Tres lecciones aprendidas al desarrollar con VectorAI DB en Hacklytics 2026





Summary
- An enterprise data marketplace is a centralized internal platform where teams can publish, discover, understand, and request access to data products.
- Its purpose is to break down data silos by making enterprise data visible, reusable, and easier to trust across departments.
- Typical features include cataloging, search, access workflows, quality indicators, and usage tracking.
- Main benefits include faster time to insight, less duplicate data work, stronger governance, better data quality, greater self-service, and improved collaboration.
- It helps organizations get more value from their data by turning scattered information into accessible, well-managed, business-ready data products.
Un simple cambio en la redacción transformó una consulta en la base de datos de eventos adversos de la FDA (FAERS) de 1.532 resultados a solo uno. En Hacklytics 2026, el hackatón anual de ciencia de datos de Georgia Tech, el equipo de RxGuard consultó la base de datos FAERS, que contiene más de 31 millones de informes de interacciones farmacológicas, en busca de «warfarina-ibuprofeno» utilizando cuatro formulaciones diferentes: nombres genéricos, nombres comerciales, formas de sal y lenguaje natural. Cada nueva variante de consulta arrojó menos resultados porque la base de datos FAERS no podía entender la variación lingüística.
Esa conclusión fue una de las muchas que sacaron a la luz tres equipos mientras desarrollaban soluciones con la base de datos Actian VectorAI durante un fin de semana. Cada equipo eligió un caso de uso y abordó sus limitaciones en materia de recuperación, predicción y generación de datos. A continuación se presentan los problemas del sector sanitario que identificaron y las soluciones que desarrollaron.
Los farmacéuticos que consultan la base de datos FAERS para detectar interacciones farmacológicas pasan por alto señales de seguridad fundamentales, ya que el sistema solo reconoce coincidencias exactas de palabras clave. RxGuard cubre esa laguna con un motor de búsqueda semántico que ofrece informes de investigación sobre interacciones peligrosas registradas en toda la base de datos. La API de openFDA extrae informes históricos de reacciones adversas para 70 clases de medicamentos, all-MiniLM-L6-v2 incorpora los informes como vectores densos de 384 dimensiones, y Actian VectorAI DB almacena esas representaciones. Una única instancia de Vultr con Docker Compose gestiona toda la pila. Cuando los farmacéuticos introducen la medicación propuesta para un paciente y sus enfermedades preexistentes, RxGuard recupera de VectorAI DB los 10 casos de efectos adversos de la FDA más similares desde el punto de vista semántico, junto con puntuaciones de riesgo de gravedad y recomendaciones de medicación alternativa.
El diagnóstico de las enfermedades autoinmunes lleva entre cuatro y siete años y requiere la intervención de cuatro o más especialistas. Aura es un motor RAG de triaje clínico que da prioridad a los datos locales. Un modelo XGBoost, preentrenado con datos públicos de 100 000 pacientes, detecta los primeros signos de enfermedades autoinmunes a partir de historiales médicos con una AUC de 0,90. VectorAI DB actúa como capa de recuperación local, almacenando registros de PubMed integrados mediante pritamdeka/S-PubMedBert-MS-MARCO, en forma de representaciones de 768 dimensiones. Un modelo cuantificado de 8 000 millones de parámetros, entrenado con datos médicos generales y resúmenes de pacientes, genera informes clínicos con citas de revistas de PubMed.
La mayoría de las facturas médicas contienen errores, pero para impugnarlas se necesitan conocimientos sobre los códigos CPT, las tarifas de Medicare y las disposiciones de la legislación federal, algo de lo que carecen muchos pacientes. Reembolso es un sistema de gestión de reclamaciones médicas con múltiples agentes basado en un proceso de LangGraph. Gemini 2.0 Flash extrae los códigos CPT de las facturas cargadas y los compara con el conjunto de datos de precios transparentes de DoltHub, utilizando bien la coincidencia con el asegurador o, en su defecto, la media del mercado. Un motor de reglas señala las irregularidades en la facturación, mientras que all-MiniLM-L6-v2 genera localmente representaciones de 384 dimensiones para casos de litigios históricos. VectorAI DB almacena estas representaciones y extrae los tres precedentes más relevantes como contexto para que Gemini 2.5 Pro redacte las cartas de litigio.
