5 Architekturmuster für Edge-KI in Umgebungen ohne Internetverbindung




Zusammenfassung
- Für isolierte Umgebungen sind Edge-AI-Architekturen erforderlich, die vollständig offline und ohne Cloud funktionieren.
- Fünf Deployment ermöglichen eine ausfallsichere Edge-KI: Drohnen, Fabriken, föderiertes Lernen, Store-and-Forward und Mesh-Netzwerke.
- Edge-native Designs ermöglichen Echtzeit-Inferenz, geringe Latenz und einen zuverlässigen Betrieb in abgelegenen oder instabilen Netzwerken.
- Die Wahl der richtigen Architektur hängt von der Stabilität der Verbindung, den Anforderungen an die Latenz und den Hardware-Einschränkungen ab.
Ein Muldenkipper, der 200 Meilen vom nächsten Mobilfunkmast entfernt im Einsatz ist, hält nicht an, wenn die Verbindung unterbrochen wird. Eine Offshore-Windkraftanlage unterbricht die Fehlererkennung nicht, nur weil eine Satellitenverbindung während eines Sturms ausfällt. In solchen Umgebungen müssen Inferenz, Regelkreise und Sicherheitssysteme unabhängig vom Netzwerkstatus weiterlaufen. Dennoch dreht sich die vorherrschende Edge-KI-Architektur nach wie vor um Konnektivität und Cloud .
Dezentrale Umgebungen erfordern Edge-native, Offline-First-Architekturen, die auf operative Autonomie ausgelegt sind. Die Signale des Marktes bestätigen diese Entwicklung.
ABI Research prognostiziert, dass die Ausgaben für Edge-Server bis 2027 19 Milliarden US-Dollar erreichen werden, wobei auf On-Premises fast 10,5 Milliarden US-Dollar entfallen. Im Jahr 2025 setzten Unternehmen weltweit rund 815 Millionen Edge-fähige IoT ein.
Die meisten Betriebsumgebungen sind von Natur aus dezentral aufgebaut, sodass Daten weit entfernt von zentralisierten Cloud generiert werden. Deployment , die darauf beruhen, diese Daten zur Verarbeitung hin und her zu senden, führen dazu, dass IoT wichtige Erkenntnisse entgehen, die Latenzzeit steigt und Datenverluste entstehen. Dennoch behandeln die vorgeschlagenen Edge-Architekturen Bereitschaft nach wie vor eher Bereitschaft Zusatzfunktion denn Bereitschaft Standard.
Wir stellen fünf Deployment Edge-KI vor, die ohne vorausgesetzte Konnektivität funktionieren, und behandeln dabei deren Implementierungsstrategien, Anwendungsfälle aus der Praxis, Vor- und Nachteile sowie ein Framework Auswahl des richtigen Modells für Ihre betrieblichen Prioritäten.
TL;DR
Die geeigneten Anwendungsfälle für jedes dokumentierte Deployment auf einen Blick.
| Muster | Am besten geeignet für |
| Die Drohne (autonome Edge-KI mit einem einzigen Knoten) | Autonome mobile Systeme mit strengen Energievorgaben und ohne Cloud |
| Die Fabrik (Edge-KI mit mehreren Knoten und optionaler Cloud) | Einrichtungen mit lokaler Infrastruktur in Umgebungen mit unregelmäßiger Stromversorgung |
| Hierarchisches föderiertes Lernen (Cloud) | Datenschutzkritische verteilte Vorgänge, bei denen das Risiko eines Datenlecks nicht akzeptabel ist |
| Store-and-Forward-Inferenz ohne Verbindung | Vorgänge mit festgelegten Verbindungsfenstern |
| Das Netzwerk (verteilte Edge-to-Edge-Struktur) | Verteilte Koordination ohne Cloud |
Warum isolierte Umgebungen ein Problem für Edge-KI darstellen
Es gibt einen strukturellen blinden Fleck in Bezug auf Umgebungen ohne Internetverbindung, der auf der Annahme beruht, dass Branchen, die Edge-KI-Modelle einsetzen, Cloud sind und unter ständiger Netzwerkanbindung arbeiten. Gerade dort, wo Edge-KI-Anwendungen am wichtigsten sind, gibt es keinen ständigen Netzwerkzugang.
Was „getrennt“ eigentlich bedeutet
Von der Außenwelt getrennte Umgebungen sind Umgebungen mit unzuverlässiger oder fehlender Konnektivität, die von vollständig isolation Netzwerken isolation Umgebungen mit zeitweiligen Verbindungen und häufigen Verbindungsstörungen reichen.
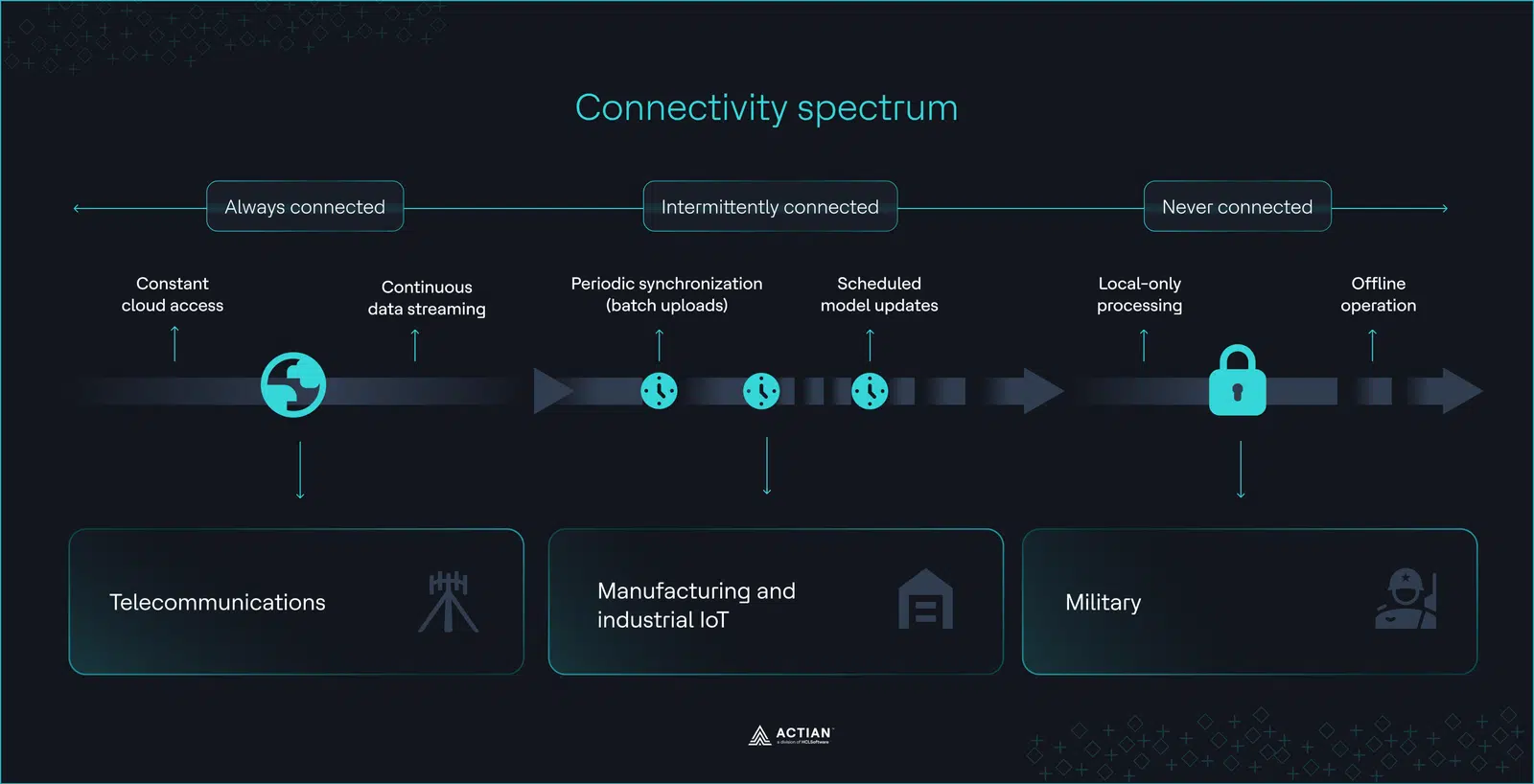
In solchen Einsatzumgebungen kommen Fähigkeiten der Edge-KI Fähigkeiten zum Tragen, da sie die Echtzeit-Datenverarbeitung, geringe Latenzzeiten, Bandbreitenoptimierung und Data Governance ermöglichen, Data Governance in netzwerkunabhängigen Umgebungen erforderlich sind.
Precedence Research schätzt, dass der weltweite Markt für Edge-KI bis 2034 ein Volumen von 143 Mrd. US-Dollar erreichen wird – ein potenzieller Anstieg um 472 % gegenüber 25 Mrd. US-Dollar im Jahr 2025. Für einen erheblichen Teil dieses Marktes ist Cloud ständige Cloud nicht realisierbar. Dennoch Entscheidungsfindung Inferenz, lokale Datenspeicherung und Entscheidungsfindung in Echtzeit unabhängig vom Netzwerkstatus oder Standort weiterlaufen.
Gerade in Situationen ohne Internetverbindung zeigt sich der wahre Wert von Edge-KI
Netzwerkunabhängige Umgebungen wie Bergbaustandorte, Produktionsstätten, militärische Einrichtungen, Offshore-Windparks und Smart Cities zeigen die Grenzen der derzeitigen Deployment Edge-KI auf.
Rio Tinto betreibt Bergbaustandorte, die bis zu 930 Meilen von Mobilfunknetzen entfernt liegen, sodass sich die Betreiber nicht auf eine zentralisierte Infrastruktur verlassen können. Sie benötigen autonome Inspektionsroboter, die mithilfe von Edge-KI Personal und Fahrzeuge verfolgen und Daten von 3D-LiDAR, Wärmebildkameras und Gassensoren in Echtzeit auswerten.
