Sollten Sie RAG verwenden oderfeinabstimmen LLMfeinabstimmen ?




Zusammenfassung
- RAG dominiert den Bereich der Unternehmens-KI aufgrund seiner Flexibilität, während Fine-Tuning bei Skalierbarkeit, Latenz und strukturierten Ausgaben überzeugt.
- RAG verursacht wiederkehrende Kosten für Kontext und Abruf, während die Feinabstimmung die Kosten durchabfragen stabileabfragen im Voraus verlagert.
- Hybride Ansätze kombinieren das Abrufen von Informationen mit einer Feinabstimmung, um eine höhere Genauigkeit und eine bessere Schlussfolgerungsfähigkeit zu erzielen.
- Die Wahl des richtigen Ansatzes hängt von der Datenvolatilität, abfragen und Fähigkeiten des Teams ab.
Die Debatte um „Retrieval Augmented Generation“ (RAG) und „Fine-Tuning“ erscheint auf den ersten Blick einfach. Bei RAG werden externe Daten zum Zeitpunkt der Inferenz herangezogen. Beim Fine-Tuning werden die Modellgewichte während Training angepasst. In Produktionssystemen reicht diese Unterscheidung jedoch nicht aus.
Laut Bericht „State of Generative AI in the Enterprise“ von Menlo Ventures aus dem Jahr 2024 „State of Generative AI the Enterprise“ von Menlo Ventures nutzen 51 Prozent der KI-Implementierungen in Unternehmen RAG in der Produktion. Nur neun Prozent setzen hauptsächlich auf Fine-Tuning. Doch Untersuchungen wie die RAFT-Studie der UC Berkeley zeigen, dass hybride Systeme, die Retrieval und Fine-Tuning kombinieren, in Benchmarks besser abschneiden als jeder der beiden Ansätze für sich allein.
Wenn Hybridsysteme bessere Ergebnisse erzielen können, warum setzt die Industrie dann fast ausschließlich auf RAG? In diesem Artikel vergleichen wir RAG, Fine-Tuning und eine Hybridarchitektur, um die Vor- und Nachteile zu verstehen und herauszufinden, wo die einzelnen Ansätze ihre Stärken haben.
TL;DR
- RAG: Am besten geeignet für sich häufig änderndes Wissen und mäßigen Datenverkehr; einfach zu aktualisieren, ohne dass eine erneute Schulung erforderlich ist.
- Feinabstimmung: Am besten geeignet für stabile Domänen und niedrige Latenz mit hohem Volumen oder niedrige Latenz ; verbessert die Aufgabe Genauigkeit und Formatierung.
- Hybrid/RAFT: Kombiniert aktuelle Datenabfrage mit optimiertem Modellverhalten für höchste Genauigkeit.
- Wichtiger Kompromiss: Die Wahl hängt vom abfragen , der Häufigkeit von Wissensänderungen und der Fachkompetenz des Teams ab.
Warum der Vergleich zwischen Standard-RAG und Feinabstimmung nicht funktioniert
RAG ist eine Methode, bei der das Modell während der Inferenz dynamisch externe Daten abruft. Bei jeder abfragen relevante Dokumente oder Wissensbausteine abfragen , die das System an die Eingabeaufforderung anhängt, sodass das Modell Antworten generieren kann, die auf aktuellen Informationen basieren.
Unter Feinabstimmung versteht man den Prozess, bei dem die Gewichte eines Modells während Training beschrifteten Daten angepasst werden. Anstatt auf externe Datenabfragen zurückzugreifen, verinnerlicht das Modell Muster direkt und liefert konsistente Ergebnisse, ohne externe Quellen abfragen zu müssen.
Auch wenn diese Definitionen technisch korrekt sind, lassen die meisten Standardvergleiche die Faktoren außer Acht, die Entscheidungen in der Produktion tatsächlich beeinflussen. In realen Systemen hängt die Wahl zwischen RAG und Feinabstimmung von Variablen wie dem Umfang, abfragen und der Häufigkeit der Datenänderungen ab.
Fehlende Variable 1: Kontext-Erweiterung in großem Maßstab
In vielen RAG-Systemen in der Produktion fügt jede Anfrage Hunderte von Tokens hinzu. Dieser zusätzliche Kontext beeinflusst, wie das Modell seine Aufmerksamkeit verteilt und Gewichte priorisiert.
Umfangreiche, abgerufene Kontexte konkurrieren mit der Eingabeaufforderung und den Anweisungen um die Aufmerksamkeit, was die Signalqualität beeinträchtigen kann. Geringfügige Fehler beim Abruf oder nur lose relevante Textabschnitte können zu Formatabweichungen führen oder die Schlussfolgerungen auf subtile Weise verzerren. Die Ausgabe des Systems hängt stark von der Qualität des abgerufenen Inhalts ab.
Die Feinabstimmung funktioniert anders. Anstatt bei der Inferenz große Textmengen einzuspeisen, werden Muster und Einschränkungen bereits während Training direkt in das Modell eingebettet. Dieser Unterschied wirkt sich darauf aus, wie sich das System unter realen Arbeitslasten verhält.
Fehlende Variable 2: Häufigkeit des Umtrainings
Der gängige Rat lautet: „Verwende RAG, wenn sich das Wissen häufig ändert“, und „verwende Fine-Tuning, wenn das Verhalten stabil ist“. Aber wie oft ist „häufig“?
Wenn sich Ihre Wissensbasis täglich ändert, können Umlernprozesse zu operativen Reibungsverlusten führen. Bewertungszyklen, Datensatz und Deployment verursachen zusätzliche Verzögerungen.
Auch die Datenaufbereitung spielt eine Rolle. Wenn es Ihrem Unternehmen an strukturierten, versionierten und bereinigten Datensätzen mangelt, entstehen versteckte Kosten durch Aufbereitung Training die Rechenkosten übersteigen.