A continuación, compartimos las lecciones aprendidas de su proceso de desarrollo, las principales limitaciones de búsqueda que resolvieron con VectorAI DB y lo que sus casos de uso revelan sobre las bases de datos vectoriales en entornos reales.
La búsqueda por palabras clave tiene un sesgo oculto
En las demostraciones, la búsqueda por palabras clave funciona bien. Sin embargo, cuando los usuarios reales realizan consultas en un corpus específico de un ámbito utilizando vocabulario sinónimo, la calidad de la recuperación de resultados disminuye rápidamente. Este es el problema de la falta de correspondencia léxica que pone de manifiesto la búsqueda por palabras clave.
En sectores como la sanidad, las finanzas y el derecho, la misma terminología se expresa de múltiples formas. El equipo de RxGuard lo comprobó de primera mano en la base de datos FAERS: «El mismo medicamento aparece con docenas de variantes de nombre, formas de sal, grafías extranjeras y errores tipográficos en 11,5 millones de informes. Los investigadores estadounidenses que buscan “hemorragia gastrointestinal” no obtienen ningún resultado porque el término MedDRA correcto utiliza la grafía británica».
La búsqueda basada en palabras clave no es capaz de reconocer las paráfrasis, la similitud temática ni la equivalencia entre expresiones. Como señala el equipo de RxGuard: «La búsqueda por palabras clave no solo arroja menos resultados, sino que devuelve un subconjunto sistemáticamente sesgado, y ese sesgo resulta invisible para el investigador. Nadie sabe lo que se está perdiendo porque los casos que faltan nunca aparecen». Los equipos de asistencia que revisan los tickets, los representantes de ventas que buscan especificaciones de productos y los ingenieros que investigan en wikis internos se enfrentan todos al mismo reto. La solución es la coincidencia semántica.
RxGuard utilizó la búsqueda vectorial a través de la base de datos VectorAI como mecanismo principal de recuperación, aplicando como restricciones un filtrado opcional por gravedad previo a la búsqueda y la coincidencia de nombres de medicamentos, tal y como se muestra a continuación. Las representaciones vectoriales sitúan los sinónimos y los alias muy cerca entre sí en el espacio vectorial, por lo que el sistema entiende que «(…) “Coumadin”, “warfarina” y “anticoagulante” significan todos lo mismo».
def search_faers(
query: str,
top_k: int = 10,
min_severity: int = 0,
drug_filter: str | None = None,
) -> list[dict]:
model = _get_model()
query_vector = model.encode(query).tolist()
f = Filter()
if min_severity > 0:
f = f.must(Field("severity_score").gte(min_severity))
fetch_k = top_k * 3 if drug_filter else top_k
with CortexClient(config.VECTORDB_ADDRESS) as client:
results = client.search(
config.VECTORDB_COLLECTION,
query=query_vector,
top_k=fetch_k,
filter=f if not f.is_empty() else None,
with_payload=True,
)
output = []
for r in results:
payload = r.payload or {}
# Post-filter by drug name if requested
if drug_filter:
drugs = payload.get("drugs", [])
if not any(drug_filter.lower() in d.lower() for d in drugs):
continue
output.append({
"rank": len(output) + 1,
"score": round(r.score, 4),
"doc_id": payload.get("doc_id", ""),
"text": payload.get("text", ""),
"drugs": payload.get("drugs", []),
"reactions": payload.get("reactions", []),
"severity_score": payload.get("severity_score", 0),
"patient_age": payload.get("patient_age", -1),
"patient_sex": payload.get("patient_sex", "unknown"),
})
if len(output) >= top_k:
break
return outputEste fragmento de código muestra cómo el sistema transforma una consulta en lenguaje natural en una lista ordenada de casos de efectos adversos. VectorAI DB realiza una búsqueda por similitud en la base de datos FAERS almacenada, recuperando de forma predeterminada los 10 casos más relevantes, independientemente de la forma en que se exprese el nombre del medicamento. Los filtros de metadatos restringen los resultados según la puntuación de gravedad antes de la recuperación, de modo que solo aparecen los casos clínicamente relevantes. Para ver la implementación completa del código, visita el repositorio de GitHub.