In der Pilbara-Region von Rio Tinto sind mindestens 300 autonome Muldenkipper im Einsatz. Jeder Lkw verarbeitet täglich rund 5 TB Daten in unterirdischen Stollen mit begrenzter Netzabdeckung, was den Einsatz privater LTE-Netzwerke für IoT direkt auf den Geräten erforderlich macht.
Offshore-Windparks stehen vor einer ähnlichen Herausforderung. Windkraftanlagen und Inspektionsschiffe fallen aus, wenn die Satellitenverbindung aufgrund von Unwettern oder Sichtbehinderungen unterbrochen wird, und jede Anlage verzeichnet im Durchschnitt etwa 8,3 Ausfälle pro Jahr. Diese Windparks benötigen Edge-KI-Systeme, die Probleme frühzeitig erkennen, den Schiffsverkehr in Echtzeit überwachen, lokale SCADA-Daten analysieren und Inspektionen auf Grundlage der aktuellen Windverhältnisse anstoßen.
In abgelegenen Produktionsumgebungen benötigen Werksleiter zudem Edge-KI, um Qualitätskontrollen zu automatisieren, Maschinenausfälle vorherzusagen und die Gesundheit der Mitarbeiter zu schützen.
Eine ähnliche Nachfrage nach lokaler, sicherer Datenverarbeitung treibt militärische Operationen an, bei denen Systeme in isolierten Netzwerken in Umgebungen mit eingeschränkter, unterbrochener, zeitweise verfügbarer und begrenzter (DDIL) Konnektivität betrieben werden, um die Vertraulichkeit und Integrität der Daten zu gewährleisten. Soldaten müssen mit Kommandoeinheiten kommunizieren und Kriegsdaten in Echtzeit analysieren, ohne auf Cloud oder umfangreiche Rechenressourcen angewiesen zu sein.
In diesen Umgebungen Deployment Edge-KI die größte Wirkung. Laut Dell wird sich die Datenverarbeitung in Unternehmen bis 2026 auf verteilte Rechenzentren verlagern, doch bei den meisten dokumentierten Architekturen steht nach wie vor die Rückübertragung von Daten an Cloud im Vordergrund.
Die Hardware-Einschränkungen bestimmen Deployment
Die Anforderungen an die Rechenleistung für KI und Workload am Netzwerkrand sind ebenfalls ausschlaggebend für Deployment Cloud.
Ein Deep-Learning-Modell mit 3 Milliarden Parametern kann bis zu 4 GB RAM benötigen, doch Edge-Geräte wie Mikrocontroller und IoT verfügen in der Regel über weniger als 1 GB für Betriebssystem, Arbeitslasten und Speicher zusammen. Architekturen für vernetzte Umgebungen gehen von einer hohen Rechenleistung aus, die am Edge nicht vorhanden ist.
Architekturen für Edge-KI müssen von Anfang an auf Offline-First-Annahmen und Hardware-Einschränkungen ausgelegt sein. Die nachträgliche Integration von Offline-Fähigkeiten in Cloud kann Verbindungslücken und begrenzte Hardware-Ressourcen nicht ausgleichen. Im Folgenden stellen wir fünf Architekturmuster vor, die speziell auf Umgebungen ohne Internetverbindung zugeschnitten sind.
Modell 1: Die Drohne (autonome Edge-KI mit einem einzigen Knoten)
In Umgebungen, in denen keine Netzwerkverbindung besteht und die Betriebslatenz keine Netzwerk-Roundtrips zulässt, beschränkt sich die Deployment auf ein einzelnes Gerät. Die Inferenz kann weder delegiert, synchronisiert noch aufgeschoben werden. Edge-Geräte wie Drohnen, Unterwasserfahrzeuge und Ferninspektionsroboter müssen Entscheidungen ausschließlich auf der Grundlage lokal verfügbarer Rechenleistung, Speicher und Sensordaten treffen.
Diese Vorgabe bestimmt die Architektur der Drohne. Die gesamte KI-Logik läuft auf einem einzigen Gerät, ohne externe Orchestrierung Cloud .
Wenn das Gerät den gesamten Stapel umfasst
Mobile Systeme, die in Umgebungen ohne Netzwerkverbindung autonom funktionieren müssen, Nutzen von diesem Muster.
Da keine externe Orchestrierung vorhanden ist, erfolgen Datenerfassung, Vorverarbeitung, Inferenz, Speicherung und Steuerungslogik innerhalb eines in sich geschlossenen Pakets. Dieses Paket läuft auf einem einzelnen Knoten, ohne dass eine Vernetzung mit anderen Knoten oder eine Verteilung Training erforderlich ist.
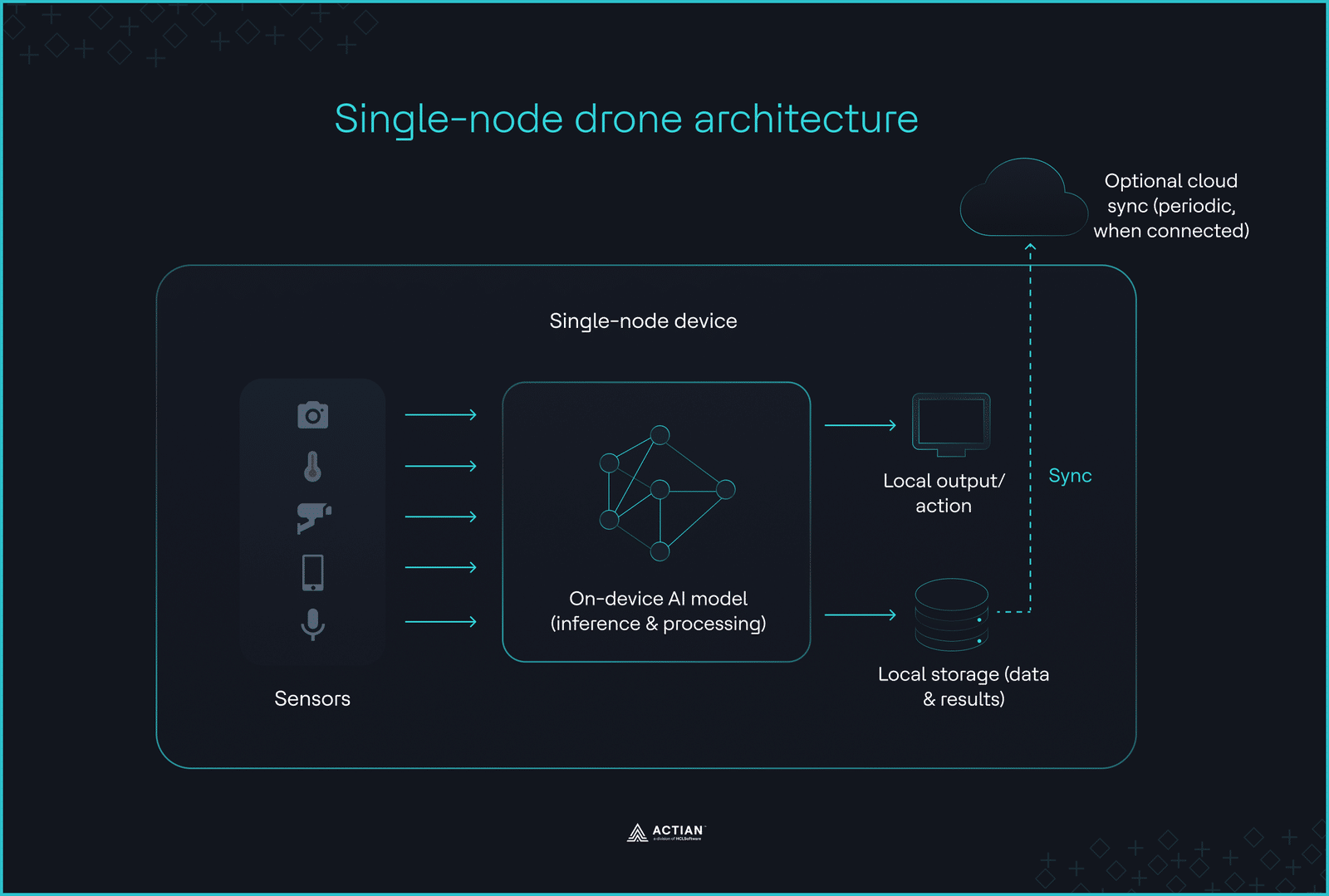
Dank der integrierten Entscheidungslogik können Edge-Geräte vordefinierte Vorgänge auch dann ausführen, wenn sie nicht mit dem Netzwerk verbunden sind. Sobald ein Gerät Daten erfasst, filtert es redundante Informationen heraus und speichert nur die relevanten Daten für einen späteren manuellen Abruf.
Autonome Drohnen, die in Bergbaugebieten Objekterkennung und Geländeklassifizierung durchführen, können ihre Ausführung nicht unterbrechen, während sie auf externe Inferenzergebnisse warten. Die Drohnenarchitektur macht das System unabhängig vom Netzwerk, indem sie den Schwerpunkt auf die Inferenz direkt auf dem Gerät legt.
Dies macht es zum geeignetsten Modell für DDIL-Umgebungen, in denen die Konnektivität aktiv unterbunden oder beeinträchtigt ist. Verteidigungsdrohnen können nicht davon ausgehen, dass sich das Netzwerk wiederherstellt oder dass ein Befehlssignal überhaupt eintrifft. Jede Koordination auf dem Schlachtfeld muss allein vom Gerät aus ausführbar sein.
GE Aerospace, das mehr als 45.000 Triebwerke für Verkehrsflugzeuge betreibt und täglich über 480.000 Daten-Snapshots pro Flugzeug erfasst, setzt diese Architektur in großem Maßstab um. Bord-KI-Modelle übernehmen die vorausschauende Wartung in strikter Übereinstimmung mit DO-178C, wonach GE Aerospace jedes Bordsystem vor dem Start auf alle möglichen Ausfallbedingungen überprüfen muss. Diese Qualitätssicherung entspricht der architektonischen Anforderung der Drohne, nach Deployment keine externe Unterstützung zu benötigen.