Die Kostenrechnung bei RAG im Vergleich zum Fine-Tuning
Oberflächliche Vergleiche zwischen RAG und Feinabstimmung lassen häufig die Kostenkurven außer Acht, die für die langfristige Rentabilität entscheidend sind. In Produktionssystemen spielen finanzielle Schätzungen bei architektonischen Entscheidungen eine entscheidende Rolle. Um RAG und Feinabstimmung realistisch zu bewerten, müssen wir drei Kostenschichten untersuchen:
- Tokenkosten und Kontext-Erweiterung.
- Kosten für die Abrufinfrastruktur.
- Kosten für die Ausbildungsinfrastruktur.
Die Kostenstruktur von RAG
RAG-Systeme verursachen wiederkehrende Betriebskosten, da bei jeder abfragen externe Informationen abfragen und in die Eingabeaufforderung des Modells eingefügt werden. Dieser zusätzliche Kontext wird bei jeder Anfrage in Rechnung gestellt.
Kontext-Erweiterung
Produktions-RAG-Systeme fügen jeder abfragen etwa 500 Token des abgerufenen Kontexts hinzu. Der Anbieter berechnet diese Token bei jeder Anfrage.
Bei einer Preisgestaltung ähnlich wie GPT-5.2 bei 1,750 Dollar pro Million Eingabetoken betragen die zusätzlichen monatlichen Kosten:
Kosten pro abfragen
500 Token × 1,75 $/1.000.000 = 0,000875 $ pro abfragen
Im kleinen Maßstab erscheinen diese Kosten vernachlässigbar. Da sie jedoch bei jeder abfragen anfallen, steigt der Gesamtaufwand linear mit dem Datenverkehr.
Bei unterschiedlichem Verkehrsaufkommen:
| Monatliche Abfragen | Kontextkosten |
| 10 Millionen | $8,750 |
| 50 Millionen | $43,750 |
| 100 Millionen | $87,500 |
Dies sind allein die Kontextkosten. Ausgabetoken oder Basis-Prompt-Token sind darin nicht enthalten. Bei anhaltendem Umfang wird das, was zunächst flexibel und kostengünstig erscheint, zu einem erheblichen wiederkehrenden Kostenfaktor.
Vektordatenbank und Abrufkosten
Die Token-Kosten sind nur ein Bestandteil der RAG-Kosten. RAG stützt sich zudem auf eine Vektordatenbank für die semantische Suche. Das System muss abfragen effizient speichern, indizieren und abfragen .
Öffentliche Preisgestaltung der Pinecone-Listen:
- Speicherplatz für etwa 0,33 Dollar pro Gigabyte und Monat.
- Die Leseeinheiten kosten etwa 16 Dollar pro Million.
- Die Kosten pro Einheit liegen bei etwa vier Dollar pro Million.
Nehmen wir beispielsweise ein System, das monatlich 50 Millionen Abfragen verarbeitet, wobei jede abfragen eine einzelne Vektorsuche abfragen (unter der Annahme eines Vektors mit 1.024 Dimensionen). Dies würde monatlich 50 Millionen Lesevorgänge ergeben. Wenn das System zudem monatlich etwa sechs Millionen Datensätze schreibt, würden die kombinierten Lese- und Schreibvorgänge die geschätzten monatlichen Gesamtkosten auf etwa 1.532 US-Dollar belaufen.
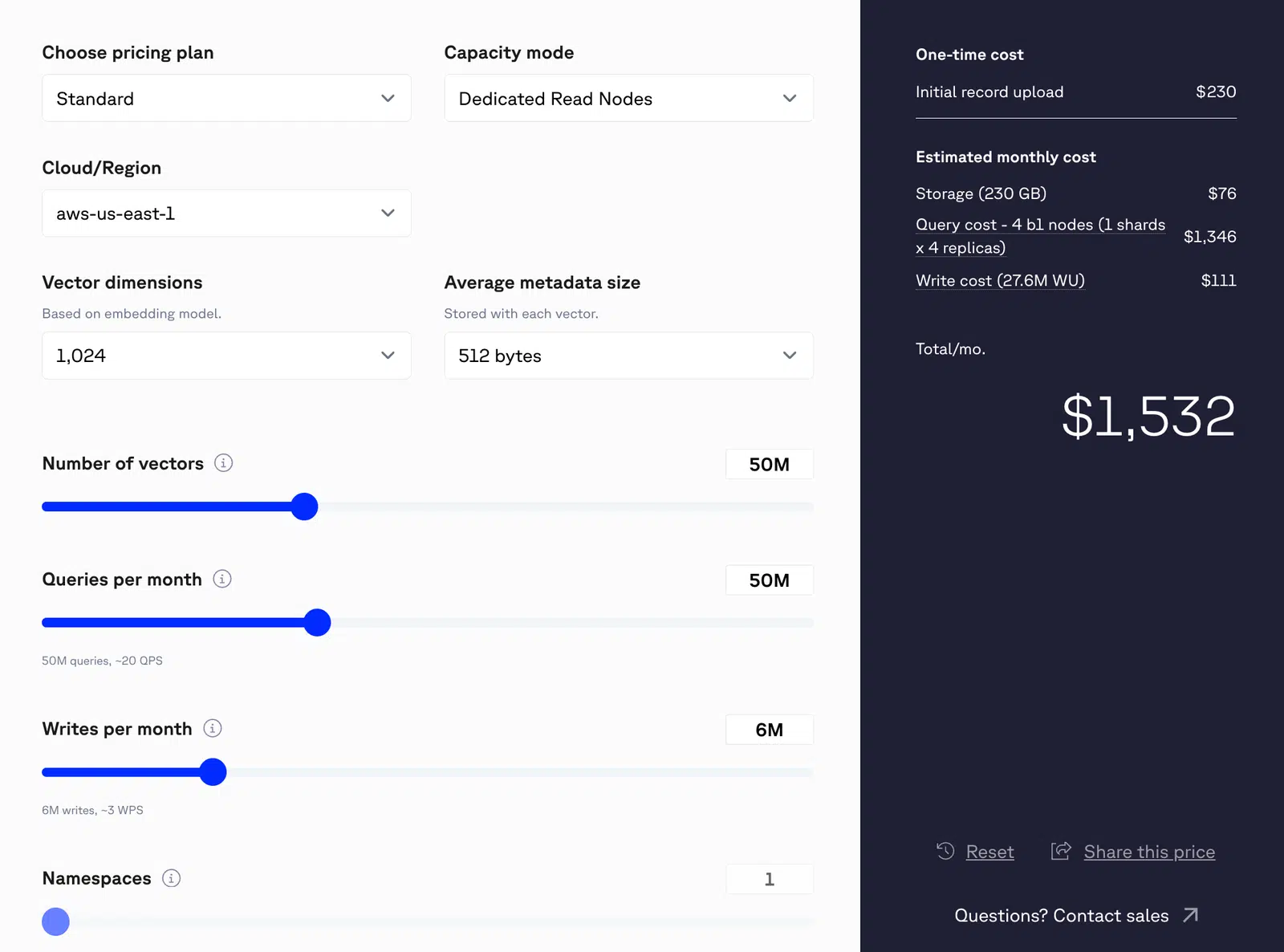
Abbildung 1: Pinecone-Preise für 50 Millionen Vektoren
Bei 200 Millionen Suchanfragen pro Monat belaufen sich die Gesamtkosten auf 9.000 Dollar pro Monat.