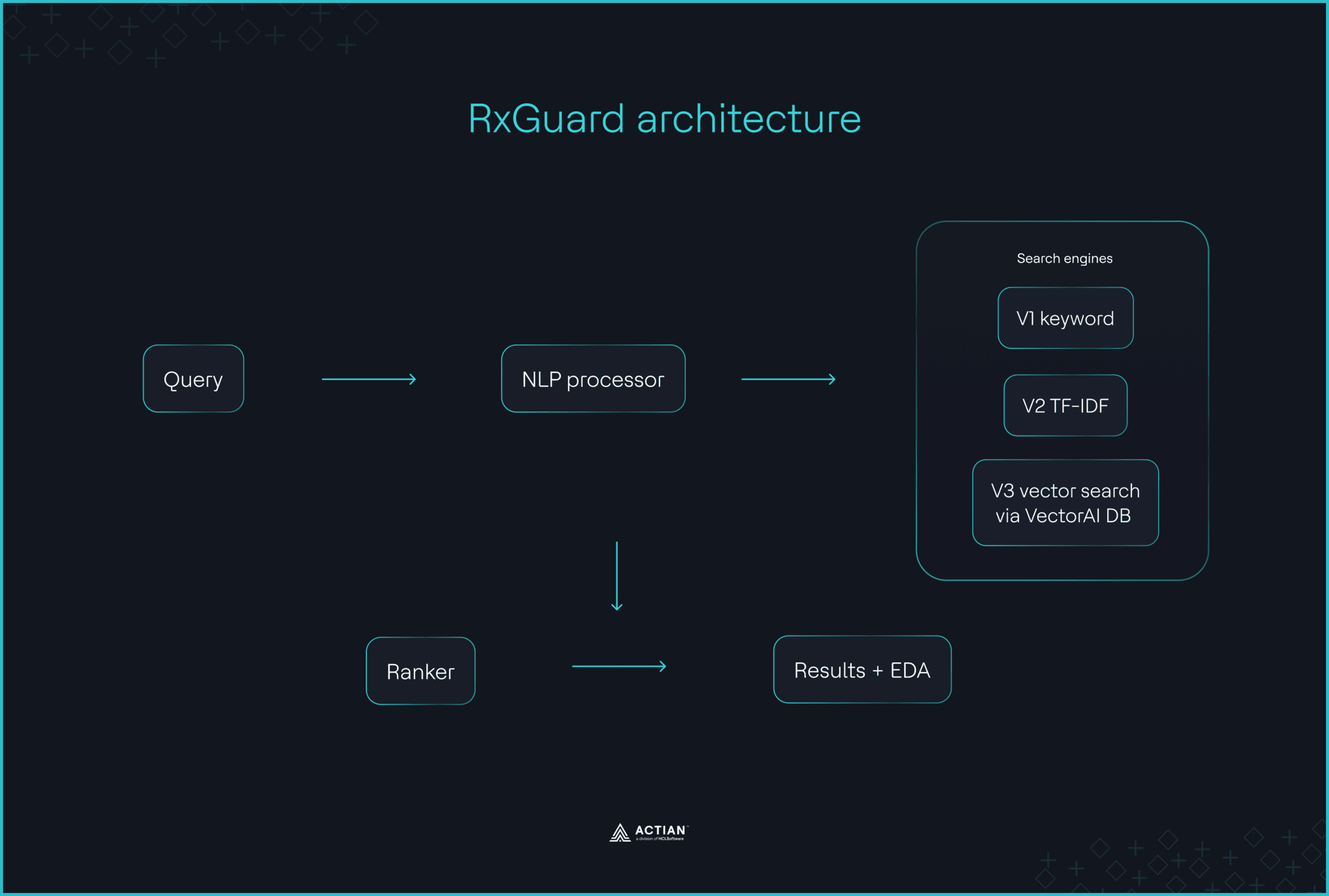
La búsqueda por palabras clave se limita a encontrar coincidencias exactas, pero la eficacia de la recuperación depende del reconocimiento de sinónimos. Y la solución no es nada nuevo. Como señala el equipo de RxGuard: «(…) los componentes de esta solución existen desde hace años: transformadores de frases, bases de datos vectoriales y la API de openFDA. El problema no era técnico. El problema era que nadie los había relacionado con este caso de uso concreto».
