Wie Actian Vector Ihnen bei der Beseitigung von OLAP-Würfeln hilft




Actian Vector wurde im Jahr 2026 in Actian Analytics Engine umbenannt.
OLAP-Cubes (analytische Verarbeitung online) werden heute in großem Umfang eingesetzt, da viele Datenbankplattformen große Datenmengen nicht schnell analysieren können. Dies liegt daran, dass die meisten Datenbankprogramme die Rechenleistung und den Arbeitsspeicher nicht voll ausschöpfen, um eine optimale Leistung zu erzielen. Einige der Anzeichen hierfür sind:
- Umfangreiche Abfragen beanspruchen am Ende einen Großteil der Serverressourcen.
- Die Reaktionszeit verlangsamt sich mit zunehmender Datenmenge und steigender Nutzerzahl.
- Die Unterstützung paralleler Abfragen wird schwierig oder unmöglich.
- Zusätzliche aggregierte/materialisierte Tabellen, Indizes und manchmal sogar einzelne Data Marts können die erforderliche Leistung und Zustimmung nicht gewährleisten.
OLAP Cube wurden geschaffen, um den Bedarf Nutzerzu decken, große Datenmengen für eine Reihe vorab festgelegter Fragen schnell zu aggregieren, zu segmentieren und zu analysieren. Nun werden wir uns ansehen, wie wir Actian Vector, unsere hochgeschwindigkeitsfähige spaltenorientierte Analysedatenbank, nutzen können, um den Einsatz von OLAP-Cubes überflüssig zu machen.
Was sind die Nachteile der Verwendung von OLAP Cube ?
- Zusätzliche Investitionen in Hardware/Software sowie laufende Wartungskosten.
- Für abfragen OLAP-Cubes sind völlig neue Kenntnisse in Multi-Dimensional Expressions (MDX) erforderlich.
- Es schreibt ein striktes Schema vor (Stern- oder Schneeflockenschema), während einige der Cube-Speicher der neueren Generation 3NF-Tabellen (oder ROLAP-Modelle) unterstützen. Die beste Leistung wird jedoch stets durch ein Star-Schema erzielt.
- Sie schränken abfragen ein. Die Gestaltung des OLAP Cube erfordert sorgfältige Planung. Sobald er erstellt ist, stehen für Abfragen nur noch die darin enthaltenen Zeilen und Spalten zur Verfügung. Oftmals ist für jede neue abfragen ein neuer Cube erforderlich.
- Dies verlängert die Verarbeitungszeit erheblich und verursacht neue Engpässe im BI-Lebenszyklus. Die Nutzer einen hohen Zeitverlust in Kauf nehmen, wenn der OLAP Cube nicht korrekt aufgebaut OLAP Cube . Die Aktualität der Daten wird beeinträchtigt, da diese von den operativen Systemen über das Data Warehouse zum OLAP Cube schließlich zu den BI-Tools übertragen werden müssen.
Ein Blick unter die Haube
Schauen wir uns einmal an, worauf man bei einem OLAP Cube verzichtet. Hier ist ein einfaches Beispiel, bei dem die Rohdaten in der zugrunde liegenden relationalen Datenbank wie folgt aussehen:
| Verkaufsdatum | Jahr | Monat | Jahrzehnt | Stadt-ID | Stadtname | Zustand | Region _id | Name der Region | Produkt-ID | Produktname | Umsatz _Betrag |
| 1990 | 1990 | Januar | 1990–2000 | 1 | Palo Alto | CA | 1 | US-West | 1 | Schrauben | 20 |
| 1990 | 1990 | Januar | 1990–2000 | 1 | Palo Alto | CA | 1 | US-West | 1 | Schrauben | 23 |
| 1990 | 1990 | Januar | 1990–2000 | 1 | Palo Alto | CA | 1 | US-West | 1 | Schrauben | 15 |
| 1993 | 1993 | Januar | 1990–2000 | 1 | Palo Alto | CA | 1 | US-West | 2 | Hammer | 14 |
| 1993 | 1994 | Mai | 1990–2000 | 2 | La Jolla | CA | 2 | US-West | 3 | Schrauben | 60 |
| 2003 | 2003 | Januar | 2000–2010 | 3 | Dallas | TX | 1 | Südstaaten | 1 | Schrauben | 12 |
