Convierte tus documentos internos en una base de conocimientos basada en IA





Summary
- RAG permite realizar búsquedas en la documentación combinando la recuperación semántica con un modelo de lenguaje grande (LLM) que responde basándose únicamente en el contexto del documento recuperado.
- El proceso consta de tres pasos principales: dividir los documentos en fragmentos e indexarlos, recuperar los fragmentos más relevantes mediante una búsqueda vectorial y, a continuación, generar una respuesta fundamentada a partir de esos fragmentos.
- La búsqueda de vectores densos funciona convirtiendo el texto en representaciones vectoriales, lo que permite encontrar contenido semánticamente similar incluso cuando la redacción es diferente.
- Este enfoque resulta útil para la documentación técnica, las bases de conocimientos de asistencia técnica, las búsquedas relacionadas con el cumplimiento normativo, la incorporación de nuevos usuarios, la búsqueda en transcripciones y los catálogos de productos.
- La principal ventaja es que obtienes respuestas rápidas y fundamentadas a partir de tu propio contenido, sobre todo cuando todo el proceso se ejecuta en tu propia infraestructura, lo que te garantiza privacidad y control.
El problema de la documentación
Todas las organizaciones que cuentan con un producto, un proceso o un requisito de cumplimiento se enfrentan al mismo reto: la información existe, pero no es accesible. Un ingeniero de soporte técnico que atiende una llamada no puede buscar en 400 páginas de documentación en tiempo real. Un empleado nuevo no puede asimilar tres años de guías internas en su primera semana. Un cliente no puede encontrar el parámetro de configuración específico que se encuentra en la página 247 de un PDF.
La búsqueda tradicional es útil, pero requiere palabras clave exactas. Si escribes «¿Cómo soluciono el error 12?» cuando el documento dice «código de estado 12: MicroKernel no puede encontrar el archivo especificado», la búsqueda por palabras clave no da resultado. Necesitas una búsqueda semántica, es decir, una búsqueda que comprenda el significado, no solo las palabras.
Idea clave: La respuesta ya está en tu documentación. El reto es hacer que sea fácil de encontrar: al instante, con precisión y sin confusiones.
Cómo funciona RAG
La generación aumentada por recuperación (RAG) distingue entre dos problemas que los modelos de lenguaje grande (LLM) tienen dificultades para resolver: conocer el contenido específico y razonar sobre él. La RAG aborda el problema del conocimiento mediante la recuperación. El LLM aborda el problema del razonamiento mediante la generación.
El proceso en tres pasos:
- Indexa tus documentos. Los documentos se dividen en fragmentos. Cada fragmento se convierte en una representación vectorial mediante un modelo de lenguaje, y tanto el vector como el texto original se almacenan en una base de datos vectorial.
- Recuperar el contexto relevante. Cuando un usuario formula una pregunta, esta se integra utilizando el mismo modelo. La base de datos vectorial encuentra los fragmentos de documentos más similares desde el punto de vista semántico, independientemente de la redacción exacta.
- Genera una respuesta fundamentada. Los fragmentos más relevantes se envían a un modelo de lenguaje grande (LLM) como contexto. El modelo los lee y responde basándose únicamente en lo que se le ha proporcionado. Sin alucinaciones: solo razonamiento a partir de tus documentos reales.
Ventaja en materia de privacidad: Con Actian VectorAI y Ollama, todo el proceso se ejecuta en tus propios servidores. Tus documentos, consultas y respuestas nunca salen de tu infraestructura.
¿Qué es la búsqueda en vectores densos?
Cuando un modelo de incrustación procesa un texto, lo convierte en una lista de números —un vector— en la que la posición en un espacio de alta dimensión codifica el significado semántico. Los textos con un significado similar terminan ocupando posiciones similares. Esta es la base de la búsqueda densa.
El modelo «nomic-embed-text», utilizado en esta guía, convierte cualquier texto en 768 números. Estas dimensiones no son legibles para el ser humano. Se trata de representaciones aprendidas que surgen del entrenamiento con miles de millones de ejemplos de texto. El modelo aprende que «no se puede encontrar el archivo» y «archivo no encontrado» deben generar vectores similares, aunque no compartan ninguna palabra en común.
