Cómo crear un ecosistema de IA que cumpla con la HIPAA sin recurrir a la nube




Summary
- Un BAA no garantiza automáticamente el cumplimiento de las directrices RAG en la nube, ya que los mayores riesgos para la privacidad suelen provenir de la capa de aplicaciones, y no solo de la infraestructura del proveedor.
- El enfoque más seguro que se describe aquí consiste en mantener todo el flujo de trabajo de RAG en la infraestructura local del hospital, incluyendo la ingesta, la recuperación, la generación y el registro.
- El sistema protege los datos mediante la desidentificación del contenido antes de su incorporación, la aplicación de un control de acceso basado en roles en el momento de la consulta y la prevención de la recuperación de datos entre departamentos.
- Utiliza una base de datos vectorial local y modelos locales, por lo que ningún dato de pacientes, representaciones, indicaciones ni registros sale de la red.
- El registro de auditoría local es esencial, ya que genera un registro completo y verificable de quién consultó qué, cuándo y con qué rol.
El sector sanitario no puede confiar en el RAG en la nube, ya que los datos de los pacientes salen de su red y su sistema los registra, almacena y expone fuera de su control. Usted firma un acuerdo de socio comercial (BAA), conecta su canal de datos a una base de datos vectorial gestionada y da por hecho que el cumplimiento normativo está garantizado. Esa suposición es errónea. El BAA cubre la infraestructura del proveedor, pero no lo que su aplicación envía, registra o expone durante la recuperación y la generación de datos.
Usted sigue siendo responsable de todas las vías por las que su sistema transmite información médica protegida (PHI). Una consulta de un profesional sanitario puede filtrar datos confidenciales a través de los registros. Un mensaje del sistema puede incluir información sobre el paciente que su sistema almacena fuera de su ámbito de control. Un control de acceso deficiente permite que los resultados de las búsquedas expongan registros a otros departamentos. Estos riesgos se dan en su capa de aplicación, no en el ámbito del proveedor de servicios en la nube.
Las autoridades reguladoras estadounidenses se centran ahora en esta laguna. En 2026, señalaron patrones de ataque como la inferencia de afiliación, en la que un atacante sondea un sistema de IA para confirmar si los datos de un paciente figuran en el índice. Los flujos de trabajo alojados en la nube aumentan este riesgo, ya que las consultas y las representaciones se transmiten a través de infraestructuras externas. Los requisitos de auditoría se endurecen aún más cuando los registros se almacenan en sistemas de terceros.
En este tutorial, crearás un asistente de conocimientos clínicos que se ejecuta íntegramente en la infraestructura del hospital. Este asistente realiza búsquedas semánticas en datos clínicos, aplica controles de acceso basados en roles en el momento de la consulta y genera respuestas con citas claras. Todas las consultas se mantienen dentro de tu red, todos los accesos se registran localmente y no se requieren llamadas a API externas.
Por qué la BAA no es suficiente
Un BAA protege la infraestructura del proveedor de servicios en la nube, pero no la forma en que su sistema gestiona la información médica protegida (PHI) durante las consultas, la recuperación y la generación de datos. Usted sigue siendo responsable de todos los puntos en los que la PHI aparece, se transfiere o se almacena dentro de su proceso. Existen múltiples situaciones que pueden hacer que su sistema incumpla la normativa, incluso aunque haya firmado un BAA.
Brecha en la responsabilidad compartida
El BAA se limita al perímetro de la infraestructura. Tu sistema controla lo que se introduce en una solicitud, lo que se registra y lo que sale de tu red. Si la consulta de un profesional sanitario incluye información médica protegida (PHI) y tu aplicación la registra en un servicio externo, la responsabilidad recae sobre ti. Si tu proceso de recuperación devuelve registros de distintos departamentos sin aplicar filtros estrictos, has creado una filtración de datos interna filtración de datos. Estos fallos se producen en tu código, no en el ámbito de responsabilidad del proveedor de la nube.
Por ejemplo, un médico busca: «Muéstrame casos similares al de Juan Pérez con cáncer de pulmón en fase inicial». Tu aplicación registra la consulta completa en un servicio de registro en la nube con fines de depuración. Ese registro contiene ahora información médica protegida fuera de tu red. El proveedor de la nube no la ha filtrado. Ha sido tu aplicación la que la ha enviado.
Titularidad del registro de auditoría
La HIPAA exige un registro de auditoría completo para cada acceso a la información médica protegida (PHI). Cuando su base de datos vectorial se ejecuta en una infraestructura de terceros, su sistema almacena los registros de consultas y los rastros de recuperación fuera de su control. No puede garantizar la integridad, la conservación ni el aislamiento de los datos. Su equipo de seguridad no puede verificar los patrones de acceso sin depender del sistema de otro proveedor. Esto le impide garantizar y demostrar el cumplimiento normativo.
Por ejemplo, tu equipo de cumplimiento normativo solicita un informe de todos los historiales de pacientes oncológicos de los últimos 30 días. Tu proveedor de bases de datos vectoriales almacena los registros de consultas en su plataforma con un periodo de conservación limitado. Faltan algunos registros y otros carecen de metadatos a nivel de usuario. No puedes presentar un registro de auditoría completo.
Exposición a la inferencia de pertenencia
Los atacantes pueden sondear su sistema con consultas específicas para determinar si los datos de un paciente concreto figuran en su índice. Este tipo de ataque se ha convertido en motivo de preocupación desde el punto de vista normativo. Los índices alojados en la nube aumentan este riesgo, ya que exponen una interfaz remota que permite realizar sondeos repetidos. Un índice alojado localmente elimina esa interfaz externa y limita el acceso a su red interna.
Por ejemplo, un atacante envía consultas repetidas del tipo «Pacientes diagnosticados con el VIH en 2024 tratados con el fármaco X» y modifica ligeramente los filtros cada vez. Observa los cambios en la fiabilidad y el contenido de las respuestas. Con el tiempo, deduce si el expediente de una persona concreta existe en tu conjunto de datos.
