Las 5 mejores bibliotecas de bases de datos vectoriales para Python





Summary
- Los problemas de rendimiento en las bases de datos vectoriales suelen deberse a incompatibilidades entre los paquetes, las API y el entorno, y no a la velocidad.
- La arquitectura del cliente (nube, OSS, integrada, extensión) influye en la escalabilidad y en el éxito de la implementación.
- Factores clave: estabilidad de la API, fiabilidad de la instalación, compatibilidad con la asincronía y claridad en la depuración.
- Qdrant ofrece una gran paridad entre el entorno local y el de producción; Pinecone simplifica el uso de la nube.
- La base de datos Actian VectorAI destaca por su estabilidad, portabilidad y capacidad de implementación en entornos empresariales.
La mayoría de las comparaciones entre bibliotecas de bases de datos vectoriales de Python se centran en la velocidad de recuperación, los algoritmos de indexación o los resultados de las pruebas de rendimiento. Estos parámetros son importantes, pero los fallos en producción se deben a diversos factores: inconsistencias en la instalación, diferencias en los paquetes de los clientes, cambios frecuentes de versión y modificaciones inesperadas en la API. En realidad, surge una clase diferente de problemas una vez que la aplicación sale del entorno del cuaderno y se ejecuta dentro de un servicio de producción.
Un ejemplo típico se da en las configuraciones de ChromaDB integradas. Un proyecto puede funcionar perfectamente durante el desarrollo, pero fallar en producción con un error como:
RuntimeError: Chroma running in http-only client modeUn conflicto estructural entre el chromadb and chromadb-client Los paquetes provocan este error porque el paquete «solo para el cliente» carece de las funciones de integración predeterminadas de las que depende la aplicación. Diagnosticar este problema puede llevar horas.
Las opciones de configuración del cliente y las decisiones de diseño de la biblioteca, y no la calidad de la recuperación ni el rendimiento de la indexación, son las que provocan este tipo de fallos.
Este artículo compara las principales bibliotecas de bases de datos vectoriales de Python desde esa perspectiva, analizando la arquitectura del cliente, la estabilidad de la instalación, el diseño de la API y la facilidad de mantenimiento a largo plazo, en lugar de limitarse únicamente a las cifras de las pruebas de rendimiento.
TL;DR
- ChromaDB: La configuración más rápida para entornos de prototipado y de cuadernos, con una configuración mínima.
- Pinecone: Solución en la nube totalmente gestionada sin gastos de gestión de infraestructura.
- Qdrant: Sin cambios en el código desde el desarrollo local hasta la producción; la mejor opción de código abierto para la estabilidad de las API.
- Weaviate: Búsqueda híbrida que combina la similitud vectorial y el filtrado por palabras clave a gran escala.
- Actian VectorAI DB: Implementación local con la misma arquitectura desde el portátil hasta la producción; Actian la ha diseñado para entornos periféricos y aislados.
El panorama de Python: conocer las opciones
La relación entre una biblioteca de bases de datos vectoriales de Python y su backend de almacenamiento determina cómo desarrollarás, probarás y, en última instancia, escalarás tu aplicación. Elegir una biblioteca inadecuada suele provocar los fallos específicos del entorno descritos anteriormente, ya que cada arquitectura gestiona los entornos locales y de producción de forma diferente.
Estas diferencias suelen clasificarse en cuatro categorías distintas, cada una con su propio enfoque respecto a la interacción entre la infraestructura y el código.
Cuatro arquitecturas de cliente
- Solo en la nube (p. ej., Pinecone): Estos clientes actúan como una abstracción completa de la API para entornos sin servidor. La principal ventaja es que no hay que gestionar la infraestructura, pero esto requiere una conexión a Internet activa y una clave de API para todo el desarrollo y las pruebas locales.
- Software de código abierto con opción gestionada (por ejemplo, Qdrant, Weaviate, Milvus): este conjunto de herramientas utiliza la misma API tanto para instancias de Docker autohospedadas como para servicios gestionados en la nube. Esto ofrece una excelente paridad entre el entorno de desarrollo y el de producción, aunque a menudo requiere gestionar un servidor local o un contenedor de Docker durante el desarrollo.
- Bibliotecas integradas (por ejemplo, ChromaDB, FAISS): Estas herramientas se ejecutan dentro del proceso e integran la lógica de la base de datos en tu aplicación de Python. Aunque son ideales para cuadernos de trabajo y la creación rápida de prototipos, sus desarrolladores nunca las concibieron para entornos de producción distribuidos, y no ofrecen una ruta de migración bien definida a medida que la aplicación crece.
