Quelle est la différence entre un centre d'analyse de données et un lac ?





Dans le premier article de cette série de blogs - Lacs de données, entrepôts de données et concentrateurs de données : Avons-nous besoin d'un autre choix ? j'explique pourquoi la simple migration de ces plateformes intégration, de gestion et d'analyse des données sur site vers le cloud ne répond pas entièrement aux besoins modernes en matière d'analyse des données. En comparant ces trois plateformes, il apparaît clairement qu'elles répondent toutes à certains besoins critiques, mais qu'aucune d'entre elles ne répond aux besoins des utilisateurs finaux de l'entreprise sans un support important de la part du service informatique. Dans le deuxième blog de cette série - Qu'est-ce qu'une plateforme d'analyse de données ? - j'introduis le terme de hub d'analyse de données pour décrire une plateforme qui reprend les éléments opérationnels et analytiques optimaux des hubs, lacs et entrepôts de données et les combine avec des caractéristiques et fonctionnalités cloud pour répondre directement aux besoins opérationnels en temps réel et en libre-service des utilisateurs professionnels (plutôt qu'exclusivement des utilisateurs informatiques). Je prends également le temps d'examiner une quatrième technologie connexe, le hub analytique. Étant donné la proximité entre le hub analytique et le hub d'analyse de données, il était logique de préciser qu'un hub analytique reste une solution incomplète pour l'analyse moderne, au même titre qu'un lac de données, un hub et un entrepôt de données.
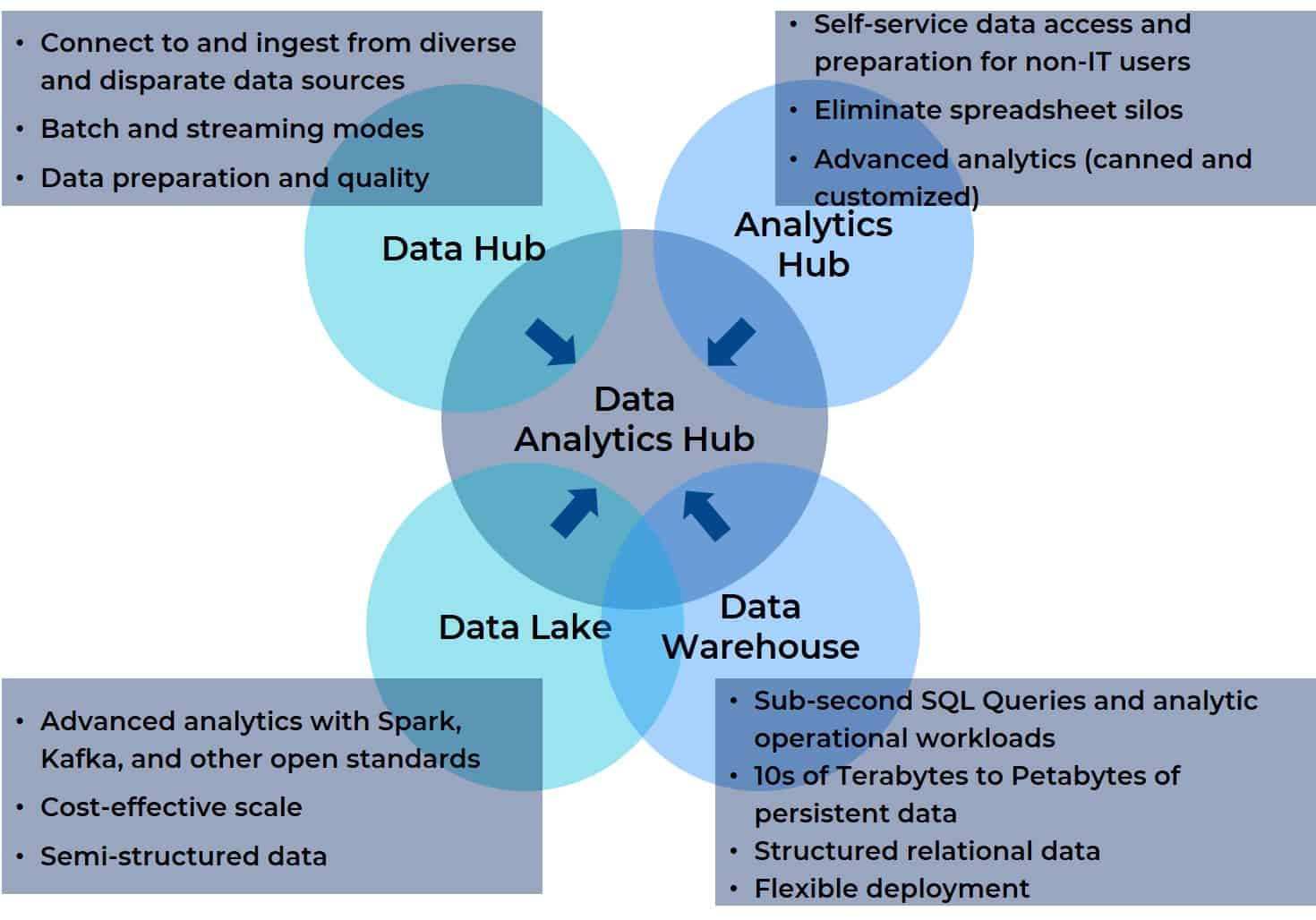
Pourquoi ? Parce que, par essence, un hub d'analyse de données prend le meilleur de toutes ces plateformes intégration, de gestion et d'analyse et les combine en une seule plateforme. Un hub d'analyse de données rassemble l'agrégation de données, la gestion et le support analytique pour n'importe quelle source de données avec n'importe quel outil de BI ou d'IA, de visualisation, de reporting ou autre destination. En outre, un hub d'analyse de données est conçu pour être accessible à tous les utilisateurs d'une équipe interfonctionnelle (même virtuelle). Le diagramme ci-dessous illustre la relation entre les quatre prédécesseurs et le pôle d'analyse de données (il vous semblera familier si vous avez lu le deuxième volet de cette série).