Estos fallos demuestran que un acuerdo de nivel de servicio (BAA) no garantiza el cumplimiento normativo. Una implementación local elimina por completo la dependencia de terceros y le ofrece un control total sobre el flujo de datos, el acceso y la auditabilidad.
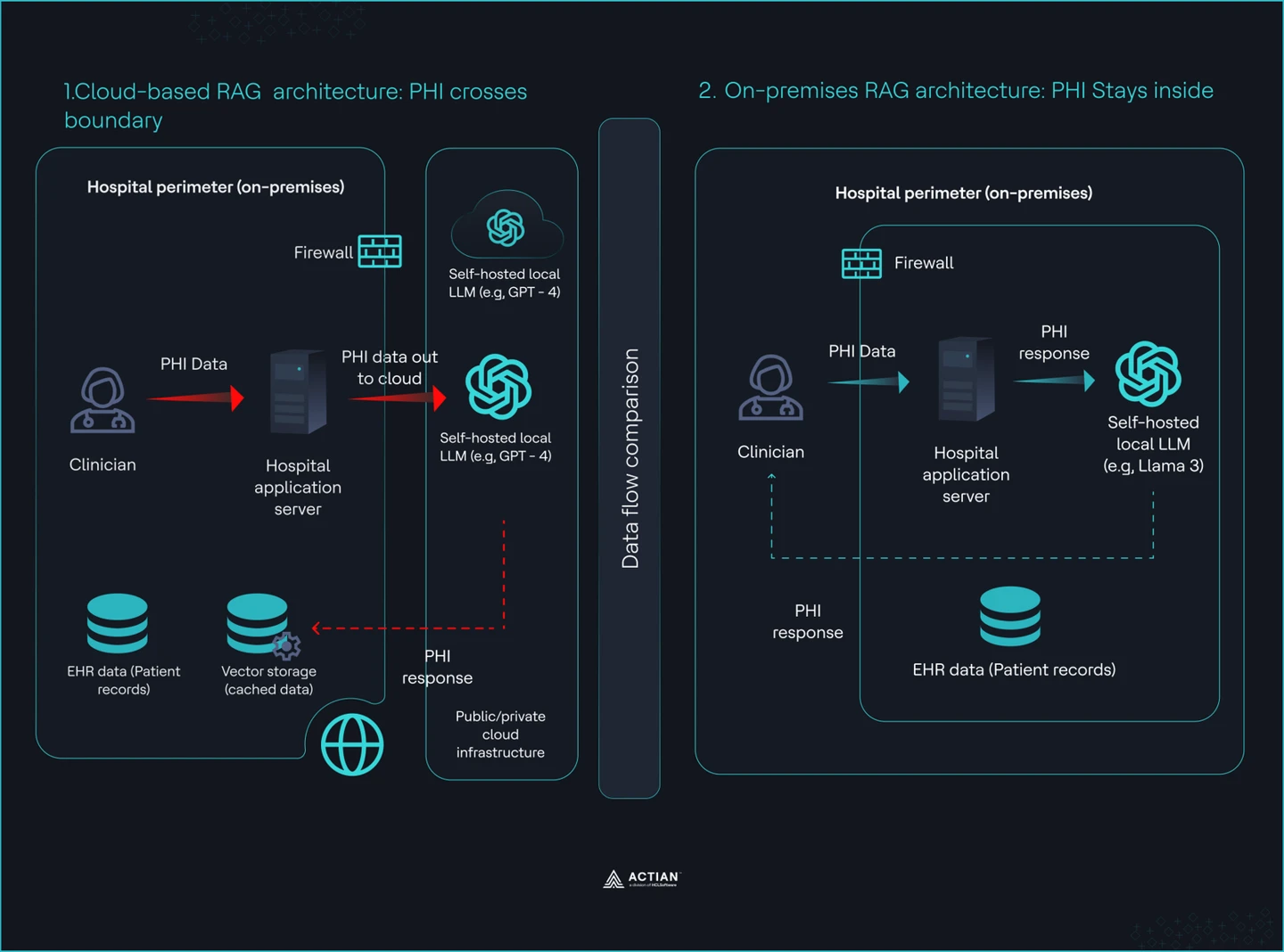
Vista dividida que muestra la arquitectura RAG en la nube frente a la arquitectura RAG local
Lo que estás construyendo
En esta sección, crearás un sistema RAG de tres capas:
Capa de ingestión
Se importan las notas clínicas y los protocolos de tratamiento a un índice vectorial controlado que garantiza la higiene de los datos. Los datos se anonimizan antes de cualquier procesamiento. La cláusula de exención de responsabilidad de la HIPAA exige la eliminación de los identificadores, mientras que la «determinación experta» permite un enfoque estadístico. Se aplica uno de estos métodos antes de la importación, no después. A continuación, los documentos se dividen en segmentos de 512 tokens con un solapamiento de 50 tokens, se generan representaciones vectoriales utilizando un modelo local y se almacenan en VectorAI DB junto con los metadatos.
Se define un esquema estricto para cada registro. Cada bloque incluye el tipo de documento, el departamento, la fecha y la función del autor. Estos metadatos no son opcionales. Permiten controlar el acceso en el momento de la consulta y evitan la filtración de información entre departamentos. No se deben almacenar documentos sin procesar y sin estructura.
Capa de consulta
Las consultas de los médicos se procesan a través de un flujo de recuperación controlado. Cada consulta pasa por un control de acceso basado en roles antes de llegar al índice. Un usuario de cardiología solo puede recuperar datos de cardiología. Un bot de programación de citas no puede acceder a las notas de diagnóstico. Esto se garantiza mediante un filtro «MUST» aplicado al departamento o al grupo de pacientes a nivel de la base de datos.
Realiza una búsqueda híbrida. La similitud vectorial recupera fragmentos semánticamente relevantes. Los filtros de metadatos restringen el conjunto de resultados. Pasa el contexto filtrado a un modelo de lenguaje grande (LLM) local. El modelo genera una respuesta basándose únicamente en los datos recuperados e incluye citas. No permitas que el modelo invente información ni recurra a conocimientos externos.
