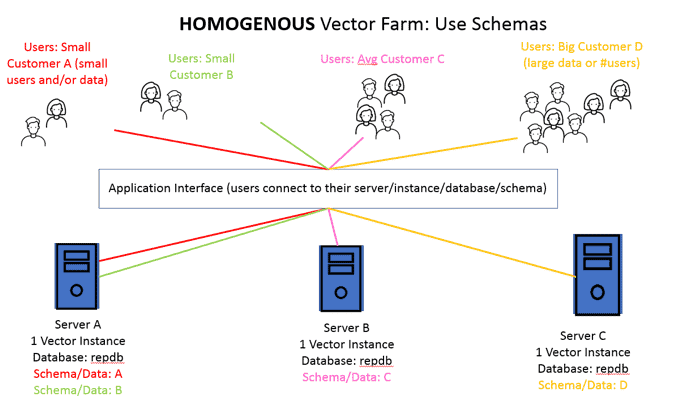
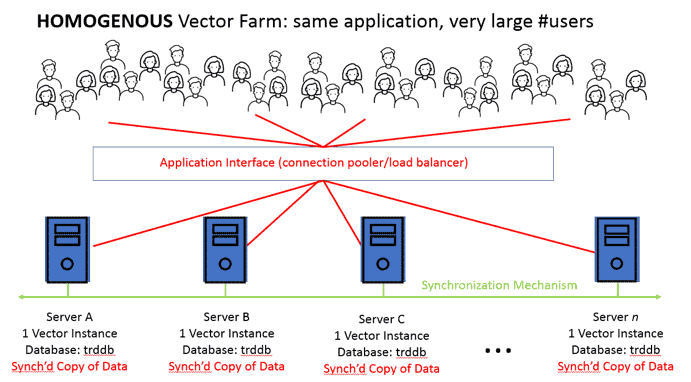
Automatically Synchronize Your OLTP and OLAP Tables in Ingres 11
Alex Hanshaw
February 9, 2018

A key feature of the latest update to our hybrid database Ingres 11 is the inclusion of the x100 analytics engine and support for x100 tables. Adding a world-class analytics engine to Ingres enterprise OLTP (OnLine Transaction Processing) capability enables a new class of applications that can mix OLTP and analytic queries – with each query being directed to the appropriate execution engine.
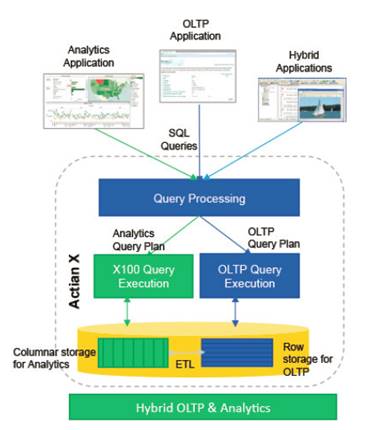
Actian engineers have just delivered an enhancement to Ingres which adds support for X100 table references in database procedures. This allows database procedures and rules to be used to trigger updates, inserts and deletes against X100 tables when inserts, updates and deletes are applied to Ingres tables. This means you can automatically synchronize your OLTP (Ingres) and OLAP (X100) tables, adding new transactional data to your analytics data.
The following example will walk you through the creation of two tables (airport and airport_X100) and the creation of the database procedures and rules that will mirror inserts, updates and deletes from the Ingres table to the X100 table. Take a look and let us know what you think!
This enhancement is delivered via a patch that can be downloaded from esd.actian.com here.