La búsqueda vectorial tiene una única función
La función natural de la búsqueda vectorial en los sistemas de producción es la de mecanismo de recuperación. Los modelos de incrustación y los métodos de indexación aproximada convierten la búsqueda por similitud en un proceso probabilístico. Esta búsqueda muestra documentos conceptualmente similares, pero no puede garantizar la especificidad ni interpretar por qué esos documentos son relevantes. En sectores de alto riesgo, donde «lo suficientemente parecido» no es suficiente y la explicabilidad es imprescindible, la búsqueda vectorial por sí sola no debería constituir la capa de toma de decisiones.
El proceso práctico de RAG y búsqueda para su implementación en producción sigue consistiendo en la búsqueda vectorial para la recuperación de incrustaciones, reglas deterministas para la toma de decisiones y un modelo de lenguaje grande (LLM) para la generación de respuestas. PayBack y Aura han desarrollado este proceso en distintos ámbitos.
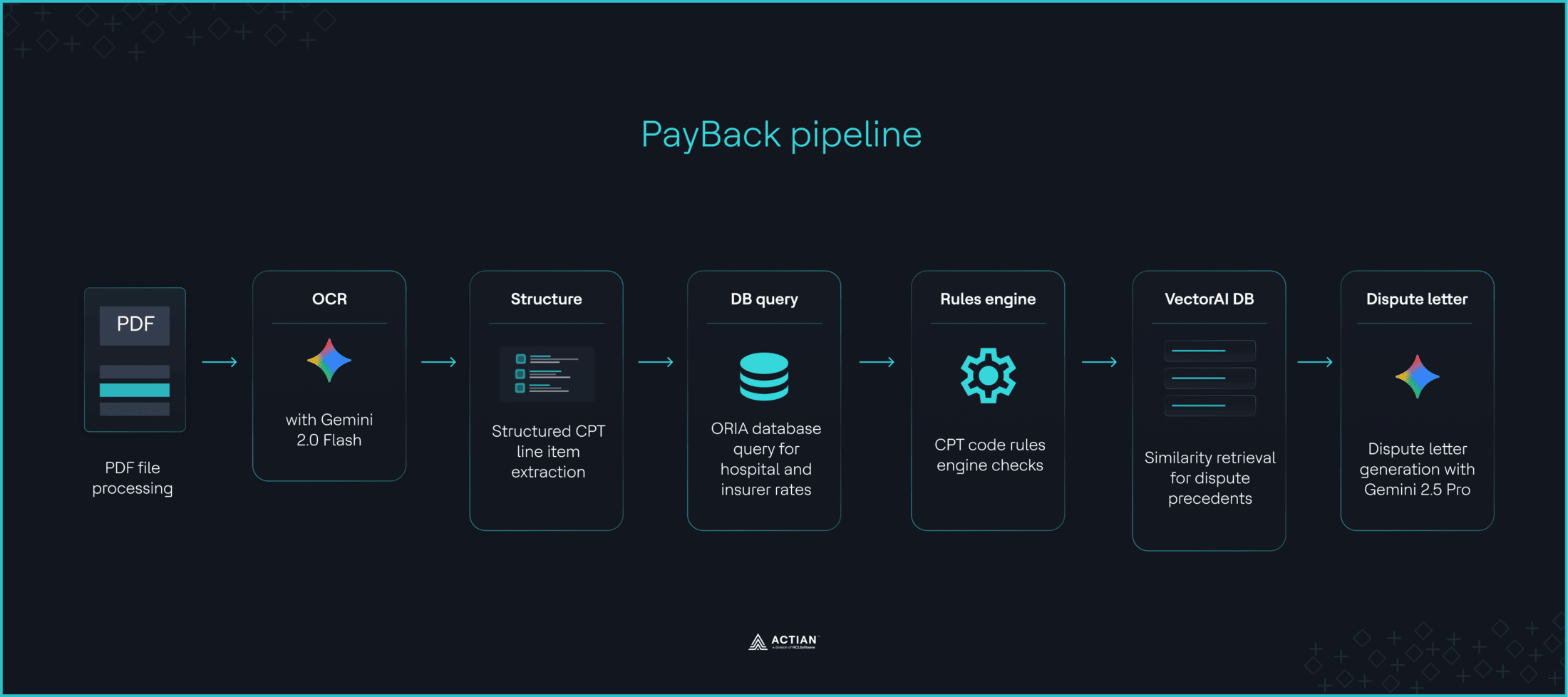
PayBack utilizó un motor de reglas en Python que señala «duplicados, anomalías en las cantidades, márgenes de beneficio extremos, tasas de centro, autorreferencias y facturación en el día del alta». VectorAI DB funcionó como una capa de recuperación semántica y enriquecimiento del contexto que «recoge los tres casos históricos de disputa más similares y los incorpora como contexto para las indicaciones de Gemini». A continuación, Gemini 2.5 Pro «generaba una reclamación formal citando las alertas, los puntos de referencia de DoltHub y el lenguaje de los precedentes». Estefragmento de código muestra el traspaso entre el motor de reglas de PayBack y la búsqueda vectorial. Visita el repositorio de GitHub para ver el código completo.
