Actian Shows Big Advantages Over SQL on Hadoop Alternatives





Actian Vector was renamed to Actian Analytics Engine in 2026.
Imagine if reports that currently take many minutes to run in Hadoop could come back with results in seconds. Get answers to detailed questions about sales figures and customer trends in real-time. Make revenue predictions based on up-to-date customer metrics across a spectrum of sources. Iterate more quickly simulating different business decisions to achieve better outcomes. The Actian Vector for Hadoop analytics platform can deliver those improvements in your Hadoop big data environment.
Actian Vector for Hadoop has demonstrated one to three orders of magnitude better query performance in a comparison with other major SQL in Hadoop alternatives.
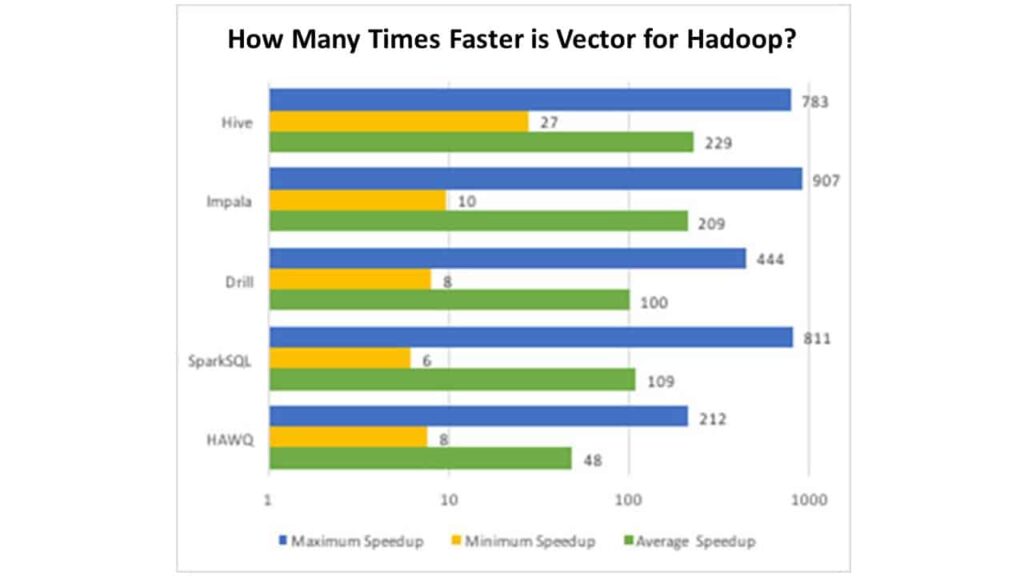
Actian performance engineering used the full set of 22 TPC-H queries to run unaudited benchmarks on several of the SQL on Hadoop solutions in the market, and the results may surprise you (but not us). Here is a quick summary:
These results have been published in an academic paper submitted to and presented at the International Conference on Management of Data (ACM SIGMOD). That paper goes into many technical reasons how Vector for Hadoop is able to achieve such a performance advantage – here is the short version:
- Efficient, multi-core parallel and vectorized execution – Vector for Hadoop is designed to take advantage of the performance features in the Intel CPU architecture, including the AVX2 vector instruction set and large, multi-layer caches.
- Well-tuned query optimizer – Vector for Hadoop extends the mature optimizer from its original SMP version to exploit the multiple levels of parallelism and advantages of data locality in an MPP Hadoop system. The Vector for Hadoop optimizer can change the join order or partition data tables to improve parallel operations, steps that have to be done manually for queries in the other alternatives.
- Control over HDFS block locality – since Vector for Hadoop operates natively within HDFS and YARN, it can participate in resource management and make allocation decisions in the context of the larger cluster workload. At the same time, specific table storage optimizations reduce overhead, accelerate reads, maximize disk efficiency, and reduce data skew to help deliver faster query results.
- Effective I/O filtering – tracking the range of values in a column (MinMax) allows skipping the reading of blocks which fall outside the range of the query, reducing disk I/O and read delays, and avoiding decompression computations, sometimes significantly.
- Lightweight compression – Vector ‘s compression achieves good levels of compaction at high speed, achieving faster vectorized execution by minimizing branches and instruction counts. Our compression algorithms are capable of running fully in CPU cache, effectively increasing memory bandwidth. Different compression algorithms are tailored for the various data types and Vector automatically calibrates and chooses among them to reach higher levels of compression and efficiency when compared to general purpose compression algorithms.
How was the testing conducted?
- Actian performance engineering built a 10-node Hadoop cluster, each node 2xIntel 3.0GHz E5-2690v2 CPUs, 256GB RAM, 24x600GB HDD, 10Gb Ethernet, Hadoop 2.6.0. There was one name node and nine SQL-on-Hadoop nodes, set up using Cloudera Express 5.5.
- These tests were conducted in early 2016, running the then-most-current release of each of the SQL on Hadoop alternatives (Actian Vector for Hadoop 4.2.2, Apache Hive 1.2.1, Cloudera Impala 2.3, Apache Drill 1.5, Apache Spark SQL 1.5.2, and Pivotal HAWQ 1.3.1). Reasonable efforts were made to tune each platform to make fair comparisons.
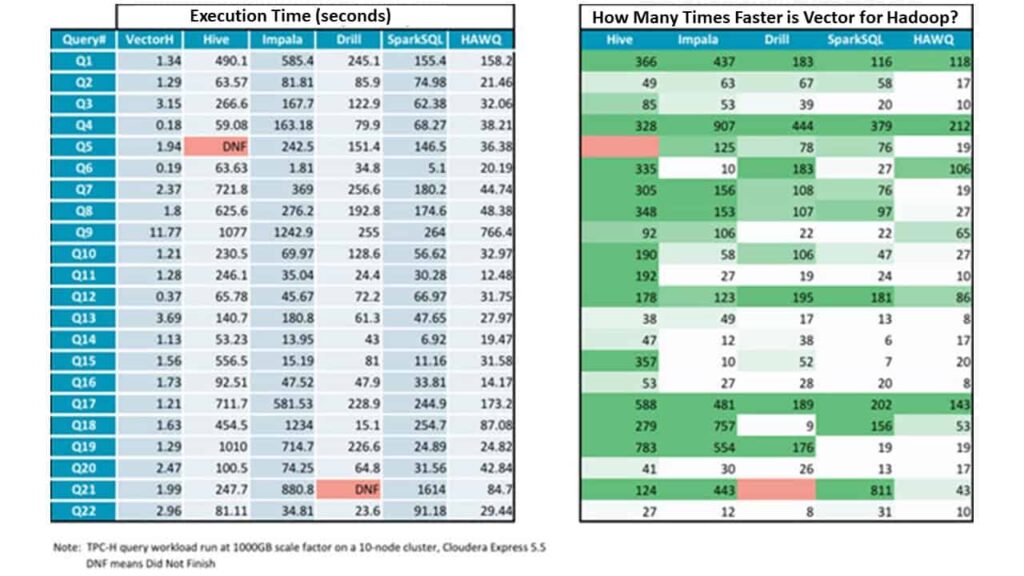
Here are the actual individual query execution times and the speed-up factor for Vector for Hadoop versus each of the alternatives:
Stay connected
Data insights delivered to you.
(i.e. sales@..., support@...)