Attendez... Et le Data Lakehouse ?
La semaine dernière, j'ai eu le privilège d'accueillir Bill Inmon, considéré comme le père de l'entreposage de données, pour un webinaire sur l'intégration des données modernes dans les entrepôts de données en nuage. Inutile de dire que les questions posées à Bill étaient nombreuses, mais il y en avait une qui, à mon avis, méritait d'être abordée en détail ici : Qu'est-ce qu'un data lakehouse, et en quoi est-il différent d'un data lake ou d'un data warehouse ?
Commençons par ce qui est le plus évident et ce que son nom laisse présager : un data lakehouse est une combinaison de matériel de base, de normes ouvertes, de traitement de données semi-structurées et non structurées, de Fonctionnalités un data lake et de SQL Analytics, de support schémas structurés et d'intégration d'outils de BI que l'on trouve dans un data warehouse. Ceci est important car la question est moins de savoir en quoi un data lakehouse diffère d'un data lake ou d'un data warehouse que de savoir s'il est plus proche de l'un ou de l'autre. Cette distinction est importante car le point de départ de la convergence est déterminant. En termes mathématiques simples, si A + B = C, alors B + A = C. Mais dans le monde réel, ce n'est pas tout à fait vrai. Le point de départ est essentiel lorsqu'il s'agit de la convergence de deux plateformes ou produits, car ce point de départ informe votre vision de l'endroit où vous allez, votre perception du voyage et votre sentiment d'avoir atteint ou non l'objectif que vous vous étiez fixé lorsque vous arrivez à la fin du voyage.
En parlant de voyage, faisons un petit voyage dans le temps pour comprendre les défis qui ont conduit à l'idée d'un centre de données.
Historiquement, les lacs de données étaient le domaine des data scientists et des utilisateurs expérimentés. Ils supportaient de grandes quantités de données - structurées et non structurées - pour l'exploration des données et des projets complexes de science des données sur du matériel standard ouvert. Mais ces besoins ne nécessitaient pas l'accès à des données actives telles que celles associées aux processus opérationnels quotidiens de l'entreprise. Ils sont souvent devenus des laboratoires scientifiques et, dans certains cas, des décharges de données.
Cette situation contraste avec les besoins historiques des analystes commerciaux et des autres utilisateurs puissants de la ligne d'activité (LOB). Ils construisaient et exécutaient des charges de travail opérationnelles associées à l'analyse SQL, à la BI, à la visualisation et à la création de rapports, et ils avaient besoin d' accéder à des données actives. Pour répondre à leurs besoins, les services informatiques ont mis en place des entrepôts de données d'entreprise, qui s'appuyaient traditionnellement sur un ensemble limité de référentiels de données d'applications ERP intimement liées aux opérations quotidiennes. L'informatique devait servir d'intermédiaire entre l'entrepôt de données, les analystes commerciaux et les utilisateurs du LOB, mais l'entrepôt de données lui-même constituait une boucle de rétroaction fermée qui permettait d'obtenir des informations pour améliorer l'support décision et la souplesse de l'entreprise.
