Can AI in Manufacturing Work Without the Cloud?





Summary
- Este tutorial muestra cómo crear un proceso RAG totalmente local para entornos de fabricación en los que el acceso a la nube está limitado por la arquitectura de red, los requisitos de latencia, los costes y las restricciones normativas.
- El proceso consta de tres fases: la importación de registros de mantenimiento en formato PDF a una base de datos vectorial, la recuperación de datos en el momento de la consulta mediante filtros de metadatos y un modelo de lenguaje grande (LLM) local que genera respuestas basadas en el contexto recuperado.
- Funciona íntegramente con el hardware de la planta de producción, utilizando VectorAI DB, Sentence Transformers para las representaciones y Ollama para la inferencia de modelos de lenguaje locales.
- Además, incluye funciones prácticas como el filtrado por línea de equipos y por fecha, el registro de auditoría para garantizar la trazabilidad y el funcionamiento local durante los cortes de suministro, sin necesidad de conexión a Internet.
- La conclusión principal es que la búsqueda de mantenimiento basada en la inteligencia artificial puede funcionar de forma segura dentro de entornos de tecnología operativa, lo que permite a los técnicos obtener respuestas rápidas y fundamentadas a partir de registros históricos sin necesidad de enviar datos fuera de la planta.
Mantener el tráfico externo fuera de las redes operativas es una práctica recomendada que la mayoría de las plantas de fabricación incorporan en su arquitectura desde el principio.
Las redes de fabricación utilizan el modelo Purdue, un sistema de cinco niveles que ha marcado el diseño de las redes industriales durante décadas. En el nivel más bajo se encuentran las máquinas físicas: sensores, motores y actuadores en el nivel 0; controladores en tiempo real y sistemas SCADA en el nivel 1; y servidores de supervisión y sistemas HMI en el nivel 2. El nivel 3 gestiona las operaciones. Los niveles 4 y 5 se conectan a la red de la empresa y a Internet.
La norma IEC 62443 establece límites estrictos entre estos niveles. El tráfico del Nivel 2 no llega a Internet. Para los contratistas de defensa, la normativa ITAR agrava el problema. Los datos técnicos deben permanecer en territorio estadounidense y ser accesibles únicamente para ciudadanos estadounidenses. Las bases de datos vectoriales alojadas en la nube, como Pinecone, Weaviate Cloud y Qdrant Cloud, incumplen ambos requisitos. El Nivel 2 no tiene forma de enviar esa solicitud, y otros sectores han aprendido esta lección por las malas.

La latencia agrava el problema. Los tiempos de ida y vuelta en la nube oscilan entre 50 y 500 milisegundos. Los bucles de control a nivel de PLC requieren respuestas en menos de 10 milisegundos. Los equipos que necesitan IA durante las interrupciones del servicio utilizan modelos de implementación en el borde diseñados para entornos sin conexión.
El coste supone un factor adicional. La tarifa estándar de AWS por transferencia de datos de salida parte de 0,09 dólares por GB. A cualquier escala de producción significativa, los datos de sensores y de visión se acumulan rápidamente, y la factura llega antes de lo que la mayoría de los equipos esperan.
La arquitectura, la latencia y el coste apuntan todos en la misma dirección. La IA en la planta de producción debe ejecutarse allí donde se encuentran los datos.
Este tutorial te muestra cómo crear un proceso RAG local que se ejecute íntegramente en el hardware de la planta de producción, donde un técnico puede plantear una pregunta sobre cualquier equipo y obtener una respuesta documentada basada en décadas de registros de mantenimiento, sin necesidad de conexión a Internet.
Lo que estás construyendo
Crearás un proceso RAG de tres capas que se ejecutará íntegramente dentro de la red de tu fábrica. La capa de ingesta procesa los documentos de mantenimiento en formato PDF y los almacena en la base de datos Actian VectorAI. La capa de consulta recibe la pregunta de un técnico y devuelve una respuesta documentada con la rapidez suficiente para su uso interactivo en los dispositivos de la planta de producción.
- Ingestión: Lee los documentos de mantenimiento en PDF, los divide en fragmentos de 256 tokens con un solapamiento de 25 tokens, genera incrustaciones utilizando transformadores de frases en una CPU y almacena todo en la base de datos VectorAI junto con metadatos sobre la línea de equipos, la fecha del documento y el archivo de origen.
