Selon Gartner, la mauvaise qualité des données coûte en moyenne 12,9 millions de dollars par an aux organisations, tandis que des recherches menées par IBM en 2025 montrent qu’il faut en moyenne 258 jours aux entreprises pour identifier et contenir une violation de données. Ces statistiques révèlent une réalité fondamentale : la gouvernance ne peut plus être une réflexion tardive ni un processus manuel ; elle doit être automatisée, centralisée et intégrée aux opérations de données.
Un catalogue de données est un système centralisé de métadonnées qui aide les organisations à découvrir, comprendre et gouverner leurs données. Au sein d’une plateforme de Data Intelligence, le catalogue de données fournit la base de découverte et de contextualisation qui relie les métadonnées, le lignage des données, la gouvernance et l’observabilité à l’échelle de l’entreprise. Il offre la découverte automatisée, le lignage, la classification et l’application des politiques, afin que les équipes puissent trouver rapidement des données fiables et les utiliser de manière responsable.
Un catalogue de données moderne, doté de la découverte automatisée, de métadonnées centralisées et de mécanismes d’application des politiques, transforme une gouvernance fragmentée et risquée en un accès en libre-service proactif et fiable, améliorant la conformité, la qualité et la prise de décision. Il marque le passage d’une gestion réactive des incidents à une véritable gouvernance stratégique des données, permettant aux organisations de gouverner à grande échelle tout en accélérant l’analyse des données et l’innovation.
Les catalogues de données d’entreprise exigent plus qu’une simple recherche et un inventaire de base. Les capacités essentielles incluent la découverte automatisée des métadonnées, l’alignement intégré avec un glossaire métier, un lignage de bout en bout, des contrôles d’accès basés sur les rôles, l’application des politiques, une marketplace de données, ainsi que des indicateurs de qualité et d’observabilité des données. Lorsqu’elles sont proposées dans le cadre d’une plateforme de Data Intelligence, ces fonctionnalités garantissent que des données fiables et gouvernées sont disponibles là où l’analyse des données et l’IA sont réellement utilisées.
Qu’est-ce qu’un catalogue de données ?
Un catalogue de données est un système centralisé qui inventorie, organise et enrichit les métadonnées afin que les utilisateurs puissent découvrir, comprendre, faire confiance et gouverner les données au sein de l’organisation. Les catalogues de données modernes automatisent la collecte des métadonnées, suivent le lignage des données, appliquent les politiques de gouvernance et mettent en avant des indicateurs de qualité et de confiance pour soutenir les initiatives d’analyse des données, de conformité et d’IA.
Principaux bénéfices d’un catalogue de données
Les catalogues de données modernes apportent des bénéfices significatifs en matière de gouvernance, de conformité et d’efficacité opérationnelle.
- Centralisent les métadonnées provenant de toutes les sources dans un référentiel unique et interrogeable, éliminant les silos de données.
- Améliorent la qualité et la fiabilité des données grâce à une surveillance continue, des mécanismes de validation et des scores de qualité.
- Automatisent la classification et l’application des politiques, garantissant un traitement cohérent des données sensibles.
- Accélèrent l’analyse des données et l’accès en libre-service en rendant les données fiables accessibles en quelques minutes plutôt qu’en plusieurs semaines.
- Renforcent la conformité au RGPD, à la HIPAA et aux réglementations sectorielles.
- Fournissent un lignage des données permettant de comprendre l’origine des données, leurs transformations et leur utilisation dans l’ensemble de l’écosystème.
- Réduisent les risques opérationnels et le travail manuel de gouvernance, libérant les équipes pour qu’elles se concentrent sur des initiatives stratégiques.
- Permettent la démocratisation des données tout en maintenant la sécurité et le contrôle grâce à des accès basés sur les rôles.
- Accélèrent les initiatives d’IA et de machine learning en fournissant des données d’entraînement fiables et bien documentées.
- Améliorent la collaboration entre équipes techniques et métiers grâce à une compréhension partagée.