Für die lokale Verarbeitung auf einem einzelnen Knoten sind Maschinelles Lernen mit geringem Speicherbedarf erforderlich.
Optimierung der Intelligenz am Netzwerkrand
Edge-Geräte arbeiten mit strengen Speicher- und Leistungsgrenzen, die in Megabyte und Milliwatt gemessen werden. Wenn Netzwerke mit voller Genauigkeit die verfügbaren RAM- oder Energiebudgets überschreiten, muss die Modellkapazität optimiert werden, bevor eine Inferenz möglich ist.
Nicht jede Workload ein neuronales Netzwerk. In ressourcenbeschränkten Umgebungen wie Offshore-Windparks schneiden klassische statistische Methoden wie der Welford-Algorithmus und die lineare Regression bei der Verarbeitung Streaming oft besser ab als neuronale Netzwerke.
Ein Mikrocontroller, der Sensordaten mit dem Welford-Algorithmus verarbeitet, aktualisiert die Statistiken schrittweise, ohne frühere Datenpunkte zu speichern, wodurch Speicherbedarf und Stromverbrauch gering gehalten werden. Bevor Sie ein neuronales Netzwerk bis an seine Hardware-Grenzen ausreizen, sollten Sie prüfen, ob die Modellklasse selbst für den use case geeignet ist.
Wenn neuronale Netze für die jeweilige Workload geeignet sind, gleicht die Quantisierung ihre Hardware-Einschränkungen aus, indem sie die numerische Genauigkeit ihrer Gewichte, Vorspannungen und Aktivierungen verringert. Durch die Reduzierung von 32 Bit auf 8 Bit lässt sich die Modellgröße um etwa 75 % verringern, wobei der Genauigkeitsverlust weniger als 1 % beträgt.
Eine weitere Methode zur Modellkomprimierung, das sogenannte „Pruning“, eliminiert redundante Parameter, die nur minimal zur Genauigkeit der Ausgabe beitragen. Durch das Pruning eines Objekterkennungsmodells wie YOLOv5 lassen sich die Anzahl der Parameter und der Rechenaufwand vor Deployment um 40 % reduzieren.
TinyML-Frameworks wie TensorFlow Lite für Mikrocontroller, ONNX Runtime und PyTorch Mobile unterstützen Deployment kompakter Modelle. Der folgende Code zeigt ein Beispiel für ein Quantisierungsszenario mit TensorFlow Lite.
import tensorflow as tf
import numpy as np
#Training mit dem TFLite-Konverter
# Konvertiert 32-Bit-Fließkommazahlen in 8-Bit-Ganzzahlen
def representative_dataset():
for i in range(100):
yield [X_train[i:i+1]]
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.representative_dataset = representative_dataset
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.inference_input_type = tf.int8
converter.inference_output_type = tf.int8
tflite_quant_model = converter.convert()
Start with quantization for higher speedup rates without significant accuracy loss, followed by pruning to compress the model’s size further. For the drone architecture, the target size on a single microcontroller is <1MB. Plumerai’s person detection model demonstrates how compression techniques can achieve this goal. The model achieved 737KB on an ARM Cortex-M7 microcontroller with less than 256KB of on-chip RAM using binarized neural networks.
Auf Hardware-Ebene führen energieeffiziente Prozessoren wie der NVIDIA Jetson Nano, der Google Edge TPU und der ARM Cortex-M KI-Modelle direkt auf Edge-Geräten aus, die speziell für Aufgaben im Bereich Computer Vision und Sensorfusion entwickelt wurden. ARM-Cortex-M-Varianten liefern je nach Konfiguration bis zu 600 Giga-Operationen pro Sekunde (GOPS) bei einer Energieeffizienz von durchschnittlich 3 Tera-Operationen pro Sekunde pro Watt (TOPS/W).
Deployment Drohnen Deployment einer architektonischen Starrheit. Da Eingriffe während der Laufzeit nur begrenzt möglich sind, muss die Architektur bereits bei der Entwicklung alle möglichen Fehlerzustände vorwegnehmen. Die Norm DO-178C verstärkt diese Einschränkung, indem sie eine vollständige Systemvalidierung vor Deployment vorschreibt. Die Teams müssen jede Modellaktualisierung und jede Verhaltenskorrektur ohne Orchestrierung entwickeln.
Modell 2: Die Fabrik (Edge-KI mit mehreren Knoten und optionaler Cloud)
Bei Netzwerkausfällen in Produktionsstätten und großen Einzelhandelsbetrieben muss die Inferenz in-house mehreren Maschinen weiterlaufen. Die Fabrikarchitektur erfüllt diese Anforderung, indem sie KI-Workloads auf On-Premises verteilt und so die operative Kontrolle innerhalb der Betriebsgrenzen gewährleistet.
Cloud bleibt optional und wird lediglich für das erneute Trainieren von Modellen oder für Batch-Analysen genutzt, nicht jedoch als Laufzeitabhängigkeit. Vorrangig ist die Aufrechterhaltung der Ausfallsicherheit und der operativen Unabhängigkeit aller Knoten, unabhängig von der Netzwerkverfügbarkeit.
Die Inferenz bleibt in der Fertigung
Die Fabrikarchitektur basiert auf drei Komponenten: Edge-Gateways, Rechenknoten und lokaler Speicher.
Ein Edge-Gateway leitet Sensoranfragen an Edge-Knoten weiter, die Kontextdaten aus lokalen Edge-Datenbanken wie Actian Zen abrufen, auf der Grundlage von Modellinferenz Maßnahmen ergreifen und die Ergebnisse wieder in die Datenbank zurückschreiben. Entscheidungsfindung die lokale Datenverarbeitung erfolgen weiterhin On-Premises. Cloud übernehmen lediglich die Modellaktualisierung in regelmäßigen Abständen oder bei Auslösung eines Triggers.
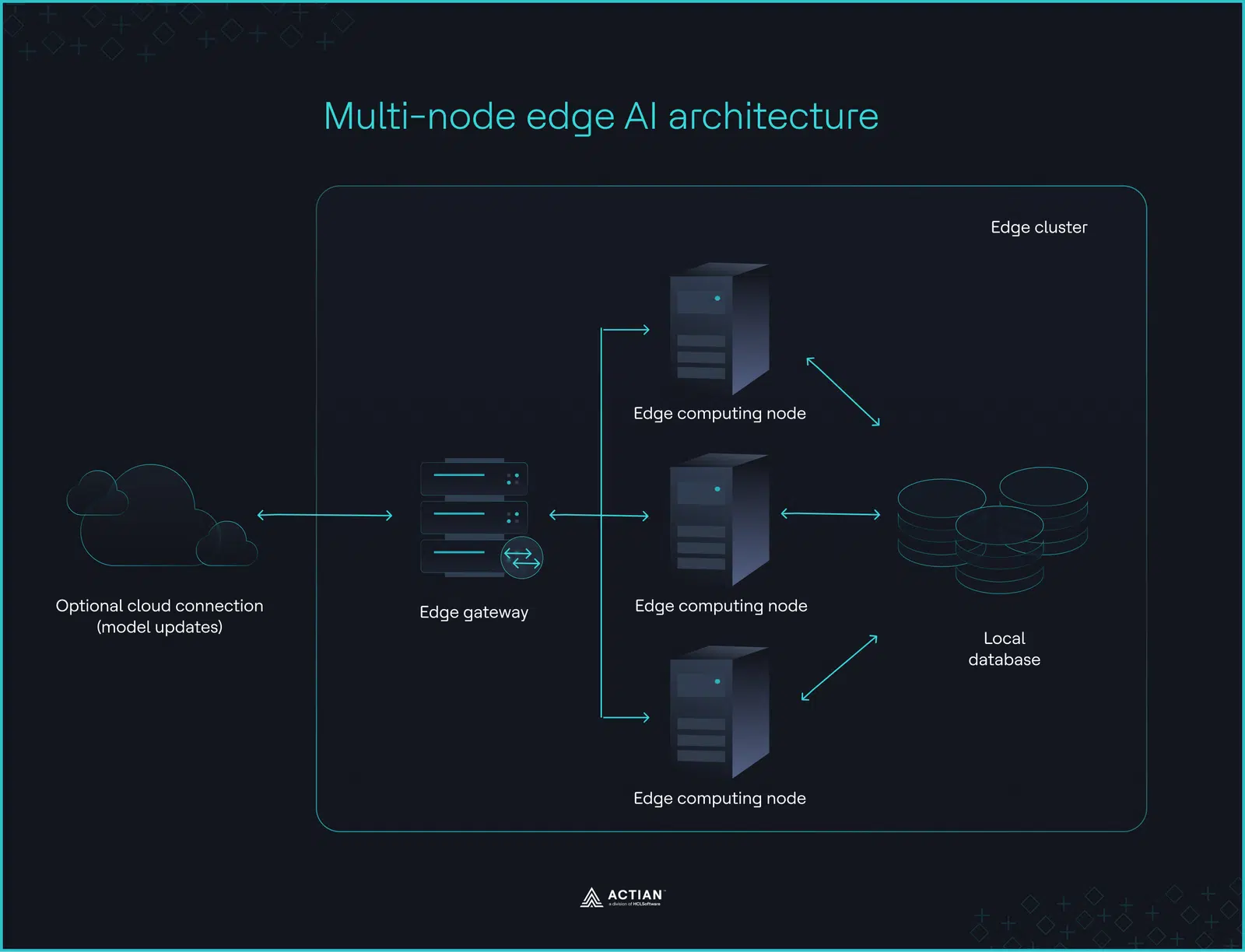
In industriellen Umgebungen fallen kontinuierlich große Mengen an Telemetriedaten von Sensoren, Steuerungen und Prüfsystemen an. Durch die Verteilung der Inferenz auf mehrere Edge-Knoten wird ein hoher Inferenzdurchsatz gewährleistet. Ohne eine lokale Orchestrierung , die die Verteilung und den Modelllebenszyklus verwaltet, arbeiten Edge-Knoten jedoch eher als isolierte Prozessoren denn als koordiniertes System.