| 1993 | 1993 | Mai | 2000–2010 | 4 | Atlanta | GA | 2 | Südstaaten | 3 | Schrauben | 34 |
| 2004 | 2004 | Oktober | 2000–2010 | 5 | New York | NY | 1 | Ostküste der USA | 1 | Schrauben | 35 |
| 2004 | 2004 | November | 2000–2010 | 6 | Boston | MA | 1 | Ostküste der USA | 1 | Schrauben | 37 |
| 2004 | 2004 | Dezember | 2000–2010 | 1 | Palo Alto | CA | 1 | US-West | 1 | Schrauben | 39 |
| 2004 | 2004 | Januar | 2000–2010 | 1 | Palo Alto | CA | 1 | US-West | 1 | Schrauben | 42 |
| 2004 | 2004 | Februar | 2000–2010 | 7 | Madison | WI | 1 | Mittel-USA | 1 | Schrauben | 44 |
| 2004 | 2004 | März | 2000–2010 | 8 | Chicago | IL | 1 | Mittel-USA | 2 | Hammer | 46 |
| 2011 | 2011 | April | 2010–2020 | 9 | Salt Lake City | UT | 2 | US-West | 3 | Schrauben | 49 |
| 2012 | 2012 | Mai | 2010–2020 | 1 | Palo Alto | CA | 2 | US-West | 1 | Schrauben | 51 |
| 2013 | 2013 | Juni | 2010–2020 | 2 | La Jolla | CA | 2 | US-West | 3 | Schrauben | 53 |
| 2014 | 2014 | Juli | 2010–2020 | 10 | Jersey City | NJ | 2 | Ostküste der USA | 1 | Schrauben | 56 |
Wenn ein Nutzer daran interessiert Nutzer , aus den oben genannten Daten einen einfachen OLAP Cube den Umsatz zu erstellen, und die gewünschten Kennzahlen die aggregierten Umsatzbeträge für jedes Jahrzehnt, jedes Jahr sowie nach Produkt und Region umfassen, OLAP Cube der OLAP Cube folgende Daten enthalten:
| Jahrzehnt | Jahr | Name der Region | Produktname | Umsatz | Durchschnittspreis |
| 1990–2000 | 1994 | US-West | Schrauben | $60.00 | $19.33 |
| 1990–2000 | 1993 | Südstaaten | Schrauben | $34.00 | $14.00 |
| 1990–2000 | 2003 | Südstaaten | Schrauben | $12.00 | $60.00 |
| 2000–2010 | 2004 | Mittel-USA | Schrauben | $44.00 | $34.00 |
| 2000–2010 | 2004 | Zentral-USA | Hammer | $46.00 | $12.00 |
| 2000–2010 | 2004 | Ostküste der USA | Schrauben | $72.00 | $44.00 |
| 2000–2010 | 2004 | US-West | Schrauben | $81.00 | $46.00 |
| 2000–2010 | 2011 | US-West | Schrauben | $49.00 | $36.00 |
| 2010–2020 | 2012 | US-West | Schrauben | $51.00 | $40.50 |
| 2010–2020 | 2013 | US-West | Schrauben | $53.00 | $49.00 |
| 2010–2020 | 2014 | Ostküste der USA | Schrauben | $56.00 | $51.00 |
| 2010–2020 | 1994 | US-West | Schrauben | $60.00 | $53.00 |
Die Daten werden nach Jahrzehnt, Jahr, Region und Produktname aggregiert. Die Details auf Transaktionsebene gehen dabei verloren. Aus diesem Grund bieten einige der ausgereifteren OLAP Cube eine Drill-Through-Funktion an, Nutzer dem Nutzer ermöglicht, die Detaildaten Nutzer . Allerdings kann sich die Leistung verschlechtern, wenn die Datenmenge hinter der Aggregation sehr groß ist.
Eine typische abfragen diese Daten aus dem Cube abzurufen, würde je nachdem, was der Nutzer in den Zeilen, Spalten und Datenpunkten sehen Nutzer , wie folgt aussehen.
WITH
MEMBER[measures].[avg price] AS
'[measures].[sales_amt] / [measures].[sales_num]'
SELECT
{[measures].[sales_sum],[measures].[avg price]} ON COLUMNS,
{[product].members, [year].members} ON ROWS
FROM SALES_CUBE
Der „Avg_price“ ist eine berechnete Kennzahl. Beachten Sie, dass berechnete Kennzahlen entweder in der OLAP Cube festgelegt oder in abfragen definiert werden können. Einer der Vorteile von in OLAP-Cubes definierten berechneten Kennzahlen besteht darin, dass die berechnete Kennzahl automatisch mit den neuen Parametern neu berechnet wird, wenn die abfragen geändert abfragen , um einen Filter hinzuzufügen, oder wenn eine zusätzliche Dimension hinzugefügt wird.