Cependant, à mesure que la transformation numérique progresse, les besoins évoluent. Les applications sont devenues plus intelligentes et imprègnent tous les aspects de l'entreprise. Les attentes en matière de lacs et d'entrepôts de données ont évolué. La demande d'support décision en temps réel a réduit la boucle de rétroaction entrepôt de données/ERP dépôt manière asymptotique, au point qu'elle s'approche du temps réel. De plus, les référentiels ERP d'origine ne sont plus les seuls référentiels qui intéressent les analystes commerciaux et les utilisateurs de LOB - les flux de clics sur le web, l'IdO, les fichiers journaux et d'autres sources sont également des pièces essentielles du puzzle. Mais ces autres sources se trouvent dans les jeux de données disparates et divers qui nagent dans les lacs de données et couvrent de multiples applications et départements. Essentiellement, chaque aspect de l'interaction humaine peut être modélisé pour révéler des informations susceptibles d'améliorer considérablement la précision des opérations. La consolidation des données provenant d'un univers de données diverses et disparates et leur intégration dans une vue unifiée sont donc devenues des exigences essentielles. Ce besoin est à l'origine de la convergence des espaces de lac de données et d'entrepôt de données et a donné naissance à l'idée d'un lac de données (data lakehouse).
Revenons au présent : Deux des principaux promoteurs des lacs de données sont databricks et Snowflake. Le premier aborde la tâche la consolidation des plateformes du point de vue d'un fournisseur de lac de données et le second du point de vue d'un fournisseur d'entrepôt de données. Leurs offres de data lakehouse ont ceci en commun :
- Accès direct aux données sources pour les outils de BI et d'analyse (du côté de l'entrepôt de données ).
- Support des données structurées, semi-structurées et non structurées (du côté du lac de données).
- support schémas avec conformité ACID pour les lectures et écritures simultanées (du côté de l'entrepôt de données).
- Outils standard ouverts pour support data scientists (du côté du lac de données).
- Séparation du calcul et du stockage (du côté de l'entrepôt de données).
Les principaux avantages partagés sont les suivants :
- Suppression de la nécessité de disposer de référentiels distincts pour les charges de travail liées à la science des données et à la BI opérationnelle.
- Réduction de la charge d'administration informatique.
- Consolider les silos établis par les outils individuels de BI et d'IA qui créent leurs propres référentiels de données.
L'accent est essentiel
Améliorer la rapidité et la précision de l'analyse de grands jeux de données complexes jeux de données une tâche laquelle l'esprit humain est particulièrement bien adapté ; nous sommes tout simplement incapables de comprendre et de repérer des tendances subtiles dans des ensembles de données vraiment volumineux et complexes (ou, pour le dire autrement, désolé, vous n'êtes pas Neo et vous ne pouvez pas « voir » la Matrice dans un flux de données numériques). Cependant, l’IA excelle dans la détection de modèles au sein jeux de données multivariés complexes jeux de données à condition que data scientists concevoir, entraîner et optimiser algorithmes nécessaires à cette fin (des tâches pour lesquelles leur esprit est parfaitement adapté). Une fois que les algorithmes ont été ajustés et déployés dans le cadre de charges de travail opérationnelles, ils peuvent support prise de décision par des humains ( support la décision support sur la connaissance de la situation) ou effectuée de manière programmatique ( support la décision support et exécutée par des machines sous forme d’opérations machine-à-machine non supervisées). Au fil du temps, tout ou partie de ces algorithmes peuvent nécessiter des ajustements en fonction d'une tendance des résultats ou d'un écart par rapport aux résultats attendus ou souhaités. Encore une fois, sans vouloir faire de publicité, ce sont là des tâches pour lesquelles l'esprit humain est parfaitement adapté.
Mais revenons à cette tendance à la convergence et examinons d’où partent les fournisseurs de solutions de « data lakehouse ». Quel est leur point de vue ? Et en quoi cela influence-t-il leur vision de ce à quoi ressemble cette destination convergente ? Les lacs de données ont toujours été utilisés par data scientists, avec l’aide d’ingénieurs de données et d’autres professionnels informatiques qualifiés, pour collecter et analyser les données nécessaires à la gestion de la phase initiale du cycle de vie de l’IA, en particulier pour l’apprentissage automatique (ML). Étendre cet environnement signifie faciliter le déploiement leur ML dans les charges de travail opérationnelles. De ce point de vue, le succès serait une plateforme convergente qui raccourcit le cycle de vie du ML et le rend plus efficace. Pour les analystes métier, les ingénieurs de données et les utilisateurs avancés, cependant, jouer avec des algorithmes ou créer jeux de données de référence jeux de données entraîner optimiser ne optimiser pas partie de leur travail quotidien. Pour eux, ce qui importe, c’est d’exécuter en plus le ML dans le cadre de leurs charges de travail opérationnelles, y compris les jeux de données supplémentaires, divers et disparates.