- Consulta: Toma la pregunta de un técnico, la integra en el mismo modelo, realiza una búsqueda híbrida en la base de datos de VectorAI filtrada por línea de equipos y rango de fechas, y envía los resultados principales a un modelo de lenguaje grande (LLM) local que se ejecuta con Ollama, el cual genera una respuesta clara y concisa en un lenguaje sencillo.
- Auditoría: Registra cada evento de ingesta y consulta como una entrada JSON estructurada en el archivo ./data/audit.log, con marca de tiempo en UTC, y se almacena dentro de su perímetro de seguridad para cumplir los requisitos de trazabilidad de la norma IEC 62443.
VectorAI DB se sitúa en el centro de las tres capas. Almacena las representaciones generadas por la capa de ingesta y proporciona los resultados de búsqueda que genera la capa de consultas. Al ejecutarlo en las propias instalaciones en lugar de en la nube, todo el proceso se mantiene dentro de su perímetro de seguridad.
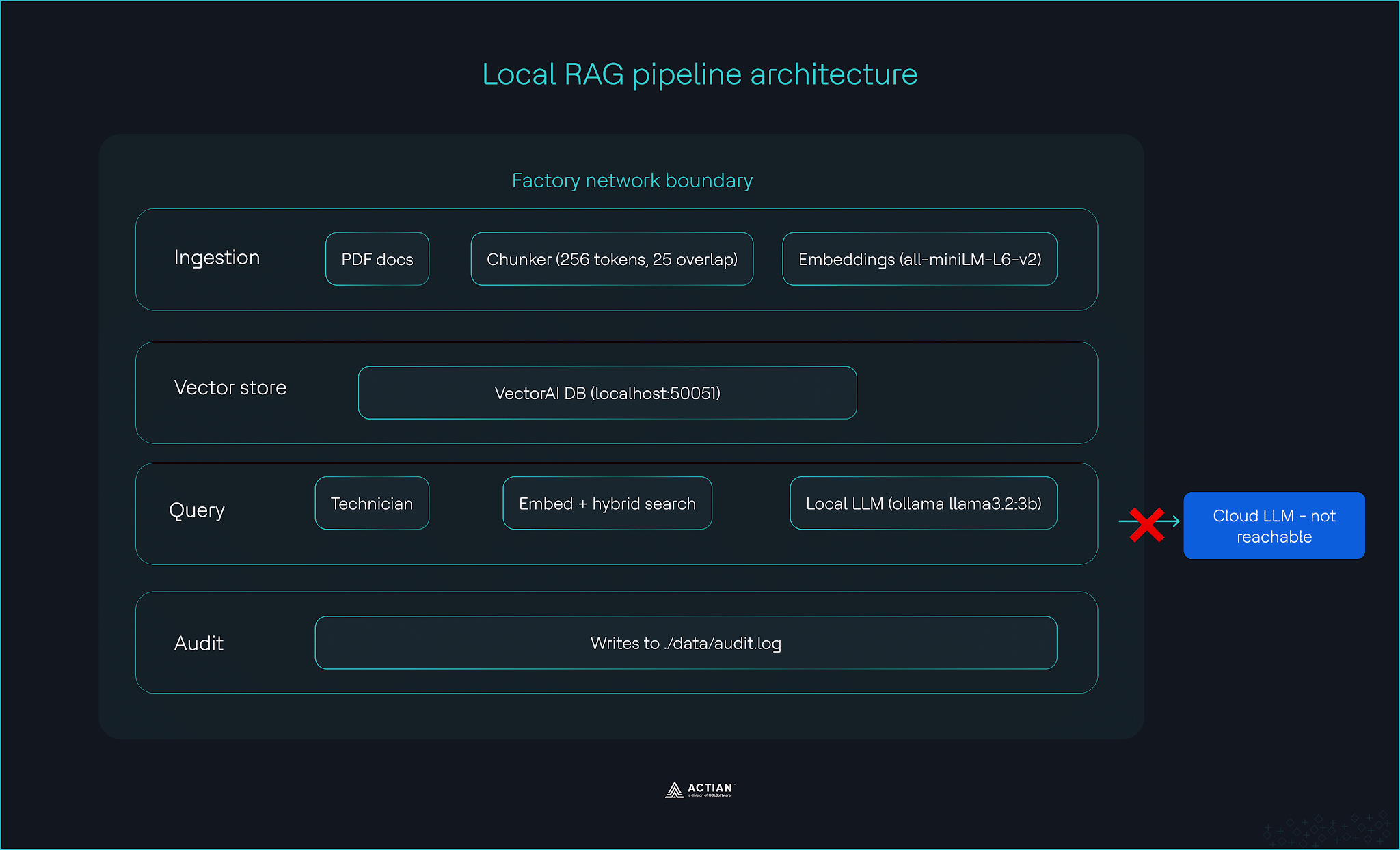
El proceso se ejecuta en hardware estándar de servidor periférico de fábrica, con Ubuntu 22.04 LTS, 16 GB de RAM y una CPU de cuatro núcleos.
