The Hidden Cost of Vector Database Pricing Models





Summary
- Vector DB “usage-based” pricing now includes monthly minimums, turning steady workloads into sudden cost jumps.
- Hidden costs—embeddings, reranking, backups, reindexing, and egress—can double real production spend.
- Query costs often scale with index size, so the same search can cost 10x more as data grows from 10GB to 100GB.
- At high, predictable query volume, self-hosting can cut costs 50–75% and improve spend predictability.
- Choose pricing models early—billing mechanics should influence architecture, not surprise you after launch.
For a long time, usage-based pricing seemed like the safest way to run new infrastructure. The appeal was to start small, pay very little, and let costs rise only if the product proved itself. For teams experimenting with semantic search or early retrieval systems, that trade-off made sense, particularly when fixed infrastructure commitments felt riskier than uncertain usage patterns.
That sense of safety began to fade in 2025 as several vector database providers introduced pricing floors and minimums. Pinecone announced a $50/month minimum, Weaviate implemented a $25/month floor, and similar changes rippled across the managed vector database market.
Small, steady workloads suddenly experienced step changes in cost without any corresponding increase in activity, a pattern that reflected a broader shift across the SaaS landscape. Always-on vector database infrastructure no longer fits the economics of single-digit monthly pricing. SaaS subscription costs from several large vendors rose between 10% and 20% in 2025, outpacing IT budget growth projections of 2.8%, according to Gartner.
Today, vector databases power production systems at scale. They run semantic search, recommendations, copilots, and internal knowledge tools. Data volumes stay relatively stable, and traffic patterns follow predictable curves. Yet for many organizations, vector search infrastructure has become one of the most volatile cost centers in the stack. Not because usage swings wildly, but because vector database pricing models behave differently once systems mature.
TL;DR
- Cloud native vector databases pricing advertises low minimums and usage-based flexibility, but production costs tell a different story.
- Hidden fees (embeddings, reindexing, backups) can double your bill.
- Query costs scale with dataset size, meaning the same query becomes 10x more expensive as you grow from 10GB to 100GB.
- The October 2025 pricing shift introduced $50 minimums, forcing 400–500% cost increases for stable workloads.
- At 60–100M queries/month, self-hosting becomes 50–75% cheaper than cloud.
- Pricing model must be an architectural decision, not an afterthought.
What Pricing Pages Leave Out
Vector database pricing pages prioritize adoption over long-term cost modeling. Their job is to make adoption frictionless, not to walk you through how the bill is calculated after a system is live. Most pages spotlight a familiar set of numbers: storage per gigabyte, read and write units, and a low monthly minimum. Free tiers are marketed as enough to get started, which makes experimentation feel low-risk.
What these pages rarely explain is how those line items interact once usage stabilizes. They typically don’t model how query costs change as datasets grow, how write activity accumulates over time, or how meaningful parts of the workflow sit entirely outside the database. Pinecone’s pricing examples exclude initial data import, inference for embeddings and reranking, and assistant usage. Weaviate’s pricing calculator similarly omits backup costs and data egress fees. Qdrant’s estimates don’t account for reindexing overhead. The same vendors that dominate every comparison list now face questions about their pricing sustainability. These disclaimers are present but easy to skim past when you’re focused on shipping a proof of concept.
A predictable pattern repeats itself. Someone runs the calculator and sets a monthly budget. The system goes live. A few weeks later, the bill is two to four times higher than expected. Nothing broke, no traffic spike happened. The database is doing exactly what it was built to do. The pricing page simply didn’t describe the total cost of operating it.
How Usage-Based Pricing Works (And Why it Gets Expensive)
Usage-based pricing reduces risk during experimentation when traffic is unknown. The issue is that vector databases in production are rarely unpredictable.
Once a system is live, most engineering groups have a reasonable understanding of data size and baseline query volume. What they lack is a reliable way to predict next month’s bill, because managed vector databases charge across several dimensions simultaneously: storage, writes, and queries.
Each cost grows on its own curve, and none maps cleanly to user value. The part that catches development teams off guard is query pricing. In many models, query cost rises as the dataset grows, even when the query itself stays the same.