Comprendre les principaux défis de la gouvernance des données
La gouvernance des données regroupe l’ensemble des politiques, des rôles et des processus qui garantissent que les données sont disponibles, utilisables, exactes et sécurisées à l’échelle de l’entreprise. À mesure que les organisations ingèrent davantage de données provenant de sources diverses, la gouvernance devient à la fois plus complexe et plus stratégique.
Les principaux défis incluent des métadonnées fragmentées réparties sur des systèmes déconnectés, créant des visions incohérentes et rendant impossible une gouvernance à l’échelle de l’entreprise. Les silos de données persistent parce que les systèmes départementaux ne communiquent pas entre eux, dupliquant les données et générant des problèmes de contrôle de version difficiles à gérer. Une terminologie métier incohérente signifie qu’un même concept peut porter des noms différents selon les équipes, comme « customer » ou « client », tandis que des concepts distincts peuvent partager le même nom, ce qui entraîne confusion et erreurs.
Les processus de conformité manuels restent lents et sujets aux erreurs. Les inventaires de données basés sur des feuilles de calcul deviennent obsolètes immédiatement. Les revues d’accès ont lieu chaque trimestre ou chaque année, laissant en place pendant des mois des autorisations inappropriées. La classification repose sur un étiquetage manuel qui ne détecte pas toujours les données sensibles ou applique les labels de manière incohérente. La préparation des audits mobilise des semaines de collecte manuelle de preuves.
Le manque de visibilité pénalise les organisations : les équipes ne trouvent pas des jeux de données déjà existants, ce qui entraîne du travail en double et un gaspillage de ressources. Elles ne peuvent pas évaluer la qualité sans connaissance informelle ou sans mener une enquête longue et chronophage. Elles ne peuvent pas retracer le lignage des données pour comprendre d’où elles proviennent ou ce qui en dépend, rendant l’analyse d’impact impossible et les investigations sur les causes profondes particulièrement lentes.
Sans responsabilité ni gestion clairement définies, la qualité des données se dégrade, car personne n’assume la responsabilité de leur exactitude, de leur exhaustivité ou de leur actualité. La confiance s’érode lorsque les utilisateurs rencontrent régulièrement des problèmes de qualité, et ils cessent d’utiliser les sources officielles au profit d’alternatives non contrôlées.
Les conséquences vont au-delà de la simple inefficacité : amendes réglementaires, incidents de sécurité et blocage des initiatives d’analyse des données ou d’IA. Les organisations qui cherchent à industrialiser l’IA constatent que le développement des modèles ralentit fortement en l’absence de données d’entraînement fiables et correctement documentées. Pour développer un libre-service fiable et devenir réellement pilotées par les données, les organisations ont besoin d’une gouvernance automatisée, centralisée et intégrée aux workflows quotidiens.
Automatiser la découverte des données et la collecte des métadonnées
La découverte automatisée analyse en continu les bases de données, les fichiers, les espaces de stockage cloud et les applications afin d’identifier les actifs de données, éliminant les inventaires manuels et garantissant une couverture complète. Les outils modernes de découverte détectent les emplacements des sources, les schémas, les relations et les modèles d’utilisation, et améliorent leur précision au fil du temps grâce au machine learning.
La collecte automatisée des métadonnées extrait des informations bien plus riches que ne pourrait jamais le faire une documentation manuelle. Les métadonnées techniques incluent les détails des schémas, les types de données, la possibilité de valeurs nulles, l’unicité, la cardinalité et des profils statistiques montrant la distribution des valeurs ainsi que des indicateurs de qualité. Les métadonnées métier capturent la finalité, la responsabilité, les scores de qualité et les règles d’utilisation. Les métadonnées opérationnelles suivent les modèles d’accès, les performances des requêtes, les calendriers d’actualisation des données et le lignage des données montrant les transformations.
Ces processus automatisés maintiennent le catalogue synchronisé avec la réalité. Lorsque les développeurs déploient des modifications de schéma via des pipelines CI/CD, la découverte les détecte en quelques heures. Lorsque de nouvelles sources de données sont mises en service, elles apparaissent automatiquement dans le catalogue. Lorsque des jeux de données sont retirés, le catalogue reflète leur suppression. Cette synchronisation empêche le catalogue de devenir un système de documentation obsolète que les équipes finissent par ignorer.