Zwei RAG-Systeme, die denselben Datenverkehr bedienen, können daher je nach , wie die Vektordatenbank gestaltet und optimiert ist.
Infrastrukturkosten
RAG-Systeme benötigen eine Speicher- und Recheninfrastruktur, um Einbettungen zu generieren, Vektoren zu speichern und zu indizieren, Abfragen durchzuführen und Inferenzberechnungen auszuführen. Jede dieser Phasen beansprucht Rechenressourcen, die in der Regel über Cloud bereitgestellt werden, die sich an das Datenaufkommen anpassen müssen.
Für Echtzeit- oder Hochdurchsatzanwendungen ist zusätzliche Kapazität erforderlich, um eine geringe Latenz und die Zuverlässigkeit des Systems zu gewährleisten. Replikation, automatische Skalierung, Überwachung und Failover-Mechanismen erhöhen die Komplexität des Betriebs. Diese Infrastrukturebenen sind für RAG im Produktionsbetrieb unverzichtbar, erhöhen jedoch die Gesamtkosten über die reine Token-Nutzung hinaus.
Die Kostenstruktur der Feinabstimmung
Durch die Feinabstimmung wird ein anderes Wirtschaftsmodell als bei RAG-Systemen eingeführt. Anstatt bei jeder Abfrage von externem Kontext zusätzliche Kosten zu tragen, investieren Sie im Voraus, um das interne Verhalten des Modells anzupassen.
Diese Anfangsinvestition lässt sich in vier Hauptkostenkategorien unterteilen: Daten, Training , Experimente und laufende Wartung.
Kosten für die Datenaufbereitung
Hochwertige, annotierte Daten bilden die Grundlage für ein effektives Fine-Tuning. Dazu gehören das Sammeln domänenspezifischer Beispiele, das Bereinigen von Inkonsistenzen, die korrekte Formatierung von Ein- und Ausgaben sowie die Überprüfung der Qualität der Annotationen.
In vielen Unternehmen verbraucht die Datenaufbereitung 20 bis 40 Prozent des gesamten Budgets für die Feinabstimmung. Schlecht aufbereitete Daten beeinträchtigen direkt die Modellleistung, was zu zusätzlichen Trainingszyklen und verschwendeter Rechenleistung führt.
Kosten für das Training
OpenAI gibt die Kosten für das Fine-Tuning für GPT-4.1 mit etwa 25 US-Dollar pro Million Training an. Ein Durchlauf mit 20 Millionen Token würde etwa 500 US-Dollar an direkten Training kosten, wobei sich dieser Gesamtbetrag bei größeren Datensätzen oder mehreren Durchläufen erhöht.
Bei selbst gehosteten Training hängen die Kosten von der Modellgröße und der Hardware ab. High-Performance wie A100-Cluster können Tausende von Dollar pro Training kosten. Da das Fine-Tuning selten in einem einzigen Durchgang erfolgt, sind mehrere Epochen, Bewertungen und Neu-Trainingszyklen üblich, was die Gesamtkosten weiter in die Höhe treibt.
Kosten für Versuche und Validierung
Das Fine-Tuning ist ein iterativer Prozess, der das Experimentieren mit Hyperparametern, den Vergleich mit Basismodellen und das Testen in Randfällen erfordert. Diese Arbeitsabläufe erfordern Entwicklungszeit, Infrastruktur und strukturierte Bewertungsrahmen. Im Gegensatz zum Prompt Engineering führt das Fine-Tuning einen vollständigen ML-Lebenszyklus ein, was einen laufenden betrieblichen Mehraufwand mit sich bringt.
Dadurch entsteht eine nichtlineare Kostenkurve. Durch die Feinabstimmung konzentrieren sich die Kosten auf den Anfang, während die Grenzkosten pro Anfrage bei steigendem Datenverkehr relativ stabil bleiben.