K3s, AWS IoT , Azure IoT und Siemens Industrial Edge sind beliebte Orchestrierung für die Verwaltung von Edge-Clustern. Sie unterscheiden sich in der Art und Weise, wie sie Deployment die Knotenverwaltung handhaben.
K3s stellt containerisierte Modelle als Cluster von Worker-Knoten bereit, ergänzt durch eine Steuerungsebene zur Überwachung des Betriebszustands. Durch die Konfiguration des Endpunktparameters für den Datenspeicher können Teams lokale Daten in On-Premises wie PostgreSQL und Actian Zen speichern und so das standardmäßige SQLite ersetzen. Chick-fil-A nutzt K3s am Netzwerkrand, um Kassentransaktionen in über 3.000 Restaurants zu verarbeiten.
AWS IoT stellt Cloud KI-Modelle als Komponenten mit vordefinierten Inferenzfunktionen auf NVIDIA Jetson TX2-, Intel Atom- und Raspberry Pi-basierten Geräten bereit. Die Inferenz erfolgt weiterhin On-Premises, wobei die Daten optional zur Modelloptimierung an AWS IoT exportiert werden können. Die Produktionsstätten von Pfizer nutzen AWS IoT für die Überwachung von Bioreaktoren nahezu in Echtzeit, um das Kontaminationsrisiko zu minimieren.
Siemens Industrial Edge setzt Docker-containerisierte Modelle direkt in der Fertigung ein und liefert so Maschinenstatusdaten in Echtzeit. Die Siemens-Elektronikfabrik in Erlangen konnte mithilfe dieses Orchestrators Deployment um 80 % und die Anzahl derfalsch Anomalie Anomalieerkennungen bei Leiterplatten (PCBs) um 50 % reduzieren . Durch die lokale Durchführung der Inferenz auf Leiterplattenbildern und die Auslagerung lediglich des Modell-Retrainings in die Cloud hat das Werk die Kosten für die Datenspeicherung um 90 % gesenkt.
Azure IoT verwendet ein Deployment , um festzulegen, welche containerisierten Modelle auf Edge-Geräte heruntergeladen werden sollen. Die Datenverarbeitung erfolgt am Edge, wobei Azure IoT eine zentrale Überwachung gewährleistet, während die Geräte ihre Autonomie behalten. Die Thomas Concrete Group nutzt Azure IoT , um Daten von Sensoren zu erfassen, eingebettet nassen Beton eingebettet , den Aushärtungszeitplan des Betons abzuschätzen und Prognosen an Azure IoT zu senden.
Die folgende Tabelle zeigt die Unterschiede zwischen den einzelnen Orchestratoren auf.
| Kriterien | K3s | Azure IoT | AWS IoT | Siemens Industrial Edge |
| Knotenverwaltung | Verwaltet Knoten über eine schlanke Steuerungsebene | Verwaltet Knoten aus der Ferne über IoT Azure IoT | Verwaltet Knoten über AWS IoT | Verwaltet Knoten über die Siemens Industrial Edge Management-Plattform |
| Modellbereit Deployment | Stellt Modelle mithilfe von Standard-Container-Images als Kubernetes bereit | Konfiguriert Bereitstellungen über ein JSON-Manifest, das festlegt, welche Module – die die trainierten Modelle enthalten – auf welchen Knoten ausgeführt werden | Stellt Modelle als Komponenten mit vordefinierten Inferenzfunktionen bereit | Stellt Modelle direkt in der Fertigung als Docker-Container bereit |
| Cloud | Kann in eine zentrale Infrastruktur integriert werden | Unterstützt über Azure IoT | Lässt sich in AWS IoT integrieren | Unterstützt die Integration mit AWS-Diensten |
Wenn das OT-Netzwerk die Sicherheitsgrenze darstellt
Industrieunternehmen führen ihre IT- und Betriebstechnologienetzwerke (OT) zusammen, um On-Premises und IoT On-Premises zu unterstützen. Diese Zusammenführung vergrößert jedoch ihre Angriffsfläche. 75 % der OT-Angriffe gehen von IT-Umgebungen aus, und 80 % der Hersteller berichten von zunehmenden Sicherheitsbedrohungen in ihren IT-/OT-Netzwerken.
Für Teams, die Deployment in Fabrikumgebungen Deployment industrielle Systeme in Betracht ziehen, muss die Netzwerksegmentierung oberste Priorität haben. Edge-AI-Lösungen sollten gemäß dem Purdue-Modell ausschließlich innerhalb des OT-Netzwerks betrieben werden. Sensible Daten und Inferenzberechnungen verbleiben in unmittelbarer Nähe zu den Maschinen, Sensoren und speicherprogrammierbaren Steuerungen (SPS), die sie benötigen. Diese Sicherheitsgrenze minimiert die laterale Ausbreitung von Bedrohungen aus dem IT-Netzwerk.
Modell 3: Hierarchisches föderiertes Lernen (Cloud)
Das hierarchische föderierte Lernen (HFL) basiert auf einer dreistufigen Infrastruktur für Teams, die mit Einschränkungen der Datenmobilität am Netzwerkrand konfrontiert sind.
Auf der untersten Ebene führen Client-Geräte Training lokales Training durch und optimieren die Modellparameter mittels lokalem Gradientenabstieg. Edge-Server auf der mittleren Ebene aggregieren die aktualisierten Modellgewichte aller Client-Geräte, um statistische Kohärenz zu gewährleisten. Eine abschließende Aggregationsrunde durch einen Cloud bildet die oberste Ebene und erzeugt ein globales Modell, das die Edge-Server an die Client-Geräte zurückverteilen. Da diese Hierarchie nur von Parameteraktualisierungen durchlaufen wird, wird Training durch zeitweise unterbrochene Verbindungen nicht gestoppt.
Das folgende Bild zeigt diese Iteration, die so lange fortgesetzt wird, bis das globale Modell die gewünschte Genauigkeit erreicht oder konvergiert.
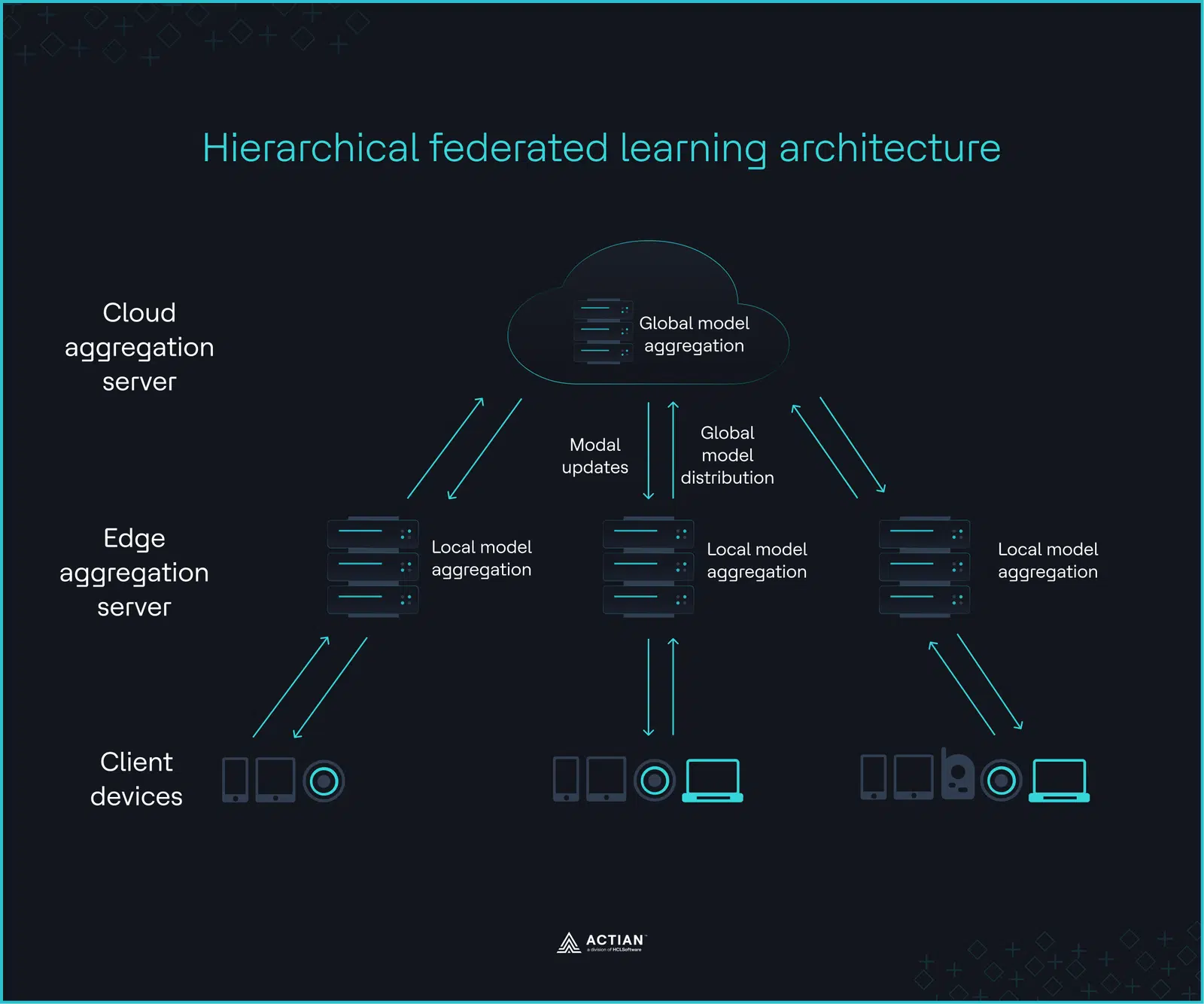
Branchen wie das Gesundheitswesen und Finanzdienstleistungen, in denen Rohdaten aufgrund von Datenschutzbestimmungen, regulatorischen Anforderungen und Bandbreitenbeschränkungen an ihren Ursprungsort gebunden sind, stellen ideale Anwendungsfälle für HFL dar. Vorschriften zur Datenhoheit und geopolitische Spannungen verschärfen diese Einschränkungen zusätzlich und schränken auf Infrastrukturebene ein, wohin und wie Daten fließen dürfen.