- Enfoque de extensión (por ejemplo, pgvector a través de Timescale Vector): este modelo añade capacidades de búsqueda vectorial a las bases de datos relacionales tradicionales. Permite que la infraestructura existente de PostgreSQL admita la búsqueda de similitud vectorial. Sin embargo, el rendimiento de las consultas varía en función de la configuración del índice, el tamaño del conjunto de datos y las características de la carga de trabajo; algunos escenarios se benefician de la base relacional, mientras que otros se adaptan mejor a arquitecturas vectoriales diseñadas específicamente para ese fin.
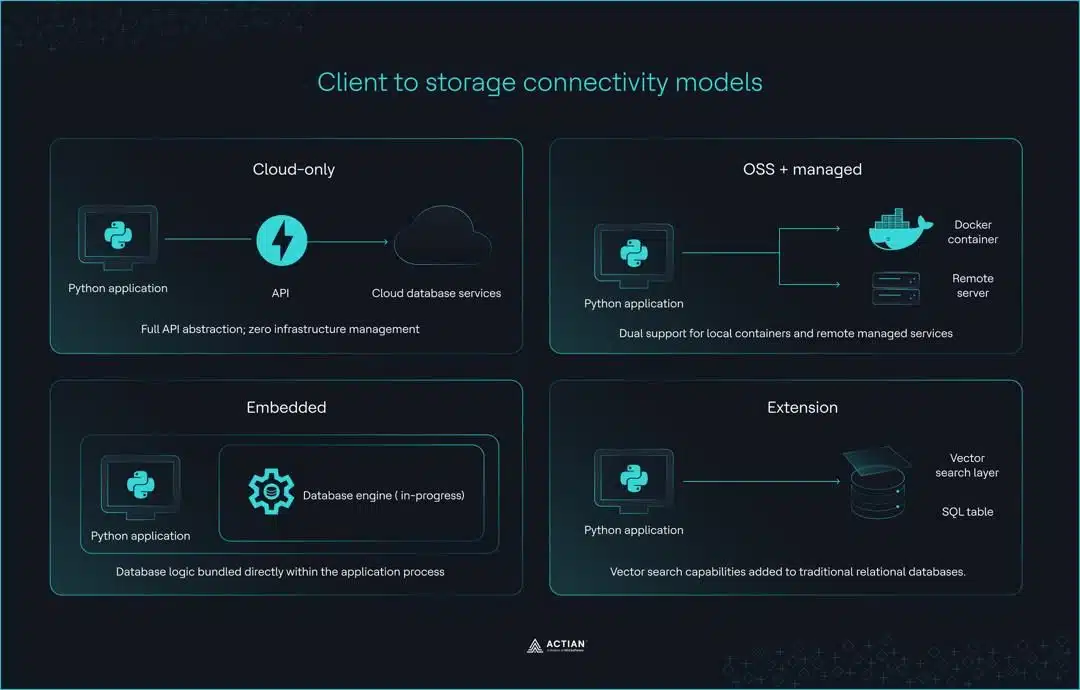
Estos cuatro modelos describen cómo se conecta un cliente al almacenamiento, pero también ponen de manifiesto una distinción práctica entre las bibliotecas de búsqueda independientes y los sistemas de bases de datos gestionados. Elegir el modelo incorrecto genera algunos de los problemas más recurrentes en las aplicaciones de búsqueda vectorial.
Una base de datos vectorial proporciona la infraestructura necesaria para la producción, y va más allá de lo que ofrecen las bibliotecas independientes de los desarrolladores. Bibliotecas como FAISS o Annoy son herramientas estáticas que funcionan en memoria y se centran en la búsqueda aproximada del vecino más cercano en grandes conjuntos de datos. Son muy eficaces para la búsqueda de similitudes dentro de un espacio vectorial fijo, pero no pueden gestionar datos a lo largo del tiempo.
Las bases de datos especializadas como Pinecone, Qdrant o Milvus van más allá, ya que ofrecen compatibilidad completa con CRUD, filtrado basado en metadatos y persistencia distribuida para grandes conjuntos de datos.