Creación de un proceso RAG local con VectorAI DB
Configura VectorAI DB, crea el canal de ingesta, ejecuta tu primera consulta, añade filtros híbridos y conecta un modelo de lenguaje grande (LLM) local.
Requisitos previos
Regístrate en la edición comunitaria de VectorAI DB antes de empezar y, a continuación, asegúrate de tener instalados los siguientes programas:
- Docker y Docker Compose
- Python 3.10 o superior
- Gestor de paquetes UV. Instálalo con
curl -LsSf https://astral.sh/uv/install.sh | sh - Ollama. Instalar desde Ollama.com y arrastra el modelo con
ollama pull llama3.2:3b
Tu equipo necesita al menos 8 GB de RAM (se recomiendan 16 GB o más) y 10 GB de espacio en disco (se recomiendan 100 GB o más) para ejecutar VectorAI DB. Si utilizas Windows, el comando de instalación «uv» requiere «sh», algo de lo que carece PowerShell. Ejecuta todos los comandos en WSL2 (Subsistema de Windows para Linux). Para configurar WSL2, ejecuta «wsl –install» en PowerShell y, a continuación, utiliza el terminal de Ubuntu para este tutorial.
Estructura del proyecto
Configura la carpeta de tu proyecto de la siguiente manera:
factory-rag/
├── docker-compose.yml
├── data/
│ └── audit.log
├── config/
└── src/
├── healthcheck.py
├── ingest.py
├── query.py
├── llm.py
├── audit.py
└── test_e2e.pyCrea los directorios:
mkdir -p factory-rag/{data,config,src}
cd factory-ragPaso 1: Implementar VectorAI DB
Crea el archivo docker-compose.yml en el directorio raíz de tu proyecto:
services:
vectorai-db:
image: williamimoh/actian-vectorai-db:latest
platform: linux/amd64
container_name: vectorai-db
ports:
- "50051:50051"
volumes:
- ./data:/data
- ./config:/config
restart: unless-stopped
healthcheck:
test: ["CMD-SHELL", "nc -z localhost 50051 || exit 1"]
interval: 10s
timeout: 5s
retries: 5
start_period: 15sInicia el contenedor con:
docker compose up -dInstala el SDK con:
uv add actian_vectorai-0.1.0b2-py3-none-any.whlInstala estas bibliotecas necesarias:
uv add sentence-transformers pypdfComprueba que el servidor esté en funcionamiento. Crea un archivo llamado src/healthcheck.py:
from actian_vectorai import VectorAIClient
with VectorAIClient("localhost:50051") as client:
info = client.health_check()
print(f"✓ VectorAI DB is running")
print(f" Title: {info['title']}")
print(f" Version: {info['version']}")Ejecuta el script:
uv run python src/healthcheck.pySalida del terminal:

Paso 2: Crear el canal de ingesta
Guarda los documentos de mantenimiento en formato PDF en la carpeta «data/» antes de continuar con este paso. Añade allí cualquier registro de mantenimiento de equipos, informe de inspección o registro de averías.
El proceso utiliza «sentence-transformers/all-MiniLM-L6-v2», que requiere menos de 200 MB de RAM en la CPU. Dividimos el texto en fragmentos de 256 tokens con un solapamiento de 25 tokens para mantener suficiente contexto y garantizar una buena recuperación.
