Wie man Vektordatenbanken im Jahr 2026 bewertet




Zusammenfassung
- Die meisten Benchmarks für Vektordatenbanken sind auf bestimmte Anbieter zugeschnitten und spiegeln reale Produktionsbedingungen wie Zustimmung, Filterung und kontinuierliche Dateneingabe nicht wider.
- Zu den wichtigsten Produktionsrisiken zählen die Latenz am Ende der Verteilung (P95/P99), eine mit der Zeit einsetzende Leistungsminderung sowie steigende Gesamtbetriebskosten bei Skalierung.
- Die Branche entwickelt sich in Richtung „Vektor als Funktion“ und bevorzugt integrierte Plattformen wie PostgreSQL + pgvector oder Actian VectorAI DB gegenüber eigenständigen Vektordatenbanken.
- Eine aussagekräftige Bewertung erfordert Tests unter realistischen Bedingungen mit hochdimensionalen Daten, gleichzeitigen Arbeitslasten und einer langfristigen Kostenmodellierung.
Im Jahr 2026 stellt eine Krise im Bereich der synthetischen Leistungsmessung den Markt für Vektordatenbanken vor eine Herausforderung. Eine GitHub-Suche nach „Vektordatenbank-Benchmark“ liefert gepflegte Repositorys mit Dashboards und Leistungsdiagrammen. Allerdings entwickeln Anbieter diese Tools häufig, um ihre eigenen Produkte zu bewerten und architekturbezogene Stärken als objektive Vergleiche darzustellen.
Zilliz pflegt VectorDBBench. Redis und Qdrant veröffentlichen Benchmark-Suiten, die ihre eigenen Systeme in den Vordergrund stellen. Selbst viel zitierte Bewertungen von Approximate Nearest Neighbor (ANN)-Verfahren, wie beispielsweise ANN-Benchmarks, stützen sich auf niedrigdimensionale Datensätze wie Scale-Invariant Feature Transform (SIFT) und Generalized Search Trees (GIST). Moderne Einbettungen großer Sprachmodelle (LLM) erreichen oft 3.072 Dimensionen. Diese Benchmarks spiegeln diese Realität nicht wider.
Ranglisten belohnen Leistung unter statischen Bedingungen, doch Produktionssysteme müssen kontinuierliche Schreibvorgänge, Metadaten und Zustimmung bewältigen. Wie der Softwareentwickler Simon Frey in einem vielbeachteten Beitrag treffend feststellte: „Die beste Vektordatenbank ist die, die man bereits hat.“ Dies spiegelt den Marktwandel im Jahr 2026 wider und veranlasst Teams dazu, sich von spezialisierten Silos weg und hin zu den Datenbanken zu bewegen, denen sie bereits vertrauen und die sie bereits nutzen.
Dieser Leitfaden verfolgt einen produktionsorientierten Ansatz. Wir definieren die fünf entscheidenden Tests für das Jahr 2026 und untersuchen, warum Ihre optimale Vektordatenbank möglicherweise bereits in Ihrer aktuellen Architektur vorhanden ist – sei es PostgreSQL mit pgvector oder eine hybride Enterprise-Engine wie Actian VectorAI DB.
TL;DR
- Die Verzerrung: Die meisten Benchmark-Suiten stammen von Anbietern und sind auf spezifische architektonische Vorteile optimiert.
- Die Realität: Produktions-Workloads umfassen kontinuierliche Datenaufnahme, Metadaten und Zustimmung , die synthetische Tests ignorieren.
- Das Risiko: Tail-Latenz (P99), Indexfragmentierung und Schreibverstärkung beeinträchtigen Systeme lange bevor die durchschnittliche QPS sinkt.
- Die Kostenkurve: Bei Managed Vector Services kommt es häufig zu einer nichtlinearen Preisgestaltung, wenn die Datensatz zunimmt.
- Die Richtung: Im Jahr 2026 werden integrierte Plattformen bevorzugt, von etablierten relationalen Erweiterungen (PostgreSQL + pgvector) bis hin zu hybriden Unternehmenssystemen (Actian VectorAI DB), gegenüber reinen „Vektor“-Silos.
Warum jeder Benchmark, den Sie bisher gesehen haben, auf den jeweiligen Anbieter zugeschnitten ist
Benchmarks erwecken den Anschein von Objektivität, spiegeln jedoch häufig architektonische Annahmen wider. Tools wie VectorDBBench (Zilliz) belohnen verteilte Skalierung, während die Redis- und Qdrant-Suiten den Schwerpunkt auf in-memory legen. Um objektive Daten zu erhalten, müssen Architekten auf wissenschaftliche Konferenzen mit Peer-Review wie NeurIPS und VLDB (Very Large Databases) zurückgreifen, bei denen algorithmische Stringenz Vorrang vor Marketing hat.