if line_items:
try:
query = _build_precedent_query(line_items)
precedents = search_precedents(query, top_k=3)
similar_cases_context = _format_similar_cases(precedents)
print(f"[rules_engine] Fetched {len(precedents)} similar cases for context")
except PrecedentServiceError as exc:
print(f"[rules_engine] Precedent search unavailable, proceeding without: {exc}")El equipo de Aura combinó la búsqueda vectorial con un sistema de puntuación dual jerárquico basado en XGBoost. El modelo clasifica las características estructuradas de los pacientes en grupos de enfermedades e identifica una posible afección dentro del grupo previsto. Esta clasificación incorpora la explicabilidad al sistema, ya que Aura puede rastrear qué datos del paciente determinaron la predicción y la puntuación de confianza.
VectorAI DB siguió la ruta de recuperación, utilizando el contexto de las características del paciente para mostrar los cinco artículos más relevantes de PubMed que respaldan los resultados de XGBoost con evidencia clínica. A continuación se muestra un fragmento de cómo el equipo de Aura configuró VectorAI DB para almacenar y filtrar fragmentos de PubMed con metadatos, en lugar de rastrear toda la bibliografía en el momento de la consulta.
with CortexClient(ACTIAN_HOST) as client:
client.create_collection(
name=COLLECTION_NAME,
dimension=EMBEDDING_DIM,
distance_metric=DistanceMetric.COSINE,
)
for batch_start in range(0, total, EMBED_BATCH):
batch_end = min(batch_start + EMBED_BATCH, total)
texts = rows["text"][batch_start:batch_end]
embeddings = model.encode(
texts,
batch_size=EMBED_BATCH,
normalize_embeddings=True,
).tolist()
for sub_start in range(0, len(texts), UPSERT_BATCH):
sub_end = min(sub_start + UPSERT_BATCH, len(texts))
i = batch_start + sub_start
client.batch_upsert(
COLLECTION_NAME,
ids=list(range(i, i + (sub_end - sub_start))),
vectors=embeddings[sub_start:sub_end],
payloads=[
{
"chunk_id": rows["chunk_id"][i + k],
"doi": rows["doi"][i + k],
"journal": rows["journal"][i + k],
"year": rows["year"][i + k],
"section": rows["section"][i + k],
"cluster_tag": rows["cluster_tag"][i + k],
"text": rows["text"][i + k],
"pmc_id": rows["pmc_id"][i + k],
}
for k in range(sub_end - sub_start)
],
)Un modelo de traducción redactó el resumen final del paciente y la nota clínica SOAP con citas DOI extraídas de la bibliografía consultada en PubMed. La ilustración del proceso de Aura que se muestra a continuación destaca cómo XGBoost genera la predicción del diagnóstico y la búsqueda vectorial aporta la justificación. Consulte la implementación completa del código en GitHub.
Utiliza la búsqueda vectorial para comprender la intención de la consulta, preseleccionar posibles coincidencias y mejorar las respuestas de los modelos de lenguaje grande (LLM). Añade lógica explícita cuando necesites precisión y trazabilidad de los resultados. Si se elimina esta separación, la precisión del proceso de búsqueda disminuye en producción.
