La gestion des données en vue d'une support décision opportune est un défi. Les données ne cessent de croître et sont fournies dans de multiples formats. Il existe encore de nombreux silos de données qui contiennent des données qui doivent être intégrées. Des tentatives ont été faites pour créer une source unique de vérité pour les données, les informations et les connaissances que l'organisation doit utiliser en collaboration dans l'ensemble de l'organisation. Les premières tentatives sont visibles dans la manière dont les systèmes ERP fonctionnent dans plusieurs domaines fonctionnels d'une organisation. Mais cela n'est pas suffisant en raison de la croissance et de l'utilisation des données par les différents consommateurs de données.
Qu'est-ce que l'architecture Data Hub ?
Les architectures de centres de données sont une collection de données et d'informations provenant de sources multiples et disparates pour des décisions de consommation spécifiques. Les données collectées peuvent résider n'importe où et dans n'importe quel format. Le hub consomme les données nécessaires, ce qui permet d'éliminer le bruit des données et d'améliorer la performance des décisions. Les données sont intégrées et organisées de manière efficace, efficiente et économique afin de support résultats fonctionnels de l'entreprise.
Les hubs de données peuvent consommer des données provenant de diverses sources, telles que des lacs de données. L'architecture du hub de données qui est construite dépend de la compréhension des consommateurs de données et des décisions qui doivent être prises, ainsi que des sources de données elles-mêmes et de la manière dont elles sont liées les unes aux autres pour les besoins de l'entreprise, essentiellement l'support prise de décision dans les unités fonctionnelles.
L'architecture du Data Hub doit prendre en compte la chaîne de valeur entre toutes les fonctions et les transitions de données qui se produisent entre ces fonctions, y compris les activités de décision automatisées sur les données que l'on trouve dans les Fonctionnalitésintelligence artificielle (IA) et d'apprentissage automatique (ML). La valeur finale peut être envisagée dans quatre domaines uniques pour les services et les produits fournis, pris en charge et consommés. Ces quatre domaines sont liés aux décisions en matière d'innovation, de croissance, de satisfaction des besoins des clients et de compétitivité de l'organisation.
Les hubs de données ouvertes permettent de répondre aux différents critères d'accès aux données requis par les différentes personnes au sein de l'organisation. En effet, chaque fonction et chaque rôle consomme les données différemment et parfois de la même manière. Le hub de données ouvertes facilite également l'utilisation d'infrastructures de cloud hybride, la collaboration et l'intégration entre les différentes équipes fonctionnelles. Cela est particulièrement vrai pour la collaboration entre les développeurs, les data scientists et les ingénieurs des données.
Les architectures de hub d'intégration de données permettent de connecter, par le biais du hub de données, plusieurs magasins de données, quel que soit l'endroit où ils se trouvent, par exemple dans le nuage ou sur site. Cela permet de créer des systèmes d'enregistrement spécifiques qui sont nécessaires pour des applications particulières des données.
Types d'architecture de carrefour de données
Les architectures de carrefour de données permettent le partage de données, d'informations et de connaissances en faisant collaborer des producteurs de données spécifiques avec des consommateurs de données spécifiques. Cela doit se faire dans une optique de client ou de consommateur, de sorte que les données collectées profitent au client de ces données. Les architectures de centres de données clients doivent être considérées comme l'approche permettant le cycle de vie des données clients pour une support décision intelligente de l'entreprise. Le centre de données clients doit être considéré comme l'épicentre de la compréhension et de la réponse aux besoins des clients.
Les types d' architectures de concentrateurs de données sont basés sur les modèles de données découverts dont les consommateurs de données ont besoin. L'architecture d'un hub de données peut être différente d'un hub à l'autre en fonction des données d'entrée et des consommateurs de données. Bien qu'elle suive une construction de base telle que le hub et le spoke, chaque architecture peut être très différente dans la manière dont les données sont architecturées pour la consommation. Toutes les sources de données ne sont pas copiées dans le hub, mais seulement ce qui est nécessaire aux décisions des consommateurs.
Architecture en étoile ou en bus Entrepôt de données
L'architecture de données Hub and Spoke est fondamentalement une approche centralisée pour connecter le hub de données à de multiples entrées ou fournisseurs de données pour divers consommateurs de données. Un hub peut être créé avec une architecture Spoke ou Bus. Une architecture Bus est utilisée pour créer un entrepôt de données similaire à un Hub, mais les données n'ont pas de référence standard liée aux consommateurs de données. Les architectures en étoile ont tendance à considérer le hub comme un point central pour les données et constituent donc souvent le point de référence standard. Dans les cas d'utilisation où un contrôle et une gouvernance stricts sont nécessaires, les entreprises ont tendance à utiliser des architectures en rayons plutôt qu'en bus. Le bus peut contenir tous les types de données, mais les applications sont la principale source de données à extraire de l'architecture de l'entrepôt du grand bus. L'architecture Hub and Spoke du Data Hub est explicitement créée pour les consommateurs. Elle est considérée comme plus rapide en raison de la spécificité des données qu'elle contient.