Capa de auditoría
Registra cada interacción de forma local con total trazabilidad. Cada consulta genera un registro que incluye una marca de tiempo, el ID de usuario, el departamento, el texto de la consulta y las referencias de los documentos recuperados. Este registro se almacena en tu propia infraestructura, con políticas de retención y acceso definidas. No dependes de sistemas de registro externos.
A partir de este registro, puede reconstruir cualquier evento de acceso. Podrá saber quién accedió a qué, cuándo y con qué rol. Esto cumple con los requisitos de auditoría y ofrece a su equipo de seguridad una visibilidad directa del comportamiento del sistema.
Todo el sistema funciona con hardware estándar dentro de la red del hospital. En la imagen se muestra la arquitectura de extremo a extremo del sistema:
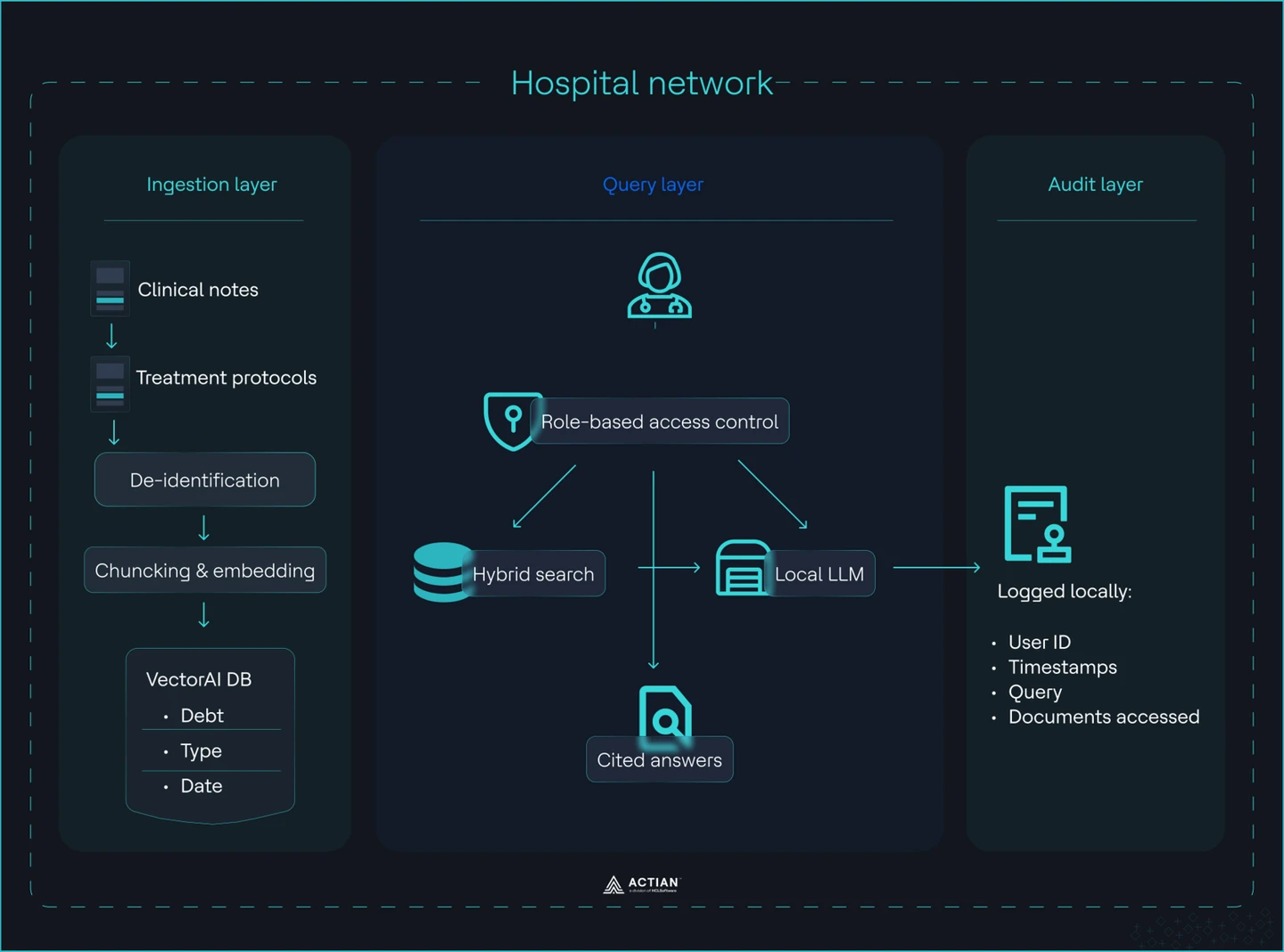
Arquitectura del sistema RAG del hospital
Creación de un flujo de trabajo RAG conforme a la HIPAA
En esta sección, crearás un sistema RAG totalmente local que recopila datos clínicos, aplica el control de acceso, responde a consultas y registra cada interacción.
Requisitos previos
Para seguir los pasos, instala las siguientes herramientas en tu red local:
- Docker y Docker Compose están instalados.
- Python 3.10 o superior.
- PIP o UV: En esta guía se utiliza UV.
Paso 1: Implementar una base de datos vectorial
Se implementa una instancia local de Actian VectorAI DB con almacenamiento persistente tanto para los datos vectoriales como para los registros de auditoría.
Crear un docker-compose.yaml archivo:
services:
vectorai:
image: williamimoh/actian-vectorai-db:latest
platform: linux/amd64
container_name: vectorai_db
ports:
- "50052:50051"
volumes:
# vector data persists across restarts
- ./data:/app/data
# audit log lives on host — not inside the container
- ./audit_logs:/app/audit_logs
environment:
- VECTORAI_LOG_LEVEL=info
restart: unless-stopped
Ejecuta el servicio:
docker-compose up -dLa base de datos se inicia y abre el puerto 50051 para el acceso local. Los datos vectoriales se almacenan en ./data. Los registros de auditoría se escriben en ./audit_logs en el servidor, que almacena todos los registros de acceso dentro de los límites de tu red.