Bevor wir uns damit befassen, worauf es in der Produktion ankommt, ist es hilfreich zu verstehen, wie gängige Benchmark-Tools die Ergebnisse beeinflussen.
| Benchmark-Tool | Hauptverantwortlicher | Optimierungsschwerpunkt | Typische Verzerrung |
|---|---|---|---|
| VectorDBBench | Zilliz (Milvus) | Skalierung bei hohem Durchsatz | Bevorzugt große Cluster; benachteiligt Ein-Knoten-Systeme. |
| vector-db-benchmark | Redis/Qdrant | In-memory | Bevorzugt RAM-intensive Architekturen; berücksichtigt die Gesamtbetriebskosten (TCO) des Arbeitsspeichers nicht. |
| ANN-Benchmarks | Wissenschaftlich | Effizienz des Algorithmus im Rohzustand | Verwendet veraltete, niedrigdimensionale Datensätze (SIFT/GIST). |
| NeurIPS / VLDB | Wissenschaftliche Kollegen | Algorithmische Robustheit | Konzentriert sich auf Mathematik/Theorie; lässtSLA außer Acht. |
Die verborgenen Regeln des Benchmarkings
Eine erhebliche Hürde stellt die „DeWitt-Klausel“ dar, eine rechtliche Bestimmung in vielen Nutzer (EULAs), die es Nutzern untersagt, ohne die Zustimmung des Anbieters unabhängige Benchmark-Ergebnisse zu veröffentlichen. Im Jahr 2024 stellte BenchANT fest, dass 30 % der großen Vektordatenbanken die Offenlegung der Tatsache, dass ihre Produkte langsam sind, rechtlich untersagen.
Zudem laufen diese Benchmarks oft zum „Zeitpunkt Null“ ab, jenem künstlichen Zeitfenster unmittelbar nach der Datenaufnahme, aber noch vor den Live-Aktualisierungen. In der Produktion müssen Systeme ständig Daten einfügen und löschen, was den Index zwingt, sich in Echtzeit neu zu optimieren. In den Benchmarks der Anbieter werden die daraus resultierenden Out-of-Memory-Fehler (OOM) oft nicht berücksichtigt.
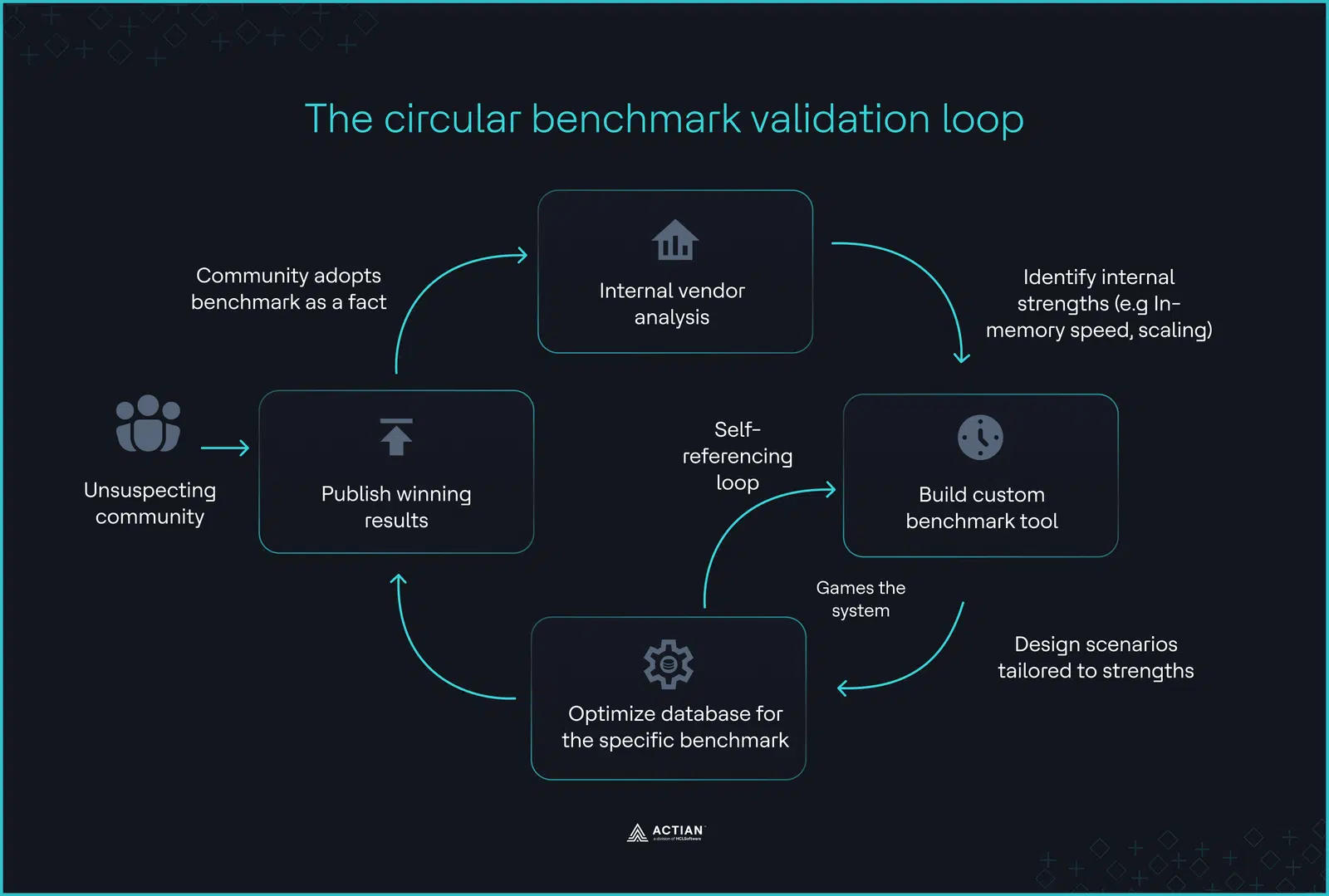
Der zirkuläre Validierungszyklus
Die fünf Produktionstests, auf die es wirklich ankommt
Die meisten Benchmarks messen die Leistung nach dem Laden der Daten, bevor tatsächliche Aktualisierungen stattfinden. Der Echtbetrieb ist jedoch ein ununterbrochener, unvorhersehbarer Prozess. Um eine Datenbank zu finden, die den Anforderungen realer Benutzer gewachsen ist, sollten Sie diese fünf Belastungstests durchführen.
