Actian Vector for Hadoop for Fuller SQL Functionality and Current Data
Actian Corporation
June 7, 2020

In this second of a three-part blog series (part 1), we’ll explain how SQL execution in Actian Vector in Hadoop (VectorH) is much more functional and ready to run in an operational environment, and how the ability for VectorH to handle data updates efficiently can enable your production environment to stay current with the state of your business. In the first part of this three-part blog post, we showed the tremendous performance advantage VectorH has over other SQL on Hadoop alternatives. The third part will cover the advantages of the VectorH file format.
Better SQL Functionality for Business Productivity
One of the original barriers to getting value out of Hadoop is the need for MapReduce skills, which are rare and expensive, and take time to apply to a given analytical question. Those challenges led to the rise of many SQL on Hadoop alternatives, many of which are now projects in the Apache ecosystem for Hadoop. While those different projects open up access to the millions of business users already fluent in writing SQL queries, in many cases they require other tradeoffs: differences in syntax, limitations on certain functions and extensions, immature optimization technology, and inefficient implementations. Is there a better way to get SQL on Hadoop?
Yes! Actian VectorH 6.0 supports a much more complete implementation, with full ANSI SQL:2003 support, plus analytic extensions like CUBE, ROLLUP, GROUPING SETS, and WINDOWING for advanced analytics. Let’s look at the workload we evaluated in our SIGMOD paper, based on the 22 queries in the TPC-H benchmark.
Each of the other SQL on Hadoop alternatives had issues running the standard SQL queries that comprise the TPC-H benchmark, which means that business users who know SQL may have to make changes manually or suffer from poor results or even failed queries:
- Apache Hive 1.2.1 couldn’t complete query number 5.
- Performance for Cloudera Impala 2.3 is hindered by single-core joins and aggregation processing, creating bottlenecks for exploiting parallel processing resources.
- Apache Drill 1.5 couldn’t complete query number 21, and only 9 of the queries ran without modification to their SQL code.
- Since Apache Spark SQL version 1.5.2 is a limited subset of ANSI SQL, most queries had to be rewritten in Spark SQL to avoid IN/EXISTS/NOT EXISTS sub-queries, and some queries required manual definition of join orders in Spark SQL. VectorH has a mature query optimizer that will reorder joins based on cost metrics to improve performance and reduce I/O bandwidth requirements.
- Apache Hawq version 1.3.1 is based on PostgreSQL, so its older technology foundations can’t compete with the performance of a vectorized query engine.
Efficient Updates for More Consistent View of the Business
Another barrier to Hadoop adoption is that it is an append-only file system, limiting the file system’s ability to handle inserts and deletes. Yet many business applications require updates to the data, putting the burden on the database management system to handle those changes. VectorH can receive and apply updates from transactional data sources to ensure that analytics are performed on the most current representation of your business, not from an hour ago, or yesterday, or the last batch load into your data warehouse.
- As part of the ad hoc decision support workload it represents, TPC-H has a requirement to run inserts and deletes as part of the workload. There are two refresh streams that make inserts and deletes into the six fact tables.
- Four of the SQL on Hadoop alternatives do not support updates on HDFS: Impala, Drill, SparkSQL, and Hawq. They would not be able to meet the requirements for a full audited result.
- The fifth, Hive, does support updates but incurs a significant performance penalty executing queries after handling the updates.
- VectorH executed the updates more quickly than Hive. With its patent-pending Positional Delta Trees, VectorH tracks inserts and deletes separately from the data blocks, maintaining full ACID compliance while preserving the same level of query performance (no penalty!)
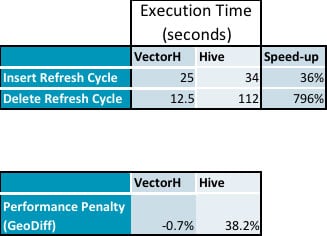
- Here is the summary data from our testing that shows the performance penalty on Hive while there is no impact on VectorH from executing updates (detailed data follows):
- Inserts took 36% longer and deletes required 796% more time on Hive than VectorH
Query performance afterwards shows PDTs have no measurable overhead, compared to the 38% performance penalty on Hive:
- The average speedup for VectorH over Hive increases from 229x before the refresh cycles to 331x after updates are applied, with a range of 23 to 1141 on individual queries.
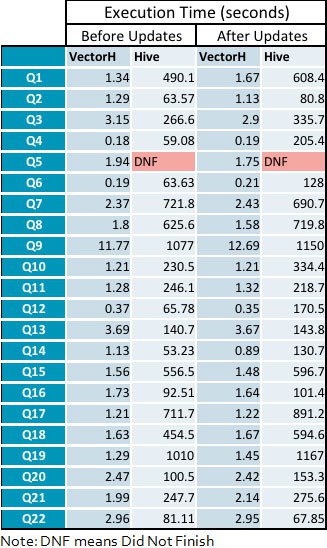
Appendix: Detailed Query Execution Times
Subscribe to the Actian Blog
Subscribe to Actian’s blog to get data insights delivered right to you.
- Stay in the know – Get the latest in data analytics pushed directly to your inbox.
- Never miss a post – You’ll receive automatic email updates to let you know when new posts are live.
- It’s all up to you – Change your delivery preferences to suit your needs.