L’automatisation réduit considérablement le temps d’intégration de nouvelles sources, passant de plusieurs semaines ou mois à quelques heures ou jours, ce qui permet aux projets d’analyse des données de démarrer plus rapidement. Dans le même temps, les politiques de gouvernance et les contrôles d’accès s’appliquent dès l’ingestion des données.
Construire un catalogue de données centralisé et complet
Un catalogue de données centralisé indexe et organise l’ensemble des actifs de données de l’entreprise dans une interface unique et interrogeable, supprimant les silos et créant une source unique de vérité. Cette consolidation apporte des bénéfices pratiques immédiats. Les utilisateurs trouvent les jeux de données en quelques minutes au lieu de passer des jours à demander autour d’eux. Le travail en double diminue fortement lorsque les équipes peuvent voir ce qui existe déjà. Les politiques de gouvernance s’appliquent de manière uniforme puisqu’il n’existe qu’un seul endroit pour les définir et les appliquer. La préparation des audits s’accélère car toutes les preuves se trouvent dans un seul système doté d’une journalisation complète.
Capacités de recherche et de découverte : les catalogues modernes proposent plusieurs modes de recherche afin de répondre aux différents besoins des utilisateurs. La recherche par mots-clés permet des recherches rapides par nom ou description. La recherche sémantique comprend les concepts métier et permet de trouver des jeux de données liés au « chiffre d’affaires » lorsqu’un utilisateur recherche « ventes ». La recherche à facettes permet de filtrer par système source, domaine de données, propriétaire, classification, score de qualité ou niveau de fraîcheur. Les utilisateurs peuvent parcourir des taxonomies et des hiérarchies, ou suivre des recommandations basées sur leur rôle et leurs habitudes d’utilisation.
Indicateurs de qualité et de confiance des données : chaque jeu de données affiche des métriques de qualité calculées à partir du profiling et des règles de validation : pourcentages de complétude, scores d’exactitude, indicateurs d’actualité et mesures de cohérence. Les évaluations et commentaires des utilisateurs apportent un retour qualitatif. Les statistiques d’utilisation montrent la popularité : les jeux de données largement utilisés par des analystes expérimentés sont souvent considérés comme plus fiables que ceux rarement consultés. Les badges de certification indiquent une validation formelle par les responsables de la gestion des données.
Analytique d’utilisation : le catalogue suit qui accède aux jeux de données, quand et dans quel objectif. Cette visibilité met en évidence les produits de données populaires qui méritent davantage d’investissement, identifie les actifs sous-utilisés susceptibles d’être archivés et aide les responsables à comprendre l’impact de leurs données. Ces analyses permettent également de détecter des schémas d’accès inhabituels qui pourraient signaler des problèmes de sécurité ou des violations de politiques.
Fonctionnalités collaboratives : les utilisateurs peuvent commenter les jeux de données, poser des questions ou partager des informations. Ils peuvent évaluer la qualité des données en fonction de leur expérience. Les responsables peuvent joindre des exemples d’utilisation illustrant des requêtes ou des analyses courantes. Les discussions autour des actifs de données créent une connaissance collective qui, autrement, resterait dispersée dans des conversations Slack ou des échanges par e-mail et deviendrait difficile à retrouver par la suite.
Contexte métier et standardisation : la centralisation permet d’imposer un langage métier cohérent grâce à des définitions, classifications et glossaires standardisés. Lorsque « client » possède une définition de référence liée à chaque jeu de données contenant des informations client, la confusion entre départements disparaît. Les équipes s’alignent sur une terminologie commune, réduisant les malentendus susceptibles d’entraîner des analyses incorrectes ou du travail en double.
Les catalogues modernes stockent les métadonnées techniques et métier, les exemples d’utilisation et les évaluations de qualité afin que les utilisateurs comprennent ce que signifient les données, comment elles sont produites, leur niveau de fiabilité ainsi que les cas d’usage et les limites associés.