Si les data scientists et les data engineers ne font pas partie des départements informatiques proprement dits, il n'en va pas de même pour les utilisateurs finaux non informaticiens. Les lacs de données sont généralement des environnements complexes dans lesquels travailler, avec de multiples API et des quantités importantes de codage, ce qui convient aux data scientists et aux ingénieurs, mais pas du tout aux rôles non informatiques tels que les analystes commerciaux et opérationnels ou leurs équivalents dans les différents départements LOB. Ils ont vraiment besoin d'une convergence qui élargisse un entrepôt de données pour traiter les composants ML opérationnalisés dans leurs charges de travail sur une plate-forme unifiée - sans accroître la complexité de l'environnement ou ajouter des exigences pour beaucoup de nuits et de week-ends pour obtenir de nouveaux diplômes.
Sommes-nous à l'écoute de tous ceux que nous devons écouter ?
J'ai travaillé dans la gestion et le marketing de produits et, en fin de compte, la voix qui porte le plus loin et le plus fort est celle de vos clients. Ce sont eux qui définiront toujours le mieux les caractéristiques et les fonctionnalités incrémentales de vos produits. Pour les fournisseurs de lacs de données, il s'agit des data scientists, des ingénieurs et des informaticiens ; pour les fournisseurs d'entrepôts de données, il s'agit des informaticiens. Logiquement, le domaine du problème se limite à ces groupes.
Mais devinez quoi ? Cette logique ne tient pas compte du groupe le plus important qui soit
Ce groupe comprend l'entreprise et ses représentants, les analystes commerciaux et opérationnels et d'autres utilisateurs puissants en dehors de l 'informatique et de l'ingénierie. Les fournisseurs de lacs de données et d'entrepôts de données - et par extension les fournisseurs de data lakehouse - ne s'adressent pas à ces utilisateurs parce que l'informatique se trouve toujours au milieu, toujours en position d'intermédiaire. Ces utilisateurs s'adressent aux fournisseurs d'outils de BI et d'analyse et, dans une moindre mesure, aux fournisseurs de hubs de données et de hubs d'analyse.
Pour tous ces groupes, le véritable problème consiste à intégrer les données dans le dépôt données, à les enrichir, à effectuer des analyses de base dans la plate-forme et à tirer parti des outils existants pour des analyses BI plus poussées, l'IA, la visualisation et la création de rapports sans quitter l'environnement. Le problème est encore plus aigu pour les entreprises, car elles ont besoin d'outils libre-service dont elles ne disposent pas actuellement en dehors des outils de BI et d'analyse (qui cloisonnent souvent les données au sein de l'outil/du projet au lieu de faciliter la construction d'une vue unifiée qui peut être vue par toutes les parties).
Tout le monde est d'accord pour dire qu'il faut une vue unifiée des données à laquelle toutes les parties peuvent accéder, mais l'accord ne satisfera pas toutes les parties de la même manière. Un data lakehouse basé sur un lac de données est un excellent moyen d'améliorer le cycle de vie de la ML et de rapprocher les data scientists du reste de l'équipe interfonctionnelle. Toutefois, il suffirait de déplacer l'infrastructure HDFS dans le nuage et d'utiliser S3, ADLS ou Google Cloud Store, ainsi qu'un entrepôt de données cloud moderne entrepôt de données cloud. Une telle solution satisferait la grande majorité des cas d'utilisation qui opérationnalisent les composants ML dans les charges de travail. Ce qui manque vraiment aux lacustres de données et aux entrepôts de données, c'est la fonctionnalité du hub de données et du hub d'analyse, qui est intégrée dans le hub d'analyse de données.
Conclusion : Un Lakehouse n'offre qu'un sous-ensemble des fonctionnalités d'un Data Analytics Hub
Le schéma présenté au début de cet article montre comment un hub d'analyse de données regroupe les éléments essentiels d'un lac de données, d'un entrepôt de données, d'un hub d'analyse et d'un hub de données. Il met également en évidence le manque de vision à long terme de l'approche « data lakehouse ». Il ne suffit pas de fusionner seulement deux des quatre composantes dont les utilisateurs ont besoin pour l'analyse moderne, d'autant plus que le développement de cette chimère repose sur les retours d'une partie seulement des rôles interfonctionnels qui utilisent la plateforme.
Dans le prochain article, nous examinerons plus en détail les cas d'utilisation proposés par ce groupe d'utilisateurs plus large, et nous comprendrons mieux pourquoi et comment une plateforme d'analyse de données répondra mieux aux besoins de toutes les parties, qu'elles se concentrent sur des optimisations basées sur l'apprentissage automatique ou sur les tâches opérationnelles quotidiennes.



Restez connecté
Des informations exploitables à votre disposition.
(par exemple, sales@..., support)