This is the first episode of our series “The Effective Data Governance Framework”. Split into three seasons, this first part will focus on Alignment: understanding the context, finding the right people, and preparing an action plan for your data-driven journey. Our first episode will give you the keys on how to evaluate the maturity of your company’s data strategy for you to visualize where your efforts should lie in your data governance implementation.
Data is the Petrol of the 21st Century
With GAFA paving the way (Google, Apple, Facebook, and Amazon), data has, in recent years, become a crucial enterprise asset and has taken a substantial place in the minds of key data and business people alike.
The importance of data has been amplified by new digital services and uses that disrupt our daily lives. Traditional businesses who lag behind in this data revolution are inevitably put at a serious competitive disadvantage.
To be sure, all organizations and all sectors of activity are now impacted by the new role data represents as a strategic asset. Most companies now understand that in order to keep up with innovative startups and powerful web giants, they must capitalize on their data.
This shift in the digital landscape has led to widespread digital transformations the world over with everybody now wanting to become “Data-Driven”.
The Road to Becoming Data-Driven
In order to become data-driven, one has to look at data as a business asset that needs to be mastered first and foremost, and then exploited.
The data-driven approach is a means to collect, safeguard and maintain data assets of the highest quality whilst also tackling the new data security issues that come with the territory. Today, data consumers must have access to accurate, intelligible, complete, and consistent data in order to detect potential business opportunities, minimize time-to-market, and undertake regulatory compliance.
The road to the promised land of data innovation is full of obstacles.
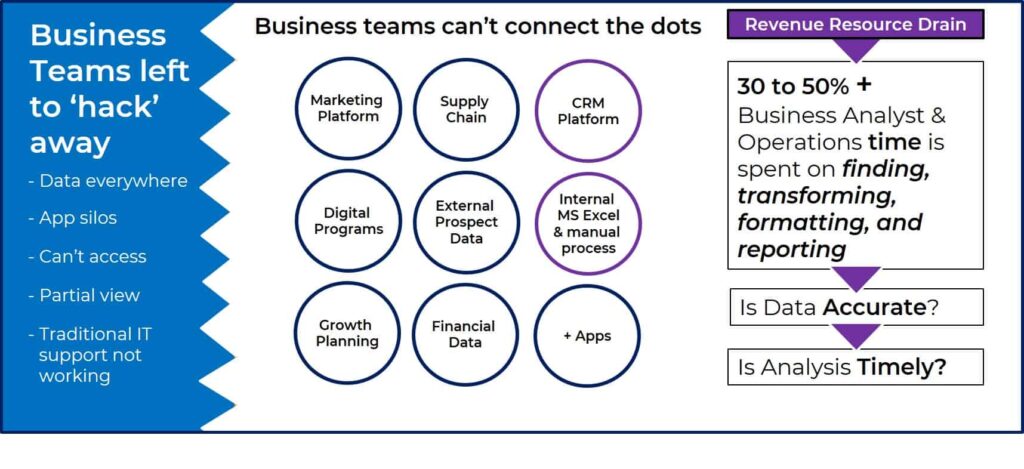
Data legacy, with its heavy silos and the all too often tribal nature of data knowledge, rarely bodes well for the overall quality of data. The advent of Big Data has also reinforced the perception that the life cycle of any given data must be mastered in order for you to find your way through the massive volume of the enterprise’s stored data.
It’s a challenge that encompasses numerous roles and responsibilities, processes and tools.
The implementation of a data governance is therefore, a chapter that any data-driven company must write.
However, our belief that the approaches to data governance from recent years have not kept their promises is borne out by our own field experience along with numerous and ongoing discussions with key data players.
We strongly believe in adopting a different approach to maximize the chances of success. Our Professional Services and Customer Success teams provide our customers with the expertise they need to build effective data governance, through a more pragmatic and iterative approach that can adapt to a constantly changing environment.
We call it the Effective Data Governance Framework.
Our Beliefs on Data
Awareness of the importance of data is a long journey that every company has to make. But each journey is different: company data maturity varies a lot; expectations and obligations can also vary widely.
Overall success will come about with a litany of small victories over time.
We have organized our framework in 3 steps.