1. Filterung unter gleichzeitiger Belastung
Reine Vektorähnlichkeitssuchen kommen in der Praxis selten vor. Im Produktivbetrieb sucht man eher nach etwas wie „Produktempfehlungen, WOBEI die Kategorie ‚Schuhe‘ ist UND der Lagerbestand > 0 ist“.
Das Entwicklerteam von Reddit, das mehr als 340 Millionen Vektoren verwaltet, identifizierte Metadaten als den größten Leistungsengpass bei seiner Deployment im Jahr 2025. Es stellte fest, dass die Datenbank mit steigender Anzahl gleichzeitiger Nutzer mehr Zeit für die Auflösung Metadaten aufwendete als für die Berechnung von Ähnlichkeitsabständen.
- Die Realität: In der Produktion greifen über 100 Clients gleichzeitig auf verschiedene Metadaten zu.
- Die Lücke: VectorDBBench testet nur mit einem einzigen Client. In der Praxis kann der Datenaustausch zwischen dem Vektorgrafen und dem relationalen Metadaten dazu führen, dass die P99-Latenz um das Zehnfache ansteigt, da die CPU auf Festplatten-E/A CPU .
2. Leistungsabfall im Laufe der Zeit
Zwar können RAG-Systeme (Retrieval-Augmented Generation) technisch gesehen statische Wissensdatenbanken nutzen, doch müssen produktionsreife Anwendungen im Jahr 2026 Echtzeitdaten wie Kundentickets oder Produktbestände widerspiegeln. Wie das Entwicklerteam von Milvus einräumte: „Benchmark-Tests werden nach Dateneingang durchgeführt, doch der Datenfluss in der Produktion hört nie auf.“ Wenn die Datenbank nicht so schnell neu indiziert werden kann, wie Daten eingelesen werden, liefert Ihre KI möglicherweise stundenlang veraltete oder falsche Antworten.
Benchmarks, bei denen der Test „72 Stunden ununterbrochenesabfragenweggelassen wird, sind völlig wertlos. Sie müssen feststellen, ob abfragen nach sechs Monaten ununterbrochener Indexpflege nachlässt.
3. Tail-Latenz unter Last (P95/P99)
Die durchschnittliche Latenz kann irreführend sein und gibt nicht wieder, was die Nutzer tatsächlich erleben. So nützt beispielsweise eine durchschnittliche Antwortzeit von 10 ms nichts, wenn das langsamste 1 % der Abfragen (P99) 800 ms benötigt. Dadurch wirkt Ihr KI-Agent langsam und unzuverlässig. NurZustimmung decken diese Spitzenwerte auf, die häufig während der Garbage Collection oder bei Indexsperren auftreten.
4. Gesamtbetriebskosten (TCO)
Im Jahr 2025 führten Managed Vendors ein komplexes Preismodell auf Basis von „Leseeinheiten“ ein. Dies führte zu einer „Wachstumsstrafe“: Wenn Ihr Index von 10 GB auf 100 GB anwächst, zahlen Sie möglicherweise das Zehnfache für dasselbe abfragen .
| Maßstab | Verwaltete Vektor-Datenbank (nutzungsabhängig) | Integrierte/Hybrid-Plattform | Auswirkungen auf die Gesamtbetriebskosten |
|---|---|---|---|
| Anfangs (10 GB) | Hoch (Plattformgebühr + Nutzung) | Mäßig (feste Ressourcen) | Der integrierte Wert liegt um etwa 40 % niedriger |
| Wachstum (100 GB) | Hoch (skaliert mit dem Volumen) | Niedrig (vertikale Skalierung) | 8-fache Kostendifferenz |
| Enterprise (1 TB+) | Unerschwinglich (lineares Wachstum) | Optimiert (reservierte Kapazität) | Langfristige Einsparungen von über 90 % |
Diese wirtschaftliche Realität ist der Hauptgrund für den Trend des Marktes hin zu „Vector as a Feature“, bei dem Teams folgenden Aspekten Priorität einräumen On-PremisesFähigkeiten vorhersehbare Skalierung gegenüber nutzungsbasierten Silos.
5. Operative Reife
Benchmarks lassen die „Operational Support Tax“ außer Acht, die die Kosten und Risiken für die Wartung spezialisierter Infrastruktur quantifiziert. Es ist leicht, einen PostgreSQL-Experten zu finden, da die Community seit 30 Jahren floriert, doch die Einstellung einer Fachkraft für eine Nischen-Vektordatenbank, die erst seit drei Jahren existiert, führt oft zu einem Engpass.