Und so OLAP Cube der OLAP Cube eine Teillösung für ein Problem – nämlich dass zeilenorientierte relationale Datenbanken für analytische Abfragen einfach nicht schnell genug sind. Was würden sich Ihre OLAP-Anwender wünschen, wenn sie alles hätten, was sie wollen? Von den Anwendern hören wir folgende Anforderungen:
- OLAP-ähnliche Geschwindigkeit oder besser mit vollständiger abfragen hoc abfragen
- die Möglichkeit, jedes beliebige Datenmodell zu verwenden
- All ihre bevorzugten BI-Tools
- die aktuellsten verfügbaren Daten
- Zugriff auf alle Detaildaten in derselben abfragen, ohne dabei Leistungseinbußen hinnehmen zu müssen
Klingt das unmöglich? Das ist es nicht. Actian Vector kann all das und noch mehr leisten. Wie ist das möglich? Lesen Sie weiter!
Ersetzen von OLAP-Cubes durch Vector
Actian Vector ist ideal geeignet, um OLAP-Cubes zu ersetzen. Wir haben es von Grund auf neu entwickelt und dabei zahlreiche Optimierungen vorgenommen, um die Leistung analytischer Abfragen deutlich zu steigern. Hier ein kurzer Überblick über das, was wir entwickelt haben:
- Vektorverarbeitung: Durch die Vektorisierung wird die Parallelisierung auf eine neue Ebene gehoben, indem ein single instruction multiple data gesendet wird, was eine Reaktion nahezu in Echtzeit ermöglicht.
- Vertikale Speicherung: Die spaltenorientierte Speicherung reduziert den E/A-Aufwand erheblich, indem nur die für eine abfragen erforderlichen Spalten abfragen den Arbeitsspeicher geladen werden, anstatt alle Spalten in den Arbeitsspeicher zu laden und dann die für die abfragen erforderlichen Spalten herauszufiltern.
- Optimiert In-Memory: Die gezielte Nutzung des Prozessor-Caches und des Hauptspeichers sowie in-memory und Dekomprimierung in-memory beschleunigen den Prozess.
- Flexibilität: Vector funktioniert mit jedem Datenmodell – Sternmodell, Schneeflockenmodell, 3NF und denormalisierten Modellen –, sodass keine Datenmaterialisierung erforderlich ist. Da der Nutzer direkt mit der Datenquelle Nutzer , bleibt abfragen erhalten.
- Funktionsvielfalt: Dank fortschrittlicher OLAP-/Windows-Funktionen Nutzer eine Vielzahl komplexer Abfragen durchführen.
Umstieg von Cubes auf Actian Vector
Um BI-Berichte aus OLAP-Cubes zu migrieren, ist es wichtig, die Cube-Funktionen zu kennen, die migriert werden müssen. Dazu gehören:
- OLAP Cube – Das Datenmodell des Cubes selbst verstehen und es auf das Datenmodell RDBMS abbilden.
- Verwendete MDX-Abfragen, berechnete Kennzahlen und Filter.
- KPIs – Leistungskennzahlen.
- Was-wäre-wenn-Analyse für verschiedene Szenarien.
OLAP Cube
Untersuchen Sie den OLAP Cube ermitteln Sie, auf welchem Datenmodell er basiert: ROLAP, HOLAP oder MOLAP. ROLAP-Modelle basieren auf Datenmodellen der dritten Normalform (3NF), bei denen die Daten stark normalisiert sind. In der Regel kommt es bei der Verwendung von ROLAP-Modellen in Cubes zu Leistungseinbußen.
HOLAP ist ein Hybridmodell, bei dem eine Kombination aus Stern- oder Schneeflockenmodellen, denormalisierten Tabellen und der 3NF zum Einsatz kommt. Dies geht jedoch auch mit Leistungseinbußen einher.
MOLAP ist das bevorzugte zugrunde liegende Modell, bei dem ein Stern- oder Schneeflocken-Datenmodell zum Einsatz kommt und die beste Leistung bietet. In der Regel liegen die Quelldaten im BI-Lebenszyklus in 3NF vor und müssen einen langwierigen Transformationsprozess durchlaufen, um in ein Star-Schema umgewandelt zu werden. Dieser Aufwand wird im Vorfeld in Kauf genommen, um später eine bessere Leistung zu erzielen.
Die folgenden Faktoren müssen geprüft werden, wenn an der Datenquelle eine abfragen verwendet abfragen :
- Dimensionen: Wie werden diese im Cube ermittelt? Speziell für ROLAP- und HOLAP-Modelle.
- Maße: Sowohl berechnete als auch normale Maße.
- Fakten: Handelt es sich um eine einzelne Tabelle oder um eine Kombination aus mehreren Tabellen?