Alignment
Evaluate your Data maturity
Specify your Data strategy
Getting sponsors
Build a SWOT analysis
Adapting
Organize your Data Office
Organize your Data Community
Creating Data Awareness
Implementing Metadata Management With a Data Catalog
The importance of metadata
6 weeks to start your data governance journey
Season 1, Episode 1: Alignment
This first season is designed to help your organization align itself with your data strategy by ensuring an understanding of the overall context.
What follows will help you, and all the key sponsors, identify the right stakeholders from the get-go. This first iteration will help you evaluate the data maturity of your organization through different angles.
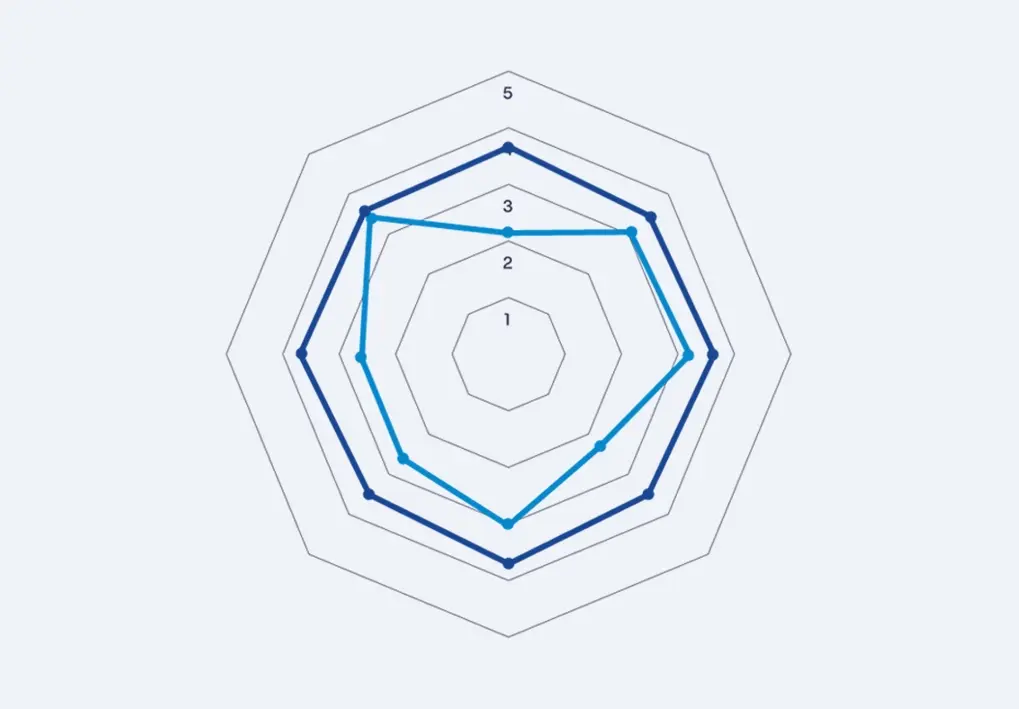
In the form of a workshop, our Data Governance Maturity Audit will help you visualize, through a Kiviat Diagram, your scores as shown below:
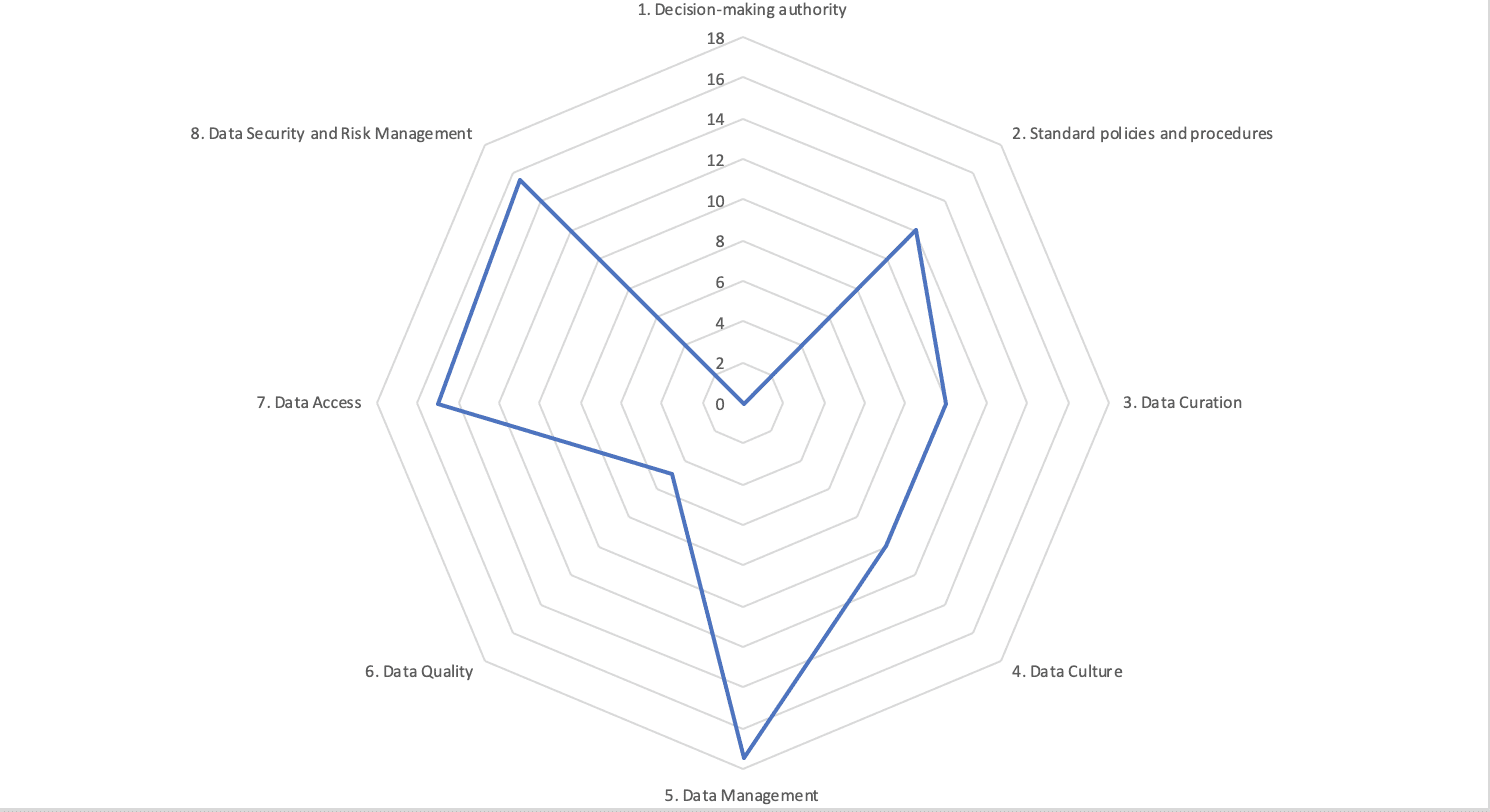
Data Maturity Audit: Important Questions to Ask
Organization
Is an organizational structure with different levels of governance (exec, legal, business, …) in place? Are there roles and responsibilities at different specified levels (governance committees, tech leaders, data stewards, …)?
Data Stewards
Are the data stewards in charge of coordinating data governance activities identified and assigned to each area or activity?
Accountabilities
Have the roles, responsibilities and accountability for decision-making, management and data security been clearly defined and communicated (to the data stewards themselves, but also to everyone involved in the business)?
The Means
Do data stewards have sufficient authority to quickly and effectively correct data problems while ensuring that their access does not violate personal or sensitive data policies?