Nota:
- Los procesadores Apple Silicon M3/M4pueden presentar un error de desconexión de GRPC sin que aparezcan registros en el contenedor . En ese caso, desactiva Rosetta en Docker Desktop.
- VectorAI DB se encuentra en fase de desarrollo activo.
Paso 2: Crear el canal de ingesta
Instala la biblioteca de cliente y ejecuta el proceso de ingestión para convertir los documentos clínicos en representaciones vectoriales y almacenarlos en tu base de datos vectorial local.
Utiliza uv para la gestión de dependencias y la ejecución. Es rápido, reproducible y evita el estado global de Python.
Descarga el Paquete de cliente de Actian VectorAI. Esto crea un archivo actian_vectorai-0.1.0b2-py3-none-any
Inicia tu proyecto de la siguiente manera:
uv init .
uv venvUna vez completada la inicialización, instale el paquete Actian VectorAI de la siguiente manera:
uv pip3 install actian_vectorai-0.1.0b2-py3-none-anyAñade la dependencia del modelo de incrustación:
uv add sentence-transformersCrear un archivo ingest.py con el siguiente contenido:
import re
import hashlib
from actian_vectorai import VectorAIClient, Distance, VectorParams, PointStruct
from sentence_transformers import SentenceTransformer
# ── Config ────────────────────────────────────────────────────────────────────
VECTORAI_HOST = "localhost:50052"
COLLECTION = "clinical_docs"
EMBED_MODEL = "sentence-transformers/all-MiniLM-L6-v2" # 384-dim
VECTOR_DIM = 384
CHUNK_TOKENS = 512
OVERLAP_TOKENS = 50
# ── Synthetic clinical notes (replace with real de-identified corpus) ─────────
RAW_NOTES = [
{
"document_id": "card_note_001",
"document_type": "clinical_note",
"department": "cardiology",
"date": "2025-03-15",
"author_role": "attending_physician",
"text": """
Patient: [NAME REDACTED], DOB: [DATE REDACTED], MRN: [MRN REDACTED]
Chief Complaint: Chest pain radiating to left arm, onset 2 hours ago.
Assessment: Acute ST-elevation myocardial infarction confirmed on ECG.
History: Hypertension and type 2 diabetes. Started on aspirin 325 mg,
clopidogrel 600 mg loading dose, and heparin infusion per ACS protocol.
Plan: Emergency PCI. Beta-blocker therapy with metoprolol succinate
25 mg daily post-procedure. ACE inhibitor ramipril 5 mg daily initiated
24 hours post-PCI. Follow-up echocardiography in 6 weeks.
""",
},
{
"document_id": "card_protocol_001",
"document_type": "treatment_protocol",
"department": "cardiology",
"date": "2025-01-10",
"author_role": "department_head",
"text": """
Cardiology Protocol — Heart Failure with Reduced EF (HFrEF)
First-line therapy:
- ACE inhibitor: ramipril 2.5–10 mg daily (or ARB if ACE-intolerant).
- Beta-blocker: bisoprolol 1.25–10 mg daily, carvedilol 3.125–25 mg BID,
or metoprolol succinate 12.5–200 mg daily. Titrate every 2 weeks.
- MRA: spironolactone 25–50 mg daily for NYHA class II–IV
if eGFR > 30 and K+ < 5.0.
Target: Symptomatic improvement. Reassess LVEF at 3–6 months.
Device therapy (ICD/CRT) if LVEF ≤ 35% after 3 months optimal therapy.
""",
},
{
"document_id": "psych_note_001",
"document_type": "clinical_note",
"department": "psychiatry",
"date": "2025-03-18",
"author_role": "psychiatrist",
"text": """
Psychiatry intake note — [NAME REDACTED], [AGE REDACTED]-year-old.
Presenting with major depressive episode, PHQ-9 score 18 (severe).
No current suicidal ideation. Started sertraline 50 mg daily.
Psychotherapy referral placed. Follow-up in 2 weeks.
Safety plan documented. Family support confirmed present.
""",
},
{
"document_id": "onco_note_001",
"document_type": "clinical_note",
"department": "oncology",
"date": "2025-03-20",
"author_role": "oncologist",
"text": """
Oncology note — [NAME REDACTED].
Diagnosis: Stage IIIA non-small cell lung cancer, adenocarcinoma.
EGFR mutation positive (exon 19 deletion).
Plan: Osimertinib 80 mg daily (first-line EGFR-targeted therapy).
Baseline CT chest/abdomen/pelvis completed. Brain MRI negative.
Next imaging review in 8 weeks. Antiemetics PRN, skin care for rash.
""",
},
]
# ── Step 1: De-identification ─────────────────────────────────────────────────
# For production use Presidio:
# from presidio_analyzer import AnalyzerEngine
# from presidio_anonymizer import AnonymizerEngine
# analyzer, anonymizer = AnalyzerEngine(), AnonymizerEngine()
# result = analyzer.analyze(text=raw, entities=[...], language="en")
# clean = anonymizer.anonymize(text=raw, analyzer_results=result).text
#
# This demo applies lightweight regex to already-synthetic notes.
_HIPAA_PATTERNS = [
(r"\b\d{3}-\d{2}-\d{4}\b", "[SSN]"), # SSN
(r"\bMRN[-:\s]*\d{4,10}\b", "[MRN]"), # medical record #
(r"\b\d{1,2}/\d{1,2}/\d{2,4}\b", "[DATE]"), # dates
(r"\b[A-Z][a-z]+ [A-Z][a-z]+\b", "[NAME]"), # names (simple)
(r"\b\d{3}[-.\s]\d{3}[-.\s]\d{4}\b", "[PHONE]"), # phone
(r"\b[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.\w+\b","[EMAIL]"), # email
(r"\b\d{5}(?:-\d{4})?\b", "[ZIP]"), # zip
(r"\b(?:https?://)\S+", "[URL]"), # URLs
(r"\b\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\b", "[IP]"), # IP addresses
]
def deidentify(text: str) -> str:
"""Remove HIPAA Safe Harbor identifiers from text."""