Bewerten Sie das Ökosystem: Lässt sich die Datenbank mit gängigen backup verwenden? Lässt sie sich in Prometheus integrieren? Wie lange dauert es, einen Index nach einem Absturz wiederherzustellen?
Hier sehen Sie, wie sich die Angaben aus Benchmark-Tests mit der tatsächlichen Produktionsleistung vergleichen lassen.
| Metrisch | Schwerpunkt Benchmark | Produktionsrealität |
|---|---|---|
| Verschlucken | Statische QPS nach Abschluss | Konstante QPS bei kontinuierlichen Schreibvorgängen |
| Latenz | Durchschnittliche Latenz | Latenz von P95/P99 unter gleichzeitiger Belastung |
| Filtern | Gefilterte Suche für einen einzelnen Kunden | Über 100 gleichzeitige, Metadaten Abfragen |
| Kosten | Infrastrukturkosten pro abfragen | Gesamtbetriebskosten bei über 100 Millionen Abfragen pro Monat |
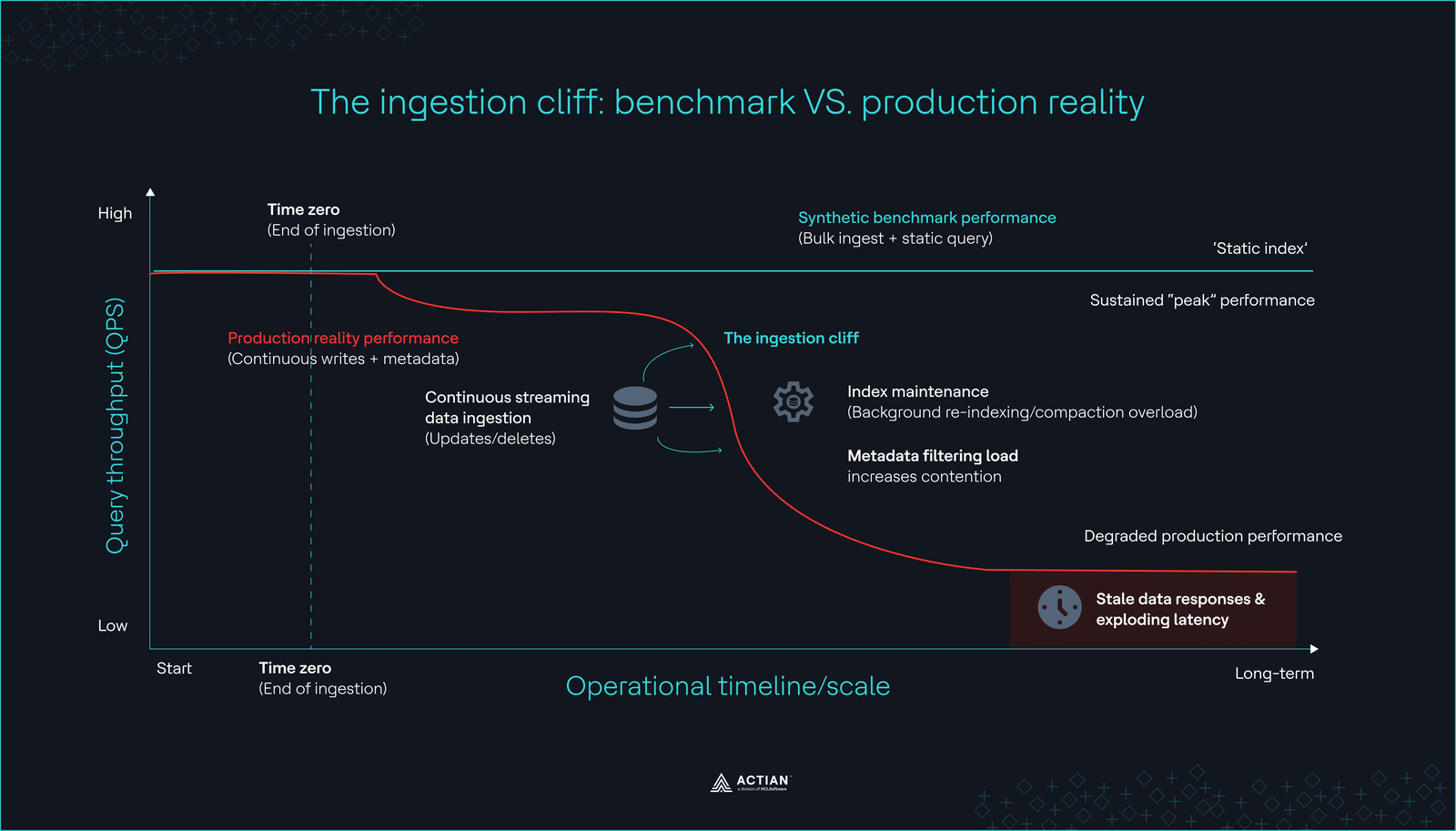 Die Einführungshürde
Die EinführungshürdeDas Aufspüren dieser versteckten Engpässe ist der erste Schritt zum Aufbau eines robusten Systems. Im Jahr 2026 besteht die Lösung selten darin, eine schnellere, spezialisierte Datenbank einzusetzen. Stattdessen erweitern Entwickler die Tools, die sie bereits kennen und denen sie vertrauen, um diese Funktionen.