Crea el archivo src/ingest.py:
from __future__ import annotations
import argparse
import uuid
from pathlib import Path
from actian_vectorai import Distance, PointStruct, VectorAIClient, VectorParams
from pypdf import PdfReader
from sentence_transformers import SentenceTransformer
from audit import log_ingestion
COLLECTION = "maintenance_records"
HOST = "localhost:50051"
MODEL_NAME = "sentence-transformers/all-MiniLM-L6-v2"
VECTOR_DIM = 384
CHUNK_TOKENS = 256
OVERLAP_TOKENS = 25
def chunk_text(text, tokenizer, chunk_size=CHUNK_TOKENS, overlap=OVERLAP_TOKENS):
token_ids = tokenizer.encode(text, add_special_tokens=False)
chunks = []
start = 0
while start < len(token_ids):
end = min(start + chunk_size, len(token_ids))
window = token_ids[start:end]
decoded = tokenizer.decode(window, skip_special_tokens=True).strip()
if decoded:
chunks.append(decoded)
if end >= len(token_ids):
break
start += chunk_size - overlap
return chunks
def ingest_pdf(pdf_path, equipment_line, doc_date, model, client):
reader = PdfReader(str(pdf_path))
full_text = "\n".join(page.extract_text() or "" for page in reader.pages)
if not full_text.strip():
print(f" [warn] No extractable text in {pdf_path.name}, skipping.")
return 0
tokenizer = model.tokenizer
chunks = chunk_text(full_text, tokenizer)
points = []
for idx, chunk in enumerate(chunks):
embedding = model.encode(chunk, show_progress_bar=False).tolist()
points.append(
PointStruct(
id=str(uuid.uuid5(uuid.NAMESPACE_DNS, f"{pdf_path.name}:{idx}")),
vector=embedding,
payload={
"equipment_line": equipment_line,
"doc_date": doc_date,
"source_file": pdf_path.name,
"text": chunk,
"chunk_index": idx,
},
)
)
if points:
client.points.upsert(COLLECTION, points)
return len(points)
def main(data_dir, equipment_line, doc_date):
data_path = Path(data_dir)
pdfs = sorted(data_path.glob("*.pdf"))
if not pdfs:
print(f"No PDF files found in '{data_dir}'. Add PDFs to ./data/ and retry.")
return
print(f"Loading embedding model '{MODEL_NAME}'...")
model = SentenceTransformer(MODEL_NAME)
with VectorAIClient(HOST) as client:
if not client.collections.exists(COLLECTION):
client.collections.create(
COLLECTION,
vectors_config=VectorParams(size=VECTOR_DIM, distance=Distance.Cosine),
)
print(f"Created collection '{COLLECTION}' ({VECTOR_DIM}-dim, Cosine)")
else:
print(f"Collection '{COLLECTION}' already exists, appending chunks.")
total = 0
for pdf_path in pdfs:
print(f"Ingesting {pdf_path.name} ...")
count = ingest_pdf(pdf_path, equipment_line, doc_date, model, client)
print(f" → {count} chunks stored")
log_ingestion(pdf_path.name, equipment_line, count)
total += count
print(f"\nDone. {total} total chunks stored in '{COLLECTION}'.")
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Ingest PDFs into VectorAI DB")
parser.add_argument("--data-dir", default="./data")
parser.add_argument("--equipment-line", required=True)
parser.add_argument("--doc-date", required=True)
args = parser.parse_args()
main(args.data_dir, args.equipment_line, args.doc_date)Ejecuta el paso de ingesta:
uv run python src/ingest.py --equipment-line turbine-A --doc-date 2024-03-15Resultado esperado:

El esquema de metadatos guarda la línea de equipo, la fecha del documento y el archivo de origen junto con cada fragmento. Esto te permite filtrar las búsquedas por línea de equipo o intervalo de fechas sin tener que buscar en toda la colección.
Paso 3: Ejecuta tu primera consulta
Tu canal de ingestión ha almacenado los registros de mantenimiento en la base de datos VectorAI. El canal puede responder a preguntas. Cuando un técnico formula una pregunta en lenguaje coloquial, el canal incorpora la pregunta, busca en la colección «maintenance_records» y devuelve los cinco fragmentos más relevantes junto con sus puntuaciones de similitud.