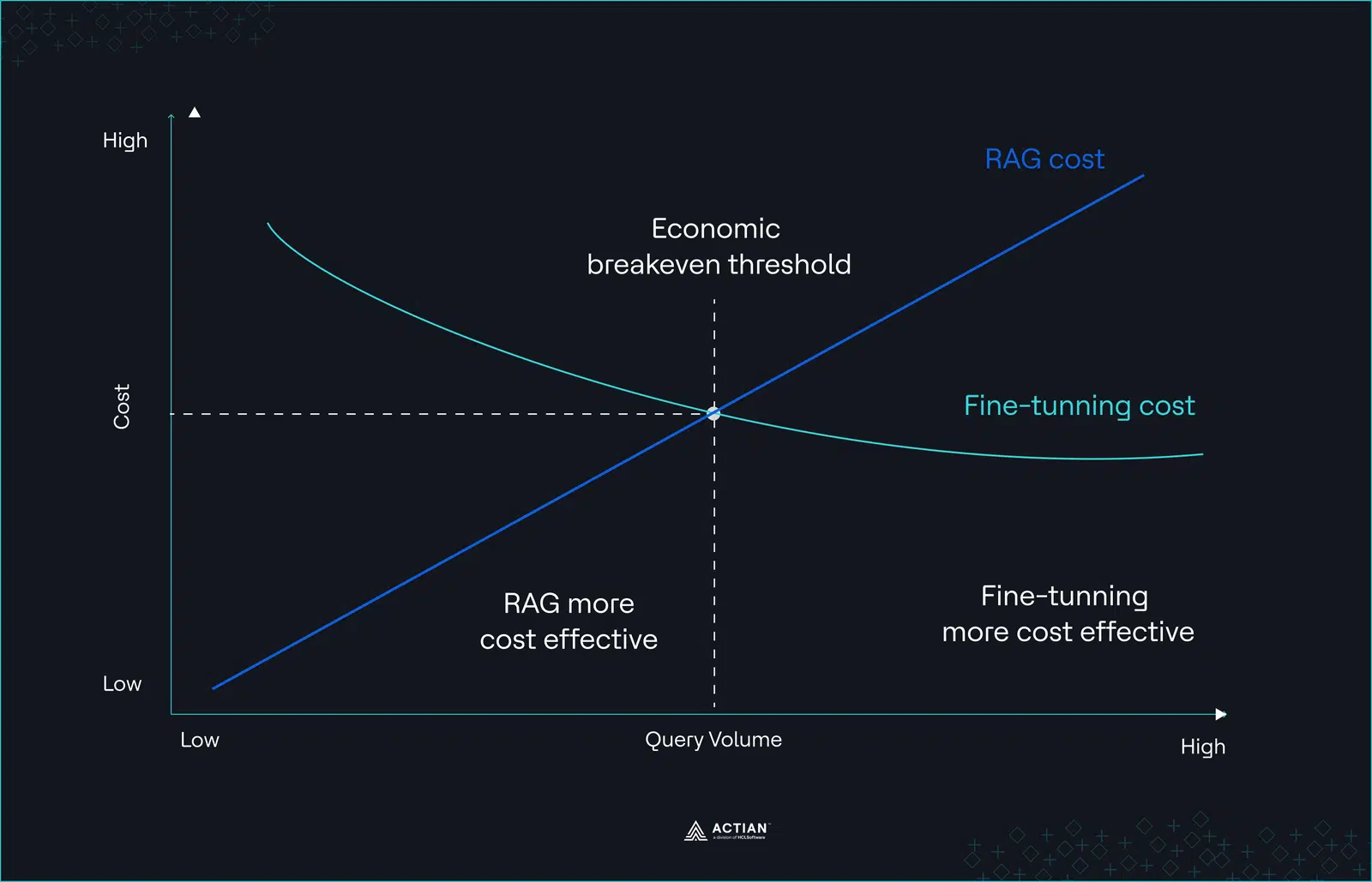
Abbildung 2: Nichtlineare Kostenkurve
Ob dieser Kompromiss vorteilhaft ist, hängt von drei Variablen ab: abfragen , der Wissensstabilität und der Häufigkeit der Neuausrichtung. Ohne diese Variablen explizit zu modellieren, bleiben Kostenvergleiche zwischen RAG und Fine-Tuning unvollständig.
Wenn RAG gewinnt
Trotz der mit der Skalierung verbundenen Kompromisse bleibt RAG aus gutem Grund die bevorzugte Wahl für den produktiven Einsatz. Unter bestimmten Betriebsbedingungen ist es strukturell flexibler, lässt sich schneller iterieren und ist im Betrieb sicherer als das Fine-Tuning. RAG eignet sich für folgende Szenarien:
- Wenn sich Wissen häufig ändert
Wenn sich Ihr Fachwissen wöchentlich oder täglich ändert, wird die Feinabstimmung zu einem betrieblichen Aufwand. Datensatz , das erneute Trainieren, die Bewertung und Deployment Verzögerungen, die je nach Governance-Anforderungen von Stunden bis zu Wochen reichen können.
Teams unterschätzen häufig den operativen Aufwand, der damit verbunden ist, ein feinabgestimmtes Modell mit einer sich rasch weiterentwickelnden Wissensbasis synchron zu halten. In solchen Umgebungen verlagert RAG das Problem vom erneuten Trainieren des Modells hin zur Datenindizierung.
- Wenn Sie über umfangreiche unstrukturierte Daten, aber nur wenige beschriftete Daten verfügen
Viele Unternehmen verfügen über Terabytes an internen Dokumenten, es fehlen ihnen jedoch hochwertige, überwachte Datensätze. Der Aufbau von beschrifteten Training erfordert Annotationsabläufe, Fachexperten und Pipelines zur Qualitätsprüfung. In der Praxis ist dies oft der kostspieligste Teil von Fine-Tuning-Projekten.
RAG umgeht diese Einschränkung, indem es Modellen ermöglicht, direkt auf vorhandenen Dokumentenkorpora zu arbeiten, ohne dass große, mit Anmerkungen versehene Datensätze erstellt werden müssen.
- Wenn strenge Anforderungen an die Unternehmensführung und den Datenstandort gelten
Sobald sensible Informationen eingebettet den Modellgewichten eingebettet sind, gestalten sich das Löschen und die Nachverfolgung schwierig. Das Entfernen einer bestimmten Aufzeichnung einem feinabgestimmten Modell erfordert oft ein erneutes Training oder die Pflege Datensatz komplexen Datensatz .
RAG-Architekturen umgehen dieses Problem, indem sie sensible Informationen in externen Speichersystemen aufbewahren, in denen bereits standardmäßige Governance-Kontrollen vorhanden sind.