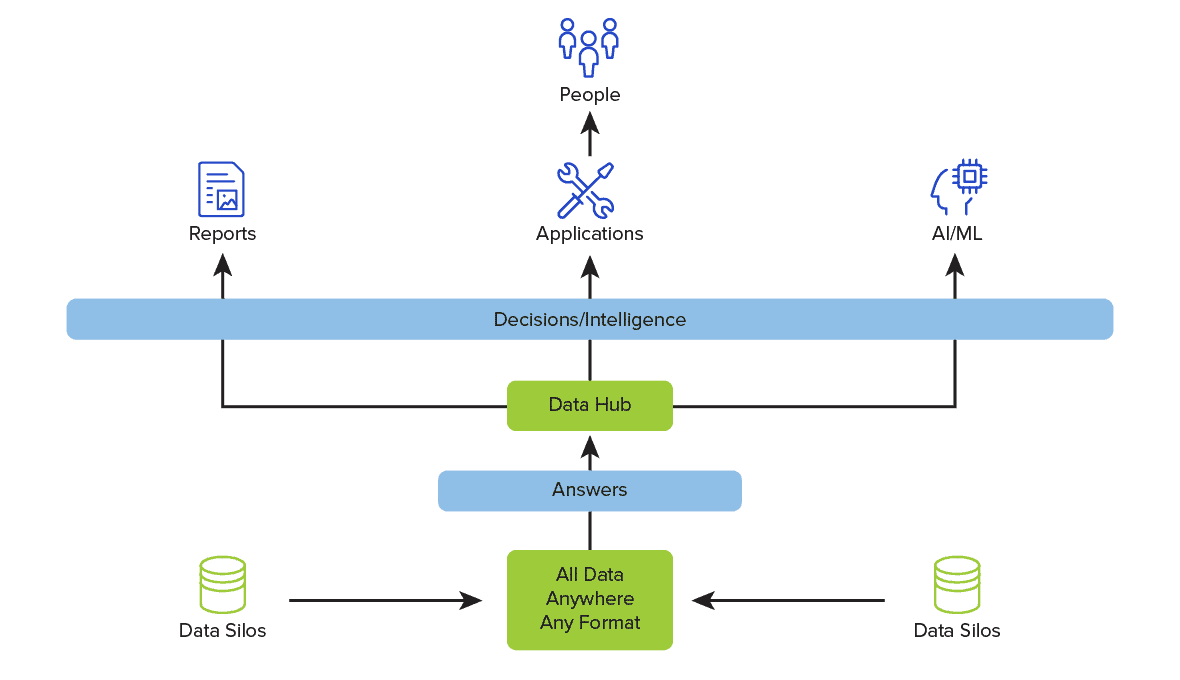
Diagramme de l'architecture du Data Hub
Le diagramme d'architecture du concentrateur de données suivant présente une simple perspective en étoile entre les données et le consommateur de données. L'architecture peut contenir plusieurs concentrateurs de données adaptés aux besoins des consommateurs de données. Cela permet d'améliorer les performances et la compréhension globale de la manière dont les données sont utilisées pour prendre des décisions au sein de l'organisation.
Les entrées du hub de données peuvent provenir d'entrepôts de données, de XML, de JSON, de Sharepoints, d'autres silos de données et de n'importe quel endroit où résident des données. L'élément essentiel à prendre en compte lors de la construction d'un hub de données est la spécificité du choix des données nécessaires à la prise de décision des consommateurs. Dans le cas contraire, une trop grande quantité de données à gérer diminuera les performances et augmentera la complexité.
Les données fournissent des réponses sous la forme de données elles-mêmes ou d'une transformation avec d'autres données en informations et en connaissances pour le consommateur des données. Les consommateurs de données peuvent être des personnes ou des sources automatisées, telles que l'apprentissage automatique et l'intelligence artificielle. Dans les deux cas, l'organisation doit comprendre que l'application d'un hub de données est une initiative d'amélioration continue pour soutenir des résultats commerciaux très performants.
Actian et la plate-forme d'intelligence des données
Actian Data Intelligence Platform est conçue pour aider les entreprises à unifier, gérer et comprendre leurs données dans des environnements hybrides. Elle rassemble la gestion des métadonnées , la gouvernance, le lignage, le contrôle de la qualité et l'automatisation en une seule plateforme. Les équipes peuvent ainsi savoir d'où viennent les données, comment elles sont utilisées et si elles répondent aux exigences internes et externes.
Grâce à son interface centralisée, Actian offre une insight en temps réel des structures et des flux de données, ce qui facilite l'application des politiques, la résolution des problèmes et la collaboration entre les services. La plateforme aide également à relier les données au contexte commercial, ce qui permet aux équipes d'utiliser les données de manière plus efficace et plus responsable. La plateforme d'Actian est conçue pour s'adapter à l'évolution des écosystèmes de données, favorisant une utilisation cohérente, intelligente et sécurisée des données dans l'ensemble de l'entreprise. Demandez votre démo personnalisée.
Diagramme de l'architecture du Data Hub