En el momento de la búsqueda, el vector de consulta se compara con cada vector de documento almacenado utilizando la similitud coseno, una medida del ángulo entre dos vectores. Cuanto menor es el ángulo, mayor es la similitud y más relevante es el resultado. El índice HNSW agiliza esta comparación, incluso con millones de vectores.
| Entrada | Similitud |
| Consulta: «estado de corrección 12» | — (vector de consulta) |
| Doc: «12: MicroKernel no encuentra…» | 0,94 — muy relevante |
| Doc: «Crystal Reports para Zen…» | 0,12 — no es relevante |
Arquitectura del sistema
El proceso RAG denso consta de dos fases. La fase de indexación se ejecuta una sola vez, o de forma programada cuando se producen cambios en los documentos. La fase de consulta se ejecuta con cada solicitud de los usuarios y suele completarse en menos de 200 ms.
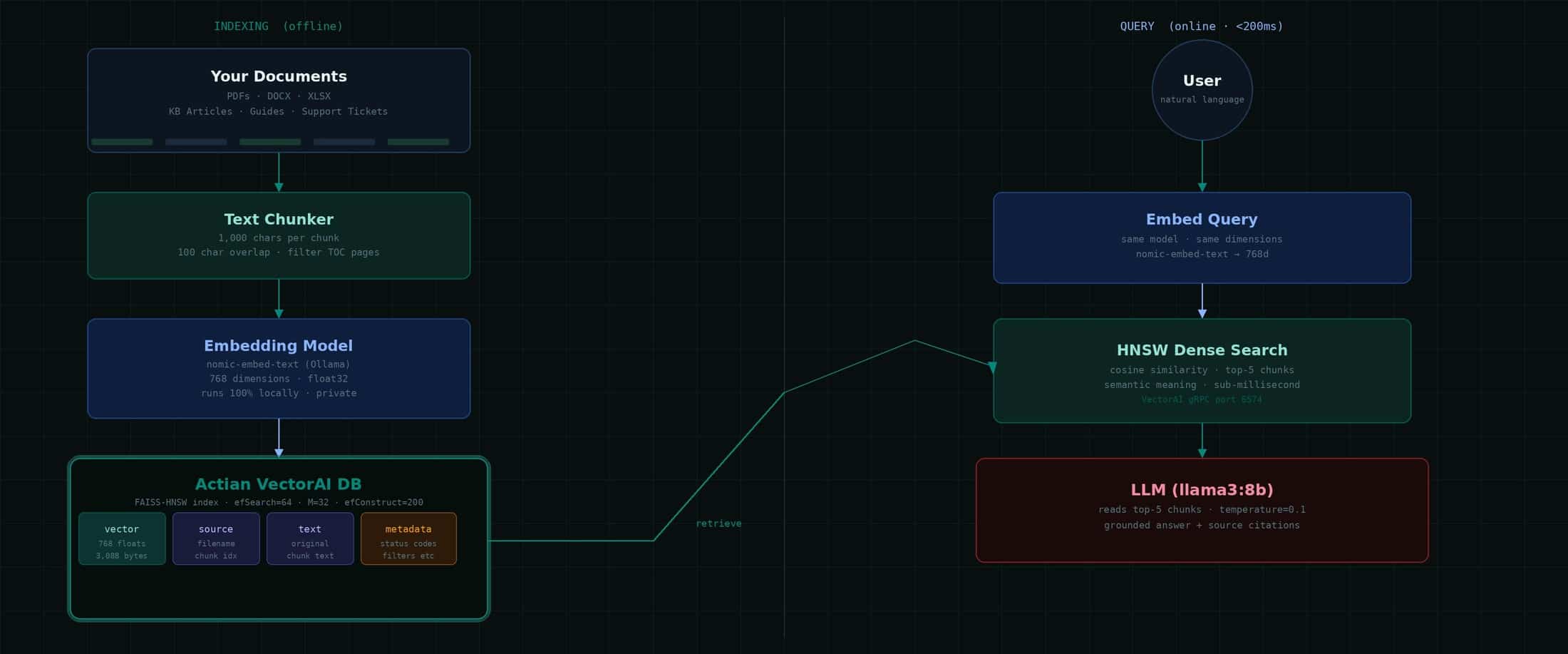
Fíjate en este detalle fundamental: se utiliza el mismo modelo de incrustación tanto para la indexación como para las consultas. Si indexas con nomic-embed-text, debes realizar las consultas con nomic-embed-text. Los vectores solo tienen sentido en relación con el modelo que los ha creado. Cambiar de modelo requiere una reindexación completa.