Eine Studie von BARC ergab, dass 19 % der Unternehmen planen, ihre On-Premises zu erhöhen, was vor allem auf das Bedürfnis nach Datenhoheit zurückzuführen ist. HFL ermöglicht ein gemeinsames Modell, das sich über verteilte Knoten hinweg verbessern lässt, ohne dass die zugrunde liegenden Daten jemals eine Rechtsgrenze überschreiten.
Ein kürzlich durchgeführtes experimentelles Training Gesundheitswesen erzielte auf einem modifizierten Datensatz des National Institute of Standards and Technology eine Genauigkeit von 94,23 %, wobei die Daten auf den Endgeräten der Kunden verblieben. Nur relevante aggregierte Informationen werden an die Cloud übermittelt, Cloud den Datenschutz zu gewährleisten und das Risiko von Datenlecks zu minimieren.
Deployment Gesundheitswesen übertragen tragbare Geräte (unterste Ebene) Rohdaten an den lokalen Edge-Server eines Krankenhauses (mittlere Ebene), der die Daten mehrerer tragbarer Geräte zusammenführt und sie zur abschließenden Auswertung an eine regionale Forschungseinrichtung (oberste Ebene) weiterleitet, ohne dabei Patientendaten offenzulegen.
HFL ist das komplexeste Muster, das zu implementieren ist. Die Tool-Unterstützung ist nach wie vor lückenhaft, und im Gegensatz zu den anderen besprochenen Mustern fehlt es derzeit an nativer Unterstützung innerhalb des Actian-Ökosystems. Teams sollten diesen Implementierungsaufwand abwägen, bevor sie sich für diese Architektur entscheiden.
Die HFL-Architektur umfasst drei Varianten, je nachdem, welche Ebene die Datenentscheidungen koordiniert.
1. Cloud hierarchisches Föderatives Lernen
Der zentrale Cloud koordiniert den Training , die Kommunikation zwischen Client und Edge-Servern, die Synchronisationszeitpläne sowie die Gesamttopologie, ohne dass zusätzliche Aggregationsrunden von den Edge-Servern erforderlich sind.
Cloud HFL eignet sich für Finanzinstitute, bei denen eine gelegentliche, zuverlässige Verbindung ausreicht, um den Koordinationskreislauf aufrechtzuerhalten. In einerDeployment könnten mehrere Bankinstitute trainieren anhand von Transaktionsdaten trainieren und Aktualisierungen an die Cloud senden, die diese aggregiert, validiert und das verbesserte Modell an die Banken zurückgibt.
2. Am Edge koordiniertes hierarchisches Föderiertes Lernen
Edge-Server verwalten -Zuweisungen autonom und aggregieren Client-Updates, um ein lokal verbessertes Modell zu erstellen, ohne dass Cloud . Cloud werden nur in bestimmten Intervallen für das massenhafte Nachtrainieren von Modellen genutzt. Umgebungen wie Offshore-Windparks, in denen eine instabile Verbindung die Regel ist, Nutzen von dieser Variante. Die Turbinen senden Modell-Updates an einen lokalen Edge-Server, der die Aggregation und die eigenständige Modellverbesserung übernimmt.
3. Peer-to-Peer-Aggregation
Diese Variante basiert auf einem „Gossip“-ähnlichen Modell ohne zentralen Koordinator. Die Clients tauschen ihre Modellgewichte mit anderen Knoten aus, wodurch Gradientenkonflikte bei heterogenen Daten reduziert werden.
Während das zentrale HFL-Modell die Cloud durch aggregierte Aktualisierungen senkt, bleiben bei der Peer-to-Peer-Aggregation sowohl Training die Aggregation innerhalb der teilnehmenden Knoten. In verteilten Umgebungen wie Smart Cities tauschen Verkehrssensoren Aktualisierungen Anomalie direkt mit benachbarten Geräten aus, bis sie sich organisch auf ein verbessertes Modell im gesamten Netzwerk einigen.
Alle drei Varianten unterscheiden sich hinsichtlich ihrer funktionalen Anforderungen, wie in der folgenden Tabelle dargestellt.
| Merkmal | Cloud | am Rand koordiniert | Peer-to-Peer-Aggregation |
| Orchestrierung | Cloud die gesamte Aggregation und Modellverteilung | Der Edge-Server führt lokal eine Zusammenfassung durch und synchronisiert sich Cloud mit Cloud | Kein Koordinator; Aktualisierungen werden zwischen den Clients weitergegeben, bis eine Übereinstimmung erreicht ist |
| Datenschutzstufe | Medium; die Cloud die Modellaktualisierungen | Hoch; die Rohdaten verbleiben auf lokalen Edge-Servern | Hoch; es gibt keine zentrale Stelle, die die aggregierten Aktualisierungen überwacht |
| Anforderungen an die Bandbreite | Hoch; alle Aktualisierungen werden an die Cloud gesendet | Mittel; nur aggregierte Aktualisierungen gelangen in Cloud | Niedrig; Aktualisierungen werden nur zwischen benachbarten Peers übertragen |
| Ausfalltoleranz | Niedrig; Durch Cloud wird die Koordination beeinträchtigt | Hoch; der Edge-Server arbeitet bei Ausfällen eigenständig weiter | Mittel; langsame Konvergenz bei Netzwerkpartitionen |
Die mehrschichtige Infrastruktur von HFL unterstützt Training groß angelegter Modelle, Training sie Rechen- und Kommunikationsaufgaben auf mehrere Knoten innerhalb der Hierarchie verteilt. Die Herausforderung bei diesem mehrschichtigen Design besteht darin, den Kommunikationsaufwand, veraltete globale Modelle und die Neukonfiguration von Knoten zu bewältigen.
Bei HFL sind die Kommunikationskosten direkt proportional zur Größe der Modellaktualisierung. Techniken zur Gradientenkomprimierung wie zufällige Sparsifizierung und stochastische Rundung reduzieren die Aktualisierungsdaten vor der Übertragung um bis zu 98 %.
Der asynchrone Aktualisierungszyklus von HFL, bei dem das globale Modell Client-Aktualisierungen sofort nach ihrem Eintreffen einbezieht, erhöht zudem die Wahrscheinlichkeit, dass Modellparameter veraltet sind. Die gewichtete Aggregation begrenzt den Einfluss veralteter Aktualisierungen und verhindert so, dass langsamere Geräte die Qualität des globalen Modells beeinträchtigen.
Topologieänderungen stellen eine weitere Herausforderung dar. Clients werden anderen Edge-Servern zugewiesen, Rollen wechseln zwischen Client- und Aggregator-Knoten, und neue Geräte kommenTraining hinzu. Jede Neukonfiguration verzögert die Konvergenz und beeinträchtigt die Genauigkeit, wenn neuen Edge-Servern Training bisherigen Training fehlen.
Muster 4: Store-and-Forward-Inferenz ohne Verbindung
In Umgebungen ohne Internetverbindung kann es vorkommen, dass die Verbindung stunden- oder tagelang unterbrochen ist. Die Store-and-Forward-Architektur trägt dieser Tatsache Rechnung, indem sie die Datenverarbeitung und -speicherung in großem Umfang während Downtime aufrechterhält und Zusammenfassungen an die Cloud weiterleitet, Cloud die Verbindung wiederhergestellt ist.
In Umgebungen der industriellen Automatisierung, wie beispielsweise bei Öl- und Gasförderanlagen in abgelegenen Gebieten oder auf Seeschiffen, die kilometerweit von Mobilfunkmasten entfernt operieren, löst diese Architektur das zentrale Problem, die Datenkontinuität trotz Netzwerkausfällen aufrechtzuerhalten.
Die Inferenz wartet nicht auf die Cloud
Deployment einem hybriden Ansatz. Das Training beginnt in der Cloud, doch nach Deployment wird die Ausführung an den Edge verlagert. Bei einem Verbindungsabbruch laufen Entscheidungsfindung, Regelkreise und Alarmauslöser lokal ohne Unterbrechung weiter, und das System speichert die mit einem Zeitstempel versehenen Ergebnisse in einer lokalen Edge-Datenbank die Synchronisation wiederhergestellt ist.
Sobald die Netzwerkverbindung wiederhergestellt ist, überträgt das Edge-Gateway alle zwischengespeicherten Ereignisse an eine zentrale Cloud und stellt so die Daten bereit, die für die Bereitstellung aktualisierter Modelle und die Optimierung von KI-Pipelines erforderlich sind.
