Lo que nos enseñó la «repatriación en la nube» de 37signals sobre la infraestructura de IA





Resumen
- La repatriación de la nube puede suponer un ahorro de millones de euros a gran escala.
- Las cargas de trabajo de IA aumentan el ahorro gracias a los costes de las GPU y el almacenamiento.
- Las soluciones locales o híbridas son adecuadas para tareas de inferencia predecibles y de gran volumen.
- La nube sigue siendo adecuada para cargas de trabajo de tipo «burst», como el entrenamiento de modelos.
- Las estrategias híbridas logran un equilibrio entre el coste, el rendimiento y el cumplimiento normativo.
En 2023, 37signals anunció que había abandonado por completo la nube pública y, a continuación, documentó públicamente su proceso de repatriación de la nube, lo que constituyó uno de los ejemplos más claros del mundo real de la rentabilidad de las soluciones locales a gran escala. Al revertir su migración a la nube y trasladar las cargas de trabajo a una infraestructura de nube privada, la empresa su gasto anual en infraestructura en la nube en casi 2 millones de dólares.
La transparencia de las cifras hizo que el argumento resultara convincente. En 2022, 37signals gastó 3 201 564 dólares en servicios en la nube, lo que supone unos 266 797 dólares al mes. Estos desgloses detallados de los costes, junto con la inversión en hardware publicada y los plazos de amortización, ofrecieron una visión poco habitual de los mecanismos financieros de una migración a la nube a gran escala.
En el caso de las cargas de trabajo SaaS estándar, las cuentas estaban claras. Pero esa misma lógica plantea una pregunta importante para la próxima generación de sistemas con un uso intensivo de recursos computacionales: «¿Se aplica este razonamiento económico también a la infraestructura de IA?». En este artículo, analizamos si la misma lógica económica es válida para la infraestructura de IA.
TL;DR
- 37signals gastó unos 3,2 millones de dólares al año en AWS en 2022.
- Tras repatriar las cargas de trabajo a su propia infraestructura, el gasto en la nube se redujo a unos 1,3 millones de dólares en 2024.
- La empresa invirtió entre 700 000 y 800 000 dólares en servidores y amortizó esa inversión en menos de 18 meses.
- Toda la infraestructura sigue estando gestionada por el mismo equipo de 10 personas. Sin gastos operativos adicionales.
- La conclusión principal es que, a largo plazo, ser propietario de la infraestructura puede resultar mucho más económico que alquilarla.
El manual de 37signals: lo que Hanson realmente documentó
En 2022, 37signals gastó 3,2 millones de dólares al año en AWS. Tras abandonar la nube en 2023, sus costes anuales se habían reducido a aproximadamente 1,3 millones de dólares en 2024, lo que supone reducción de casi 2 millones de dólares al año.
La transición requirió una inversión en hardware de aproximadamente 600 000 dólares en servidores Dell. La empresa recuperó íntegramente la inversión en menos de 18 meses, alcanzando la amortización total en la segunda mitad de 2023, al vencerse sus contratos de instancias reservadas de AWS. A partir de ese momento, el ahorro se destinó directamente al margen operativo, en lugar de compensar los gastos de capital.
37signals había previsto unos costes de hardware de 1,5 millones de dólares y unos gastos operativos de aproximadamente 200 000 dólares al año. Este cambio sustituye una factura anual recurrente de 1,3 millones de dólares en almacenamiento en la nube por un gasto de capital único, más una pequeña parte de los costes operativos continuos. A lo largo de cinco años, 37signals revisó al alza sus previsiones de ahorro total, pasando de 7 millones de dólares a más de 10 millones.
Resultados financieros de 37signals por año
Para ilustrar el impacto financiero de la salida de 37signals de la nube a lo largo del tiempo, la siguiente tabla desglosa el gastos en la nube, las inversiones en hardware localy los costes operativos, destacando el ahorro neto resultante y las notas operativas clave.
| Año | Gasto en la nube | Inversión en hardware | Costes de funcionamiento | Notas |
| Referencia de 2022 | unos 3,2 millones de dólares | $0 | Incluido en el gasto en la nube | Dependencia total de la nube |
| Migración 2023 | unos 2 millones de dólares | entre 700 000 y 800 000 dólares | Moderado | La inversión en hardware se amortizó por completo en menos de 18 meses |
| 2024+ Tras la repatriación | aproximadamente 1,3 millones de dólares | ~1,5 millones de dólares (almacenamiento) | unos 200 000 dólares al año | Un ahorro anual de aproximadamente 1,9 millones de dólares |
| 2025+ | Dependencia mínima de AWS | ~1,5 millones de dólares (Pure Storage, 18 PB) | unos 200 000 dólares al año | Ahorro previsto de más de 10 millones de dólares en cinco años |
Cabe destacar que la migración no obligó al equipo a ampliar sus operaciones. Un equipo de infraestructura formado por diez personas se encargó de todo el proceso de repatriación sin necesidad de contratar a más personal. En respuesta a una preocupación habitual sobre los gastos operativos, el cofundador de 37signals, David Heinemeier Hansson, señaló:
Llevamos poco más de un año fuera del mercado y el equipo que se encarga de todo sigue siendo el mismo. No hubo ningún problema oculto de aumento de la carga de trabajo asociado a la salida que nos obligara a ampliar el equipo, como especularon algunos observadores cuando lo anunciamos. Todas las respuestas de nuestra sección de preguntas frecuentes sobre la salida de Big Cloud siguen siendo válidas.