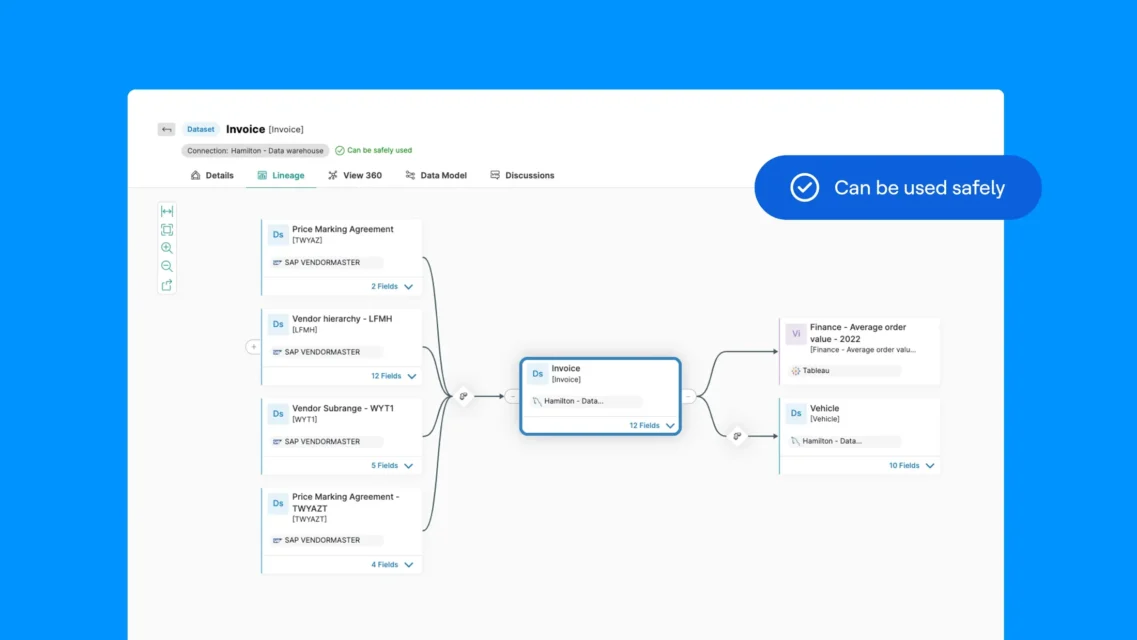
Lignage des données et analyse d’impact
La visualisation du lignage des données constitue l’une des capacités de gouvernance les plus puissantes, car elle montre comment les données circulent depuis les systèmes sources, à travers les transformations, les intégrations et les analyses, jusqu’aux points de consommation finaux. Un lignage complet permet de répondre à des questions essentielles auxquelles la documentation manuelle peine à répondre : d’où provient cette valeur ? Quelles transformations ont été appliquées ? Quels rapports et modèles dépendent de ce jeu de données ? Si je modifie cette table, qu’est-ce qui sera impacté en aval ?
Visualisation des flux de bout en bout : les catalogues modernes construisent des graphes de lignage complets couvrant l’ensemble du patrimoine de données. Cette visibilité traverse les technologies et les plateformes, montrant le lignage même lorsque les données franchissent les frontières entre différents systèmes.
Lignage au niveau des colonnes : pour la conformité réglementaire et les analyses d’impact approfondies, le lignage au niveau des tables n’est souvent pas suffisant. Le lignage au niveau des colonnes suit chaque champ à travers les transformations, montrant par exemple que « annual_revenue » dans un rapport provient finalement de « total_sales » dans le système source après conversion de devise et agrégation. Ce niveau de granularité est essentiel pour les réglementations sur la protection des données qui exigent de documenter la circulation des données personnelles dans les systèmes, ainsi que pour les investigations sur la qualité qui nécessitent d’identifier précisément la cause d’un problème.