- Wenn abfragen moderat ist
Wie aus der vorangegangenen Kostenanalyse hervorgeht, steigt der Aufwand für die Kontext-Erweiterung mit abfragen und erreicht bei 50 Millionen Abfragen etwa 43.750 US-Dollar pro Monat. Bei moderatem Datenverkehr liegen die Kosten pro Anfrage bei RAG in der Regel unter den amortisierten Kosten für das Fine-Tuning, einschließlich Training laufender Wartung. Dies macht RAG zu einer attraktiven Wahl für Unternehmen, die qualitativ hochwertige Ergebnisse erzielen möchten, ohne vorab hohe Investitionen in Infrastruktur und Rechenleistung tätigen zu müssen.
Use Cases
Groß angelegte Beispiele verdeutlichen die Wirksamkeit von RAG in diesem Umfang. Der Q&A-Assistent von Notion ist im Grunde ein groß angelegtes RAG-System für Daten im Arbeitsbereich. Die technische Herausforderung bestand nicht in der Abfrage selbst, sondern in der Durchsetzung von Identitäts- und Zugriffskontrollen während der Abfrage. Wenn ein Nutzer den Assistenten Nutzer , muss das System sicherstellen, dass das Modell nur Dokumente abruft, die der Nutzer einsehen Nutzer .
LinkedIn nutzte RAG und Wissensgraphen, um die Struktur seiner Supportfälle zu bewahren. Dieses System griff auf relevante Teilgraphen statt auf isolierte Textabschnitte zurück, wodurch die Treffgenauigkeit um 77,6 % verbessert und die mittlere Problemlösungszeit um 28,6 %.
Bei Systemen dieser Größenordnung verbindet RAG Kosteneffizienz mit Flexibilität und ermöglicht es Teams, Wissensquellen schnell zu aktualisieren, ohne Modelle neu trainieren zu müssen, und dabei dennoch qualitativ hochwertige Ergebnisse zu liefern.
Wenn Feinabstimmung den Ausschlag gibt
Die Feinabstimmung erweist sich unter verschiedenen Bedingungen als struktureller Vorteil. Zu diesen Bedingungen zählen typischerweise Größenordnung, Stabilität und Verhaltenspräzision.
- Wenn abfragen 100 Millionen pro Monat übersteigt
Bei sehr hohem Datenaufkommen (über 100 Millionen Abfragen pro Monat) wird der Kontext-Overhead von RAG pro Anfrage erheblich. Jede abfragen Hunderte von abgerufenen Tokens abfragen , die das Modell verarbeiten muss, wodurch die Kosten linear mit dem Datenaufkommen steigen. Große Kontextfenster können zudem die Latenz erhöhen, den Durchsatz verringern und die Zuverlässigkeit der Infrastruktur beeinträchtigen.
Wenn das Fachwissen relativ stabil ist, kann die Feinabstimmung effizienter gestaltet werden. Durch die direkte Einbettung des Fachwissens in das Modell vermeiden Unternehmen wiederholte Abruf- und Token-Kosten, was zu besser vorhersehbarenabfragen , höherer Beständigkeit und einem einfacheren Betrieb im großen Maßstab führt.
- Wenn die Ausgabestruktur entscheidend ist
Feinabgestimmte Modelle schneiden oft besonders gut bei Aufgaben ab, die eine strikte Einhaltung von Strukturen oder formalen Vorgaben erfordern. Zum Beispiel Cosine, ein KI-Assistent für die Softwareentwicklung, der in der Lage ist, Fehler autonom zu beheben und Funktionen zu entwickeln, konnte einen SOTA-Ergebnis von 43,8 % im SWE-bench-verifizierten Benchmark zu erzielen.
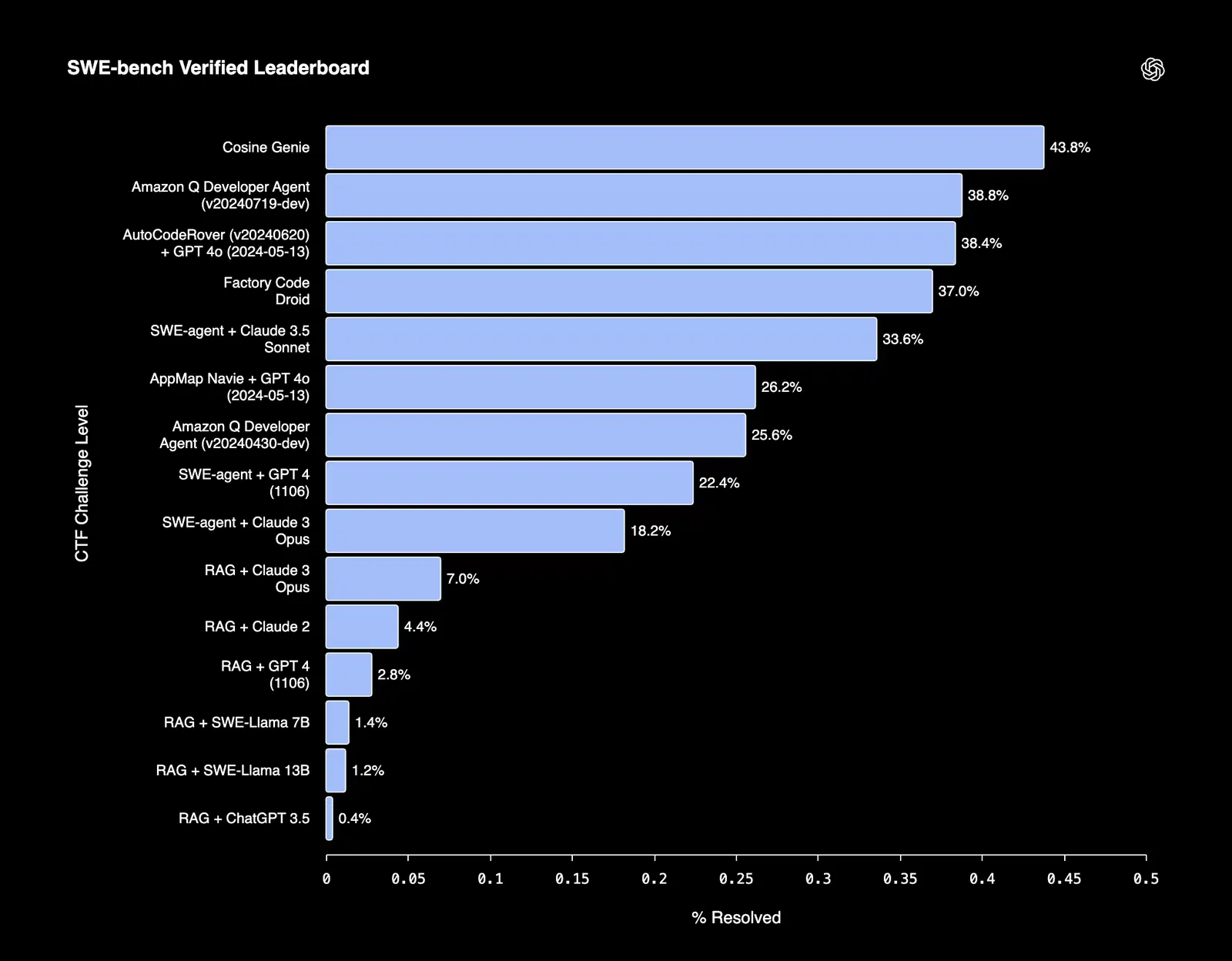
Abbildung 3: SWE-Bench-Rangliste
Ebenso, sicherte sich Distyl sicherte sich den ersten Platz im BIRD-SQL-Benchmark, der weithin als die führende Bewertung für die Text-to-SQL-Leistung gilt. Sein feinabgestimmtes GPT-4o-Modell erreichte auf der Rangliste eine Ausführungsgenauigkeit von 71,83 %.