for pattern, replacement in _HIPAA_PATTERNS:
text = re.sub(pattern, replacement, text)
return text.strip()
# ── Step 2: Chunking ──────────────────────────────────────────────────────────
def chunk(text: str, size: int = CHUNK_TOKENS, overlap: int = OVERLAP_TOKENS) -> list[str]:
"""Split text into overlapping token windows (whitespace tokenisation)."""
tokens = text.split()
chunks, start = [], 0
while start < len(tokens):
end = min(start + size, len(tokens))
chunks.append(" ".join(tokens[start:end]))
if end == len(tokens):
break
start += size - overlap
return chunks
# ── Step 3: Embedding ─────────────────────────────────────────────────────────
print(f"Loading embedding model: {EMBED_MODEL}")
_model = SentenceTransformer(EMBED_MODEL)
def embed(texts: list[str]) -> list[list[float]]:
return _model.encode(texts, normalize_embeddings=True).tolist()
# ── Step 4: Ingest into VectorAI DB ──────────────────────────────────────────
def _chunk_id(doc_id: str, idx: int) -> int:
"""Stable integer ID from (document_id, chunk_index)."""
h = hashlib.sha256(f"{doc_id}:{idx}".encode()).hexdigest()
return int(h[:15], 16)
def ingest(notes: list[dict]) -> None:
with VectorAIClient(VECTORAI_HOST) as client:
# Health check
info = client.health_check()
print(f"VectorAI DB connected version={info['version']}")
# Create collection (skip if already exists)
try:
client.collections.create(
name=COLLECTION,
vectors_config=VectorParams(size=VECTOR_DIM, distance=Distance.Cosine),
)
print(f"Collection '{COLLECTION}' created dim={VECTOR_DIM}")
except Exception as e:
if "exists" in str(e).lower():
print(f"Collection '{COLLECTION}' already exists — skipping create")
else:
raise
total_chunks = 0
for note in notes:
# De-identify FIRST — before chunking or embedding
clean_text = deidentify(note["text"])
# Chunk second
chunks = chunk(clean_text)
# Embed third
vectors = embed(chunks)
# Build PointStruct records with strict metadata schema
# All four metadata fields are REQUIRED — no optional fields.
points = [
PointStruct(
id=_chunk_id(note["document_id"], i),
vector=vectors[i],
payload={
# ── strict schema ──────────────────────────────────────
"document_type": note["document_type"], # required
"department": note["department"], # required — RBAC filter key
"date": note["date"], # required
"author_role": note["author_role"], # required
# ── retrieval helpers ──────────────────────────────────
"document_id": note["document_id"],
"chunk_index": i,
"text": chunks[i], # de-identified chunk text
},
)
for i in range(len(chunks))
]
client.points.upsert(COLLECTION, points)
total_chunks += len(chunks)
print(f" ✓ {note['document_id']} dept={note['department']} chunks={len(chunks)}")
print(f"\nIngestion complete — {len(notes)} documents, {total_chunks} chunks total")
if __name__ == "__main__":
ingest(RAW_NOTES)
Este archivo realiza las siguientes acciones:
- Anonimización de datos: el sistema elimina todos los identificadores sujetos a la HIPAA del texto sin procesar antes de su tratamiento. Los nombres, las fechas y otros campos confidenciales se sustituyen por marcadores de posición para evitar que la información médica protegida (PHI) entre en el flujo del sistema.
- División del texto en fragmentos: el sistema divide el texto depurado en segmentos de 512 tokens con un solapamiento de 50 tokens. Este solapamiento permite mantener el contexto entre los límites de los segmentos, lo que mejora la precisión de la recuperación.
- Incorpora los fragmentos: el modelo convierte cada fragmento en un vector numérico utilizando un modelo local de «sentence-transformers». Este proceso captura el significado semántico al tiempo que mantiene todo el procesamiento dentro de la red.
- Almacenamiento con metadatos: El sistema guarda cada fragmento y su vector en la base de datos VectorAI, junto con los campos necesarios, como «document_type», «department», «date» y «author_role». Estos campos permiten un control de acceso estricto durante las consultas.
Ejecuta el script de la siguiente manera:
uv run ingest.py
Tras ejecutar el comando, deberías ver los siguientes resultados:
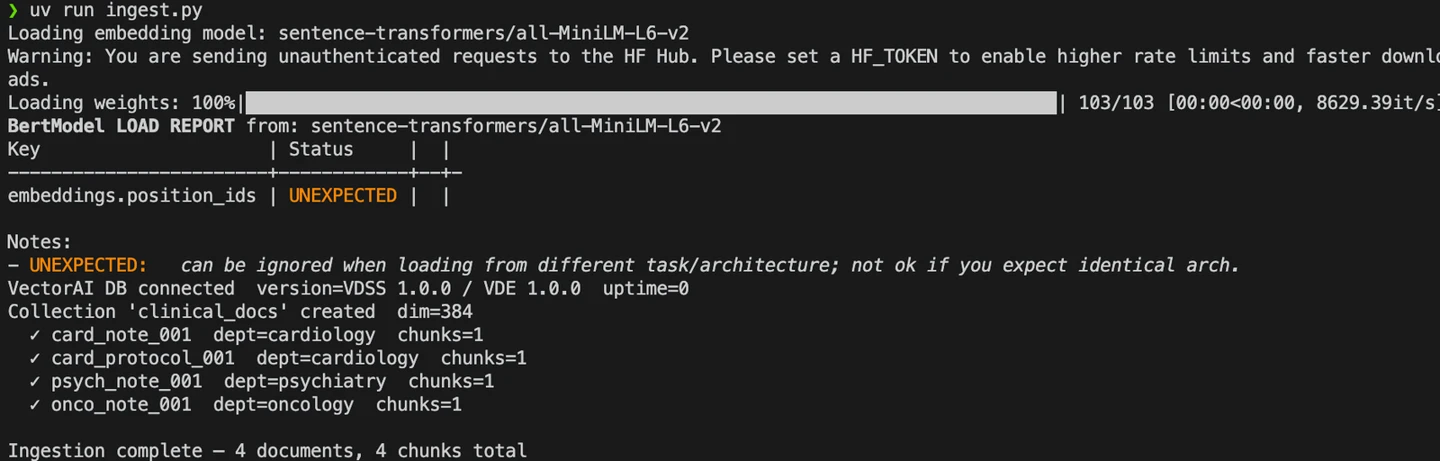
Ejecución de ingest.py
En los registros se puede ver que el canal de ingestión escribe fragmentos en la base de datos de VectorAI.