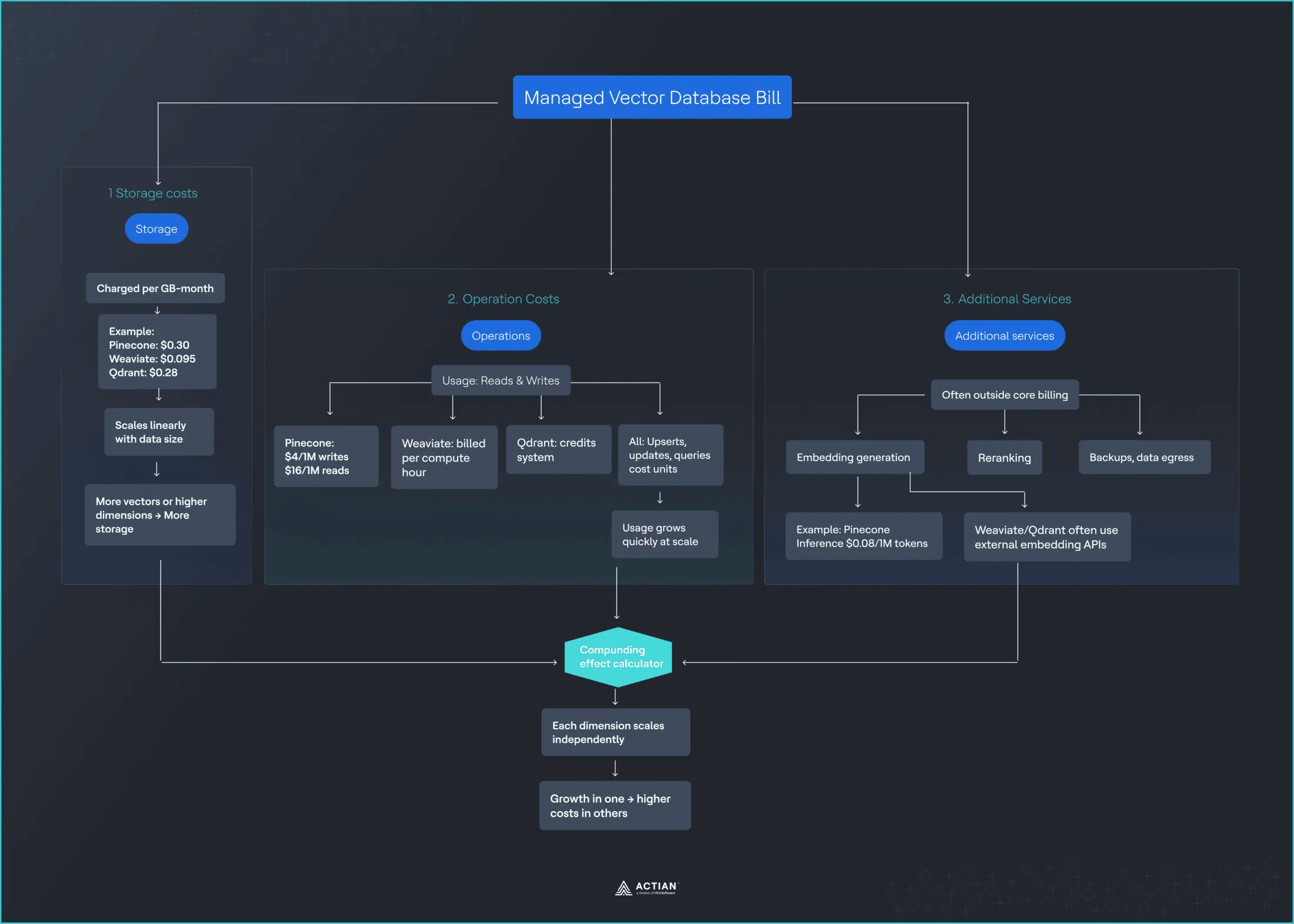
The Three Cost Drivers You’re Actually Paying For
Managed vector databases bill across three primary dimensions, though the exact rates vary by provider:
Storage
- Pinecone: $0.30/GB/month.
- Weaviate: $0.095/GB/month.
- Qdrant: $0.28/GB/month.
- Scales linearly as your dataset grows.
- More vector dimensions = larger bill.
Operations
- Pinecone: Write units ($4/million), Read units ($16/million).