Der Wandel in der Konsolidierung: Vector als Merkmal
Corey Quinn, Chief Cloud , sagte einmal: „Vektor ist eine Funktion, kein Produkt.“ Diese Prognose prägt den Markt im Jahr 2026. Teams wenden sich von spezialisierten „Vector-Only“-Datenbanken ab und entscheiden sich für integrierte „Vector-Also“-Plattformen. Der Datenaustausch zwischen einer Hauptdatenbank und einer separaten Vektordatenbank verursacht oft mehr Probleme, als er löst.
Die Renaissance von PostgreSQL
Ingenieure argumentieren auf Plattformen wie Hacker News häufig, dass etwa 80 % der RAG-Anwendungsfälle (insbesondere solche mit Einbettungen unter 2 Millionen) keine spezialisierte Vektordatenbank erfordern. Bei diesen Workloads verursachen eigenständige Silos oft mehr operative Reibungsverluste, als sie an Leistungsgewinnen bieten. Instacart hat dies in großem Maßstab bestätigt, indem das Unternehmen von Elasticsearch auf PostgreSQL umstieg und so Kosteneinsparungen von 80 % erzielte sowie Workload das Zehnfache reduzierte, nachdem die Notwendigkeit entfiel, Daten über fragmentierte Architekturen hinweg zu koordinieren und abzugleichen.
Vor kurzem erreichte pgvectorscale bei 50 Millionen Vektoren 471 Abfragen pro Sekunde bei einer Recall-Rate von 99 % und übertraf damit die 41 QPS von Qdrant auf identischer AWS-Hardware. In Hersteller-Benchmarks wird dieses Ergebnis oft ausgelassen, da es zeigt, dass die meisten RAG-Anwendungen keinen spezialisierten Anbieter erfordern.
| Leistungskennzahl | PostgreSQL (pgvector + pgvectorscale) | Qdrant (Spezialisiert) | Das Delta |
|---|---|---|---|
| Durchsatz (QPS) | 471.57 | 41.47 | 11,4-mal schneller in Postgres |
| P95-Latenz | 60,42 ms | 36,73 ms | Qdrant ist am Ende um 39 % schneller |
| P99-Latenz | 74,60 ms | 38,71 ms | Qdrant ist am Ende 48 % schneller |
| Hardware | AWS r6id.4xlarge (16 vCPU) | AWS r6id.4xlarge (16 vCPU) | Parität |
Die Lücke bei der Unternehmensintegration
Für Workloads, die über die grundlegenden Erweiterungen hinausgehen, schließt Actian VectorAI DB diese Lücke durch die Integration einer High-Performance mit nativer Vektorunterstützung. Teams können Metadaten und Ähnlichkeitssuche innerhalb eines einzigen Systems durchführen, wodurch der Datentransport reduziert und abfragen vereinfacht wird.
| Plattform | Architektonische Strategie | Geplante KI-Fähigkeiten |
|---|---|---|
| Actian VectorAI DB | High-Performance | Entwickelt für integrierte Analysen und native Vektorunterstützung. |
| PostgreSQL | Integrierte Funktion | Hebel pgvector innerhalb von Standard-SQL. |
| AWS S3-Vektoren | Speicherorientiert | Entwickelt, um abfragen Vektoren im Objektspeicher abfragen . |
| MongoDB Atlas | Einheitliche Dokument-/Vektor-API | Integriert die native Vektorsuche direkt in den bestehenden Workflow des Dokumentenarchivs. |
Mit der zunehmenden Konsolidierung des Marktes verändert sich auch die Art und Weise, wie wir Datenbanken bewerten. Die Teams fragen nicht mehr: „Wer hat den schnellsten Graphen?“, sondern: „Welche Architektur bietet die zuverlässigste abfragen ?“ Es gibt keinen universellen Sieger. Stattdessen sehen sich die Teams mit einer Reihe von Kompromissen zwischen spezialisierter Geschwindigkeit und integrierter Zuverlässigkeit konfrontiert.
Im Bewertungsprozess wird nun mehr Gewicht auf die operative Leistungsfähigkeit, die Flexibilität in der Praxis und die Unterstützung der hybriden Suche gelegt. abfragen zuverlässige abfragen rückt zunehmend in den Vordergrund, insbesondere angesichts der steigenden Nachfrage nach hybrider Suche.
Die hybride Suchrealität, die reine Vektor-Benchmarks verbergen
Die reine Vektorsuche besteht den „Groundedness“-Test oft nicht; dieser Test misst, wie streng sich die Antwort einer KI auf das bereitgestellte Quellenmaterial stützt. Ein hoher Groundedness-Wert stellt sicher, dass das LLM keine Erfindungen liefert und sich eng an Ihre internen Daten hält.
Laut einer Analyse des Microsoft Azure DevBlogs hat die reine Vektorsuche allein Schwierigkeiten mit der sachlichen Genauigkeit und erzielt bei der Fundiertheit nur mittelmäßige 2,79 von 5 Punkten. Die Lösung ist die Hybrid-Suche, die semantische Vektorähnlichkeit mit traditionellem Schlüsselwortabgleich (BM25) kombiniert.