Paso 3: Ejecuta tus consultas
Ejecute consultas en su sistema RAG local y compruebe la recuperación de datos, el control de acceso y el registro de auditoría.
Crear un archivo query.py con el siguiente contenido:
import json
import datetime
import urllib.request
import urllib.error
from pathlib import Path
from actian_vectorai import VectorAIClient
from actian_vectorai import FilterBuilder, Field
from sentence_transformers import SentenceTransformer
# ── Config ─────────────────────────────────────────────────────────────────────
VECTORAI_HOST = "localhost:50052"
COLLECTION = "clinical_docs"
EMBED_MODEL = "sentence-transformers/all-MiniLM-L6-v2"
AUDIT_LOG = Path("./audit_logs/queries.jsonl") # volume-mounted path
# Ollama settings — set OLLAMA_ENABLED=True once `ollama serve` is running
OLLAMA_ENABLED = False # flip to True when Ollama is ready
OLLAMA_URL = "https://localhost:11434/api/generate"
OLLAMA_MODEL = "mistral" # or "llama3.2:3b" for lower hardware
# ── RBAC: role → allowed departments ──────────────────────────────────────────
# Access is enforced as a MUST filter at the database level.
# A scheduling_bot cannot reach clinical notes; cardiology cannot see psychiatry.
ROLE_PERMISSIONS = {
"cardiology_clinician": ["cardiology"],
"oncology_clinician": ["oncology"],
"general_practitioner": ["cardiology", "oncology", "general"],
"admin": ["cardiology", "oncology", "psychiatry", "general"],
"scheduling_bot": ["scheduling"], # no clinical note access
}
class AccessDeniedError(Exception):
pass
def allowed_departments(role: str) -> list[str]:
if role not in ROLE_PERMISSIONS:
raise AccessDeniedError(f"Unknown role '{role}' — access denied by default.")
return ROLE_PERMISSIONS[role]
# ── Embedding (reuse the same model as ingest.py) ─────────────────────────────
print(f"Loading embedding model: {EMBED_MODEL}")
_model = SentenceTransformer(EMBED_MODEL)
def embed(text: str) -> list[float]:
return _model.encode([text], normalize_embeddings=True).tolist()[0]
# ── Step 5: Search with department MUST filter ─────────────────────────────────
def retrieve(query_vec: list[float], departments: list[str], top_k: int = 5) -> list[dict]:
"""
Hybrid retrieval: vector similarity + metadata MUST filter.
Results from departments outside the allowed list are impossible —
the filter is applied at the database level, not in application code.
"""
results = []
with VectorAIClient(VECTORAI_HOST) as client:
for dept in departments:
hits = client.points.search(
collection_name=COLLECTION,
vector=query_vec,
limit=top_k,
# MUST filter — department equality enforced at DB level
filter=FilterBuilder().must(Field("department").eq(dept)).build(),
)
for hit in hits:
payload = getattr(hit, "payload", {}) or {}
results.append({
"score": round(getattr(hit, "score", 0.0), 4),
"document_id": payload.get("document_id"),
"document_type": payload.get("document_type"),
"department": payload.get("department"),
"date": payload.get("date"),
"author_role": payload.get("author_role"),
"chunk_index": payload.get("chunk_index"),
"text": payload.get("text", ""),
})
results.sort(key=lambda r: r["score"], reverse=True)
return results[:top_k]
# ── Step 6: LLM answer via Ollama ─────────────────────────────────────────────
_RAG_SYSTEM = (
"You are a clinical decision support assistant. "
"Answer ONLY using the context passages below. "
"Do NOT use external knowledge or make assumptions. "
"Cite each fact as [Doc N]. "
"If the context is insufficient, say: 'I cannot answer from the available documents.'"
)
def build_context(chunks: list[dict]) -> str:
return "\n\n".join(
f"[Doc {i+1}] ({c['document_type']}, dept={c['department']}, "
f"date={c['date']}, role={c['author_role']})\n{c['text']}"
for i, c in enumerate(chunks)
)
def generate(query_text: str, chunks: list[dict]) -> str:
if not OLLAMA_ENABLED:
# Return raw retrieved context when LLM is disabled
return "[LLM disabled — set OLLAMA_ENABLED=True]\n\n" + build_context(chunks)
context = build_context(chunks)
prompt = f"{_RAG_SYSTEM}\n\nContext:\n{context}\n\nQuestion: {query_text}\n\nAnswer:"
payload = json.dumps({
"model": OLLAMA_MODEL,
"prompt": prompt,
"stream": False,
"options": {"num_predict": 400},
}).encode()
try:
req = urllib.request.Request(
OLLAMA_URL,
data=payload,
headers={"Content-Type": "application/json"},
method="POST",
)
with urllib.request.urlopen(req, timeout=30) as resp:
data = json.loads(resp.read())
return data.get("response", "").strip()
except urllib.error.URLError as e:
return f"[Ollama unreachable: {e}]\n\nRetrieved context:\n{build_context(chunks)}"
def write_audit(record: dict) -> None:
AUDIT_LOG.parent.mkdir(parents=True, exist_ok=True)
with open(AUDIT_LOG, "a", encoding="utf-8") as f:
f.write(json.dumps(record, ensure_ascii=False) + "\n")
# ── Public query entry point ───────────────────────────────────────────────────
def query(user_id: str, role: str, query_text: str, top_k: int = 5) -> dict:
"""
Execute a role-gated RAG query.