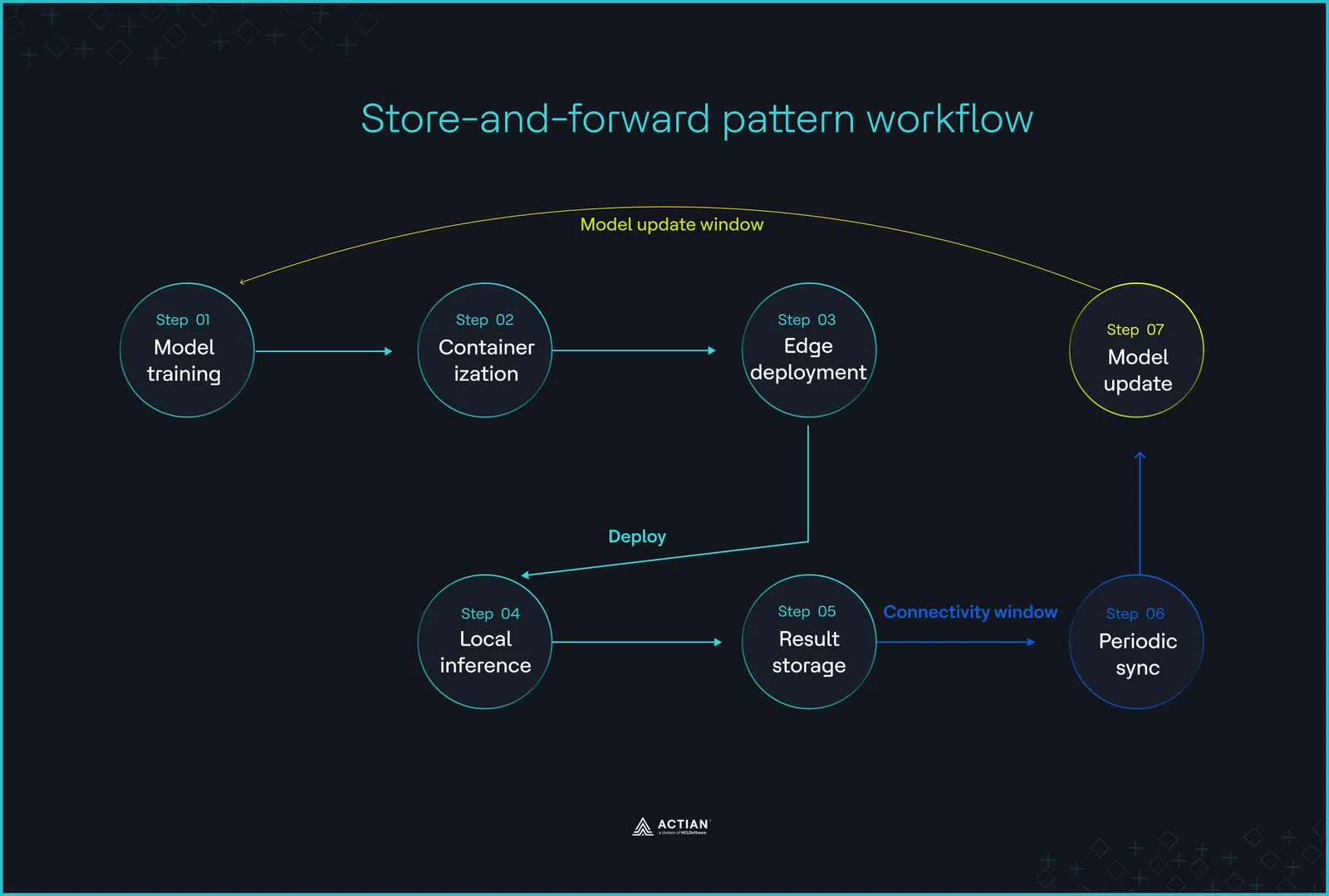
Die Store-and-Forward-Architektur schafft eine Rückkopplungsschleife, die Datenverluste bei Verbindungsunterbrechungen verhindert. In Produktionsanlagen erfassen SCADA-Systeme weiterhin Daten von SPSen, Fernterminalgeräten (RTUs) und Edge-Gateways, bis die Verbindung wiederhergestellt ist.
Wenn die Daten endlich übertragen werden
Der „Frontend“-Teil dieser Architektur stützt sich auf schlanke Kommunikationsprotokolle wie Message Queuing Telemetry Transport (MQTT), die für instabile Netzwerke und Umgebungen mit begrenzter Bandbreite konzipiert sind.
Das Publish-Subscribe-Modell von MQTT leitet die in der Warteschlange befindlichen Aktualisierungen von Edge-Gateways Cloud Broker wie Mosquitto an die Cloud weiter. Publisher (Sensoren) senden Nachrichten an ein Thema (Temperatur), und Subscriber (Cloud ) empfangen Nachrichten von den Themen, für die sie registriert sind. Die Nachrichten werden in genau der Reihenfolge wiedergegeben, in der sie empfangen wurden.
Der folgende Python zeigt eine erste Implementierung unter Verwendung der Paho-MQTT-Bibliothek. Dabei kommt Quality of Service (QoS) 1 zum Einsatz, eine persistente Sitzung, die es Mosquitto ermöglicht, Nachrichten in die Warteschlange zu stellen, während der Abonnent offline ist.
# pip install paho-mqtt
import paho.mqtt.publish as publish
import sys
if len(sys.argv) < 3:
print("Usage: publisher.py <topic> <message>")
sys.exit(1)
# Production code will add retry logic, local queue persistence, and message deduplication
topic = sys.argv[1]
message = sys.argv[2]
publish.single(topic, message, hostname="localhost", qos=1)
Um die Datenübertragung nach dem erneuten Verbindungsaufbau zu starten, erstellt das folgende Skript eine dauerhafte Sitzung mithilfe von clean_session=False und loop_forever().
import paho.mqtt.client as mqtt
import sys
if len(sys.argv) < 2:
print("Usage: subscriber.py <topic>")
sys.exit(1)
topic = sys.argv[1]
client_id = "test-client"
def on_connect(client, userdata, flags, rc):
print(f"Connected with result code {rc}")
client.subscribe(topic, qos=1)
def on_message(client, userdata, msg):
print(f"{msg.topic}: {msg.payload.decode()}")
client = mqtt.Client(client_id=client_id, clean_session=False)
client.on_connect = on_connect
client.on_message = on_message
client.connect("localhost", 1883, 60)
client.loop_forever()
Bei einer Store-and-Forward-Architektur kann es während der Gateway-Synchronisation zu Inkonsistenzen bei der Datenreplikation kommen. Das System benötigt eine Arbitrationsrichtlinie, beispielsweise „Last-Write-Wins“, die Änderungen auf der Grundlage des Zeitstempels der jeweiligen Aktualisierung übernimmt. Sind die Zeitstempel identisch, führen Datenstrukturen wie Conflict-free Replicated Data Types (CRDTs) die Kopien zusammen, um einen konsistenten Endzustand über alle Edge-Gateways hinweg zu erreichen.
Die Delta-Synchronisierung verbessert die Ergebnisse von CRDTs noch weiter. Während bei Datensatz vollständigen Datensatz bei jeder Aufzeichnung eine Synchronisierung ausgelöst wird, löst die Delta-Synchronisierung Konflikte auf Eigenschaftenebene und berücksichtigt dabei nur die geänderten Felder.
Modell 5: Das Netzwerk (verteilte Edge-to-Edge-Struktur)
Das Netzwerk Deployment behebt das Problem der mangelnden Fehlertoleranz und verteilten Verarbeitung, das bei dezentralen, standortübergreifenden Abläufen wie Logistiknetzwerken und Smart Grids häufig auftritt.
Die Koordination von Edge-Geräten an mehreren Standorten über ein Cloud stößt schnell an die Grenzen der Netzwerkabdeckung. Aus diesem Grund folgt die Netzwerkarchitektur einem Ost-West-Kommunikationsmuster, wodurch Edge-Knoten Daten direkt mit anderen Knoten austauschen können, ohne dass eine zentrale Koordination erforderlich ist.
Die Mesh-Kommunikation ermöglicht verteilte Intelligenz
Das Deployment basiert auf einem nicht-hierarchischen Aufbau, bei dem mehrere IoT über ein Mesh-Netzwerk miteinander verbunden werden, um die Systemverfügbarkeit bei Ausfällen zu verbessern. Jeder Knoten kommuniziert dynamisch mit seinen Nachbarn und bildet so ein bidirektionales Netzwerk, das Daten über Mehrfach-Hop-Pfade an entfernte Umgebungen weiterleitet.
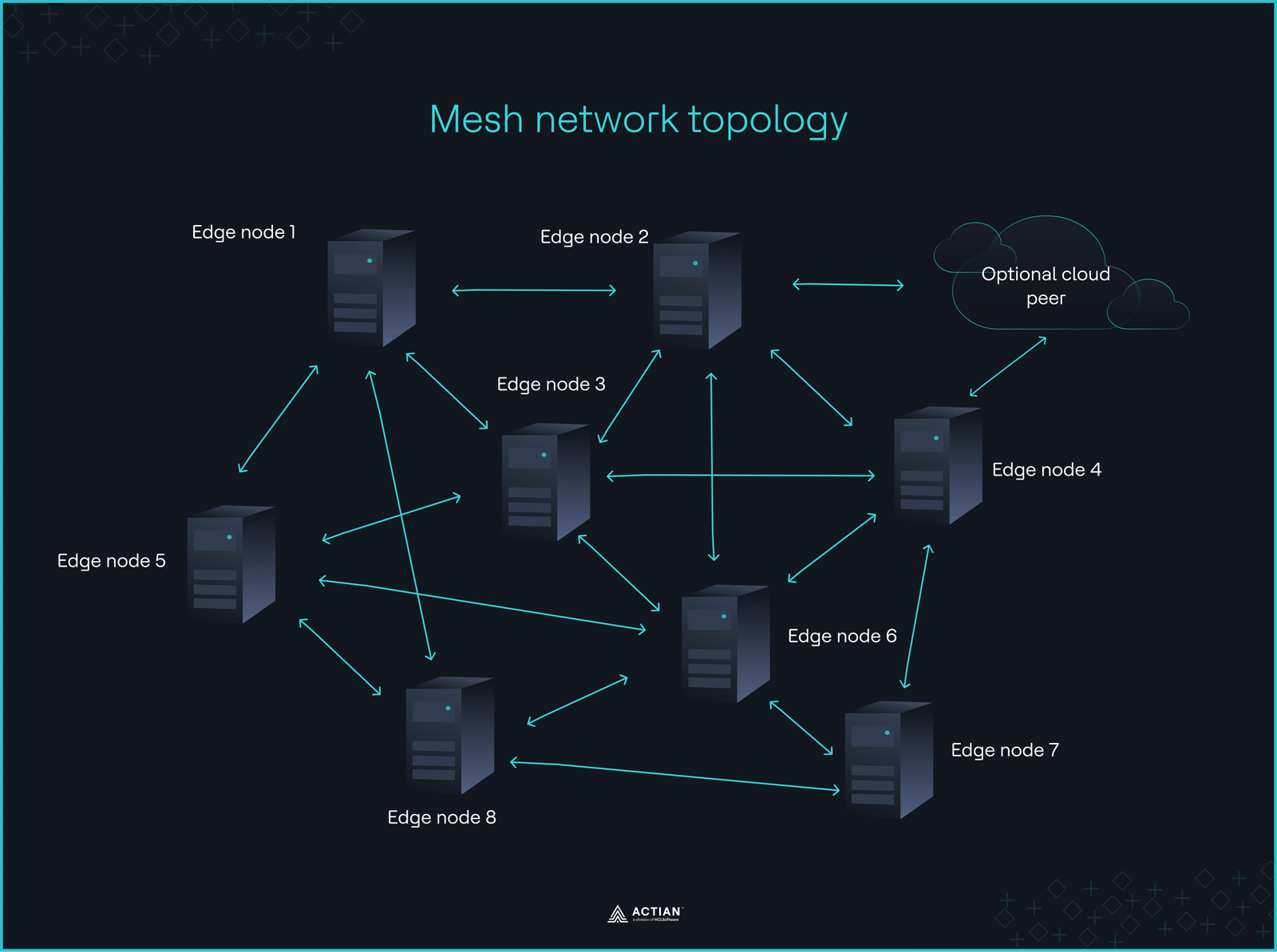
Die Cloud wird Cloud als Peer für die optionale Synchronisierung eingebunden, während die eigentliche Rechenleistung weiterhin im Netzwerk verbleibt und ohne zentrale Steuerung erfolgt.