Analyse des causes racines pour les problèmes de qualité : lorsqu’un problème de qualité des données apparaît, le lignage permet une investigation rapide. Si un tableau de bord affiche des valeurs incorrectes, les équipes peuvent remonter le lignage à travers les transformations pour identifier où l’erreur a été introduite. S’agit-il de données sources incorrectes ? D’une erreur logique dans le code de transformation ? D’une valeur nulle inattendue qui a perturbé les calculs ? Le lignage réduit le temps d’investigation de plusieurs jours à quelques heures en fournissant une feuille de route directe vers l’origine du problème.
Gouvernance des modèles de machine learning : à mesure que les organisations déploient davantage de modèles de machine learning, le lignage devient essentiel pour la gouvernance et l’explicabilité des modèles. Il documente quelles données d’entraînement ont été utilisées, comment les variables ont été construites, quels traitements préalables ont été appliqués et si l’un de ces éléments a évolué depuis le déploiement du modèle. Lorsque les performances d’un modèle se dégradent, le lignage aide à déterminer si la cause provient d’une dérive des données, d’une dérive des concepts ou de modifications dans les sources de données amont.
Développement de produits de données : les organisations qui créent des produits de données internes, c’est-à-dire des jeux de données préparés et publiés pour être réutilisés par différentes équipes, s’appuient sur le lignage pour comprendre les dépendances et garantir la fiabilité. Les responsables de ces produits peuvent identifier toutes les sources amont dont dépend leur produit ainsi que tous les consommateurs en aval qui l’utilisent, ce qui permet une gestion rigoureuse des changements et le respect des engagements de niveau de service.
Appliquer des contrôles d’accès basés sur les rôles et des politiques de sécurité
Le contrôle d’accès basé sur les rôles (RBAC) attribue des autorisations selon les rôles afin de garantir que seuls les utilisateurs autorisés accèdent aux données sensibles tout en permettant un usage légitime pour les besoins métiers. Dans un catalogue, le RBAC associe les fonctions professionnelles à des droits spécifiques de consultation, de modification et d’utilisation, garantissant un accès cohérent et traçable.
L’intégration du RBAC aux politiques de sécurité de l’entreprise centralise l’application des règles et simplifie les audits de conformité. L’automatisation des décisions d’accès sur la base de règles prédéfinies réduit la charge pour les équipes IT et supprime les pratiques d’autorisation ad hoc qui créent des failles. Lorsqu’un nouvel analyste rejoint l’organisation, il reçoit automatiquement les autorisations standards correspondant à son service et à son niveau de responsabilité. Lorsqu’un employé change de poste, ses autorisations sont ajustées automatiquement. Lorsqu’un collaborateur quitte l’entreprise, son accès est immédiatement révoqué dans l’ensemble des systèmes gouvernés. Cette automatisation élimine le processus manuel de demande d’accès basé sur des tickets, qui génère retards et incohérences.
Les mécanismes RBAC avancés peuvent également être sensibles au contexte, en adaptant les autorisations selon l’heure, la localisation, l’appareil utilisé ou l’objectif de l’accès, afin d’équilibrer la protection stricte des informations sensibles avec la flexibilité opérationnelle nécessaire aux workflows légitimes.
Cette approche sophistiquée concilie la protection rigoureuse des données sensibles avec la flexibilité opérationnelle nécessaire aux activités métiers. Un data scientist peut accéder à des enregistrements clients complets pour entraîner un modèle depuis un ordinateur professionnel pendant les heures de travail, mais ne consulter que des statistiques agrégées depuis un appareil personnel à domicile. Un prestataire externe peut accéder à des jeux de données spécifiques à un projet pendant la durée de son contrat, puis perdre automatiquement cet accès à la fin de sa mission.
Mettre en œuvre la classification automatisée et l’application des politiques
La classification automatisée utilise des algorithmes et du machine learning pour étiqueter les données selon leur type, leur sensibilité et leurs exigences réglementaires, garantissant ainsi un traitement cohérent dans l’ensemble du patrimoine de données. Cette approche remplace l’étiquetage manuel, souvent sujet aux erreurs, et garantit que les données sensibles (PII, informations financières, propriété intellectuelle) sont correctement identifiées.