La siguiente tabla resume dónde encaja cada arquitectura en los casos de uso más habituales.
| Categoría | Compromiso principal | Plan de migración de la producción |
| Solo en la nube | No requiere gestión de infraestructura; necesita conexión a la red y autenticación mediante API en todos los entornos | El mismo código de cliente tanto en el entorno de desarrollo como en el de producción |
| Software de código abierto + gestionado | La misma API para implementaciones locales y en la nube; requiere Docker o la configuración de un servidor | Sin cambios en el código entre la instancia local de Docker y el servicio gestionado en la nube |
| Embedded | Ejecución en tiempo real con una configuración mínima; limitada a una arquitectura de una sola máquina | Es necesario sustituir la clase de cliente; la implementación distribuida requiere un rediseño |
| Extensión | Se integra con la infraestructura de PostgreSQL; el rendimiento varía en función de la configuración | Depende de la configuración actual de PostgreSQL y de los requisitos de escalabilidad |
Comparación de clientes: análisis en profundidad de la experiencia del desarrollador
La arquitectura limita las opciones, pero la experiencia diaria al trabajar con una biblioteca de bases de datos vectoriales en Python se reduce a cómo gestiona cada cliente la configuración de la conexión, la estabilidad de las versiones y los puntos conflictivos que surgen durante el desarrollo activo.
A continuación comparamos los cuatro clientes basándonos en lo que los desarrolladores se encuentran en la práctica.
1. Cliente Pinecone Python
Pinecone ofrece una de las experiencias de conexión más pulidas entre los clientes de bases de datos vectoriales exclusivamente en la nube, con numerosas sugerencias de tipos y un patrón de inicialización sencillo.
from pinecone import Pinecone
pc = Pinecone(api_key="your-api-key")
index = pc.Index("your-index-name")Puntos fuertes:
- Amplias sugerencias de tipos y compatibilidad con la función de autocompletado del IDE.
- Pinecone introdujo la compatibilidad con AsyncIO en la versión 6 a través de Pinecone Asyncio.
- El modo gRPC ofrece un mayor rendimiento para cargas de trabajo exigentes.
- Documentación oficial en buen estado.
Puntos débiles:
- Pinecone lanzó tres versiones principales en 18 meses (v5, v6 y v7), introduciendo cambios que afectaban a la compatibilidad con versiones anteriores en la lógica de conexión y cambiando el nombre del paquete de «pinecone-client» a «pinecone».
- Confusión histórica entre los paquetes «pinecone» y «pinecone-client».
- Las operaciones asíncronas de query_namespaces bajo carga requieren un ajuste del grupo de subprocesos.
2. Cliente de Weaviate para Python
El cliente v4 de Weaviate supone un avance significativo con respecto a la v3, ya que incorpora clases tipadas y compatibilidad con gRPC, lo que mejora notablemente el rendimiento de las consultas.
import weaviate
client = weaviate.connect_to_local()
collection = client.collections.get("your-collection-name")Puntos fuertes:
- El modo gRPC ofrece un rendimiento de las consultas entre un 40 % y un 70 % más rápido que la versión 3.
- Las clases de propiedades tipadas y DataType sustituyen a los diccionarios sin tipar de la versión 3.
- Búsqueda híbrida integrada que combina la búsqueda vectorial y la búsqueda por palabras clave.
- Amplio soporte para cargas de trabajo multitenencia.
Puntos débiles:
- Weaviate ha dejado de dar soporte a la API v3, y los equipos informan de que la migración requiere semanas de trabajo.
- gRPC requiere que el puerto 50051 esté abierto, lo que supone un obstáculo en entornos de red con restricciones.
- El rediseño de la API de lotes provocó una gran confusión (Incidencia n.º 433).
- LangChain no incorporó la compatibilidad con la versión 4 hasta varios meses después del lanzamiento de Weaviate (Incidencia n.º 14531).
3. Cliente de Python para ChromaDB
ChromaDB ofrece una de las experiencias de iniciación más sencillas entre las bibliotecas de bases de datos vectoriales para Python, lo que la convierte en un punto de partida ideal para cuadernos de trabajo y la creación de prototipos en las primeras fases.
import chromadb
client = chromadb.Client()Puntos fuertes:
- La interfaz de programación de aplicaciones (API) más sencilla de todos los clientes incluidos en esta comparación.
- Integración consolidada de LangChain con ejemplos bien documentados.
- El modo en memoria no requiere ninguna configuración en entornos de portátiles.
- Una comunidad de código abierto amplia y activa.
Puntos débiles:
- Incompatibilidad con Python 3.13 (Incidencia n.º 3651).
- Inestabilidad de Windows con más de 99 registros (Incidencia n.º 3058).
- Confundir «chromadb» con «chromadb-client» provoca fallos en las implementaciones de producción.
- Errores de compilación de hnswlib en procesadores Mac ARM.