- Weaviate: Per compute unit hour (variable).
- Qdrant: Credit-based system.
- Every upsert, update, and query consumes units.
- Vector search operations accumulate quickly at scale.
Additional services
- Embedding generation: Pinecone Inference ($0.08/million tokens).
- Weaviate/Qdrant: Require external services (OpenAI, Cohere).
- Reranking, backups, data transfer are billed separately.
- Adds another vendor relationship and cost stream.
Each cost dimension scales independently, and their interaction creates compounding effects that pricing calculators rarely capture. Understanding why these costs compound requires looking at how vector search actually works, specifically HNSW indexing.
Why Costs Compound as You Scale
The cost increases stem directly from how vector search works under the hood.
How HNSW works
Most production vector databases use approximate nearest neighbor (ANN) algorithms like HNSW (Hierarchical Navigable Small World) to make searches tractable at scale.
HNSW constructs a multi-layer graph in which each layer represents vectors at different levels of granularity, thereby organizing millions of vector dimensions into an efficient structure.
The cost impact
Pinecone’s documentation indicates that a query consumes 1 RU per 1 GB of namespace size, with a minimum of 0.25 RUs per query. As your dataset grows, so does the graph:
| Dataset size | RU per query | Cost at $16/M RU | Same query, different cost |
|---|---|---|---|
| 10 GB | 10 RU | $0.00016 | Baseline |
| 100 GB | 100 RU | $0.0016 | 10x more expensive |
| 1 TB | 1,000 RU | $0.016 | 100x more expensive |
Result: Ten times the cost, for the same query, delivering the same result quality.
At $16 per million read units, costs scale linearly with data growth, but the functionality delivered to users stays the same. A search query returns the same number of results with the same accuracy whether your index is 10 GB or 100 GB. Your users see no difference, but you pay 10x more. This is the moment growth starts to feel like a penalty. The graph structure needs to traverse more vector dimensions as your index expands, and you pay for every additional operation.
The Free Tier That isn’t Really Free
The free tier enables early experimentation but doesn’t predict production economics. By the time you hit the limits, switching costs are no longer theoretical. Migration is perceived as expensive, and people accept pricing they would have questioned earlier.
| Provider | Free tier limits | Production reality | Time to exceed |
|---|---|---|---|
| Pinecone | 2 GB, 1M reads, 2M writes (single region) | 60+ GB, 5M+ reads typical | 2–4 weeks |
| Weaviate | 1M vectors, limited compute | 10M+ vectors standard | 1–3 weeks |
| Qdrant | 1 GB storage | 60+ GB storage common | 1–2 weeks |
The October 2025 Pricing Shift That Changed Everything
These structural issues became impossible to ignore when Pinecone made a significant pricing change. By late 2025, pricing changes across major vector database providers made it clear that the pay-as-you-go (PAYG) model did not always hold once systems reached steady production. The most visible signal came in October, when Pinecone implemented a $50 monthly minimum across paid Standard plans.
For organizations already spending well above that level, the change barely registered. For smaller but stable workloads, the situation was different. Some groups had intentionally designed their usage to stay under $10 per month.
These weren’t abandoned projects, but internal tools, early production features, and low-volume customer-facing systems that had already stabilized. Usage remained flat, but in some cases the introduction of pricing minimums led to five- to tenfold increases in monthly costs.
What made the moment important was not the dollar amount. It was the introduction of a fixed floor into a model marketed as consumption-based. Low usage no longer guaranteed low cost. Once that assumption broke, minimums stopped feeling like an edge case and started looking like structural risk.
| Previous monthly cost | New minimum | Increase |
|---|---|---|
| $8 | $50 | 525% |
| $12 | $50 | 317% |
| $25 | $50 | 100% |
The Migration it Forced
For anyone below the new $50 minimum, migration was rarely planned. It was reactive. Platform owners had to evaluate alternatives, export data, rebuild indexes, and validate query behavior under time pressure. In some cases, the engineering effort required to migrate exceeded the annual savings from switching providers. Many still moved anyway, because the alternative was committing to pricing that no longer matched the workload.
The impact of the pricing change became visible across developer communities. One developer documented their migration experience publicly, noting they had managed to keep bills under $10 per month by storing only essential data in the vector database. The September 2025 announcement requiring a $50 monthly minimum regardless of actual usage prompted an immediate search for alternatives.