Cómo almacena VectorAI tus datos
La base de datos Actian VectorAI almacena vectores en un motor de almacenamiento en columnas de alto rendimiento que utiliza FAISS para la indexación. Cada vector se almacena como números de 32 bits en coma flotante, el estándar del sector para las representaciones de aprendizaje automático. Con 768 dimensiones, eso supone exactamente 3.088 bytes por vector, tal y como se confirma en el registro del motor:
# Confirmed from vde.log on a production deployment
[VectorStore::CreateFile] Created file: vectors.db
(dim=768, record_len=3088)
# The math:
768 dimensions x 4 bytes (float32) = 3,072 bytes
+ 16 bytes overhead
= 3,088 bytes per vector (confirmed)Datos sobre el almacenamiento — verificados a partir de los registros de producción:
| Parámetro | Valor | Notas |
| Algoritmo de indexación | FAISS HNSW | Búsqueda por similitud con IA de Facebook |
| Infraestructura de almacenamiento | Archivos Vector DB | Almacenamiento empresarial de probada eficacia |
| Formato vectorial | float32 (4 bytes) | Estándar del sector para el aprendizaje automático |
| Tamaño del registro (resolución = 768) | 3.088 bytes | 768 x 4 + 16 de gastos generales |
| Tamaño del registro (dim=384) | 1.552 bytes | 384 x 4 + 16 gastos generales |
| Límite del segmento | 2 GB por segmento | Se amplía automáticamente a nuevos segmentos |
| Límite de tamaño de archivo | Ninguno | Limitado únicamente por el espacio en disco |
| HNSW efSearch | 64 | Candidatos evaluados por consulta |
| HNSW efConstruct | 200 | Candidatos durante la creación del índice |
| HNSW M | 32 | Conexiones por nodo |
El motor de almacenamiento divide los archivos automáticamente en segmentos de 2 GB, por lo que no existe un límite práctico en el número de vectores. La capacidad de almacenamiento viene determinada exclusivamente por el espacio disponible en disco. A razón de 3.088 bytes por vector, un terabyte de almacenamiento permite almacenar aproximadamente 340 millones de vectores.
Casos prácticos
Búsqueda de documentación técnica. Indexa manuales de productos, referencias de API y guías de configuración. Los usuarios formulan preguntas en lenguaje sencillo y obtienen respuestas con citas exactas de documentos y referencias de páginas.
Base de conocimientos de asistencia técnica. Indexa los tickets de asistencia y las resoluciones anteriores. Cuando llega un nuevo caso, muestra automáticamente casos similares anteriores y sus soluciones, lo que reduce significativamente el tiempo de resolución.
Búsqueda de políticas y normas de cumplimiento. Permite buscar al instante documentos legales y políticas de cumplimiento. Siempre cita la cláusula o sección específica que se aplica a la pregunta del usuario.
Incorporación de empleados. Los nuevos empleados plantean preguntas sobre las políticas, los procesos y las herramientas de RR. HH. El sistema responde basándose en tu documentación interna real: de forma personalizada, precisa y siempre actualizada.
Búsqueda en vídeo y audio. Transcribe vídeos de formación y reuniones con Whisper, indexa las transcripciones y busca contenido hablado por significado, con enlaces directos a la marca de tiempo exacta.
Catálogo de productos. Consulte las especificaciones de los productos, las tablas de compatibilidad y las notas de la versión. Los equipos de ventas obtienen respuestas precisas al instante durante las llamadas con los clientes sin tener que interrumpir la conversación.