- Requiere SQLite 3.35 o superior, lo que supone una carga adicional en la configuración específica del entorno.
4. Cliente de Python de Qdrant
Los desarrolladores valoran Qdrant por su paridad entre el entorno local y el de producción. El mismo código de cliente se ejecuta en una instancia en memoria durante el desarrollo y en una implementación en la nube totalmente gestionada en producción, sin necesidad de modificaciones.
from qdrant_client import QdrantClient
client = QdrantClient(":memory:")Puntos fuertes:
- El modo :memory: permite un flujo de trabajo de la versión local a la de producción sin necesidad de modificar el código.
- Qdrant ha presentado un AsyncQdrantClient nativo para cargas de trabajo de alta concurrencia.
- Seguridad de tipos de Pydantic en toda la interfaz de cliente.
- Implementación basada en Rust con una menor carga de memoria en comparación con las alternativas basadas en la JVM.
Puntos débiles:
- Los desarrolladores deben establecer explícitamente prefer_grpc=True para habilitar gRPC, un paso que suelen pasar por alto.
- La división del puerto entre REST (6333) y gRPC (6334) requiere una configuración de red cuidadosa.
- Restricciones de versión de Pydantic: solo v1.10.x o v2.21 y versiones posteriores.
- Problemas de conexión a la nube (Incidencia n.º 112).
Cuándo elegir Qdrant:
- La paridad entre el entorno local y el de producción es una prioridad, y es fundamental que no haya cambios en el código entre entornos.
- Las cargas de trabajo asíncronas con alta concurrencia requieren compatibilidad nativa con AsyncQdrantClient.
- Prefieres una implementación de una base de datos vectorial de código abierto y autohospedada en lugar de un servicio gestionado en la nube.
- La búsqueda híbrida, que combina vectores densos y dispersos, es un requisito fundamental.
Cuándo evitar Qdrant:
- El equipo no tiene experiencia con Docker y necesita una configuración local más sencilla.
- El entorno de destino no admite la configuración de red de gRPC.
- Las restricciones de versión de Pydantic entran en conflicto con las dependencias existentes del proyecto.
Instalación y gestión del entorno
En condiciones ideales, instalar una biblioteca de bases de datos vectoriales para Python es muy sencillo. Sin embargo, en la práctica, la plataforma de destino, la versión de Python y las dependencias de los paquetes existentes introducen variables que pueden convertir una simple instalación con pip en una sesión de depuración de varias horas. Merece la pena realizar una rápida comprobación de compatibilidad antes de comprometerse con un cliente, ya que la mayoría de estos problemas solo salen a la luz una vez finalizada la configuración.
La tabla de compatibilidad
La siguiente matriz muestra el comportamiento de los clientes en Python 3.8–3.13 en macOS ARM, Windows y Linux.
| Cliente | macOS ARM (M1/M2) | Windows | Linux (Debian) | Python 3.13 |
| Piña | ✓ Asistencia completa | ✓ Asistencia completa | ✓ Asistencia completa | ✓ Compatible |
| Weaviate | ✓ Asistencia completa | ✓ Asistencia completa | Requiere Docker para gRPC | ✓ Compatible |
| ChromaDB | Errores de compilación de hnswlib | Inestabilidad por encima de 99 registros (n.º 3058) | Requiere Debian Bookworm+ | ✗ No funciona (#3651) |
| Cuadrante | ✓ Asistencia completa | ✓ Asistencia completa | ✓ Asistencia completa | ✓ Compatible |
ChromaDB es el cliente que presenta mayores problemas de compatibilidad de todos los incluidos en esta comparación. En macOS con procesadores ARM, hnswlib genera errores de compilación durante la instalación, lo que obliga a los desarrolladores a fijar manualmente la versión de Python en 3.11 o 3.12.
En Windows, ChromaDB deja de funcionar correctamente cuando una colección supera los 99 registros, lo que hace que el cliente integrado no sea adecuado para nada más allá de la fase inicial de creación de prototipos. En Linux, las distribuciones basadas en Debian requieren Bookworm o una versión posterior para instalar y ejecutar ChromaDB sin problemas.
Buenas prácticas en entornos virtuales
python -m venv venv
source venv/bin/activate # On Windows: venv\Scripts\activate
pip install chromadbEs igualmente importante especificar la versión del cliente en un archivo requirements.txt, ya que varios de estos clientes suelen introducir cambios que rompen la compatibilidad entre versiones secundarias.
chromadb==0.4.x
qdrant-client==1.7.x
pinecone==3.x
weaviate-client==4.xLa arquitectura de dos paquetes de ChromaDB confunde a muchos desarrolladores. Cuando alguien instala «chromadb-client» en lugar de «chromadb», la aplicación muestra este error la primera vez que intenta llamar a la función de incrustación predeterminada.