The Requirements
Have policy priorities affecting key data governance rules and requirements been defined? Is there an agreement (formal agreement or verbal approval) on these priorities by the key stakeholders (sponsors, policy makers, exec)?
Life Cycle Management
Have standard policies and procedures for all aspects of data governance and data management lifecycle, including collection, maintenance, use and dissemination, been clearly defined and documented?
Compliance
Are policies and procedures for ensuring that all data is collected, managed, stored, transmitted, used and destroyed in such a way that confidentiality is maintained in accordance with security standards in place (GDPR for example)?
Feedback
Has an assessment been conducted to ensure the long-term relevance and effectiveness of the policies and procedures in place, including the assessment of staffing, tools, technologies and resources?
Process Visions
Do you have a mapping describing the processes to monitor compliance with its established policies and procedures?
Transparency
Have the policies and procedures been documented and communicated in an open and accessible way to all stakeholders, including colleagues, business partners and the public (eg: via a publication on your website)?
Overview
Does your organization have an inventory of all the data sources (from software packages, internal databases, data lakes, local files, …)?
Managing Sensitive Information
Does your organization have a detailed, up-to-date inventory of all data that should be classified as sensitive (ie, which is at risk of being compromised / corrupted by unauthorized or inadvertent disclosure), personal, or both?