Intelligente Stromnetze eignen sich hervorragend für diese Architektur, bei der die Fernschutztechnik eine Latenz von 10 bis 20 ms erfordert. Ein Netzwerk von Umspannwerken erfasst kontinuierlich den Stromfluss und die Verbrauchsmuster in Echtzeit, um Ungleichgewichte zu erkennen, bevor sie sich verschärfen. Diese Echtzeit-Transparenz ermöglicht eine dynamische Lastumverteilung und ein autonomes Mikronetzmanagement.
use case weiterer use case sind militärische unbemannte Luftfahrzeuge (UAVs). Wenn das GPS in DDIL-Umgebungen ausfällt, leiten UAVs ISR-Daten über Mesh-Netzwerke untereinander weiter. Adaptives Interferenz-Routing gewährleistet einen zuverlässigen Datenfluss, während die Übertragung über Sichtverbindung die Latenzzeit verringert.
Dieses Deployment ist auf Netzwerkredundanz ausgelegt. Das Gossip-Protokoll und verteilte Konsensalgorithmen wie Raft verhindern einzelne Ausfallpunkte. Wenn ein Knoten die Verbindung verliert, bleibt das Netzwerk funktionsfähig und leitet die Daten über andere Knoten weiter.
Das Gossip-Protokoll ermöglicht die Live-Erkennung von Peers durch kontinuierlichen, ressourcenschonenden Informationsaustausch. Jeder Knoten verfügt stets über einen aktuellen Überblick über sein lokales Netzwerk. Raft verfolgt einen Leader-basierten Ansatz, bei dem ein gewählter Leader-Knoten alle Schreibvorgänge abwickelt und die Protokollreplikation sicherstellt, dass die Follower-Knoten einen gemeinsamen Zustand beibehalten. Edge-Datenbanken replizieren Daten über mehrere Knoten hinweg, um Beständigkeit zu verbessern.
Wenn man Gossip und Raft als konkurrierende Optionen betrachtet, übersieht man das Wesentliche. Der Fokus sollte darauf liegen, zu verstehen, wo sich die beiden im CAP-Theorem einordnen und welche Kompromisse sie in einem verteilten Netzwerk mit sich bringen.
Der Zielkonflikt Beständigkeit und Verfügbarkeit
Wenn Netzwerkpartitionen das Mesh aufteilen, gewährleistet Raft Beständigkeit starke Beständigkeit, während Gossip Beständigkeit Verbindung mit Ansätzen wie CRDTs für einen Ausweichmechanismus bei der Verfügbarkeit und für eventuelle Beständigkeit sorgt.
Im Edge-Computing, wo die Verbindungsmöglichkeiten begrenzt sind und es zahlreiche Knoten gibt, ist Partitionstoleranz unabdingbar. Bei der Umsetzung der Netzwerkarchitektur müssen Edge-KI-Systeme entscheiden, ob sie Beständigkeit Verfügbarkeit priorisieren.
Die Verfügbarkeit ist oft optimal, da Edge-Knoten nach einer Unterbrechung weiterhin unabhängig funktionieren. Beständigkeit Designs wie Raft bergen das Risiko von Schreibunterbrechungen und veralteten Lesevorgängen während Netzwerkpartitionen.
| Merkmal | Floß | Klatsch |
| Architektur | Wahl des Leiters und Protokollreplikation | Peer-to-Peer |
| Latenz | Mäßig; erfordert, dass mindestens die Hälfte der Knoten in einem Netzwerk verfügbar ist | Niedrig; Nachrichten werden schnell übertragen, doch Ausbreitungsrunden können die Geschwindigkeit verringern |
| Beständigkeit | Hohe Beständigkeit | Endgültige Beständigkeit |
| Partitionstoleranz | Mäßig; übersteht eine Partitionierung möglicherweise nicht | Hoch; Partitionen werden schneller repariert |
Speed and data delivery trade-offs are another critical constraint of the network architecture. Mesh networking adds latency with each hop as the node count increases. If your system needs data back in <50ms or your latency requirements can tolerate >100ms, this trade-off should shape your design decision.
Die Wahl des richtigen Deployment für Edge-KI
Es gibt kein spezifisches „richtiges“ Deployment Edge-KI in netzwerkunabhängigen Umgebungen. Eine solide Architekturumsetzung beginnt mit einem klaren Verständnis der spezifischen Einschränkungen, Ziele und Merkmale Ihrer Zielanwendung. Das bedeutet, den gesamten Workload zu berücksichtigen, einschließlich des Konnektivitätsprofils, Rechenressourcen verfügbaren Rechenressourcen und der Latenzanforderungen.
1. Die Netzwerkstabilität prüfen
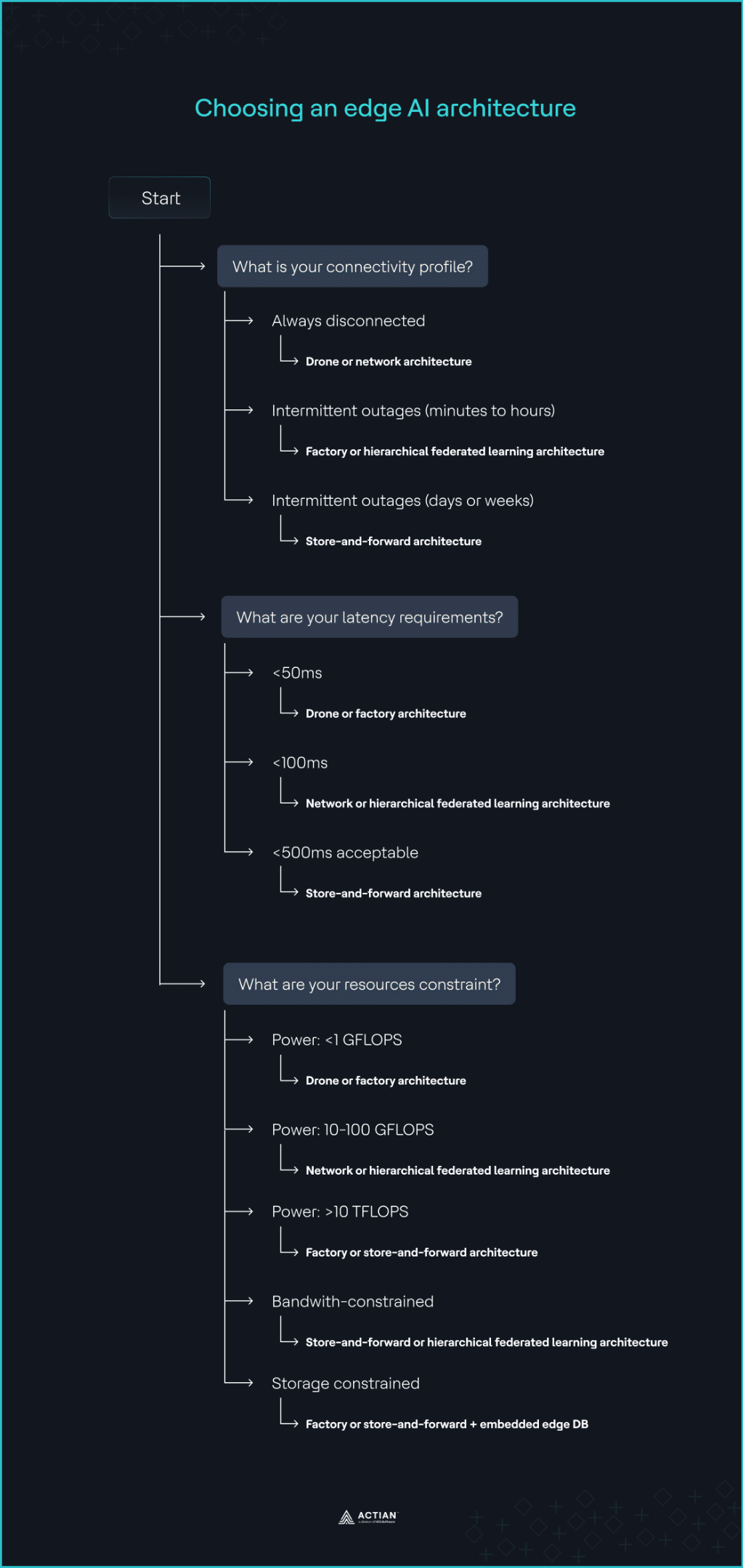
Die Netzwerkstabilität ist der wichtigste Faktor bei jeder Deployment Edge-KI. Legen Sie fest, wie viel Ausfallsicherheit in die Edge-Knoten integriert werden muss, und zwar auf der Grundlage der zu erwartenden Dauer der Unterbrechung.