ValueError: You must provide an embedding functionExtras y dependencias opcionales
# Pinecone with gRPC support
pip install pinecone[grpc]
# Qdrant with FastEmbed for local embedding generation
pip install qdrant-client[fastembed]
# ChromaDB with sentence-transformers for local embedding support
pip install chromadb sentence-transformersgRPC es el factor que más influye en el rendimiento de las consultas cuando se instala de forma opcional. Weaviate registra consultas entre un 40 % y un 70 % más rápidas con gRPC que con REST, mientras que Qdrant mejora la velocidad de las consultas en aproximadamente un 15 %. La contrapartida es que gRPC requiere una configuración de red adicional, lo que puede no ser viable en entornos con restricciones.
Tanto FastEmbed como sentence-transformers permiten generar representaciones locales sin depender de una API externa, lo que reduce la latencia y los costes de las representaciones en tareas de búsqueda semántica y de similitud.
El AsyncQdrantClient nativo de Qdrant y el PineconeAsyncio de Pinecone ofrecen un aumento del rendimiento de entre 3 y 5 veces en cargas de trabajo con alta concurrencia.
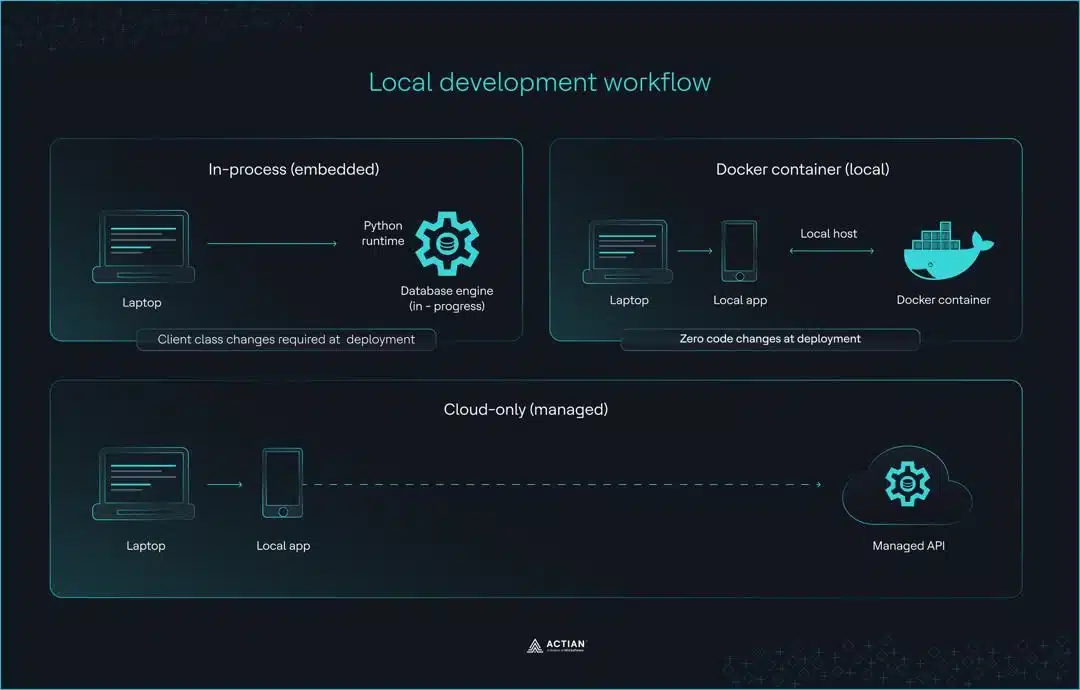
Flujos de trabajo de desarrollo local
Los desarrolladores toman la mayoría de las decisiones relativas a las bases de datos vectoriales en el entorno de desarrollo local. La pregunta clave es: ¿qué cliente requiere menos cambios en el código al pasar a producción?
La ruta de migración
A continuación se explica cómo gestiona cada cliente la transición de la implementación local a la fase de producción.