Create an OLTP table (airport) and an OLAP (OnLine Analytical Processing) target (airport_x100):
CREATE TABLE airport ( ap_id INT, ap_iatacode NCHAR(3) NOT NULL, ap_place NVARCHAR(30), ap_name NVARCHAR(50), ap_ccode NCHAR(2))g commit; g CREATE TABLE airport_x100 ( ap_id INT, ap_iatacode NCHAR(3) NOT NULL, ap_place NVARCHAR(30), ap_name NVARCHAR(50), ap_ccode NCHAR(2)) with structure=x100g commitg
First we’ll create a procedure that can be used to mirror inserts from airport into airport_x100:
CREATE PROCEDURE proc_ins_airport_x100 (apid INT NOT NULL NOT DEFAULT, apiatacode NCHAR(3) NOT NULL NOT DEFAULT, applace NVARCHAR(30) NOT NULL NOT DEFAULT, apname NVARCHAR(50) NOT NULL NOT DEFAULT, apccode NCHAR(2) NOT NULL NOT DEFAULT) AS BEGIN INSERT INTO airport_x100 ( ap_id, ap_iatacode, ap_place, ap_name, ap_ccode) VALUES ( :apid, :apiatacode, :applace, :apname, :apccode); ENDg
Now we create a rule that will automatically trigger on an insert into airport and fire the procedure proc_ins_airport_x100 with each parameter containing the column values that were part of the insert into airport:
CREATE RULE trg_ins_airport_x100 AFTER INSERT INTO airport EXECUTE PROCEDURE proc_ins_airport_x100 (apid = new.ap_id, apiatacode = new.ap_iatacode, applace = new.ap_place, apname = new.ap_name, apccode = new.ap_ccode)g
We insert 4 rows into the OLTP table airport:
INSERT INTO airport VALUES (50000, 'AAA', 'Vector', 'Aomori', 'AU')g INSERT INTO airport VALUES (50001, 'AA1', 'Vector', 'Tegel', 'AU')g INSERT INTO airport VALUES (50002, 'AA2', 'Vector', 'Tegel', 'NL')g INSERT INTO airport VALUES (50003, 'AA3', 'Vector', 'Tegel', 'NL')g
Now we see if our target OLAP table (airport_x100) has been updated:
select ap_id, ap_iatacode as iatacode, cast(ap_place as varchar(20)) as ap_place, cast(ap_name as varchar(20)) as ap_name, ap_ccode from airport_x100;g +-------------+--------+--------------------+--------------------+--------+ |ap_id |iatacode|ap_place |ap_name |ap_ccode| +-------------+--------+--------------------+--------------------+--------+ | 50000|AAA |Vector |Aomori |AU | | 50001|AA1 |Vector |Tegel |AU | | 50002|AA2 |Vector |Tegel |NL | | 50003|AA3 |Vector |Tegel |NL | +-------------+--------+--------------------+--------------------+--------+ (4 rows)
So the inserts were automatically propagated. Now we take a look at updates. Multiple rules fired on a single condition do not have a defined order of execution. So we take care to ensure only one rule fires or that the order does not affect the end result.
First off we are creating a procedure that will update airport_x100’s ap_id column with the value of the ap_id parameter if airport_x100’s ap_iatacode column matches the apiatacodeold parameter value:
CREATE PROCEDURE proc_upd_airport_x100_01 ( apid INT NOT NULL NOT DEFAULT, apiatacodeold NCHAR(3) NOT NULL NOT DEFAULT) AS BEGIN UPDATE airport_x100 SET ap_id = :apid WHERE ap_iatacode = :apiatacodeold; ENDg
Now we create the rule that triggers the above procedure, it only fires if the ap_id column in the table airport is updated. It is possible to pass the new and/or old value from an update into the called procedure:
CREATE RULE trg_upd_airport_x100_01 AFTER UPDATE(ap_id) of airport EXECUTE PROCEDURE proc_upd_airport_x100_01 ( apid = new.ap_id, apiatacodeold = old.ap_iatacode)g
Now we create a second update procedure that will similarly, conditionally update airport_x100’s ap_iatacode column with the supplied value. As well as updating airport_x100 this table will generate pop-up messages when executed. We are not limited to single insert, delete or update statements:
CREATE PROCEDURE proc_upd_airport_x100_02 (apiatacode NCHAR(3) NOT NULL NOT DEFAULT, apiatacodeold NCHAR(3) NOT NULL NOT DEFAULT) AS DECLARE str VARCHAR(30) not null; BEGIN str = 'apiatacode = ' + :apiatacode; MESSAGE :str; str = 'apiatacodeold = ' + :apiatacodeold; MESSAGE :str; UPDATE airport_x100 SET ap_iatacode = :apiatacode WHERE ap_iatacode = :apiatacodeold; ENDg