Creación del proceso
Paso 1: divide tus documentos en partes
La agrupación por bloques de 1.000 caracteres con un solapamiento de 100 caracteres funciona bien para la documentación técnica. El solapamiento garantiza que las frases nunca se corten en un límite:
def chunk_text(text: str, chunk_size=1000, overlap=100) -> list:
"""Split text into overlapping character-based chunks."""
chunks, i = [], 0
while i < len(text):
chunk = text[i : i + chunk_size].strip()
if len(chunk) > 80: # skip near-empty chunks
chunks.append(chunk)
i += chunk_size - overlap
return chunksPaso 2: Crear una colección y un índice
from actian_vectorai import VectorAIClient, VectorParams, Distance, PointStruct
import requests
def embed(text: str) -> list:
r = requests.post("https://localhost:11434/api/embeddings",
json={"model": "nomic-embed-text", "prompt": text})
return r.json()["embedding"]
with VectorAIClient("192.168.x.x:6574") as client:
client.collections.create(
"my_docs",
vectors_config=VectorParams(size=768, distance=Distance.Cosine)
)
for i, chunk in enumerate(chunks):
client.points.upsert("my_docs", [PointStruct(
id = i,
vector = embed(chunk),
payload = {"source": "doc.pdf", "chunk": i, "text": chunk}
)])La función de consulta RAG completa
import requests
from actian_vectorai import VectorAIClient
VECTOR_SERVER = "192.168.x.x:6574"
OLLAMA = "https://localhost:11434"
COLLECTION = "my_docs"
def rag_query(question: str, top_n: int = 5) -> dict:
# Step 1: Embed the question
query_vec = embed(question)
# Step 2: Search VectorAI DB
with VectorAIClient(VECTOR_SERVER) as c:
results = c.points.search(
COLLECTION, vector=query_vec,
limit=top_n, with_payload=True,
)
# Step 3: Build context from retrieved chunks
context = "\n\n---\n\n".join(
r.payload["text"] for r in results)
# Step 4: Ask the LLM with grounded context
prompt = f"""You are a knowledgeable assistant.
Answer using ONLY the documentation excerpts below.
Documentation: {context}
Question: {question}
Answer:"""
resp = requests.post(f"{OLLAMA}/api/chat", json={
"model": "llama3:8b", "stream": False,
"options": {"temperature": 0.1, "num_predict": 1024},
"messages": [{"role": "user", "content": prompt}]
})
answer = resp.json()["message"]["content"].strip()
# Step 5: Return answer + citations
sources = list({r.payload["source"] for r in results})
return {"answer": answer, "sources": sources}¿Por qué una temperatura de 0,1? En el caso de preguntas y respuestas basadas en hechos, lo que se busca son respuestas deterministas y precisas. Una temperatura baja hace que el LLM se centre en lo que realmente dice la documentación, en lugar de extrapolar o adornar la información.
Datos clave — Implementación en producción
| Métrico | Valor |
| Dimensiones de incrustación | 768 |
| Bytes por vector | 3,088 |
| Algoritmo de indexación | HNSW (FAISS) |
| Modelo de integración | nomic-embed-text (Ollama) |
| Máster en Derecho | llama3:8b (Ollama) |
| Puerto gRPC | 6574 |
| Infraestructura | 100 % en las propias instalaciones |
Respuestas basadas en tu contenido
El RAG de vectores densos con la base de datos Actian VectorAI convierte la documentación estática en una base de conocimientos que se puede consultar al instante. El proceso es sencillo: divide los documentos en fragmentos, incrústalos con nomic-embed-text, almacénalos en el índice FAISS-HNSW de VectorAI y deja que el modelo de lenguaje grande (LLM) responda a partir del contexto que recupere la búsqueda.
Dado que todo se ejecuta en tu propia infraestructura, tus documentos nunca salen de tu red. Cada respuesta se basa en tu contenido real, no en lo que un modelo haya aprendido durante el entrenamiento.
Más información Acerca de Actian DB.
Desarrollado con Actian VectorAI DB · FAISS-HNSW · Almacenamiento de alto rendimiento · Ollama · llama3:8b
Todas las consultas se ejecutan al 100 % en las instalaciones. Ningún documento, consulta o respuesta sale de su infraestructura.

Stay connected
Data insights delivered to you.
(i.e. sales@..., support@...)