Der Leistungsabfall von 20–40 %
Die hybride Suche erfordert einen erheblichen Rechenaufwand. Die Datenbank muss die Ergebnisse aus zwei verschiedenen Suchmaschinen – beispielsweise einer lexikalischen und einer semantischen – bewerten und diese anschließend mithilfe eines Fusionsalgorithmus zusammenführen. Bei Produktivimplementierungen kommt es beim Wechsel von der reinen Vektorsuche zur hybriden Suche typischerweise zu einem Leistungsabfall von 20 bis 40 %. Reciprocal Rank Fusion (RRF) verursacht den größten Teil dieser „Merge-Belastung“, die laut Untersuchungen von Elastic abfragen im Vergleich zu Suchvorgängen mit einem einzigen Index erheblich erhöhen kann.
Datenbanken, die die Vektorsuche mit Filterung, Volltextsuche und abfragen in einer einzigen Engine vereinen, führen hybride Abfragen innerhalb einer einzigen atomaren Anweisung aus. Der abfragen kann Metadaten , Volltextbedingungen und Vektorähnlichkeit gleichzeitig auswerten. Dadurch kann der Optimierer bessere Ausführungspläne erstellen und weniger Daten verschieben.
Im Gegensatz dazu fragmentieren spezialisierte Vektorsilos den abfragen . Anwendungen leiten Anfragen über mehrere Systeme weiter und führen die Ergebnisse außerhalb der Datenbank zusammen. Dies erhöht die Komplexität des Systems und führt unter Last zu unvorhersehbaren Latenzen.
Hybridplattformen wie Actian VectorAI DB lösen dieses Problem, indem sie die Vektorsuche direkt in die Datenbank-Engine integrieren. Dieser Ansatz macht systemübergreifende Verknüpfungen überflüssig, vereinfacht die Abläufe und verringert den langfristigen architektonischen Aufwand.
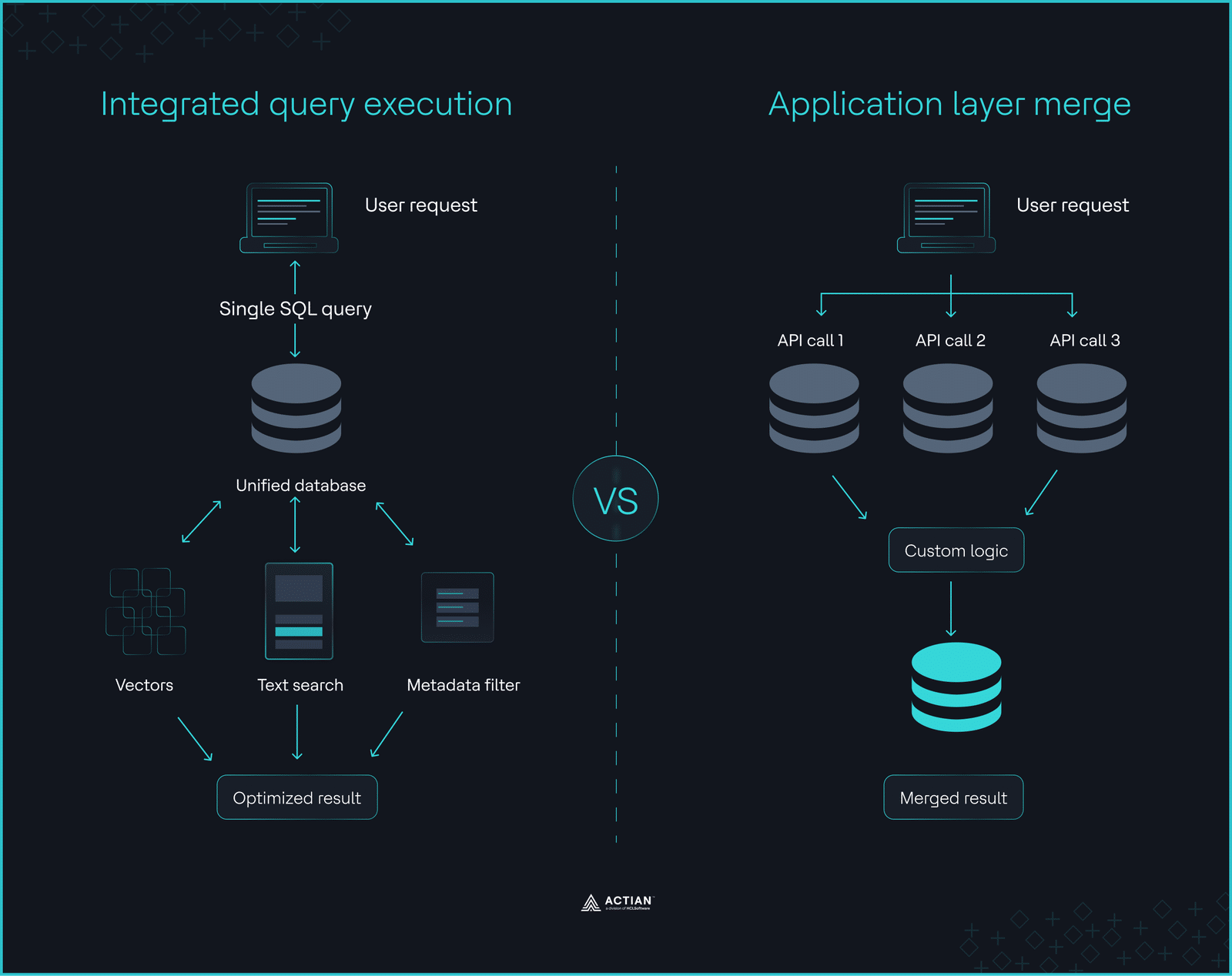 Integrierte abfragen vs. Zusammenführung auf Anwendungsebene
Integrierte abfragen vs. Zusammenführung auf AnwendungsebeneEntwickeln Sie Ihr eigenes Framework
Hören Sie auf zu fragen, welche Datenbank in einem GitHub-Ranking ganz oben steht. Fragen Sie stattdessen, welche Architektur Ihren Anforderungen gerecht wird. Im Jahr 2026 drehen sich diese Anforderungen vor allem um Datenstandort, Skalierbarkeit und das Fachwissen Ihres Teams.