We now create a rule that will fire the above procedure if the ap_iatacode in the table airport is updated:
CREATE RULE trg_upd_airport_x100_02 AFTER UPDATE(ap_iatacode) of airport EXECUTE PROCEDURE proc_upd_airport_x100_02 ( apiatacode = new.ap_iatacode, apiatacodeold = old.ap_iatacode)g
We go on to create procedures and rules that will apply updates to other columns in airport_x100. This is not a requirement. Multiple columns can be updated in a single procedure if required:
CREATE PROCEDURE proc_upd_airport_x100_03 (applace NVARCHAR(30) NOT NULL NOT DEFAULT, apiatacodeold NCHAR(3) NOT NULL NOT DEFAULT) AS BEGIN UPDATE airport_x100 SET ap_place = :applace WHERE ap_iatacode = :apiatacodeold; ENDg CREATE RULE trg_upd_airport_x100_03 AFTER UPDATE(ap_place) of airport EXECUTE PROCEDURE proc_upd_airport_x100_03 ( applace = new.ap_place, apiatacodeold = old.ap_iatacode)g CREATE PROCEDURE proc_upd_airport_x100_04 (apname NVARCHAR(30) NOT NULL NOT DEFAULT, apiatacodeold NCHAR(3) NOT NULL NOT DEFAULT) AS BEGIN UPDATE airport_x100 SET ap_name = :apname WHERE ap_iatacode = :apiatacodeold; ENDg CREATE RULE trg_upd_airport_x100_04 AFTER UPDATE(ap_name) of airport EXECUTE PROCEDURE proc_upd_airport_x100_04 ( apname = new.ap_name, apiatacodeold = old.ap_iatacode)g CREATE PROCEDURE proc_upd_airport_x100_05 (apccode NVARCHAR(30) NOT NULL NOT DEFAULT, apiatacodeold NCHAR(3) NOT NULL NOT DEFAULT) AS BEGIN UPDATE airport_x100 SET ap_ccode = :apccode WHERE ap_iatacode = :apiatacodeold; ENDg CREATE RULE trg_upd_airport_x100_05 AFTER UPDATE(ap_ccode) of airport EXECUTE PROCEDURE proc_upd_airport_x100_05 ( apccode = new.ap_ccode, apiatacodeold = old.ap_iatacode)g
Now we will perform updates to our transactional data in the airport table to show how the above procedures and rules automatically apply changes to our analytics table airport_x100:
update airport set ap_id = 99999 where ap_id = 50000g
The select shows trg_upd_airport_x100_01 was triggered and executed the procedure proc_upd_airport_x100_01. The single column update has been mirrored into the airport_x100 table:
select ap_id, ap_iatacode as iatacode, cast(ap_place as varchar(20)) as ap_place, cast(ap_name as varchar(20)) as ap_name, ap_ccode from airport_x100;g +-------------+--------+--------------------+--------------------+--------+ |ap_id |iatacode|ap_place |ap_name |ap_ccode| +-------------+--------+--------------------+--------------------+--------+ | 99999|AAA |Vector |Aomori |AU | | 50001|AA1 |Vector |Tegel |AU | | 50002|AA2 |Vector |Tegel |NL | | 50003|AA3 |Vector |Tegel |NL | +-------------+--------+--------------------+--------------------+--------+ (4 rows)
The next update will trigger the procedure proc_upd_airport_x100_02 which also displays a message when fired. We’ll apply a number of updates to the airport table to show and then select from the analytics table airport_x100 to show how the above databases and rules are automatically applying changes to our analytics data based on transaction that affect our transactional data:
update airport set ap_iatacode = 'AA9' where ap_iatacode = 'AA1'g MESSAGE 0: apiatacode = AA9 MESSAGE 0: apiatacodeold = AA1 (1 row)
select ap_id, ap_iatacode as iatacode, cast(ap_place as varchar(20)) as ap_place, cast(ap_name as varchar(20)) as ap_name, ap_ccode from airport_x100;g +-------------+--------+--------------------+--------------------+--------+ |ap_id |iatacode|ap_place |ap_name |ap_ccode| +-------------+--------+--------------------+--------------------+--------+ | 99999|AAA |Vector |Aomori |AU | | 50001|AA9 |Vector |Tegel |AU | | 50002|AA2 |Vector |Tegel |NL | | 50003|AA3 |Vector |Tegel |NL | +-------------+--------+--------------------+--------------------+--------+ (4 rows)
update airport set ap_place = 'VectorUPD' where ap_place = 'Vector'g (4 rows)