Esto pone directamente en tela de juicio la creencia generalizada de que abandonar los entornos de nube pública implica, inevitablemente, contar con un equipo de infraestructura mucho más numeroso.
La ejecución siguió una estrategia de «escalera de criticidad», en la que el equipo migró primero los servicios de menor riesgo y los más críticos más tarde. El equipo trasladó el sistema de correo electrónico de HEY por etapas, comenzando por el almacenamiento en caché, luego la base de datos y, por último, los servicios de tareas. Para minimizar el riesgo, ubicaron la infraestructura a aproximadamente un milisegundo de la región de AWS con el fin de preservar la capacidad de reversión durante el proceso de repatriación a la nube. Tras estabilizar el sistema, sustituyeron los servicios gestionados con costes recurrentes sustanciales, incluidos RDS y Elasticsearch gestionado, que en conjunto superaban los 500 000 dólares anuales.
Lo que hace que el caso práctico de 37signals sea relevante es la rentabilidad que se ha documentado públicamente. Para las organizaciones que se plantean , especialmente en lo que respecta a los costes de almacenamiento y los servicios gestionados, la documentación de 37signals ofrece una referencia de comparación poco habitual.
Por qué la economía de la infraestructura de la IA es aún más extrema
Las lecciones extraídas de la «repatriación a la nube» de 37signals cobran mayor relevancia cuando se aplican a la infraestructura de IA. El aumento de los costes de las GPU, las cargas de trabajo de inferencia predecibles, el almacenamiento masivo de representaciones y las normativas de datos más estrictas generan presiones financieras y operativas que acentúan las ventajas de soluciones locales o de nube híbrida, que permiten trasladar las cargas de trabajo allí donde más sentido tenga. A continuación, desglosamos los factores clave.
Comparación de costes de infraestructura de IA
Para evaluar las implicaciones económicas de los distintos enfoques de infraestructura de IA, en la tabla siguiente se comparan los costes iniciales de instalación, los gastos operativos mensuales para diferentes cargas de trabajo y los plazos previstos para alcanzar el umbral de rentabilidad en configuraciones en la nube, locales e híbridas.
| Configuración | Coste de instalación | Coste mensual | Umbral de rentabilidad |
| Alquiler de GPU en la nube (AWS/Azure) | $0 | 2.900–3.500 $ (8 horas al día × 4–8 $ por hora × 15 días) | N/A |
| API de inferencia en la nube (Lambda Labs) | $0 | 1.800–2.500 $ (8 horas al día × 3,67 $ por hora × 15 días) | N/A |
| GPU autohospedada (servidor con 8 tarjetas H100) | entre 200 000 y 400 000 dólares | 1.500–2.000 $ (electricidad + mantenimiento) | <12 months |
| Híbrido (formación en la nube + presencial) | entre 200 000 y 400 000 dólares | Solo entrenamiento, inferencia mínima | <12 months |
Nota: En el caso del alquiler de GPU en la nube, calculamos el coste mensual partiendo de la base de ocho horas al día por GPU. El coste varía de forma lineal en función de la utilización; no se calcula directamente por consulta.
- Los márgenes de beneficio de los servicios de GPU en la nube son elevados
Las cargas de trabajo de IA dependen en gran medida de las GPU, y los proveedores de servicios en la nube aplican recargos mucho más elevados por la capacidad de las GPU que por la computación típica de las CPU. Las instancias P5 de AWS bajo demanda con GPU H100 cuestan aproximadamente entre 4 y 8 dólares por hora de GPU, mientras que las instancias H100 comparables de Azure rondan los 3,67 dólares por hora. Por el contrario, los mercados de precios variables y los proveedores alternativos como Lambda Labs , ofrecen una capacidad de GPU similar por entre 1 y 2 dólares por hora, o entre 1,85 y 2,49 dólares por hora con compromisos reservados.
El resultado es un margen de beneficio de entre 4 y 8 veces mayor para la capacidad de GPU bajo demanda de los hiperescaladores, en comparación con el mercado de la nube de GPU spot o especializadas. En otras palabras, la prima que cobran los proveedores de nube por la computación de IA de gama alta es considerablemente mayor que los márgenes habituales de la nube de CPU. Para las organizaciones que ejecutan cargas de trabajo de inferencia continuadas, esta diferencia de precios se convierte rápidamente en el principal factor de coste de la infraestructura de IA.