Level of Risks
Has your data been organized according to the level of risk of disclosure of personal information potentially contained in the records?
Documentation Rules
Does your organization have a written and established rule describing what should be included in a data catalog? Is it clear how, when and how often this information is written and by whom?
Information Accessibility
Does your organization let everyone concerned by data access the data catalog? Is the data needed indexed in the catalog or not?
Global Communication
Does your organization communicate internally on the importance data can play in its strategy?
Communication Around Compliance
Does your organization communicate with its employees (at least those who are directly involved in using or manipulating data) about current regulatory obligations related to data?
Working for the Common Good
Does your organization promote the sharing of datasets (those that are harder to find and/or only used by a small group for example) via different channels?
Optimizing Data Usage
Does your organization provide the relevant people training on how to read, understand and use the data?
Promoting Innovation
Does your organization value and promote the successes and innovations produced (directly or not) by the data?
Collecting & Storing Data
Does your organization have clear information on the reason for capturing and storing personal data (operational need, R&D, legal, etc.)?
Justification Control
Does your organization have a regular verification procedure to ensure the data collected is consistent with the information mentioned above?
Anonymization
Have anonymization or pseudo-anonymization mechanisms been put in place for personal data, direct or indirect?
Detailed Procedure
Has the organization established and communicated policies and procedures on how to handle records at all stages of the data life cycle, including the acquisition, maintenance, use, archiving or destruction of records?
Data Quality Rules
Does the organization have policies and procedures in place to ensure that the data is accurate, complete, up-to-date and relevant to the users’ needs?
Data Quality Control
Does the organization conduct regular data quality audits to ensure that its quality control strategies are up-to-date and that corrective actions taken in the past have improved the quality of the data?
Data Access Policy
Are there policies and procedures in place to restrict and monitor access to data in order to limit who can access what data (including assigning differentiated access levels based on job descriptions and responsibilities)?
Are these policies and procedures consistent with local, national, … privacy laws and regulations (including the GDPR)?
Data Access Control
Have internal procedural controls been put in place to manage access to user data, including security controls, training and confidentiality agreements required by staff with personal data access privileges?
General Framework
Has a comprehensive security framework been defined, including administrative, physical, and technical procedures to address data security issues (such as access and data sharing restrictions, strong password management, regular selection and training of staff, etc.)?
Risk Assessment
Has a risk assessment been undertaken?
Does this risk assessment include an assessment of the risks and vulnerabilities related to both intentional and malicious misuse of data (eg hackers) and inadvertent disclosure by authorized users?
Risk Mitigation Plan
Is there a plan in place to mitigate the risks associated with intentional and unintentional data breaches?
Prevention
Does the organization monitor or audit data security on a regular basis?
Recovery Plan
Have policies and procedures been established to ensure the continuity of data services in the event of a data breach, loss, or another disaster (this includes a disaster recovery plan)?
Flow Regulation
Are policies in place to guide decisions on data exchange and reporting, including sharing data (in the form of individual records containing personal information or anonymized aggregate reports) internally with business profiles, analysts/data scientists, decision-makers, or externally with partners?
Usage Contracts and Legal Commitment
When sharing data, are appropriate procedures, such as sharing agreements, in place to ensure that personal information remains strictly confidential and protected from unauthorized disclosure? Note that data sharing agreements must fall in line with all applicable regulations, such as the GDPR.
These agreements can only take place if data sharing is permitted by law.
Control of Product Derivatives
Are appropriate procedures, such as obfuscation or deletion, in place to ensure that information is not inadvertently disclosed in general reports and that the organization’s reporting practices remain in compliance with the laws and regulations in force (for example, GDPR)?
Stakeholder Information
Are stakeholders, including the individuals whose data are kept, regularly informed about their rights under the applicable laws or regulations governing data confidentiality?
Our interactive toolkit will allow you to visualize where your efforts should lie when implementing a data governance strategy.
About Actian Corporation
Actian empowers enterprises to confidently manage and govern data at scale. Actian data intelligence solutions help streamline complex data environments and accelerate the delivery of AI-ready data. Designed to be flexible, Actian solutions integrate seamlessly and perform reliably across on-premises, cloud, and hybrid environments. Learn more about Actian, the data division of HCLSoftware, at actian.com.