The migration calculus proved challenging. Moving to Chroma Cloud became the chosen path, but the process revealed deeper concerns about serverless pricing models. As the developer noted, they were seeking a truly serverless solution in which costs scale linearly with usage, starting at $0. The $50 minimum eliminated that possibility.
This pattern repeated across Reddit threads and developer forums. A discussion thread titled “Pinecone’s new $50/mo minimum just nuked my hobby project” captured the broader sentiment. Teams running stable, low-volume production workloads faced a choice: accept a 400–500% cost increase or invest engineering time in migration.
The issue wasn’t the absolute dollar amount. For many teams, $50 per month remained affordable. The problem was precedent. If a vendor could introduce a minimum that quintupled costs without warning, what prevented future increases? The pricing change transformed vendor selection from a technical decision into a risk management calculation.
A few patterns showed up repeatedly across these migrations. Pricing predictability started to matter more than managed convenience. Open source and self-hosted options re-entered discussions that had previously defaulted to cloud. Vendor pricing risk became a first-class architectural concern. These migrations were not driven by dissatisfaction with features or performance. They were driven by economics.
What it Reveals About Vendor Pricing Power
Once a vector database is deployed in production, vendors can adjust pricing in ways that materially affect customers, even if usage remains unchanged.
Usage-based pricing lowers the barrier to adoption, but it increases switching costs over time as APIs become embedded, data formats solidify, and migrations grow expensive.
For engineering leadership, the evaluation question shifts:
- Was: “What does this cost today?”
- Became: “How exposed are we to pricing changes once this is in production?”
Real-World Cost Scenarios (What You’ll Actually Pay)
Understanding these dynamics in the abstract is one thing. Seeing how they play out in actual production systems is another.
To see the full picture, let’s examine three common production scenarios and compare costs across major providers.
Scenario 1: Customer support RAG system
Imagine a customer support assistant built on historical tickets, internal documentation, and help articles. At this stage, you might be dealing with about 10 million vectors (typically 768 or 1536 vector dimensions) and around five million queries per month.
| Previous monthly cost | New minimum | Increase |
|---|---|---|
| $8 | $50 | 525% |
| $12 | $50 | 317% |
| $25 | $50 | 100% |
Key finding: Even at small scale, actual costs are 3–5x higher than base calculator estimates due to minimums and complex pricing structures.
Scenario 2: E-commerce recommendation engine
As systems grow, the cost dynamics become more pronounced. With around 100 million vectors and tens of millions of queries per month, costs climb quickly. Product catalogs, user vector embeddings, and real-time personalization introduce sustained traffic and frequent updates.
| Provider | Storage | Queries | Writes | Embeddings | Overhead | Total |
|---|---|---|---|---|---|---|
| Pinecone | $180 | $192 | $8 | $200–300 | $50–80 | $1,500–2,500 |
| Weaviate | $57 | Compute: $800–1,000 | Included | $200–300 | $40–60 | $1,400–2,200 |
| Qdrant | $168 | Credits: $600–900 | Included | $200–300 | $40–60 | $1,300–2,100 |
Key finding: At mid-scale, costs converge across providers. Embedding fees often exceed base database costs.
Scenario 3: Multi-tenant SaaS platform
The economics shift dramatically at the enterprise scale. At 500 million vectors and 100 million queries per month, usage-based pricing becomes structural. These large datasets contain high-dimensional vector embeddings across many customers.
| Provider | Storage | Queries | Writes | Embeddings | Support | Total |
|---|---|---|---|---|---|---|
| Pinecone | $921 | $1,200 | $100–150 | $500–700 | $300–500 | $2,500–4,000+ |
| Weaviate | $292 | Compute: $2,000–3,000 | Included | $500–800 | $200–400 | $3,000–4,500 |
| Qdrant | $860 | Credits: $1,500–2,200 | Included | $500–800 | $200–400 | $2,900–4,200 |
Key finding: At enterprise scale, annual costs reach $30,000–$54,000. This is where self-hosting economics become compelling.