# Qdrant - zero code changes required
client = QdrantClient(":memory:") # Development
client = QdrantClient( # Production
url="https://your-cluster-url",
api_key="your-api-key"
)
# ChromaDB - client class change required
client = chromadb.Client() # Development
client = chromadb.HttpClient( # Production
host="your-host",
port=8000
)
# Pinecone - same code in both environments
pc = Pinecone(api_key="your-api-key") # Development and production
index = pc.Index("your-index-name")
Cuadrante :memory: Este modo mantiene el mismo código de cliente desde el desarrollo local hasta la fase de producción. La configuración del almacén vectorial, los ajustes de similitud coseno y los parámetros del índice hnsw se mantienen iguales en todos los entornos.
ChromaDB requiere una modificación en la clase del cliente al pasar a producción. Cuanto más se utilice el cliente en el código, mayor será el alcance de este cambio en la aplicación.
Pinecone utiliza el mismo código tanto en el entorno de desarrollo como en el de producción, ya que todo se ejecuta en la nube independientemente de la fase en la que se encuentre.
Estas diferencias en la migración se deben a tres enfoques distintos de desarrollo local: el modo integrado, Docker y el exclusivo en la nube.
Modo integrado
El cliente integrado predeterminado de ChromaDB almacena los datos únicamente en memoria. Cuando la aplicación deja de ejecutarse, los datos se pierden. Para desarrollos que impliquen colecciones persistentes, PersistentClient en su lugar, escribe los datos en el disco.
# In-memory only: data lost when process ends
client = chromadb.Client()
collection = client.create_collection("my_collection")
collection.add(documents=["doc1", "doc2"], ids=["1", "2"])
# Persistent local storage
client = chromadb.PersistentClient(path="/local/path")
De Qdrant :memory: Este modo utiliza la misma interfaz de cliente que una implementación en producción. Cualquier código que funcione localmente también funciona en producción sin necesidad de modificaciones.
client = QdrantClient(":memory:")
client.create_collection(
collection_name="my_collection",
vectors_config=VectorParams(size=384, distance=Distance.COSINE)
)
Ambos clientes funcionan bien para la creación de prototipos iniciales y en entornos de portátiles, y las diferencias solo se hacen evidentes en la fase de producción.
Docker para el desarrollo local
Docker ejecuta la base de datos vectorial en un contenedor local aislado utilizando la misma configuración que en una implementación de producción. Qdrant y Weaviate son dos bases de datos vectoriales de código abierto que admiten este enfoque.
# Qdrant
docker run -p 6333:6333 qdrant/qdrant
# Weaviate
docker run -p 8080:8080 -p 50051:50051 cr.weaviate.io/semitechnologies/weaviate:latest
Una vez que el contenedor está en funcionamiento, el cliente se conecta a localhost del mismo modo que lo haría a una base de datos Vector autohospedada en producción.
# Qdrant
client = QdrantClient(url="https://localhost:6333")
# Weaviate
client = weaviate.connect_to_local()
La principal ventaja es que la configuración del índice vectorial se comporta de la misma manera tanto en el entorno local como en el de producción, y los problemas que surgen en el entorno local son problemas reales y no meros artefactos propios del entorno.
La contrapartida es la carga que supone la instalación de Docker y la configuración de los puertos, en particular el requisito de Weaviate de disponer de ambos puertos 8080 and 50051.
Desarrollo exclusivamente en la nube
Ecosistema de integración: LangChain y LlamaIndex
from langchain_pinecone import PineconeVectorStore
from langchain_chroma import Chroma
from langchain_qdrant import QdrantVectorStore
from langchain_weaviate import WeaviateVectorStore
from llama_index.vector_stores.qdrant import QdrantVectorStore- El cliente lanza una nueva versión con cambios que implican incompatibilidades.
- Más adelante habrá una actualización de LangChain y LlamaIndex.
- Las tuberías se rompen temporalmente.
Consideraciones sobre el rendimiento: más allá de la velocidad pura
La mayoría de las comparativas de clientes pasan por alto tres factores que influyen de manera significativa en el rendimiento de las bases de datos vectoriales: la elección del protocolo, la calidad de la compatibilidad con la asincronía y el uso de grupos de conexiones.
Elección del protocolo: REST frente a gRPC
gRPC y REST son los dos protocolos de transporte disponibles en estos clientes. Como se ha mencionado anteriormente, Weaviate registra un aumento de entre el 40 % y el 80 % en la velocidad de las consultas con gRPC, mientras que Qdrant gana aproximadamente un 15 % en velocidad de consulta con gRPC habilitado. En entornos de red restringidos donde el puerto 50051 si no es accesible, REST es la opción más práctica.