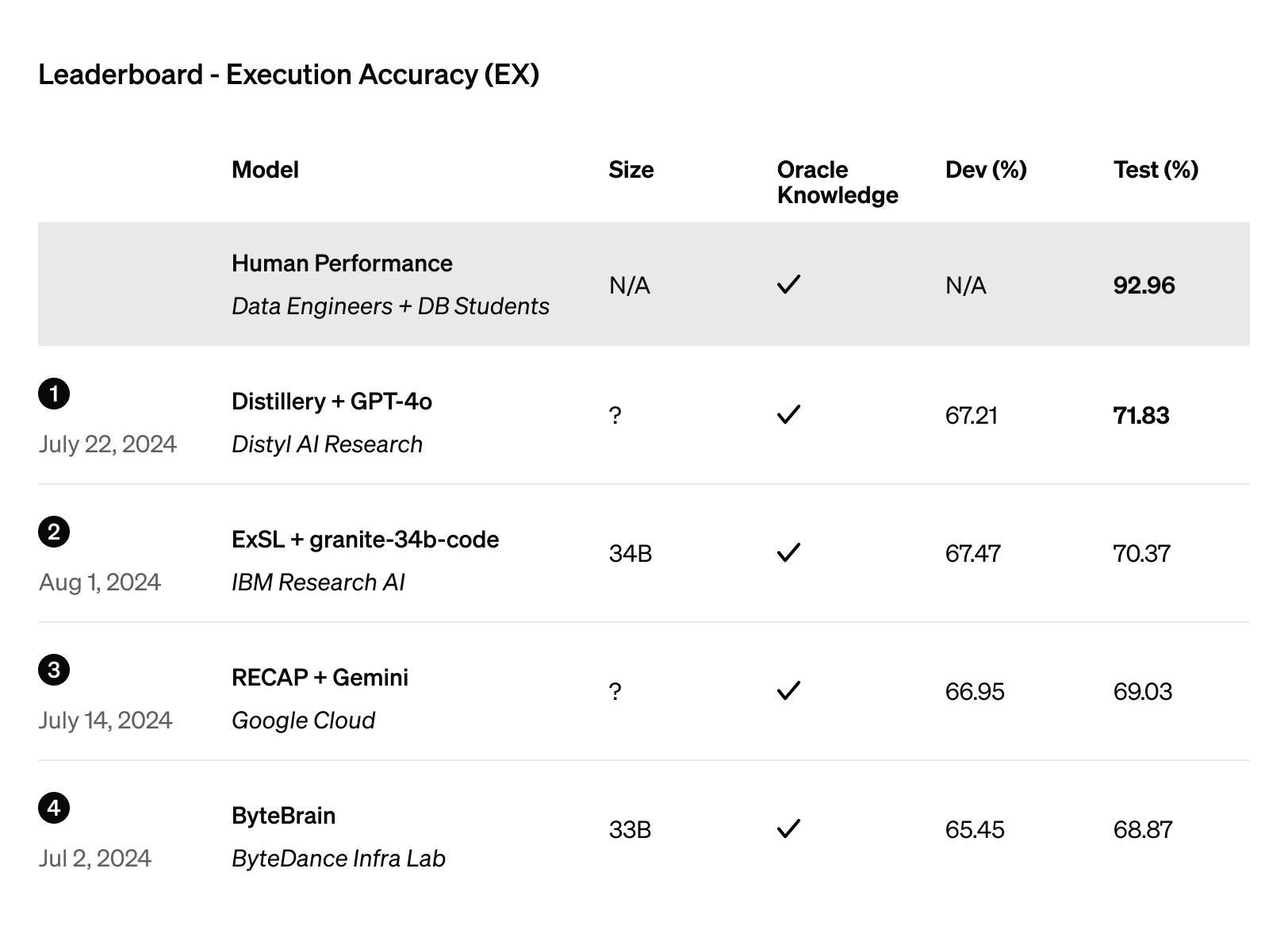
Abbildung 4: Rangliste der Ausführungsgenauigkeit
In Anwendungsfällen, in denen sich Fehler nachgelagert auswirken – etwa in Finanzberechnungen, automatisierten APIs oder Compliance-Dokumenten –, Beständigkeit unerlässlich. In diesen Kontexten sorgt die Feinabstimmung für die erforderliche Zuverlässigkeit, um Risiken zu minimieren und das Vertrauen in automatisierte Ergebnisse zu wahren.