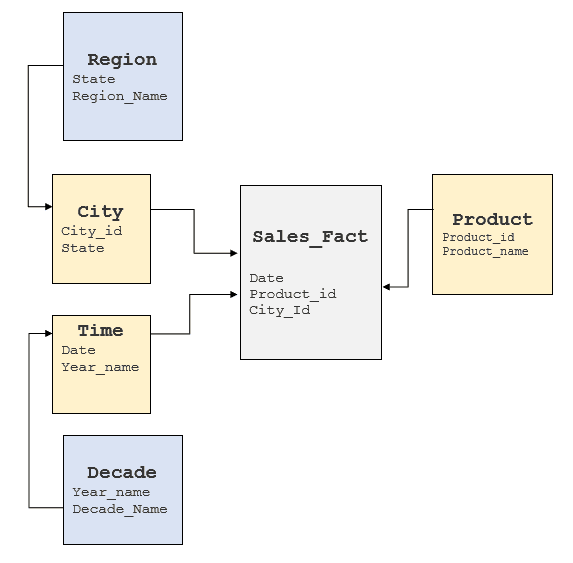
Es ist wichtig, die oben genannten Faktoren zu untersuchen, um ein Verständnis für das zugrunde liegende RDBMS zu erlangen und zu erkennen, wo diese Elemente zu finden sind. In der Regel basieren Data Warehouses auf Stern- oder Schneeflockenmodellen, doch manche Data Warehouses weisen ein stark normalisiertes Modell auf. Für den oben dargestellten Cube würde ein typisches Schneeflockenmodell wie folgt aussehen:
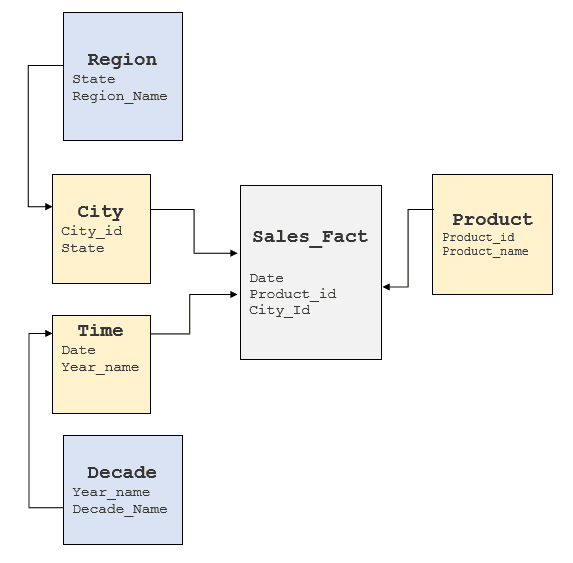
Konvertierung von MDX-Abfragen in SQL
Sehen Sie sich die abfragen an abfragen identifizieren Sie die folgenden Elemente aus dem OLAP Cube abfragen. Schlagen Sie bei Bedarf in einem grundlegenden MDX-Tutorialnach. Folgendes müssen Sie wissen:
- Abmessungen
- Maßnahmen
- Berechnete Kennzahlen
- Datenausschnitte oder Filter (Beispiel: Wenn der Nutzer nur die Umsätze für „Schrauben“ oder nur für den Monat Januar wissen Nutzer .)
Nehmen wir als Beispiel die MDX abfragen dem vorigen Abschnitt:
WITH
MEMBER[measures].[avg price] AS
'[measures].[sales_amt] / [measures].[sales_num]'
SELECT
{[measures].[sales_sum],[measures].[avg price]} ON COLUMNS,
{[product].members, [year].members} ON ROWS
FROM SALES_CUBE
Wo:
- Der Durchschnittspreis ist eine berechnete Kennzahl
- „Sales_amt“ ist eine Kennzahl, die im Cube definiert ist
- [product].members ist die Produktdimension
- [Jahr].members ist die Dimension „Jahr“
Nun möchten Sie die MDX-Abfragen auf der Grundlage des obigen Modells in SQL-Abfragen umwandeln. Die abfragen sich wie folgt in SQL umschreiben:
SELECT year_name, product_name, SUM(sales_amt) AS sales, AVG(sales_amt) AS avg_sales FROM Sales FT join Time_Dimension TD on FT.date = TD.date join Month_Dimension MD on month(TD.date) = MD.month join Year_Dimension YD on year(date) = YD.year join City_Dimension RD on FT.city_id = RD.city_id join State_Dimension SD on FT.state_id= RD.state_id join Product PD on FT.product_id = PD.Product_id group by year_name, product_name
oder vereinfachen Sie die abfragen weiter, indem Sie die Dimensionstabellen entfernen, sofern diese nur zum Aufbau des Cubes eingeführt wurden:
Wähle date_part(year, sale_date) als year_name, product_name, sum(sales_amt) als sales, avg(sales_amt) als avg_sales aus Sales FT verknüpft mit Product PD über FT.product_id = PD.Product_id gruppiert nach decade, year_name, region_name, product_name
Hinweis: Damit soll nicht gesagt werden, dass Verknüpfungen zu anderen Tabellen vollständig vermieden werden können. Es können lediglich Tabellen entfernt werden, die lediglich eingeführt wurden, um dem strengen Stern- bzw. Schneeflockenschema zu entsprechen.