Calidad de la compatibilidad con la asincronía
La mayoría de los equipos desarrollan aplicaciones de modelos de lenguaje a gran escala (LLM) en producción utilizando FastAPI o marcos asíncronos similares, lo que hace que la compatibilidad con clientes asíncronos sea un factor importante a tener en cuenta en cuanto al rendimiento. El uso de un cliente síncrono dentro de una aplicación asíncrona da lugar a llamadas bloqueantes, lo que reduce drásticamente el rendimiento.
Nativo de Qdrant AsyncQdrantClient, disponible desde la versión 1.61, ofrece una implementación asíncrona consolidada. Pinecone introdujo PineconeAsyncio en la versión 6, lo que aporta una compatibilidad asíncrona adecuada a las cargas de trabajo de búsqueda vectorial exclusivamente en la nube. Weaviate incorporó la compatibilidad asíncrona en la versión 4.7, lo que la convierte en la más reciente de las cuatro en alcanzar capacidades asíncronas listas para producción. La compatibilidad asíncrona de ChromaDB sigue siendo limitada en las cuatro.
La diferencia en el rendimiento es considerable. En el caso de las cargas de trabajo limitadas por la E/S, en las que la latencia de la red constituye el cuello de botella, los clientes asíncronos suelen ofrecer un rendimiento entre tres y cinco veces superior al de sus equivalentes síncronos.
Agrupación de conexiones y gestión de recursos
Esta es una de las áreas de configuración en las que los ajustes predeterminados suelen resultar insuficientes en entornos de producción. Tanto Qdrant como Pinecone ofrecen parámetros que permiten un mayor control sobre la gestión de las conexiones en condiciones de tráfico de producción sostenido.
# Qdrant connection pool configuration
client = QdrantClient(
url="https://your-cluster-url",
api_key="your-api-key",
timeout=30,
pool_size=10
)
# Pinecone connection pool configuration
index = pc.Index(
"your-index-name",
pool_threads=30,
connection_pool_maxsize=30
)
Para Pinecone, query_namespaces necesita un ajuste pool_threads and connection_pool_maxsize para cargas de trabajo de producción. En el caso de Qdrant, el aumento de pool_size Un valor superior al predeterminado reduce la congestión de conexiones en las aplicaciones que gestionan grandes volúmenes de incrustaciones de documentos en paralelo.
Los equipos que ajustan estos parámetros antes de la implementación evitan dedicar un tiempo considerable a la depuración cuando la aplicación se ejecuta bajo carga.
Gestión de errores y depuración
Las bibliotecas de bases de datos vectoriales gestionan una gran complejidad a nivel interno. Cuando se produce un error, la claridad con la que el cliente comunica dicho error determina la rapidez con la que los equipos pueden solucionarlo.
Calidad de los mensajes de error
La calidad de los mensajes de error varía considerablemente entre los cuatro clientes.
Pinecone genera mensajes de error claros y prácticos que suelen incluir una sugerencia de solución junto con la descripción del fallo, lo que reduce el tiempo que los equipos dedican a buscar la causa raíz.
Los mensajes de error de Qdrant son útiles y señalan directamente el origen del problema. La excepción UnexpectedResponse incluye un campo de motivo específico que identifica exactamente qué parámetro no ha superado la validación.
qdrant_client.http.exceptions.UnexpectedResponse: Status 400, reason: "Wrong input: Vector dimension error: expected dim: 384, got 768"Los mensajes de error de ChromaDB suelen ser vagos y requieren una búsqueda en GitHub para diagnosticarlos. Cuando se produce la confusión entre los dos paquetes, ChromaDB genera un ValueError indicando que faltan funciones de incrustación, en lugar de señalar la causa real del problema. El requisito de la versión de SQLite genera un error igualmente poco útil:
RuntimeError: Your system has an unsupported version of sqlite3. Chroma requires sqlite3 >= 3.35.0.Este error es un obstáculo habitual para los desarrolladores de Python que realizan implementaciones en entornos antiguos de Amazon Linux 2 o Streamlit.
Weaviate v3 fallaba de forma silenciosa, devolviendo objetos nulos o diccionarios con una clave «errors» que los desarrolladores tenían que comprobar manualmente. La reescritura de la versión v4 solucionó este problema mediante excepciones tipadas, como WeaviateQueryError and WeaviateGRPCUnavailableError.
Registro y observabilidad
Las funciones de observabilidad varían según los cuatro clientes.
- Qdrant admite el registro estructurado, el rastreo distribuido y las métricas sin necesidad de configuración adicional, lo que lo convierte en una opción ideal para aplicaciones de aprendizaje automático en producción que requieren visibilidad sobre el rendimiento de los motores de búsqueda vectorial.