- Falls das System ständig vom Netz getrennt ist: Verwenden Sie Drohnen- oder Netzwerkarchitekturen, da diese so konzipiert sind, dass sie unabhängig vom Verbindungsstatus vollständig offline funktionieren.
- Falls die Unterbrechung nur wenige Minuten oder Stunden andauert: Nutzen Sie die Factory- oder HFL-Architektur, um die Datenaggregation und -auswertung ohne Unterbrechung fortzusetzen. Das System bleibt während des Ausfalls funktionsfähig, da alle erforderlichen Abhängigkeiten bereits innerhalb des Betriebsbereichs vorhanden sind.
- Falls die Verbindung nur zeitweise für Tage oder Wochen verfügbar ist: Nutzen Sie die Store-and-Forward-Architektur, um Inferenzergebnisse und Betriebsdaten lokal zwischenzuspeichern, bis das geplante Verbindungsfenster wieder verfügbar ist.
2. Latenzanforderungen ermitteln
Legen Sie die maximal zulässige Latenz für Ihre spezifische Anwendung fest, indem Sie Netzwerk-Hops, die Verfügbarkeit der Knoten und die geografische Nähe der Edge-Knoten berücksichtigen. Die unten aufgeführten Grenzwerte spiegeln typische Deployment wider. Überprüfen Sie diese anhand Ihrer spezifischen Hardware- und Netzwerkbedingungen.
- If the system requires <50ms latency: Use the drone deployment pattern. Its single-node architecture keeps inference directly on sensors, cameras, or gateways, enabling near-real-time responses. Factory architecture also minimizes latency by running on edge servers within the same facility or on the factory floor.
- If the system requires <100ms latency: Use the network or HFL architecture to distribute model improvement workloads across multiple nodes.
- If <500ms latency is acceptable: Use store-and-forward architecture for non-critical IoT data that requires batch processing or long-term analytics. It batch-offloads data-intensive tasks to the cloud.
3. Ressourcenengpässe bewerten
Edge-AI-Anwendungen unterscheiden sich hinsichtlich Rechenleistung, Speicherbedarf und Bandbreitenverbrauch, was sich auf die Inferenzgeschwindigkeit, die Datenaggregation und Echtzeitanalysen auswirkt. Bewerten Sie jede Ressourcenbeschränkung separat:
- Power constraint: For compute power <1 GFLOPS, common in microcontrollers used for sensor inference, the drone architecture is most suitable. It runs on constrained IoT devices using lightweight, inference-only models. At 10–100 GFLOPS, common in edge gateways, HFL and network architectures become more effective as they handle data aggregation needs well at this level. For edge GPU clusters that scale to >10 TFLOPS, factory and store-and-forward architecture support clustered inference pipelines, since they run on-premises.
- Bandbreitenbeschränkung: Verwenden Sie eine Store-and-Forward-Architektur oder HFL, um große Mengen an Rohdaten am Netzwerkrand zu speichern und zu verarbeiten, und leiten Sie Cloud Bedarf nur zusammengefasste Aktualisierungen an die Cloud weiter.
- Einschränkung bei der Datenspeicherung: Verwenden Sie Factory- oder Store-and-Forward-Architekturen in Verbindung mit eingebettet , um Zeitreihendaten lokal zu speichern und die Kapazität innerhalb der Anlage vertikal zu skalieren. Datenbanken wie Actian Zen sind für Edge-AI-Anwendungsfälle optimiert und können zudem mit der Cloud synchronisiert werden, Cloud die Verbindung wiederhergestellt ist.
4. Ziehen Sie einen hybriden Ansatz in Betracht
Industriesysteme vereinen häufig die Stärken mehrerer Architekturen in einem abgestimmten System, das Ausfallsicherheit und Flexibilität bietet. Die Bergbaubetriebe von Rio Tinto veranschaulichen, wie Deployment hybrider Deployment in großem Maßstab Deployment .
In der Eisenerzmine Greater Nammuldi sind mehr als 50 autonome Lkw auf vordefinierten Routen im Einsatz, die mithilfe von Bordsensoren Hindernisse erkennen – ein Beispiel für die Drohnenarchitektur. An 17 Standorten in Westaustralien übermitteln diese Lkw Betriebsdaten an das Betriebszentrum von Rio Tinto in Perth, was die Netzwerkarchitektur widerspiegelt. Schließlich transportiert ein autonomes Schienensystem das geförderte Erz und synchronisiert sich bei Erreichen der Hafenanlagen mit dem Betriebszentrum. Dies entspricht der Store-and-Forward-Architektur.
Rio Tinto zeigt, dass sich Deployment nicht gegenseitig ausschließen. Wenn Ihr use case mehrere Architekturen use case , sollten Sie in Erwägung ziehen, diese auf der Systemebene auszuführen, auf der sie am besten geeignet sind, anstatt eine einzige Architektur für den gesamten Betrieb vorzuschreiben.
Die folgende Tabelle ordnet bestimmte Deployment ihrem optimalen Deployment Offline-Edge-KI zu, um Ihnen eine Entscheidungsgrundlage zu bieten.
| Deployment | Empfohlenes Muster | Begründung |
| Autonome Inspektionsdrohnen über Ölfeldern oder Offshore-Windparks | Drone (einknotige, eigenständige Lösung) | Eine eigenständige Inferenz-Laufzeitumgebung mit eingebettet Speicher macht verteilte Berechnungen überflüssig, um Hardware-Einschränkungen zu umgehen |
| Montagelinien in der Automobilindustrie, auf denen Fehlererkennungsmodelle zum Einsatz kommen | Fabrik (Edge-KI mit mehreren Knoten) | Da Cloud für die Anforderungen an die Verfügbarkeit zu riskant ist, werden Edge-Cluster innerhalb der Einrichtung betrieben |
| Krankenhausverbünde, in denen Patientendaten gemäß HIPAA die einzelnen Einrichtungen nicht verlassen dürfen | Hierarchisches föderiertes Lernen | Die Modelle trainieren , wobei lediglich die aktualisierten Gewichte in die Cloud übertragen werden, sodass die Rohdaten gemäß den Anforderungen an Datenhoheit und Datenschutz vor Ort verbleiben |
| Frachtschiffe auf See synchronisieren ihre Betriebsdaten im Hafen | Speichern und Weiterleiten | Ein lokaler Puffer stellt sicher, dass bei Verbindungsunterbrechungen, die mehrere Tage andauern können, keine Inferenzergebnisse oder Betriebsereignisse verloren gehen |
| Intelligentes Verkehrsmanagement in Städten über verteilte Kreuzungen hinweg ohne Abhängigkeit von einem zentralen Server | Netzwerk (verteilte Edge-to-Edge-Struktur) | Die Knoten kommunizieren im Peer-to-Peer-Verfahren auf Konsensbasis, sodass der Ausfall eines Knotens zwar die Kapazität verringert, den Gesamtbetrieb des Netzwerks jedoch nicht beeinträchtigt |
Die Quintessenz
Branchen, die in abgelegenen, unterirdischen, maritimen und geografisch verstreuten Gebieten tätig sind, benötigen Edge-native Architekturen, die Real-Time-Insights liefern Real-Time-Insights den Betrieb kritischer Anlagen ohne Cloud gewährleisten.
Die hier behandelten Deployment legen den Schwerpunkt auf das, was in netzwerkunabhängigen Umgebungen am wichtigsten ist: lokale Inferenz, keine Latenz durch Zentralisierung, geringere Kommunikationskosten und Systemautonomie.
Bevor Sie sich für ein Modell entscheiden, sollten Sie in Ihrer eigenen Umgebung drei Punkte überprüfen: Wie lange kann Ihr System einen Netzwerkausfall verkraften, bevor der Datenverlust betriebliche Auswirkungen hat? Kann Ihre Edge-Hardware die Rechenanforderungen der von Ihnen gewählten Architektur bewältigen, ohne dass die Qualität der Inferenz beeinträchtigt wird? Und verfügt Ihr Team über die erforderlichen Werkzeuge, um verwalten am Edge ohne Cloud verwalten ? Setzen Sie Ihre Einschränkungen in Beziehung zum Framework .
Die richtige Antwort ist möglicherweise nicht ein einziges Modell. Setzen Sie hybride Ansätze nur dann ein, wenn die damit verbundenen Vorteile für die Ausfallsicherheit den betrieblichen Aufwand rechtfertigen.
Jedes Modell ist auf eine Dateninfrastruktur angewiesen, die vollständig am Edge betrieben, gespeichert und synchronisiert werden kann. Für Teams, die über strukturierte Speicherung hinausgehen und semantische Suchvorgänge an ihren lokalen Daten durchführen möchten, ohne Vektor-Einbettungen auf einen Cloud zu exportieren, ist die Actian VectorAI DB für diesen use case optimiert. Tragen Sie sich in die Warteliste ein, um frühzeitig Zugang zu erhalten.
Treten Sie der Actian-Community auf Discord und tauschen Sie sich mit Ingenieuren, die in netzwerkunabhängigen Umgebungen arbeiten, über Architekturmuster für Edge-KI aus.

Bleiben Sie in Verbindung
Datenanalysen, die Ihnen geliefert werden.
(z. B. sales@..., support@...)