Side-by-Side Provider Comparison
To make the economics clearer, here’s how the major vector database providers stack up across the dimensions that matter most for production deployments:
| Feature | Pinecone | Weaviate | Qdrant | PostgreSQL + pgvector |
|---|---|---|---|---|
| Pricing model | Usage-based | Usage-based | Usage-based | Self-hosted (fixed) |
| Monthly minimum | $50 | $25 | None | None |
| Storage cost | $0.30/GB | $0.095/GB | $0.28/GB | Hardware cost only |
| Query pricing | Scales with data | Compute-based | Credit-based | Free within capacity |
| Additional cost | Many | Moderate | Some | None |
| Cost predictability | Low | Low-Medium | Medium | High |
| Scenario 1 cost | $350–500 | $300–400 | $280–380 | ~$200–300 |
| Scenario 2 cost | $1,500–2,500 | $1,400–2,200 | $1,300–2,100 | ~$800–1,200 |
| Scenario 3 cost | $2,500–4,000+ | $3,000–4,500 | $2,900–4,200 | ~$1,500–2,000 |
| Best for | Fast prototyping | Hybrid search | K8s-native teams | Stable, high-volume |
The Hidden Fees That aren’t in the Calculator
These scenarios reveal a consistent pattern: the advertised pricing rarely captures the full cost. Production vector search systems incur costs that are rarely modeled comprehensively by calculators. Understanding these hidden costs is crucial for accurate budgeting.
Embedding and inference fees
Pinecone Inference charges $0.08 per million tokens for generating vector embeddings. Weaviate and Qdrant don’t provide native embedding services, requiring you to use external providers like OpenAI (starting at $0.10 per million tokens) or Cohere.
Converting documents to vectors costs extra beyond database operations across all platforms. Reranking adds additional per-request fees. Cohere-rerank-v3.5 has no free requests on any tier, meaning every reranking operation is billed.
These embedding and inference costs can match or exceed the database bill itself, depending on data churn and query patterns. Every time you generate new vector embeddings or update existing ones, you’re paying separately from your core vector storage costs.
Reindexing costs (the silent killer)
The cost impact becomes especially severe when you need to change your approach. When you change embedding models, you must re-vectorize all data. For a 100-million-vector dataset, this could mean:
- Embedding costs: $8,000–$15,000 one-time.
- Increased write units during migration.
- Processing time and compute overhead.
Experimentation with models becomes prohibitively expensive, creating lock-in to initial embedding choices. The cost of generating vector embeddings at scale makes it risky to improve your system.
The support tax
Support tiers add meaningful costs across all managed providers. Pinecone’s support tiers run from free community forums to $499/month for 24/7 coverage. Weaviate charges $500/month for its Professional support tier. Qdrant’s enterprise support starts at similar levels.
| Tier | Pinecone | Weaviate | Qdrant |
|---|---|---|---|
| Free | Community only | Community only | Community only |
| Developer | $29/month | N/A | N/A |
| Pro/Enterprise | $499/month | $500/month | Custom |
Geographic distribution costs
Multi-region deployment for latency optimization adds data transfer costs, regional infrastructure overhead, and can increase base costs by 30–50% depending on configuration. Running vector search across multiple cloud provider regions compounds these expenses.
When Self-Hosting Becomes 75% Cheaper
Given these hidden costs and pricing volatility, many teams eventually reach a crossroads. There is a point where vector database pricing stops being a convenience question and becomes an economic one. That point usually arrives earlier than many people expect.
Timescale benchmarks show that PostgreSQL + pgvector is 75% cheaper than Pinecone, while also delivering 28x faster P95 latency compared to Pinecone’s storage-optimized tier. The tipping point at which self-hosting becomes materially cheaper typically occurs between 60 and 100 million queries per month.
The cost crossover point
- Below 10M queries/month:
- 10M–60M queries/month:
- 60M–100M+ queries/month: Self-hosting becomes 50–75% cheaper. At this volume, the math becomes hard to ignore.
What self-hosting actually costs
- Server: $400–$800/month.
- Setup: About 40 hours initial effort ($4,000–$8,000 one-time).
- Ongoing maintenance: 10–15 hours/month ($1,500–$2,250/month in engineering time).
- Monitoring stack: $50–$200/month.
- Backup storage: $100–$300/month.
Total: About $2,050–$3,550/month versus Pinecone $5,000–$10,000+ at enterprise scale.