- La inferencia predecible hace que la adquisición de una GPU resulte rentable
El elevado precio de las GPU cobra especial relevancia debido a que las cargas de trabajo de inferencia de IA son inusualmente predecibles. La compra directa de GPU H100 puede resultar rentable. Una sola GPU cuesta aproximadamente entre 25 000 y 40 000 dólares, mientras que un servidor completo con 8 GPU H100 oscila entre 200 000 y 400 000 dólares. El análisis de Lenovo muestra que seis o más horas de uso diario continuado permiten amortizar la inversión frente a AWS en el primer año.
La razón por la que se alcanza el umbral de rentabilidad tan rápidamente es que las cargas de trabajo de inferencia de IA son inusualmente predecibles. A diferencia del tráfico de SaaS, que fluctúa a lo largo del día, los sistemas de IA en producción, como los motores de recomendación, suelen procesar volúmenes constantes de solicitudes.
La previsibilidad cambia la economía. Cuando la infraestructura funciona con una utilización constante, el hardware propio se puede amortizar de manera eficiente a lo largo de toda la carga de trabajo. Ya no es necesario pagar las tarifas adicionales de la nube por una capacidad de picos que los equipos rara vez utilizan.
En el caso de las organizaciones que realizan inferencias de forma continua, la inversión en hardware suele amortizarse en menos de 12 meses. A partir de ese momento, el ahorro sigue el mismo patrón descrito por 37signals: una infraestructura fija que sustituye a una factura de alquiler recurrente.
- Los requisitos de almacenamiento para dispositivos integrados son enormes
Aunque se optimizara el cálculo en la GPU, los sistemas de IA introducen otra capa de costes que crece rápidamente: el almacenamiento de incrustaciones. Las bases de datos vectoriales almacenan incrustaciones de alta dimensión que se utilizan para la búsqueda, la recuperación y las recomendaciones. A medida que los conjuntos de datos alcanzan millones o miles de millones de registros, los requisitos de almacenamiento aumentan rápidamente.
Por ejemplo, 10 millones de vectores de 1.536 dimensiones requieren al menos 58 GB de almacenamiento bruto, y a menudo entre 200 y 300 GB si se incluyen índices y metadatos. Los servicios de almacenamiento en la nube como Pinecone cobran 0,33 $/GB/mes, lo que significa que 500 GB podrían costar 165 $ al mes, sin contar las consultas. Las soluciones autohospedadas como PostgreSQL con pgvector reducen drásticamente el gasto en la nube, al tiempo que mantienen los datos confidenciales bajo control directo. Con el tiempo, estos requisitos de almacenamiento se suman a los costes de infraestructura junto con la computación en GPU, lo que refuerza aún más las ventajas económicas de las arquitecturas autohospedadas o híbridas.
- La soberanía de los datos y el cumplimiento normativo favorecen la implementación local
Las normativas sobre la residencia de datos y el cumplimiento normativo en general son prioridades en el ámbito de la IA, dado que el sector está cada vez más regulado. En particular, la Ley de IA de la UE introdujo normas estrictas para los sistemas de IA, con prohibiciones sobre determinados casos de uso de la IA que entraron en vigor en febrero de 2025. La implementación local simplifica el cumplimiento normativo.
Para las entidades financieras que se enfrentan a entornos normativos complejos, soluciones como la Actian Data Intelligence Platform ayudan a reforzar la gobernanza de los datos y a optimizar los flujos de trabajo de cumplimiento normativo.
Casos prácticos sobre infraestructura en la nube: 37signals los ha validado
Por muy radical que fuera la transparencia financiera de la salida de 37signals de la nube, su repatriación no fue un caso aislado. Formaba parte de una tendencia creciente entre muchas organizaciones que intentaban recuperar el control de los costes y optimizar su infraestructura en la nube. Numerosos casos prácticos de gran repercusión ilustran la magnitud y la rentabilidad de trasladar las cargas de trabajo de las nubes públicas a una infraestructura propia o híbrida.
Dropbox
Dropbox fue pionera en la repatriación de datos empresariales a la nube ya en 2015, y completó la migración entre 2016 y 2018. La empresa trasladó aproximadamente el 90 % de los datos de los clientes, según se informa más de 500 petabytes, de AWS a tres instalaciones de coubicación de su propiedad. La inversión en infraestructura ascendió a 53 millones de dólares, pero Dropbox declaró un ahorro operativo de 74,6 millones de dólares en dos años según su documento S-1 de 2018. Una pequeña parte de las cargas de trabajo, principalmente clientes europeos y servicios especializados, permanece en AWS. Internamente, la iniciativa se conocía como «Magic Pocket» y ejemplifica cómo un enfoque de nube híbrida puede generar ahorros sustanciales al tiempo que se alinea con los objetivos empresariales a largo plazo.