Argumente für Hybrid- und On-Premises
Für globale Unternehmen ist die Datenlokalisierung mittlerweile keine Option mehr. Angesichts der im EU-KI-Gesetz vorgesehenen Strafen in Höhe von bis zu 35 Millionen Euro oder 7 % des weltweiten Umsatzes sind Cloud Cloud-Vektordatenbanken für regulierte Branchen rechtlich undenkbar.
- Souveränität: 60 % der Finanzunternehmen außerhalb der USA planen, bis 2028On-Premises lösungen einzuführen.
- Kosten: Sobald abfragen 100 Millionen pro Monat erreicht, macht sich dieCloud bemerkbar. Durch Eigenhosting oder die Nutzung von Hybridplattformen wie Actian lassen sich Ihre Infrastrukturkosten um die Hälfte senken.
- Reifegrad: Wenn Sie bereits verwalten relationale Datenbank verwalten , verfügt Ihr Team bereits über 90 % der erforderlichen Kompetenzen.
Der Entscheidungsbaum für die Architektur 2026
- Müssen die Daten aus Compliance-Gründen On-Premises werden? → Entscheiden Sie sich für Actian VectorAI DB oder eine selbst gehostete PostgreSQL-Instanz.
- Übersteigt Ihr abfragen 100 Millionen pro Monat? → Vermeiden Sie eine nutzungsabhängige Abrechnung; nutzen Sie stattdessen selbst gehostete oder reservierte Kapazitäten.
- Benötigen Sie komplexe Metadaten ? → Eine integrierte relationale/Vektor-Engine ist unverzichtbar.
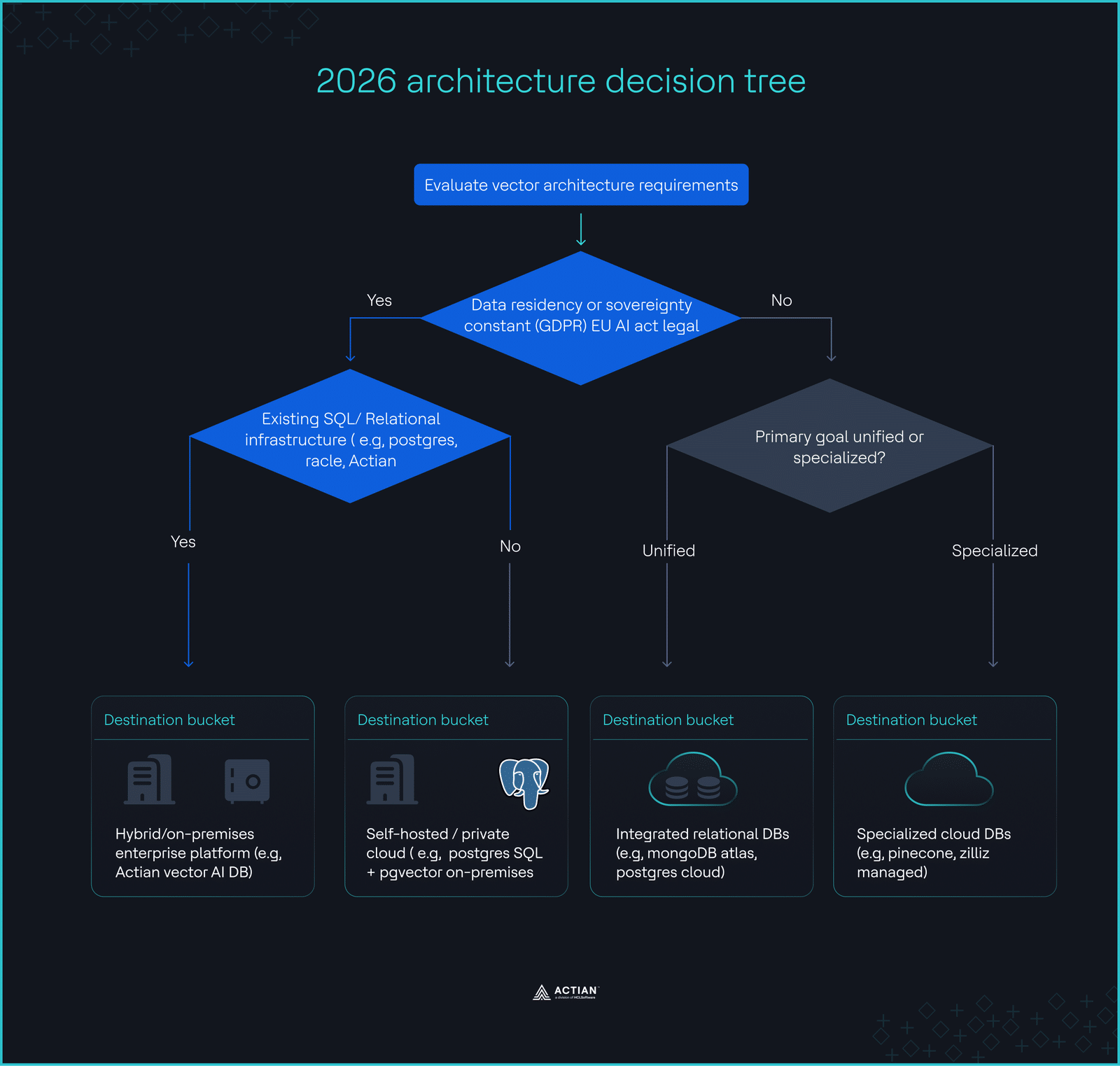 Der Entscheidungsbaum für die Architektur 2026
Der Entscheidungsbaum für die Architektur 2026Wie man die Bewerter bewertet
Um zu vermeiden, dass Sie sich von Hersteller-Benchmarks irreführen lassen, sollten Sie das Bewertungstool genauso sorgfältig prüfen wie die Datenbank. Um einen verzerrten Test zu erkennen, sollten Sie nicht nur auf die angegebenen QPS-Zahlen achten, sondern auch die genauen Bedingungen überprüfen, unter denen diese ermittelt wurden.
Verwenden Sie die folgende Bewertungsrubrik, um jeden Benchmark-Bericht zu prüfen, bevor Sie auf dieser Grundlage Ihre architektonischen Entscheidungen treffen.
| Bewertungskriterium | Rote Flagge (Ergebnis verwerfen) | Grüne Flagge (Vertrauenswürdiges Ergebnis) |
|---|---|---|
| Aufnahmezustand | Abfragen werden gegen einen statischen, unveränderlichen Index ohne Schreibvorgänge im Hintergrund ausgeführt. | „Read-while-Write“-Tests, bei denen Abfragen während Dateneingang kontinuierlichen Dateneingang ausgeführt werden. |