Falls das BI-Tool keine Fenster-Analysefunktionen bereitstellt, greifen Sie auf die von Vector bereitgestelltenAnalysefunktionen undFensterfunktionen zurück, damit diese direkt in der Datenbank ausgeführt werden können.
Wenn der Nutzer detaillierte Informationen zu einer bestimmten Gruppe von Zeilen abrufen Nutzer , kann die Aggregation entfernt und die abfragen in der Datenbank ausgeführt abfragen . Wenn der Nutzer beispielsweise die Verkaufszahlen für das Produkt „Bolts“ im Januar 1993 genauer untersuchen Nutzer , könnte er die folgende abfragen verwenden:
SELECT DATE_PART(year, sale_date) AS year_name, product_name, sales_amt AS sales FROM Sales FT JOIN Product PD ON FT.product_id = PD.Product_id WHERE Product_name = „Bolts“ AND DATE_PART(year, sale_date) = „1993“ und Date_part(month, sale_date) = „Januar“
Leistungskennzahlen
In der Wirtschaftsterminologie ist ein Key Performance Indicator (KPI) ein quantifizierbarer Maßstab zur Beurteilung des Geschäftserfolgs.
Ein einfaches KPI-Objekt besteht aus: Basisinformationen, dem Zielwert, dem tatsächlich erzielten Wert, einem Statuswert, einem Trendwert und einem Ordner, in dem der KPI angezeigt wird. Zu den Basisinformationen gehören der Name und die Beschreibung des KPI. In einem Microsoft SQL Server Analysis Services-Cube ist das Ziel ein MDX-Ausdruck, dessen Ergebnis eine Zahl ist. Der Istwert ist ein MDX-Ausdruck, dessen Ergebnis eine Zahl ist. Der Status- und der Trendwert sind MDX-Ausdrücke, deren Ergebnis eine Zahl ist. Der Ordner ist ein vorgeschlagener Speicherort, an dem der KPI dem Kunden präsentiert werden soll.
Zwar bieten einige OLAP cube elegante und benutzerfreundliche Schnittstellen zum Speichern und Implementieren von KPIs und Aktionen, doch lassen sich diese auch problemlos durch eine Kombination aus gängigen Datenbankfunktionen und Anwendungscode realisieren.
Was-wäre-wenn-Analyse für verschiedene Szenarien
Einige Cube-Stores Fähigkeiten zur Was-wäre-wenn-Analyse mit benutzerfreundlichen Oberflächen. Dies lässt sich mit etwas Aufwand auch mithilfe von Datenbankfunktionen und Anwendungscode umsetzen.
Diese Art der Analyse erfordert die Speicherung verschiedener Szenarien und die Untersuchung der Auswirkungen der aktuellen Geschäftslage im Vergleich zu diesen unterschiedlichen Szenarien. Sie wird häufig in Finanzdienstleistungs- und Handelsunternehmen eingesetzt, um die Risiken und Auswirkungen des Handels kontinuierlich zu bewerten.
Eine detaillierte Anforderungsanalyse wäre erforderlich und würde den Rahmen dieses Blogbeitrags etwas sprengen.
Zusammenfassung
Für OLAP-Anwender, die den BI-Lebenszyklus vereinfachen möchten, bietet die Actian Vector-Analysedatenbank mit ihrer bahnbrechenden Technologie, ihrer überragenden Leistung und ihren integrierten Fähigkeiten eine praktikable Alternative zu OLAP-Cubes. Die Nutzen Migration liegen in geringeren Kosten und einer besseren Nutzer durch abfragen bei abfragen .
Glauben Sie mir nicht einfach blind. Probieren Sie es selbst aus. Wir haben einen Leitfaden und eine Testversion von Vector sowie alle Begleitmaterialien vorbereitet, die Sie benötigen, um Vector in etwa einer Stunde zu testen. Hier können Sie unserer aktiven Vector-Community Fragen stellen.
Bleiben Sie in Verbindung
Datenanalysen direkt bei Ihnen.
(z. B. sales@..., support@...)