Les classifications couvrent plusieurs dimensions : le type de données identifie si les données correspondent à des informations personnelles (PII), des données de santé (PHI), des informations financières, de la propriété intellectuelle ou des données publiques. Le niveau de sensibilité classe les données comme publiques, internes, confidentielles ou restreintes. Le périmètre réglementaire identifie les données soumises au RGPD, à HIPAA, à PCI DSS, au CCPA ou à d’autres réglementations sectorielles. Les exigences de conservation précisent combien de temps les données doivent être conservées et quand elles doivent être supprimées. Les restrictions géographiques indiquent où les données peuvent être stockées et qui peut y accéder en fonction des lois de résidence des données.
L’application des politiques utilise ces classifications pour mettre automatiquement en place des contrôles, tels que des restrictions d’accès, le masquage des données, des règles de conservation et des mécanismes de surveillance, tout en analysant en continu les violations potentielles des politiques. La plateforme peut signaler des accès inhabituels, générer des alertes et déclencher des workflows de remédiation afin de réduire les erreurs humaines et les délais d’application des règles.
Les rapports de conformité automatisés produisent des journaux d’audit et des rapports détaillant qui a accédé à quelles données, à quel moment et sous quels contrôles, conformément aux exigences du RGPD, de HIPAA et d’autres réglementations, réduisant ainsi les efforts et les risques associés aux rapports manuels.
Maintenir des pistes d’audit et permettre une surveillance proactive de la conformité
Les pistes d’audit enregistrent de manière chronologique les actions effectuées sur les actifs de données, notamment les accès, les modifications, les changements de métadonnées et les mises à jour du lignage des données, fournissant des preuves essentielles pour la responsabilité, les investigations d’incidents et les audits réglementaires. Les journaux capturent les usages directs et indirects des données, qu’il s’agisse de rapports, d’analyses ou de pipelines de données, afin de faciliter les analyses forensiques et l’évaluation des risques.
La surveillance proactive de la conformité analyse en continu les modèles d’accès, le respect des politiques et les anomalies d’utilisation afin de détecter les problèmes avant qu’ils ne s’aggravent. Lorsqu’une anomalie est détectée, le système peut alerter les parties prenantes, déclencher des workflows de remédiation ou appliquer automatiquement des corrections selon le niveau de gravité.
Les mécanismes de surveillance avancés peuvent également fournir des analyses prédictives basées sur des tendances historiques, aidant les équipes à anticiper et à prévenir les risques de conformité plutôt qu’à y réagir après coup.
Faciliter la collaboration grâce à une documentation basée sur des modèles
La documentation basée sur des modèles standardise la manière dont les métadonnées, le contexte métier, les responsabilités de gestion des données et les politiques sont collectés et présentés, réduisant la variabilité et l’effort manuel. Des interfaces en glisser-déposer et des formulaires guidés permettent aux contributeurs non techniques d’ajouter du contexte, des règles métier et des recommandations d’utilisation sans compétences techniques particulières.
Les plateformes proposent généralement des modules adaptés aux différents rôles : des modules studio permettant aux responsables de gérer les workflows et les politiques, et des modules explorer permettant aux utilisateurs métiers de découvrir les actifs de données et d’apporter leur connaissance du domaine. Les modèles prennent en charge les registres d’actifs, les glossaires, l’attribution des responsabilités, les déclarations de politiques et les recommandations d’utilisation, avec des workflows d’approbation et un contrôle de version garantissant l’exactitude des informations.
Cette approche structurée et collaborative répartit le travail de documentation, maintient la qualité et garantit que les informations publiées sont examinées et gouvernées.
Bonnes pratiques pour réussir l’implémentation d’un catalogue de données
La mise en œuvre réussie d’un catalogue de données nécessite de prendre en compte à la fois la technologie et les personnes. Les bonnes pratiques clés incluent :
- Attribuer des responsabilités claires : désigner des responsables et des stewards pour chaque domaine de données majeur, avec des responsabilités clairement définies concernant la documentation, la qualité et la gouvernance des accès.