select ap_id, ap_iatacode as iatacode, cast(ap_place as varchar(20)) as ap_place, cast(ap_name as varchar(20)) as ap_name, ap_ccode from airport_x100;g +-------------+--------+--------------------+--------------------+--------+ |ap_id |iatacode|ap_place |ap_name |ap_ccode| +-------------+--------+--------------------+--------------------+--------+ | 99999|AAA |VectorUPD |Aomori |AU | | 50001|AA9 |VectorUPD |Tegel |AU | | 50002|AA2 |VectorUPD |Tegel |NL | | 50003|AA3 |VectorUPD |Tegel |NL | +-------------+--------+--------------------+--------------------+--------+ (4 rows)
update airport set ap_name = 'TegelUPD' where ap_name = 'Tegel'g (3 rows)
select ap_id, ap_iatacode as iatacode, cast(ap_place as varchar(20)) as ap_place, cast(ap_name as varchar(20)) as ap_name, ap_ccode from airport_x100;g +-------------+--------+--------------------+--------------------+--------+ |ap_id |iatacode|ap_place |ap_name |ap_ccode| +-------------+--------+--------------------+--------------------+--------+ | 99999|AAA |VectorUPD |Aomori |AU | | 50001|AA9 |VectorUPD |TegelUPD |AU | | 50002|AA2 |VectorUPD |TegelUPD |NL | | 50003|AA3 |VectorUPD |TegelUPD |NL | +-------------+--------+--------------------+--------------------+--------+ (4 rows)
Now we create a procedure and rule to mirror deletes. In many cases we would want to retain historical data in our analytics tables but we may need to delete rows for compliance reasons. The next procedure and rule we create will delete data from airport_x100 automatically when rows are deleted from the airport table:
CREATE PROCEDURE proc_del_airport_x100_01 (apiatacodeold NCHAR(3) NOT NULL NOT DEFAULT) AS BEGIN DELETE from airport_x100 WHERE ap_iatacode = :apiatacodeold; ENDg CREATE RULE trg_del_airport_x100_01 AFTER DELETE FROM airport EXECUTE PROCEDURE proc_del_airport_x100_01 (apiatacodeold = old.ap_iatacode)g
delete from airport where ap_iatacode = 'AA9'g (1 row)
This select shows that the row deleted from airport has been automatically deleted from airport_x100:
select ap_id, ap_iatacode as iatacode, cast(ap_place as varchar(20)) as - ap_place, cast(ap_name as varchar(20)) as ap_name, ap_ccode from airport_x100;g +-------------+--------+--------------------+--------------------+--------+ |ap_id |iatacode|ap_place |ap_name |ap_ccode| +-------------+--------+--------------------+--------------------+--------+ | 99999|AAA |VectorUPD |Aomori |AU | | 50002|AA2 |VectorUPD |TegelUPD |NL | | 50003|AA3 |VectorUPD |TegelUPD |NL | +-------------+--------+--------------------+--------------------+--------+ (3 rows)
delete from airport where ap_name = 'TegelUPD'g (2 rows)
Select shows 2 rows deleted from airport are automatically deleted from airport_x100:
select ap_id, ap_iatacode as iatacode, cast(ap_place as varchar(20)) as ap_place, cast(ap_name as varchar(20)) as ap_name, ap_ccode from airport_x100;g +-------------+--------+--------------------+--------------------+--------+ |ap_id |iatacode|ap_place |ap_name |ap_ccode| +-------------+--------+--------------------+--------------------+--------+ | 99999|AAA |VectorUPD |Aomori |AU | +-------------+--------+--------------------+--------------------+--------+ (1 row)
These examples show basic mirroring of inserts, updates and deletes from transactional tables to analytics tables to get you started. Much more sophisticated database procedures can be built and the changes applied to your analytics data does not need to be a mirror of the changes to your transactional data. You may want to trigger an insert into your analytics table after a row is deleted from your transactional data to establish an audit trail.
We’d love to hear how you are seamlessly and automatically generating your analytics data from your existing transactional tables. Please post a reply in our community forums to let us know about the cool things you are doing with the Ingres Hybrid Database.
Subscribe to the Actian Blog
Subscribe to Actian’s blog to get data insights delivered right to you.
- Stay in the know – Get the latest in data analytics pushed directly to your inbox.
- Never miss a post – You’ll receive automatic email updates to let you know when new posts are live.
- It’s all up to you – Change your delivery preferences to suit your needs.
Subscribe
(i.e. sales@..., support@...)