Ahrefs
Ahrefs, la empresa de herramientas de SEO, se basó en una infraestructura de coubicación en Singapur con 850 servidores. Según sus datos, el ahorro conseguido al evitar la nube pública fue de aproximadamente 400 millones de dólares en un periodo de dos años y medio. Coste real de la infraestructura: 39,5 millones de dólares por 850 servidores (unos 1500 dólares por servidor al mes), frente a los 447,7 millones de dólares estimados si se hubiera alojado íntegramente en AWS (equivalente a unos 17 557 dólares por servidor al mes). Como Ahrefs lo expresó: «No seríamos rentables, ni siquiera existiríamos, si nuestros productos estuvieran al 100 % en AWS». Aunque los críticos argumentan que Ahrefs exageró las estimaciones de AWS, el ahorro general fue innegable, lo que ilustra que los retos de la repatriación de la nube pueden superarse a gran escala con una planificación cuidadosa.
GEICO
GEICO dedicó una década a migrar a varios proveedores de servicios en la nube, pero sus costes no hicieron más que aumentar y superaron las previsiones en 2,5 veces, hasta alcanzar los 300 millones de dólares en 2022 entre ocho proveedores. En respuesta a ello, GEICO comenzó a trasladar cargas de trabajo a una nube privada utilizando OpenStack y Kubernetes, con el objetivo de recuperar más del 50 % de los recursos para 2029. Los primeros resultados muestran una reducción del 50 % en los costes de computación y una reducción del 60 % por gigabyte de los costes de almacenamiento en comparación con los servicios de nube pública, lo que demuestra cómo una arquitectura de nube híbrida puede aportar eficiencia, cumplimiento normativo y alineación con los objetivos empresariales a largo plazo.
Akamai
Akamai se encaminaba a punto de gastar más de 100 millones de dólares en servicios en la nube de terceros antes de migrar las cargas de trabajo informáticas a su propia red global de más de 350 000 servidores. La migración supuso un ahorro de aproximadamente 100 millones de dólares al año, lo que demuestra la rentabilidad de la repatriación cuando la infraestructura existente y la escala están en consonancia.
Lo que estos casos tienen en común es el mismo patrón económico documentado por 37signals. Las cargas de trabajo predecibles y de gran volumen acaban resultando más económicas de gestionar en una infraestructura propia que en las nubes de los hiperescaladores.
Estos ejemplos reflejan un cambio más amplio que se está produciendo en las estrategias de infraestructura empresarial. Las encuestas a los directores de sistemas de información (CIO) de Barclays muestran que la repatriación de la nube lleva una tendencia al alza en los últimos años, y que esta tendencia alcanzará su punto álgido en la segunda mitad de 2024, cuando el 86 % de los CIO tiene previsto llevar a cabo la repatriación.
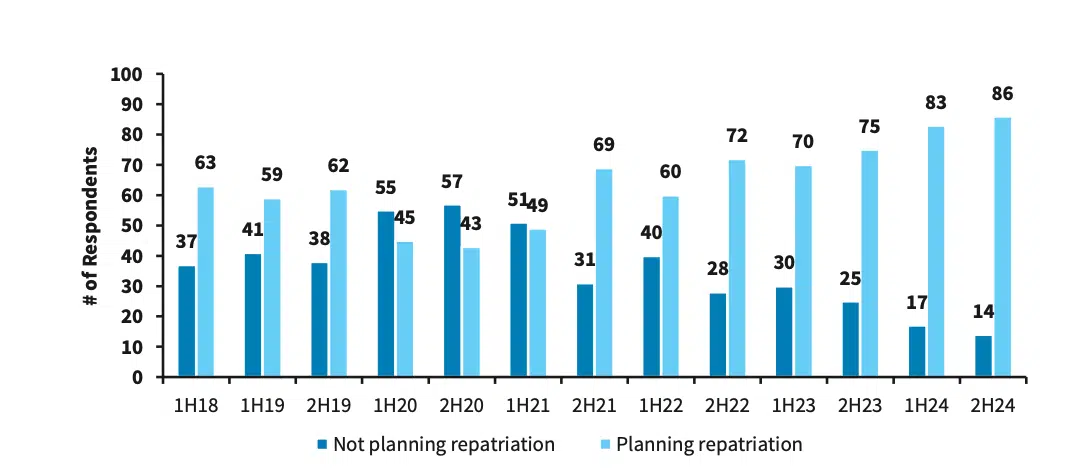
La encuesta de Barclay’s a directores de sistemas de información revela que el 86 % de ellos tiene previsto repatriar sus servicios a la nube
Sin embargo, esta estadística no significa que las empresas estén abandonando por completo los entornos de nube pública. Según IDC, solo entre el 8 % y el 9 % de las empresas se decantan por una repatriación total, mientras que la mayoría prefiere un enfoque híbrido que combine la nube pública y la privada. La infraestructura de nube híbrida permite a las organizaciones optimizar la ubicación de las cargas de trabajo mediante la asignación estratégica de datos confidenciales y aplicaciones críticas en las instalaciones, al tiempo que se aprovechan los servicios de la nube pública para las cargas de trabajo menos críticas. Por ello, cada vez es más importante que los equipos que barajan transiciones similares comprendan los matices de las implementaciones híbridas y los riesgos asociados a ellas.