Crea el archivo src/query.py:
from __future__ import annotations
import argparse
import time
from actian_vectorai import Field, FilterBuilder, VectorAIClient
from sentence_transformers import SentenceTransformer
from audit import log_query
COLLECTION = "maintenance_records"
HOST = "localhost:50051"
MODEL_NAME = "sentence-transformers/all-MiniLM-L6-v2"
TOP_K = 5
def build_filter(equipment_line=None, doc_date=None, doc_date_to=None):
fb = FilterBuilder()
if equipment_line:
fb.must(Field("equipment_line").eq(equipment_line))
if doc_date and doc_date_to:
fb.must(Field("doc_date").range(gte=doc_date, lte=doc_date_to))
elif doc_date:
fb.must(Field("doc_date").eq(doc_date))
return fb.build() if (equipment_line or doc_date) else None
def search(question, equipment_line=None, doc_date=None, doc_date_to=None):
model = SentenceTransformer(MODEL_NAME)
embedding = model.encode(question, show_progress_bar=False).tolist()
query_filter = build_filter(equipment_line, doc_date, doc_date_to)
with VectorAIClient(HOST) as client:
hits = client.points.search(
COLLECTION,
vector=embedding,
limit=TOP_K,
filter=query_filter,
)
return [
{
"score": round(r.score, 4),
"source_file": r.payload.get("source_file", ""),
"equipment_line": r.payload.get("equipment_line", ""),
"doc_date": r.payload.get("doc_date", ""),
"chunk_index": r.payload.get("chunk_index", -1),
"text": r.payload.get("text", ""),
}
for r in hits
]
def main():
parser = argparse.ArgumentParser(description="Search maintenance records")
parser.add_argument("question", help="Natural language question")
parser.add_argument("--equipment-line", default=None)
parser.add_argument("--doc-date", default=None)
parser.add_argument("--doc-date-to", default=None)
args = parser.parse_args()
start = time.monotonic()
results = search(args.question, equipment_line=args.equipment_line,
doc_date=args.doc_date, doc_date_to=args.doc_date_to)
latency_ms = (time.monotonic() - start) * 1000
log_query(args.question, args.equipment_line or "", results, latency_ms)
if not results:
print("No results found.")
return
print(f"Top {len(results)} results for: \"{args.question}\"\n")
for i, r in enumerate(results, 1):
print(f"[{i}] score={r['score']:.4f} {r['source_file']} "
f"(chunk {r['chunk_index']}) {r['doc_date']} {r['equipment_line']}")
print(f" {r['text'][:200].strip()}...")
print()
if __name__ == "__main__":
main()Prueba con tu primera consulta:
uv run python src/query.py "What caused the bearing failure?"La búsqueda utiliza el mismo modelo que la ingesta para integrar la consulta, manteniendo tanto la consulta como los vectores almacenados en el mismo espacio semántico. En el caso de los registros de mantenimiento con este modelo, las puntuaciones de similitud comprendidas entre 0,4 y 0,6 indican coincidencias relevantes.
Paso 4: Añadir filtros híbridos
Filtrar por línea de equipos y fecha ayuda a que los resultados de la búsqueda sean relevantes para el trabajo actual del técnico. Realice la misma consulta del paso 3, pero añada estos filtros:
uv run python src/query.py "What caused the bearing failure?" --equipment-line turbine-AAñade un filtro de fecha para acotar aún más los resultados:
uv run python src/query.py "What caused the bearing failure?" --equipment-line turbine-A --doc-date 2024-03-15Resultado esperado:

La función `build_filter` crea una consulta `FilterBuilder` que combina la similitud vectorial con la coincidencia exacta de metadatos. Un técnico que trabaje en la turbina A solo verá los resultados correspondientes a esa línea de equipos, y no a todo el historial de mantenimiento.
Paso 5: Conecta el LLM local
Los resultados de la búsqueda se envían a un modelo de lenguaje grande (LLM) local que se ejecuta a través de Ollama, el cual genera una respuesta clara y concisa en un lenguaje sencillo. Todo el proceso se ejecuta en el propio hardware de la planta de producción.