| Hardware-Parität | Cloud Instanzen des Anbieters Cloud im Vergleich zu „Standard“-Instanzen des Mitbewerbers (lokal/nicht kompatibel). | Es wurde überprüft, dass alle getesteten Systeme über identische Konfigurationen hinsichtlich CPU, RAM und Festplatten-E/A verfügen. |
| Datenselektivität | Filter mit „hoher Selektivität“ (99 % der Daten werden entfernt), die Ineffizienzen bei Join- und Scan-Operationen verschleiern. | „Low Selectivity“-Tests (10–20 % gefiltert), die den Motor dazu zwingen, umfangreiche Indexdurchläufe zu bewältigen. |
| Dimension | Tests an 128-dimensionalen historischen Datensätzen (SIFT/GIST). | Tests mit Vektoren der Dimension 1.536 oder 3.072, die mit den Ausgaben moderner LLM-Modelle übereinstimmen. |
| Latenzkennzahl | Konzentriert sich ausschließlich auf die „durchschnittliche Latenz“ oder die „mittlere Antwortzeit“. | Es werden die P95- und P99-Latenzzeiten bei hoher gleichzeitiger Auslastung klar angegeben. |
Checkliste vor der Verpflichtung
- Test mit produktionsrepräsentativen hochdimensionalen Einbettungen (3.072+ Dimensionen).
- Messen Sie die Latenz von P99 bei über 100 gleichzeitigen Benutzern, die verschiedene Metadaten abfragen.
- Berechnen Sie die Gesamtbetriebskosten (TCO) für drei Jahre, einschließlich Speicherwachstum, Datenausgabekosten und Gebühren für die Neuindizierung.
- Vergewissern Sie sich, dass Ihr TeamBeobachtbarkeit die Backups für den neuen Stack verwalten kann.
Abschließende Überlegungen
Eine echte Bewertung erfordert Tests mit Ihren Daten, Ihren Mustern und Ihrem Umfang. Laden Sie Ihre produktionsrelevanten Daten, führen Sie einen einwöchigen Stabilitätstest unter gleichzeitiger Belastung durch und messen Sie die P99-Latenz sowie die Gesamtbetriebskosten (TCO).
Wenn Ihre Workload Compliance, Deployment hybride Deployment oder eine Betriebsreife auf Produktionsniveau Workload , die verwaltete Vektordatenbanken nicht bieten, dann ist der Early-Access-Zugang zu Actian VectorAI DB der richtige nächste Schritt.
Treten Sie der Actian-Community auf Discord bei, um mit Ingenieuren, die reale Produktionsprobleme lösen, über die Vektorarchitektur zu diskutieren.

Bleiben Sie in Verbindung
Datenanalysen, die Ihnen geliefert werden.
(z. B. sales@..., support@...)