Estadísticas sobre la repatriación de servicios en la nube
La repatriación de la nube se está acelerando al mismo tiempo que el gasto en la nube pública sigue aumentando. IDC prevé que el gasto global en la nube pública alcanzará los 1,6 billones de dólares en 2028, duplicando su previsión para 2024. Sin embargo, como se ha mencionado anteriormente, el 86 % de los directores de sistemas de información (CIO) está planeando algún tipo de repatriación , según Barclays. Ambas tendencias pueden ser ciertas, ya que no se trata tanto de un éxodo de la nube como de un reequilibrio. Las empresas se inclinan por un modelo de nube híbrida.
Es probable que la IA acelere ese cambio. Las cargas de trabajo de IA representan actualmente menos del 10 % del total de la computación en la nube, pero Gartner prevé que esta cifra se acerque al 50 % para 2029. Los hiperescaladores están respondiendo con enormes inversiones de capital. Se estima se estima un gasto en infraestructura de 600 000 millones de dólares en 2026, de los cuales aproximadamente tres cuartas partes estarán vinculadas a la IA. La hipótesis es clara: las empresas alquilarán esa capacidad de GPU. Pero los cálculos de 37signals sugieren que, una vez que las cargas de trabajo de IA pasen de la fase experimental a la producción estable, la economía de la propiedad comenzará a predominar.
La presión de los costes ya está influyendo en el comportamiento. Flexera informa de que el 27 % de los recursos en la nube se desperdician o están infrautilizados, y el 21 % de las cargas de trabajo ya se han repatriado. La razón principal citada es que los costes superan las previsiones, seguida de las preocupaciones sobre el rendimiento. Con las GPU, el margen de ineficiencia es menor. Hay menos palancas de optimización, tarifas por hora más elevadas y un agotamiento más rápido del presupuesto.
La normativa añade otra capa de complejidad. La Ley de IA de la UE, la DORA para los servicios financieros, la PIPL de China y la DPDP de la India están endureciendo los requisitos en materia de gobernanza de datos. Mimecast informa que el 87 % de las organizaciones tienen ahora en cuenta la soberanía de los datos a la hora de tomar decisiones sobre proveedores. En el caso de los sistemas de IA, la soberanía va más allá de la ubicación de los datos y abarca la procedencia de los modelos, los registros de auditoría y la documentación de cumplimiento. La implementación local no elimina la complejidad normativa, pero centraliza el control y, para muchas empresas, esa simplicidad está resultando estratégicamente atractiva.
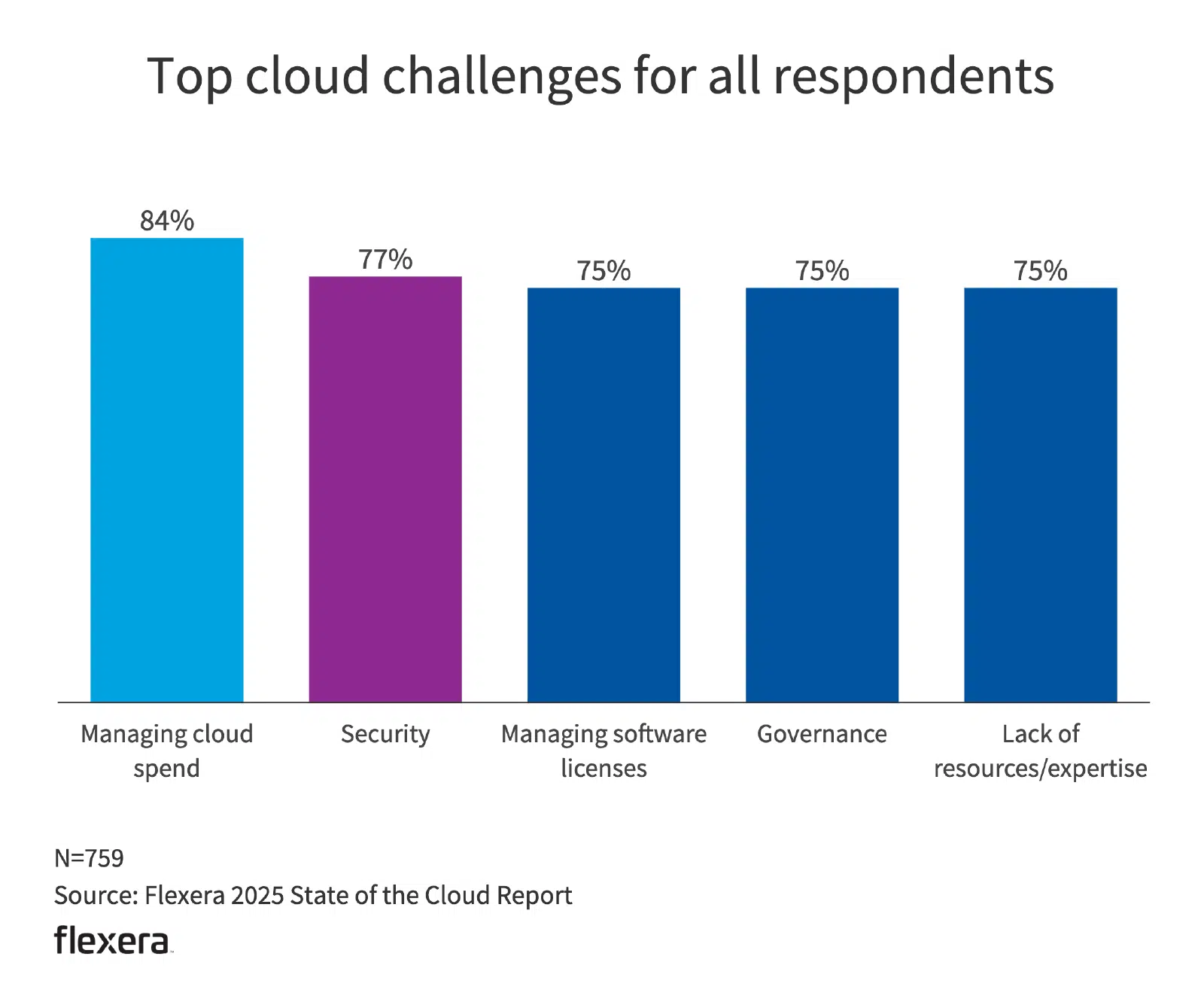
Un gráfico de barras que muestra por qué las empresas repatrían sus fondos
Los argumentos en contra y cuándo ganan los proveedores de servicios en la nube