Crea el archivo src/llm.py:
from __future__ import annotations
import json
import os
import sys
import urllib.request
from typing import Any
OLLAMA_HOST = os.environ.get("OLLAMA_HOST", "https://localhost:11434")
OLLAMA_MODEL = "llama3.2:3b"
MAX_NEW_TOKENS = 256
TEMPERATURE = 0.1
TIMEOUT_SECONDS = 300
def build_prompt(question: str, results: list[dict[str, Any]]) -> str:
if not results:
return f"Question: {question}\n\nAnswer: I have no relevant context to answer this question."
context_blocks = []
for i, r in enumerate(results, 1):
source = r.get("source_file", "unknown")
date = r.get("doc_date", "unknown")
equip = r.get("equipment_line", "unknown")
text = r.get("text", "").strip()
context_blocks.append(
f"[{i}] Source: {source} | Equipment: {equip} | Date: {date}\n{text}"
)
context = "\n\n".join(context_blocks)
return (
"You are a maintenance records assistant. "
"Answer the question using ONLY the provided context. "
"Cite sources inline using [1], [2], etc. "
"If the context does not contain enough information, say so.\n\n"
f"Context:\n{context}\n\n"
f"Question: {question}\n\n"
"Answer:"
)
def generate(question: str, results: list[dict[str, Any]]) -> str:
prompt = build_prompt(question, results)
payload = json.dumps({
"model": OLLAMA_MODEL,
"prompt": prompt,
"stream": False,
"options": {
"num_predict": MAX_NEW_TOKENS,
"temperature": TEMPERATURE,
},
}).encode()
req = urllib.request.Request(
f"{OLLAMA_HOST}/api/generate",
data=payload,
headers={"Content-Type": "application/json"},
method="POST",
)
with urllib.request.urlopen(req, timeout=TIMEOUT_SECONDS) as resp:
body = json.loads(resp.read().decode())
return body["response"].strip()
def answer(question: str, results: list[dict[str, Any]]) -> str:
reply = generate(question, results)
print(reply)
print()
print("Sources")
for i, r in enumerate(results, 1):
print(
f" [{i}] {r.get('source_file', '?')} "
f"(chunk {r.get('chunk_index', '?')}, score {r.get('score', 0):.4f}) "
f"{r.get('doc_date', '?')} / {r.get('equipment_line', '?')}"
)
return reply
if __name__ == "__main__":
question = sys.argv[1] if len(sys.argv) > 1 else "What maintenance was performed?"
dummy_results = [
{
"source_file": "example.pdf",
"doc_date": "2024-03-15",
"equipment_line": "turbine-A",
"chunk_index": 0,
"score": 0.95,
"text": (
"Performed scheduled bearing inspection on turbine-A. "
"Replaced worn bearing race on shaft 2. "
"Torque settings verified per spec TRB-004."
),
}
]
answer(question, dummy_results)Conecta todo creando el archivo src/test_e2e.py:
from query import search
from llm import answer
question = "What maintenance was performed on the gearbox?"
results = search(question, equipment_line="turbine-A")
answer(question, results)Ejecuta el proceso completo:
uv run python src/test_e2e.pyllama3.2:3b cabe en la memoria de un servidor periférico estándar de fábrica. El modelo de lenguaje grande (LLM) solo recibe los fragmentos recuperados como contexto, y no la colección completa de documentos, lo que garantiza que las respuestas sean rápidas y se basen en las fuentes citadas.
Resultado esperado:
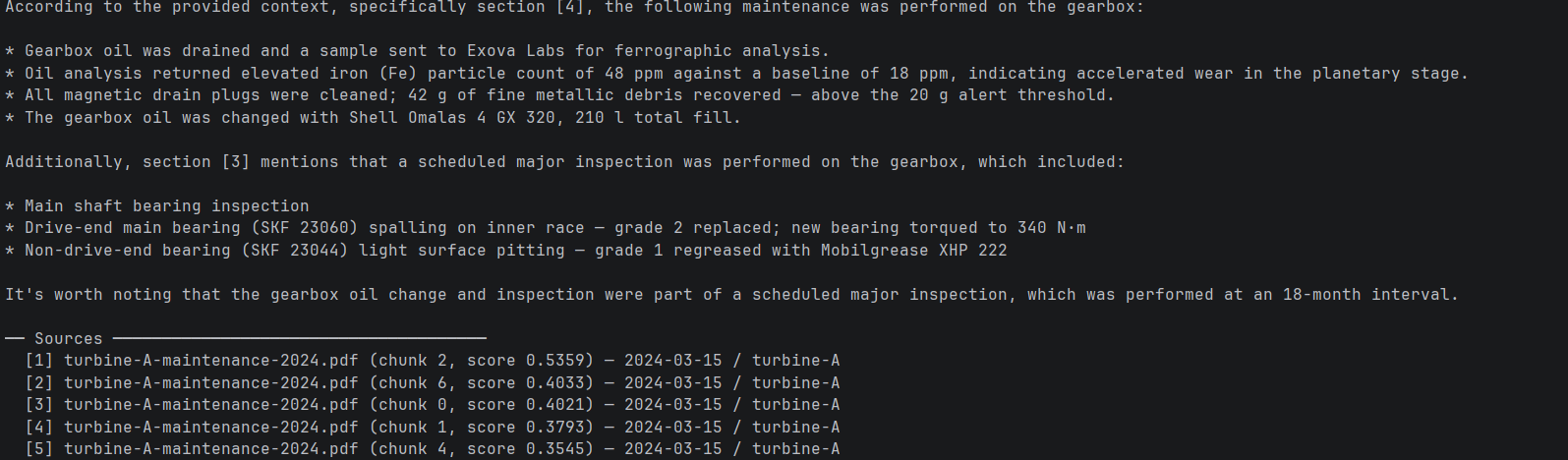
El sistema ya está plenamente operativo. Un técnico puede plantear una pregunta, obtener una respuesta documentada a partir de los registros de mantenimiento locales y no tener que recurrir en ningún momento a Internet.