Returns:
{answer, retrieved_docs, access_denied, error}
"""
timestamp = datetime.datetime.now(datetime.timezone.utc).isoformat()
# RBAC check — before anything else
try:
departments = allowed_departments(role)
except AccessDeniedError as e:
write_audit({
"timestamp": timestamp, "user_id": user_id, "role": role,
"department": "DENIED", "query_text": query_text,
"retrieved_docs": [], "answer_provided": False, "access_denied": True,
"denial_reason": str(e),
})
return {"answer": f"Access denied: {e}", "retrieved_docs": [], "access_denied": True}
# Embed → retrieve (with MUST filter) → generate
q_vec = embed(query_text)
chunks = retrieve(q_vec, departments, top_k)
answer = generate(query_text, chunks)
doc_refs = [
{"document_id": c["document_id"], "chunk_index": c["chunk_index"],
"department": c["department"], "document_type": c["document_type"],
"score": c["score"]}
for c in chunks
]
# Audit log — every query, regardless of outcome
write_audit({
"timestamp": timestamp,
"user_id": user_id,
"role": role,
"department": ",".join(departments),
"query_text": query_text,
"retrieved_docs": doc_refs,
"answer_provided": True,
"access_denied": False,
})
return {"answer": answer, "retrieved_docs": doc_refs, "access_denied": False}
# ── Demo runs ─────────────────────────────────────────────────────────────────
if __name__ == "__main__":
separator = "─" * 60
# ── Query 1: authorised cardiology query ────────────────────────────────
print(f"\n{separator}")
print("QUERY 1 — cardiology_clinician (authorised)")
print(separator)
r1 = query(
user_id="dr_chen_007",
role="cardiology_clinician",
query_text="What beta-blocker is recommended for heart failure with reduced ejection fraction?",
)
print(f"\nAnswer:\n{r1['answer']}\n")
print("Retrieved sources:")
for d in r1["retrieved_docs"]:
print(f" score={d['score']} [{d['document_type']}] dept={d['department']} "
f"doc={d['document_id']} chunk={d['chunk_index']}")
# ── Query 2: scheduling bot tries to access clinical notes ───────────────
print(f"\n{separator}")
print("QUERY 2 — scheduling_bot (attempting clinical note access)")
print(separator)
r2 = query(
user_id="bot_sched_01",
role="scheduling_bot",
query_text="What are the diagnosis notes for cardiology patients?",
)
if r2["access_denied"]:
print(f"\n✗ Access denied (as expected): {r2['answer']}")
else:
print(f"\nAnswer:\n{r2['answer']}")
print("Sources:", r2["retrieved_docs"])
# ── Query 3: cardiology query that must NOT return psychiatry notes ───────
print(f"\n{separator}")
print("QUERY 3 — cardiology_clinician (RBAC must exclude psychiatry)")
print(separator)
r3 = query(
user_id="dr_chen_007",
role="cardiology_clinician",
query_text="antidepressant dosing and patient management",
)
departments_returned = {d["department"] for d in r3["retrieved_docs"]}
cross_leak = "psychiatry" in departments_returned
print(f"\nDepartments in results: {departments_returned or 'none'}")
print(f"Cross-department leak: {'✗ LEAK DETECTED' if cross_leak else '✓ none — RBAC working correctly'}")
# ── Show audit log tail ───────────────────────────────────────────────────
print(f"\n{separator}")
print("AUDIT LOG → {AUDIT_LOG}")
print(separator)
if AUDIT_LOG.exists():
lines = AUDIT_LOG.read_text().strip().splitlines()
for line in lines[-3:]: # show last 3 entries
entry = json.loads(line)
print(json.dumps({
"timestamp": entry["timestamp"],
"user_id": entry["user_id"],
"role": entry["role"],
"query_text": entry["query_text"][:60] + "…",
"docs_accessed": len(entry["retrieved_docs"]),
"access_denied": entry["access_denied"],
}, indent=2))
else:
print("No audit log found — run ingest.py first.")
El script realiza tres operaciones principales en un único flujo.
- Aplica el control de acceso: El sistema comprueba el rol del usuario antes de recuperar cualquier dato. Cada rol se asigna a departamentos específicos y se aplica como un filtro obligatorio a nivel de la base de datos. La capa de autorización bloquea y registra inmediatamente los roles no autorizados.
- Recuperación y generación de respuestas: El sistema integra la consulta y recupera fragmentos de documentos relevantes mediante una búsqueda vectorial, aplicando filtros departamentales estrictos. A continuación, los resultados se envían a un LLM local. Si el LLM está desactivado, el contexto recuperado se devuelve directamente.
- Registro de auditoría: El sistema registra localmente todas las consultas, incluyendo el ID de usuario, el rol, el texto de la consulta, los documentos a los que se ha accedido y el estado del acceso. Esto genera un registro de auditoría completo para fines de cumplimiento normativo y revisión.