Net savings: $2,950–$6,450/month = $35,000–$77,000/year.
The math gets more compelling as you scale. With large datasets containing hundreds of millions of vector dimensions, the gap widens substantially.
Performance advantages beyond cost
The economic case is strong, but performance matters too. Timescale benchmarks demonstrate that PostgreSQL with pgvector achieves a P95 latency 28x lower than Pinecone’s storage tier: 63ms versus 1,763ms. Additionally, PostgreSQL achieves 16x higher query throughput at 99% recall.
Beyond performance, self-hosting provides:
- Control: Tune for your specific workload and vector dimensions.
- No throttling or rate limits.
- Data sovereignty and compliance benefits.
- Predictable scaling where costs are tied to capacity, not usage.
- Hybrid search flexibility to combine vector search with traditional queries.
The Hidden Cost of Free and Serverless
Free tiers and serverless pricing are designed to feel safe. They lower friction, reduce upfront commitment, and make it easy to start building. In practice, they often delay cost visibility rather than eliminate it.
Serverless does not mean infrastructure is free. It means infrastructure is abstracted and billed indirectly through usage. For steady workloads, that abstraction usually comes at a premium. Every query, every stored vector, every embedding refresh, and every background operation is metered. Over time, convenience replaces predictability.
Free tiers follow a similar pattern. They are useful for experimentation, but they are not representative of production economics. By the time limits are reached, integration work is already done, APIs are embedded, and migration feels expensive. At that point, teams tend to accept pricing they would have challenged earlier.
A Practical Way to Choose
Once pricing volatility appears, the question is no longer which database is cheapest today. It becomes clear which pricing model still works once the system stabilizes.
Three factors matter most:
- Scale: How many vectors you store, how many queries you run per month, and how quickly those numbers grow.
- Predictability: Whether usage is bursty and uncertain, or steady and forecastable over the next six to twelve months.
- Control: How much operational responsibility your team can realistically take on, and how sensitive the business is to budget variance.
Early on, managed cloud services usually make sense. They optimize for speed, experimentation, and unknown demand. As workloads stabilize and query volumes climb into the tens of millions per month, usage-based pricing begins to lose its advantage. Costs rise faster than value, and forecasting becomes harder, not easier.
Beyond roughly 60–100 million queries per month, many teams reach a crossover point. At that scale, self-hosted or on-premises deployments are often materially cheaper and far more predictable, even after accounting for infrastructure and operational overhead.
When Each Option Fits
Cloud-managed services work best when:
- Traffic is unpredictable or highly bursty.
- Speed of iteration matters more than long-term cost.
- DevOps capacity is limited.
- Workloads are still exploratory.
Self-hosted or on-premises deployments make sense when:
- Query volume is high and stable.
- Cost predictability is a business requirement.
- Budgets must be defended in advance.
- Compliance or data residency matters.
- Performance targets are tight.
The right choice depends on matching your pricing model to your actual production behavior.
Decision Triggers That Help
Instead of debating architecture continuously, many teams define clear triggers:
- If monthly vector database spend exceeds $1,500, re-evaluate deployment options.
- If query volume exceeds 50 million per month, model total cost of ownership for owned infrastructure.
- If pricing changes exceed 20%, reassess vendor risk.
- If latency targets are consistently missed, evaluate alternatives.
These triggers turn pricing from a surprise into a planned decision point.
The Bottom Line
Vector database pricing looks simple at the start. Free tiers, low minimums, and usage-based billing suggest you only pay for what you use. In production, the economics change. Costs compound across storage, queries, embeddings, and background operations.
The same query gets more expensive as datasets grow, even when it delivers the same value. Predictability disappears at the stage where predictability matters most. For sustained workloads, there is a clear tipping point where ownership becomes cheaper and easier to justify. Teams that avoid bill shock are not the ones who negotiated better discounts; they are the ones who treated pricing as an architectural decision early.
For organizations that value fixed budgets, predictable spend, and long-term control, this is why on-premises vector databases are re-entering serious architectural discussions. Actian’s on-premises vector database, designed around transparent licensing rather than usage-based volatility, reflects that shift.
Do the cost math before you need to migrate. It is always cheaper that way.
Stay connected
Data insights delivered to you.
(i.e. sales@..., support@...)