Paso 6: Añadir el registro de auditoría
La norma IEC 62443 exige una trazabilidad completa de todas las operaciones que se realizan en la red OT. Sin un registro de auditoría local, su canalización no dispone de ningún registro de qué se consultó, cuándo ni qué resultados se obtuvieron.
Crea el archivo src/audit.py:
from __future__ import annotations
import json
import logging
from datetime import datetime, timezone
from pathlib import Path
LOG_PATH = Path("./data/audit.log")
LOG_PATH.parent.mkdir(parents=True, exist_ok=True)
handler = logging.FileHandler(str(LOG_PATH))
handler.setLevel(logging.INFO)
logger = logging.getLogger("actian_vectorai.audit")
logger.setLevel(logging.INFO)
logger.addHandler(handler)
def log_query(question: str, equipment_line: str, results: list, latency_ms: float) -> None:
entry = {
"event": "query",
"timestamp": datetime.now(tz=timezone.utc).isoformat(),
"question": question,
"equipment_line": equipment_line,
"results_returned": len(results),
"latency_ms": round(latency_ms, 2),
}
logger.info(json.dumps(entry))
def log_ingestion(source_file: str, equipment_line: str, chunks_stored: int) -> None:
entry = {
"event": "ingestion",
"timestamp": datetime.now(tz=timezone.utc).isoformat(),
"source_file": source_file,
"equipment_line": equipment_line,
"chunks_stored": chunks_stored,
}
logger.info(json.dumps(entry))Ejecuta el script de auditoría con este comando:
cat data/audit.logResultado esperado:

Ahora, el canal de datos mantiene un registro estructurado de cada evento de ingesta y consulta en el archivo ./data/audit.log, con marca de tiempo en UTC y almacenado dentro de su perímetro de seguridad.
Conclusión
Acabas de crear un canal RAG local que funciona íntegramente con el hardware de la planta de producción, atiende consultas durante los cortes de red y ofrece respuestas extraídas de décadas de registros de mantenimiento.
La IA en el sector manufacturero puede funcionar sin conexión a la nube. VectorAI DB lo hace posible al ejecutarse íntegramente dentro del perímetro de seguridad de la norma IEC 62443, sin depender de la nube. Aunque se corte por completo la conexión a Internet, el proceso sigue funcionando.
Tu canaliza la ingesta de documentos de mantenimiento en formato PDF, almacena las representaciones en la base de datos VectorAI en el nivel 2 de tu red OT y responde a preguntas en lenguaje natural utilizando un modelo de lenguaje grande (LLM) local, sin depender de la nube en ninguna fase del proceso. A partir de aquí, puedes ampliar el canal añadiendo más tipos de documentos, ajustando el modelo de representación al vocabulario específico de tu equipo, incorporando filtros de consulta basados en el rol del técnico o ampliando la ingesta a múltiples líneas de equipos.
Consulta la documentación completa de VectorAI DB y el repositorio de GitHub para obtener más información.
Únete a la comunidad y descubre más Acerca de Actian.

Stay connected
Data insights delivered to you.
(i.e. sales@..., support@...)