Los datos confidenciales tienen una solución local
La búsqueda vectorial debe realizarse en las propias instalaciones, donde ya se encuentran los datos. Normativas como la HIPAA y el RGPD imponen requisitos estrictos sobre el lugar donde deben almacenarse la información de identificación personal (PII) y la información sanitaria protegida (PHI). Para muchos sectores, eso significa dentro de la red interna.
Aura, PayBack y RxGuard se toparon, cada uno por su cuenta, con esta restricción de residencia de datos. El equipo de Aura tuvo dificultades para obtener datos durante el hackatón porque «Los hospitales custodian los datos de los pacientes con gran rigor, de conformidad con la normativa HIPAA». PayBack se ejecutó all-MiniLM-L6-v2 a nivel local, manteniendo las incrustaciones dentro de los mismos límites que los documentos de origen. RxGuard tiene previsto un «A largo plazo, la implementación en las instalaciones de los hospitales, donde el cumplimiento de la HIPAA exige que las consultas sobre la medicación de los pacientes nunca salgan de la red, es precisamente la arquitectura para la que se diseñó Actian VectorAI DB».
Tres equipos llegaron a la misma conclusión en cuanto a la arquitectura. La búsqueda vectorial debe ejecutarse en un entorno controlado desde el primer día, y VectorAI DB garantiza que ese requisito arquitectónico sea sencillo de implementar. Aura puso en marcha VectorAI DB localmente con tres comandos:
git clone https://github.com/hackmamba-io/actian-vectorAI-db-beta
cd actian-vectorAI-db-beta
docker compose up -dEl equipo subrayó: «Ningún dato de los pacientes sale del dispositivo. La base de datos de vectores, la inferencia del modelo y la generación de informes se ejecutan íntegramente en el equipo del usuario. Esto es imprescindible en el ámbito de la IA médica».
RxGuard alojó la extracción mediante PLN, la generación de incrustaciones, la búsqueda vectorial y la recuperación de etiquetas de DailyMed en una única instancia de Vultr, con VectorAI DB ejecutándose a través de Docker Compose. Cuando las normas de cumplimiento impiden enviar datos privados a una API externa o las políticas internas exigen que la inferencia se ejecute localmente, lo más sensato es recurrir a una lógica de implementación local similar.
Una instancia local de Docker te ofrece un control total sobre el flujo de los datos confidenciales, desde su captación e indexación hasta su recuperación y la generación de respuestas. Los roles regulan el acceso al almacén vectorial y cada consulta deja un registro de auditoría. Ningún dato confidencial traspasa los límites de la red sin una autorización explícita.
Lo que estos proyectos te dicen sobre tu próxima construcción
La investigación sobre la seguridad de los medicamentos, la detección de enfermedades autoinmunes y las disputas sobre facturas médicas son tres retos que se plantean en un mismo sector. El sector sanitario y las ciencias de la vida cuentan con décadas de datos clínicos estructurados, marcos normativos estrictos y una terminología fragmentada. Estos tres equipos crearon sistemas operativos en un fin de semana. Los casos de uso que eligieron son solo una pequeña parte de lo que necesita este sector.
Cada proyecto aplicó la arquitectura existente para sistemas de búsqueda de nivel de producción. Como señaló el equipo de RxGuard: «Los componentes de esta solución existen desde hace años. El problema era que nadie los había relacionado con este caso de uso concreto». La integración de modelos, la búsqueda vectorial, los motores de reglas deterministas y la implementación local de Docker no son nada nuevo. Estos equipos identificaron el lugar adecuado para cada herramienta y la aplicaron al contexto adecuado.
Los mismos problemas con los que se encontraron están presentes en tu ámbito. La falta de coherencia en el vocabulario se manifiesta en cualquier corpus con terminología inconsistente, la trazabilidad de los resultados es fundamental para los sistemas que deben justificar cada resultado, y la residencia de los datos es un requisito en los sectores regulados.
Si estás evaluando VectorAI DB como herramienta de búsqueda especializada o como motor RAG diseñado para datos confidenciales, estos tres equipos ya han validado la arquitectura que estás barajando. Prueba Actian VectorAI DB con tus datos siguiendo la guía de instalación local disponible en el repositorio de GitHub.
Únete a la comunidad de Actian en Discord para conectar con otros desarrolladores que están implementando la búsqueda vectorial a nivel local.

Stay connected
Data insights delivered to you.
(i.e. sales@..., support@...)