What’s New in Actian DataFlow Version 6.6.1?




Actian DataFlow is a parallel workflow platform for end-to-end data access, transformation, preparation, and predictive analysis that eliminates performance bottlenecks in your data-intensive applications. Complimentary to the Actian Analytic Engine, DataFlow leverages concurrency, parallelism, and pipelining to accelerate data movement between locations in your data architecture, creating faster results. DataFlow eliminates memory constraints, as well as the need for data movement into specific data stores before analytics are run. DataFlow understands the available resources before breaking up the execution into smaller chunks that can be run in parallel to take maximum advantage of horizontal and vertical scaling.
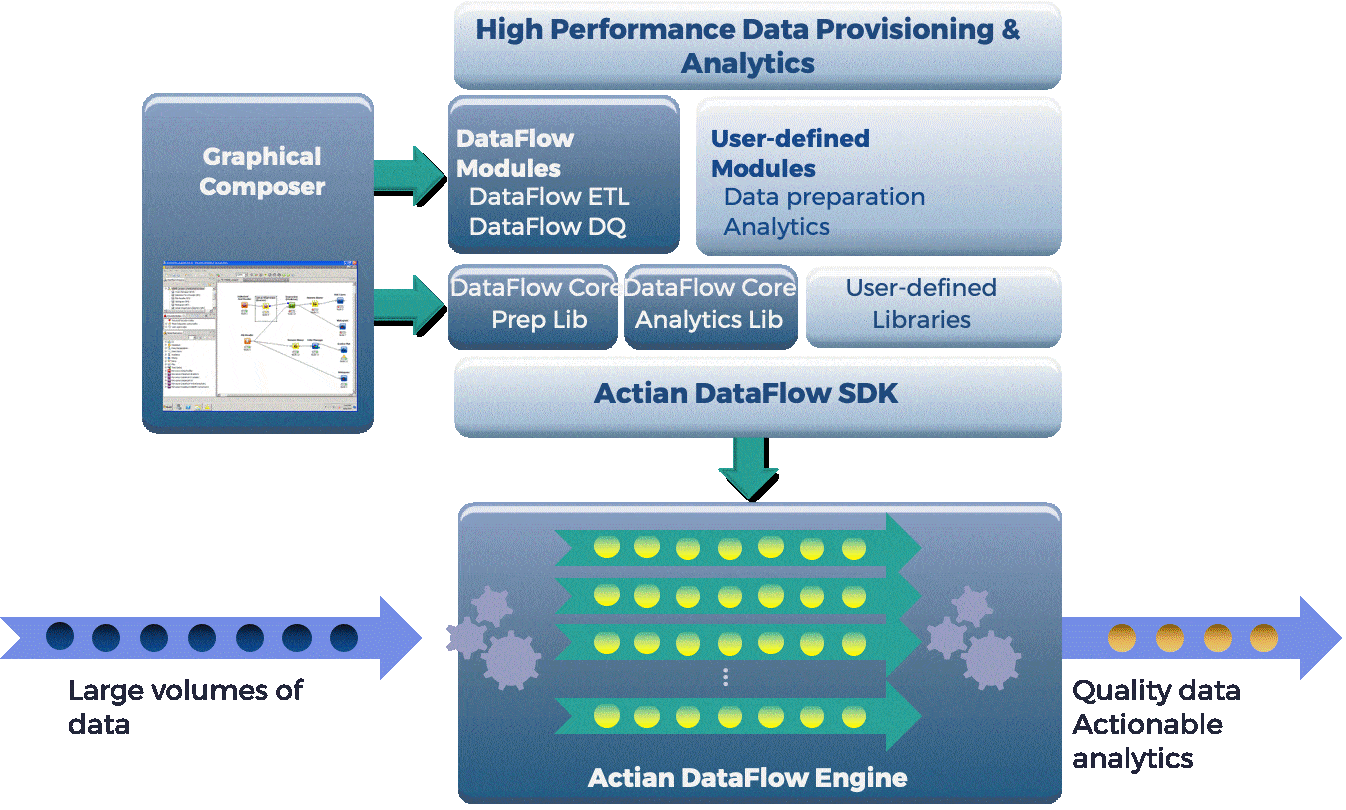
DataFlow combines the KNIME (open source data mining platform) drag-and-drop visual workflow environment with the underlying Actian DataFlow platform to provide greater control over the entire process of reading the data, performing the transformation and analytic functions, and writing the results.
What’s new in version 6.6.1?
This update to DataFlow certifies new releases of the most popular Hadoop distributions from Apache, Cloudera, Hortonworks, and MapR, as well as improves parallel load features with the most recent releases of Vector for Linux, Windows, and Hadoop. There is also support for five new data types with DataFlow to handle a larger variety of data formats. Here is the specific list:
- Added support for Apache Hadoop 3.0.1+.
- Added support for MapR 6.0.1.
- Verified Support for MapR 5.2.2.
- Updated support for Hortonworks HDP 2.6.
- Updated support for Cloudera CDH 5.15.
- Updated direct vector loader to work with latest Vector & VectorH (5.0 & 5.1).*
- Added support for 5 new base types: Money, ip4, ip6, uuid, and Intervals (Periods and Durations).
- Added support for latest AWS authentication library (1.11 previously 1.3).
- Added support for logical paths in Hadoop.
*Actian Vector was renamed to Actian Analytics Engine in 2026.
DataFlow Results:
For data preparation, data onboarding, and ETL use cases, DataFlow can accelerate the process by factors of 20X or more. For one customer who previously required 17 hours to prepare and cleanse data to onboard new customers, DataFlow reduced the time to 43 minutes, almost 24 times faster. Another customer used DataFlow to parallelize and pipeline their data transfer process to reduce their claims processing times from more than 30 hours to just 20 minutes, which is 90 times faster. In a third example DataFlow demonstrated that it could load 500,000 records into an Oracle database in seven seconds, versus a previous runtime of more than 3 minutes. Contact [email protected] if you are interested in seeing a demonstration.
Stay connected
Data insights delivered to you.
(i.e. sales@..., support@...)