Ejecuta el script de la siguiente manera:
uv run query.py
Tras ejecutar el comando, deberías ver los siguientes resultados:
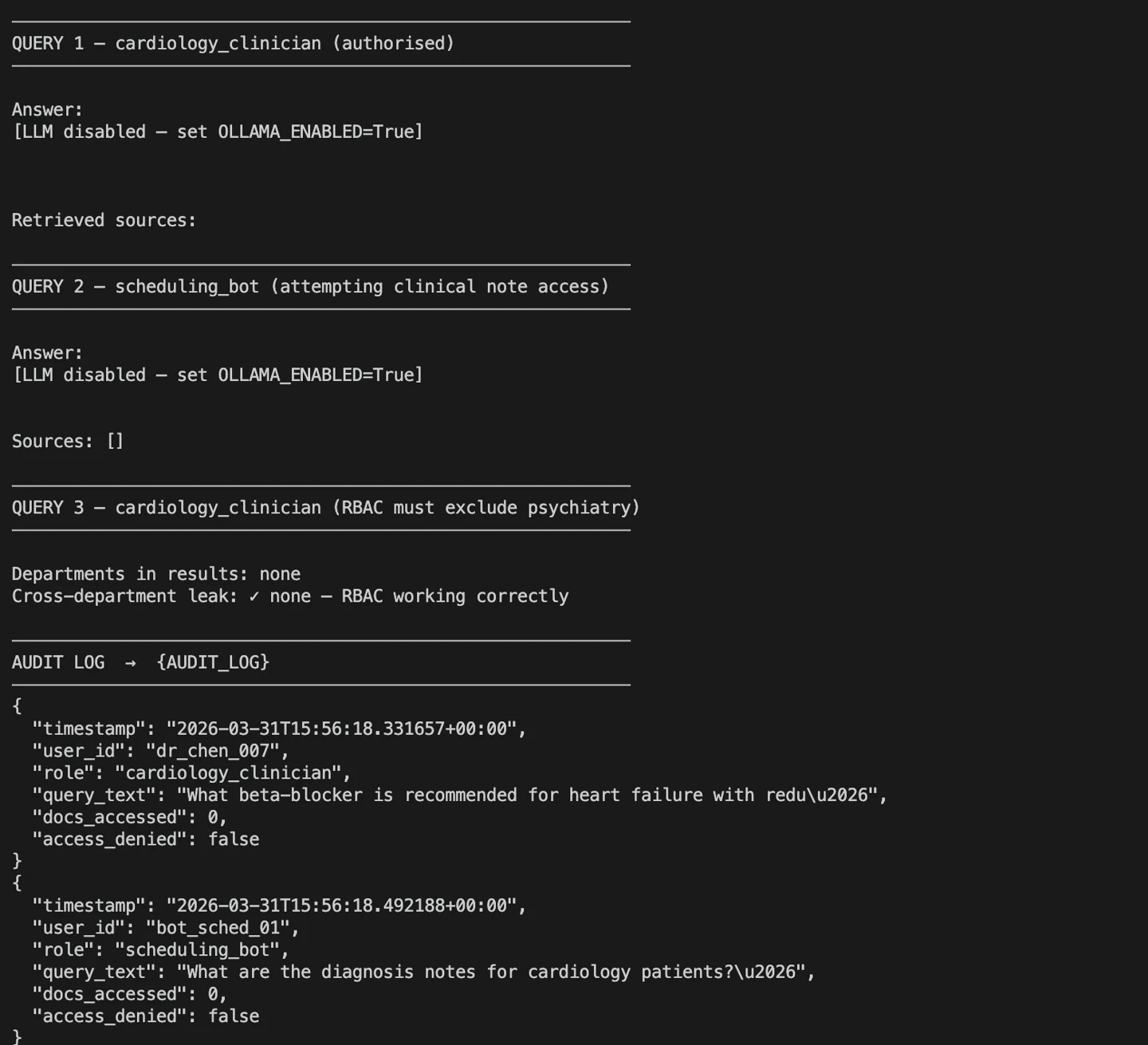
Ejecución de query.py
El resultado muestra tres casos de prueba: uno que muestra una consulta válida de un profesional sanitario, un intento de acceso denegado y una comprobación de fugas entre departamentos. Estos casos confirman que control de acceso según roles el registro de auditoría funcionan correctamente antes de pasar a producción.
Paso 4: Configurar el registro de auditoría
Almacena cada consulta localmente utilizando la asignación de volúmenes definida durante la implementación.
La configuración de Docker monta la carpeta ./audit_logs de tu host en el contenedor. Cuando ejecutas consultas, se crea una carpeta local llamada audit_logs que contiene un archivo llamado queries.jsonl.
El archivo contiene las siguientes entradas:
{"timestamp": "2026-03-31T15:56:02.552088+00:00", "user_id": "dr_chen_007", "role": "cardiology_clinician", "department": "cardiology", "query_text": "What beta-blocker is recommended for heart failure with reduced ejection fraction?", "retrieved_docs": [], "answer_provided": true, "access_denied": false}
{"timestamp": "2026-03-31T15:56:03.098346+00:00", "user_id": "bot_sched_01", "role": "scheduling_bot", "department": "scheduling", "query_text": "What are the diagnosis notes for cardiology patients?", "retrieved_docs": [], "answer_provided": true, "access_denied": false}
{"timestamp": "2026-03-31T15:56:03.663767+00:00", "user_id": "dr_chen_007", "role": "cardiology_clinician", "department": "cardiology", "query_text": "antidepressant dosing and patient management", "retrieved_docs": [], "answer_provided": true, "access_denied": false}
{"timestamp": "2026-03-31T15:56:18.331657+00:00", "user_id": "dr_chen_007", "role": "cardiology_clinician", "department": "cardiology", "query_text": "What beta-blocker is recommended for heart failure with reduced ejection fraction?", "retrieved_docs": [], "answer_provided": true, "access_denied": false}
{"timestamp": "2026-03-31T15:56:18.492188+00:00", "user_id": "bot_sched_01", "role": "scheduling_bot", "department": "scheduling", "query_text": "What are the diagnosis notes for cardiology patients?", "retrieved_docs": [], "answer_provided": true, "access_denied": false}
{"timestamp": "2026-03-31T15:56:18.569824+00:00", "user_id": "dr_chen_007", "role": "cardiology_clinician", "department": "cardiology", "query_text": "antidepressant dosing and patient management", "retrieved_docs": [], "answer_provided": true, "access_denied": false}Cada línea representa un único evento de consulta. El registro recoge quién realizó la solicitud, su función, el ámbito del departamento, el texto de la consulta y si se permitió el acceso. Este archivo se almacena íntegramente en su infraestructura y le proporciona un registro de auditoría completo y verificable de cada interacción con la información médica protegida (PHI).
Conclusión
Un acuerdo de nivel de servicio (BAA) nunca fue suficiente, ya que no controla cómo gestiona tu aplicación la información médica protegida (PHI). Resolviste ese problema manteniendo todos los datos, consultas y registros dentro de tu red.
Ahora dispone de un sistema RAG que aplica el acceso basado en roles, recupera únicamente los datos autorizados y registra cada interacción a nivel local, sin necesidad de API externas ni exposición a terceros.
Aplica este patrón a otros sistemas regulados. Consulta la documentación de VectorAI DB y el repositorio de GitHub para conocer las actualizaciones y los detalles de implementación.
Únete a la comunidady descubre más Acerca de Actian.

Stay connected
Data insights delivered to you.
(i.e. sales@..., support@...)