No todos los observadores coinciden en que la repatriación de la nube sea la mejor opción para todas las organizaciones. Los entornos de nube pública siguen aportando valor en determinadas circunstancias. Sin embargo, estos argumentos no suelen ser muy sólidos en el caso de las cargas de trabajo de IA.
Cuándo es mejor la nube y cuándo es mejor la infraestructura local
| Componente | Ventajas de la nube | Ventajas de la solución local |
| Previsibilidad de la carga de trabajo | Gestiona cargas de trabajo irregulares o impredecibles | Las cargas de trabajo predecibles resultan más económicas si se alojan en servidores propios |
| Experiencia del equipo | Requiere unos conocimientos mínimos de infraestructura interna | Unos equipos de TI sólidos pueden optimizar los procesos y reducir la dependencia de los proveedores |
| Envergadura y crecimiento | Rápido crecimiento y expansión global | Un crecimiento predecible permite disponer de hardware rentable |
| Requisitos normativos | Cumplimiento normativo gestionado, redundancia geográfica | El control directo simplifica la armonización normativa |
| Costes y márgenes | El modelo de pago por uso reduce el gasto inicial | Ahorro a largo plazo gracias a la infraestructura propia |
| Calidad del servicio | Los acuerdos de nivel de servicio (SLA) en la nube garantizan la disponibilidad y el rendimiento | Los recursos dedicados garantizan un tiempo de actividad predecible |
El argumento del «uso incorrecto» de la nube
Jeremy Daly, defensor de la tecnología sin servidor, sostiene que «37signals estaba utilizando la nube de forma incorrecta». Al tratar los entornos en la nube como una coubicación virtual, ejecutando máquinas virtuales y Kubernetes, estaban pagando las tarifas de la nube sin aprovechar el valor de los servicios sin servidor, los servicios gestionados y el escalado instantáneo. Como señala Daly, «En la nube, deberíamos alquilar servicios, no servidores».
En el caso de las cargas de trabajo SaaS con un tráfico muy variable o con picos, este argumento resulta convincente. La infraestructura sin servidor permite a las organizaciones escalar al instante y pagar únicamente por la capacidad de procesamiento que realmente utilizan.
Sin embargo, las cargas de trabajo de inferencia de IA suelen comportarse de manera muy diferente. Los sistemas de inferencia en producción, como los modelos de recomendación, los copilotos y los flujos de trabajo de procesamiento de documentos, tienden a funcionar con una utilización constante y sostenida, en lugar de con picos impredecibles. En estos casos, la ventaja económica del escalado elástico en la nube se ve reducida. La prima que se paga por la capacidad de picos sigue existiendo, pero la propia carga de trabajo rara vez necesita esa capacidad.