- Pinecone ofrece funciones básicas de registro a través de su infraestructura gestionada.
- ChromaDB cuenta con un sistema de registro limitado y sin una salida estructurada, lo que dificulta considerablemente el diagnóstico de problemas en las aplicaciones de IA en producción.
Errores habituales y soluciones
Hay tres tipos de errores que se repiten en los cuatro clientes en entornos de producción.
- Las incompatibilidades entre versiones del cliente provocan fallos frecuentes e inesperados, especialmente en el contexto de las tres versiones lanzadas por Pinecone en 18 meses y la migración de Weaviate de la versión 3 a la 4. Los equipos pueden controlar esto fijando las versiones del cliente en un
requirements.txtarchivo. - La incompatibilidad de dimensiones de incrustación se produce cuando las dimensiones de incrustación de la consulta no se ajustan a las expectativas de la colección. Esto se puede evitar comprobando que el tamaño de salida del modelo de incrustación coincida con la configuración de la colección antes de la implementación.
- La limitación de velocidad afecta a las implementaciones exclusivamente en la nube en Pinecone y Weaviate Cloud. La implementación de un retroceso exponencial en las llamadas a la API es la solución estándar para las cargas de trabajo en producción que se acercan a los límites de velocidad en condiciones de tráfico sostenido.
La frecuencia con la que surgen incompatibilidades entre versiones, el alcance de las incompatibilidades entre plataformas y la claridad con la que los mensajes de error informan de los fallos determinan, en conjunto, el coste real de mantenimiento de un cliente en producción.
Los continuos cambios de versión en Pinecone, Weaviate y ChromaDB han llevado a muchos equipos de producción a buscar un cliente que anteponga la estabilidad operativa a la rapidez en la incorporación de nuevas funciones. Actian VectorAI DB da respuesta directa a esta necesidad.
Actian VectorAI DB
- La misma arquitectura en todos los entornos.
- Implementación basada en Docker.
- Indexación HNSW.
- Indexación en tiempo real.
- SDK de Python y JavaScript.
- Integración nativa con LangChain y LlamaIndex.
Marco de decisión: cómo elegir tu cliente de Python
Matriz de decisión
| Criterios | Piña | Cuadrante | Weaviate | ChromaDB | Actian VectorAI DB |
| Estabilidad de la API | Medio | Bien | Mejorar | Bajo | Alta |
| Desarrollo local | ✗ No hay modo local | ✓ Modo :memory: | Se requiere Docker | ✓ Integrado | ✓ :memoria: + SQLite |
| Compatibilidad con plataformas | ✓ Solo en la nube | ✓ Todas las plataformas | ✓ Todas las plataformas | ✗ Problemas en ARM y Windows | ✓ Todas las plataformas |
| Compatibilidad con Async | ✓ v6+ | ✓ Nativo | ✓ v4.7+ | ✗ Limitado | ✓ Nativo |
| Coste | Entre 50 y 500 $ al mes | Gratis / Autohospedado | Gratuito / Gestionado | Gratis | Tarifas para empresas |
Reflexiones finales
El fallo de producción de ChromaDB del ejemplo inicial se debe a problemas de empaquetado del cliente que los desarrolladores solo detectan tras la implementación. Esta comparación ayuda a evitar fallos similares: incompatibilidades entre plataformas, cambios que rompen la compatibilidad al migrar de una versión a otra y rediseños de clases de cliente que se propagan por todo el código.
ChromaDB permite poner en marcha proyectos rápidamente, pero tiende a mostrar sus limitaciones una vez que la aplicación pasa a producción. Pinecone es una solución pulida y bien gestionada, pero la frecuencia de las actualizaciones de versión y las dependencias permanentes de la nube suponen un coste real. Qdrant es la mejor opción de código abierto para equipos que buscan la paridad entre el entorno local y el de producción sin necesidad de modificar el código. El cliente v4 de Weaviate supone una mejora significativa con respecto a la v3 y resulta ideal para equipos que necesitan una búsqueda híbrida a gran escala.
Para los equipos en los que la estabilidad de las API y la compatibilidad entre plataformas son fundamentales, los clientes de nivel empresarial como Actian VectorAI DB ofrecen una estabilidad lista para producción con compatibilidad multiplataforma contrastada.
Descubre Actian VectorAI DB para disfrutar de una estabilidad garantizada en producción.

Stay connected
Data insights delivered to you.
(i.e. sales@..., support@...)