- Développer et maintenir un glossaire métier standardisé : aligner la terminologie entre les équipes grâce à des définitions officielles des termes métier, des métriques et des concepts. Le glossaire devient la base sémantique qui garantit que tous parlent le même langage.
- Automatiser la synchronisation des métadonnées : intégrer les mises à jour du catalogue aux déploiements CI/CD et aux pipelines de données afin que les métadonnées restent automatiquement à jour.
- Proposer des formations adaptées aux rôles : adapter la formation aux stewards, data engineers, analystes et utilisateurs métiers avec des scénarios concrets illustrant la valeur du catalogue pour chaque rôle.
- Intégrer le catalogue dans les workflows : intégrer les fonctionnalités du catalogue là où les utilisateurs travaillent déjà afin que la gouvernance soit intégrée aux processus et non perçue comme une étape supplémentaire.
Les organisations qui appliquent ces pratiques constatent une meilleure visibilité sur leurs données, un accès plus rapide aux insights, une auditabilité renforcée et une plus grande confiance dans les résultats analytiques. Le catalogue cesse alors d’être une simple exigence de conformité pour devenir une capacité stratégique permettant une innovation rapide et sécurisée.
En quoi les catalogues de données modernes diffèrent des outils de catalogage traditionnels
Les outils de catalogage de données traditionnels se concentrent principalement sur l’inventaire et la recherche. Bien qu’utiles, ces outils manquent souvent de synchronisation des métadonnées en temps réel, de glossaire métier unifié, de lignage approfondi, de gouvernance intégrée et d’indicateurs de qualité nécessaires pour l’analyse des données et l’IA à l’échelle de l’entreprise.
Les catalogues de données modernes fonctionnent comme une composante d’une plateforme de Data Intelligence plus large. Ils collectent en continu des métadonnées techniques, métier et opérationnelles, relient le lignage des données, l’observabilité et les définitions du glossaire métier, et intègrent les politiques de gouvernance directement dans la manière dont les données sont consultées et utilisées. Cette évolution transforme le catalogue d’un simple système de référence passif en une couche active de contrôle et de confiance pour les données de l’entreprise.
Catalogue de données vs solutions traditionnelles et solutions ponctuelles
De nombreuses organisations adoptent des solutions ponctuelles pour le catalogage de données, les glossaires métier, le lignage des données ou la qualité des données. Bien que ces outils répondent à des besoins spécifiques, ils créent souvent des expériences fragmentées difficiles à faire évoluer à grande échelle.
Un catalogue de données moderne intégré dans une plateforme de Data Intelligence unifie la découverte des données, les définitions du glossaire métier, le lignage des données, la gouvernance et l’observabilité dans un système unique. Cela élimine les outils déconnectés, réduit les efforts d’intégration manuelle et garantit que les politiques de gouvernance et les indicateurs de confiance sont appliqués de manière cohérente dans les workflows d’analyse des données et d’IA.
Contrairement aux outils de catalogage autonomes, une approche intégrée permet aux organisations de dépasser la simple gestion d’inventaire pour mettre en place une gouvernance active, un libre-service fiable et des données prêtes pour l’IA à l’échelle de l’entreprise.
FAQ
Un catalogue de données est un système centralisé de métadonnées qui aide les équipes à découvrir, comprendre et gouverner les données de l’entreprise. Il fonctionne en analysant automatiquement les sources de données, en collectant les métadonnées, en classifiant les informations sensibles, en cartographiant le lignage des données et en appliquant les politiques de gouvernance afin que les utilisateurs puissent rapidement trouver des données fiables pour l’analyse des données et l’IA.
Un catalogue de données soutient la Data Intelligence en agissant comme la principale couche de découverte et de contextualisation qui relie les métadonnées, le lignage des données, la gouvernance et la qualité des données à l’échelle de l’entreprise.