Por lo tanto, el argumento de Daly es válido para las cargas de trabajo SaaS variables, en las que la elasticidad es fundamental. En el caso de cargas de trabajo de inferencia de IA continuas que se ejecutan con un alto nivel de utilización, pagar un sobreprecio por una capacidad de picos que rara vez se utiliza puede hacer que la infraestructura dedicada o las implementaciones híbridas resulten más rentables.
Análisis exhaustivo de los costes
Algunos críticos también cuestionan los supuestos financieros en los que se basa el enfoque de 37signals. Señalan que el hardware y el software suelen representar solo alrededor del 20 % de los costes de TI, mientras que el resto corresponde a electricidad, refrigeración, seguridad física, bastidores, sistemas de alimentación ininterrumpida (SAI) y costes de oportunidad. El análisis de David Heinemeier Hanson no incluyó todos estos gastos generales porque 37signals utilizaba instalaciones de coubicación en lugar de centros de datos de su propiedad. Aun así, teniendo en cuenta las cifras de 37signals, es razonable concluir que alquilar espacio de coubicación puede seguir siendo mucho más barato que recurrir a servicios en la nube.
Marco de competencia frente a crecimiento
El marco de Forrest Brazeal sobre la competencia en TI frente a las aspiraciones de crecimiento aporta matices adicionales. Sitúa a 37signals en el cuadrante de alta competencia/bajo crecimiento , ideal para el autoalojamiento. «No todas las empresas tienen la competencia (alta) o las aspiraciones de crecimiento (bajo) de 37signals», observa. Las startups con cargas de trabajo inciertas o irregulares se benefician de la flexibilidad de la nube, pero las empresas de IA que ejecutan inferencias de producción a gran escala suelen combinar una alta competencia operativa con un crecimiento constante. Estos perfiles (crecimiento constante y alta competencia) son muy adecuados para la repatriación.
Aplicación del manual de estrategias a la infraestructura de IA
Si 37signals proporcionó el modelo económico, la infraestructura de IA lo hace más concreto. La decisión ya no es abstracta. Se convierte en una evaluación estructurada basada en el comportamiento de la carga de trabajo, la utilización y el riesgo normativo.
Un práctico esquema de cuatro preguntas ayuda a traducir la lógica de 37signals al lenguaje de la IA:
1. ¿Tu carga de trabajo de inferencia es predecible y constante?
A diferencia de los picos de tráfico del SaaS, la mayoría de los sistemas de IA en producción, como los motores de recomendación, los flujos de trabajo RAG o los modelos de detección de fraudes, procesan volúmenes constantes con un crecimiento gradual.
2. ¿Se prevé que los índices de utilización de la GPU superen el 60-70 %?
En este umbral, la amortización del hardware propio suele resultar más económica que el precio de las GPU en la nube pública durante el primer año.
3. ¿Procesa entre 10 y 50 millones de consultas al mes?
A esta escala, los costes por token y por consulta de las API en la nube se acumulan rápidamente.
4. ¿Se enfrenta a requisitos de soberanía de datos o de cumplimiento normativo estricto?
En el caso de los servicios financieros, la asistencia sanitaria o las cargas de trabajo gubernamentales, los requisitos normativos pueden inclinar la balanza a favor de entornos controlados.
Si la respuesta es «sí» a tres o cuatro de estas preguntas, los aspectos económicos de la repatriación suelen favorecer la implementación local para la inferencia en producción.
Matriz de decisión
| Fase de carga de trabajo | Entorno recomendado | Justificación |
| Entrenamiento de modelos | Nube pública | Tareas que requieren un uso intensivo de recursos informáticos; las GPU en la nube gestionan las cargas de trabajo puntuales de forma rentable |
| Experimentación y creación de prototipos | Nube pública | Aprovisionamiento flexible y rápido para las primeras fases de desarrollo |
| Inferencia de producción | Local / Híbrido | Cargas de trabajo constantes; el hardware propio resulta más económico con una utilización de la GPU del 60-70 % o superior |
| Almacenamiento de vectores (incrustaciones) | En las instalaciones | Reduce los costes recurrentes de los servicios gestionados y garantiza el control de los datos |
El modelo híbrido de IA
En la práctica, la mayoría de las empresas de IA adoptan un modelo híbrido en lugar de un cambio radical. El entrenamiento sigue realizándose en la nube, mientras que la inferencia se traslada a una infraestructura propia.
Lenovo ha calculado que entrenar Llama 3.1 a hiperescala (39,3 millones de horas de GPU) en la nube superaría los 483 millones de dólares. Ese tipo de escalabilidad elástica a corto plazo es precisamente donde destaca la nube pública. La inferencia es diferente. Una vez que se entrena un modelo, mantenerlo en funcionamiento durante tres a cinco años se convierte en una tarea estable y predecible. Ahí es donde la economía del hardware amortizado lleva la ventaja.