- Wenn strenge Anforderungen an die Latenz bestehen
RAG fügt der Inferenz-Pipeline mehrere Schritte hinzu, die die Antwortzeit verlängern. Jede abfragen die Erzeugung der Einbettung, die Vektorsuche und die Kontexteinbindung durchlaufen, bevor sie das Modell erreicht.
Feinabgestimmte Modelle verzichten gänzlich auf den Abruf von Daten. Das gesamte erforderliche Wissen und alle Denkmodelle sind bereits integriert, sodass das Modell sofort Ergebnisse generieren kann. In Anwendungen, in denen Reaktionszeiten von unter 100 ms erforderlich sind, wie beispielsweise bei Live-Empfehlungssystemen oder Hochfrequenzhandelssystemen, wird durch den Wegfall der Abruf-Pipeline ein wesentlicher Engpass beseitigt.
- Wenn fundiertes Fachwissen wichtiger ist als Aktualität
Eine domänenspezifische Benchmark-Studie im Bereich Landwirtschaft ergab, dass das Fine-Tuning die Modellgenauigkeit von 75 % auf 81 % verbesserte, während Hybridsysteme (Feinabstimmung + Abruf) 86 % erreichten. Da Datensatz der Datensatz auf spezialisiertes landwirtschaftliches Wissen und Schlussfolgerungsaufgaben Datensatz , spiegelt die Verbesserung in erster Linie eine stärkere domänenspezifische Schlussfolgerungsfähigkeit wider und nicht lediglich einen besseren Zugang zu externen Informationen.
In Bereichen wie der Rechtsanalyse oder der medizinischen Entscheidungsunterstützung können Denkprozesse komplex sein. Durch Feinabstimmung können Modelle Fachwissen verinnerlichen, anstatt sich ausschließlich auf den abgerufenen Kontext zu stützen.
Der hybride Ansatz
Zwar haben sowohl RAG als auch das Fine-Tuning jeweils klare Vorteile, doch zeigen Forschungsergebnisse, dass ihre effektive Kombination zu überlegenen Ergebnissen führen kann – allerdings nur, wenn sie richtig umgesetzt wird. Der von der UC Berkeley, Microsoft und Meta Research entwickelte RAFT-Ansatz (Retrieval Augmented Fine-Tuning) zeigt, wie dies in der Praxis.
RAFT trainiert ein Modell darauf, in einer „Open-Book“-Umgebung zu arbeiten. Es lernt, den abgerufenen Kontext zu verarbeiten, relevante Passagen zu identifizieren, irrelevante Informationen zu ignorieren und Belege korrekt zu zitieren. Ohne dieses explizite Training scheitert der Versuch, RAG einfach auf ein feinabgestimmtes Modell aufzulegen, häufig. So kann beispielsweise ein Modell, das auf medizinisches Denken feinabgestimmt wurde, irrelevante Fachartikel abrufen, wenn es nicht gelernt hat, den Kontext zu filtern und zu priorisieren, was zu Halluzinationen oder falschen Empfehlungen führt.
RAFT begegnet diesem Problem mit einem strukturierten 80/20 Training . 80 % der Training enthalten Oracle-Dokumente, auf die das Modell zurückgreifen soll, während dies bei 20 % nicht der Fall ist. Dadurch wird das Modell gezwungen zu lernen, wann es den abgerufenen Daten vertrauen und wann es sich auf interniertes Wissen stützen soll. Dieses operative Detail ist entscheidend für Ingenieure, die beurteilen müssen, ob ihr Team einen hybriden Ansatz erfolgreich umsetzen kann. Es reicht nicht aus, RAG und Fine-Tuning einfach nur zu kombinieren. Das Modell muss darauf trainiert werden, den abgerufenen Kontext zu interpretieren.
Ein gängiges und praktisches Muster lautet:feinabstimmen das Format, RAG für das Wissen.“ Durch Fine-Tuning wird das interne Verhalten des Modells gestaltet, wodurch domänenspezifisches Schlussfolgern, die Struktur der Ausgaben und der Stil festgelegt werden. RAG bietet dynamischen Zugriff auf externe Informationen, die sich häufig ändern oder zu umfangreich sind, um in den Modellgewichten gespeichert zu werden. Im Gesundheitswesen beispielsweise stellt das Fine-Tuning sicher, dass das Modell medizinische Fachbegriffe versteht, einer korrekten diagnostischen Argumentation folgt und die Ausgaben gemäß den Standards für klinische Dokumentation formatiert. RAG ergänzt dies durch das Abrufen der neuesten Forschungsergebnisse, neu veröffentlichter Behandlungsleitlinien oder patientenspezifischer Unterlagen, wodurch die Empfehlungen auf dem neuesten Stand gehalten werden, ohne das gesamte Modell neu trainieren zu müssen.
Ebenso wurde Harvey AI auf 10 Milliarden Token aus der Rechtsprechung, nutzt aber dennoch RAG, um aktuelle Fälle und Aktualisierungen zu verarbeiten. Dieses Muster ist auch in anderen Bereichen weit verbreitet. Rechtssystemefeinabstimmen die juristische Argumentation und den Zitierstilfeinabstimmen , dann wird RAG eingebunden, um die aktuellste Rechtsprechung abzurufen; Finanzmodellefeinabstimmen die Regeln der Portfolioanalysefeinabstimmen , dann wird RAG für Marktaktualisierungen und regulatorische Änderungen eingebunden. Auf diese Weise lässt sich die Stabilität des erlernten Verhaltens mit der Anpassungsfähigkeit der Informationsbeschaffung in Einklang bringen.
Ein quantifiziertes Framework RAG im Vergleich zur Feinabstimmung
Die Frage lautet nicht mehr: „Welcher Ansatz ist besser?“, sondern: „Unter welchen Bedingungen ist der jeweilige Ansatz wirtschaftlich und betrieblich sinnvoll?“
Anstatt sich auf architektonische Präferenzen zu verlassen, sollten Sie drei messbare Variablen bewerten:
- Häufigkeit von Wissensänderungen.