Au sein d'une plateforme de Data Intelligence, le catalogue collecte en continu des métadonnées techniques, métier et opérationnelles, rendant les actifs de données recherchables, compréhensibles et gouvernés à grande échelle. Il fournit une visibilité sur la propriété des données, leur utilisation, leur lignage et leurs indicateurs de confiance afin que les équipes d’analyse des données, les systèmes d’IA et les utilisateurs métiers puissent sélectionner en toute confiance les données adaptées à leurs besoins.
Sans catalogue de données, la Data Intelligence ne dispose pas d’une interface pratique permettant la découverte et l’adoption des données. Le catalogue garantit que l’intelligence des données n’est pas seulement documentée, mais qu’elle est réellement utilisée dans les workflows d’analyse des données, d’IA et d’exploitation.
Un catalogue de données fournit la visibilité et le contrôle dont les équipes de gouvernance ont besoin. Il centralise les métadonnées, standardise les définitions, applique les politiques d’accès et automatise la surveillance de la conformité. Cela réduit les risques, améliore la qualité des données et garantit une gouvernance cohérente dans l’ensemble du patrimoine de données.
Un catalogue de données répond aux principaux défis qui empêchent les organisations de faire confiance à leurs données et d’en étendre l’usage à grande échelle. Il élimine les métadonnées fragmentées, réduit le travail d’analyse des données en double et facilite la recherche et la compréhension de données gouvernées et de haute qualité.
Les catalogues de données modernes répondent à des problématiques fréquentes telles que des définitions métier incohérentes, une visibilité limitée sur le lignage des données, des processus de conformité manuels et un faible niveau de confiance dans les résultats analytiques. En centralisant les métadonnées, le lignage des données, le contexte de gouvernance et les indicateurs de qualité, un catalogue de données permet une prise de décision plus rapide, une conformité renforcée et des initiatives d’IA et d’analyse des données plus fiables.
Les catalogues de données d’entreprise doivent offrir bien plus qu’une simple fonction de recherche et d’inventaire. Les fonctionnalités essentielles incluent la découverte automatisée des métadonnées, un lignage des données de bout en bout, des contrôles d’accès basés sur les rôles, l’application des politiques, des indicateurs de qualité et d’observabilité des données, ainsi que la prise en charge des environnements hybrides et multi-cloud.
En pratique, ces capacités ne peuvent évoluer à grande échelle que lorsque le catalogue fonctionne comme une composante d’une plateforme de Data Intelligence plus large, où les workflows de gouvernance, les indicateurs de confiance et le contexte métier sont directement intégrés à la manière dont les données sont consultées et utilisées dans les systèmes d’analyse des données et d’IA. Sans cette base, les catalogues peinent à dépasser des usages limités à de petites équipes ou à la seule conformité.
L’IA améliore un catalogue de données en automatisant la découverte, la classification et l’enrichissement des métadonnées. Le machine learning identifie les modèles dans les données, détecte les anomalies, recommande des actifs de données connexes, signale les problèmes de qualité et anticipe les risques potentiels de conformité. Ces capacités permettent aux organisations de déployer la gouvernance à grande échelle tout en réduisant le travail manuel.
Oui. Un catalogue de données moderne joue un rôle essentiel dans les initiatives d’IA et de machine learning en fournissant les métadonnées, le lignage des données et le contexte de qualité dont dépendent les modèles.
Les initiatives d’IA nécessitent des données d’entraînement fiables, des pipelines de variables explicables et une visibilité sur l’évolution des données dans le temps. Un catalogue de données rend cela possible en documentant l’origine des données, les transformations, les indicateurs de qualité et les contraintes d’utilisation, réduisant ainsi les risques, les biais et la dérive des modèles tout en améliorant la transparence et la gouvernance.
Les catalogues open source offrent de la flexibilité aux équipes qui souhaitent personnaliser leurs propres outils, mais ils peuvent nécessiter davantage de ressources d’ingénierie. Les catalogues de données d’entreprise fournissent une automatisation intégrée, des workflows de gouvernance, des contrôles de sécurité, une scalabilité, un support technique et une intégration avec des plateformes de données plus larges, ce qui les rend mieux adaptés aux environnements réglementés ou aux déploiements à grande échelle.