Esta arquitectura dividida también reduce el riesgo asociado a la migración de datos. En lugar de trasladar todos los flujos de trabajo de IA de una sola vez, las organizaciones pueden migrar gradualmente las cargas de trabajo de inferencia en producción, dejando la experimentación y el entrenamiento en fase inicial en entornos en la nube. Un proceso de migración controlado y por fases reduce las interrupciones operativas, al tiempo que garantiza una integración fluida entre el entrenamiento basado en la nube y las capas de servicio locales.
Economía de la inferencia autohospedada
La rentabilidad de la inferencia autohospedada depende en gran medida de la utilización y del volumen de tokens. Según los datos de referencia de implementaciones empresariales, un modelo de 7.000 millones de parámetros que se ejecuta en una GPU H100 con una utilización aproximada del 70 % cuesta unos 10 000 dólares al año en nodos spot o en amortización de hardware. La energía cuesta unos 300 dólares al año, lo que eleva los costes totales a unos 10 300 dólares.
Las API públicas de LLM, por el contrario, suelen cobrar por cada millón de tokens; en 2025, los precios para empresas oscilarán entre 0,25 y 15 dólares por cada millón de tokens de entrada y entre 1,25 y 75 dólares por cada millón de tokens de salida, dependiendo del nivel del modelo y del proveedor.
Cuando los niveles de uso son bajos, las API siguen siendo la opción más económica, ya que la infraestructura permanece inactiva. Sin embargo, la rentabilidad cambia a medida que aumentan las cargas de trabajo. Los análisis del sector indican que la implementación autohospedada empieza a ser rentable a partir de unos dos millones de tokens al día, tras lo cual el coste fijo de la infraestructura propia se amortiza con un gran volumen de inferencias.
En entornos de gran volumen, la inferencia autohospedada puede reducir los costes hasta en un 78 %. El análisis de Artefact reveló que el umbral de rentabilidad se sitúa en torno a las 8.000 conversaciones al día. Por debajo de ese umbral, las API gestionadas en la nube siguen siendo más económicas. Por encima de él, la propiedad propia aumenta el ahorro. El patrón es similar al de 37signals: una carga de trabajo predecible más una alta utilización equivale a una rápida amortización.
Bases de datos vectoriales
Instacart ha documentado la migración de Elasticsearch más FAISS a PostgreSQL con pgvector, logrando un ahorro de costes del 80 % y una reducción de 10 veces en la amplificación de escritura. Las pruebas de rendimiento de pgvectorscale de Timescale muestran unos costes aproximadamente un 75 % más bajos que los servicios de vectores gestionados como Pinecone con un rendimiento comparable.
En el caso de los sistemas RAG que gestionan millones de consultas al mes, una infraestructura vectorial autohospedada genera un ahorro similar al del caso de 37signals con S3: las elevadas facturas recurrentes de almacenamiento se sustituyen por hardware amortizado y herramientas de código abierto.
La soberanía de los datos como motor estructural
Grandview Research informa de que el mercado de la nube soberana tuvo un valor de 648 870 millones de dólares en 2025 y se prevé que alcance los 648 870 millones de dólares en 2033. Además, según Gartner, se espera que alrededor del 60 % de las entidades financieras fuera de Estados Unidos adopten implementaciones soberanas o locales para 2028.
Marcos normativos como la Ley de IA de la UE, la Ley de Protección de la Información Personal (PIPL) de China y la Ley de Protección de Datos y Privacidad (DPDP) de la India exigen la localización y la trazabilidad de los datos. Para las organizaciones que tratan conjuntos de datos de entrenamiento sensibles o registros de inferencia propios, la implementación local cumple de por sí los requisitos de residencia, ya que los datos nunca salen de los límites jurisdiccionales.
Lo esencial
37signals demostró que los equipos de repatriación de la nube pueden medir, modelar y justificar sus decisiones con cifras concretas. Con una infraestructura de IA, los beneficios económicos pueden ser aún más notables. Si la repatriación de la nube supuso un ahorro de unos 10 millones de dólares para Basecamp, una empresa de IA equivalente que ejecute inferencias en producción a una escala similar podría ahorrar un múltiplo de esa cantidad, dado el coste mucho mayor de la computación con GPU y la infraestructura de integración.
Para las organizaciones que optan por ejecutar cargas de trabajo de IA en entornos controlados, plataformas como Actian VectorAI DB ofrecen una base de datos vectorial específica, diseñada para cargas de trabajo de búsqueda vectorial de gran volumen e inferencia de IA. Se puede implementar en las propias instalaciones o en la nube, lo que permite a las organizaciones ubicar la infraestructura vectorial donde mejor se adapte a sus necesidades operativas y económicas.
Únete a la comunidad y descubre más Acerca de Actian.

Mantente conectado
Te ofrecemos información detallada sobre los datos.
(por ejemplo, sales@..., support@...)