- Monatliches abfragen .
- Einschränkungen hinsichtlich der Infrastrukturkapazitäten und der Governance.
Wenn diese Variablen quantifiziert werden, wird die Entscheidung viel klarer.
Schritt 1: Messung der Wissensfluktuation
Die Häufigkeit von Wissensänderungen ist oft der schnellste Weg, um eine Option auszuschließen. Wenn sich Ihr Fachwissen wöchentlich oder täglich ändert, ist RAG strukturell im Vorteil. Die Aktualisierung eines Index ist weitaus einfacher als das erneute Trainieren eines feinabgestimmten Modells. Die Trennung zwischen Modellgewichten und externen Daten ermöglicht Datenabruf in Echtzeit Datenabruf erneute Bereitstellungszyklen.
Wenn das Wissen über Monate hinweg stabil bleibt, wird eine Feinabstimmung wirtschaftlich sinnvoll. Die Häufigkeit der Neu-Trainings sinkt, und Training können über längere Zeiträume verteilt werden. In solchen Umgebungen kann die direkte Einbettung von domänenspezifischem Wissen in die Modellparameter den langfristigen Aufwand für die Inferenz verringern.
Als praktischer Richtwert:
- Das Wissen ändert sich häufiger als einmal im Monat → Priorisieren Sie RAG.
- Der Wissensstand ist seit mehreren Monaten stabil → Feinabstimmung prüfen.
Schritt 2: Berechnung der Kosten für die Kontexterweiterung
Die nächste Variable ist abfragen . Groß angelegte RAG-Systeme fügen jeder abfragen Hunderte von Tokens hinzu, und dieser Kontextaufwand steigt linear mit dem Datenverkehr.
Quantitative Auslöser
| Monatliche Abfragen | Leitfaden |
| <10M | RAG ist günstiger |
| 10–50 Mio. | Vergleich zwischen Feinabstimmung und RAG |
| 50–100 Mio. | Feinabstimmung oder Hybrid |
| >100M | Feinabstimmung oder Hybrid |
Schritt 3: Bewertung des Reifegrades der Infrastruktur
Auch wenn wirtschaftliche Erwägungen für einen Ansatz sprechen, kann die Infrastruktur die Machbarkeit bestimmen.
RAG erfordert:
- Kompetentes Data Engineering.
- Zuverlässige Datenpipelines.
- Effiziente Architektur für Vektordatenbanken.
- Beobachtbarkeit Überwachung.
Für die Feinabstimmung ist Folgendes erforderlich:
- Hochwertige, gekennzeichnete Daten.
- Maschinelles Lernen .
- Berechnung der Ressourcenzuweisung.
- Bewertungsdisziplin.
Wenn Teams ihre tatsächlichen Fähigkeiten außer Acht lassen, scheitern Architekturentscheidungen bei steigendem Umfang. Viele Produktionsausfälle, die der „Modellqualität“ angelastet werden, sind lediglich Anzeichen einer unausgereiften Infrastruktur.
Entscheidungsmatrix
Die folgende Matrix setzt die Analyse in praktische Leitlinien um.
| Szenario | Monatliche Abfragen | Häufigkeit der Aktualisierung der Informationen | Empfehlung | Begründung |
| Die Fachinformationen werden wöchentlich aktualisiert, mäßiger Traffic | 10–50 Mio. | Wöchentlich/Täglich | RAG | Sofortige Indizierung und geringe laufende Kosten |
| Hohes Verkehrsaufkommen, stabiles Wissen | 50–100 Mio.+ | <1 update/month | Feinabstimmung | Verhindert wiederholte Kontext-Injektion und verringert die Latenz |
| Strukturierte Ausgabe oder Codegenerierung erforderlich | Beliebig | Beliebig | Feinabstimmung | Bindet domänenspezifische Regeln und Formatierungen intern ein |
| Spezialisiertes Denken + regelmäßige Aktualisierungen | 10–50 Mio. | Wöchentlich/Täglich | Hybride | Verbindet verinnerlichtes Denken mit dynamischem Wissen |
| Systeme mit mehreren Domänen und unterschiedlichen Zyklen zur Wissensaktualisierung | 10–100 Mio. | Gemischt | Hybride | Die Feinabstimmung stabilisiert Kerndomänen, RAG bewältigt sich schnell ändernde Quellen |
Anhand dieser Matrix fällt die Entscheidung leichter, ob man RAG einsetzen,feinabstimmen LLMsfeinabstimmen oder den hybriden Ansatz wählen soll.
Abschließende Überlegungen
Die Debatte zwischen RAG und Fine-Tuning wird oft als Entweder-oder-Entscheidung dargestellt, doch die sinnvollere Frage lautet: „Wenn Hybridsysteme nachweislich besser abschneiden als jeder der beiden Ansätze für sich genommen, warum setzt die Industrie dann nach wie vor überwiegend auf RAG?“
Hybrid erfordert sowohl Fähigkeiten im Bereich des maschinellen Lernens Fähigkeiten im Data Engineering Fähigkeiten eine Kombination, über die nur wenige Unternehmen verfügen. RAG bleibt die praktische Standardlösung, da es Agilität und Transparenz bei geringerer Komplexität im Vorfeld bietet.
Das Wichtigste ist, eine Architektur zu wählen, die zu Ihrer Wissensfluktuation, abfragen und den Fähigkeiten Ihres Teams passt. Für Teams, die sich mit Retrieval-Systemen im Unternehmensmaßstab befassen, bieten sich Plattformen wie Actian an VectorAI DB spezielle Fähigkeiten , die auf Leistung und Scalability Fähigkeiten .
Treten Sie der Discord-Community bei und erfahren Sie, wie Actian in Ihre KI-Strategie passt.

Bleiben Sie in Verbindung
Datenanalysen, die Ihnen geliefert werden.
(z. B. sales@..., support@...)